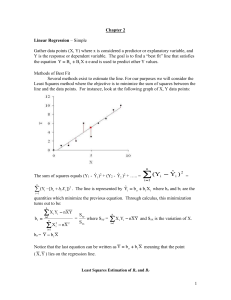
MULTPLE REGRESSION-I
advertisement

MULTPLE REGRESSION-I
Regression analysis examines the relation between a single dependent variable Y and one
or more independent variables X1, …,Xp.
SIMPLE LINEAR REGRESSION MODELS
First Order Model with One Predictor Variable
Yi 0 1X i1 i , i=1,2,…,n
0 is the intercept of the line, and 1 is the slope of
the line. One unite increase in X gives 1 unites
increase in Y.
i is called a statistical random error for the ith
observation Yi. It accounts for the fact that the
statistical model does not give an exact fit to the
data.
i cannot be observed. We assume:
o E(i)=0
o Var(i)=2 for all i=1,…,n
o Cov(i, j)=0 for all ij
Response/Regression function and an example:
EYi 0 1X i1
EYi 9.5 2.1X i1
The response Yi, given the level of X in the ith
trial Xi, comes from a probability distribution
whose mean is 9.5+2.1 Xi. Therefore,
Response/Regression function relates the
means of the probability distributions of Y (for
given X ) to the level of X.
0, 1, and are unknown parameters and have to
be estimated from data. We use b0, b1, and e for the
estimates of 0, 1, and .
Fitted Values and an Example:
Ŷi b0 b1Xi1
is called fitted values
Ŷi 9.6 1.9Xi1
Residual and an Example:
ei Yi Ŷi
is called the residual value
ei 108 (9.6 1.9 * 45) 12.9
i 108 104 4
o The residuals are observable, and can be used to check
assumptions on the statistical random errors i.
o Points above the line have positive residuals, and points below the
line have negative residuals
o A line that fits the data well has small residuals.
o We want the residuals to be small in magnitude, because large
negative residuals are as bad as large positive residuals. Therefore,
we cannot simply require ei 0.
o In fact,
e
i
0. (derivation on board).
o Two immediate solutions:
| e | to be small
Require e to be small
- Require
-
i
2
i
o We consider the second option because working with squares is
mathematically easier than working with absolute values (for
example, it is easier to take derivatives).
Find the pair (b0, b1) that minimizes e (least
square estimates)
o We call SSE= e the Residual Sum of
Squares
o We want to find the pair (b0, b1) that
minimizes
SSE= e = (Y b b X )
2
i
2
i
2
i
2
i
0
1
i
o We set the partial derivatives of SSE with
respect to b0, b1 equal to zero:
SSE
0
Normal equation (1) :
(Y b
i
0
X (Y b
i
i
i
0
b1X i ) 0
b1Xi ) 0
Normal equation (2) :
(1)(2)(Y b
0
SSE
1
(X )(2)(Y b
i
i
0
b1X i ) 0
b1Xi ) 0
Then the solution is (derivation on board);
b 0 Ŷ b1X
b1
(X X)(Y Y )
(X X )
i
i
2
i
Properties of the residuals
o e 0. since the regression line goes through
the point (X, Y) .
o X e 0 and Ŷ e 0 The residuals are
uncorrelated with the independent variables
Xi and with the fitted values Ŷ . (prove it on
board)
i
i i
i i
i
Why e 0. , X e 0 and Ŷ e 0 ?
In fact, from normal equation (1) and (2), we
can immediately tell e 0 and X e 0 . Since
Ŷ e (b b X )e b e b X e , we can easily
know that Ŷ e 0 ?
i
i i
i i
i
i i
0
1
i
i i
i
0
i
i i
1
i i
o Least square estimates are uniquely defined
as long as the values of the independent
variable are not all identical. In that case the
numerator (X X) 0 (draw figure).
Point Estimation of Error Terms Variance 2
o Single Population: Unbiased sample
variance estimator of the population
variance
2
i
Yi i , i 1, , n
i , i , j 0
2
2
s2
2
Y
Y
i
E s2
n 1
2
o Regression model:Unbiased sample variance
estimator of the population variance
Yi 0 1X i i , i 1,, n
E i 0, 2 i 2 , i , j 0
SSE
n2
EMSE 2
MSE
Inference in Regression Analysis:
SS XY
b1
Estimator of 1
SS XX
Eb1 1
Mean of b1
2
2
Variance of b1
b1
SS XX
Estimated variance
MSE
s 2 b1
SS XX
t-Score and 1- CI of 1
t*
b1 1
~ t n 2
sb1
1 CI :
b1 t 1 2 ; n 2sb1
s 2 b1
MSE
SS XX
Estimating the Mean Value at Xh:
EY X
Estimator
Yˆ b b X
Mean
E Yˆ EY
Variance
1 X X
Yˆ
SS
Estimated variance
n
1 X X
s Yˆ MSE
h
0
h
0
1
1
h
h
h
h
2
2
2
h
h
XX
2
2
h
h
n
SS XX
Analysis of Variance Approach to Regression
Analysis
SSTOT SSR SSE
Yi Y Ŷi Y Yi Ŷi
Y Y Ŷ Y Y Ŷ
Ŷ Y Y Ŷ
2
2
i
i
i
2
i
2
i
i
Basic Table
Source of
Variation
SS
Regression
SSR Yi Y
Error
SSE Yi Yi
Total
SSTOT Yi Y
2
2
2
df
MS
E{MS}
1
MSR
SSR 2 2 X X 2
1
i
1
n-2
MSE
SSE
n2
2
n-1
o Test Statistic
o F Distribution
o Numerator
Degrees of Freedom dfR=1
o Denominator
MSR
MSE
MSR
F*
~ F 1, n 2
MSE
Tail Probability :
F*
*
Degrees of Freedom dfR=n-1 P F F 1 ;1, n 2
H 0 : 1 0
o Hypothesis:
H 1 : 1 0
For level of significance
o Decision Rule:
If F * F 1 ;1, n 2 H 0
If F * F 1 ;1, n 2 H1
Fitting a regression in SAS
data Toluca;
infile 'C:\stat231B06\ch01ta01.txt';
input lotsize workhrs;
proc reg;
/*least square estimation of regression
coefficient*/
model workhrs=lotsize;
output out=results p=yhat r=residual;/*yhat denotes for fitted values
and residual denotes for residual values*/
run;
proc print data=results;
var yhat residual; /*print the fitted values and residual vales*/
run;
SAS Output
The REG Procedure
Model: MODEL1
Dependent Variable: workhrs
Number of Observations Read
Number of Observations Used
25
25
Analysis of Variance
Source
DF
Sum of
Squares
Mean
Square
Model
Error
Corrected Total
1
23
24
252378
54825
307203
252378
2383.71562
Root MSE
Dependent Mean
Coeff Var
48.82331
312.28000
15.63447
Variable
Intercept
lotsize
DF
1
1
R-Square
Adj R-Sq
Parameter Estimates
Parameter
Standard
Estimate
Error
62.36586
26.17743
3.57020
Obs
1
2
0.34697
yhat
residual
347.982
169.472
51.018
-48.472
F Value
Pr > F
105.88
<.0001
0.8215
0.8138
t Value
2.38
Pr > |t|
0.0259
10.29
<.0001
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
240.876
383.684
312.280
276.578
490.790
347.982
419.386
240.876
205.174
312.280
383.684
133.770
455.088
419.386
169.472
240.876
383.684
455.088
169.472
383.684
205.174
347.982
312.280
-19.876
-7.684
48.720
-52.578
55.210
4.018
-66.386
-83.876
-45.174
-60.280
5.316
-20.770
-20.088
0.614
42.528
27.124
-6.684
-34.088
103.528
84.316
38.826
-5.982
10.720
Extension to multiple regression model
Extension to multiple regression model:
Extension to multiple regression model
Extension to multiple regression model
Extension to multiple regression model
Degrees of freedom: the number of independent components that are needed to calculate the
respective sum of squares.
(1) SSTOT is the sum of n squared components. However, since ( yi y) 0 , only n1 components are needed for its calculation. The remaining one can always be
n 1
calculated from y n y ( yi y) . Hence, SSTOT has n-1 degrees of freedom.
i 1
(2) SSE= ei2 is the sum of n squared components. However, there are p restrictions
among the residuals, coming from the p normal equations
XY XX b X' (Y Xb ) X' e 0 . Hence SSE has n-p degrees of freedom.
p1
p p p1
(3) SSR= ( ŷi y)2 is the sum of p squared components since all fitted values Ŷi are
calculated from the same estimated regression line. One degree of freedom is lost
because of one restriction
(ŷi y) (ŷi yi yi y) (ŷi yi ) (yi y) 0 . Hence SSR has p-1
degrees of freedom.
Extension to multiple regression model
Extension to multiple regression model