probability distribution
advertisement

Last lecture summary
Probability
• long-term chance that a certain outcome will
occur from some random (stochastic) process
• how to get probabilities?
– classical approach (combinatorics)
– relative frequencies
– simulations
• sample space S (finite, countably infinite,
uncountably infinite), event A, B, C, …
Types of probabilities
1. marginal (marginální, nepodmíněná)
• S={1,2,3,4,5,6}, A={1,3,5}, P(A)=3/6=0.5, P(1)=1/6
2. union (pravděpodobnost sjednocení)
• prob. of A or B
3. joint (intersection), (průniku)
• prob. of A and B, happens at the same time
4. conditional (podmíněná)
•
P(A|B), “probability of A given B”
5. of complement (doplňku)
P A | B
P( A B)
P B
sum rule
P X P X , Y
Y
P X , Y PY | X P X P X | Y PY
product rule
P(X,Y) – joint probability, “probability of X and at the same time Y”
P(Y|X) – conditional probability, “probability of Y given X”
P(X) – marginal probability, “probability of X”
• Because P(X,Y) = P(Y,X), we immediately
obtain Bayes’ theorem
P X | Y PY
PY | X
P X
P X P X , Y P X | Y PY
Y
Y
Bayes theorem interpretation
• If we had been asked which box had been
chosen before being told the fruit identity, the
most complete information we have available is
provided by the P(B).
– This probability is called prior probability because it is
the probability before observing the fruit.
• Once we’re told that the fruit is an orange, we
used Bayes to compute P(B|F). This probability
is called posterior because it is the probability
after we have observed F.
• Just based on the prior we would say we have
chosen blue box (P(blue)=6/10), however based
on the knowledge of fruit identity we actually
answer red box (P(red|orange)=2/3). This also
agrees with the intuition.
New stuff
Probability distribution
• Now we’ll move away from individual probability
scenarios, look at the situations in which
probabilities follow certain predictable pattern and
can be described by the model.
• probability model – formally, it gives you
formulas to calculate probabilities, determine
average outcomes, and figure the amount of
variability in data
• e.g. probability model helps you to determine the
average number of times you need to play to win
a lottery game
• fundamental parts of probability model:
– random variable
– probability distribution
Random variable
• Not all outcomes of the experiment can be
assigned numerical values (e.g. coin toss,
possible events are “heads” or “tails”).
• But we want to represent outcomes as numbers.
• A random variable (usually denoted as X, Y, Z) is
a rule (i.e. function) that assigns a number to
each outcome of an experiment.
• It is called random, because its value will vary
from trial to trial as the experiment is repeated.
• Two types of random variable (rv):
– discrete – may take on only a countable
number of distinct values such as 0, 1, 2,
3, 4, ...
• example: number of children in a family
– continuous (spojité) – takes an infinite
number of possible values
• example: height, weight, time required to run a
kilometer
Probability distribution
• Once we know something about random
variable X, we need a way how to assign a
probability P(X) to the event – X occurs.
• For discrete rv this function is called
probability mass function (pmf)
(pravděpodobnostní funkce).
• For continuous rv it is called probability
density function (pdf) (hustota pravděpodobnosti,
frekvenční funkce).
pmf
• rolling two dice, take the sum of the
outcomes
probability that X = 2?
1/36 (only {1,1})
X=3
1/36+1/36 ({1,2} and {2,1})
from Probability for Dummies, D. Rumsey
• pmf – it is called mass function, because it
shows how much probability (or mass) is
given to each value of rv
• pdf – continuous rv does not assign
probability (mass), it assigns density, i.e. it
tells you how dense the probability is
around X for any value of X
– you find probabilities for intervals of X, not
particular value of X
– continuous rv’s have no probability at a single
point
• probability distribution (pravděpodobnostní rozdělení,
rozložení, distribuce) – listing of all possible values of
X along with their probabilities
• P(x) is between 0 and 1
• prob X takes value a or b: P(a)+P(b)
• probs must add up to one
These probabilities are assigned by
pmf.
from Probability for Dummies, D. Rumsey
• probability distribution of discrete rv (i.e. its pdf)
can be pictured using relative frequency
histogram
• the shape of histogram is important
from Probability for Dummies, D. Rumsey
• pdf of continuous rv
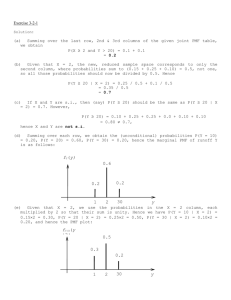
Calculating probabilities from
probability distribution
• two dice-rolling example
• calculate the probability
of these events: sum is
– at least 7
• i.e. P(7≤X≤12)=P(7)+P(8)+…=6/36+5/36+…
– less than 7
– at most 10
– more than 10
• That’s a lot of additions! And again and
again for “less than, at most, …”
• There is a better way – use cummulative
distribution function (cdf) (distribuční funkce)
– it represents the probability that X is less or
equal to the given value a
– and is equal to the sum of all the probabilities for
X that are less or equal to a
F a P X a P X x
xa
cdf for sum of two dice example
X
F(X)
X < 2 0 = 0.00, 0%
X < 3 1/36 = 0.025, 2.9% F(2)
X < 4 1/36 + 2/36 = 8.3% F(3)
X < 5 16.7%
F(4)
X < 6 27.7%
F(5)
X < 7 15/36 = 41.7%
F(6)
X < 8 58.3%
F(7)
X < 9 72.2%
F(8)
X < 10 83.3%
F(9)
X < 11 91.7%
F(10)
X < 12 97.2%
F(11)
X > 12 100%
F(12)
less than 7: P(6)+P(5)+…=42%
cdf is defined on all
values from -Inf to +Inf
F(6) … less than 7
from Probability for Dummies, D. Rumsey
• for continuous rv, cumulative distribution
function (cdf) is the integral of its
probability density function (pdf)
• from pmf you can figure out the long-term
average outcome of a random variable –
expected value
• and the amount of variability you need to
expect from one set set of result to another
– variance (rozptyl)
Expected value
•
•
long-term (infinite number of times)
average value
mathematically – weighted average of all
possible values of X, weighted by how
often you expect each value to occur
E X x P x
all x
•
E(X) is mean of X
1.
2.
3.
•
multiply value of X by its probability
repeat step for all values of X
sum the results
rolling two dice example:
2*1/36 + 3*2/36 + … = 7
from Probability for Dummies, D. Rumsey
• the average sum of two dice is the middle
value between 2 and 12
• however, this is not a case in every problem,
this happened because of the symmetric
nature of pmf
E(X) = 0 * 0.30 + 1 * 0.35 + … = 1.42
• E(X) does not have to be equal to
a possible value of X
from Probability for Dummies, D. Rumsey
Variance of X
•
variance – expected amount of variability
after repeating experiment infinite number
of times
V X 2 E X P x x
2
2
all x
•
weighted average squared distance from
E(X)
1.
2.
3.
4.
5.
Subtract E(X) (i.e. μ) from the value of X
square the difference
multiply by the P(x)
repeat 1-3 for each value of X
sum the results
Standard deviation
• (směrodatná odchylka)
• variance of X is in squared units of X !!
• take the root, and you have standard
deviation
V X
Discrete uniform distribution
• Each probability model has its own name, its
own formulas for pmf and cdf, its own formulas
for expected value and variance
• The most basic is discrete uniform
distribution U(a,b).
• values of X: integers
from a to b (inclusive)
• each value of X has an
equal probability
from Probability for Dummies, D. Rumsey
• pmf
1
P X
ba
• cdf
0, x a
x a
F X
, a x b
b a
1
,
x
b
• expected value
• variance
ba
EX
2
2
b
a
V X 2
12
Statistics
Jargon
• population
– specific group of individuals to be studied
(e.g. all Czech), …
– data collected from the whole population census
• sample (výběr)
– Studying whole population may be impractical
(e.g. whole mankind), so you select smaller
number of individuls from the population.
• representative sample – if you send out a survey
(about time spent on the internet by teenagers) by
e-mail to “all teenagers”, you’re actually excluding
teenagers that don’t have internet access at all
•
random sample (náhodný výběr, vzorek)
– good thing, it gives every member of
population same chance to be chosen
•
bias (zaujatost, upřednostnění, chyba)
– systematic favoritism present in data
collection process
– occurs, because
1. in the way the sample is selected
2. in the way data are collected
• data
– actual measurements
– categorical (gender, political party, etc …),
numerical (measurable values)
• data set
– collection of all the data taken from the
sample
• statistic (výběrová statistika)
– a number that summarizes the data collected
from a sample
– if census is collected, this number is called
parameter (populační parametr), not a statistic
Means, medians and more
• statistic summarizes some characteristic
od data
• why to summarize?
– clear, consise number(s) that can be easily
reported and understood even by people less
intelligent than you (e.g. your boss or teacher)
– they help researchers to make a sense of
data (they help formulate or test claims made
about the population, estimate characteristics
of the population, etc.)
Summarizing categorical data
• reporting percentage of individuals falling
into each category
– e.g. survey of 2 000 teenagers included 1 200
females and 800 males, thus 60% females
and 40% males
– crosstabs (two-way tables)
• tables with rows and columns
• they summarize the information from two
categorical variables at once (e.g. gender and
political party – what is the percentage of ODS
females, etc.)
Summarizing numerical data
• the most common way of summarizing
– where the center is (i.e. what’s a typical value)
– how spread the data are
– where certain milestones are
Getting centered
• average, mean x
– sum all the numbers in data set
– divide by the size of data set n
• this is the sample mean, and the population
mean is μ
• however, average is a perfidious bitch
• a few large/small values (outliers) (odlehlé body)
greatly influence the average
– e.g. avg(x) of 2,3,2,2,500 is cca 100
– or averge salary at VŠCHT is 38 000,- (he, he, he)
• in these cases more appropriate is a median
– order the data set from smallest to largest
– median is the value exactly in the middle (e.g.
2,3,2,2,500 → 2,2,2,3,500 → median is 2)
– if the numer of data points is even, take the
average of two values in the middle (e.g.
2,3,2,500 → 2,2,3,500 → median is (2+3)/2 =
2.5)
• Statistic which is not influenced by outliers is
called robust statistic.
skewed (zešikmené) to the right
50% of data lie below the median,
50% above
skewed to the left
symmetric data: median = mean
skewed to the right: mean > median
skewed to the left: mean < median
symmetric
from Statistics for Dummies, D. Rumsey