Quantitative Data Graphs: Dotplots, Stemplots, Histograms
advertisement

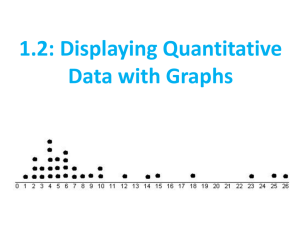
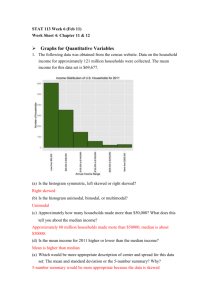
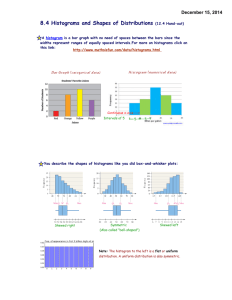
1.2 Displaying Quantitative Data w/ Graphs Pages 25-48 Objectives SWBAT: 1) Make and interpret dotplots and stemplots of quantitative data. 2) Describe the overall pattern (shape, center, and spread) of a distribution and identify any major departures from the pattern (outliers). 3) Identify the shape of a distribution from a graph as roughly symmetric or skewed. 4) Make and interpret histograms of quantitative data. 5) Compare distributions of quantitative data using dotplots, stemplots, and histograms. 4) What is the most important difference between cities C, F, and G? Their shapes The dotplots show the daily high temperatures for 7 cities in June, July and August. 1) What is the most important difference between cities A, B, and C? Their centers 2) What is the most important difference between cities C and D? Their spreads 3) What are two important differences between cities D and E? Their spreads (but not range) and unusual values (outliers) When describing the distribution of a quantitative variable, what characteristics should be addressed? • You want to address patterns and departures from patterns. The acronym to remember is SOCS: Shape, Outliers, Center, and Spread. Someone else is on 1.2! Shape • When you describe a distribution’s shape, concentrate on the main features. Look for rough symmetry or clear skewness. Definitions: A distribution is roughly symmetric if the right and left sides of the graph are approximately mirror images of each other. A distribution is skewed to the right (right-skewed) if the right side of the graph (containing the half of the observations with larger values) is much longer than the left side. It is skewed to the left (left-skewed) if the left side of the graph is much longer than the right side. Symmetric Skewed-left Skewed-right To help remember skewed right and skewed left, think about your feet. A distribution is skewed to the right when the right side of the graph is more spread out than the left side. Think about your right foot. The toes are tall on the left side and get progressively smaller as you move to the right. A distribution is skewed to the left when the left side of the graph is more spread out than the right side. Think about your left foot. The toes are tall on the right side and get progressively smaller as you move to the left. Other terms to describe shape Unimodal A distribution is unimodal when it shows one distinct peak. Bimodal A distribution is bimodal if it has two distinct peaks. Note: we don’t worry about little bumps. They have to be distinct. This is an example of a bimodal distribution. It shows the duration (in minutes) of 220 eruptions of the Old Faithful geyser. Uniform A distribution is uniform when the heights of the bars are all about the same. How would you describe the shapes of these distributions? Skewed right, unimodal Symmetric, unimodal • An outlier is an individual value that falls outside the overall pattern of a distribution. – For now we’ll use an eye test to determine outliers. Looking at this distribution, there’s two unusually high values that appear to be outliers, at approximately 57 and 91. • The center is the middle value in the distribution (either the mean or median). • The spread is the variability of a sampling distribution (how spread out the data is). – Common measures of spread are range and IQR. • Here is an example of Tom Brady’s passer ratings in the 2001 NFL season. Describe the spread. The range is 148.3-57.1=91.2 Frozen Pizza Example Here are the number of calories per serving for 16 brands of frozen cheese pizza, along with a dotplot of the data. 340 340 310 320 310 360 350 330 260 380 340 320 360 290 320 330 Shape: roughly symmetric and unimodal Center: median at 330 calories Spread: the values vary from 260 calories to 380 calories (a range of 120) Outliers: there appears to be one unusually small value (260 calories) What is the most important thing to remember when you are asked to compare two distributions? • You need to actually compare the distributions using explicit comparison words! – Examples: • The center for distribution A is larger than the center for distribution B. • Carucci’s cat meows less than Mr. Fal’s cat. • Prestige Worldwide makes the same amount of money as the South Pole Elf Corporation. • Needless to say, this is only applicable to certain parts of SOCS (center and spread). One shape cannot necessarily be better than another shape. How do the annual energy costs (in dollars) compare for refrigerators with top freezers and refrigerators with bottom freezers? The data below is from the May 2010 issue of Consumer Reports. • Shape: The distribution for bottom freezers looks skewed right and possibly bimodal (modes near $58 and $70 per year). The distribution for top freezers looks roughly symmetric, with its main peak centered near $55. • Outliers: There appear to be two bottom freezers with unusually high energy costs (over $140). There are no outliers for the top freezers. • Center: The typical energy cost for bottom freezers is greater than the typical cost for the top freezers (midpoint of $69 vs midpoint of $56). • Spread: There is much more variability in the energy costs for bottom freezers. What is the most important thing to remember when making a stemplot? • Stemplots (aka stem-and-leaf plots) are simple graphical displays for fairly small data sets. • Stemplots give us a quick picture of the distribution while including the actual numerical values. • Just like with all displays, it is important to remember the LABELS (and a key)!!!! How to Make a Stemplot 1)Separate each observation into a stem (all but the final digit) and a leaf (the final digit). 2)Write all possible stems from the smallest to the largest in a vertical column and draw a vertical line to the right of the column. 3)Write each leaf in the row to the right of its stem. 4)Arrange the leaves in increasing order out from the stem. 5)Provide a key that explains in context what the stems and leaves represent. • Stemplots (Stem-and-Leaf Plots) – These data represent the responses of 20 female AP Statistics students to the question, “How many pairs of shoes do you have?” Construct a stemplot. 50 26 26 31 57 19 24 22 23 38 13 50 13 34 23 30 49 13 15 51 1 1 93335 1 33359 2 2 664233 2 233466 3 3 1840 3 0148 4 4 9 4 9 5 5 0701 5 0017 Stems Add leaves Order leaves Key: 4|9 represents a female student who reported having 49 pairs of shoes. Add a key Sometimes it may be beneficial to split stems, which is a method for spreading out a stemplot that has too few stems (the data tends to be bunched up). [every number 0-4 goes in the first stem, 5-9 in the second] Example: Which gender is taller, males or females? A sample of 14year-olds from the UK was randomly selected using the CensusAtSchool website. Here are the heights of the students (in cm). Make a back-to-back stemplot and compare the distributions. Male: 154, 157, 187, 163, 167, 159, 169, 162, 176, 177, 151, 175, 174, 165, 165, 183, 180 Female: 160, 169, 152, 167, 164, 163, 160, 163, 169, 157, 158, 153, 161, 165, 165, 159, 168, 153, 166, 158, 158, 166 If we opted to not split stems: By splitting stems: Male: 154, 157, 187, 163, 167, 159, 169, 162, 176, 177, 151, 175, 174, 165, 165, 183, 180 Female: 160, 169, 152, 167, 164, 163, 160, 163, 169, 157, 158, 153, 161, 165, 165, 159, 168, 153, 166, 158, 158, 166 Shape: The female distribution is skewed left unimodal. The male distribution is symmetric unimodal. Outliers: Neither distribution appears to contain outliers. Centers: The males have a larger center than the females (median of 167 centimeters vs median of 162 centimeters [avg the middle two]. Spread: The male distribution has greater variability than the female distribution. • Histograms – Quantitative variables often take many values. A graph of the distribution may be clearer if nearby values are grouped together. – The most common graph of the distribution of one quantitative variable is a histogram. How to Make a Histogram 1)Divide the range of data into classes of equal width. 2)Find the count (frequency) or percent (relative frequency) of individuals in each class. 3)Label and scale your axes and draw the histogram. The height of the bar equals its frequency. Adjacent bars should touch, unless a class contains no individuals. It might make it easier to visualize a dotplot first before creating a histogram. • Here are the run totals for the 30 MLB teams in 2008. Note: the Astros were still in the NL. • Here is a dotplot showing the runs scored for the 30 MLB teams. Step 1: Divide the data into 5 to 10 equally wide classes. For this example, we can use classes that are 50 runs wide. Therefore, our first class will be 600-650 runs, the next class is 650700 runs, etc… Step 2: Count how many observations are in each class. If an observation falls exactly on a border line, it is considered part of the class above the boundary. For example, the observation on 750 would count as part of the 750-800 class. Step 3: Label and scale your axes and draw the histogram. The height of the bar equals its frequency. Adjacent bars should touch, unless a class contains no individuals. • The smallest observation is 93.2 and the largest is 106.1 We could choose classes of width 2 starting at 93. How do you make a histogram? • Already answered! • Points of emphasis: labels, equal class widths, make sure values that fall on the boundaries go in the class above. Why would we prefer a relative frequency histogram to a frequency histogram? • When comparing distributions of different sample size! When the number of observations are not equal, a fair comparison cannot be made using just the frequency. Think of the radio stations in NJ vs radio stations in the USA example. • Using Histograms Wisely – Here are several cautions based on common mistakes students make when using histograms. Cautions 1)Don’t confuse histograms and bar graphs. 2)Don’t use counts (in a frequency table) or percents (in a relative frequency table) as data. 3)Use percents instead of counts on the vertical axis when comparing distributions with different numbers of observations. 4)Just because a graph looks nice, it’s not necessarily a meaningful display of data. • Follow pages 36-37 to make a histogram on the TI-84! • Note: – To change the boundaries, press WINDOW. – Xmin defines where the first class begins and Xscl defines the class width. – Xmax, Ymin, and Ymax define how big the window will be.