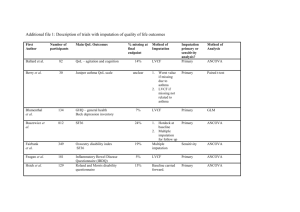
3. Application of ANCOVA
advertisement

Group 4
AMS 572
Table of Contents
1. Introduction and History
1.1 Part 1: Ahram Woo
1.2 Part 2: Jingwen Zhu
2. Theoretical Background
2.1 Part 1: Xin Yu
2.2 Part 2: Unjung Lee
3. Application of ANCOVA and Summary
3.1 Part 1: Xiaojuan Shang
3.2 Part 2: Younga Choi
3.3 Part 3: Qiao Zhang
1. Introduction and History
Group 4
by Ahram Woo
1. Introduction and History
Individual
by Ahram Woo
Xin Yu
Ahram Woo
Unjung Lee
Jingwen Zhu
Qiao Zhang
Xiaojuan Shang
Younga Choi
1. Introduction and History
1.1 Introduction to ANCOVA
by Ahram Woo
• Analysis of covariance : An extension of
ANOVA in which main effects and
interactions are assessed on Dependent
Variable(DV) scores after the DV has been
adjusted for by the DV’s relationship with one
or more Covariates (CVs)
• ANCOVA = ANOVA + Linear Regression
1. Introduction and History
1.1 Introduction to ANCOVA
• R.A. Fisher who is credited with
the introduction of ANCOVA
"Studies in crop variation. IV. The
experimental determination of
the value of top dressings with
cereals" published in Journal of
Agricultural Science, vol. 17, 548562. The paper was published in
1927.
by Ahram Woo
1. Introduction and History
1.1 Introduction to ANCOVA
by Ahram Woo
• ANOVA is described by R. A. Fisher to assist in
the analysis of data from agricultural
experiments.
• ANOVA compare the means of any number of
experimental conditions without any increase
in Type 1 error.
• ANOVA is a way of determining whether the
average scores of groups differed significantly.
1. Introduction and History
1.2 Introduction to Linear Regression
by Jingwen Zhu
Model the relationship between
explanatory and dependent variables by
fitting a linear equation to observed data.
(i.e. Y = a + bX)
There is a relationship or not ?
One variable causes the other?
Scatter Plot & Correlation Coefficient
1. Introduction and History
1.2 Introduction to Linear Regression
by Jingwen Zhu
The term “ regression” was first studied in d
epth by 19th-century scientist,
.
Geographer
Psychologist
Statistician
Meteorologist
Eugenicist
1. Introduction and History
1.2 Introduction to Linear Regression
by Jingwen Zhu
Galton studied data on relative heights of fathers
and their sons
Conclusions:
A taller-than-average father tends to produce
a taller-than-average son
The son is likely to be less tall than the father in
terms of his relative position within his own
population
1. Introduction and History
1.2 Introduction to Linear Regression
by Jingwen Zhu
ANCOVA is a merger of ANOVA and
regression.
ANCOVA allows to compare one variable in 2
or more groups taking into account (or to
correct for) variability of other variables, called
covariates.
The inclusion of covariates can increase
statistical power because it accounts for some
of the variability
1. Introduction and History
1.2 Introduction to Linear Regression
by Jingwen Zhu
Example: whether MCAT scores are significantly
different among medical students who had
different types of undergraduate majors, when
adjusted for year of matriculation?
•Dependent variable (continuous)
MCAT total (most recent)
•Fixed factor (categorical variables)
Undergraduate major
• 1 = Biology/Chemistry
• 2 = Other science/health
• 3 = Other
•Covariate
Year of matriculation
1. Introduction and History
1.2 Introduction to One-way Analysis of Variance
by Jingwen Zhu
One factor of k levels or groups. E.g., 3
treatment groups in a drug study.
The main objective is to examine the equality of
means of different groups.
Total variation of observations (SST) can be split
in two components: variation between groups
(SSA) and variation within groups (SSE).
1. Introduction and History
1.2 Introduction to One-way Analysis of Variance
by Jingwen Zhu
Consider a layout of a study with 16 subjects
that intended to compare 4 treatment
groups (G1-G4). Each group contains four
subjects.
G1
G2
G3
G4
S1
Y11
Y21
Y31
Y41
S2
Y12
Y22
Y32
Y42
S3
Y13
Y23
Y33
Y43
S4
Y14
Y24
Y34
Y44
1. Introduction and History
1.2 Introduction to One-way Analysis of Variance
by Jingwen Zhu
Model:
yij = m + ai + eij , where, i = 1, 2.....a; j = 1, 2.....n
where, yij is the ith observation of jth group,
ai is the effect of ith group,
m is the general mean and eij is the error.
Assumptions:
– Observations yij are independent.
– e ij are normally distributed with mean
zero and constant standard deviation.
1. Introduction and History
1.2 Introduction to One-way Analysis of Variance
by Jingwen Zhu
Hypothesis
Ho: Means of all groups are equal.
Ha: At least one of them is not equal to
other.
ANOVA Table
Source of
Variance
Sum of
Squares
Degree of
Freedom
Mean
Square
F
Treatment
SSA
a-1
SSA/(a-1)
MSA/MSE
Error
SSE
N-a
SSE/(N-a)
Total
SST
N-1
1. Introduction and History
1.2 Introduction to One-way Analysis of Variance
by Jingwen Zhu
SSA (Variation between groups) is due to
the difference in different groups. E.g.
different treatment groups or different
doses of the same treatment.
a
SSA = nå (yi - y. )2
i=1
a
n
åå y
ij
y. =
i=1 j=1
N
1. Introduction and History
1.2 Introduction to One-way Analysis of Variance
by Jingwen Zhu
Treatment
1
2
….
a
y21
….
ya1
y12
y22
….
ya2
….
….
….
….
y1n1
y2n2
y11
SAMPLE
MEAN
yana
….
y1
y2
ya
1. Introduction and History
1.2 Introduction to One-way Analysis of Variance
by Jingwen Zhu
SSE (Variation within groups) is the inherent
variation among the observations within
each group.
a
ni
SSE = åå(yij - yi )2
i=1 j=1
SSE
s = MSE =
N -a
2
1. Introduction and History
1.2 Introduction to One-way Analysis of Variance
by Jingwen Zhu
Treatment
Sample
Mean
1
2
….
a
y11
y21
….
ya1
y12
y22
….
ya2
….
….
….
….
y1n
y2n
....
yan
y1
y2
….
ya
1. Introduction and History
1.2 Introduction to One-way Analysis of Variance
• SST (SUM SQUARE OF TOTAL) is the
combination of SSE and SSA
a
n
SST = åå(yij - y. )2
i=1 j=1
SST = SSE + SSA
by Jingwen Zhu
2. Theoretical Background
2.1 Model of ANOVA
Y
Data, the
jth
observatio
ij
by Xin Yu
u
Grand
mean of Y
i
ij
Error N(0, σ ^2)
n of the ith
Effects of the jth group(we mainly
group
focus on when ai=0,i=1, …,a )
2. Theoretical Background
2.1 Model of Linear Regression
Data, the
(ij)th
observation
Predictor
by Xin Yu
Error
Slope and Intersect (we mainly
focus on the estimate)
2. Theoretical Background
2.1 ANCOVA: ANOVA Merged With Linear Regression
Y u ( X
ij
i
Effects of the ith
group (We still
focus on if ai=0,
i=1,… ,a)
ij
by Xin Yu
X ..) ij
Known covariance
2. Theoretical Background
2.1 How to Perform ANCOVA
Y u a (X
ij
i
~
Y
ij
by Xin Yu
ij
X ..) ij
(adjust ) Y ij ˆ ( X ij X ..)
ANOVA Model!
2. Theoretical Background
2.1 How do we get
Y
ij
i ( X ij X ..) ij
Within each group, consider ai as a
constant, and notice that we actually
only desire the estimate of slope β
instead of intersect.
by Xin Yu
2. Theoretical Background
2.1 How do we get
(continue)
by Xin Yu
(*)Within each group, do Least Square:
(*)Assume that β1=…=βi=…=βa
(*)Which means that αi and β are independent; Or,
Covariate has nothing to do with group effect
2. Theoretical Background
2.1 How do we get
(continue)
We use POOLED ESTIMATE of β
by Xin Yu
2. Theoretical Background
2.1 Model of ANOVA
by Xin Yu
2. Theoretical Background
2.2.A The Simple Linear Regression Model
by Unjung Lee
Y = β0 + β1 X+ ε
Y : dependent (response) variable
X : independent (predictor) variable
β0 : the intercept
β1 : the slope
ε : error term ~ N(0,σ2)
E(Y) = β0 + β1X
2. Theoretical Background
2.2.A The Simple Linear Regression Model
by Unjung Lee
Y
E(Y) =β0 + β1 x
y
Error:
} β = Slope
}
{
1
1
β0 = Intercept
X
2. Theoretical Background
2.2.A The Simple Linear Regression Model
Y
E(Y) =β0 + β1 x
y
N(y|x, sy|x2)
Identical normal distrib
utions of errors, all cent
ered on the regression
line.
by Unjung Lee
2. Theoretical Background
2.2.A Assumptions of simple linear regression model
by Unjung Lee
The relationship between X and Y is the strai
ght-line relationship.
X and Y has a common variance σ2 .
Error is normally distributed.
Error is independent.
2. Theoretical Background
2.2.A The least squares(LS) method
by Unjung Lee
2. Theoretical Background
2.2.A The least squares(LS) method
by Unjung Lee
The fitted values and residuals
We can get these ones with the nor
mal equations
2. Theoretical Background
2.2.A Fitting a Regression Line
Y
by Unjung Lee
Y
Data
Three errors from the le
ast squares regression li
ne
X
X
Y
e
Three errors fro
m a fitted line
X
Errors from the least s
quares regression line
are minimized
X
2. Theoretical Background
2.2.A Errors in Regression
by Unjung Lee
Y
yˆ a bx
.
yi
Error ei yi yˆi
yˆi
the fitted regression line
{
yˆ
the predicted value of Y for x
X
xi
2. Theoretical Background
2.2.A Multiple linear regression
by Unjung Lee
A statistical model that utilizes two or more q
uantitative and qualitative explanatory varia
bles (x1,..., xp) to predict a quantitative depe
ndent variable Y.
Caution: have at least two or more quantitati
ve explanatory variables (rule of thumb)
2. Theoretical Background
2.2.A Dummy-Variable Regression Model
by Unjung Lee
• Involves categorical X variable with
two levels
– e.g., female-male, employed-not emp
loyed, etc.
• Variable levels coded 0 & 1
• Assumes only intercept is different
– Slopes are constant across categories
2. Theoretical Background
2.2.A Dummy-Variable Model Relationships
Y
by Unjung Lee
Same slopes b1
Females
b0 + b2
b0
Males
0
0
X1
2. Theoretical Background
2.2.A Dummy Variables
by Unjung Lee
• Permits use of qualitative data
(e.g.: seasonal, class standing, location, gender)
.
• 0, 1 coding (nominative data)
• As part of Diagnostic Checking;
incorporate outliers
(i.e.: large residuals)
and influence
easures.
m
2. Theoretical Background
2.2.A Interaction Regression Model
by Unjung Lee
• Hypothesizes interaction between pairs of X vari
ables
– Response to one X variable varies at different
levels of another X variable
• Contains two-way cross product terms
Y = 0 + 1x1 + 2x2 + 3x1x2 +
• Can be combined with other models
e.g. dummy variable models
2. Theoretical Background
2.2.A Effect of Interaction
by Unjung Lee
• Given:
Yi 0 1X 1i 2 X 2i 3 X 1i X 2i i
• Without interaction term, effect of X1 on Y is me
asured by β1
• With interaction term, effect of X1 on
Y is measured by β1 + β3X2
– Effect increases as X2i increases
2. Theoretical Background
2.2.A Interaction Example
Y
by Unjung Lee
Y = 1 + 2X1 + 3X2 + 4X1X2
Y = 1 + 2X1 + 3(1) + 4X1(1) = 4 + 6X1
12
8
Y = 1 + 2X1 + 3(0) + 4X1(0) = 1 + 2X1
4
0
0
0.5
1
1.5
X1
Effect (slope) of X1 on Y does depend on X2 value
2. Theoretical Background
2.2.A The two-way ANOVA
by Unjung Lee
2. Theoretical Background
2.2.A The two-way ANOVA table
by Unjung Lee
sourse
df
ss
Ms
Factor A
a-1
SS(A)
Factor B
b-1
SS(B)
MS(A) =
SS(A)/(a-1)
MS(B) =
SS(B)/(b-1)
Intersection AB (a-1)(b-1)
SS(AB)
MS(AB)=
SS(AB)/(a1)(b-1)
Error
ab(r-1)
SSE
SSE/ab(r-1)
Total
abr-1
SS(Total)
2. Theoretical Background
2.2.A Test homogeneity of variance
by Unjung Lee
2. Theoretical Background
2.2.B Test Whether Ho:
by Xin Yu
2. Theoretical Background
2.2.B Test Whether Ho:
by Xin Yu
a
SSE G SSEi
i 1
̂
i
2. Theoretical Background
2.2.B Test Whether Ho:
(2) SSE is generated by
(*) Random Error ε
ˆ
(*)Difference between distinct
i
we can calculate SSE based on a common ˆ i
(3) Let SSA=SSESSA
Sum of Square between Groups
SSA is constituted by the difference between differ
ent β i
by Xin Yu
2. Theoretical Background
2.2.B Test Whether Ho:
df
a
G
df df
e
SSA
e
MSA df
SSE
MSA
df
a
G
G
by Xin Yu
[ a ( n 1) 1] a ( n 2) a 1
SSA
a 1
G
SSE
G
a ( n 2)
e
MSA
Mean Square between Groups
Mean Square within Groups
Do F test on MSA and
to see whether we can
reject our Ho
F= MSA/
2. Theoretical Background
2.2.C Test Linear Relationship
Assumption 3:
Test a linear relationship between the dependent
variable and covariate.
Ho: β=0
How to do it next?
Use F test on SSR and SSE
S um of
S quare of
R egres s ion
by Xin Yu
2. Theoretical Background
2.2.C Test Linear Relationship
by Xin Yu
How to calculate SSR and MSR?
From each
SST is the difference obtained from the sum
mation of the square of the
differences between and y
..
an
ni
22
SST
(
y
y
)
SSR
( yˆ ij y. )
i 1 j 1
i 1
i
MSR SSR /1
2. Theoretical Background
2.2.C Test Linear Relationship
How to calculate SSE and MSE?
From each
by Xin Yu
yˆ
i
SSE is the error obtained from the summation of th
e square of the differences between and
a
ni
SSE ( yij yi ) 2
i 1 j 1
SSE
MSE
(n a)
2. Theoretical Background
2.2.C Test Linear Relationship
MSR
F
MSE
Based on the T.S. we determine whether to
accept Ho(β=0) or not.
Assume Assumption 1 and 2 are already passed.
(*)If H0 is true (β=0), we do ANOVA.
(*)Otherwise, we do ANCOVA
So, anytime we want to use ANCOVA, we need to
test the three assumptions first!
by Xin Yu
3. Application of ANCOVA
3.1 Case Introduction
by Xiaojuan Shang
Analysis of covariance (ANCOVA) is a statistical
procedure that allows you to include both cate
gorical and continuous variables in a single mod
el. ANCOVA assumes that the regression coeffici
ents are homogeneous (the same) across the c
ategorical variable. Violation of this assumption
can lead to incorrect conclusions
3. Application of ANCOVA
3.1 Case Introduction
by Xiaojuan Shang
Here is an example data file we will use. It conta
ins 30 subjects who used one of three diets, diet
1 (diet=1), diet 2 (diet=2) and a control group (d
iet=3). Before the start of the study, the height of
the subject was measured, and after the study t
he weight of the subject was measured.
3. Application of ANCOVA
3.1 Data Structure
by Xiaojuan Shang
3. Application of ANCOVA
3.1 Case Concerns
by Xiaojuan Shang
• Difference between three diet groups
• Correlation between height and weight
• Difference between control group and the oth
er two groups
3. Application of ANCOVA
3.1 Case Data: Compare with ANOVA
by Xiaojuan Shang
PROC GLM DATA=htwt;
CLASS diet ;
MODEL weight = diet ;
MEANS diet / deponly ;
CONTRAST 'compare 1&2 with control' diet 1 1 -2 ;
CONTRAST 'compare diet 1 with 2 ' diet 1 -1 0 ;
RUN;
QUIT;
3. Application of ANCOVA
3.1 Case Data: Compare with ANOVA
by Xiaojuan Shang
3. Application of ANCOVA
3.1 Case Data: Compare with ANOVA
by Xiaojuan Shang
3. Application of ANCOVA
3.2 SAS Codes for ANCOVA model: Outline
by Younga Choi
1. Description of data
2. Investigation of equality of slope for the grou
ps through traditional ANOVA model (homog
eneity of regression assumption)
3. When homogeneity of assumption is violated
examination on the effect of the group va
riable
(diet group) at different levels of the covariat
e
(height levels).
3. Application of ANCOVA
3.2 Data Description
by Younga Choi
•N= 30
•IV:
(1)Diet (three levels)
- diet 1 (diet=1, n=10)
- diet 2 (diet=2, n=10)
- diet 3, control group, (diet=3, n=10)
(2) Height
•DV: weight of the subject was measured after
the study
3. Application of ANCOVA
3.2 Reading the Data & Traditional ANCOVA model
Comparing
means of
diet groups
by Younga Choi
3. Application of ANCOVA
3.2 Homogeneity of Regression Assumption
by Younga Choi
Checking on the Homogeneity of Regression Assumption:
3. Application of ANCOVA
3.2 Homogeneity of Regression Assumption
by Younga Choi
Checking on the Homogeneity of Regression Assumption:
Pairwise Comparisons
3. Application of ANCOVA
3.2 Homogeneity of Regression Assumption
by Younga Choi
When the Homogeneity of Regression Assumption is Violated
3. Application of ANCOVA
3.2 Homogeneity of Regression Assumption
by Younga Choi
Comparing Slope of Diet1 and Diet2 and Diet3 Combined
3. Application of ANCOVA
3.2 Homogeneity of Regression Assumption
by Younga Choi
3. Application of ANCOVA
3.2 Homogeneity of Regression Assumption
by Younga Choi
Overall mean
value of height
3. Application of ANCOVA
3.3 SAS Output- One Way ANOVA Model
by Qiao Zhang
3. Application of ANCOVA
3.3 Standard ANCOVA Model
by Qiao Zhang
The results are consistent with those of the ANOVA
3. Application of ANCOVA
3.3 Assumptions (Homogenity of Regresion)
by Qiao Zhang
3. Application of ANCOVA
3.3 Assumptions (Homogenity of Regresion)
by Qiao Zhang
Diet=1
Dependent Variable: weight
Diet=2
Dependent Variable: weight
Diet=3
Dependent Variable: weight
There is significant linear relationship between wei
ght and height in both diet 2 and diet 3 group, but
not in diet 1 group.
3. Application of ANCOVA
3.3 Assumptions (Homogenity of Regresion)
by Qiao Zhang
The diet*height effect is indeed significant, indicat
ing that the slopes do differ across the three diet g
roups.
3. Application of ANCOVA
3.3 Tests : Comparing diet 1 with diet 2
by Qiao Zhang
These results indicate a significant difference betwee
n diet 1 and diet 2 for those 59 inches tall, and a signi
ficant difference for those 64 inches tall. For those w
ho are tall (i.e., 68 inches), diet 1 and diet 2 are abo
ut equally effective.
3. Application of ANCOVA
3.3 Comparing diets 1 and 2 to the control group
by Qiao Zhang
The difference in weight between diet groups 1 an
d 2 combined and the control group is significant
at different heights.
3. Application of ANCOVA
3.3 Testing to pool slopes
by Qiao Zhang
The test comparing the slopes of diet group 1 vers
us 2 and 3 was significant, and the test comparing
the slopes for diet groups 2 versus 3 was not signif
icant.
We can combine slopes for diet group 2 and 3.
3. Application of ANCOVA
3.3 Overall analysis: diet groups 2 and 3
Pooled slopes model
Unpooled slopes model
by Qiao Zhang
3. Application of ANCOVA
3.3 Overall analysis
by Qiao Zhang
3. Application of ANCOVA
3.3 Summary of Outputs
by Qiao Zhang
• The homogeneity of regression assumption is viol
ated in this data set.
• We then estimated models that have separate s
lopes across groups.
• When comparing the control group to diets 1 a
nd 2, we found the control group weighed mor
e at 3 different levels of height (59 inches, 64 inc
hes and 68 inches).
• When we comparing diets 1 and 2, we found di
et 2 to be more effective at 59 and 64 inches, b
ut there was no difference at 68 inches.