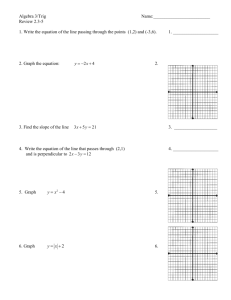
Computational Geometry and Spatial Data Mining
advertisement

Computational Geometry and Spatial Data Mining Marc van Kreveld Department of Information and Computing Sciences Utrecht University Two-part presentation • Morning: Introduction to computational geometry with examples from spatial data mining • Afternoon: Geometric algorithms for spatial data mining (and spatio-temporal data mining) Spatial data mining and computation • “Geographic data mining involves the application of computational tools to reveal interesting patterns in objects and events distributed in geographic space and across time” (Miller & Han, 2001) [ data analysis ? ] • Large data sets attempt to carefully define interesting patterns (to avoid finding non-interesting patterns) advanced algorithms needed for efficiency Introduction to CG • Some words on algorithms and efficiency • Computational geometry algorithms through examples from spatial data mining – Voronoi diagrams and clustering – Arrangements and largest clusters – Approximation for the largest cluster Algorithms and efficiency • You may know it all already: • Please look bored if you know all of this • Please look bewildered if you haven’t got a clue what I’m talking about Algorithms • Computational problems have an input size, denoted by n – A set of n numbers – A set of n points in the plane (2n coordinates) – A simple polygon with n vertices – A planar subdivision with n vertices • A computational problem defines desired output in terms of the input Algorithms • Examples of computational problems: – Given a set of n numbers, put them in sorted order – Given a set of n points, find the two that are closest – Given a simple polygon P with n vertices and a point q, determine if q is inside P P q Algorithms • An algorithm is a scheme (sequence of steps) that always gives the desired output from the given input • An algorithm solves a computational problem • An algorithm is the basis of an implementation Algorithms • An algorithm can be analyzed for its running time efficiency • Efficiency is expressed using O(..) notation, it gives the scaling behavior of the algorithm – O(n) time: the running time doubles (roughly) if the input size doubles – O(n2) time: the running time quadruples (roughly) if the input size doubles Algorithms • Why big-Oh notation? – Because it is machine-independent – Because it is programming languageindependent – Because it is compiler-independent unlike running time in seconds It is only algorithm/method-dependent Algorithms • Algorithms research is concerned with determining the most efficient algorithm for each computational problem – Until ~1978: O(n2) time – Until 1990: O(n log n) time – Now: O(n) time } polygon triangulation Algorithms • For some problems, efficient algorithms are unknown to exist • Approximation algorithms may be an option. E.g. TSP – Exact: exponential time – 2-approx: O(n log n) time – 1.5-approx: O(n3) time – (1+)-approx: O(n1/) time Voronoi diagrams and clustering • A Voronoi diagram stores proximity among points in a set Voronoi diagrams and clustering • Single-link clustering attempts to maximize the distance between any two points in different sets Voronoi diagrams and clustering Voronoi diagrams and clustering Voronoi diagrams and clustering • Algorithm (point set P; desired: k clusters): – Compute Voronoi diagram of P – Take all O(n) neighbors and sort by distance – While #clusters > k do • Take nearest neighbor pair p and q • If they are in different clusters, then merge them and decrement #clusters (else, do nothing) Voronoi diagrams and clustering • Analysis; n points in P: – Compute Voronoi diagram: O(n log n) time – Sort by distance: O(n log n) time – While loop that merges clusters: O(n log n) time (using union-find structure) • Total: O(n log n) + O(n log n) + O(n log n) = O(n log n) time Voronoi diagrams and clustering • What would an “easy” algorithm have given? – really easy: O(n3) time – slightly less easy: O(n2 log n) time n3 time 10 n2 log n 1000 n log n 100 200 300 Computing Voronoi diagrams • By plane sweep • By randomized incremental construction • By divide-and-conquer all give O(n log n) time Computing Voronoi diagrams • Study the geometry, find properties – 3-point empty circle Voronoi vertex – 2-point empty circle Voronoi edge Computing Voronoi diagrams • Some geometric properties are needed, regardless of the computational approach • Other geometric properties are only needed for some approach Computing Voronoi diagrams • Fortune’s sweep line algorithm (1987) – An imaginary line moves from left to right – The Voronoi diagram is computed while the known space expands (left of the line) Computing Voronoi diagrams • Beach line: boundary between known and unknown sequence of parabolic arcs – Geometric property: beach line is y-monotone it can be stored in a balanced binary tree Computing Voronoi diagrams • Events: changes to the beach line = discovery of Voronoi diagram features – Point events Computing Voronoi diagrams • Events: changes to the beach line = discovery of Voronoi diagram features – Point events Computing Voronoi diagrams • Events: changes to the beach line = discovery of Voronoi diagram features – Circle events Computing Voronoi diagrams • Events: changes to the beach line = discovery of Voronoi diagram features – Circle events Computing Voronoi diagrams • Events: changes to the beach line = discovery of Voronoi diagram features – Only point events and circle events exist Computing Voronoi diagrams • For n points, there are – n point events – at most 2n circle events Computing Voronoi diagrams • Handling an event takes O(log n) time due to the balanced binary tree that stores the beach line in total O(n log n) time Intermediate summary • Voronoi diagrams are useful for clustering (among many other things) • Voronoi diagrams can be computed efficiently in the plane, in O(n log n) time • The approach is plane sweep (by Fortune) Figures from the on-line animation of Allan Odgaard & Benny Kjær Nielsen Arrangements and largest clusters • Suppose we want to identify the largest subset of points that is in some small region – formalize “region” to circle – formalize “small’’ to radius r Place circle to maximize point containment r Arrangements and largest clusters • Bad idea: Try m = 1, 2, ... and test every subset of size m • Not so bad idea: for every 3 points, compute the smallest enclosing circle, test the radius and test the other points for being inside Arrangements and largest clusters • Bad idea analysis: A set of n points has roughly ( mn ) = O(nm) subsets of size m • Not so bad idea analysis: n points give ( n3 ) = O(n3) triples of points. Each can be tested in O(n) time O(n4) time algorithm Arrangements and largest clusters • The placement space of circles of radius r C p A circle C of radius r contains a point p if and only if the center of C lies inside a circle of radius r centered at p Arrangements and largest clusters • The placement space of circles of radius r Circles with center here contain 2 points of P Circles with center here contain 3 points of P Arrangements and largest clusters • Maximum point containment is obtained for circles whose center lies in the most covered cell of the placement space Computing the most covered cell • Compute the circle arrangement in a topological data structure • Fill the cells by the cover value by traversal of the arrangement 1 0 1 2 1 2 3 1 The value to be assigned to a cell is +/- 1 of its (known) neighbor Computing the most covered cell • Compute the circle arrangement: – by plane sweep: O(n log n + k log n) time – by randomized incremental construction in O(n log n + k) time where k is the complexity of the arrangement; k = O(n2) If the maximum coverage is denoted m, then k = O(nm) and the running time is O(n log n + nm) Computing the most covered cell • Randomized incremental construction: – Put circles in random order – “Glue” them into the topological structure for the arrangement with vertical extensions Every cell has ≤ 4 sides (2 vertical and 2 circular) Computing the most covered cell Every cell has ≤ 4 sides (2 vertical and 2 circular) Trace a new circle from its leftmost point to glue it into the arrangement the exit from any cell can be determined in O(1) time Computing the most covered cell • Randomized analysis can show that adding one circle C takes O(log n + k’ ) time, where k’ is the number of intersections with C • The whole algorithm takes O(n log n + k) time, where k = k’ is the arrangement size • The O(n + k) vertical extensions can be removed in O(n + k) time Computing the most covered cell • Traverse the arrangement (e.g., depth-first search) to fill the cover numbers in O(n + k) time • into a circle +1 • out of a circle -1 Intermediate summary • The largest cluster for a circle of radius r can be computed in O(n log n + nm) time if it has m entities • We use arrangement construction and traversal • The technique for arrangement construction is randomized incremental construction (Mulmuley, 1990) Largest cluster for approximate radius • Suppose the specified radius r for a cluster is not so strict, e.g. it may be 10% larger Place circle to maximize point containment r (1+) r If the largest cluster of radius r has m entities, we must guarantee to find a cluster of m entities and radius (1+) r Approximate radius clustering • The idea: snap the entity locations to grid points of a well-chosen grid Snapping should not move points too much: less than r /4 grid spacing r /4 works Approximate radius clustering • The idea: snap the entity locations to grid points of a well-chosen grid 1 1 1 1 2 2 1 1 1 2 2 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 For each grid point, collect and add the count of all grid points within distance (1+/2) r Approximate radius clustering • The idea: snap the entity locations to grid points of a well-chosen grid 1 1 1 1 2 2 1 1 1 2 2 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 For each grid point, collect and add the count of all grid points within distance (1+/2) r 1 Collected count = 10 Approximate radius clustering • The idea: snap the entity locations to grid points of a well-chosen grid 1 1 1 2 1 2 1 1 1 1 1 1 8 92 110 6 1 1 2 1 1 1 1 1 1 1 2 1 1 1 1 For each grid point, collect and add the count of all grid points within distance (1+/2) r Approximate radius clustering • Claim: a largest approximate radius cluster is given by the highest count 1 1 1 2 1 2 1 1 1 1 1 1 8 92 110 6 1 1 2 1 1 1 1 1 1 1 2 1 1 1 1 Approximate radius clustering • Let Copt be a radius-r circle with the most entities inside • Due to the grid spacing, we have a grid point within distance r /4 from the center of Copt that must have a count Approximate radius clustering • Snapping moves entities at most r /4 • C and Copt differ in radius r /2 no point in Copt can have moved outside C • Snapped points inside C have their origins inside a circle of radius at most (1+) r no points too far from C can have entered C Approximate radius clustering • Intuition: We use the in different places – Snapping points – Trying only circle centers on grid points ... and we guarantee to test a circle that contains all entities in the optimal circle, but not other entities too far away Approximate radius clustering • Efficiency analysis – n entities: each gives a count to O(1/2) grid cells – in O(n /2) time we have all collected counts and hence the largest count Exact or approximate? • O(n log n + nm) versus O(n /2) time • In practice: What is larger: m or 1 /2 ? – If the largest cluster is expected to be fairly small, then the exact algorithm is fine – If the largest cluster may be large and we don’t care about the precise radius, the approximate radius algorithm is better Concluding this session • Basic computational geometry ... Voronoi diagrams, arrangements, -approximation techniques ... is already useful for spatial data mining • Afternoon: spatial and spatio-temporal data mining and more geometric algorithms