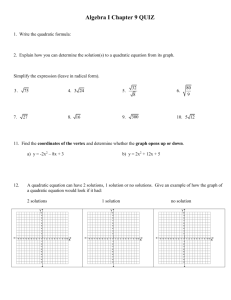
at x
advertisement

Chapter 10
Nonlinear Programming Methods
1
Background
• Solution techniques for nonlinear programming
(NLP) are much more complex and much less
effective than those for linear programming (LP).
• Linear programming codes will provide optimal
solutions for problems with hundreds of thousands
of variables, but there is a reasonable chance that
an NLP code will fail on a problem containing
only a handful of variables.
• To sharpen this contrast, recall that all interior
point methods for solving LP problems include
ideas originally developed to solve NLP problems.
2
10.1 CLASSICAL OPTIMIZATION
The simplest situation that we address concerns the minimization of
a function f in the absence of any constraints. This problem can
be written as
Minimize {f(x): x Rn}
Where f C2 (twice continuously differentiable). Without
additional assumptions on the nature of f, we will most likely
have to be content with finding a point that is a local minimum.
Elementary calculus provides a necessary condition that must be
true for an optimal solution of a nonlinear function with
continuous first and second derivatives.
gradient is zero at every stationary point that is a candidate for a
maximum or minimum.
Sufficient conditions derived from convexity properties are also
available in many cases.
3
Unconstrained Optimization
The first-order necessary condition that any point x* must satisfy
to be a minimum of f is that the gradient must vanish.
▽f(x*)=0
(2)
This property is most easily illustrated for a univariate objective
function in which the gradient is simply the derivative or the
slope of f(x).
Consider, for example, Figure 10.1. The function in part (a) has a
unique global minimum x* at which the slope is zero. Any
movement from that point yields a greater, and therefore less
favorable, value. The graph in part (b) exhibits a range of
contiguous global minima where the necessary condition holds;
however, we should note that the corresponding f(x) is not
twice continuously differentiable at all points.
4
Figure 10.2 shows why Equation (2) is only a necessary
condition and not a sufficient condition. In all three parts of
the figure there are points at which the slope of f(x) is zero
but the global minima are not attained. Figure 10.2a
illustrates a strong local maximum at x1*and a strong local
minimum at x2*. Figure 10.2b shows a point of inflection
at x1* that is a one-dimensional saddle point. Finally,
Figure 10.2c presents the case of a unique global
maximum at x1*.
The ideas embodied in Figures 10.1 and 10.2 can be easily
generalized to functions in a higher-dimensional space at
both the conceptual and mathematical levels. Because the
necessary condition that the gradient be zero ensures only a
stationary point—ie., a local minimum, a local maximum,
or a saddle point at x*.
5
6
Sufficient conditions for x* to be either a local or a global
minimum:
• If f(x) is strictly convex in the neighborhood of x*, then
x* is a strong local minimum.
• If f(x) is convex for all x, then x* is a global minimum.
• If f(x) is strictly convex for all x, then x* is a unique
global minimum.
To be precise, a neighborhood of x is an open sphere
centered at x with arbitrarily small radius ε > 0. It is
denoted by Nε(x), where Nε(x) = {y : ∥ (y - x) ∥ < ε}.
7
8
f(x) is strictly convex if its Hessian matrix H(x) is positive
definite for all x. In this case, a stationary point must be a
unique global minimum.
f(x) is convex if its Hessian matrix H(x) is positive
semidefinite for all x. For this case a stationary point will
be a global (but perhaps not unique) minimum.
If we do not know the Hessian for all x, but we evaluate
H(x*) at a stationary point x* and find it to be positive
definite, the stationary point is a strong local minimum.
(If H(x*) is only positive semidefinite at x* , x* can not be
guaranteed to be a local minimum.)
9
Functions of a Single Variable
Let f(x) be a convex function of x R1.
A necessary and sufficient condition for x* to be a global
minimum is that the first derivative of f(x) be zero at that
point.
This is also a necessary and sufficient condition for the
maximum of a concave function. The optimal solution is
determined by setting the derivative equal to zero and
solving the corresponding equation for x. If no solution
exists, there is no finite optimal solution.
A sufficient condition for a local minimum (maximum)
point of an arbitrary function is that the first derivative of
the function be zero and the second derivative be positive
(negative) at the point.
10
Example 1
Let us find the minimum of f(x) = 4x2 - 20x + 10.
The first step is to take the derivative of f(x) and set
it equal to zero.
d f(x)/dx=8x-20=0
Solving this equation yields x* = 2.5 , which is a
candidate solution. Looking at the second
derivative, we see
d2 f(x)/dx2=8>O for all x
so f is strictly convex.
Therefore, x* is a global minimum.
11
Example 2
As a variation of Example 1, let us find the
minimum of f(x) = -4x2 - 20x.
Taking the first derivative and setting it equal to
zero yields df(x) /dx = -8x - 20 = 0, so x* = -2.5.
The second derivative is d2f(x) /dx = -8 < 0 for all x,
so f is strictly concave.
This means that x* is a global maximum.
There is no minimum solution because f(x) is
unbounded from below.
12
Example 3
Now let us minimize the cubic function f(x) = 8x3 + 15x2 + 9x
+ 6. Taking the first derivative and setting it equal to zero
yields df(x) /dx = 24 x2 + 30x + 9 = (6x + 3)(4x + 3) = 0. The
roots of this quadratic are at x = -0.5 and x = -0.75, so we have
two candidates. Checking the second derivative
d2f(x) /dx2 = 48x + 30
we see that it can be > 0 or < 0.
Therefore, f(x) is neither convex nor concave.
At x = -0.5, d2f(-0.5) /dx2 = 6, so we have a local minimum.
At x = -0.75, d2f(-0.75) /dx2 = -6, which indicates a local
maximum.
These points are not global optima, because the function is
actually unbounded from both above and below.
13
Functions of Several Variables
Theorem 1:
Let f(x) be twice continuously
differentiable throughout a neighborhood of
x*. Necessary conditions for x* to be a local
minimum of f are
a.
▽f(x*)=0
b.
H(x*) is positive semidefinite.
14
Theorem 2:
Let f(x) be twice continuously differentiable
throughout a neighborhood of x*. Then a
sufficient condition for f(x) to have a strong
local minimum at x*, where Equation (2)
holds, is that H(x*) be positive definite.
Note:
H(x*) being positive semidefinite is not a sufficient
condition for f(x) to have a local minimum at x*.
15
Quadratic Forms
A common and useful nonlinear function is the quadratic
function
1 T
f ( x) a cx x Qx
2
that has coefficients a R1 , c R n , and Q R n*n .
Q is the Hessian matrix of f(x). Setting the gradient
▽ f ( x) c
T
Qx
to zero results in a set of n linear equations in n variables.
A solution will exist whenever Q is nonsingular. In such
instances, the stationary point is
x*= -Q-1cT
16
For a two-dimensional problem, the quadratic function is
1
1
2
f ( x) a c1 x1 c2 x2 q11 x1 q22 x22 q12 x1 x2
2
2
For this function, setting the partial derivatives with respect to
x1, and x2 equal to zero results in the following linear
system.
c1 q11x1 q12 x2 0
c2 q12 x1 q22 x2 0
17
These equations can be solved using Cramer's rule from
linear algebra. The first step is to find the determinant of
the Q matrix. Let
det Q
q11
q12
q12
q22
q11q22 (q12 )
2
The appropriate substitutions yield
c1q22 c2 q12
x
and
det Q
*
1
c2 q11 c1q12
x
det Q
*
2
which is the desired stationary point.
18
When the objective function is a quadratic, the determination
of definiteness is greatly facilitated because the Hessian
matrix is constant.
For more general forms, it may not be possible to determine
conclusively whether the function is positive definite,
negative definite, or indefinite. In such cases, we can only
make statements about local optimality.
In the following examples, we use H to identify the Hessian.
For quadratic functions, Q and H are the same.
19
Example 4
Find the local extreme values of f ( x) 25x12 4 x22 20 x1 4 x2 5
Solution: Using Equation (2) yields
50 X1 - 20 = 0 and 8 X2 + 4 = 0
The corresponding stationary point is x* = (2/5, -1/2).
Because f(x) is a quadratic, its Hessian matrix is constant.
50 0
H
0
8
The determinants of the leading submatrices of H are H1 = 50
and H2 = 400, so f(x) is strictly convex, implying that x* is
the global minimum.
20
Example 5
Find the local extreme values of the nonquadratic function
f ( x) 3x x 9 x1 4 x2
3
1
2
2
Solution: Using Equation (2) yields
▽f(x)=(9x12 –9, 2x2 +4) T =(0, 0) T
So x1 = ±1 and x2= -2. Checking x = (1, -2), we have
18 0
H (1,2)
0 2
21
which is positive definite since vT H(l, -2)v =18 v12 + 2v22 > 0
when v≠0. Thus (1, -2) yields a strong local minimum.
Next, consider x = (-1, -2) with Hessian matrix
18 0
H (1,2)
0
2
Now we have vT H(-l, -2)v =-18 v12 + 2v22, which may be less
than or equal to 0 when v≠0. Thus, the sufficient condition for
(-1, -2) to be either a local minimum or a local maximum is
not satisfied. Actually, the second necessary condition (b) in
Theorem 1 for either a local minimum or a local maximum is
not satisfied. Therefore, x = (1, -2) yields the only local
extreme value of f.
22
Example 6
Find the extreme values of f(x) = -2x12+ 4x1 x2-4x22 + 4x1 +
4x2 +10.
Solution: Setting the partial derivatives equal to zero leads to
the linear system
-4 x1 + 4 x2+ 4 = 0 and 4 x1 -8 x2+ 4 = 0
which yields x* = (3, 2). The Hessian matrix is
4 4
H
4 8
Evaluating the leading principal determinants of H, we find
H1= -4 and H2 = 16. Thus, f(x) is strictly concave and x*
is a global maximum.
23
Nonquadratic Forms
When the objective function is not quadratic (or linear), the
Hessian matrix will depend on the values of the decision
variables x.
Suppose
f ( x) ( x2 x ) (1 x1 )
2 2
1
2
The gradient of this function is
4 x1 ( x2 x12 ) 2(1 x1 )
f ( x)
2
2( x2 x1 )
24
For the second component of the gradient to be zero , we must
2
have x2= x1 . Taking this into account, the first component is
zero only when x1= 1, so x* = (1,1) is the sole stationary point.
It was previously shown (in Section 9.3) that the Hessian
matrix H(x) at this point is positive definite, indicating that it is
a local minimum. Because we have not shown that the function
is everywhere convex, further arguments are necessary to
characterize the point as a global minimum.
Logically, f(x)≧0 because each of its two component terms is
squared. The fact that f(1,1) = 0 implies that (1,1) is a global
minimum.
As a further example, consider
f ( x) ( x1 2 x22 )( x1 3x22 )
25
where
2 x1 5 x22
f ( x)
and
3
10 x1 x2 24 x2
2
H ( x)
10 x2
10 x2
72 x22 10 x1
A stationary point exists at x* = (0, 0). Also, H1 = 2 and H2
= 44x22 - 20x1 implying that H(x) is indefinite. Although
H(x) is positive semidefinite at (0,0) this does not allow us
to conclude that x* is a local minimum. Notice that f(x)
can be made arbitrarily small or large with the appropriate
choices of x.
These last two examples suggest that for nonquadratic
functions of several variables, the determination of the
character of a stationary point can be difficult even when
the Hessian matrix is semidefinite. Indeed, a much more
complex mathematical theory is required for the general
case.
26
Summary for Unconstrained Optimization
Table 10.1 summarizes the relationship between the
optimality of a stationary point x* and the character of the
Hessian evaluated at x*. It is assumed that f(x) is twice
differentiable and ▽f(x*) = 0.
If H(x) exhibits either of the first two definiteness properties
for all x, then "local" can be replaced with "global" in the
associated characterizations. Furthermore, if f(x) is
quadratic, a positive semidefinite Hessian matrix implies a
nonunique global minimum at x*.
27
Notice that although convexity in the neighborhood of x* is
sufficient to conclude that x* is a weak local minimum, the
fact that H(x*) is positive semidefinite is not sufficient, in
general, to conclude that f(x) is convex in the
neighborhood of x*.
28
When H(x*) is positive semidefinite, it is possible that points
in a small neighborhood of x* can exist such that f(x)
evaluated at those points will produce smaller values than
f(x*). This would invalidate the conclusion of convexity in
the neighborhood of x*.
As a final example in this section, consider
f ( x) 2 x13 4 x12 x22 2 x1 x23 5 x1 x33 x22 x3 3x33
for which
6 x12 8 x1 x22 2 x23 5 x33
2
2
f ( x) 8 x1 6 x1 x2 2 x2 x3
15 x x 2 x 2 9 x 2
1 3
2
3
29
• and
12 x1 8 x22
H ( x) 16 x1 x2 6 x22
15 x32
16 x1 x2 6 x22
8 x12 12 x1 x2 2 x3
2 x2
2 x2
30 x1 x3 18 x3
15 x32
Looking at the Hessian matrix, it is virtually impossible to
make any statements about the convexity of f(x). This gives
us a glimpse of the difficulties that can arise when one
attempts to solve unconstrained nonlinear optimization
problems by directly applying the classical theory. In fact,
the real value of the theory is that it offers insights into the
development of more practical solution approaches.
Moreover, once we have a stationary point x* obtained
from one of those approaches, it is relatively easy to check
the properties of H(x*), because only numerical
evaluations are required.
30
A Taylor series is a series expansion of a
function about a point. A one-dimensional
Taylor series is an expansion of a real
function about a point a is given by
If a=0, the expansion is known as a
Maclaurin series.
31
Taylor expansion of f(x) at x0 is:
( x x0 ) 2
( x x0 )3
( x x0 ) 4 ( 4)
f ( x) f ( x0 ) ( x x0 ) f ( x0 )
f ( x0 )
f ( x0 )
f ( x0 ) ...
2!
3!
4!
Note:
f x Pn x Rn x , for x, x0 a, b
f k x0
x x0 k
Pn x
k!
k 0
k
d
f k x0 k f |x x0
dx
n
f n 1 x
n 1
x x0
Rn x
n 1!
32
Nonnegative Variables
A simple extension of the unconstrained optimization
problem involves the addition of non-negativity
restrictions on the variables.
Minimize [f(x):x≧0]
(3)
Suppose that f has a local minimum at x*, where x*≧0. Then
there exists a neighborhood Nε(x*) of x* such that
whenever x Nε(x*) and x > 0, we have f(x) ≧ f(x*). Now
write x = x* + td, where d is a direction vector and t > 0.
Assuming that f is twice continuously differentiable
throughout Nε(x*), a second-order Taylor series expansion
of f(x* + td) around x* yields
33
t T 2 *
f ( x ) f ( x) f ( x td ) f ( x ) f ( x )td d f ( x td )td
2
*
*
*
*
• where α [0,1]. Canceling terms and dividing through by t
yields
t T 2
0 f ( x ) d d f ( x* td )d
2
*
As t —> 0, the inequality becomes 0 ≦▽f(x*)d, which says that f
must be nondecreasing in any feasible direction d.
Hence, if x* > 0, we know that ▽f(x*) = 0.
With a bit more analysis, it can be shown that the following
conditions are necessary for x* to be a local minimum of f(x).
34
f ( x * )
0, if
x j
f ( x * )
0, if
x j
x *j 0
x *j 0
These results are summarized as follows.
Theorem 3: Necessary conditions for a local minimum of f in
Problem (3) to occur at x* include
▽f(x*)≧0, ▽f(x*)x*=0, x*≧0
(4)
where f is twice continuously differentiable throughout a
neighborhood of x*.
35
Example 8
Minimize f(x) = 3x 2 x 2 x 2 2 x x 2 x x 2 x
1
2
3
1 2
1 3
1
subject to x1≧0, x2≧0, x3≧0
Solution: From Conditions (4), we have the following necessary
conditions for a local minimum.
a.
0
f
6 x1 2 x2 2 x3 2
x1
b.
0 x1
f
x1 (6 x1 2 x2 2 x3 2)
x1
c.
0
f
2 x2 2 x1
x2
d.
0 x2
e.
0
f.
g.
f
x2 ( 2 x2 2 x1 )
x2
f
2 x3 2 x1
x3
0 x3
f
x3 (2 x3 2 x1 )
x3
x1 0, x2 0, x3 0
36
From condition (d), we see that either x2 = 0 or x1 =
x2. When x2 = 0, conditions (c) and (g) imply that
x1 = 0. From condition (f) then, x3 = 0. But this
contradicts condition (a),
x2 ≠0 and x1 = x2.
37
Condition (f) implies that either x3 = 0 or x1 = x3. If x3 = 0,
then conditions (d), (e), and (g) imply that x1= x2 = x3 = 0.
But this situation has been ruled out. Thus, x1= x2 = x3 , and
from condition (b) we get x1 = 0 or x1 = 1. Since x1≠0, the
only possible relative minimum of f occurs when x1= x2
=x3= 1. To characterize the solution at x* = (1, 1, 1) we
evaluate the Hessian matrix.
6
H 2
2
2
2
0
2
0
2
which is easily shown to be positive definite. Thus, f is
strictly convex and has a strong local minimum at x*. It
follows from Theorem 2 in Chapter 9 that f(x*) = 1 is a
global minimum.
38
Necessary Conditions for Optimality
Equality constraints :
Minimize f(x) subject to gi(x) = 0, i = 1,..., m
(5)
The objective and constraint functions are assumed to be at
least twice continuously differentiable.
Furthermore, each of the gi(x) subsumes the constant term bi.
To provide intuitive justification for the general results,
consider the special case of Problem (5) with two decision
variables and one constraint—i.e.,
Minimize f(x1, x2)
subject to g(x1, x2)=0
39
To formulate the first-order necessary conditions,
we construct the Lagrangian
( x1 , x2 , ) f ( x1, x2 ) g ( x1 , x2 )
here λ is an unconstrained variable called the
Lagrange multiplier.
Our goal now is to minimize the unconstrained
function . As in Section 10.1, we construct the
gradient of the Lagrangian with respect to its
decision variables x1 and x2 and the multiplier λ.
Setting the gradient equal to zero, we obtain
40
f
f
( x1 , x2 , )
( x1 , x2 )
g ( x1 , x2 )
x1
x1
0
( x1 , x2 )
g ( x1 , x2 )
0
x2
x2
0
g ( x1 , x2 )
(6)
which represents three equations in three unknowns.
Using the first two equations to eliminate λ, we have
f g
f g
0,
x1 x2 x2 x1
g x1 , x2 0
which yields a stationary point x* and λ* when solved.
From Equation (6), we see that ▽f(x1 , x2)and ▽g(x1 , x2) are
coplanar at this solution ,i.e., ▽f(x1 , x2)= λ ▽g(x1 , x2) .
41
It is a simple matter to extend these results to the general case.
The Lagrangian is
m
( x, ) f ( x) i g i ( x)
i 1
where λ = ( 1 ,..., m ) is an m-dimensional row vector. Here,
every constraint has an associated unconstrained multiplier i.
Setting the partial derivatives of the Lagrangian with respect
to each decision variable and each multiplier equal to zero
yields the following system of n + m equations. These
equations represent the first-order necessary conditions for an
optimum to exist at x*.
m
g i ( x)
f ( x)
i
0, j 1,..., n
x j
x j
x j
i 1
g i ( x) 0, i 1,..., m
i
(7a)
(7b)
42
A solution to Equations (7a) and (7b) yields a stationary point
(x*, λ*); however, an additional qualification must be placed on
the constraints in Equation (7b) if these conditions are to be
valid.
The most common qualification is that the gradients of the
binding constraints are linearly independent at a solution.
Because Equations (7a) and (7b) are identical regardless of
whether a minimum or maximum is sought, additional work is
required to distinguish between the two.
Indeed, it may be that some selection of the decision variables
and multipliers that satisfies these conditions determines a
saddle point of f(x) rather than a minimum or maximum.
43
Example 10
Minimize f(x) = (x1 + x2)2 subject to - (x1 – 3)3 +x22= 0
The Lagrangian is ( x, ) ( x x )2 ( x 3)3 x 2
1
2
1
2
Now, setting partial derivatives equal to zero gives three highly
nonlinear equations in three unknowns:
2( x1 x2 ) 3( x1 3) 2 0,
x1
2( x1 x2 ) 2x2 0
x2
( x1 3)3 x22 0
44
The feasible region is illustrated in Figure 10.3.
Notice that the two parts of the constraint corresponding to the
positive and negative values of x2 form a cusp. At the endpoint
(3,0), the second derivatives are not continuous, foreshadowing
trouble.
In fact, x = (3, 0) is the constrained global minimum, but on
substitution of this point into the necessary conditions, we find
that the first two equations are not satisfied.
Further analysis reveals that no values of x1 , x2, and λ will
satisfy all three equations. (Constraint qualification is not
satisfied.)
45
The difficulty is that the constraint surface is not smooth, implying
that the second derivatives are not everywhere continuous.
Depending on the objective function, when such a situation arises
the first-order necessary conditions [Equations (7a) and (7b)] may
not yield a stationary point.
46
INEQUALITY CONSTRAINTS :
The most general NLP model that we investigate is
Minimize f(x)
subject to
hi ( x) 0, i 1,..., p
gi ( x) 0, i 1,..., m
where an explicit distinction is now made between the
equality and inequality constraints. In the model, all
functions are assumed to be twice continuously
differentiable, and any RHS constants are subsumed in the
corresponding functions hi(x) or gi (x). Problems with a
maximization objective or ≧ constraints can easily be
converted into the form of above problem. Although it is
possible and sometimes convenient to treat variable bounds
explicitly, we assume that they are included as a subset of
the m inequalities.
47
Karush-Kuhn-Tucker (KKT) Necessary Conditions
To derive first- and second-order optimality conditions for
this problem, it is necessary to suppose that the constraints
satisfy certain regularity conditions or constraint
qualifications, as mentioned previously.
The accompanying results are important from a theoretical
point of view but less so for the purposes of designing
algorithms. Consequently, we take a practical approach and
simply generalize the methodology used in the
developments associated with the equality constrained
Problem (5).
48
In what follows, let h(x) = (h1(x),..., hP(x))T and g(x) =
(g1(x),..., gm(x)) T. For each equality constraint we define
an unrestricted multiplier, λi, i= 1,..., p, and for each
inequality constraint we define a nonnegative multiplier,μi,
i = 1,..., m. Let X, λ and μ be the corresponding row
vectors. This leads to the Lagrangian for Problem (8).
p
m
i 1
i 1
( x, , ) f ( x) i hi ( x) i gi ( x)
Definition 1: Let x* be a point satisfying the constraints h(x*)
= 0, g(x*) ≦0 and let K be the set of indices k for which
gk(x*) = 0. Then x* is said to be a regular point of these
constraints if the gradient vectors ▽hj(x*) (1 ≦ j≦p),
▽gk (x*) (k K) are linearly independent (equality part).
49
Theorem 4 (Karush-Kuhn-Tucker Necessary Conditions):
Let x* be a local minimum for Problem (8) and suppose
that x* is regular point for the constraints. Then there
m
exists a vector * p and a vector μ* such
that
f ( x* ) p * hi ( x* ) m * g i ( x* )
i
i
0
x j
x j
x
x
i 1
i 1
j
j
hi ( x * ) 0 ,
i
g i ( x* ) 0 ,
i
i 1,..., p
j 1,..., n
(9a)
(9b)
i 1,..., m
(9c)
i* g i ( x* ) 0 , i 1,..., m
(9d)
i* 0 , i 1,..., m
(9e)
50
Constraints (9a) to (9e) were derived in the early
1950s and are known as the Karush-Kuhn-Tucker
(KKT) conditions in honor of their developers. They
are first-order necessary conditions and postdate
Lagrange's work on the equality constrained Problem
(5) by 200 years.
The first set of equations [Constraint (9a)] is referred
to as the stationary conditions and is equivalent to
dual feasibility in linear programming.
Constraints (9b) and (9c) represent primal feasibility,
and Constraint (9d) represents complementary
slackness.
Nonnegativity of the "dual" variables appears
explicitly in Constraint (9e).
51
In vector form, the system can be written as
▽f(x*) +λ*▽h(x*) + u*▽g(x*) = 0
h(x*)=0,
g(x*)≦0,
μ*g(x*)=0,
μ*≧0
52
For the linear program, the KKT conditions are necessary
and sufficient for global optimality. This is a result of the
convexity of the problem and suggests the following, more
general result.
Theorem 5 (Karush-Kuhn-Tucker Sufficient Conditions): For
Problem (8), let.f(x) and gi(x) be convex, i = 1,..., m, and
let hi(x) be linear, i = 1,..., p. Suppose that x* is a regular
point for the constraints and that there exist a λ* and aμ*
such that (x*, λ*, μ*) satisfies Constraints (9a) to (9e).
Then x* is a global optimal solution to Problem (8). If the
convexity assumptions on the objective and constraint
functions are restricted to a neighborhood Nε(x*) for some
ε > 0, then x* is a local minimum of Problem (8). (If we
are maximizing f(x), f(x) must be concave.)
53
Sufficient Conditions
The foregoing discussion has shown that under certain
convexity assumptions and a suitable constraint
qualification, the first-order KKT conditions are necessary
and sufficient for at least local optimality. Actually, the
KKT conditions are sufficient to determine if a particular
solution is a global minimum if it can be shown that the
solution (x*, λ*, μ*) is a saddle point of the Lagrangian
function. (The other case where KKT is sufficient.)
Definition 2; The triplet (x*, λ*, μ*) is called a saddle point
of the Lagrangian function if μ*≧ 0 and
( x* , , ) ( x* , * , * ) ( x, * , * )
for all x and λ, and μ ≧ 0
54
Hence, x* minimizes
over x when (λ, μ) is fixed at (λ*,
μ*), and (λ*, μ*) maximizes over (λ, μ) with μ ≧ 0 when
x is fixed at x*. This leads to the definition of the dual
problem in nonlinear programming.
Lagrangian Dual: Maximize {(, ) : free, 0} (10)
where ( , ) Min x { f ( x) h( x) g ( x)}
When all the functions in Problem (8) are linear, Problem
(10) reduces to the familiar LP dual.
In general, Ψ(λ, μ) is a concave function; for the LP it is
piecewise linear as well as concave.
55
Theorem 6 (Saddle Point Conditions for Global Minimum):
A solution (x*, λ*, μ*) with μ* ≧ 0 is a saddle point of the
Lagrangian function if and only if
• a.
x* minimizes (x, λ *, μ*)
• b.
g(x*)<0, h(x*)=0
• c.
μ*g(x*)=0
Moreover, (x*, λ*, μ*) is a saddle point if and only if x*
solves Problem (8) and (λ*, μ*) solves the dual Problem
(10) with no duality gap—that is,f(x*) = Ψ(λ*, μ*).
56
Under the convexity assumptions in Theorem 4, the KKT
conditions are sufficient for optimality. Under weaker
assumptions such as nondifferentiability of the objective
function, however, they are not applicable. Table 10.2
summarizes the various cases that can arise and the
conclusions that can be drawn from each.
57
Example 11
Use the KKT conditions to solve the following problem.
Minimize f(x) = 2(x1 + 1)2 + 3(x2- 4)2
subject to x12 x22 9 , x1 x2 2
Solution: It is straightforward to show that both the
objective function and the feasible region are convex.
Therefore, we are assured that a global minimum exists
and that any point x* that satisfies the KKT conditions will
be a global minimum. Figure 10.4 illustrates the constraint
region and the isovalue contour f(x) = 2.
The partial derivatives required for the analysis are
f
4( x1 1) ,
x1
f
6( x2 4) ,
x2
g1
g 2
2 x1 ,
1
x1
x1
g1
g 2
2 x2 ,
1
x2
x2
58
Note that we have rewritten the second constraint as a ≦
constraint prior to evaluating the partial derivatives. Based
on this information, the KKT conditions are as follows.
a. 4( x1 1) 1 (2x1 ) 2 0 , 6( x2 4) 1 (2x2 ) 2 0
b.
x12 x22 9 0 ,
c.
1 ( x12 x22 9) 0 , 2 ( x1 x2 2) 0
d.
1 0 ,
x1 x2 2 0
2 0
59
60
Explicit Consideration of Nonnegativity Restrictions
Nonnegativity is often required of the decision variables.
When this is the case, the first-order necessary conditions
listed as Constraints (9a) to (9e) can be specialized in a
way that gives a slightly different perspective.
Omitting explicit treatment of the equality constraints, the
problem is now
Minimize {f(x):gi(x)≦0, i=1,…,m ; x ≧ 0}
61
The Karush-Kuhn-Tucker conditions for a local minimum are as
follows.
m
g i
f ( x* )
i*
0,
x j
x j
x j
i 1
g i ( x* ) 0 ,
i
xj
0,
xi
i 1,..., m
j 1,..., n
i* g i ( x * ) 0 ,
x*j 0 ,
j 1,..., n
i 1,..., m
j 1,..., n ; i* 0 , i 1,..., m
(11 a)
(11 b)
(11 c)
(11 d)
(11 e)
62
Example 12
Find a point that satisfies the first-order necessary
conditions for the following problem.
Minimize f(x) = x12 4 x22 8 x1 16 x2 32
subject to x1 + x2≦5, x1≧ 0, x2 ≧0
Solution: We first write out the Lagrangian function
excluding the nonnegative conditions.
( x1 , x2 , ) x12 4 x22 8 x1 16 x2 32 ( x1 x2 5)
The specialized KKT conditions [Constraints (11 a) to (l1e)]
are
a.
2 X1-8+μ ≧0, 8 X2-16+μ ≧0
b.
X1+ X2-5≦0
c.
X1(2 X1- 8 + μ )= 0, X2(8 X2 - 16 + μ) = 0
d.
μ(X1 + X2 - 5) = 0
e.
X1 ≧ 0, X2≧0, μ ≧0
63
Let us begin by examining the unconstrained optimal
solution x = (4,2). Because both primal variables are
nonzero at this point, condition (c) requires that μ = 0. This
solution satisfies all the constraints except condition (b).
Primal feasibility, suggesting that the inequality X1 + X2 ≦
5 is binding at the optimal solution. Let us further suppose
that x > 0 at the optimal solution. Condition (c) then
requires 2 X1 - 8 + μ = 0 and 8 X2 - 16 + μ = 0. Coupled
with X1 + X2 = 5, we have three equations in three
unknowns. Their solution is x = (3.2,1.8)and = 1.6,
which satisfies Constraints (1la) to (l1e) and is a regular
point. Given that the objective function is convex and the
constraints are linear, these conditions are also sufficient.
Therefore, x* = (3.2,1.8) is the global minimum.
64
Summary
Necessary conditions for local minimum:
• Unconstrained problems (Min f(x) ):
a. ▽f(x*)=0
b. H(x*) is positive semidefinite.
• Min f(x), s.t. x ≧0:
a. ▽f(x*)≧0
b. ▽f(x*)x*=0
c. x*≧0
65
• Min f(x), s.t. h(x)=0:
a. ▽f(x*)+λ▽h(x*) =0
b. h(x*) =0.
• Min f(x), s.t. h(x)=0, g(x) ≦0:
a. ▽f(x*) +λ*▽h(x*) + u*▽g(x*) = 0
b. h(x*)=0
c. g(x*)≦0
d. μ*g(x*)=0
e. μ*≧0
66
• Min f(x), s.t. g(x) ≦0, x ≧ 0:
a. ▽f(x*) +u*▽g(x*) ≧ 0
b. g(x*)≦0
c. x*{▽f(x*) +u*▽g(x*) }=0
d. μ*g(x*)=0
e. μ*≧0
f. x* ≧ 0
67
10.4 SEPARABLE PROGRAMMING
Problem Statement
Consider the general NLP problem Minimize {f(x): gi(x) ≦ bi ,
i= 1,..., m} with two additional provisions: (1) the objective
function and all constraints are separable, and (2) each decision
variable Xj is bounded below by 0 and above by a known
constant μj,j = 1,..., n.
Recall that a function f(X) is separable if it can be expressed as
the sum of functions of the individual decision variables.
n
f ( x) f j ( x j )
j 1
68
The separable NLP has the following structure.
Minimize
f ( x)
n
j 1
n
subject to
g
j 1
ij
( x j ) bi ,
f
j
(x j )
i 1,..., m
0< Xj < μj j=1,..., n
The key advantage of this formulation is that the nonlinearities
are mathematically independent. This property, in conjunction
with the finite bounds on the decision variables, permits the
development of a piecewise linear approximation for each
function in the problem.
69
Consider the general nonlinear function f(X) depicted in
Figure 10.5. To form a piecewise linear approximation
using, say, r line segments, we must first select r + 1 values
of the scalar x within its range 0≦x≦μ (call
them x0 , x1 , ..., x r ) and let f k=f( x r )for k = 0,1, ..., r. At
the boundaries we have x0= 0 and xk = u. Notice that the
values of x0 , x1 ,…, x r
do not have to be evenly spaced.
70
Recall that any value of x lying between the two endpoints of
the kth line segment may be expressed as
x xk 1 (1 ) xk or x xk ( xk 1 xk )
for
0 1
where x k (k = 0,1,..., r) are data and α is the decision
variable. This relationship leads directly to an expression for
the kth line segment.
^
f ( x) f k
f k 1 f k
( x x k ) f k 1 (1 ) f k for
x k 1 x k
0 1
71
^
The approximation f (x) becomes increasingly more
accurate as r gets larger. Unfortunately, there is a
corresponding growth in the size of the resultant problem.
For the kth segment, let α =αk+1 and let (1 - α) = αk. As such,
for
expression for x becomes
xk x xthe
k 1
x k 1 x k 1 k x k and
^
f ( x) k 1 f k 1 k f k
where αk +αk+1 = 1 and αk ≧ 0, αk+1 ≧0.
Generalizing this procedure to cover the entire range over
which x is defined yields
r
^
r
x k x k , f ( x) k f k ,
k 0
k 0
r
k 0
k
1, k 0 , k 1,..., r
72
such that at least one and no more than two αk can be greater than
zero.
Furthermore, we require that if two αk are greater than zero, their
indices must differ by exactly 1. In other words, if αs is greater
than zero, then only one of either αs+1 or αs-1 can be greater than
zero.
If this last condition, known as the adjacency criterion, is not
^
satisfied, the approximation to f(x)will not lie on f (x).
The separable programming problem in x becomes the following
"almost" linear program in α.
73
rj
n
Minimize f(α)=
j 1 k 0
Subject to
n
jk
f jk ( x jk )
rj
gi ( ) jk gijk ( x jk ) b , i 1,..., m
j 1 k 0
rj
k 0
jk
1,
j 1,..., n
αjk≧0, j=1,…,n k=0,…, rj
74
Example 13
Consider the following problem, whose feasible region is shown graphically
in Figure 10.6. All the functions are convex, but the second constraint is
g2(x) ≧10. Because g2 (x) is not linear, this implies that the feasible
region is not convex, and so the solution to the approximate problem may
not be a global optimal solution.
Minimize f(x) = 2 x12 3x1 2 x2
subject to
g1 ( x) 3x12 4 x22 8
g 2 ( x) 3( x1 2) 2 5( x2 2) 2 10
g 3 ( x) 3( x1 2) 2 5( x2 2) 2 21
0≦x1≦1.75 ,0 ≦x2 ≦1.5
75
76
The upper bounds on the variables have been selected to be
redundant. The objective function and constraints are
separable, with the individual terms being identified in
Table 10.3.
To develop the piecewise linear approximations, we select
six grid points for each variable and evaluate the functions
at each point. The results are given in Table 10.4. For this
example, n=2, m=3, r1=5, and r2 = 5. As an illustration, the
piecewise linear approximations of f1(x) and g12(x), along
with the original graphs, are depicted in Figure 10.7. The
full model has five constraints and 12 variables. The
coefficient matrix is given in Table 10.5 where the last two
rows correspond to the summation constraints on the two
sets of a variables.
77
The problem will be solved with a linear programming code
modified to enforce the adjacency criterion. In particular,
for the jth variable we do not allow an αjk variable to enter
the basis unless αj,k-1 or αj,k+1 is already in the basis, or no
αj,k {k = 0,1,..., 5) is currently basic. The following slack
and artificial variables are used to put the problem into
standard simplex form.
• s1 = slack for constraint 1, g1
• s2 = surplus for constraint 2, g2
• a2 = artificial for constraint 2, g2
• s3 = slack for constraint 3, g2
• a4 = artificial for constraint 4,
• a5 = artificial for constraint 5,
The initial basic solution is
Xg = (s1, a2, s3, a4 , a5) = (8,10,21,1,1)
78
79
80
QUADRATIC PROGRAMMING
A linearly constrained optimization problem with a quadratic
objective function is called a quadratic program (QP).
Because of its many applications, quadratic programming
is often viewed as a discipline in and of itself. More
importantly, however, it forms the basis for several general
NLP algorithms. We begin by examining the KarushKuhn-Tucker conditions for the QP and discovering that
they turn out to be a set of linear equalities and
complementary constraints. Much as for the separable
programming problem, a modified version of the simplex
algorithm can be used to find solutions.
81
Problem Statement
The general quadratic program can be written as
1 T
Minimize f(x) = cx + x Qx
2
subject to Ax≦ b and x≧0
where c is an n-dimensional row vector describing the
coefficients of the linear terms in the objective function
and Q is an (n×n) symmetric matrix describing the
coefficients c the quadratic terms; If a constant term exists,
it is dropped from the model.
As in lines programming, the decision variables are denoted
by the n-dimensional column vector x and the constraints
are defined by an (m x n) A matrix and an m-dimensional
column vector b of RHS coefficients. We assume that a
feasible solution exists and that the constrain region is
82
bounded.
Karush-Kuhn-Tucker Conditions
We now adapt the first-order necessary conditions given in
Section 10.3 to the quadratic program. These conditions
are sufficient for a global minimum when Q is positive
definite ; otherwise, the most we can say is that they are
necessary.
Excluding the nonnegativity conditions, the Lagrangian
function for the Quadratic program is
1 T
( x, ) cx x Qx ( Ax b)
2
83
where μ is an m-dimensional row vector. The KKT
conditions for a local minimum are as follows.
T
0, j 1,..., n c x Q A 0
x j
0, i 1,..., m Ax b 0
i
(12a)
(12b)
T T
T
x j 0, j 1,..., n x (c Qx A ) 0
x j
i gi ( x) 0, i 1,..., m ( Ax b) 0
x j 0, j 1,..., n x 0
(12d )
i 0, i 1,..., m 0
(12e)
(12c)
(12c)
84
To put Conditions (12a) to (12f) into a more manageable
form, we introduce nonnegative surplus variables y n to
the inequalities in Condition (12a) and nonnegative slack
variables v to the inequalities in Condition (12b) to obtain
the equations
CT + Qx + AT μT-y=O and Ax-b+v=0
The KKT conditions can now be written with the constants
moved to the right-hand-side
Qx + A TμT - y = -CT
Ax + v = b
x≧O,μ≧0,y≧0,v≧0
yTx=O,μv= O
(13a)
(13b)
(13c)
(13d)
85
Solving for the Optimal Solution
The simplex algorithm can be used to solve Equations (13a)
to (13d) by treating the complementary slackness
conditions [Equation (13d)] implicitly with a restricted
basis entry rule. The procedure for setting up the LP model
follows.
• Let the structural constraints be Equations (13a) and (13b)
defined by the KKT conditions.
• If any of the RHS values are negative, multiply the
corresponding equation by -1.
• Add an artificial variable to each equation.
• Let the objective function be the sum of the artificial
variables.
• Convert the resultant problem into simplex form.
86
Example 14
Solve the following problem.
2
2
x
4x
Minimize f(x) = -8 x1 -16 x2 +
1
2
subject to x1 + x2 ≦ 5, x1 ≦ 3, x1 ≧0, x2 ≧0
87
Solution: The data and variable definitions are given below. As we
can see, the Q matrix is positive definite, so the KKT conditions
are necessary and sufficient for a global optimal solution.
8
c
,
16
T
X T ( x1 , x2 ),
2 0
Q
,
0 8
1 1
5
A
, b
1 0
3
yT ( y1 , y2 ), (1 , 2 )
vT (v1 , v2 )
88
The linear constraints [Equations (13a) and (13b)] take the
following form.
2x1
+μ1+μ2–y1
8x2+μ1
x1 + x2
=8
–y2
+v1
x1
=16
=5
+v2
=3
89
To create the appropriate linear program, we add artificial
variables to each constraint and minimize their sum.
Minimize a1 + a2+ a3 + a4
subject to 2x1
+μ1+μ2–y1
8x2+μ1
x1 + x2
x1
+ a1
–y2
+v1
+v2
+ a2
=8
=16
+a3
=5
+a4
=3
All variables ≧ 0 and subject to complementary conditions.
90
10.6 ONE-DIMENSIONAL SEARCH METHODS
The basic approach to solving almost all mathematical
programs in continuous variable is to select an initial point
x° and a direction d° in which the objective function is
improving, and then move in that direction until either an
extremum is reached or a constraint i violated. In either
case, a new direction is computed and the process is
repeated. A check for convergence is made at the end of
each iteration. At the heart of this approach is a one
dimensional search by which the length of the move, called
the step size, is determined. That is, given a point xk and a
direction dk at iteration k, the aim is to find an optimal step
size tk that moves us to the next point xk+1 =xk+ tk dk.
91
Unimodal Functions
Out of practical considerations, we define an interval of
uncertainty [a, b] in which the minimum of f(x) must lie. This
leads to the one-dimensional problem
Minimize {f(x): x [a, b ]}
(14)
For simplicity, it will also be assumed that f(x) is continuous and
unimodal in the interval [a, b], implying that f(x) has a single
minimum x*—that is, for x [a, b] such that f(x) ≠ f(x*), f is
strictly decreasing when x < x* and strictly increasing when x
> x*. In the case of a minimization problem, the stronger
property of strict convexity implies unimodality, but
unimodality does not imply convexity. This fact is illustrated
by the unimodal functions shown in Figure 10.9. Each function
is both concave and convex in subregions but exhibits only one
relative minimum in the entire range.
92
93
During a search procedure, if we could exclude portions
of [a, b] that did not contain the minimum, then the
interval of uncertainty would be reduced. The
following theorem shows that it is possible to obtain a
reduction by evaluating two points within the interval.
Theorem 7: Let f be a continuous, unimodal function
of a single variable defined over the interval [a, b].
Let X1, X2 [a, b] be such that X1 < X2.
If f(X1)≧f(X2), then f(x)≧f(X2) for all x [a, X1].
If f(X1)≦f(X2) then f(x)≧f(X1)for all x [X2, b].
94
Dichotomous Search Method
Under the restriction that we may evaluate f(x) only at
selected points, our goal is to find a technique that will
provide either the minimum or a specified interval of
uncertainty after a certain number n of evaluations of the
function. The simplest method of doing this is known as
the dichotomous search method.
Without loss of generality, we restrict our attention to
Problem (14). Let the unknown location of the minimum
value be denoted by x*.
95
The dichotomous search method requires a specification of
the minimal distance ε > 0 between two points X1 and X2
such that one can still be distinguished from the other. The
first two measurements are made at ε on either side of the
center of the interval [a, b], as shown in Figure 10.11.
X1 = 0.5(a + b - ε) and X2 = 0.5(a + b + ε)
96
On evaluating the function at these points, Theorem 7 allows
us to draw one of three conclusions.
• if f(X1) < f(X2), x*must be located between a and X2. This
indicates that the value of b should be updated by setting b
to X2.
• if f(X2) < f(X1), x* must be located between X1 and b. This
indicates that the value of a should be updated by setting a
to X1.
• if f(X2) =f(X1), x*must be located between X1 and X2. This
indicates that both end-points should be updated by setting
a to X1 and b to X2.
97
98
Golden Section Search Method
In the preceding approach, all new evaluations were used at
each iteration. Suppose instead that at each iteration after
the first we use a combination of one new evaluation and
one old evaluation. This should result in a significant
reduction of computational effort if comparable results can
be achieved. One method of implementing this approach
was inspired by a number commonly observed in nature. In
the architecture of ancient Greece, for example, a method
of dividing a distance measured from point a to point b at a
point c was called a golden section if
c a b c (b a) (c a)
ba ca
ca
99
Dividing the numerators and denominators of each term by
b - a and letting γ= (c - a)/ (b - a) yields
1
where γ is known as the golden section ratio. Solving for γ
is equivalent to solving the quadratic equation γ2 + γ- 1 = 0,
whose positive root is γ= (
- 1)/25= 0.618. The negative
root would imply a negative ratio, which has no meaning
from a geometric point of view
100
We now use the concept of the golden section to develop
what is called the golden section search method. This
method requires that the ratio of the new interval of
uncertainty to the preceding one always be the same. This
can be achieved only if the constant of proportionality is
the golden section ratio γ.
To implement the algorithm, we begin with the initial
interval [a, b] and place the first two search points
symmetrically at
X1= a + (1 – γ)(b - a) = b -γ(b - a) and X2= a + γ(b - a)
(16)
as illustrated in Figure 10.13.
By construction, we have X1- a = b – X2, which is
maintained throughout the computations.
101
For successive iterations, we determine the interval
containing the minimal value of f(x), just as we did in the
dichotomous search method. The next step of the golden
section method, however, requires only one new evaluation
of f(x) with x located at the new golden section point of the
new interval of uncertainty. At the end of each iteration,
one of the following two cases arises (see Figure 10.13).
•
Case 1: If f(X1) > f(X2) , the left endpoint a is updated by
setting a to X1 and the new X1 is set equal to the old X2
A new X2 is computed from Equation (16).
• Case 2: If f(X1)≦f(X2), the right endpoint b is updated by
setting b to X2 and the new X2 is set equal to the old X1.
A new X1is computed from Equation (16).
102
We stop when b - a < ε, an arbitrarily small number. At
termination, one point remains in the final interval, either
X1or X2. The solution is taken as that point.
It can be shown that after k evaluations, the interval of
uncertainty, call it dk, has width
dk
k 1
d1
(17)
where d1= b - a (initial width). From this it follows that
d k 1
0.618
dk
(18)
103
Table 10.9 provides the results for the same example used to
illustrate the dichotomous search method. From the table
we see that after 12 function evaluations (11 iterations) the
minimum point found is X2= 2.082 with f= 14.189996. The
true optimal solution is guaranteed to lie in the range
[2.0782,2.0882]. The width of this interval is 0.01 unit,
which is less than one-fourth of the interval yielded by the
dichotomous search method with the same number of
evaluations. Equation (17) indicates that the interval of
uncertainty after 12 evaluations is similarly 0.01 unit The
reader can verify that successive ratios are all
(approximately) equal to γ, as specified by Equation (18).
For example, for k = 7 we have at the completion of
iteration 6 the ratio d6 /d5 = (2.1246 - 1.9443)/(2.2361 1.9443) = 0.61789 ≡ γ, with the error attributable to
rounding.
104
105
106
Newton's Method
When more information than just the value of the function
can be computed at each iteration, convergence is likely to
be accelerated. Suppose that f(x) is unimodal and twice
continuously differentiable. In approaching Problem (14),
also suppose that at a point Xk where
a measurement is made, it is possible to determine the
following three values: f(Xk), f'(Xk,), and f"(Xk). This
means that it is possible to construct a quadratic function
q(x) that agrees with f(x) up to second derivatives at Xk.
Let
q ( x ) f ( xk ) f ( xk )( x xk )
1
f ( xk )( x xk ) 2
2
107
As shown in Figure 10.14a, we may then calculate an estimate
xk 1 of the minimum point of f by finding the point at which
the derivative of q vanishes. Thus, setting
o= q'(Xk+1)= f'(Xk)+f"( Xk)( Xk+1 - Xk)
we find
xk 1
f ' ( xk )
xk "
f ( xk )
(19)
which, incidentally, does not depend on f(Xk). This process can
then be repeated until some convergence criterion is met,
typically | Xk+1 - Xk | < εor |f'(Xk)| <ε, where ε is some small
number.
108
Newton's method can more simply be viewed as a technique
for iteratively solving equations of the form φ(x) = 0,
where φ(x) =f’(x) when applied to the line search problem.
In this notation, we have Xk+1 = Xk -φ(Xk) /φ'(Xk). Figure
10.14b geometrically depicts how the new point is found.
The following theorem gives sufficient conditions under
which the method will converge to a stationary point.
Theorem 8: Consider the function f(x) with continuous first
and second derivatives f'(x) and f”(x). Define φ(x) =f’(x)
and φ’(x) =f"(x) and let x* satisfy φ(x*) = 0, φ'(x*)≠0.
Then, if X1 is sufficiently close to x*, the sequence
generated by Newton's method [Equation (19)] converges
to x* with an order of convergence of at least 2.
109
The phrase "convergence of order ρ" will be defined
presently, but for now it means that when the iterate Xk is
in the neighborhood of x*, the distance from x* at the next
iteration is reduced by the ρth power. Mathematically, this
*
xk 1 x * xk , x
can be stated as
where
β< ∞ is some
constant. The larger the order ρ, the faster the convergence.
When second derivative information is not available, it is
possible to use first-order information to estimate f"(Xk) in
the quadratic q(x). By letting f"(Xk)
(f'(Xk-1) - f'(Xk)) /
(Xk-1- Xk), the equivalent of Equation
(19) is
110
111
xk 1 xk
xk 1 xk f ( xk ) '
'
f ( xk 1 ) f ( xk )
'
which gives rise to what is called the method of false
position. Comparing this formula with that of Newton's
method [Equation (19)], we see again that the value f(Xk)
does not enter.
112
General Descent Algorithm
The general descent algorithm starts at an arbitrary point, x°
and proceeds for some distance in a direction that improves
(decreases) the objective function. Arriving at a point that
has a smaller objective value than x°, the process finds a
new improving direction and moves in that direction to a
new point with a still smaller objective. In theory, the
process could continue until there are no improving
directions, at which point the algorithm would report a
local minimum. In practice, the process stops when one or
more numerical convergence criteria are satisfied. The
algorithm is stated more formally below.
113
• 1. Start with an initial point x°. Set the iteration counter k to 0.
• 2. Choose a descent direction d k.
• 3. Perform a line search to choose a step size tk such that
wk (t k ) f ( x k t k d k ) wk (t k 1 )
• 4. Set x k+1 =x k +tkd k.
• 5. Evaluate convergence criteria. If satisfied, stop; otherwise, increase
•
k by 1 and go to Step 2.
An exact line search is one that chooses tk as the first local minimum of
wk(tk) at Step 3— i.e., the one with the smallest t value. Finding this
minimum to high accuracy is overly time consuming, so modem NLP
codes use a variety of inexact line search techniques often involving
polynomial fits, as in the method of false position. With regard to
termination,
114
Application to a Quadratic in Two Dimensions
For purposes of illustration, let us consider the problem of
minimizing a two-dimensional quadratic function.
1 T
x Qx
2
1
c1 x1 c2 x2 (q11 x12 q22 x22 2q12 x1 x2 )
2
f ( x ) cx
The gradient of. f(x) is
▽f(x) = c +Qx
((c1 q11x1 q12 x2 ) ,
(c2 q12 x1 q22 x2 ))T
(1 f , 2 f )T
Thus, starting from the initial point x°, we must solve Problem
(21) over the line
0
0
x
f
0
1
1
x(t ) x tf ( x) 0 t
0
x2
2 f
115
to find the new point. The optimal step size, call it t*, can
be determined by substituting the right-hand side of the
expression above into f(x) and finding the value of t that
minimizes f(x(t). For this simple case, it can be shown with
some algebra that
(1 f ) ( 2 f )
t
q11 (1 f 0 ) 2 q22 ( 2 f 0 ) 2 2q121 f 0 2 f 0
0 2
0 2
*
116