EECC550 - Shaaban
advertisement

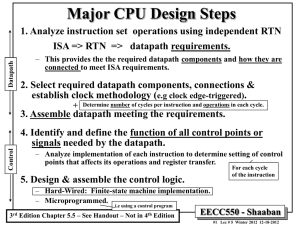
CPU Design Steps 1. Analyze instruction set operations using independent RTN => datapath requirements. 2. Select set of datapath components & establish clock methodology. 3. Assemble datapath meeting the requirements. 4. Analyze implementation of each instruction to determine setting of control points that effects the register transfer. 5. Assemble the control logic. EECC550 - Shaaban #1 Lec # 5 Winter 2000 12-20-2000 CPU Design & Implantation Process • Bottom-up Design: – Assemble components in target technology to establish critical timing. • Top-down Design: – Specify component behavior from high-level requirements. • Iterative refinement: – Establish a partial solution, expand and improve. Instruction Set Architecture => processor datapath Reg. File Mux ALU control Reg Cells Mem Decoder Sequencer Gates EECC550 - Shaaban #2 Lec # 5 Winter 2000 12-20-2000 Single Cycle MIPS Datapath: 4 Rd Imm16 RegDst ALUctr MemWr Equal Rd Rt 0 1 32 imm16 16 0 1 32 Data In 32 Clk 32 0 Mux 00 Clk Extender Clk = 32 ALU busW Mux PC Mux Adder Rs Rt 5 5 busA Rw Ra Rb 32 32-bit Registers busB 32 MemtoReg RegWr 5 Adder PC Ext imm16 Rt Instruction<31:0> <0:15> Rs <11:15> Adr nPC_sel <16:20> <21:25> Inst Memory CPI = 1, Long Clock Cycle WrEn Adr 1 Data Memory ExtOp ALUSrc EECC550 - Shaaban #3 Lec # 5 Winter 2000 12-20-2000 Drawback of Single Cycle Processor • Long cycle time. • All instructions must take as much time as the slowest: – Cycle time for load is longer than needed for all other instructions. • Real memory is not as well-behaved as idealized memory – Cannot always complete data access in one (short) cycle. EECC550 - Shaaban #4 Lec # 5 Winter 2000 12-20-2000 ALU Reg. Wrt Result Store Data Mem MemWr RegDst RegWr MemRd MemWr fun Mem Access ExtOp ALUSrc ALUctr Equal op Ext Register Fetch Instruction Fetch PC Next PC nPC_sel Abstract View of Single Cycle CPU Main Control ALU control EECC550 - Shaaban #5 Lec # 5 Winter 2000 12-20-2000 Single Cycle Instruction Timing Arithmetic & Logical PC Inst Memory Reg File mux ALU mux setup Load PC Inst Memory mux Reg File Critical Path ALU Data Mem Store PC Inst Memory Reg File ALU Data Mem Branch PC Inst Memory Reg File mux cmp mux setup mux EECC550 - Shaaban #6 Lec # 5 Winter 2000 12-20-2000 Reducing Cycle Time: Multi-Cycle Design • Cut combinational dependency graph by inserting registers / latches. • The same work is done in two or more fast cycles, rather than one slow cycle. storage element storage element Acyclic Combinational Logic (A) Acyclic Combinational Logic => storage element storage element Acyclic Combinational Logic (B) storage element EECC550 - Shaaban #7 Lec # 5 Winter 2000 12-20-2000 Clock Cycle Time & Critical Path Clk . . . . . . . . . . . . • Critical path: the slowest path between any two storage devices • Cycle time is a function of the critical path • must be greater than: – Clock-to-Q + Longest Path through the Combination Logic + Setup EECC550 - Shaaban #8 Lec # 5 Winter 2000 12-20-2000 Instruction Processing Cycles Instruction Obtain instruction from program storage Fetch Next Update program counter to address Instruction of next instruction Instruction Determine instruction type Decode Obtain operands from registers Execute Compute result value or status Result Store result in register/memory if needed Store (usually called Write Back). } Common steps for all instructions EECC550 - Shaaban #9 Lec # 5 Winter 2000 12-20-2000 Partitioning The Single Cycle Datapath Result Store MemWr MemRd MemWr RegDst RegWr Reg. File Data Mem Exec Mem Access ALUctr ALUSrc ExtOp Operand Fetch Instruction Fetch PC Next PC nPC_sel Add registers between smallest steps EECC550 - Shaaban #10 Lec # 5 Winter 2000 12-20-2000 B MemToReg MemRd MemWr ALUSrc ALUctr R RegDst Reg. RegWr File Equal A Mem Acces s Reg File Ext ALU ExtOp IR PC Result Store Data Mem Operand Fetch M Instruction Fetch Next PC nPC_sel Example Multi-cycle Datapath Registers added: IR: Instruction register A, B: Two registers to hold operands read from register file. R: or ALUOut, holds the output of the ALU M: or Memory data register (MDR) to hold data read from data memory EECC550 - Shaaban #11 Lec # 5 Winter 2000 12-20-2000 Operations In Each Cycle R-Type Logic Immediate Load Store Branch Instruction Fetch IR Mem[PC] IR Mem[PC] IR Mem[PC] IR Mem[PC] Instruction Decode A R[rs] A R[rs] A R[rs] A R[rs] A B R[rt] B R[rt] B R[rt] IR Mem[PC] R[rs] If Equal = 1 PC PC + 4 + Execution R A + B R A OR ZeroExt[imm16] R A + SignEx(Im16) R A + SignEx(Im16) (SignExt(imm16) x4) else PC PC + 4 Memory M Mem[R] Mem[R] B PC PC + 4 Write Back M R[rd] R R[rt] R R[rd] PC PC + 4 PC PC + 4 PC PC + 4 EECC550 - Shaaban #12 Lec # 5 Winter 2000 12-20-2000 Finite State Machine (FSM) Control Model • State specifies control points for Register Transfer. • Transfer occurs upon exiting state (same falling edge). inputs (conditions) Next State Logic State X Control State Register Transfer Control Points Depends on Input Output Logic outputs (control points) EECC550 - Shaaban #13 Lec # 5 Winter 2000 12-20-2000 Control Specification For Multi-cycle CPU Finite State Machine (FSM) “instruction fetch” IR MEM[PC] “decode / operand fetch” A R[rs] B R[rt] R A or ZX R[rd] R PC PC + 4 R[rt] R PC PC + 4 To instruction fetch LW SW BEQ & Equal BEQ & ~Equal PC PC + 4 R A + SX R A + SX M MEM[R] MEM[R] B PC PC + 4 R[rt] M PC PC + 4 To instruction fetch PC PC + SX || 00 To instruction fetch Write-back R A fun B ORi Memory Execute R-type EECC550 - Shaaban #14 Lec # 5 Winter 2000 12-20-2000 Traditional FSM Controller next state op cond state control points Truth or Transition Table 11 next State control points Equal 6 4 op State To datapath datapath State EECC550 - Shaaban #15 Lec # 5 Winter 2000 12-20-2000 Traditional FSM Controller datapath + state diagram => control • Translate RTN statements into control points. • Assign states. • Implement the controller. EECC550 - Shaaban #16 Lec # 5 Winter 2000 12-20-2000 Mapping RTNs To Control Points Examples & State Assignments IR MEM[PC] “instruction fetch” 0000 imem_rd, IRen A R[rs] B R[rt] Aen, Ben “decode / operand fetch” 0001 ALUfun, Sen ORi LW R A or ZX R A + SX 0110 1000 RegDst, RegWr, PCen M MEM[S] 1001 BEQ & Equal SW BEQ & ~Equal R A + SX 1011 MEM[S] B PC PC + 4 1100 R[rd] R PC PC + 4 R[rt] R PC PC + 4 0101 0111 To instruction fetch state 0000 R[rt] M PC PC + 4 1010 To instruction fetch state 0000 PC PC + 4 0011 PC PC + SX || 00 0010 To instruction fetch state 0000 Write-back R A fun B 0100 Memory Execute R-type EECC550 - Shaaban #17 Lec # 5 Winter 2000 12-20-2000 Detailed Control Specification State Op field Eq Next IR PC en sel BEQ R ORI LW SW 0000 0001 0001 0001 0001 0001 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 ?????? BEQ BEQ R-type orI LW SW xxxxxx xxxxxx xxxxxx xxxxxx xxxxxx xxxxxx xxxxxx xxxxxx xxxxxx xxxxxx xxxxxx ? 0 1 x x x x x x x x x x x x x x x 0001 1 0011 0010 0100 0110 1000 1011 0000 1 1 0000 1 0 0101 0000 1 0 0111 0000 1 0 1001 1010 0000 1 0 1100 0000 1 0 Ops AB Exec Ex Sr ALU S Mem RWM Write-Back M-R Wr Dst 11 11 11 11 11 11 0 1 fun 1 0 1 1 0 0 or 1 0 1 0 1 0 add 1 1 0 0 1 1 0 1 0 add 1 0 1 EECC550 - Shaaban #18 Lec # 5 Winter 2000 12-20-2000 Alternative Multiple Cycle Datapath (In Textbook) • Miminizes Hardware: 1 memory, 1 adder PCWr PCWrCond Zero MemWr IRWr RegDst 32 32 Rt 0 5 Rd 0 ExtOp Rb busA Reg File 32 1 Rw 1 1 Mux 0 Imm 16 Ra busW busB 32 << 2 4 Zero 32 0 1 32 ALU Out 1 32 Mux Ideal Memory WrAdr 32 Din Dout Rt 5 32 ALU Mux RAdr Instruction Reg 0 Target 1 0 Rs Mux 32 32 ALUSelA 32 PC 32 RegWr BrWr Mux IorD PCSrc 32 2 3 ALU Control Extend 32 ALUOp MemtoReg ALUSelB EECC550 - Shaaban #19 Lec # 5 Winter 2000 12-20-2000 Alternative Multiple Cycle Datapath (In Textbook) •Shared instruction/data memory unit • A single ALU shared among instructions • Shared units require additional or widened multiplexors • Temporary registers to hold data between clock cycles of the instruction: • Additional registers: Instruction Register (IR), Memory Data Register (MDR), A, B, ALUOut EECC550 - Shaaban #20 Lec # 5 Winter 2000 12-20-2000 Operations In Each Cycle R-Type Instruction Fetch IR Mem[PC] PC PC + 4 A R[rs] Instruction Decode Execution B R[rt] Logic Immediate IR Mem[PC] PC PC + 4 Load Store IR Mem[PC] PC PC + 4 IR Mem[PC] PC PC + 4 A R[rs] A R[rs] A B R[rt] B R[rt] B R[rt] ALUout PC + (SignExt(imm16) x4) ALUout PC + ALUout A + B ALUout (SignExt(imm16) x4) A OR ZeroExt[imm16] ALUout PC + (SignExt(imm16) x4) ALUout A + SignEx(Im16) Branch IR Mem[PC] PC PC + 4 A R[rs] R[rs] B R[rt] ALUout PC + ALUout PC + (SignExt(imm16) x4) (SignExt(imm16) x4) If Equal = 1 ALUout PC ALUout A + SignEx(Im16) Memory M Mem[ALUout] Write Back R[rd] ALUout R[rt] ALUout R[rd] Mem[ALUout] B Mem EECC550 - Shaaban #21 Lec # 5 Winter 2000 12-20-2000 High-Level View of Finite State Machine Control • • • • First steps are independent of the instruction class Then a series of sequences that depend on the instruction opcode Then the control returns to fetch a new instruction. Each box above represents one or several state. EECC550 - Shaaban #22 Lec # 5 Winter 2000 12-20-2000 Instruction Fetch and Decode FSM States EECC550 - Shaaban #23 Lec # 5 Winter 2000 12-20-2000 Load/Store Instructions FSM States EECC550 - Shaaban #24 Lec # 5 Winter 2000 12-20-2000 R-Type Instructions FSM States EECC550 - Shaaban #25 Lec # 5 Winter 2000 12-20-2000 Branch Instruction Single State Jump Instruction Single State EECC550 - Shaaban #26 Lec # 5 Winter 2000 12-20-2000 EECC550 - Shaaban #27 Lec # 5 Winter 2000 12-20-2000 Finite State Machine (FSM) Specification IR MEM[PC] PC PC + 4 “instruction fetch” 0000 A R[rs] B R[rt] “decode” ALUout PC +SX 0001 LW ALUout A fun B ALUout A op ZX ALUout A + SX 0100 0110 1000 M MEM[ALUout] 1001 BEQ SW ALUout A + SX 1011 If A = B then PC ALUout 0010 MEM[ALUout] B To instruction fetch Write-back ORi Memory Execute R-type 1100 R[rd] ALUout R[rt] ALUout 0101 0111 R[rt] M 1010 To instruction fetch To instruction fetch EECC550 - Shaaban #28 Lec # 5 Winter 2000 12-20-2000 MIPS Multi-cycle Datapath Performance Evaluation • What is the average CPI? – State diagram gives CPI for each instruction type – Workload below gives frequency of each type Type CPIi for type Frequency CPIi x freqIi Arith/Logic 4 40% 1.6 Load 5 30% 1.5 Store 4 10% 0.4 branch 3 20% 0.6 Average CPI: 4.1 Better than CPI = 5 if all instructions took the same number of clock cycles (5). EECC550 - Shaaban #29 Lec # 5 Winter 2000 12-20-2000