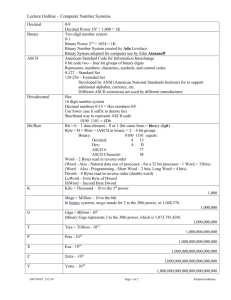
numbers and characters
advertisement

LIS512 lecture 3 numbers and characters Thomas Krichel 2010 – 10 – 06 structure • • • • • • • numbers numeric information character information the ASCII set Unicode encoding coda – ligatures – collations – transliterations introduction • We have seen that databases store records. • Records contain fields, fields have values. • Here we talk about fundamentally, how do we compose those values. – Numeric values are easy. – Character values are harder. literature • The library textbooks are hopelessly short and confused about this topic. • I have most of what I have here from my own experience. • I recommend Wikipedia, it has fascinating articles about these topics. all gone to a number • In all modern information system, information is stored to be treated on a computer. • A computer can only deal with numbers. • As a consequence all information has to be converted into a number. • It's a huge job. • Let’s look at the ground, numbers. binary code • All computers process codes that is a sequence or zeros and ones. • Such code is called binary. • All digital information is somewhere written out as sequences of on/off binary signals. binary and digital numbers • Binary numbers can be converted to normal “decimal” numbers –0 –1 – 10 – 11 – 100 – 101 • etc 0 1 2 3 4 5 a bit • A bit is the elementary unit of information. • It takes a binary value. We can label it true/false, black/white, +/-, etc. • Every piece of information in all modern information storage systems has to be reduced to a sequence of bits. • We will denote them 0/1 here. example: 2 bits • If we say that an piece of data is three bits long, we know it can hold 2 to the power 2 different numbers. • In binary, they are 00, 01, 10, 11. • In decimal, they are 0, 1, 2, 3. byte • A byte is a sequence of 8 bits. '00000000' to '11111111'. There are 2 to the power 8, meaning 256 possibilities to write a byte. • If the byte is required to start with 0, then we can only write '0000000' to '01111111'. This leaves us with 2 to the power 7, meaning 128 possibilities. hex numbers • Hex numbers contain the usual digits 0 to 9, as well as A to F. A means 10, B means 11, etc F means 15. • One hex number can represent 2 to the power 4, meaning 16 possibilities (0 to 15). • Two hex numbers can represent 2 to the power 8 possibilities. one hex number 0 2 4 6 8 a c e 0000 0010 0100 0110 1000 1010 1100 1110 | | | | | | | | 1 3 5 7 9 b d f 0001 0011 0101 0111 1001 1011 1101 1111 same in decimal number 0 2 4 6 8 10 12 14 0000 0010 0100 0110 1000 1010 1100 1110 | | | | | | | | 1 3 5 7 9 11 13 15 0001 0011 0101 0111 1001 1011 1101 1111 bytes and hex numbers • Since two hex numbers convene the same number of possibilities as a byte a byte is often represented as two hex numbers. • Thus, for example • '00000000' in binary is 00 in hex, • '11111111' in binary is 'FF' in hex, • '01111111' in binary is ‘7F‘ in hex another way to see this… • binary numbers are sometimes called base-2 numbers. • decimal number are sometimes called base-10 numbers. • so hexadecimal (hex) numbers are just base16 numbers. – sometimes written using a 0x prefix. converting information to numbers • • • A lot of problem in converting information comes from some part of the information encode in some form and some other part in some other from. Example: “15 Julliet 1923” vs “July 17, 1923” Often such inconsistencies require manual reformatting, which is very expensive. numerizing • • In the design of every information systems, if possible it is a good idea to convert information into something that is directly a number. There are examples where it is possible directly use a number, such as – – – colours times and dates locations. example: colours on the web • • Colours on the world wide web follow the red/green/blue colour model. Each colour is given as a number #rrggbb, where rr is the amount of red gg is the amount of green and bb in the amount of blue. All these numbers are hex numbers. Example – – #FFFFFF white #00FFFF aqua example: times • One way to “numerize” recent times in to take the number of seconds since the first of January 1970. • This point in time is called the Unix epoch. • Counting time like this has the advantage that it is straightforward to interpret and to convert it into a representation of time that the user can understand. example: location • On earth, locations are best given by a longitude / latitude grid system. • This for example, makes a rough calculation possible on how far two points are apart. • It also allows us to refer to a location independently of its current name. Remember, names of locations change. non-numerical information • A lot of information is not numerical by its nature. For example – – the name of a person the title of an expression of a work • The information is of a character string nature. • To store character strings in an information system, each character has to be converted to a number. character • • A character is an indivisible unit of textual information. Textual information is composed of characters, and nothing else. characters and computer • Computers can not deal with characters directly. They can only deal with numbers. • There we need to associate a number with every character that we want to use in an information encoding system. • A character set combines characters with number. ASCII • ASCII is an old character set developed in the United States. It is a seven bit character set. • In hex notation, it goes from '00' to '7F' • Because Anglo-Saxon cultural imperialism, most other character set either include or extend the ASCII character set. notable characters in ASCII decimal • 8 • 9 • 10 • 13 • 32 • 127 hex 8 9 A D 20 7F byte 08 09 0A 0D 20 7F U+0008 U+0009 U+000A U+000D U+0020 U+007F backspace horizontal tab line feed carriage return space delete UCS / Unicode • UCS is a universal character set. • It is maintained by the International Standards Organization. • Unicode is an industry standard for characters. It is better documented than UCS. • For what we discuss here, UCS and Unicode are the same. Basic multilingual plane • This is a name for the first 65536 characters in Unicode. • Each of these characters fits into two bytes and is conveniently represented by four hex numbers. • Even for these characters, there are numerous complications associated with them. wikipedia notation • Wikipedia denotes every character in the BMP as U+hhhh where h is a hex digit 0-F. We will follow this notation here. This notation is also useful when you try to enter the characters on a computer. For example, in MS Windows, you • • • • • • • press and hold ALT press + on the numeric keypad enter the hex code release ALT ascii and unicode • The first 128 characters of UCS/Unicode are the same as the ones used by ASCII. • So you can think of UCS/Unicode as an extension of ASCII. dashes • figure dash ‒ U+2012 to link numbers without a range • en dash – U+2013 to link numbers with a range • em dash — U+2014 for interjections in a sentence • minus sign − U+2212 for mathematics “smart” quotes • • • • U+201c “ is the opening double quote U+201d ” is the closing U+2019 ’ is the apostrophe The single quote of the ASCII character set is considered to be of mixed usage, it should be avoided when a specific use can be done. • Similarly, the double quote of the ASCII character set is imprecise. spaces • non-breaking space, U+00A0 is used when you want to avoid a line break between the two spaced items. For example in hyperlink text, it is good practice to replace spaces with nonbreaking spaces as to avoid there appearing to be two links. • In whitespace collapsing contents, it can also be use to add extra space. in foreign languages • • Everything becomes difficult. As an example consider the characters – – – • o ő ö The latter two can be considered o with diarcitics or as separate characters. most problematic: encoding • • • • One issue is how to map characters to numbers. This is complicated for languages other than English. But assume UCS/Unicode has solved this. But this is not the main problem that we have when working with non-ASCII character data. encoding • • • The encoding determines how the numbers of each character should be put into bytes. If you have a character set that is has one byte for each character, you have no encoding issue. But then you are limited to 256 characters in your character set. fixed-length encoding • • • If you have a fixed length encoding, all characters take the same number of bytes. Say for the basic-multilingual plane of unicode, you need two bytes for each character, and then you are limited to that. If you are writing only ASCII, it appears a waste. variable length encoding • • The most widely used scheme to encode Unicode is a variable length scheme, called UTF-8. It is important to understand that the encoding needs to known and correct. bascis of UTF-8 • Every ASCII character, represented as a byte, starts with a zero. • Characters that are beyond ASCII require two or three bytes to be complete. • The first byte will tell you how many bytes are coming to make the character complete. byte shapes in UTF-8 encoding • • • • • • 0?????? ASCII 110???? first octet of two-byte character 1110???? first byte of three-byte character 11110??? first octet of four-byte character 10??????? byte that is not the first byte as you can see, there are sequences of bytes that are not valid hex range to UTF-8 • 0000 to 007F • 0080 to 07FF • 0800 to FFFF 0??????? 110????? 10?????? 1110???? 10?????? 10?????? ligature • In fine traditional typography, certain characters appear to be linked to each other. • The most command examples in English usage are fi, ff, fl, ffi, ffl. ligatures growing up • In certain cases, ligatures have become so common that they have become characters of their own. • A prominent example is the German sz ligature the esszet. It looks a bit like a beta because it is derived from the fraktur font of the characters. • Another example, apparently, is &. collations • Collations are topic that is related to characters. • A collation is a sorting order of character strings. • You may think this is trivial, just follow the alphabetic order. • But in many languages, diacritics come to complicate matters. example German • Here are the extra letter of German: Ä/ä, Ö/ö, Ü/ü, ß • In German, there are two collations. – DIN 5007-1 “dictionary collation” treats umlauted characters as if they did not have them, and ß as s. – DIN 5007-2 “phonebook collation” treats umlauted as letter and e (ex. ä --> ae), and ß as ss transliterations • When non-English characters are supposed to be entered in a system used by English speaking people, a transliteration might be used. • This can also be the case if the original script may not be commonly understood. An example are Japanese road sign. • Wikipedia lists 20 different ways to do that for Russian, say. Library of Congress scheme is apparently the most widely used. http://openlib.org/home/krichel Thank you for your attention! Please switch off machines b4 leaving!