A számítási modell definíciója
A számításra vonatkozó alapelvek absztrakciója
A számítási modell jellemzői
Min hajtjuk végre a számítást?
Hogyan képezzük le a számítási feladatot?
Mi vezérli a végrehajtás sorrendjét?
Fejlesztői kronológia
Számítási modell
Ennek megfelelő programnyelv
Ennek megfelelő architektúra
Neumann elvű modell esetén a számítási feladat mit enged meg
Változók deklarálása
Adatmanipulációs utasítások deklarálása
Vezérlésátadó utasítások deklarálása
A Neumann modell igényeinek kielégítése az architechtúra részéről
A változókat a memória meghatározott helyén tárolja úgy, hogy biztosítja a változók értékének korlátlan számú változtathatóságát
Az architektúra rendelkezik egy speciális regiszterrel (programszámláló), ami tárolja a következő utasítás címét.
Modellek csoportosítása a műveletek elvégzésének rendje szerint
szekvenciális vagy párhuzamos
Modellek csoportosítása a végrehajtás meghajtása szerint
vezérlés szerint meghajtott, adat szerint meghajtott, igény szerint meghajtott
Modellek csoportosítása a probléma szerint
procedurális vagy deklaratív
Adat alapú számítási modellek
Neumann modell
Adatfolyam modell
Applikatív modell
Modellek csoportosítása aszerint, hogy min hajtjuk végre a számítást
Adat alapú, objektum alapú, predikátum logika, tudás alapú, hibrid
Az adat alapú modellek tulajdonságai
Az adatokat tipikusan változó képviseli. Az adatok típussal rendelkeznek/típust rendelünk hozzá
Az elemi adattípusok tulajdonságai
-értelmezési tartomány
-érték készlet
-műveletek halmaza-Például egy 16 bites előjeles int esetén:
Értelmezési tartomány: -32768 → 32768 Érték készlet: egész számok halmazaMűveletek halmaza: +, −, ∗, /
Neumann modell tulajdonságai aszerint, hogy min végezzük el a számítást
A számítást adatokon hajtjuk végre
Az adatokat tipikusan változók jelentik
Az adat végtelen értékmódosítási lehetőséggel rendelkezik (többszörös értékadás)
Az adatok és utasítások közös memóriaterületen helyezkednek el
A számítási műveleteket az adatokon végrehajtott adatmanipulációs műveletek
sorozatának segítségével végezzük el
Hogyan képezzük le a számítási feladatokat a Neumann modellben?

Szekvenciálisan
Mi vezérli a végrehajtást a Neumann modellben?
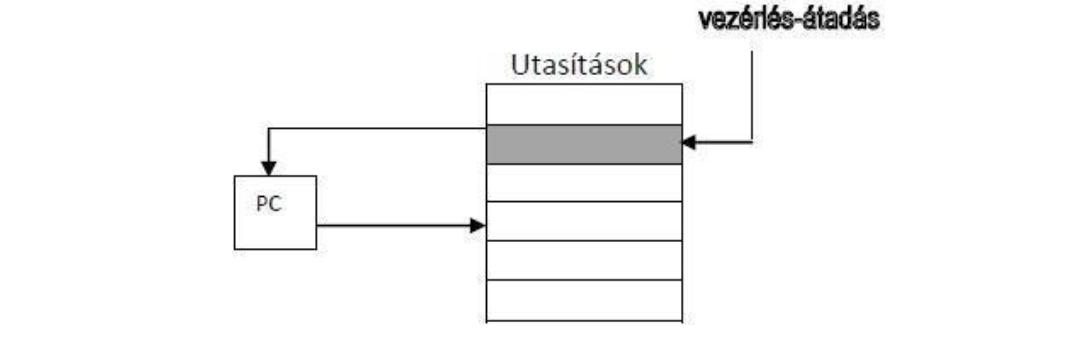
Az adatmanipuláló utasítások szekvenciája vezérli. (Vezérlés meghajtott modell)
Vezérlés meghajtott modell:
az adatmanipulálások szekvenciája (implicit: természetes sorrend; add, mul, sub...)
az explicit vezérlésátadó utasítások (pl. goto, if, for...)
A Neumann modell következményei
Előzmény érzékeny (változó értéke menet közben változik)
Alapvetően szekvenciális végrehajtás
Mellékhatások (rossz címzés, 0-val való osztás)
Egyszerű implementáció
Az adatfolyam modell rövid leírása
A számítást itt is adatokon hajtjuk végre, de csak egyszeres értékadás van, és a bemeneti adatokat egy adathalmaz formájában adjuk meg (nincsenek változók). A számítási feladatot egy adatfolyam gráffal képezzük le, amelyhez felhasználjuk az input adatok halmazát.→ input adatok halmaza + adatfolyam gráf = megoldott feladat. A gráf tartalmaz csomópontokat (szakosodott műveletvégző egységek) és éleket (I/O adatok).
Min végzünk számítást az adatolyam modellel?
Adatokon
Az adatolyam modellben az értékadások száma
Egyszeri értékadás
Neumann modell adat és utasítások tárolásának helye
Közös operatív tár
Adatfolyam modell adat és utasítások tárolásának helye
Regiszter
A Neumann modell mi alapján hajtja végre a számítást
Adatmanipulációs utasítás vezérelt
Az adatfolyam modell mi alapján hajtja végre a számítást
Adatfolyam gráf
Neumann utasítások végrehajtásának sorrendje
Szekvenciális
Adatfolyam utasítások végrehajtásának sorrendje
Párhuzamos (sok műveletvégző egység, azonnali műveletvégzés)
A probléma megfogalmazása a Neumann modellben
Procedurális jellegű
A probléma megfogalmazása az adatfolyam modellben
Procedurális jellegű
Előzmény érzékenység a Neumann modellben
Előzmény érzékeny
Előzmény érzékenység az adatfolyam modellben
Nincs előzmény érzékenység
Az adatfolyam modell igénye (hátránya)
Igen magas kommunikációs és szinkronizációs igény
Az applikatív modell min végez számítást
Adatokon
Probléma megfogalmazás az applikatív modellben
Deklaratív (előre meghatározott kapcsolatok a bemenetek között)
Hogy adjuk meg a számítási feladatot az applikatív modellnek
Egy komplex matematikai függvény formájában adjuk meg
Végrehajtás vezérlése az applikatív modellben
igény meghajtottAkkor hajtódik végre, ha kell egy folyamathoz egy másik folyamat eredménye. (Lusta modell)
Architektúra fogalma
Az az ismerethalmaz, amivel a gépi kódú programozóknak rendelkezniük kell, hogy hatékony programot tudjanak írni
Architechtúra szintjei
1. Globális P.M.S. (Processzor, Memória, Switch)
2. Programozási szint (magas, alacsony)3. Logikai/tervezési szint4. Áramköri szint
Architechtúra rétegei
Absztrakciós szint (layer) (L): Külső jellemzők, belső felépítés, és a működés együttes leírása
Számítási modell (M)
Specifikáció (S)
Implementáció (I)
Logikai architektúra tulajdonságai
adott absztrakciós szinten a fizikai architektúra elvonatkoztatása
logikai architektúra az adott absztrakciós szinten = {M, S}L
adott absztrakciós szinten a fekete doboz külseje
Processzor szintű logikai architektúra (Instruction Set Architecture) részei:
adattér
adatmanipulációs fa
állapottér
állapot műveletek
Fizikai architektúra
adott absztrakciós szinten a logikai architektúra megvalósítása
fizikai architektúra az adott absztrakciós szinten = {M, I}L
(nem vagyunk kíváncsiak a specifikációra)
adott absztrakciós szinten a fekete doboz belseje
A processzor-szintű fizikai architektúra (Micro Architecture) részei:
műveletvégző egység (ALU)
vezérlő
I/O rendszer
Megszakítási rendszer
A rendszerszintű fizikai architektúra:
• Memória
• Busz- / Sínrendszer
Adattér fogalma
Olyan tér, ami biztosítja az adattárolást olyan formában, hogy az adattérben található adatok a CPU által közvetlenül manipulálhatók legyenek (címezhető)
Az adattér két részre bontható:
memóriatér, regisztertér
Kétféle címtér:
modell címtere: címbusz szélessége határozza meg a kapacitást pld. 32 bitesnél 4 GB
az adott implementáció címtere: amennyi ténylegesen, fizikailag van
Két külön memória memóriatér létezik
fizikai (CPU által látható, kisebb így gyorsabb + alaplapi lapkán helyezkedik el)
virtuális (programozó által látható, nagyobb + a háttértáron helyezkedik el)
Regisztertér fogalma
Az adattér egy nagyteljesítményű része
Regisztertér osztályozása
Egyszerű regisztertér
Különféle adattípusokhoz különálló regiszterek
Többszörös regiszterkészlet
Egyszerű regiszter négy típusa:
-AC (akkumulátor) regiszter
-AC + Data regiszterek
-Univerzális regiszter készlet
-Stack Architektúra (regiszter)
Különféle adatokhoz különböző regiszterek
Fixpontos és logikai műveletekhez -> univerzális regiszterkészlet
Lebegőpontos (FP) műveletekhez
-SIMD (Single Instruction, Multiple Data stream)
-SSE (Single Stream Extension)
Intel Pentium III (1998)
- 8db FX (32 bit)-
- 8 db FP (80 bit)
- 8 db SSE (128 bit)
A kontextus fogalma
a program végrehajtás során a regiszterek állapotát az állapot információkkal (PC (ez a program counter), flag) együtt kontextusnak nevezzük
A többszörös regiszterkészletek célja
Ciklusok, megszakítások, egymásba ágyazott folyamatok gyorsítása
Mi történik egy megszakításkor
Le kell mentenünk az éppen futó program kontextusát, hogy később onnan lehessen folytatni
Több egymástól független regiszterkészlet előnyei
egyszerű
gyors, olcsó
független folyamatok esetén kiváló (pl.: Megszakítások)
Több egymástól független regiszterkészlet hátránya
paraméter átadásos eljárásnál nem gyorsít, mivel a paraméterátadás a memórián keresztül történik
Több egymástól független regiszterkészlet elve
Az eljárások már nem ugyanazon regiszterkészletet használják, viszont a regiszterkészletek közti kommunikáció még nem volt megoldott, ahhoz a háttértárat kellett használni -> ilyenek pl az egymásba ágyazott eljárások, amik használják a másik készletében lévő adatokat
Az átfedő regiszterkészlet elve
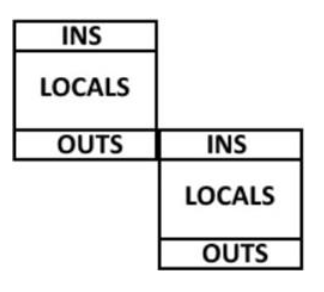
Három részre bontották a regisztereket, ezek az INS, LOCALS, OUTS
Az INS és OUTS részek a különböző regiszterekkészletek között átfedésben vannak, így az adatátvitel megoldott
Az átfedő regiszterkészlet hátrányai
- Merev, hiszen fix a regiszterek száma
- A regiszterkészletek száma is fix
A regiszterkészletek száma és a túlcsordulás előfordulása közötti összefüggés
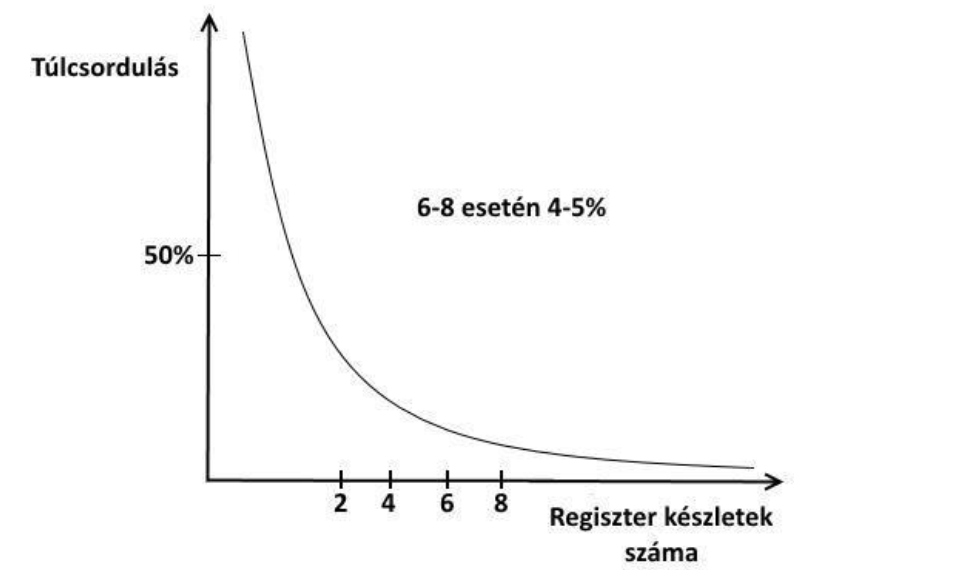
6-8 regiszterkészlet esetén már csak 4-5%-ban fordul elő túlcsordulás
Nem is javasolt 8 egymásba ágyazott folyamatnál többet írni, hiszen a lassú működés mellett átláthatatlan is lesz a program
A Stack-Cache elve
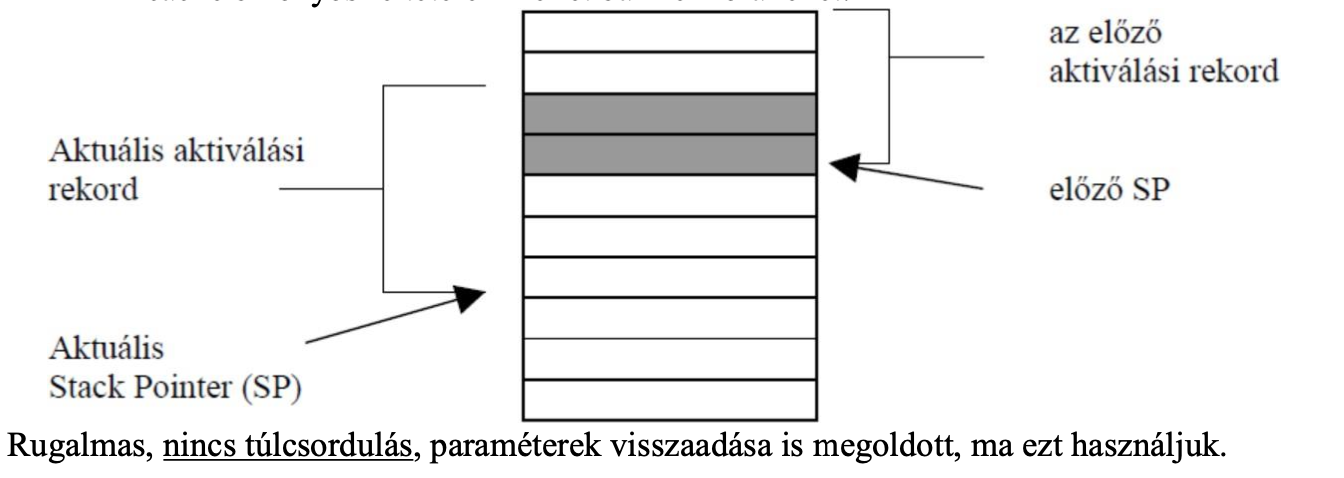
A Compiler kezeli a regisztereket és nem a programozó
Minden eljáráshoz saját regiszterkészletet hoz létre, ami akkora, amekkorát a program igényel, tehát nem fix számú regiszterrel dolgozik
Ezeket a tartományokat hívjuk aktiválási rekordoknak
A rekordra stack pointer mutat, de az egyes memóriacímek közvetlenül is elérhetőek, így bármelyik adatot lehet használni
Vannak átfedő területek a tartományok között, pont annyi van, amennyi paramétert át kell adnia az egyik folyamat részéről a másiknak
Az adatmanipulációs fa lényege
Megmutatja a potenciális adatmanipulációs lehetőségeket, formákat, valamint egy konkrét implementáció adatmanipulációs lehetőségeit
Az adatmanipulációs fa szintjei
Adattípusok: FX1(byte), FX2, FX4, BCD, FP4, FP8,
boolean (FX = fix pontos, FP = lebegő pontos, BCD = binárisan ábrázolt decimális)
Műveletek: például fix számoknál: +, -, *, /
Operandusok típusai: rrr, rmr, ..., mmm (r = regiszter, m = memória) pl: rrr -> mindhárom regiszter
Címzési módok: memória típusú operandusoknál R+D, PC+D, RI+D (D = displacement, R = register, PC = program counter, RI index register)
Gépi kódok (utasítások): Pl.: 10011110
Az adattípusok fajtái
Elemi, összetett
Az elemi adattípusok fajtái
numerikus, karakteres, logikai, pixel stb
A numerikus adattípus fajtái
fixpontos, lebegőpontos, BCD
Az összetett adattípusok jellemzői
Elemi adattípusokból épülnek fel -> adatszerkezetnek is hívjuk
Különböző adattípusokból épül fel -> rekordnak hívjuk
Azonos adattípusokból felépülő összetett adattípusok fajtái
Tömb -> ha 1D, akkor vektor
szöveg
verem
sor
lista
fa
halmaz
A fixpontos adattípus fajtái
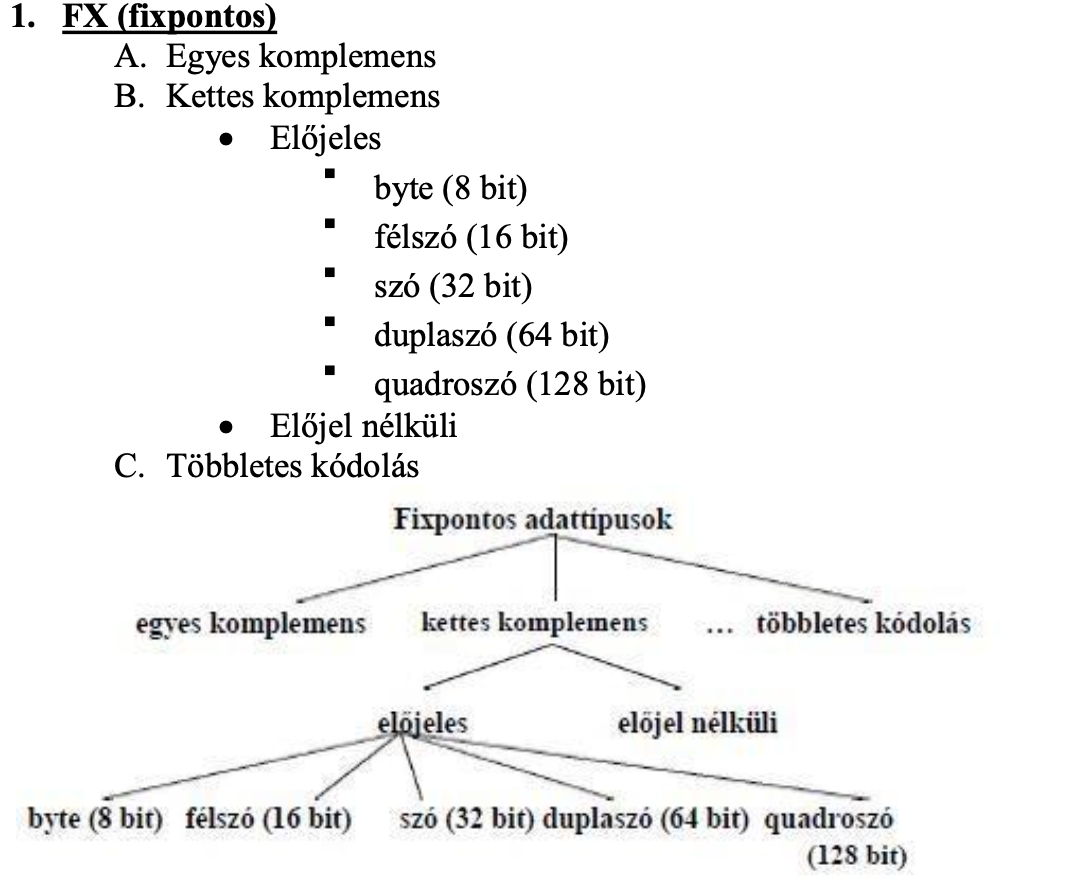
A lebegőpontos adattípus fajtái
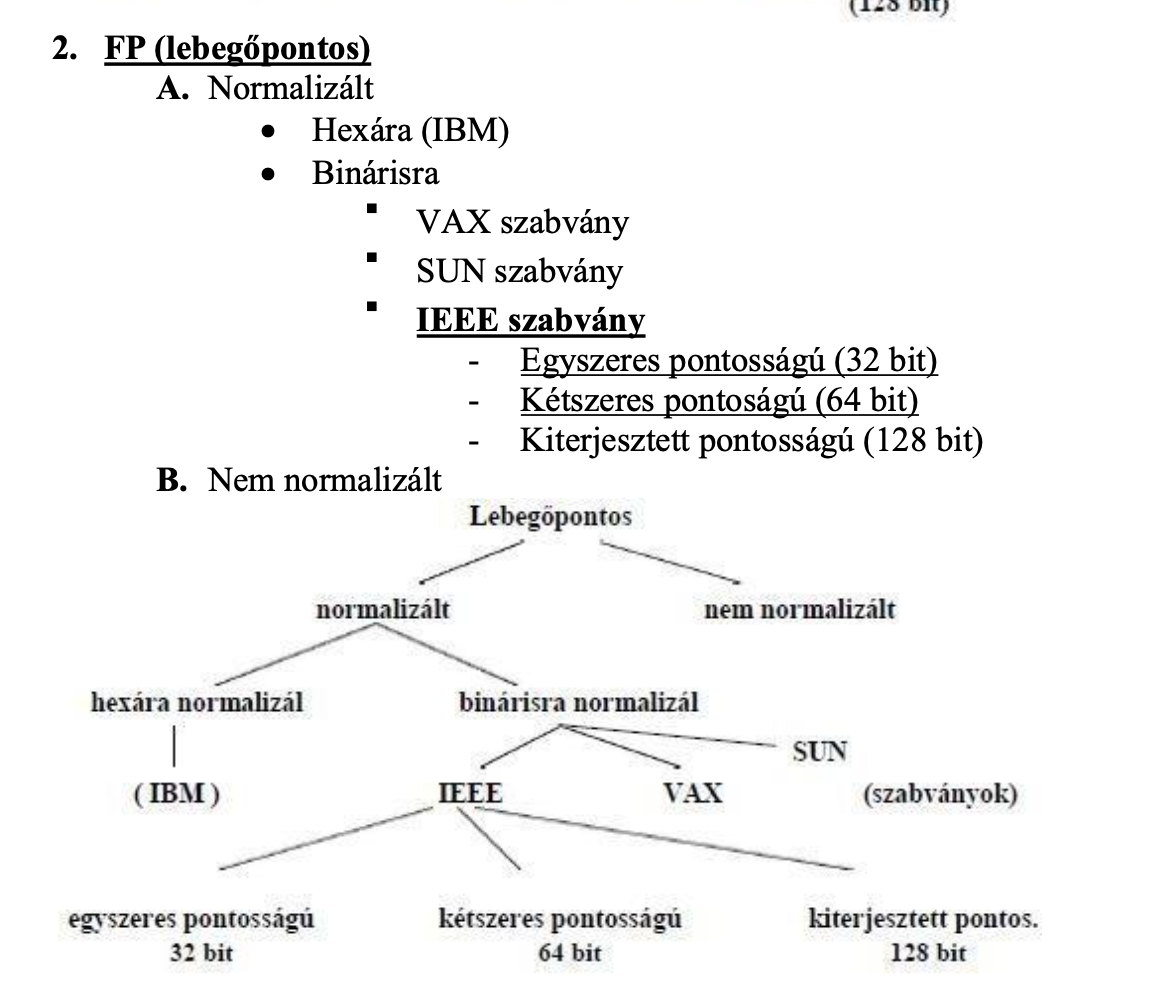
A BCD adattípus fajtái
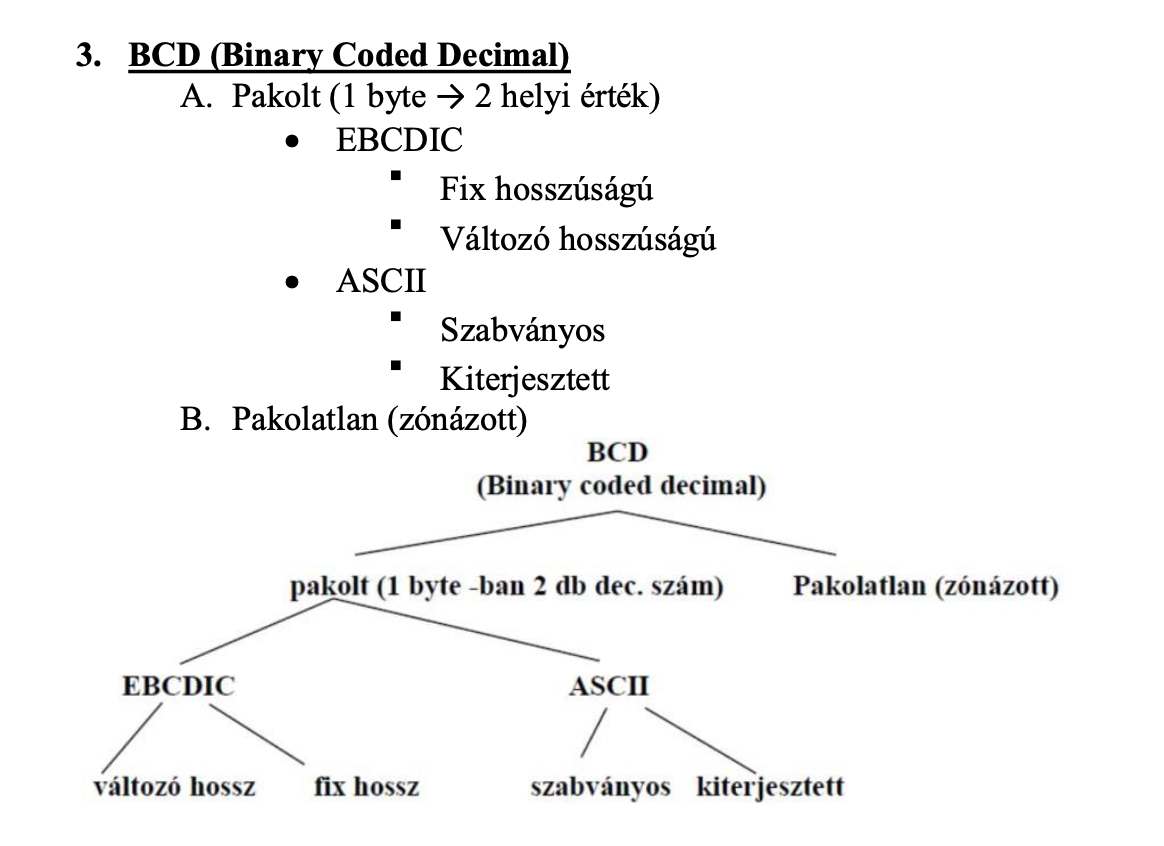
A karakteres adattípus fajtái

A logikai adattípus fajtái

Az adatmanipulációs fa műveleteinek fogalma
Az adatmanipulációs fa minden művelet esetén megállapítja, hogy milyen utasítás típusok, és operandus típusok választhatók.
Az értelmezett műveletek halmaza mindig architektúra függő. Pontosan deklarálni kell nem csak a műveleteket, hanem a kivételek kezelésére szolgáló műveleteket is.
A gépi kódú utasítás részei
MK (műveleti kód), Címrész
Az MK határozza meg, hogy milyen műveletet végzünk el, a címrész pedig azt, hogy min végezzük el (hány darab adaton, hol vannak ezek)
Az utasítás-feldolgozás általános folyamata
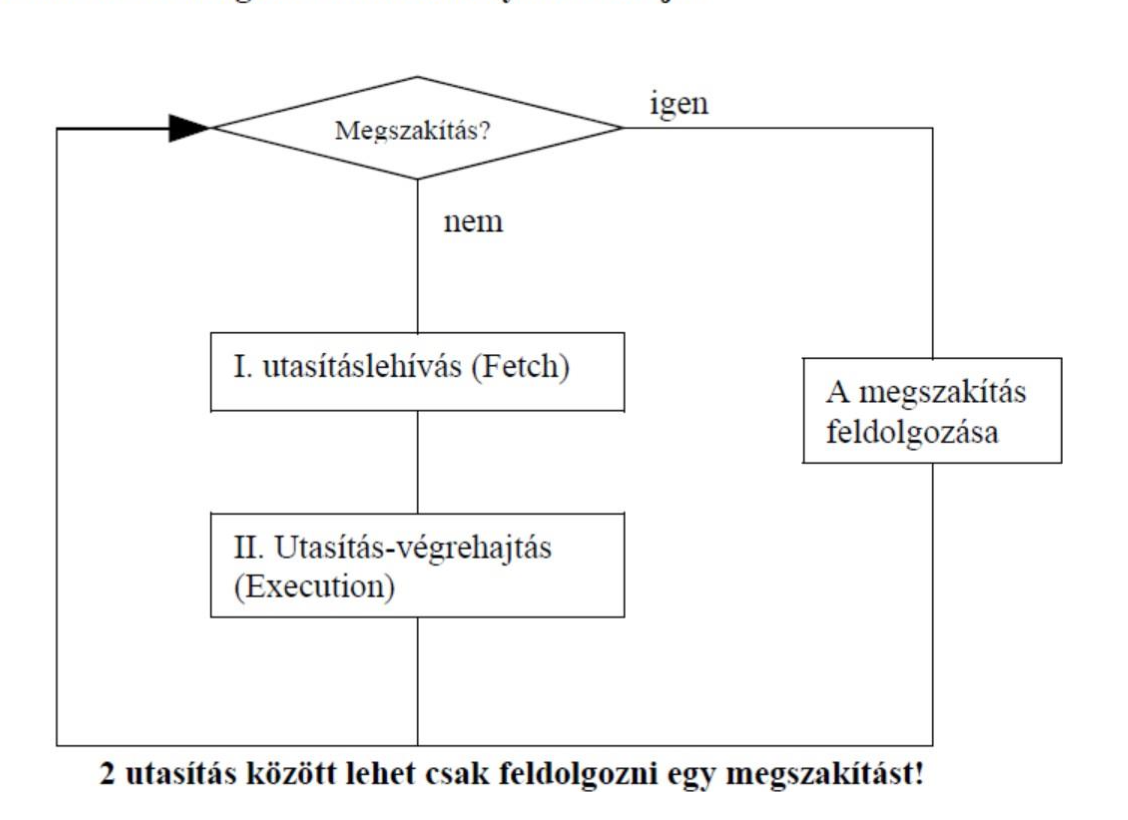
A CPU belső egységei
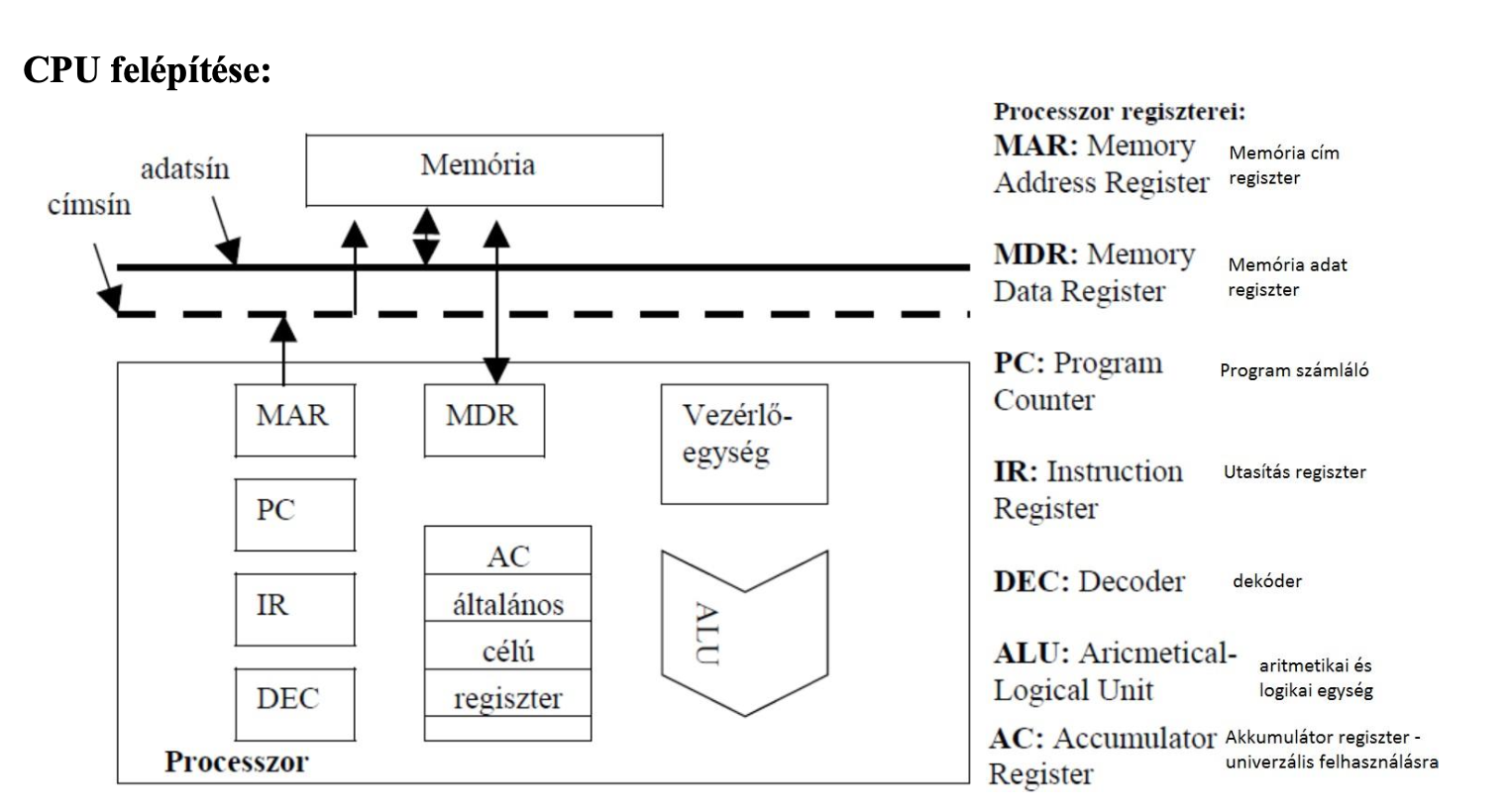
MAR - Memory Address Register
MDR - Memory Data Register
PC - Program Counter
IR - Instruction Register
DEC - Decoder
ALU - Aricmetical-Logical Unit
AC - Accumulator Register
Utasítás lehívás (fetch) folyamata
Minden utasítás esetén ugyan úgy néz ki. A PC a következő végrehajtandó utasítás címét tartalmazza. A program counter-ből átkerül a következő utasítás címe a memória cím regiszterbe. A memória cím regiszterben található memóriacím adat tartalma bekerül a memória adat regiszterbe. Innen az utasítás átkerül az utasítás regiszterbe. Program counter tartalmát megnövelni egy egységgel.
MAR <- PC
MDR <- [MAR]
IR <- MDR
PC <- PC + 1
(A cél, hogy a IR-be belekerüljön az utasítás)
A Load utasítás folyamata
Lehívjuk az utasítást. Az utasítás regiszterből átkerül az utasítás a dekóderbe. A dekóder címrésze átkerül a memória címregiszterbe. Betöltődik az adat a memória adat regiszterbe. A memória adat regiszter tartalma átkerül az akkumulátorba.
DEC <- IR
MAR <- DECcímrész
MDR <- [MAR]
AC <- MDR
(A cél, hogy az AC-ba bekerüljön az adat, hogy utána fel lehessen dolgozni)
Aritmetikai / logikai utasítás folyamata
(A példában egy ADD művelet szerepel→MK határozza meg a műveletet)
DEC <- IRMAR <- DECcímrész
MDR <- [MAR]
AC <- AC + MDR
Store utasítás folyamata
DEC <- IR
MAR <- DECcímrész
MDR <- AC
[MAR] <- MDR
Megszakítás (feltétlen vezérlésátadás) folyamata
DEC <-IR
PC <- DECcímrész
A 4 címes utasítás típus jellemzői
Legyen op – operandus, s – source, d - destination, @ - tetszőleges művelet
opd = opS1 @ opS2, op4 = következő utasítás címe
Hátrányok:
-memóriapazarlás
-további adatrögzítési hibák
-merev program-struktúra→helyette PC használata (+ auto increment)
A 3 címes utasítás típus jellemzői
Legyen op – operandus, s – source, d - destination, @ - tetszőleges művelet
opd = ops1 @ ops2
PC tárolja a következő utasítás címét
Előnye: lehetséges a párhuzamos végrehajtás
Hátránya: hosszú utasítások, nagy mennyiségű adat, sok memóriát igényel, lassú, kevés/nincs elágazás
Ilyenek a RISC processzorok
rrrd minimum 32 regiszter
Az előző utasítás eredményének mentésével párhuzamosan tölthetjük az aktuális utasítás két bemenő operandusát.Olyan helyeken használják, ahol nagy mennyiségű adat van és nincs elágazás.
A 2 címes utasítás típus jellemzői
Legyen op – operandus, s – source, d - destination, @ - tetszőleges művelet
ops1 = ops1 @ ops2
Az első operandus általában csak regiszter lehet, a kettes operandus lehet memóriacím is.
Pl.: ADD [100][102], 100-as és 102-es címet adja össze, az eredmény a 100-as címre megy.→kevesebb tárhelyet igényel, de az egyiket felülírjuk.Mai CISC processzorok általában ezt használják (x86)
Az 1 címes utasítás típus jellemzői
Legyen op – operandus, s – source, d - destination, @ - tetszőleges művelet, AC - akkumulátor regiszter
AC = AC @ op
AC LOAD [100]
ADD [102]STORE [100]
Akkumulátorba betölti a 100-as címet, majd hozzáadja a 102-es címet. végül kiírjuk az akkumulátor tartalmát. Az utasítások halmozhatók. Az utasítások rövidebbek, de több utasításra van szükség.
A 0 címes utasítás típus jellemzői
STACK (push, pop) - verem műveletekNOP – no operationA műveleti kód tartalmazza az eredményt is. (CLEAR D’) Előny: rövid, Hátrány: utasításkezelő műveletek
Az operandusok típusai
Akkumulátor (AC), Memória típus (m), Regiszter (r), Verem (s), Immediate (i)
• Akkumulátor (AC)- Gyors, csak 1 db van
• Memória típus (m)- Nagy, hosszú a cím, lassú
• Regiszter (r)- Gyors, kevés van belőle
• Verem (s)- Gyors, egyszerre csak egy elem érhető el
• Immediate (i)- magában a programban adunk értéket a változónak
(pl. ADD R1, 3)
Architektúrák osztályozása (operandus típusok szerint
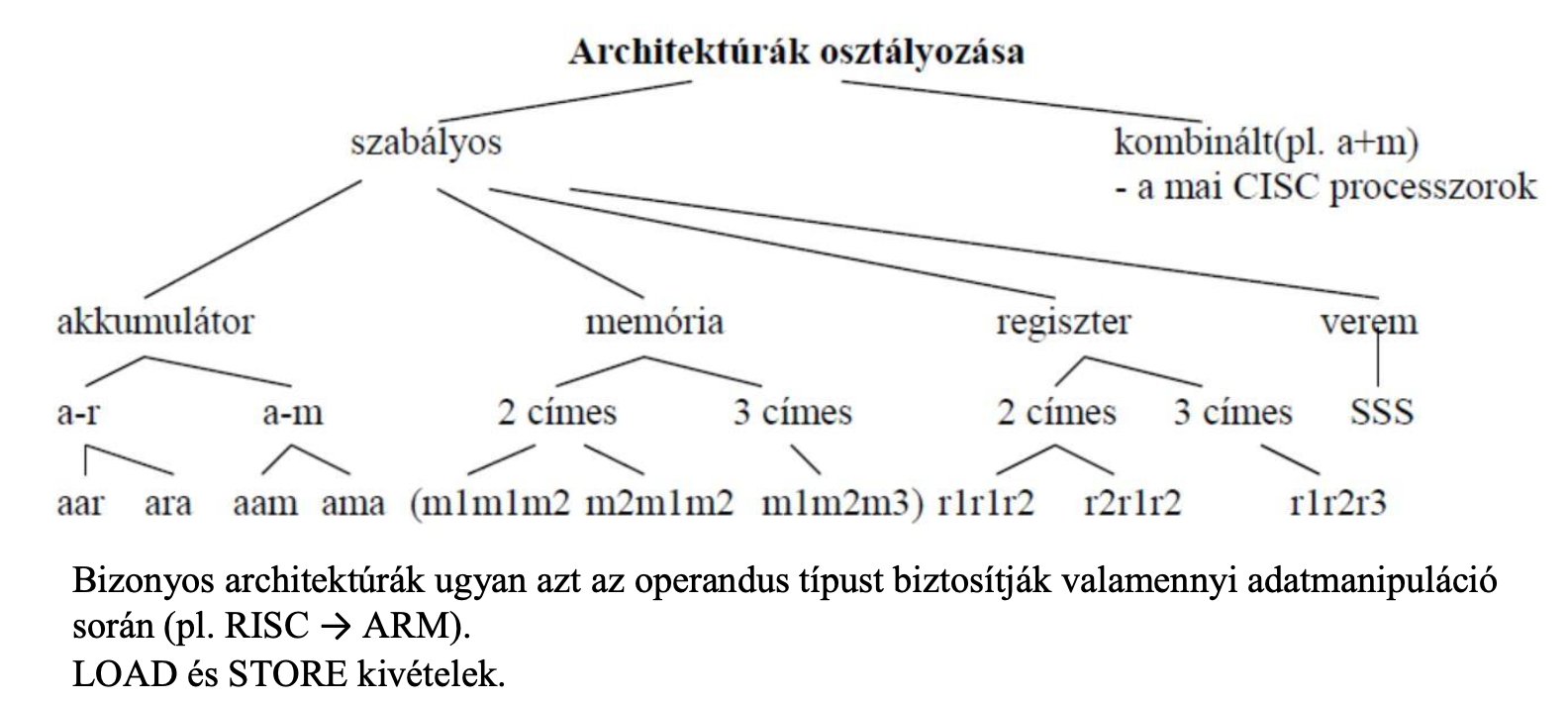
Szabályos
---
Akkumulátor
-akkumulátor-regiszter (aar vagy ara)
-akkumulátor-memória (aam vagy ama)
Memória
-2 címes (mm)
-3 címes (mmm)
Regiszter
-2 címes (rr)
-3 címes (rrr) (legjobb teljesítmény)
Stack
- sss (kontextus adatok tárolására)
Kombinált / kompozit: vegyesen helyezkednek el az operandusok
--
Címzési módok
Címszámítás, cím módosítás, tényleges (deklarált) cím interpretálása
A címszámítás jellemzői
Abszolút címzés
-hosszú címek (akár több terrabájtnyi cím is lehet), ezért nem használjuk
Relatív címzés
Y (cím) = S (bázis) + D (eltolás)
Deklarálni kell egy Bázis címet és a Címszámítási algoritmust
Bázis cím lehet: PC, Top of Stack, Index Regiszter stb.
Cím módosítás jellemzői
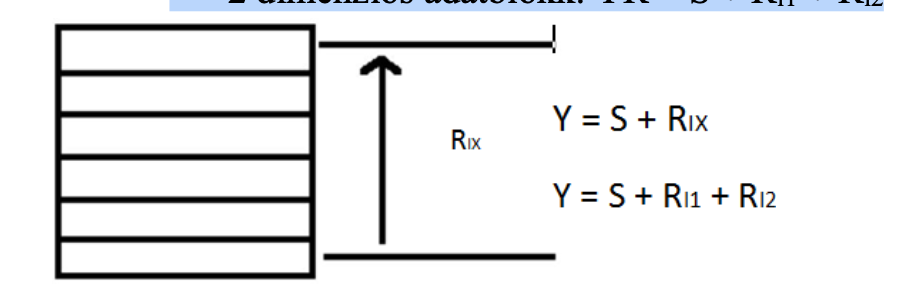
Auto inkrementálás • Indexelés
Legyen YR (relatív cím), S (bázis), Ri (indexregiszter értéke / eltolás)
- 1 dimenziós adatblokk: YR = S + Ri
- 2 dimenziós adatblokk: YR = S + Ri1 + Ri2
Tényleges (deklarált) cím interpretálásának jellemzői
Lehet direkt vagy indirekt
Felfoghatjuk valós vagy virtuális címként is
Utasítás kód jellemzője
Architechtúránként változik
Az állapottér fogalma
Olyan, programból látható, és programtranszparens tárolókból áll, amelyek az adott programra vonatkozó állapot információkat hordozzák
Olyan rendszerfunkciókhoz szükséges információk, mint pl.
Virtuális memória kezelés
Megszakítás kezelés
Az állapottér felépítése
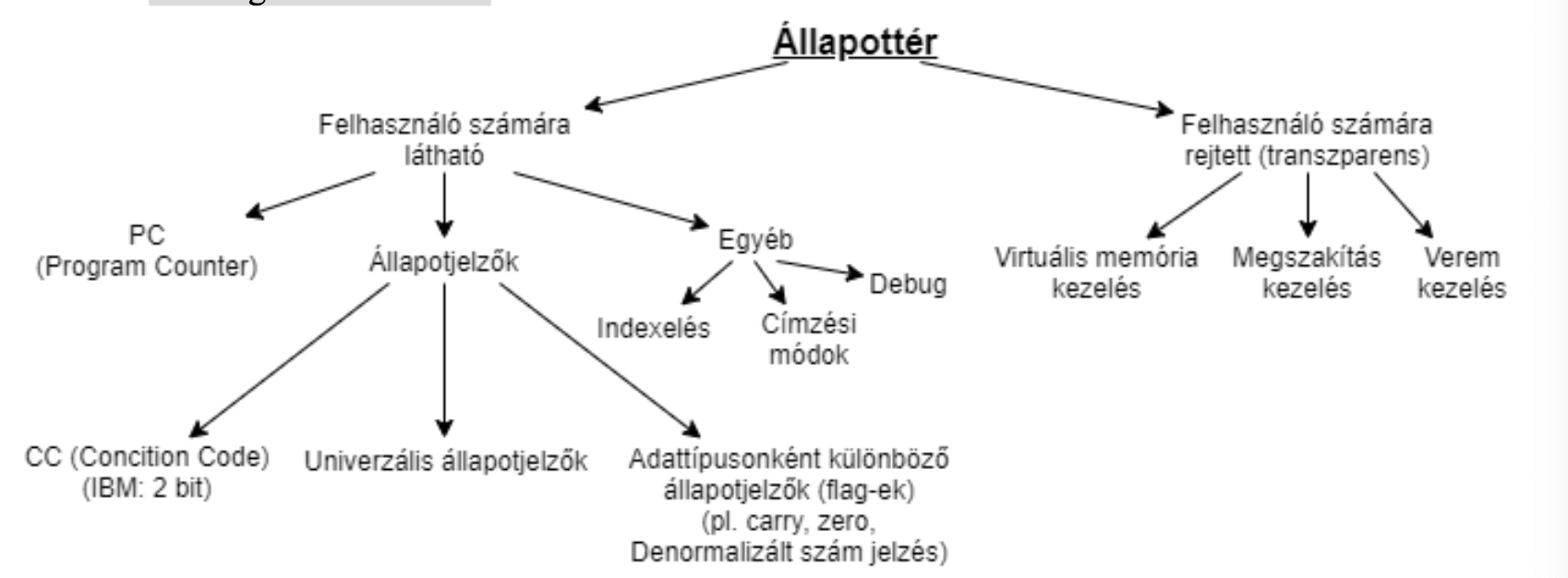
Állapot indikátorok
Olyan kivételes események kezelésére vannak, amelyek a végrehajtás során általánosan bekövetkeznek (pl.: FP-nél denormalizált szám jelzése).Minden regiszterkészlethez definiálva vannak flag-ek, pl.:
• ZERO• NEG• OVERFLOW • CARRYÁllapotműveletek
Állapotműveletek
Pl.
• Program Counter (PC) esetén: - Inkrementálás
- Dekrementálás- Felülírás (egy utasításból átvett címmel)
• Flag-ek esetén:
- Beállítás (set)→1
- Törlés (clear)→0
- Kezdeti értékre állítás (reset)
- Mentés (save)
- Visszatöltés (load)
A processzor szintű fizikai architektúra részei
Műveletvégző egység (ALU)
Vezérlő egység
I/O rendszer
Megszakítási rendszer
CPU: műveletvégző + vezérlő funckiói
Utasítás lehívás (fetch)
Utasítás végrehajtás (execute)
CPU típusok
Szinkron CPU:
- Órajel generátorral működik
- Hátránya: késleltetés, a következő órajelet mindig meg kell várni, így holtidő
keletkezhet
- Előnye: egyszerű, gyors
Aszinkron CPU:- Nincs órajel → Egyik utasítás vége jelzi a következő utasítás kezdetét
- Hátránya:
extra áramkör kell az utasítás befejezésének érzékeléséhez
drága
az utasítás befejezésének érzékelése is időbe telik
- Előnye: nincs holt idő
Az műveletvégző egység (ALU) részei
Regiszterek
Adatutak
Kapcsolópontok / csatolók
Szűk értelemben vett ALU
A regiszterek fizikai szintű típusai
-Látható (a programozó számára)
ezen belül lehet
-univerzális
-dedikált (pl: stack)
-Transzparens (rejtett): Adatfeldolgozáshoz szükséges pufferek
-hivatkozni nem lehet rájuk, de számításba kell venni őket
Az adatukat jellemzői
NEM adatbusz, mert nem értelmezett rajta semmilyen címzés (egyszerűbb csak vezetékekre gondolni)
Az ALU felépítésének rajza
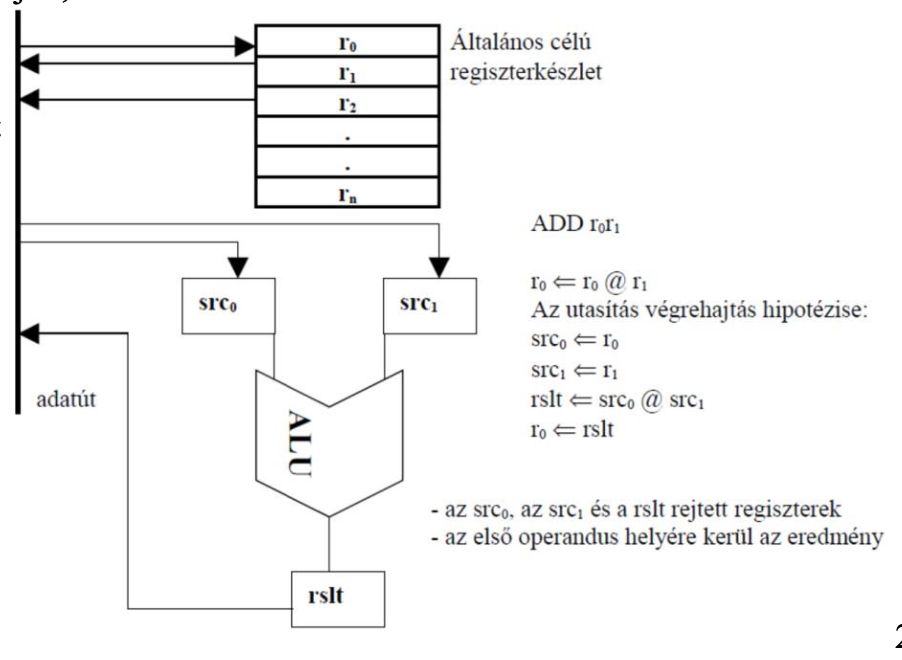
A csatolók típusai
-Egy utas -> betöltés egyenként sorban
-Két utas -> 2 adatutat használhat egyszerre
-Három utas -> 2 utas + 1 az eredmény visszaírására -> párhuzamosítási lehetőség
Kapcsolópontok (tranzisztorok)
A regiszterek részét képezik, általában tranzisztorok
Önálló vezérléssel rendelkeznek
- Kimenő (mármint a regiszterből) kapcsoló: 3 állapot -> 1, 0, zárt
- Bemenő (a regiszterbe) kapcsoló: 2 állapot -> zárt, nyílt
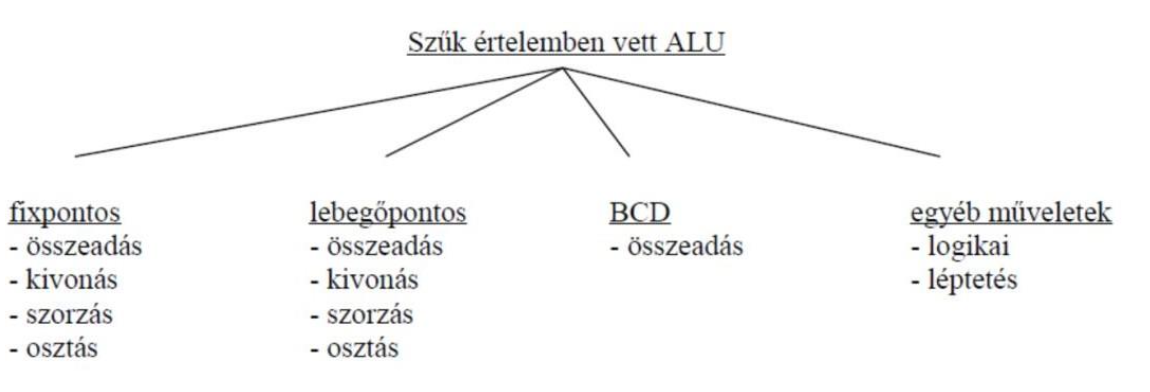
Szűk értelemben vett ALU műveletei
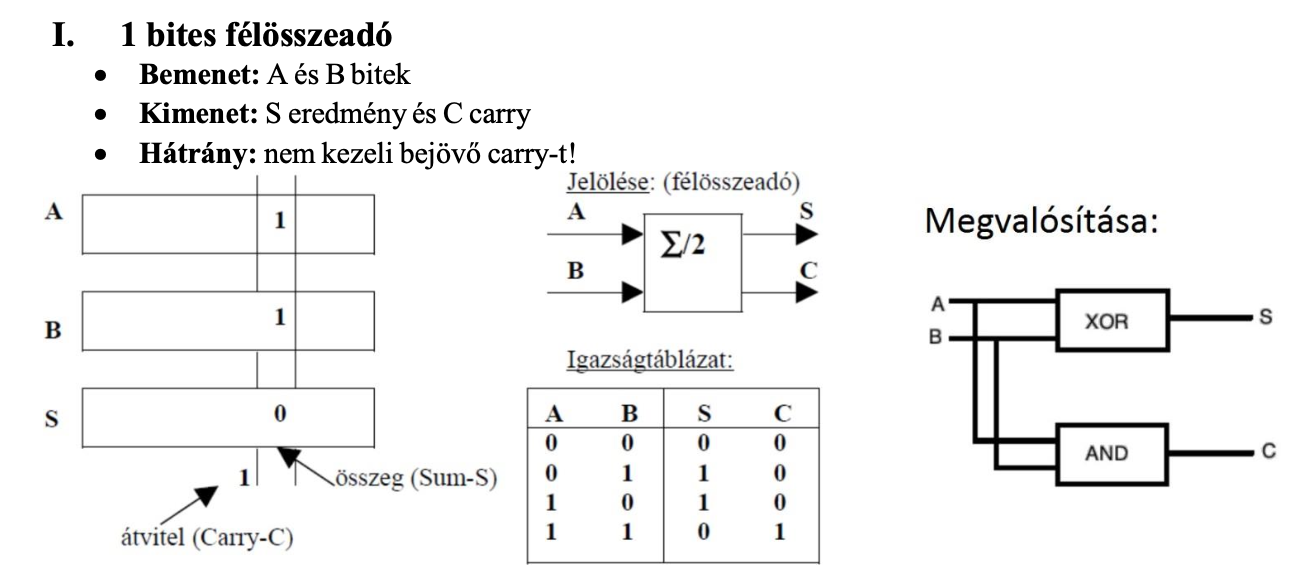
1 bites félösszeadó
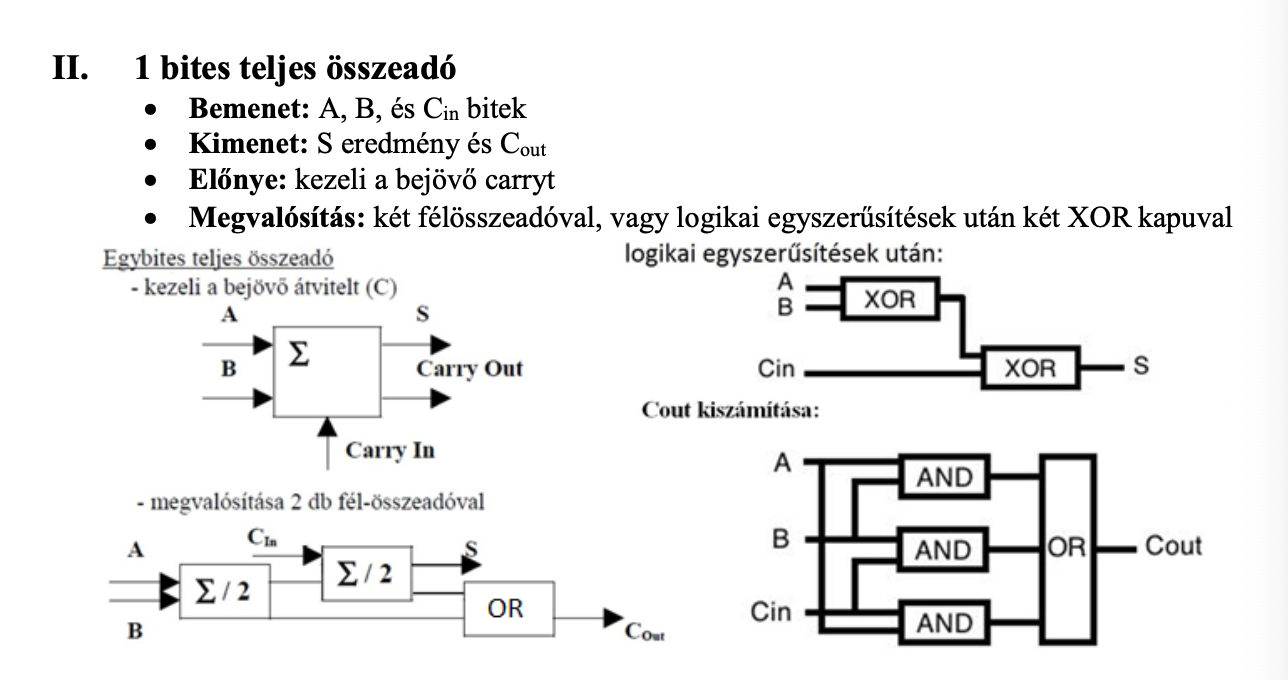
1 bites teljes összeadó
N bites soros összeadó
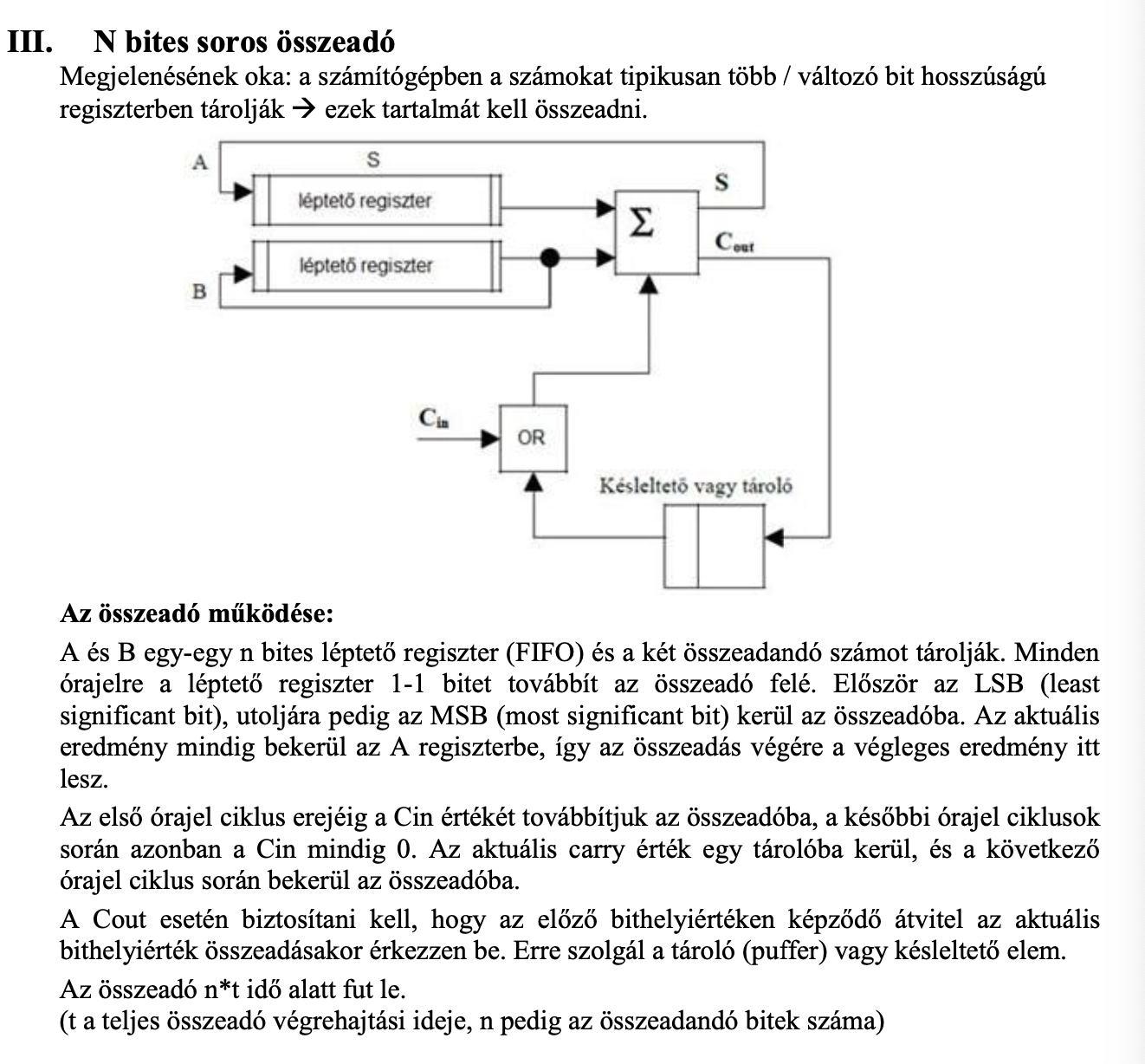
N bites párhuzamos összeadó
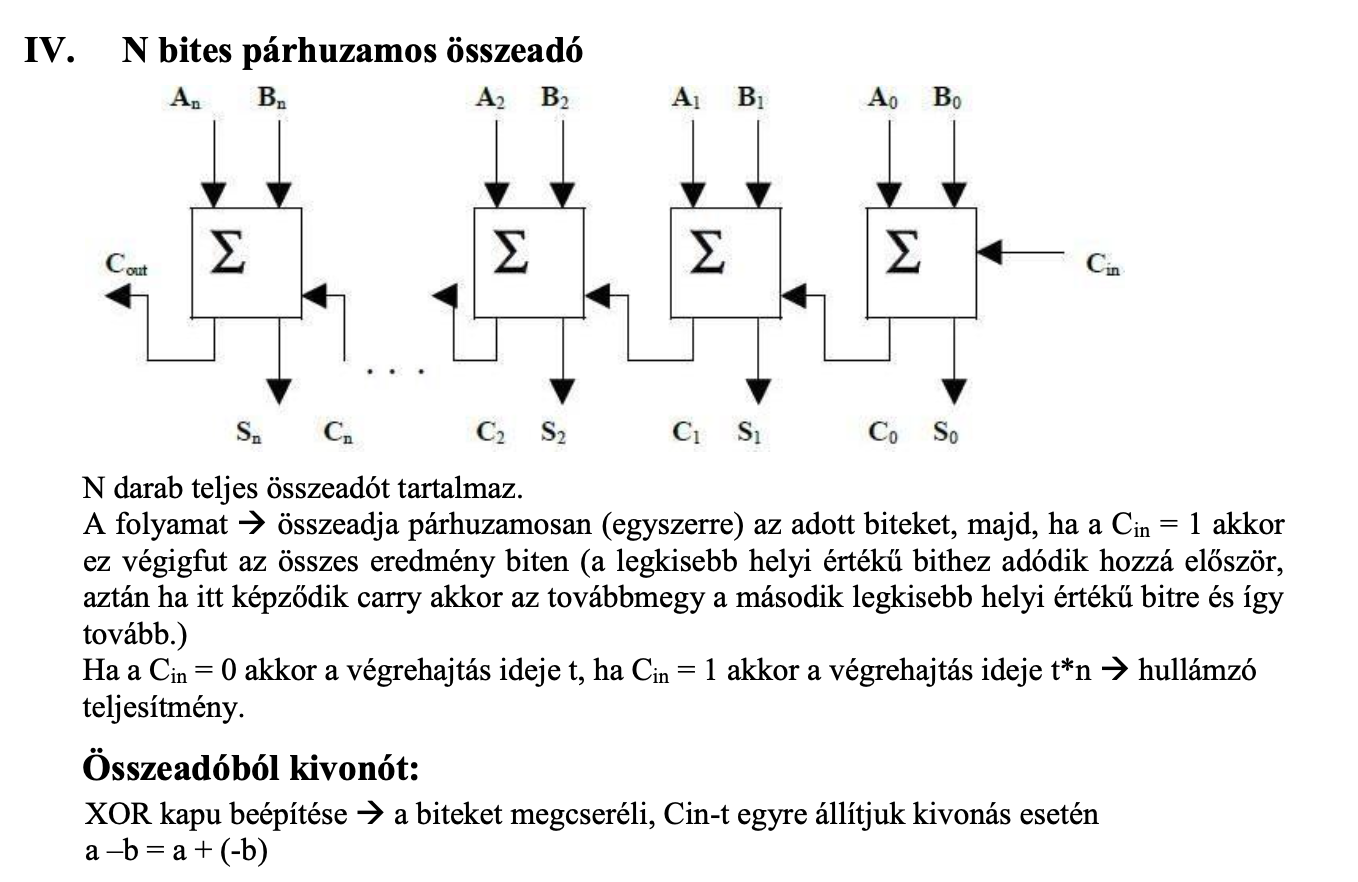
CLA alap ötlet levezetés
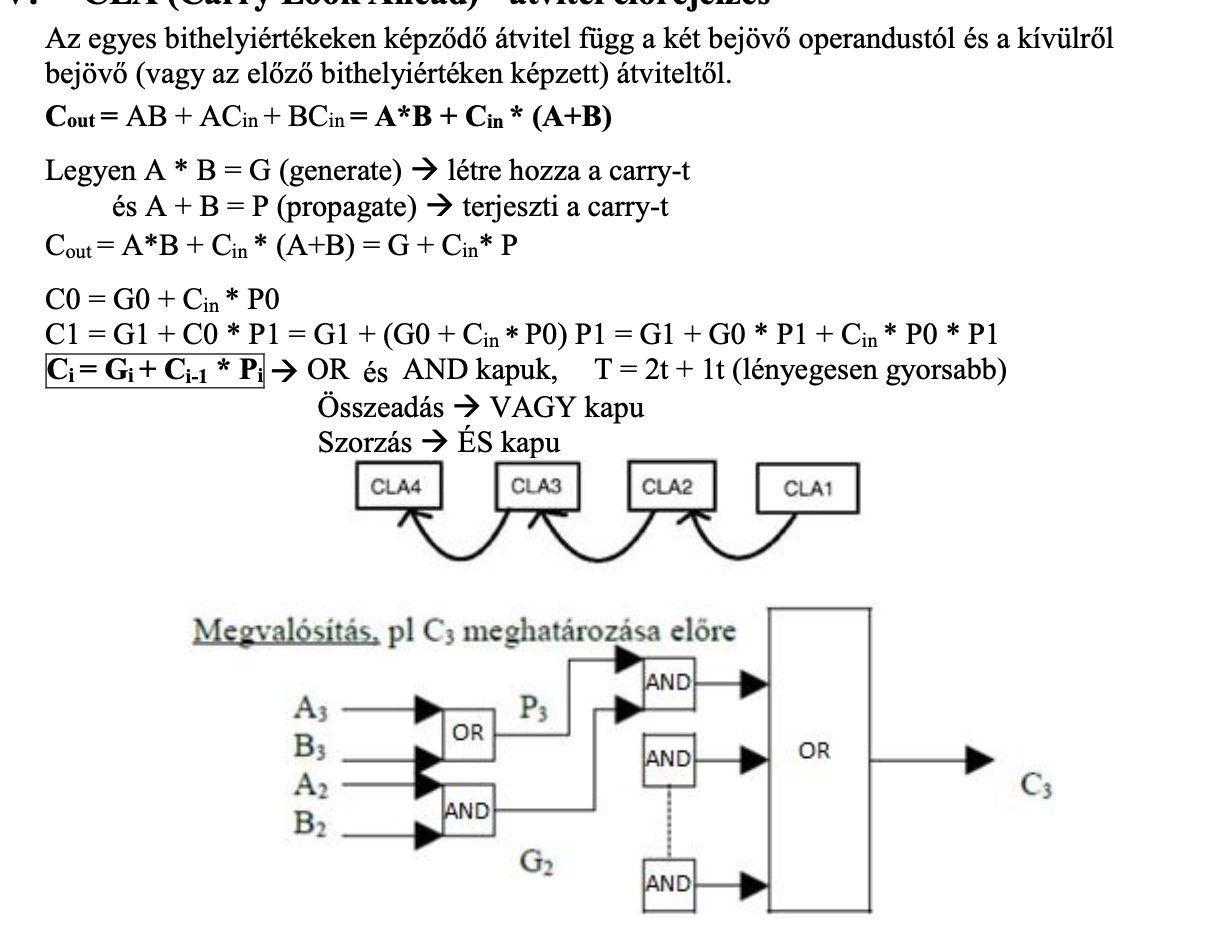
CLA implementálás
A szorzat hossza és a szorzó valamint szorzandó kapcsolata
Ha a szorzandó hossza "n", a szorzó hossza "m", akkor a szozat hossza <= n+m
Emiatt kell figyelni, hogy két szám szorzása esetén az eredménynek elég nagy regisztert tartsunk fent
A bitcsoporttal való szorzás gyakorlata

A végéről lemaradt, hogy az 11 esetet leginkább a Booth algoritmussal szokták elvégezni
Booth algoritmus

A fixpontos ábrázolás hátrányai
Viszonylag szűk értelmezési tartomány -> 16 bitnél -32768-tól +32767-ig
Tört számok pontatlan ábrázolása pl: 7/4=1
FP ábrázolás

Mantissza*radix^karakterisztika
A radix és a mantissza kódolása egyezzen meg
Ha a matissza bináris, akkor a radix is legyen az
FP normalizálás
A törtpontot az első értékes számjegy elé helyezzük
Pl: 123.456*10^0 -> nem normalizált
0.123456*10^3
FP értelmezési tartománya

A FP pontossága
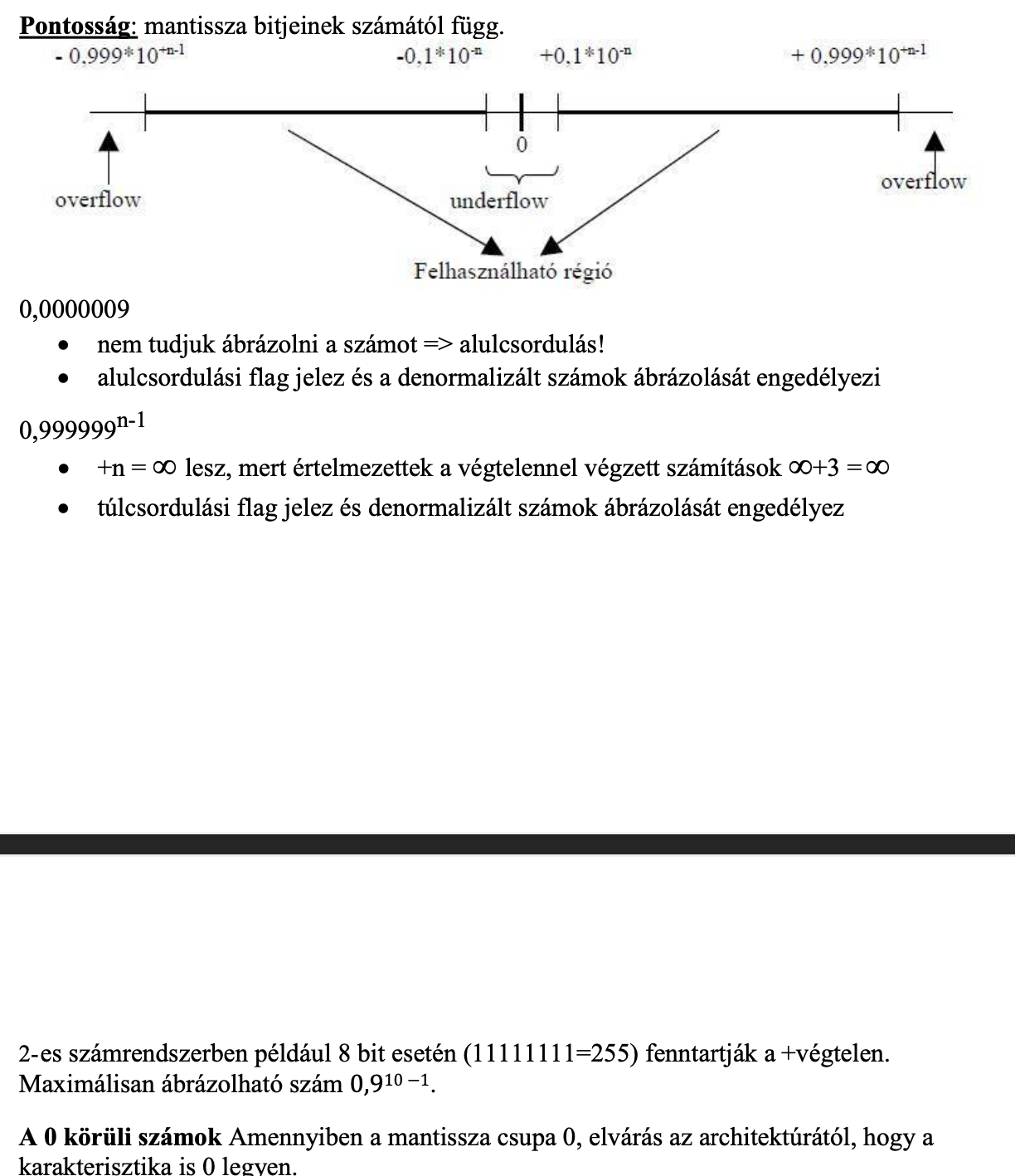
A rejtett bit fogalma
Pontosság javítás rejtett bit használatával (kettes számrendszerben vagyunk) 1⁄2 <= m <1Mivel a normalizálás után a törtpont után mindig 1 áll, ezért ezt felesleges tárolni
Az így felszabaduló bitet a pontosság növelésére tudjuk használni, ehhez balra léptetjük az értéket és beléptetjük a pontosításhoz használt új bitet
Az őrző bitek fogalma
A pontosságot őrzik. A lebegőpontos regiszternek mind a mantissza része, mind a lebegő pontos műveletvégző hossza 4-15 bittel hosszabb, mint a tárolt formátum (pl.: 32+11).
Felhasználása:
- rejtett bit kiíráskor egy értékes bitet tudunk beléptetni (helyreállítás).
- kerekítést segíti a több bit
- normalizálás 0,000
FP kódolása részenként
Mantissza: Kettes komplemens formában ábrázolunk ezért minden aritmetikai művelet elvégezhető vele
karakterisztika kódolása tipikusan többletes kód (csak + és - műveletek és léptetés)
𝑚𝑎∗𝑟𝑘𝑎
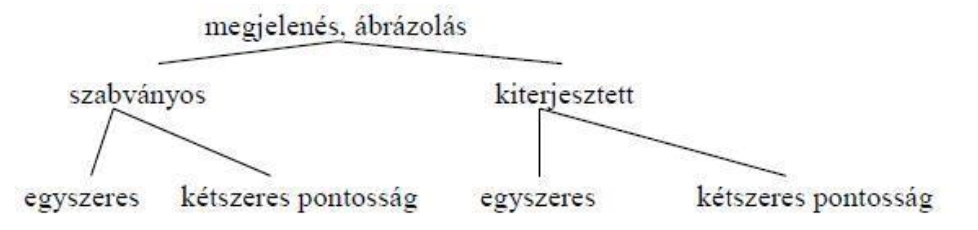
IEEE 754 szabvány részei
Adatformátumok
Adattípusok
Műveletek
Kerekítések
Kivételek kezelése
IEEE 754 Adatformátumok
Tárolási (szabványos)
- az operatív táron, illetve háttértáron való tárolásra szolgál
- Szigorúbb szabályok
- 32 vagy 64 bit
Bővített (kiterjesztett)
- csak processzoron belül
- maximális szabadság a gyártóknak a CPU-n belül
- min 43 vagy 79 bit
IEEE 754 szerinti megjelenés, ábrázolás
IEEE 754 Adattípusok
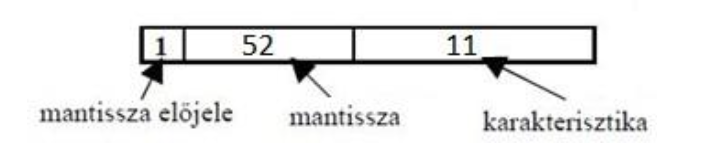
Egyszeres pontosságú
gyorsabb, kis memóriaigényű, kevésbé pontos eredmény
32bit-es formátum
Nagyobb értelmezési tartomány a fixpontoshoz képest
Kiterjesztett formátum esetén legalább 43 bit (32 + 11(őrzőbit))
Kétszeres pontosságú
Pontosabb, lassabb, nagyobb helyigény
64 bites formátum
Értelmezési tartománya jóval nagyobb a fixpontoshoz képest
Kiterjesztett formátum esetén legalább 79 bit (64 + 15 (őrzőbit))
IEEE 754 műveletek
6 darab
4 aritmetikai művelet
maradékképzés
négyzetgyökvonás
bináris, decimális konverzió
végtelennel való műveletvégzés
kivételek kezelése
IEEE 754 kerekítés
1. legközelebbire való kerekítés2. – végtelen felé kerekítés intervallum algebra
3. + végtelen felé kerekítés intervallum algebra - 0-ra kerekítés (trunc / levágás)
IEEE 754 kivételek
A kivételek felbukkanása megszakítást eredményez.
Overflow
Underflow
0-val való osztás
Négyzetgyökvonás negatív számból
Műveletek lebegőpontos számokkal

Összeadás:
A kitevőket megvizsgáljuk: csak azonos kitevőjű számok adhatók össze. Amennyiben a kitevők nem egyenlők, akkor a kisebb kitevőjű szám mantisszájának törtpontját balra léptetjük, és közben inkrementáljuk a karakterisztika értékét. A ciklus addig fut, amíg a kitevők meg nem egyeznek. Mantisszákat összeadjuk, karakterisztikákat változatlanul hagyjuk. Normalizálás szükség esetén (első értékes jegy elé tesszük a pontot).
Lebegőpontos műveletvégzés konkrét megvalósítása
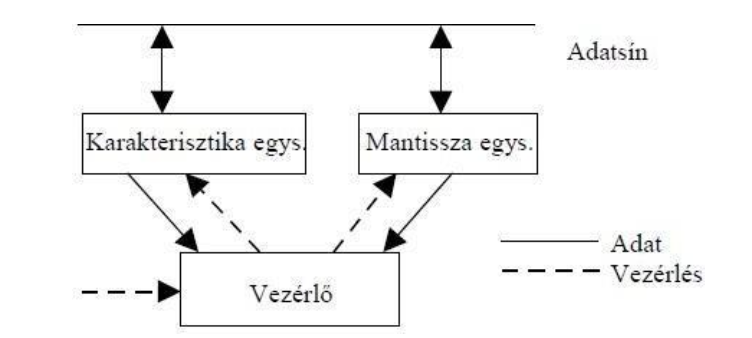
1. Univerzális (kombinált) műveletvégző segítségével
Műveletvégző (ALU) parciálása (részekre bontásával), vezérlés bonyolultabb Szervezési megoldás: egymás után mantisszát és a karakterisztikát külön regiszterekbe tároljuk, és a végén újra egyesítjük→ez lassú.
2. Dedikált FP
Dedikált jellemzői:
- Míg a mantissza egységnek szorozni/osztani is kell tudni, a karakterisztika egységnek elég összeadni/kivonni, ezért az utóbbi egyszerűbb
- A mantissza és a karakterisztika egység párhuzamosan is működhet(ekkor a mantissza egység jelenti a szűk keresztmetszetet a szorzás/osztás miatt, tehát azt kell igen gyors végrehajtásúra tervezni)
BCD megjelenésének okai
- Fixpontos ábrázolással a törtszámok pontatlanok
- Lebegőpontos ábrázolással a mantissza-, karakterisztikaforma nem teljesen pontos,
csak pontosabb.
- A kettes komplemens esetében: 10-es számrendszerű számokat átszámítjuk kettesbe,
majd vissza...
- BCD esetében decimális számrendszerből átkódoljuk a számokat kettesbe és
vissza. -> mert ha csak átváltanánk, ott kis maradékok képződnek (pl: 0,3 binárisban végtelen szakaszos, ezért kerekíteni kell -> nem pontos)Kódolás = egyértelmű megfeleltetés.→A BCD pontosabb ábrázolás
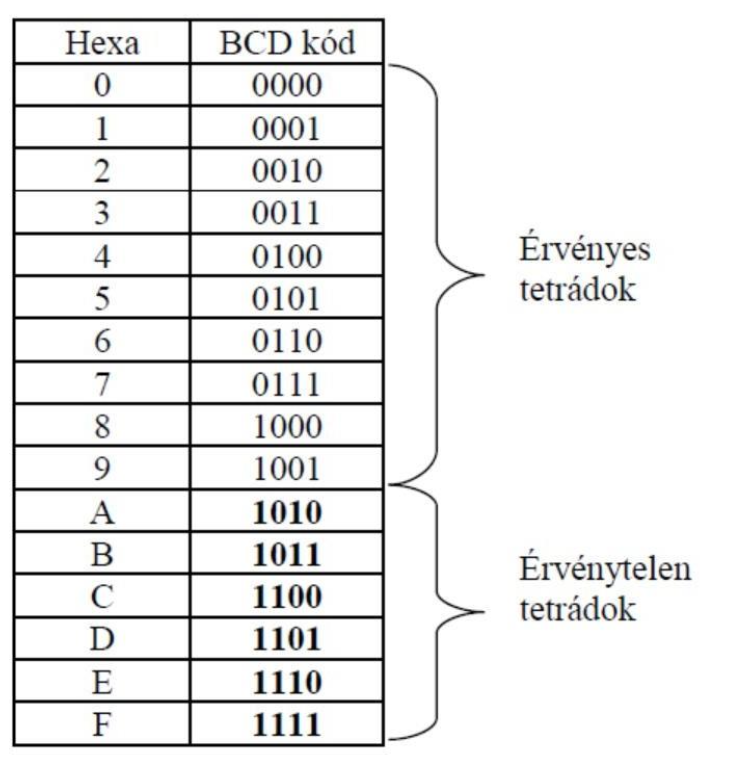
BCD ábrázolása
Ábrázolás:
4 biten ábrázoljuk a számjegyeket (tetrádok) (0000→1001).Maradnak kihasználatlan, érvénytelen bitsorozatok (tetrádok): 1010→1111, hexadecimálisan A-tól F-ig (decimálisan 1 - 9). (4 bit 1 tetrád)
BCD formátumok

Zónázott:
o Egy byte két részre oszlik.o Magas tetrád (a byte első négy bitje) a zóna (előjel), kisebb tetrád (a byte
utolsó négy bitje) a BCD szám.
Pakolt:o Az első byte első bitje az előjel. (A többi bitet nem használják másra) o A további kilenc bájt tartalmazza a BCD számokat.o Intel: 10 byte, 18 helyi érték.
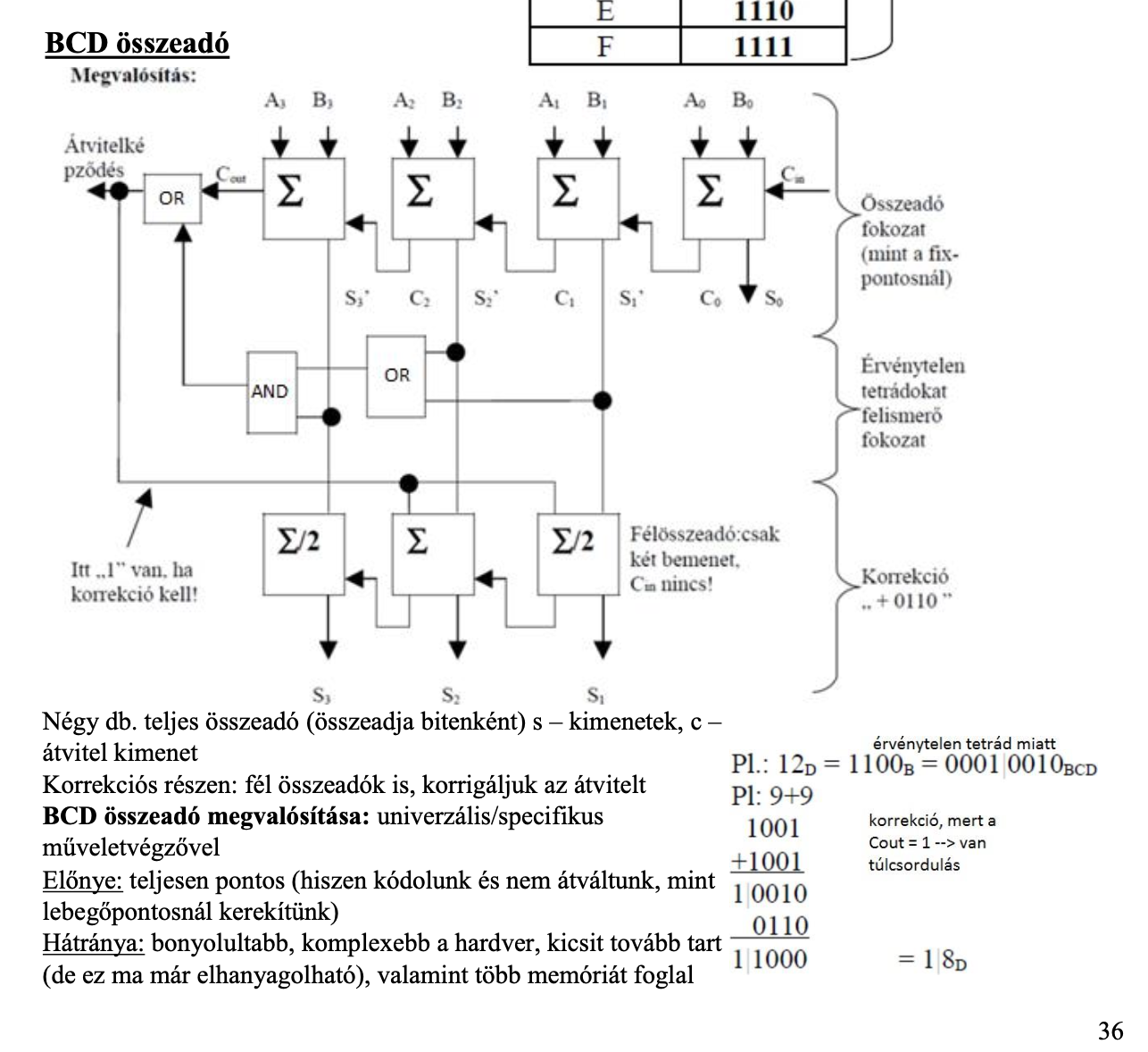
BCD összeadás menete
Összeadás:
fel kell ismernünk az érvénytelen tetrádokat és ezeknél korrekciót kell végrehajtani.
az érvénytelen tetrádok esetén kivonunk
belőle 10D-et (10-et decimálisan) és
lépünk egy 10-es átvitelt.pl.: 15D = 1111B = (érvénytelen ezért levonunk 10et, majd léptetjük) = 0001 0101BCDÉrvénytelen tetrádok felismerése:
Az első bit helyértékén 1-es áll, ÉS a második VAGY a harmadik bit helyértéken egyes áll.
Megvalósítás: 3 fokozat
a) Összeadó fokozat
b) Érvénytelen tetrád felismerő fokozat
c) Korrelációs fokozat
BCD érvényes és érvénytelen tetrádok
BCD összeadó
A fixpontos, a lebegőpontos
Finxpontos:
Előny:
-gyors műveletvégzés (ciklusváltozónak ideális)
-kisebb memóriaigény, többféle formátum: 8, 16, 32, 64, 128 bites
A formátumok közül mindig a számunkra szükséges értelmezési tartományának megfelelően válaszunk
-egész számok esetén teljesen pontos ábrázolás pl: if a=1 fixpontosnál és BCD ábrázolásnál adható ki, lebegőpontosnál nem
Hátrány:
-törtnél teljesen pontatlan (7/4=1)
Lebegőpontos:
Előny:
-akkor alkalmazzuk, amikor a fixpontos értelmezési tarománya kicsinek bizonyul
-törtszámok ábrázolásához
-a gyakorlatban kielégítő pontosságú
Hátrány:
-kétszeres pontosságot csak indokolt esetben alkalmazunk, mert lassabb, több erőforrást igényel
BCD előny/hátrány
BCD:
Előny:
-teljesen pontos, nincs kerekítés
-pontosabb, mint a lebegőpontos ábrázolás -> banki felhasználás
Hátrány:
-komplexebb műveletvégzés
-komplexebb hardver, több tranzisztor, több memória
-lassabb, ezért már kevésbé alkalmazzák
-a legtöbb hétköznapi felhasználáshoz elegendő a lebegőpontos pontossága
Az ALU egyéb műveletei
- mind a 16, kétoperandusos logikai műveletre képes (Pl.: OR, AND, XOR, NOT)
- léptetés, invertálás, load/store, összehasonlítás
- címszámítás (végrehajtási állapotban):
a korai gépekben az általános célú műveletvégző végezte
azonban napjainkban tipikusan célhardver végzi
- a karakteres műveletek tipikusan általános célú műveletvégzőben történnek.
A vezérlő egység általános jellemzése
Az egyik legkomplexebb áramkör, vezérlőjeleket állít elő, a felépítése és működése általában céges titok
Lelke az ütemező, amiről nincs pontos publikáció
Két alapvető tervezési módja van -> huzalozott és mikro programozott vezérlési mód
A mikro programozott vezérlés tulajdonságai
- Programozott vezérlőt használ, nem csupán a fizikai áramkörök végzik a vezérlést
- Minden utasítás egy vagy több mikroutasítással valósul meg
- A mikroművelet aktivál egy specifikus vezérlő vonal készletet
Előnye: rugalmasabb, áttekinthető, olcsó
Tekintettel arra, hogy a fejlesztéséhez nem kell az egészet újratervezni, elég csak a programot újraírni
Hátránya: mindig lassabb, mint a kizárólag hardveres megoldás, a programozás magas szintű hardver ismeretet igényel
A huzalozott áramköri vezérlés tulajdonságai
A vezérlés elve: forrásregiszter tartalmát módosító áramkörön keresztül a célregiszterbe vezetjük→Kapuáramkörök nyitása
Tervezésének menete:
- igazságtábla felírása
- célfüggvények (logikai függvények) felírása
- azonos átalakítások elvégzése -> a függvények egyszerűsítése az építőelemek csökkenése és az ezáltali sebességnövelés érdekében (minél kevesebb logikai kapu)
- megvalósítás
Előnyök:
- nagyon gyors
Hátrányok:
- nehezen áttekinthető
- bonyolult, merev, nehezen módosítható
- drága kivitelezés
A processzor vezérlésének megvalósítása (ábra)
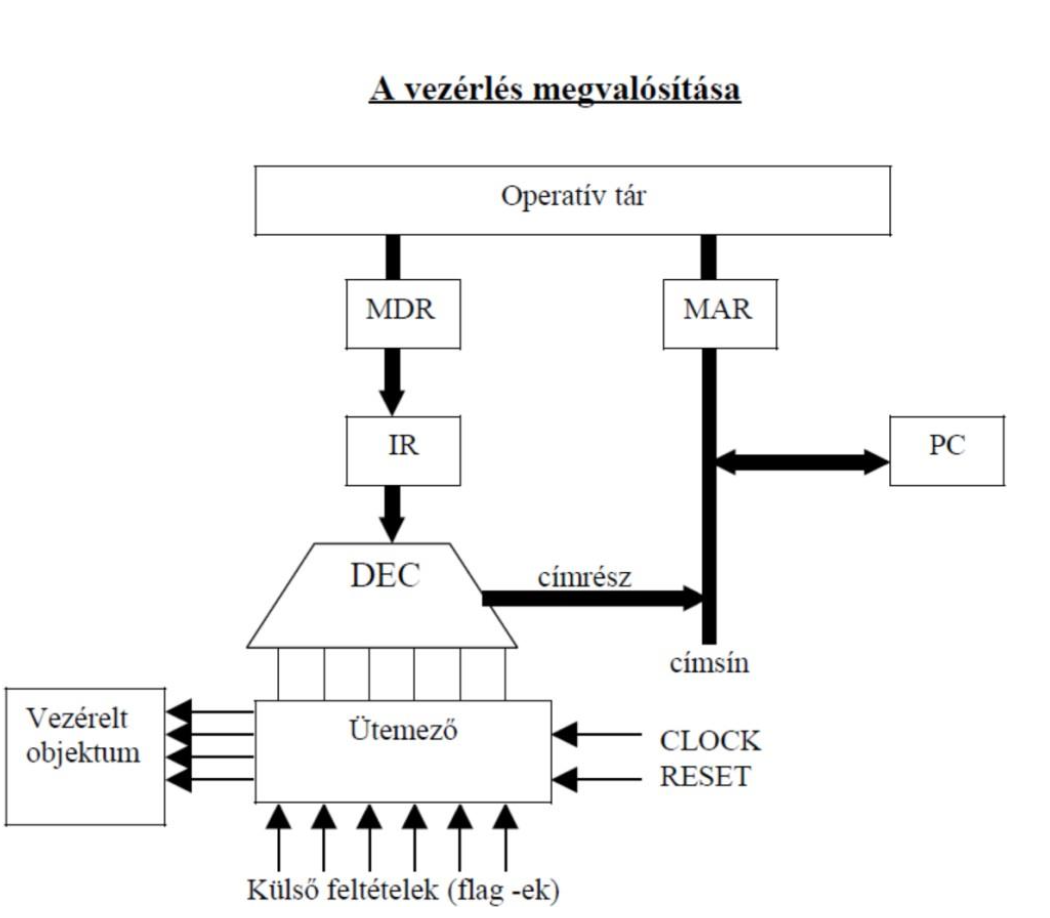
A processzor ütemező feladatai
vezérlőegység többi blokkjának a vezérlése
vezérelt objektumok szekvenciális vezérlése (MEM, ALU, ...)
Forrás és célregiszterek, amelyek a vezérlésben részt vesznek:
ALU (AC, általános regiszterek)
vezérlőbusz regiszterei (IR, PC)
memóriával kapcsolatos regiszterek (MAR, MDR)
I/O rendszerekhez kapcsolódó regiszterek és vezérlők (parancsregiszterek,
adatregiszterek, állapotregiszterek)
A processzor vezérlőn belüli módosító áramkörök
Módosító áramkörök:
• összeadás• léptetés• inkrementálás • invertálás• komparálás• stb.
A processzor vezérlő működésének lépései
a vezérlő a forrásregiszter kimenő kapuját és a módosító áramkör bemenő kapuját megnyitja
a forrásregiszter tartalma átmásolódik
előírja a módosító áramkör számára, hogy milyen módosítást hajtson végre (pl.
inkrementálás, léptetés stb.)
a módosított áramkör kimenő kapuját és a célregiszter bemenő kapuját megnyitja
az eredmény átmásolódik
A buszrendszer általános jellemzése
Az egyésgek (CPU, RAM, perifériák) közötti kommunikációra szolgál, annak az infrastruktúráját biztosítja
Adatokat és vezérlő jeleket továbbítunk
- Az adatátvitelben résztvevő eszközöknek biztosítani kell a kijelölést (megcímzés: címmegadás vagy utasítás alapján létrehozott harveres kapcsolat) és a kizárólagos használatot
- meg kell határozni az átvitel irányát
- meg kell oldani az eszközök működésének összehangolását (szinkronizáció)
Előnye: Szabványosított, ezért az eszközök könnyen cserélhetőek
Jelentősége: a buszrendszer a felhasználó számára transzparens -> nem tud és nem is kell vele foglalkoznia, automatikusan működik
A buszrendszer kommunikációjának fajtái
Egységen belüli kommunikáció (pl CPU-b belül) a BELSŐ buszrendszer
- kis távolságok, közös vezérlés, közös órajel
Egységen kívüli komm. a KÜLSŐ buszrendszer
- viszonylag nagy távolságok -> jelentős késleltetés -> nem célszerű a központi ütemadó
- jelentős eltérés az optimális sebességek közötti eltérés a különböző eszközök között
- eltérő szabványok
A buszok csoportosítása az átvitel iránya szerint
- Szimplex - CLK, RST -> csak egy irányú
- félduplex -> kétirányú, de egyszerre csak egy
- duplex (adatbusz) -> egyszerre több irányú (több vezeték)
A buszok csoportosítása az átvitel jellege szerint
Dedikált:
- gyors, megbízható
- minden egységet, minden más egységgel összekötünk. Leginkább a rendszerbuszoknál használjuk
Előnye: A sok kapcsolat miatt gyors és megbízható (egy kapcsolat meghibásodása esetén másik úton is tud kommunikálni)
Hátránya: drága a sok vezeték miatt, bonyolult új egységet adni hozzá
Shared (megosztott):
Minden egység közös buszon kommunikál, de egyidejűleg csak egy adó lehet
Előnyei: olcsó, szabványos kialakítás miatt könnyű bővíteni új elemekkel
Hátrányai: egy idejűleg csak egy adó -> lassú lehet, érzékeny a közös busz meghibásodására
A buszok csoportosítása az átvitt tartalom szerint
-címbusz
-adatbusz
o ugyanazon a vezetéken keresztül továbbítják a címeket és az adatokat vezetékkel való spórolás céljából + így kevesebb csatlakozó láb kell.
o PCI segítségével időbeli multpiplexelést hajt végre, azaz ugyanazon a vezetéken átviszi a blokk kezdőcímét, majd ciklikusan az adatokat, közben inkrementálással állapítva meg a címet
-vezérlő vezetékek
- épp adat vegy cím van-e a buszon
- vezérlési információk és az egység állapotára vonatkozó információk
A vezérlő vezetékeken továbbított jelek fajtái
Adatátvitelt vezérlő jelek:
- M/IO: megmondja, hogy a vezetéken memória vagy IO cím található
- R/W read/write: Az adatátvitel iránya a processzor felől nézve
- B/W byte/word: Az adat hossza, a párhuzamosan átvitt bitek száma
- AS (address strobe): megmutatja, hogy a rendszerbuszra címet helyeztünk-e
- DS (data stobe): megmutatja, hogy a rendszerbuszra adatot helyeztünk-e
- A/D address/data: megmutatja, hogy az adott buszon adat vagy cím van
- RDY (ready): megmutatja, hogy az átvitel befejeződött, vagy az eszköz készen áll
Megszakítást vezérlő jelek:
- megszakítás kérés
- megszakítás visszaigazolás
Buszfoglalással kapcsolatos jelek:
- sínfoglalás kérése, jelzése, engedélyezése
Egyéb:
- CLCK - órajel
- Rest - reset-jel
A buszok csoportosítása az összekapcsolt területek alapján
Processzorsín: processzor-memória
Bővítősín: prefirériák - processzor&memória
A buszok csoportosítása az átvitel módja szerint
-párhuzamos
-soros
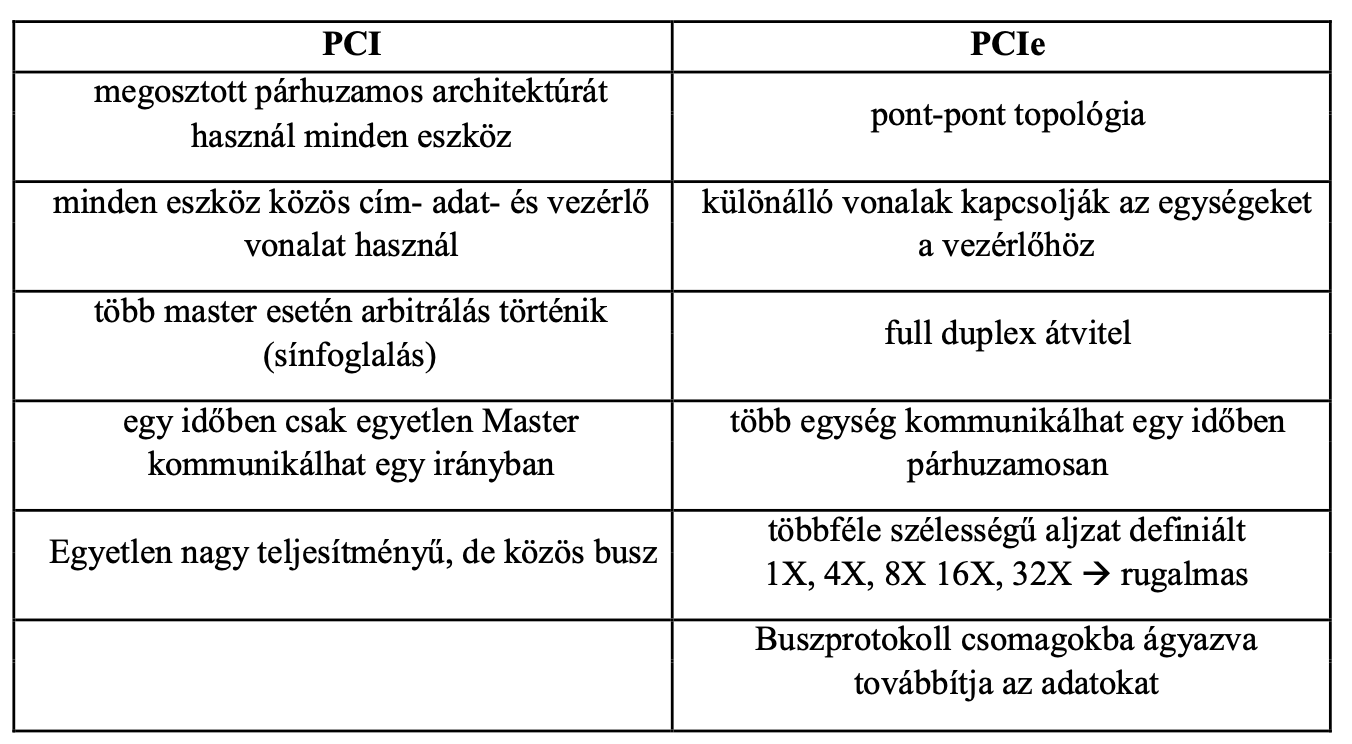
PCI és PCIe összehasonlítás
USB fejlődés
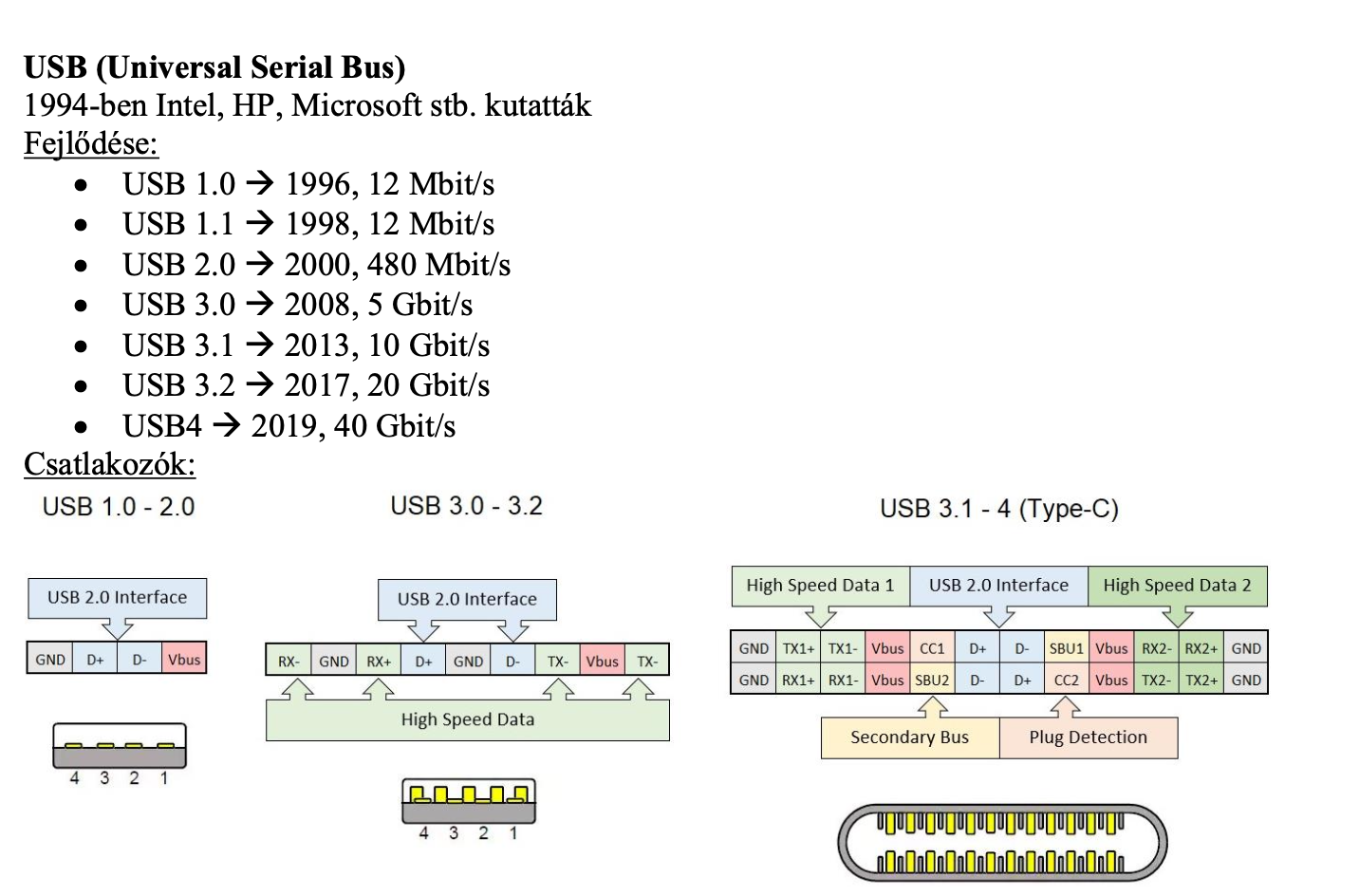
Tunderbolt 3
-PCIe busz
-USB C
-40Gb/sec
-Intel fejlesztés
Thunderbolt 4 újdonságok:
-erősebb követelmények a gyártókkal szemben -> 2 4k monitor vagy 1 8k monitor támogatás, előírt legalább 32gb/sec PCIe kapcsolat, DMA védelem
Soros, párhuzamos buszok
Több vezeték segítségével párhuzamosítja az adatokat (ISA, PCI)
Hátrány: sok vezeték -> komplex, drága, sok helyet foglal
Egyetlen gyors vezetéken több adat küldhető át, mint több lassún
sorosítás -> kódolással (bitsorozatok)
Párhuzamos buszok hátrányai
Nem alkalmas nagy frekvenciás átvitelre, mert:
- vezetékek közötti időeltérés, ha különböző a hosszuk (delay skew)
- a sor párhuzamos vezeték rengeteg elektromágneses interferenciát generál (EMI - elektromágneses zaj) -> zaj miatti adatsérülések
- áthallás a vezetékek között interferenciát okozhat
- nehezen bővíthető -> a soros buszoknál szoftveresen is lehet bővíteni
Az Intel elosztott buszrendszer megoldása
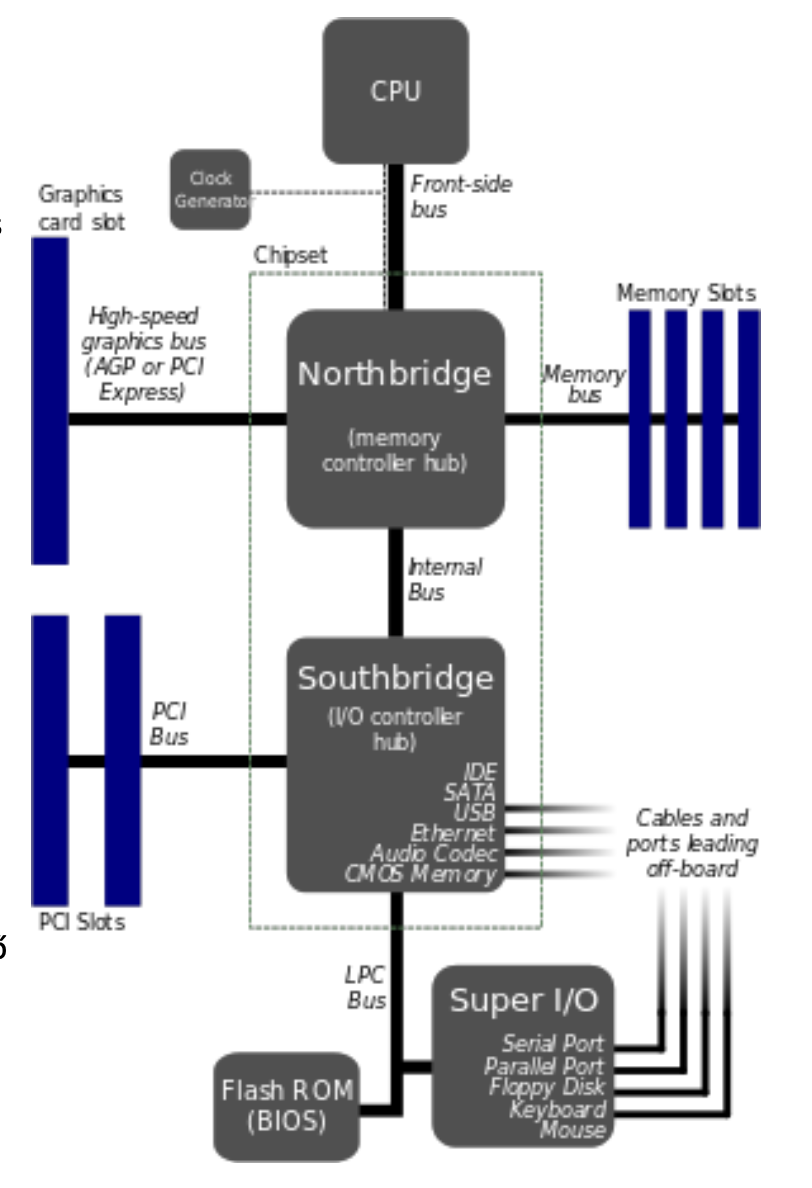
chipset: alaplapon elhelyezett szakosodott chip
Back SideBus -> CPU-n belüli gyors rendszer
Front Side Bus: a processzortól a számítógép egyéb részeihez menő chipseten keresztüli külső interfész -> sokkal lassabb
Északi- és déli híd felosztás
északi -> gyors -> memory bus, graphics bus (AGP, PCIe)
déli -> több egység (PCI, IDE, SATA, USB, Ethernet stb)
Az északi hidat később integrálták
I/O eszközök és a memória kapcsolata
- Megosztott busz koncepció pl: PCI
- pont-pont kapcsolat, dedikált buszok pl:PCIe, HyperTransport, QPI
HyperTransport
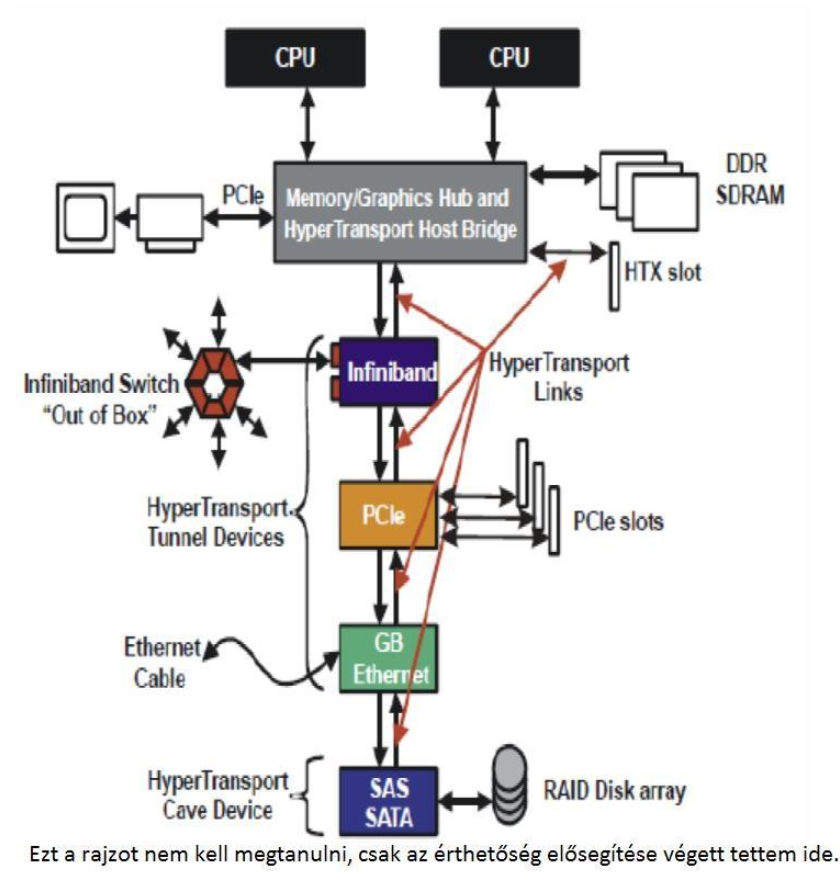
- 2001-ben az AMD mutatta be
- kétirányú soros/párhuzamos
- szélessávú
- alacsony késleltetésű
- fő feladata a front side bus kiváltása
- a processzorba integrált, de I/O buszként is alkalmazzák
- csomagkapcsolt elv
- nincs külön memória címtere, hanem a memóriában van leképzett I/O címtér neki -> ellentétben a PCI-al
Két egység:
alagút (tunnel): az eredeti funkcionalitásán kívül (pl PCIe vagy Ethernet) két HT portot is tartalmaz, amin keresztül további HT egységek csatlakoztathatóak
barlang (cave): zsákutcát jelent, ez az egység zárja a HT láncot (a képen a SATA egység)
QPI (QuickPath Interconnect)
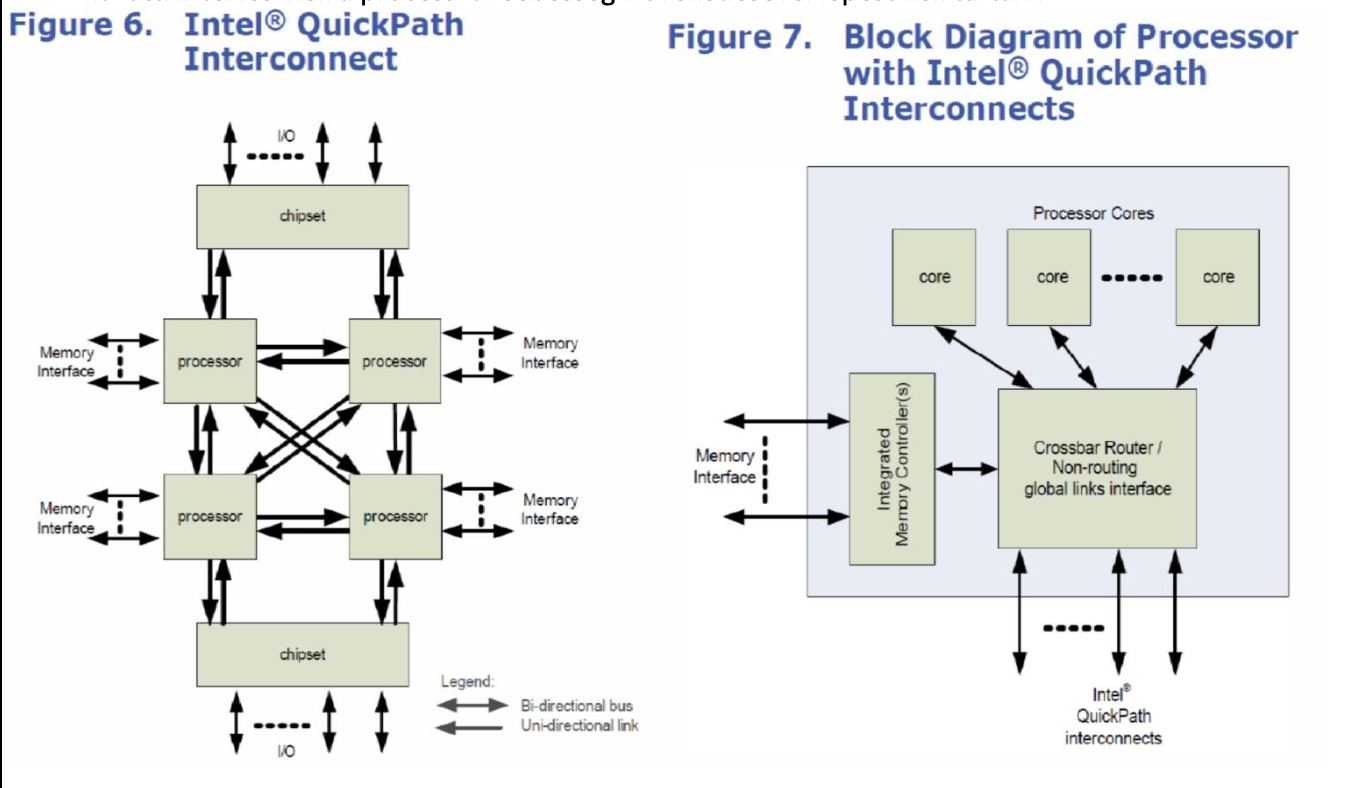
- feladata az FSB kiváltása
- 2008, Intel válasza a HT-re
- pont-pont összeköttetés
- lapkára integrált memória-vezérlők és NUMA technológia
- fizikailag elosztott memória, de közös címtérben címezhető
- minden port két darab, egyenként 20 adatvonalas linkből áll, irányonként különálló órajeladóval
- öt réteges architektúra
- 20 vonalon egy órajelre 20 bitet visz át párhuzamosan
- csomagkapcsolt
- több magos megoldás esetén lehet közös de különálló gyorsítótár is
- egy vagy több memória-vezérlő a processzoron
- skálázható -> crossbar router, több QPI port
Az I/O rendszerek fejődése
- processzor vezérelte a perifériákat
- I/O modul vezérelte -> wait for flag -> a cpu vár az I/O egységre, amíg az készen áll -> lassú, sok holtidő
- I/O vezérelte -> megszakításos üzemmód
- DMA -> Direct Memory Access -> saját memória a DMA modulnak
- Csatorna: I/O célú utasításokat dolgoz fel, közben a központi operatív tárat használja
- I/O processzor: I/O utasításokat dolgoz fel, saját operatív tárral rendelkezik
I/O fajtái
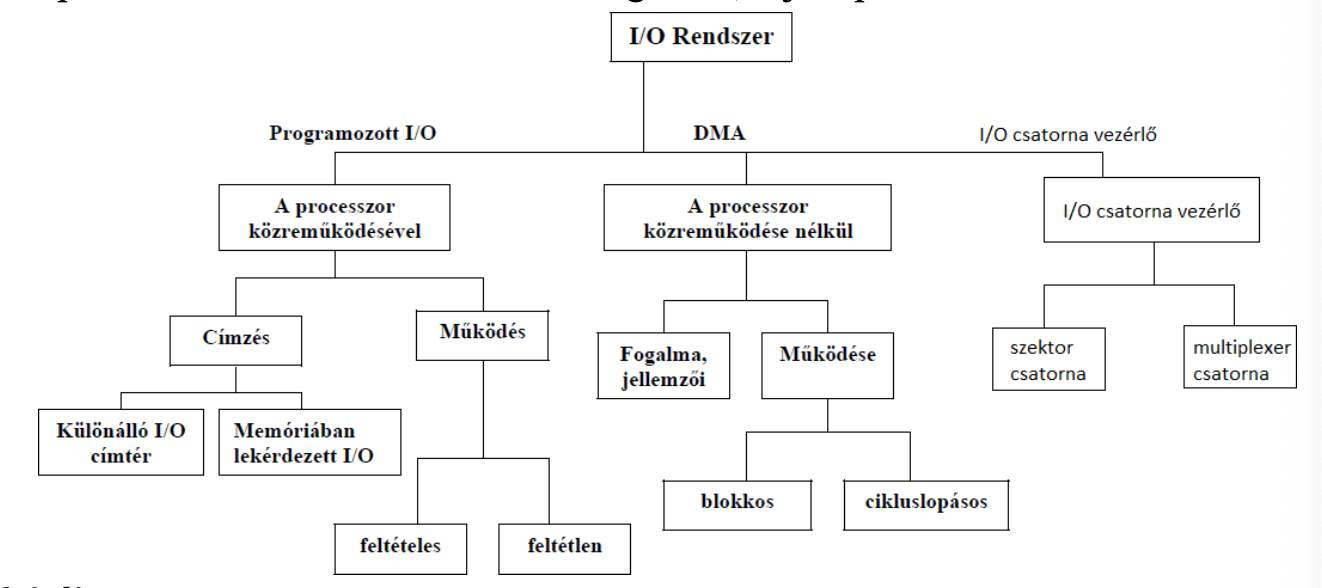
A CPU részvételével: programozott I/O
- Az I/O műveletek a CPU által irányítottan történnek
- Az I/O műveletekhez CPU utasítás tartozik
- Előnye: egyszerű megvalósítás
- Hátránya: terheli a CPU-t
CPU nélkül: plusz vezérlő egység kerül a rendszerbe, olyan képesség, hogy adatblokkokat tudjon vinni
a vezérlő képes:
- memória címeket generálni
- rendszerbuszon adatátvitelt bonyolítani
- buszfoglalást alkalmazni
- busz-master funkció betöltésére
Programozott I/O
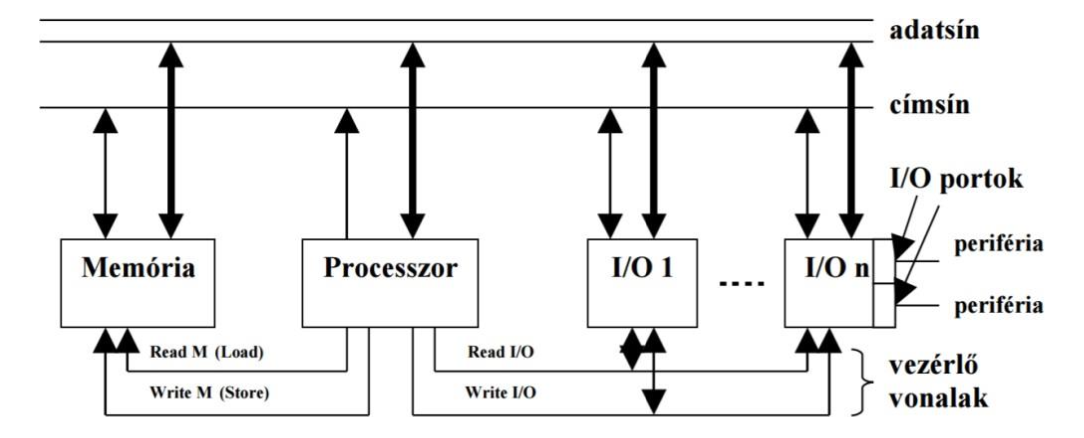
minden I/O művelethez a processzor egy-egy utasítást hajt végre
A processzor két különálló címteret lát: operatív tár, I/O címtér
- ugyanazon a címsínen keresztül haladnak a memóriacímek és az I/O címek is (rendszersín)
- létezik egy M/I/O vezérlővezeték, amely megmondja, hogy az adott időpillanatban memória- vagy I/O cím van a címsínen
- mivel különálló címtérről van szó, ugyanaz a cím szerepelhet mindkettőben
- azon regisztereket, amelyeken keresztül a processzor a perifériákkal kommunikálhat, I/O portnak nevezzük
- az I/O port fizikailag a vezérlőkártyában helyezkedik el
Az I/O port regiszterei
- parancs (command) regiszter: ebbe írja bele a processzor a kívánságait
- adatregiszterek:
- bemeneti regiszter: ebből olvassa be a processzor a periféria adatait
- kimeneti reg.: ebből írja ki ...
- állapot regiszter
A mai gyakorlat, hogy a következő regisztereket összevonják, egy regiszterben valósítják meg:
- parancs és állapot reg.
- be és kimeneti regiszter
További regiszterek:
- eszköz jelenlétet jelző reg.
- az eszköz tulajdonságait tartalmazór reg. (plug&play)
Lehet több regiszterkészlet is
A különálló I/O címtér megvalósítása
Az AC-n keresztül szállítjuk az adatot, ez lassú
következmény:
- a memória műveletekre load/store utasítások, míg az I/O műveletekre külön utasításkészlet
pl: Intel:
In X: a processzor olvassa be az X című I/O port regiszterét az AC-ba
Out X: írja be az AC tartalmát az I/O port adatregiszterébe
Előny:
- egyszerű, olcsó megvalósítás
Hátrány:
- a processzor részt vesz a kommunikációban
- az AC szűk keresztmetszetet jelent nagy mennyiségű I/O számára
Ezt az eljárást minden mai architektúra alkalmazza (pl: billentyűzet, soros és párhuzamos port)
A memóriába leképzett I/O
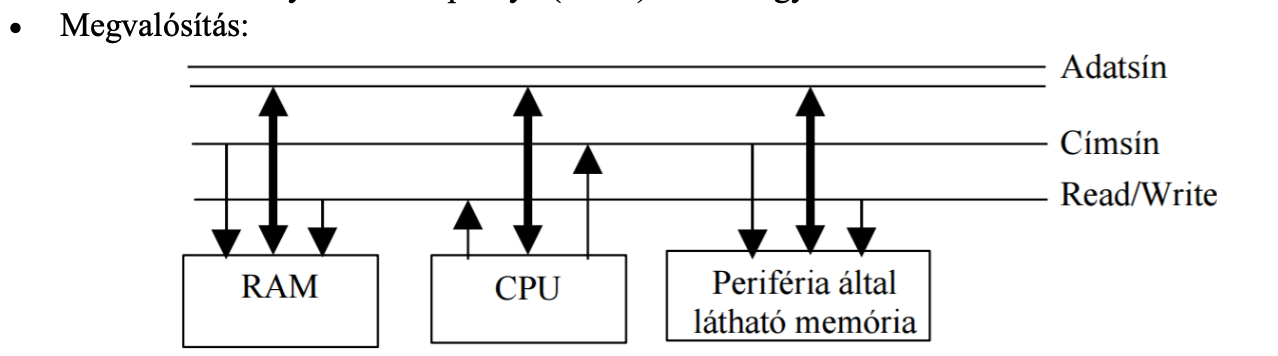
A processzor már memóriakezelő utasításokkal (load/store) éri el a közös memóriaterületet, amit a periféria is kezel
A periféria hozzáfér a rendszersínhez -> igen gyors
Értékelése:
- a különálló címtereknél sokkal gyorsabb
- továbbra is a processzornak kell utasításokat végrehajtani
- minden mai architektúrában megtalálható
pl: PC környezetben a monitor (videó) kezelés így működik
A programozott I/O működése (átvitelek)
Feltétlen átvitel: Feltétlen átvitel esetén a vevő mindig vételre kész állapotban van, és nem ellenőrizzük az átvitel sikerességét. A szinkronizálás hiánya az adó és a vevő között kihat az átvitel biztonságára is. Például LED–ek működtetésénél használjuk ezt az átvitelt.
Lekérdezéses vagy „wait for flag” átvitel
.
.
.
Megszakításos átvitel
.
.
.
DMA
Használata nagy tömegű adat esetén célszerű, ahol gyors perifériákat alkalmazunk. DMA használatával az átvitelt a processzor használata nélkül valósítjuk meg.
- a vezérlő képes kell, hogy legyen memória címek generálására
- adatátvitelre
- busz foglalásra (igénylés), vezérlésre (arbitrálás)
Adatátvitelt itt is a CPU kezdeményezi
Előnye: a megszakítások száma nagyságrendekkel csökken
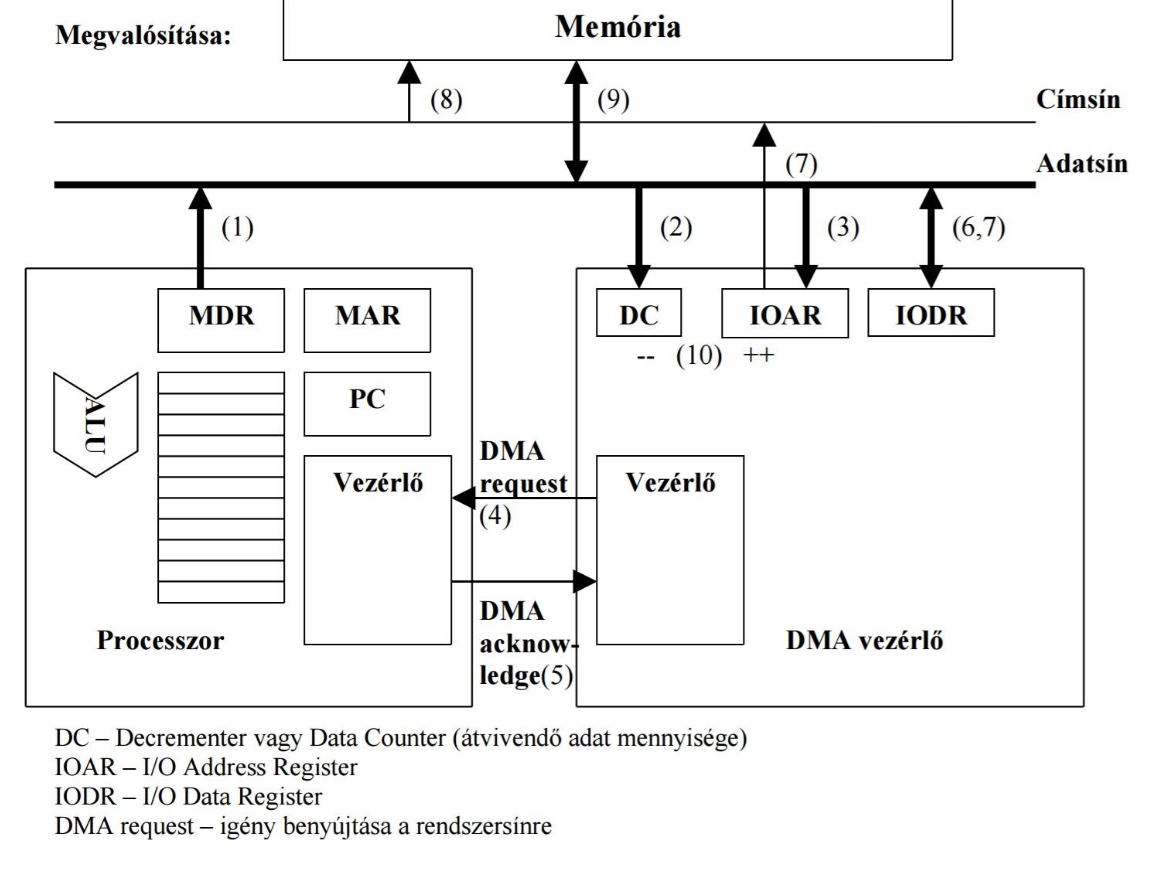
DMA működés előkészítése
programozott I/O-val átvisszük a processzorból a DMA vezérlőbe az átvitelhez szükséges információkat (mit, honnan, hová kell vinni), majd felhelyezzük ezeket az adatsínre
- DC-be az adategységek száma
- IOAR-ba (I/O Address Registry) beírjuk at adat leendő memóriabeli kezdőcímét, valamint:
- az egységet (byte, félszó, szó)
- az átvitel irányát
- a periféria címét
- az átvitel jellegét blokkos vagy cikluslopásos módon
- a résztvevő egységeket (mem. - mem., I/O - I/O, stb)
DMA Blokkos (burst) átvitel
CPU felprogramozza a DMA vezérlőt (előkészítés fázisa) (1-3)
A DMA vezérlő DMA request jelzést küld a processzornak (kéri a rendszersín használati
jogot) (4)
A processzor DMA acknowledge jelzéssel lemond a rendszersín használati jogáról (5)
A DMA vezérlő a kapott adatok alapján a perifériáról beírja az első átvinni kívánt adatot az
IODR-be (6)
A DMA vezérlő az IODR-ben lévő adatot a rendszersínen keresztül beírja az IOAR által
meghatározott memóriacímre (7-9)
A DMA vezérlő dekrementálja a DC-ben tárolt értéket, és inkrementálja az IOAR-ben tárolt
értéket (egy adategységgel növel – 1,2,4 byte) (10)
DMA ellenőrzi a DC tartalmát. Ha nem 0, vissza a (6) -ra, ha igen, megszakításkéréssel jelzi
a CPU felé, hogy befejeződött egy blokk átvitele (pl 3200 byte lehet egy HDD esetén
DMA Cikluslopásos átvitel (cycle stealing)
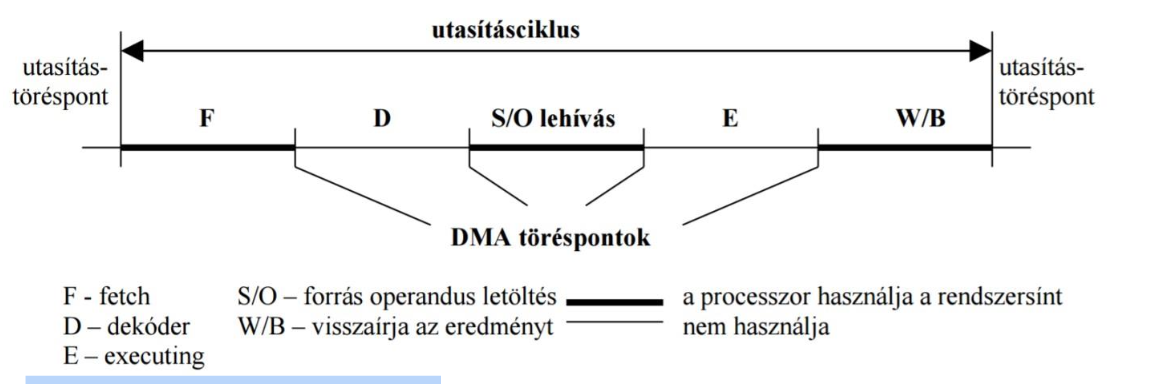
Kevés, de gyors adat átvitele esetén használatos. (pl.: karakteres nyomtatók) DMA vezérlő és CPU időosztásosan közösen használja a rendszerbuszt.
Nincs értelmezve a címgenerálás
Míg az utasítás-töréspontban a megszakítás feldolgozással a processzorra további munka várhat, addig a DMA töréspontban a DMA vezérlő a processzor helyett végezhet munkát
Ez a processzor és a DMA vezérlő általi időosztásos rendszersín használat előnye
Elve: utasítás feldolgozás felbontása pl. a következő lépésekre: lehívás, dekódolás, operandusok lehívása, végrehajtás, visszaírás a memóriába (ezek látszanak az ábrán is rövidítve)
I/O csatorna
Ez a DMA koncepció kiterjesztése a lassabb perifériák irányában
A csatorna I/O utasításokat kér le a processzorral közös memóriából, majd azokat végrehajtja
(nincs saját operatív tára)
A csatorna által vezérelt műveleteket továbbra is a processzor kezdeményezi
Ebben a koncepcióban is léteznek a perifériák irányítására hivatott I/O egységek vagy vezérlőkártyák, s a csatorna ezek munkáját hangolja össze → a processzor helyébe lép ilyen tekintetben (magát az átvitelt annak kezdete után a csatorna végzi)
Fajtái:
szelektor csatorna
multiplexer csatorna
Szelektor csatorna
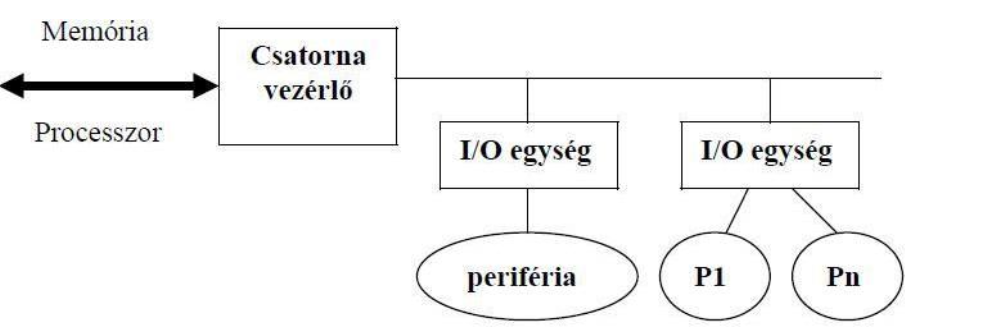
→ A gyorsabb perifériákat fogja össze
→ Közülük egyidejűleg csupán egy lehet aktív
Multiplexer csatorna
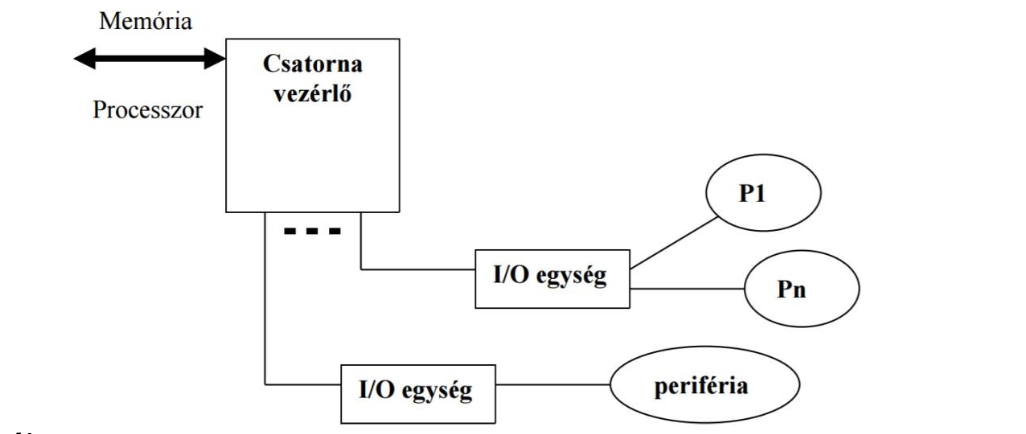
→ Lassabb perifériákat csatlakoztat
→ Közülük egyszerre több is aktív lehet
Két fajtája:
byte multiplexer: Az átvitel a lehető legnagyobb sebesség biztosítását tűzi ki célul pl. 3 db egység kommunikál egyszerre, melyek adatelemei: A1A2 A3A4 B1B2B3B4 C1C2C3C4 az eredő adatfolyam lehet pl. A1B1C1A2C2A3B2C3...
blokk multiplexer: A byte multiplexerhez hasonlóan blokkszinten végzi a munkáját
Megszakításos átvitel
Megszakításos átvitel
a processzor beírja kívánságát az I/O parancsregiszterébe és elkezd mást csinálni
az I/O egység gondoskodik arról, hogy a kívánt perifériáról a kívánt adat beírásra kerüljön az
I/O port adatregiszterébe, és ekkor az állapotregiszter „ready” bitjét beállítja, továbbá
megszakításjelzést küld a processzor felé
a processzor a következő utasítás-töréspontban észleli a megszakítás tényét és forrását:
▪ kiolvassa a megszakító I/O port állapotregiszterének tartalmát▪ mivel ott a „ready” bit be van állítva, ennek megfelelő megszakítás feldolgozó programot indít el; ez kiolvassa az I/O port adatregiszterét és tartalmát átviszi az AC-ba
Lekérdezéses vagy „wait for flag” átvitel
Lekérdezéses vagy „wait for flag” átvitel
az első lépés során a processzor beírja kívánságát az I/O port parancsregiszterébe
a processzor kiolvassa az I/O vezérlő állapotregiszterének tartalmát
amennyiben nem „ready”, akkor vissza a 2. pontba
amennyiben „ready”, akkor a processzor kiolvassa az I/O vezérlő adatregiszterének
tartalmát, és azt eljuttatja az AC-baMivel a processzor és a periféria sebessége között igen nagy különbség lehet, a 2. és 3. pont olvasási ciklusa akár több milliószor is feleslegesen fut → pazarolja a processzor időt
A megszakítás alapvető jellemzői
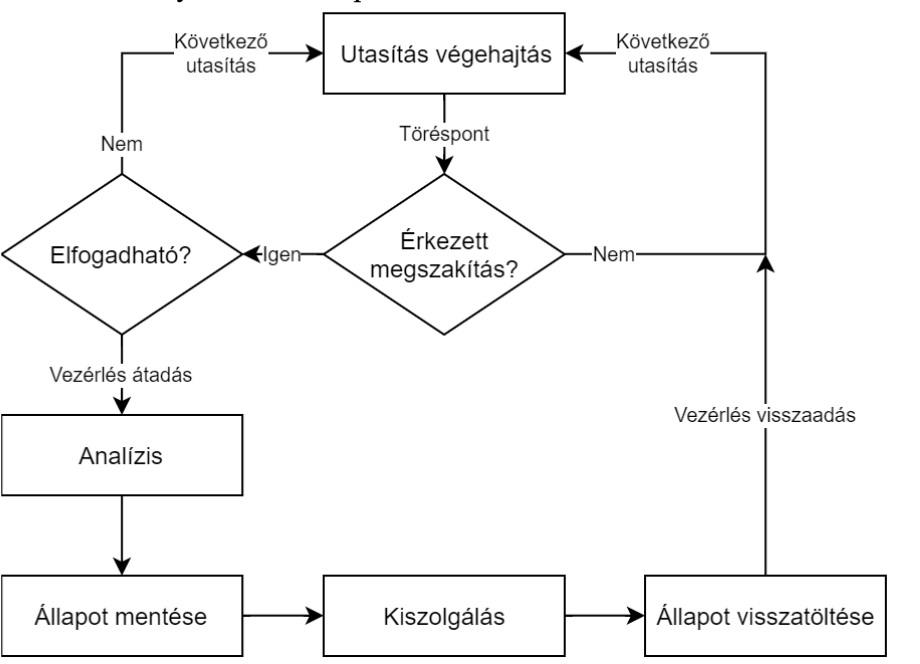
Célja a feldolgozás szempontjából véletlennek tekinthető események kezelése, a változó körülmények között az optimális működés biztosítása
folyamata az ábrán
- Megszakítás esetén tárolódik az éppen futó alkalmazás állapota (regiszterek, állapotjelzők)
- beállítódik a megszakító rutin kontextusa
A megszakítások csoportosítása
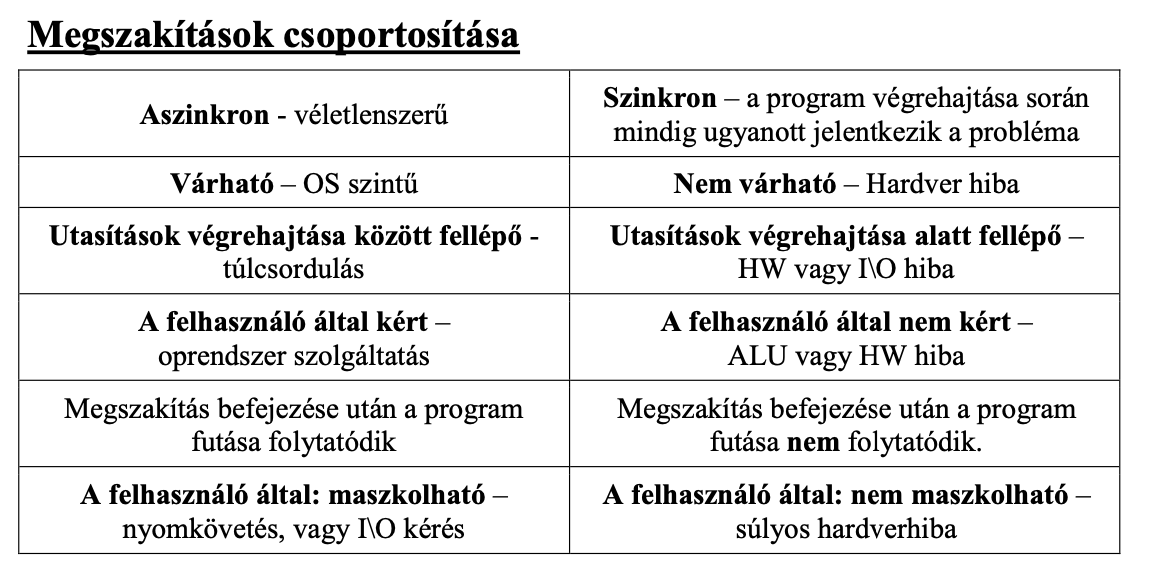
6 szempont
A megszakítási okok prioritás szerint

Megszakítások csoportosítása
non
Megszakítás menete
non
Megszakítási rendszerek szintjei
non
Memóriák csoportosítása
non
CMOS
non
ROM
non
RAM, SRAM, DRAM
non
SDRAM
non
DDR SDRAM
non
DDR2
non
DDR3
non
DDR4
non
DIMM
non