cabin_trainingSQL
advertisement

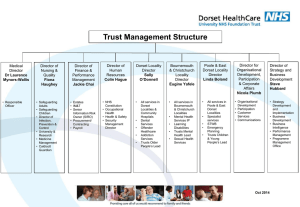
INTRODUCTION TO SQL • SQL stands for « Structured Query Language » • Progamming language for database closer to natural English than the other (based on « sentence » instead of « procedure ») • Aim is to ease the querying of data by the human and the programmation of interfaces • Powerful functions for text recognition • Powerfull extensions for GIS (PostGIS, Oracle) • Standardized and recognized by most of the recent relational database BUT 1)...minor differences of syntax between vendors and enhanced functions prevent easy interoperability between products 2) SQL databases often imply that the development of the interfaces is a distinct from the development of the core of the database Interoperability problem between vendors – possible solutions • use an intermediate layer between the database and the interface – ODBC/JDBC (connectors used by other software by Windows/Java) – use ORM (Object Relational Mapper) software that allows the programmer to use the same syntax when developing interfaces e.g : Doctrine (Open-Source) SQL and NoSQL • SQL is pretty useful for normalized database where the control of data integrity is important (scientific value) • ...but it is not scalable : huge amount (> 300 000) of data lower peformances) • since 4/5 years, with the explosion of the Internet there is a trend in NoSQL database; fastr databases that can handle huge amount of data raplidly, e.g: Solr (to index Words and PDF),MongoDB, Cassandra etc... • NoSQL offers speed, fast replication between locations, flexible structure but no control on integrity. It doesn’t replace SQL but complements it (SQL=> control of the integrity and of the completness of data is more important than speed + good interaction with GIS NoSQL: high availability of data on the Internet but no schema to validate integrity and not yet GIS plug in ) Problem: scientic information network requires both quality control and high availiability SQL: 4 parts • Data Query Language (DQL) – Search and display data matching specific criteria • Data manipulation language (DML): – modify data (insert, update, delete) – lock (atomicity of data: two user cannot modify the ame data in parallel) – use transation (rollback to the previous state of the database if a modification fails) • Data Definition language (DDL) – create the schema of the database (the normalised structure, the index): you can defined yourselve how to check the integrity of the database • Data Control language (DCL) – create authorization and access rule for users Vocabulary Table Field Field name Field Type Record (or tuple) Recommandations To ease the manipulation with SQL when creating a database: – Avoid uppercase letters in field names – Avoid accented characters in field names (but you must keep them in the content of course!) – replace white spaces with underscore – avoid at any price other non alphabetical or numerical characters – avoid giving the same name to two fields in different tables (not always possible...) – table name in plural – field name singular – use descriptive field name (e.g: not ‘dc’ but ‘date_collected’) Querying Pattern: SELECT <comma-separated list of fields> FROM <name of Table> ; e.g. SELECT Locality FROM localities; SELECT Locality, Country FROM localities; SELECT * FROM Localities; « * »=> all fields (wildcard) Querying II Pattern: SELECT <comma-separated list of fields> FROM <name of Table> WHERE [condition] ; e.g. SELECT pk_locality, latitude_decimals, longitude_decimals FROM localities WHERE Locality =‘Tienen’; Querying II Pattern: SELECT <comma-separated list of fields> FROM <name of Table> WHERE [condition] ; e.g. SELECT * FROM localities WHERE latitude_decimals >50.80 AND latitude_decimals<50.85 Querying III (boolean) Compare the result SELECT * FROM localities WHERE latitude_decimals >50.80 AND latitude_decimals<50.85 SELECT * FROM localities WHERE latitude_decimals >50.80 OR latitude_decimals<50.85 Querying IV (boolean) Compare the result SELECT * FROM localities WHERE locality=‘Tienen’ AND locality=‘Bunsbeek’; SELECT * FROM localities WHERE locality=‘Tienen’ OR locality=‘Bunsbeek’; Querying II Pattern: SELECT <comma-separated list of fields> FROM <name of Table> WHERE [condition] ; e.g. SELECT * FROM localities WHERE locality <> ‘Hensberg’; SELECT * FROM localities WHERE locality IS NULL; JOINING (I) SELECT * FROM specimens JOIN scientific_names ON specimens.fk_scientific_name = scientific_names.pk_scientific_na me [+ WHERE CONDITION] ; Joining II • Exercice – Find the collectors of ‘Agostis’ Joining II • Exercice • Find the collectors of ‘Agostis’ SELECT collector_name, genus FROM specimens JOIN scientific_names ON specimens.fk_scientific_name= scientific_names.pk_scientific_name where genus='Agrostis'; Joining III • Exercice – Find the scientific names having been collected in Tienen Joining III • Exercice – Find the scientific names having been collected in Tienen SELECT scientific_name FROM specimens JOIN scientific_names ON specimens.fk_scientific_name= scientific_names.pk_scientific_name JOIN localities ON specimens.fk_locality=localities.pk_locality where locality='Tienen'; Joining III (ordering) • Exercice Find the scientific names having been collected in Tienen SELECT scientific_name FROM specimens JOIN scientific_names ON specimens.fk_scientific_name= scientific_names.pk_scientific_name JOIN localities ON specimens.fk_locality=localities.pk_locality where locality='Tienen‘ ORDER BY scientific_name; Joining III • Exercice Find the collectors of ‘Balsaminaceae’ – Find the collectors of ‘Balsaminaceae’ Joining III • Exercice – Find the collectors of ‘Balsaminaceae’ SELECT collector_name FROM specimens JOIN scientific_names ON specimens.fk_scientific_name= scientific_names.pk_scientific_name JOIN families ON scientific_names.fk_family=families.pk_family where family='Balsaminaceae' ; Views ‘Save’ and make complex queries permanent in the database (useful for programming of filtering) CREATE VIEW v_specimen_names_localities AS SELECT scientific_name FROM specimens JOIN scientific_names ON specimens.fk_scientific_name= scientific_names.pk_scientific_name JOIN localities ON specimens.fk_locality=localities.pk_locality Search on Text Patterns (I) a) match one position: '_'; ‘_’ means any character present one time b) match several positions: '%'; ‘%’ means the absence or repetition of any character Note: white space counts for one character Search on Text Patterns (II) • SQL Syntax SELECT ...WHERE field LIKE 'pattern'; • PostgresSQL Syntax SELECT ...WHERE field SIMILAR TO 'pattern'; Search on Text Patterns (III) Example: find the scientific names having «’e’ » as second letter of genus: SELECT scientific_name FROM scientific_names WHERE genus SIMILAR TO '_e%'; Search on Text Patterns (IV) Example: Pattern: Response: '_e%'; ‘Aegopodium’ ‘Aethusa’ ‘Bellis’ ‘Betula’ ... Search on Text Patterns (V) Example: Pattern: Response: '_e%'; ‘Aegopodium’ ‘Aethusa’ ‘Bellis’ ‘Betula’ ... Search on text pattern (VI) • Interval of characters • Use brackets [a-z]: any lower case letter [A-Z]: any uppercase letter [0-9]: any numer [aA]: ‘a’ or ‘A’ Search on text pattern (VII) • Useful to control nomenclature!! • Exercice: Search the species containing uppercase characters: Search on text pattern (VII) • Useful to control nomenclature • Exercice: Search the species containing uppercase characters: SELECT * FROM scientific_names WHERE species SIMILAR TO '%[A-Z]%'; Search on text pattern (VIII) • Useful to control nomenclature • Exercice: Search the genus containing uppercase letters after the first one: Search on text pattern (VIII) Exercice: Search the genus containing uppercase letters after the first letter: SELECT * FROM scientific_names WHERE genus SIMILAR TO ‘_%[A-Z]%'; Search on text pattern (IX) • Useful to control nomenclature • Exercice: Search the genus containing more than one word: Search on text pattern (IX) Exercice: Search the genus containing more than one word SELECT * FROM scientific_names WHERE genus SIMILAR TO '%[a-z]% %[a-z]%'; Search on text pattern (X) • PostgreSQL is also compliant with an even more powerfull mechanism called « regular expression » – standard syntax shared by several programming languages – allow matching complex patterns – can perform replacements and extractions <optional if somebody ask how to group information in one row> Group specimen collected in Tienen per Collector SELECT array_to_string(array_agg(scientific_name), ','), collector_name FROM specimens JOIN scientific_names ON specimens.fk_scientific_name= scientific_names.pk_scientific_name JOIN localities ON specimens.fk_locality=localities.pk_locality where locality='Tienen' GROUP BY collector_name ORDER BY collector_name; <optional if somebody ask how to group information in one row> Group localities per collectors SELECT array_to_string(array_agg(locality), ','), collector_name FROM specimens JOIN scientific_names ON specimens.fk_scientific_name= scientific_names.pk_scientific_name JOIN localities ON specimens.fk_locality=localities.pk_locality GROUP BY collector_name ORDER BY collector_name;