CURVE FITTING AND THE METHOD OF LEAST SQUARES
advertisement

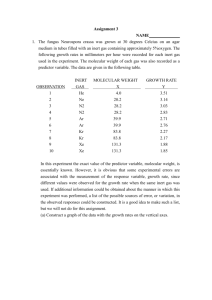
CURVE FITTING AND THE METHOD OF LEAST SQUARES Introduction. The full utilization of quantitative data typically involves the fitting of the data to a mathematical model. Fitting is usually performed for one of two purposes. On the one hand, the scientist wishes to determine a physical quantity and a measure of its uncertainty from experimental data when there is a well-established relationship between variables. For example, Ohm's Law (V = IR) states that the voltage V across a resistor is directly proportional to the current I through it. Consequently one can use measured values of V and I to determine the best value of the resistance R, a parameter. On the other hand, the goal might be to establish a mathematical relationship between a dependent variable such as the toxicity of chlorinated hydrocarbons and independent variables such as their chemical and physical properties. A wide range of tools has been developed to solve these problems. The most frequently employed technique is the method of least squares, which will be discussed in this section and used in General Chemistry. We shall only discuss in General Chemistry the method of linear-least-squares, sometimes referred to as linear regression or simply least squares because the applications in the lecture and laboratory will be limited to those cases in which there is a linear relationship, i.e. y = mx + b, between a single dependent variable and a single independent variable. Additional fitting procedures for more complicated problems are addressed in Chemistry 160. Rationale of the method of linear least squares. Suppose that a student measures V in Volts and I in Ampere and wishes to determine the resistance in Ohms from the data (c.f. Table 1). The traditional approach would involve constructing a graph of V versus I, drawing the "best" line through the points, and calculating the slope of the graph, V/I, which is the required value of R. This time honored procedure suffers from a number of deficiencies. First, what is meant by "best" is not clearly defined and the act of drawing the line through the points is subject to bias, particularly if the experimental data are noisy. Furthermore, the freehand procedure does not yield an estimate of the uncertainty of the slope. In careful work we require an objective procedure that reduces bias on the part of the researcher and yields a quantitative measure of the uncertainty of the parameters and the validity of the model. Statisticians have shown that the elementary method of least squares yields the best results if two conditions often satisfied in chemical experiments are met: 1) The principal source of error in the experiment is in the values of the dependent variable. 2) The errors in the dependent variable are random and fit a normal or Gaussian distribution. Even if these conditions are not met exactly, a careful comparison with other techniques has shown that the method of least squares usually yields acceptable results when applied to a carefully prepared set of chemical data. Table 1. V versus I for a Hypothetical Resistor V(Volt) I(Ampere) 5.2 0.10 9.8 0.20 15.4 0.30 20.1 0.40 24.6 0.50 METHOD OF LEAST SQUARES PAGE 1 Two attempts at drawing a freehand graph (Figures 1 and 2) demonstrate the basis for the method. In Figure 1, the line has clearly been poorly drawn with the result that most of the experimental points are far from the line. In contrast, the superior graph in Figure 2 is drawn so that the points are close to the line. Exact agreement should not be expected. The demon noise is always with us and a perfect fit is either evidence for fraudulent data or egregious abuse of fitting procedures. Note, however, in Figure 2 that the deviations of the points from the line, sometimes called the residuals, are small and that the signs of the deviations are randomly distributed so that there is no pattern to which points are above the line and which are below. Clearly the well-trained draftsman draws a line which minimizes these deviations or some function of the deviations. Theorems from statistics show that optimum results, i.e. the best-fit line, is obtained when the sum of the squares of the deviations, S, is minimized, provided that the assumptions outlined above are satisfied. Hence, the technique is referred to as the method of least squares. Furthermore, there is a bonus in the approach. Statisticians have also derived equations for the standard deviations of the parameters and other useful quantities that will be discussed in the following treatment of an illustrative example. V(Volt) Figure 1. "Poor" Fit 30 25 20 15 10 5 0 0 0.2 0.4 0.6 0.4 0.6 I(Ampere) V(Volt) Figure 2. "Good" Fit 30 25 20 15 10 5 0 0 0.2 I(Ampere) METHOD OF LEAST SQUARES PAGE 2 Illustrative Example and Use of Excel. In General Chemistry we shall use the Analysis Tool Package add-in to Microsoft Excel to perform the linear regression calculations. In this section we shall use an illustrative example which will include a discussion of the results produced by Excel. This example will be demonstrated in class. Following this example is a second one that will be assigned as homework and will be due at the beginning of the following lab period. Our first example is a set of student measurements in the gas phase of the temperature, pressure, volume, and mass of an unknown gas that displays small deviations from ideality. The goal is to obtain the molecular weight of the gas and a measure of its non-ideality. Before jumping in, some algebra is required. It is well known that an ideal gas obeys the equation pV = nRT from which one can readily show that pV/nRT = 1. Nonideality can be modeled by adding a term linear in the pressure p, yielding equation (1) pV/nRT = 1 + Bp (1) where the coefficient B is called the virial coefficient. There is nothing mysterious about this equation. It is a simple example of the Maclaurin theorem in mathematics that states that all well behaved functions appear linear over a small range of the independent variable, p in our case. One more step is required, as we do not know the molecular weight. From stoichiometry we know that n = m/M so with a bit of manipulation one can quickly derive equation (2): pV/mRT = (B/M)p + 1/M (2) Equation 2 states that for real gases a plot of pV/mRT, the dependent variable, versus p, the independent variable, is linear, i.e. an equation of the form y = mx + b, with a slope (B/M) and an intercept, 1/M. Note that a bit of mathematics must be performed to put the data into a linear format. In the laboratory, we shall provide the identity of the dependent and independent variables that are linearly related. In a new situation, the researcher may have to derive such a relationship. In our case, the student collected samples of the gas in a 1.1153 liter bulb and obtained the data tabulated in the first three columns of Table 2. As a first step the pressures are converted from torr to atm and the dependent variable pV/mRT is calculated, yielding columns 4 and 5 in the table and the Excel spreadsheet. p(torr) 46.6 76.3 101.6 144.1 155.8 Table 2. Gas Density Data for an Unknown Gas T(K) m(g) p(atm) pV/mRT (mole/g) 296.2 0.5504 0.06118 0.005101 296.2 0.8906 0.10040 0.005173 296.1 1.1780 0.13368 0.005209 297.0 1.6511 0.18961 0.005255 297.2 1.7871 0.20500 0.005246 METHOD OF LEAST SQUARES PAGE 3 p_torr 46.6 76.3 101.6 144.1 155.8 T_K 296.2 296.2 296.1 297 297.2 m_g 0.5504 0.8906 1.178 1.6511 1.7871 p_atm 0.0613 0.1004 0.1337 0.1896 0.2050 pV/mRT 0.00510925 0.00517001 0.00520649 0.00525254 0.00524330 SUMMARY OUTPUT Regression Statistics Multiple R 0.969570181 R Square 0.940066336 Adjusted R Square 0.920088448 Standard Error 1.65701E-05 Observations 5 ANOVA df Regression Residual Total SS MS 1.29199E-08 1.292E-08 8.23704E-10 2.746E-10 1.37436E-08 1 3 4 F Significance F 47.055341 0.00634294 Coefficients Standard Error t Stat P-value 0.005065899 2.04056E-05 248.25997 1.4412E-07 0.000945072 0.000137772 6.8596896 0.00634294 Intercept p_atm Lower 95% Upper 95% Lower 95.0% Upper 95.0% 0.005000959 0.00513084 0.005000959 0.005130839 0.00050662 0.00138352 0.00050662 0.001383524 RESIDUAL OUTPUT Observation 1 2 3 4 5 Predicted pV/mRT 0.005123847 0.005160779 0.00519224 0.005245089 0.005259639 Residuals -1.45938E-05 9.2353E-06 1.42491E-05 7.44744E-06 -1.63381E-05 p_atm Line Fit Plot 0.00535 0.00530 pV/mRT pV/mRT 0.00525 Predicted pV/mRT 0.00520 Linear (Predicted pV/mRT) 0.00515 0.00510 0.00505 0.0000 0.0500 0.1000 0.1500 p_atm METHOD OF LEAST SQUARES PAGE 4 0.2000 0.2500 When the Excel regression (linear least squares) routine is run with pV/mRT as the dependent (y) variable and p as the independent variable, the information presented on the previous page is obtained. The format of the presentation has been edited somewhat so that the data would fit on one page. The significance of the numbers in the report is given below. (We will demonstrate how to run this analysis in class. Detailed written instructions for the homework example are also provided in the following pages.) 1) SUMMARY OUTPUT. The information in this section, which is appended to the right of the spreadsheet, indicates how well the data fit the linear model. “Multiple R” provides the linear correlation coefficient, R, which tests whether the data support the hypothesis that there is a relationship between the dependent variable and the independent variable. If there is no relationship at all, R is zero. If there is a statistically significant relationship, R is close in magnitude to 1. The sign of R is given by the sign of the slope. In our case, R is 0.962 and the hypothesis that the gas deviates measurably from ideality is supported. The square of R, which is 0.925 in this example, has a straightforward interpretation. R2 gives that fraction of the variation in the dependent variable that is explained by the model. If R2 were a small number, we would have to reject the results of the entire calculation and consider another model. Some statisticians adjust R in the case of a small sample size and calculate the adjusted R (third entry in the output); we shall not use this statistic. The fourth entry, the standard error or the standard deviation of the residuals, which is 1.99 x 10-5, measures the goodness of fit. This quantity, like all standard deviations, is based on the deviations of the data points from the line. It is calculated by dividing the sum of the squares of the deviations by the number of degrees of freedom and by taking the square root of this quotient. The number of degrees of freedom equals the number of data points (the last entry in the section) minus the number of parameters. We determined two parameters, a slope and an intercept, in this case so the number of degrees of freedom is 5 - 2 = 3. A small standard error indicates that the model is good and the errors in the values of the dependent variable are small. The standard error is also used to determine whether the rejection of a suspect data point is justified. If a datum is contaminated by systematic error, the standard error will decrease significantly when the suspected datum is removed from the dataset. In close cases where bias might influence the decision to retain or reject a datum, one uses a quantitative procedure called the F test, which is based on the standard error. 2) ANOVA. ANOVA stands for analysis of variance. The most important statistic in this section is the F value, 38.8359. This statistic is used to determine if the proposed relationship is statistically significant. The column labeled “significance of F” is the probability that the observed fit could be generated by random means alone. Note that this probability, 0.009878, is a small number. Any probability larger than 0.05 is considered to be unacceptably large. A new model for the relationship or better data should be sought in such cases. 3) Coefficients. Assuming that we have a statistically significant fit, the numbers that we shall normally use will be found here. The row labeled “Intercept” contains statistics for the METHOD OF LEAST SQUARES PAGE 5 intercept unless the line is forced through the origin. In this case, which you use in the colorimetric analysis experiment, N/A (not apply) will appear in the columns of this row. The first numerical column in the “Intercept” row gives the value of the intercept, 0.005059 g/mole. The second number yields the standard deviation or error of the intercept, 2.45 x 105 . Note that the standard deviation of the intercept is a small fraction of the intercept so the intercept is a well-defined statistic. Recall that we use the standard deviation of a parameter to determine the number of significant digits in the value to be reported. If one compares the two numbers, one notes that the 10-5’th place is the first digit with significant error. This is the least significant digit (marked with an * below) and all digits to the right are insignificant. * intercept 0.005059 standard deviation of the intercept 0.0000245 Hence the value is rounded off to 0.00506. To obtain the 95% confidence interval of the intercept, we multiple the standard deviation of the intercept by the Student’s t which is 3.182 for 5 data, 2 parameters, and 3 degrees of freedom and obtain (3.182)(2.45 x 10-5) = 7.8 x 10-5. The final result is reported as (5.060.078) x 10-3 mole/g. Recall that our goal was the determination of the gas’ molecular weight, which we obtain by taking the reciprocal of the intercept. With the use of the calculus, one can calculate a standard deviation for the molecular weight from the standard deviation of the intercept. This derivation which is called a propagation of errors analysis is covered in Physics 51 and Chemistry 160. The column labeled P-value is the probability that a non-zero value of the intercept could be generated by random means alone. Note that P is very small; if P were 0.05 or greater, there would be a 5% or greater chance that the results are spurious and we would have to reject the analysis. The final data in the row yield the actual interval defined by the value of the intercept and the 95% confidence interval, i.e. the intercept minus the 95% CI and the intercept plus the 95% CI. The next row labeled by the dependent variable name provides the same information for the slope. That is, m = 0.00010 mole/g-atm. Note that the relative standard deviation of the slope is much larger than that of the intercept and the slope can only be reported to 2 significant digits. The 95% CI of the slope is calculated by multiplying the Student’s t by the standard deviation of the slope, (3.182)(0.000165) = 0.00053 so the result is reported as 0.000100.00056 mole/g-atm. The slope is as not well determined. This should come as no surprise. Gases deviate very slightly from ideal-gas behavior and measuring small quantities is a difficult task. 4) RESIDUAL OUTPUT. This section contains a table of the predicted values of the dependent variable and the residuals. The predicted values are calculated using the equations, the least-square parameters, and the value of the independent variable. The residuals or deviations give the differences between the observed and calculated values of METHOD OF LEAST SQUARES PAGE 6 the dependent variable. A large residual marks a suspect datum. If all goes well, the signs of the residuals should be randomly distributed. A pattern to these signs is an indication of systematic error and the need to modify the equation. Variations on the Theme and Extensions. More advanced packages such as NCSS which is used in Chemistry 160 and Mathematics 57 permit handling more than one independent variable as well as weighting the data points. Weighting is important if the data are of uneven quality. Our main focus in General Chemistry is on fitting data to a known equation and determining parameters such as the absorption coefficient in the colorimetric manganese experiment. In fields such as drug design, the focus shifts to developing models with predictive value and a different approach called cross-validated statistics is used. The NCSS package can also solve problems in which the relationship between the dependent and independent variable is intrinsically non-linear. All of these advanced topics are considered in Chemistry 160 with the aid of the NCSS package. METHOD OF LEAST SQUARES PAGE 7 Least Squares Exercise Using Microsoft Excel. The following exercise illustrates the method of least squares and regression calculations with Excel. Complete the following exercises on your own and turn in the printouts and answers to the questions at the beginning of your next lab period. 1) Log on to the campus network. Start the Excel software. It will automatically open with a new spreadsheet. 2) In the first column, enter the label “ T_C “ in the first row and in rows 2-11 the following values of the temperature in degrees Centigrade: 0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100. This will be the independent variable in the first model. Label the second column “p_torr” and use Appendix F in your laboratory manual to enter in rows 2-12 the vapor pressure in torr of water at the 11 temperatures defined above. 3) Label columns 3-6 “T_K”,”1/T_K”,” p_atm”, and “ln(p_atm)”, respectively. Use the spreadsheet functions (cell definition, copy, and paste) to load columns 3-5 with the values of the absolute temperature, the inverse of the absolute temperature, the vapor pressure in atmosphere, and the natural log of the vapor pressure in atmosphere. 4) Consider as the first model a linear dependence of vapor pressure on Centigrade temperature. Use the following set of instructions to perform a least squares fit with vapor pressure in atm as the dependent variable and Centigrade temperature as the independent variable. a) To access the Regression window, click on Tools in the spreadsheet command line to access the Tools menu and then on Data Analysis. Select Regression from the Data Analysis menu and click on OK. (In the event that the regression features have not been installed, further steps are required. To install the features, click on Tools, then Add-Ins, and Analysis ToolPak and Analysis ToolPak-VBA, and OK. You may wish to seek assistance from a consultant at OIT in performing this step.) b) When the regression window appears, select the following options by clicking on the appropriate boxes: labels, confidence level, residuals, and line fit plot. Do not select the “Constant Is Zero” option. This option is used in cases where the intercept is known to be zero, e.g. the Colorimetric Manganese experiment. Select the values of the dependent or Y variable by first clicking in the field for Input Y Range and then selecting the spreadsheet column that contains the values of the dependent variable and its label. Similarly select the values of the independent or X variable by clicking in the field for Input X range and then selecting the spreadsheet column that contains the values of the independent variable and its label. In general, you don’t have to use all the data in a column. You can use spreadsheet techniques to choose the data selectively. METHOD OF LEAST SQUARES PAGE 8 c) You would like to have the regression results on the same page as the input data. To achieve this result, select the option Output Range, click in the field for Output Range and then in the leftmost, top spreadsheet cell which is empty. This will be the G1 cell in your case. This step informs Excel of the location of the regression results. d) Initiate the calculations by clicking on OK. In a few seconds the regression results and the graph will appear on the screen. e) You will probably want to edit the graph produced by Excel as it is not quite in the format required in your lab reports. The following steps will achieve this goal. i. You want the graph to fill or nearly fill a full page. Force Excel to show the page boundaries by clicking on Page Setup in the File menu and then OK. Then move the graph into the first empty page and change its size to fill the page. To this end, click on the graph and a frame will appear around its perimeter. Grab the framed graph with the mouse and move the graph to its new location. When the mouse is at one of the four corners, the sizing tool will appear which can be used to change the size of the graph. ii. Add the best-fit line; Excel calls this the trendline. Activate the graph (chart in Excelese) for editing by clicking on it. Click on any one of the symbols marking a predicted value of the dependent variable. From the Chart menu, choose Add Trendline. A Trendline menu will now appear. Select the Linear trendline on the Type tab. The best-fit line is drawn between the first and last points. To extend the line so that it covers the entire graph, access the Options tab and adjust the forward and backward values of the Forecast parameter. For example, if the X value of the leftmost point on the graph is 0.2 and you want to line to extend to X = 0, the backward forecast value should be 0.2. Click on OK when you have set all the options and the best-fit line will be drawn. iii. In some case, you may wish to customize your graph further. Double click on the portion of the graph you'd like to edit and an options menu should appear. You can now edit the caption for the graph and the axes. By clicking on the symbols for the data points in the legend box on the right, you can change the symbol type and color. I usually choose the largest possible symbol for the measured values of the dependent variable and change the size and color of the symbol for the calculated values so that the latter merges with the best-fit line. You can always exit the editing mode by clicking on an empty cell outside of the graph. f) Once the graph has edited, print the spreadsheet by clicking the Print item under the File menu. METHOD OF LEAST SQUARES PAGE 9 g) Save the spreadsheet on your diskette or user space. Insert a formatted diskette in the a: drive. Click on the Save As item under the File menu. The hard drive always comes up as the default drive so you have to select the a: drive if you're saving to diskette. Also provide a file name and then execute the save by clicking on OK. Once you have saved a spreadsheet, you can always read it later by clicking on the Open item under the File menu. 5) Now that the calculations and graphics have been done, you can analyze the results. Do the statistics support the conjecture that vapor pressure depends on temperature? Is the linear model a good one? How do you know? What are the least-squares values of the slope and intercept and the associated 95% confidence intervals to the appropriate number of significant digits? Answer these questions directly on your printout or on a separate page and turn in with the printout of your results. 6) Refinement of the model. We deliberately started with a poor model so that you could recognize the characteristics of a “dog”. One can show from thermodynamics that the natural logarithm of vapor pressure depends linearly on the inverse of the absolute temperature so repeat the analysis using the better model. a) Re-open the Regression window (recall click on Tools, Data Analysis, and Regression) and select the natural log of the vapor pressure in atm as the dependent variable and the inverse of the absolute temperature as the independent variable. b) Repeat the regression calculations. All of the options in the Regression window have been preset in the previous calculation. After you click OK, you will be asked if you want to erase the old output. Choose a new output destination cell to see the new analysis without overwriting the previous results. c) Save and print out your results for the second analysis. d) Is the second model better? How do you know? As above, report the values of the slope and intercept with the associated 95% confidence intervals along with the answers to the above questions and turn in with the printout of your results. Don’t forget units and significant digits. 7) When you are done, exit Excel by clicking on the Exit item under the File menu. Log off of the network unless you want the next user to have access to your user space. least_sq.doc WES, 3 July 1997 updated, January 2, 2002, JMT METHOD OF LEAST SQUARES PAGE 10