Anatomy of a search engine
advertisement

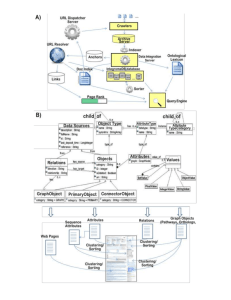
Anatomy of a search engine • Not much known about AV, Lycos, Yahoo, etc. • But Google and Clever (to some extent) are published • Design criteria • Differences • Architecture • Data structures Requirements • Basic IR concepts: – Recall: what % of relevant docs are retrieved – Precision: what % of docs retrieved are relevant • Quantity: – handle hundreds of thousands of queries/sec • Quality – High precision (not with pres. engines) Page rank • Idea: a page is important when it is referred to a lot, or referred to from an important page • PR is used to prioritize; works well even with search is just on page titles PR details • Pages T1,…,Tn point to page A, C(A) is a link fan-out of A PR(A)=(1-d) + d(PR(T1)/C(T1)+…+PR(Tn)/C(Tn)) d=dumping factor=.85 Model of random walk on the Web PR(p) = prob. That a “random” user will visit p Other features and terms • Anchor text is associated with the page it links to • Some markup aspects are used Google architecture • URL server sends list of URLs to be fetched to crawlers • StoreServer compresses and stores pages • Indexer extracts words, their pos., size, capital. • Anchors cont.links and their text • Sorter generates inverted index • Searcher uses Lexicon, II, and PR Some details • Barrels store words (wordIDs); if a doc contains a word, doc`s ID and its wordID are stored with hitlist of this word in the doc • Lexicon points to Inverted Barrels; ea word points to docid and hits Operation • Crawling • Searching • Ranking Crawling and indexing • Parsing into anchors and words – error robustness (flex+stack) • Indexing in parallel – hashing into barrels using the lexicon – the problem of new words shared Searching 1 parse query 2 convert words into wordIDs 3 Identif. A barrel for ea. Word 4 scan doclists until a doc that matches all the search words is found Ranking • For a single word, identify the hit list and its type, count the # of hits of ea type, vectormultiply • Combine with PR • For multiple words, take proximity into account Going further • Google will not return any IBM pages for the query `mainframes` • Many pages that point to IBM page use the term ‘mainframe’, so this page should be returned • Clever ranks authoritities pages and hub pages. Authorities are pages with high PR. Hubs are pages that point to authorities. E.g. my friend’s page with a list of links to on-line CD stores. Hubs may not be chosen by PR alone • Clever/HITS (Hyperlink Induced Topic Search) starts with an initial set of pages and hubs Mathematically speaking… • Let xp be authority weight, yq be hub weight, q->p denotes q links to p x p yq y p xq q p p q • Let A be adjacency matrix: Ai,j =1 if there is a link between i and j, 0 otherwise x ATy and y Ax x ATAx, and we can iterate that further, working with powers of ATA This sequence of powers converges to the eigenvector of ATA This means that the result does not depend on the initial weights • Remove ‘local’ links (“back to the main page”) • Drift: transfer of main authority to, e.g., topics of hobbies • Highjacking: if several pages from the same site occur in the base set, they may take over a topic • Remedied by partial content indexing – anchors, and by • dividing a page into pagelets – contiguous sequences of links • Hubs are good when learning about a topic, less so when seekeing specific info. Autres engins • Altavista et Lycos ont probablement des méthodes simples de sélection • Excite semble utiliser beaucoup de propriétés des pages • Voir « What is a tall poppy among Web pages? »7th Int’l WWW Conf.