Chapters 2&3.
advertisement

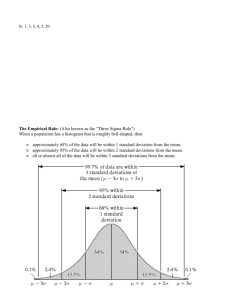
Chapter 2 Characterizing Your Data Set Allan Edwards: “Before you analyze your data, graph your data Chapter 2 Characterizing Your Data Set Allan Edwards: “Before you analyze your data, graph your data Francis Galton, Father of Intelligence Testing: Whenever you can, count! Frequency Table Variable is Continuous Grouped Frequency Table & Distribution Continuous variable, Data from Same 100 Subjects Constant Interval “Class Interval” Grouped Frequency Histogram For Continuous Variable Bars “Touch”, the end of one interval is beginning of next Value is middle value of Interval Spatz says the bars don’t touch – Whaaaaaa????? Bar Chart for Categorical Variable Bars are separated – a lot of Biology is not almost English Standard Normal Distribution The more Extreme your score the more unusual, improbable you are Remember this relationship -- it’s the basis of 90% of statistics Typical of many characteristics -- E.G., height, intelligence, speed Rectangular Distribution Never Seen One Extreme Scores are NOT less usual/frequent/probable Non-Normal Distribution Example: Income -- Where is the mean? How would you characterize these data? Negative Skew Bimodal Distribution Is the Mean appropriate/representative E.G., Mean age of onset for Anorexia is 17yrs One Peak is at 14yrs -- Onset of Puberty One Peak is at 18yrs -- Going away to college Bimodal Distribution, cont. Characterizing Your Data Measures of Central Tendency Characterizing your Data: Shorthand notation for all of your values Central Tendency: • A representative value • Where Your Scores tend to “Hang Out” • Where you go to find your data 1. Mean -- What is definition & why do you use it? 2. Median -- Middle Value What if you have an even # of values? 3. Mode -- Most frequent value Which Central Tendency is Best? •Mean Ratio Data (People allow Interval Data) Symmetrical Distributions •Median Skewed Distributions Ordinal (Ranked) Data -- A mean cannot be computed •Mode Nominal (Qualitative) Data Bimodal Data If you Had to Guess the Value of Each (Quantitative) Data Point • Mode: Highest # of correct guesses • Median: Errors would be symmetrical Overestimations would balance out Underestimations • Mean: Errors of Estimation will be smallest, overall Two Unique Properties of the Mean: 1. Deviations are smallest from the mean Than for any other value 2. Deviation scores sum to zero How Strong Is Your Tendency? Measures of Heterogeneity (Chapter 3) Two Data Sets with nearly identical: •Ns •Means •Medians •Modes Are these two data sets similar? Are They The Same? Some Data Sets are More Heterogeneous Jockeys: Very Low average height Very Homogeneous Presbyterians: Medium average height Very Heterogeneous NBA Players: Very High average height Very Homogenous How do you characterize a data set’s Heterogeneity? The Greater the Heterogeneity, the Weaker the Central Tendency Quantifying Heterogeneity Range: Highest Score minus Lowest Score Very sensitive to a single Extreme Score Inter Quartile Range: 75th percentile minus 25th percentile Captures 50% of the scores How wide do you have to go to capture 50% of values? The wider you have to go the more Heterogeneity Heterogeneity, cont. The more Heterogeneity, the more the scores will deviate from The mean Xi 5 6 7 Sum= Mean = 6 Xi-Xbar Di -1 0 1 0 0 Xi Xi-Xbar Di 4 -2 6 0 8 2 6 0 0 Heterogeneity, cont. Two Unique properties of the Mean: 1. All deviation scores sum to zero 2. Raw scores Deviate Less from the mean than from any other Value This makes the mean the Best Representative of the data Set If distribution is symmetrical Heterogeneity, cont. Problem: •All deviation scores sum to zero no matter how Heterogeneous the raw scores •You Cannot average deviations scores to quantify heterogeneity Solution: Make all deviation scores Positive Heterogeneity, cont. Two way to make all deviation scores Positive: •Take the Absolute Value of the Deviation Scores: Average of absolute values = Average Deviation Mean +/- AD Captures 50% of raw scores •Take the Square of the Deviation Scores Average of squared deviation scores = Variance 2 for Population S2 for Sample S2 -”hat” for estimating Population from Sample Variance Population Estimate of Population from Sample To Describe sample use N S2 = Sample Variance Problem: Magnitude of Variance is large relative to individual Deviation scores -- Quantifies but not very descriptive Standard Deviation Population Sample Population Estimate Mean +/- SD captures 68% of Data Points Standard Deviation, cont. The Concept Standard Deviation Standard Deviation from the Mean “Average” Deviation from the Mean Expected Deviation from the Mean Expect 68% of your data to be within 1 SD of the mean Expect 95% of your data to be within 2 SD of the mean If your score is beyond 2 SDs of the mean You are very infrequent You are very unusual You are very improbable Associate: Infrequent with Improbable Interpreting a Value Transforming a score to make it more interpretable: •Comparing two scores: Two tests of Equal Difficulty but of Different Length Pretend both tests were 100 items long How many would you have gotten right? Percent Correct is a Transformed Score •Comparing one score to everybody else: Pretend there were 100 people, where would rank? Percentile is a Transformed Score Z-scores & Z-transformations Take each score (Xi) and covert it to Zi Mean of z-scores = 0 Standard Deviation = 1 Units of z-scores are in Standard Deviations Z-score compares Your Deviation (numerator) to the “Average Deviation” (denominator) Where you are relative to Population Think Percentile Interpreting Your Z-Score Interpreting Your Z-Score, cont. Interpreting Your Z-Score, cont. Interpreting Your Z-Score, cont.