(X - ) 2 - Indiana University
 2 - Indiana University")
Distributions and Their Moments
Q560: Experimental Methods in Cognitive Science
Lecture 3
The Role of Statistics
Statistical models allow us to efficiently summarize outcomes, and determine whether the outcome is due to chance
Two main branches of Statistics:
1.
Descriptive Statistics : Summarizing and communicating information about a group of numbers (data)
2.
Inferential Statistics : Drawing conclusions based on the data collected, and making predictions that go beyond the immediate data
Populations and Samples
Observations are usually made on individuals.
A population is the set of all the individuals of interest.
Populations are often so large that it is impossible to obtain measurements from all the individuals
A sample is a set of individuals selected from a population – we usually want samples to be representative (not biased)
Mary
Justin
Ellen
Chris H
George
Praful
Sarah
Trinity
Kim
Erin
Tank
Nicole
Pete
Ji
Frank
Alex T
Ruben
Sean
Rich
David
Will Cory
John S
Greg
Sean
John L
Justin
Ricky
Dennis
Tom Jim
James
Trevor
Sorab
Ruben
June
Ruben
Ruben
Alex K
Grant
Sue
Jhung
Ruben
Chen
Bubbles
Jullian
Steve
Chris J
Matt
Art
Nathan
Chuck
Gillian
Brad
Royce
Vera
Amanda
Brenda
Tessa
Xiangen
Hillary
All CogSci Students (Population)
Sampling
Sample
Dennis
James
Sue
Erin
June
Xiangen
Sample should be
• Representative
• Generalizable
The Population
All Individuals of Interest
Results from the sample are generalized back to the population
The Sample
Individuals selected for study
Sampling
Parameters and Statistics
A parameter describes a population
A statistic describes a sample
Parameter
• Average GPA for all
U.S. university students
• Average height of all
CogSci students
Statistic
• Average GPA for IU students
• Average height for this class
• We use a statistic to estimate a parameter
• Generally, Greek letters denote parameters, and
Roman letter denote statistics
The Population
Inferential Statistics:
How good an estimate of the parameter is the statistic?
Average Height = 5 ’ 9 ’’
The Sample (n=60)
Average Height =
5 ’ 6 ’’
Sampling
The Population
Inferential Statistics:
How good an estimate of the parameter is the statistic?
Average Height = 5 ’ 9 ’’
The Sample (n=120)
Average Height =
5 ’ 10 ’’
Sampling
Sampling Error: The discrepancy between the sample statistic and the true population parameter it is estimating
Sampling Error
Sampling Error: The discrepancy between the sample statistic and the true population parameter it is estimating
To reduce sampling error:
• Use a sufficiently large sample
• Use random selection: selecting individuals from the population at random for your sample to create an unbiased sample (sometimes bias is subtle— telephone survey example)
Statistical Truth: We can only
”
“ prove can measure the population. As a result of sampling error, we can only ever determine reasonable doubt
“
” something if we beyond a
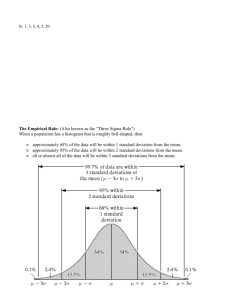
Shape of a Frequency Distribution
n = 10,000
Shape of a Frequency Distribution
Normal Distribution :
Symmetric and “ certain ” in most situations
“Everyone believes in it: experimentalists believing that it is a mathematical theorem, mathematicians believing that it is an empirical fact”
–Henri Poincaré.
On our website :
“Why are normal distributions normal?”
Population Distributions:
The Normal Curve
If we look at the shape of a histogram in behavioral data, it is often like a pyramid:
Population of heights
Shape of a Frequency Distribution
Symmetry: Are both sides of the distribution mirrors of one another, or is it skewed in one direction?
Shape of a Frequency Distribution
Kurtosis: Peakedness of a distribution
Where is the “Average”
How do we decide which is “ best ” ?
The overall goal of central tendency is to find the single score that is most representative for the distribution.
Mean
Median
Mode
Measures of Central Tendency
Mean: Arithmetic average
• sum of scores divided by number of scores
• most frequently used b/c it uses all scores in the set
Median: “ Middle ” score, when scores are in order
• corresponds to the 50th percentile
• appropriate for skewed/open-ended distributions, and distributions with undetermined scores
Mode: Most frequently occurring (popular) score
• appropriate for nominal data
Characteristics of the mean
1. Changing the value of any score will change the mean.
Always!
2. Adding or removing a score will usually (but not always) change the mean.
3. Adding or subtracting a constant value from each score will add or subtract the same constant from the mean.
4. Multiplying or dividing each of the scores will produce a mean that is multiplied or divided by the same factor.
When to use each measure
It may be possible to calculate all three measures for a given set of scores.
Often (but not always!) all three measures will have similar values.
• The mean is used most often (~90% of cases)
• Mean is often the most appropriate measure b/c it takes into account all scores in the dataset
When to use the median
1. When a distribution has a small number of extreme scores (i.e. when it is skewed).
Example: Bloomington has a mean income of $51,054 and a population of ~70,000
What happens to the mean if Bill Gates decided to move to
Bloomington?
The mean is no longer a “ representative ” measure for any one individual, including Bill
When to use the median
2. When a distribution contains undetermined values
(scores for which there is no value on the scale)
Example: sport scores (car racing, track/field), with a category “ DNF ” (did not finish).
When to use the median
3. When a distribution is open-ended (when there is no upper or lower limit for one of the intervals or categories).
Example: Income statistics, age groups.
When to use the mode
1. The scale of measurement is nominal. Only the mode can be used.
2. If the “ most typical case ” is to be identified.
Mean and median often produce fractional values.
In any case, the mode is very easy to determine ….
Relation of CT measures under data transformations
Symmetric Distribution: M = Mdn = Md
Positive Skew: Md < Mdn < M
Negative Skew: M < Mdn < Md
Kurtosis does not affect measures of central tendency
Variability
Distributions with the same central tendency, but different variability
Variability
Low/High
Variability helps to measure how well a sample of scores represents a distribution (inferential statistics).
Three measures:
• Range
• Interquartile range
• Standard deviation
Standard Deviation
The standard deviation measures variability by taking into account the distance between each score and the mean.
Note: range and interquartile range do not and are therefore not as accurate.
It is a more accurate measure of variability than the range or interquartile range
It is the average distance from the mean in a set of scores
Standard Deviation
How to find the standard deviation for a population of scores (step-by-step):
1. For each score, determine its deviation from the mean.
deviation score = X
= 3
2
1
4
3
X X -
5
Standard Deviation
How to find the standard deviation for a population of scores (step-by-step):
1. For each score, determine its deviation from the mean.
deviation score = X
= 3
X X -
5 2
4 1
3 0
2 -1
1 -2
Standard Deviation
2. Take the square of each deviation score. Take the mean of these squared values. This mean is called the mean squared deviation, or variance.
= 3 variance = sum of squared deviations (SS) number of scores
X X (X -
5 2 4
) 2
4 1 1
3 0 0
2 -1 1
1 -2 4 var
=
å
( X
m
)
2
N
=
10
5
=
2
Standard Deviation
3. The standard deviation is the square root of the variance.
Standard deviation = variance.
Done!
SS = Sum of Squares
A key step in calculating the standard deviation is to calculate the sum of the squared deviations, or sum of squares (SS).
1. Derivational formula:
SS = (X ) 2
2. Computational formula:
( X) 2
SS = X 2 –
N
These two formulae are exactly equivalent, but the second one is often easier to use.
Calculating SS:
Derivational Formula
SS = (X ) 2
X
4
3
1
0
X (X ) 2
----------------------------
Calculating SS:
Derivational Formula
SS = (X ) 2
X X (X-
1 -1 1
0 -2 4
4 2 4
3 1 1
) 2
-----------------------
=10
Calculating SS:
Computational Formula
SS = X 2 –
( X) 2
N
4
3
1
0
X X 2
----------------------------
Calculating SS:
Computational Formula
SS = X 2 –
( X) 2
N
X X 2
----------------------------
1 1
0 0
4 16
3 9
SS
=
26
-
=8 =26
(8)
2
4
=
10
Calculating Variance and
Standard Deviation
Population standard deviation: “ sigma ”
Population variance = “ sigma squared ” s s
2 s
2 =
SS
N s = s
2
Variability for Samples
So far we have talked about populations …
In a sample, s = standard deviation, s 2 = variance
Samples tend to underestimate variability of a population. We need to correct for that!
Bias:
M is an unbiased estimator of but s is a biased estimator of
Our sample scores are more likely to have come from the center of the population, so they will underestimate the true variability
Variability for Samples
Except for a change in notation, these three steps are the same for populations and for samples:
1. Find all deviation scores.
2. Square each deviation score.
3. Sum the squares.
Formulas for SS (notation!):
Derivational
Computational SS = X 2 –
( X) 2 n
Calculating Variance for Samples
To correct for bias, we will divide through by n -1
--> this increases the value closer to the true value
Sample standard deviation: s
Sample variance = s 2 s
2 =
SS n
-
1 s
= s
2 =
SS n
-
1
An Example …
These scores are a sample from a population
X: 1, 6, 4, 3, 8, 7, 6
Lets use the computational formula to keep it simple:
1. Square each score
2. Sum the scores and sum the squares of scores
3. Compute SS w/ computational formula
4. Compute variance
5. Standard deviation is square root of variance
An Example …
These scores are a sample from a population
X: 1, 6, 4, 3, 8, 7, 6
8
7
6
4
3
1
6
X
----
An Example …
These scores are a sample from a population
X: 1, 6, 4, 3, 8, 7, 6
X X 2
------------------
8
7
6
4
3
1
6
S
X
=
35 S
X
1
36
16
9
64
49
36
2 =
211
SS
= S
X
2 n
2
=
211
-
=
36
7
2
An Example …
These scores are a sample from a population
X: 1, 6, 4, 3, 8, 7, 6
X X 2
------------------
8
7
6
4
3
1
6
S
X
=
35 S
X
1
36
16
9
64
49
36
2 =
211 s
2
=
SS n
-
1
=
36
7
-
1
=
6 s
= s
2 =
6
=
2.449
Properties of the Standard Deviation
1. The standard deviation measures the
(standard) distance from the mean.
“ typical ”
2. The standard deviation allows us to visualize the distribution.
3. The smaller the standard deviation, the more accurately a sample will represent its population
(inferential statistics).
4. Transformations of scale:
• Adding a constant factor: standard deviation does not change.
• Multiplication: standard deviation is multiplied as well.