Ch 11 Sol
advertisement

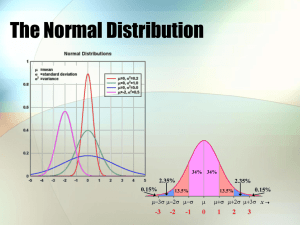
New Century Maths 12 Mathematics General 2 HSC course Worked Solutions Chapter 11 Sampling and the normal distribution SkillCheck 1 a 99.7 12 600 12 562.2 100 12 562 b 2.5 3200 80 100 c 0.3 6000 18 100 2 Number who passed 95 15 000 100 14 250 3 68% did not smoke. 100% 68% = 32% did smoke Number who smoked 32 6000 100 1920 4 Percentage of days with temperature less than or equal to 25C 100% 99.7% 0.3% 0.3 365 100 1.095 Number of days with a temperature less than or equal to 25C 1 1 day has a temperature less than or equal to 25°. 5 a 95 68 27 2 2 = 13.5 b 95 99.7 95 4.7 95 2 2 95 2.35 97.35 c 68 1 1 95 68 68 27 2 2 68 13.5 81.5 xx s 6 a z 170 160 8 10 8 1.25 1.3 b z xx s x 90 12 1.7 12 x 90 1.7 20.4 x 90 x 20.4 90 110.4 7 a P 44 28 16 44 P 28 16 77 b P 50 30 11 50 P 30 11 136.3636 136.4 c P 64 36 45 P 64 36 45 51.2 8 Number of teams of two 65 2 1 = 15 Exercise 11-01: Sampling 1 A census would be far too costly and time consuming. Observation would be unreliable, and experiment is inappropriate for sales. A properly conducted survey with a sufficient unbiased sample would be best. The correct answer is B. 2 Two reasons for choosing a sample rather than a census are: • expense, if the population is large • time, if the population is large. (Other answers may apply.) 3 Bias occurs when a sample is chosen in a way that favours one response more than other responses, so that the results of the survey are nit randomly selected and do not accurately reflect the population. 4 a Systematic. Random would be impossible because a car could be chosen randomly before there was space for the driver to be tested, and stratified would be impractical. In practice, the next car would be chosen as soon as there was a police officer free, so it wouldn’t be true stratified sampling. b, c Random would be difficult, because there would be too much travel involved. Stratified would be necessary to ensure a good cross section of the population. Systematic would also be useful, to avoid groups with similar ideas. For this reason, next door neighbours are sometimes not both interviewed because they often talk ‘over the fence’ and this may bias the results. 5 No, because every sample of 400 does not have the same chance of being selected because 100 have to each come from Holden, Ford, Hyundai and Toyota. It is a stratified sample. 6 Teacher to check. 7 Teacher to check. 8 Teacher to check. 9 a It is an unordered selection. 5 4 2 1 = 10 Number of possible samples of two = b LZ, LS, LT, LN, ZS, ZT, ZN, ST, SN, TN 10 It is an unordered selection. 10 9 2 1 = 45 Number of possible samples of two = The correct answer is B. 11 a i It is an unordered selection. Number of possible samples of 4 = 5 4 3 2 4 3 2 1 =5 ii It is an unordered selection. Number of possible samples of 2 = 5 4 2 1 = 10 iii It is an unordered selection. Number of possible samples of 3 = 5 43 3 2 1 = 10 iv It is an unordered selection. Number of possible samples of 1 = 5 1 =5 v A sample of 5 would mean choosing all five branches, so there is only one way. Number of possible samples = 1 b 5 + 10 + 10 + 5 + 1 = 31 c CNSW, CNSB, CNWB, CSWB, NSWB 12 We can have a sample of 1 in three ways, a sample of 2 in three ways, and a sample of 3 in one way. Altogether there are 3 + 3 + 1 = 7 ways. 13 a i 13 out of 30 = 13 × 100% 30 ≈ 43.3%. ii 17 out of 30 = 17 × 100% 30 ≈ 56.7% or: 100% – 43.3% = 56.7% iii 11 out of 30 = 11 × 100% 30 ≈ 36.7% iv 5 out of 30 = 5 × 100% 30 ≈ 16.7% v 6 out of 30 = 6 × 100% 30 = 20% vi 4 out of 30 = 4 × 100% 30 ≈ 13.3% b, c Answers will vary. Check with your teacher. 14 Answers will vary. Check with your teacher. Exercise 11-02: Comparing samples and populations 1 a = (1 + 3 + 5 + 6 + 8) ÷ 5 = 23 ÷ 5 = 4.6 b n = 1: 1, 3, 5, 6, 8 n = 2: 1, 3 1, 5 1, 6 1, 8 3, 5 3, 6 3, 8 5, 6 5, 8 6, 8 n = 3: 1, 3, 5 1, 3, 6 1, 3, 8 1, 5, 6 1, 5, 8 1, 6, 8 3, 5, 6 3, 5, 8 3, 6, 8 5, 6, 8 n = 4: 1, 3, 5, 6 1, 3, 5, 8 1, 3, 6, 8 1, 5, 6, 8 3, 5, 6, 8 n = 5: 1, 3, 5, 6, 8 c Find the means for the different samples. n = 1: The means are 1, 3, 5, 6 and 8 respectively. n = 2: The means are 2, 3, 3.5, 4.5, 4, 4.5, 5.5, 5.5, 6.5 and 7 respectively. (For each sample, add the values and divide by 2.) 1 2 2 1 2 1 n = 3: The means are 3, 3 , 4, 4, 4 , 5, 4 , 5 , 5 and 6 respectively. 3 3 3 3 3 3 (For each sample, add the values and divide by 3.) n = 4: The means are 3.75, 4.25, 4.5, 5 and 5.5 respectively. (For each sample, add the values and divide by 4.) n = 5: Mean is 4.6. (Add the sample values and divide by 5.) d Add all of the sample means found in part c then divide by 31, the total number of samples. x = (1 + 3 + 5 + 6 + 8 + 2 + 3 + 3.5 + 4.5 + 4 + 4.5 + 5.5 + 5.5 + 6.5 + 7 + 3 + 10 + 3 14 14 16 17 19 4+4+ +5+ + + + + 3.75 + 4.25 + 4.5 + 5 + 5.5 + 4.6) ÷ 31 3 3 3 3 3 = 4.6. e Yes, the mean of the sample means equals the mean of the population. 190 203 209 211 212 5 1025 5 205 cm 2 a μ b n = 1: 190, 203, 209, 211, 212 n = 2: 190, 203 190, 209 190, 211 190, 212 203, 209 203, 211 203, 212 209, 211 209, 212 211, 212 n = 3: 190, 203, 209 190, 203, 211 190, 203, 212 190, 209, 211 190, 209, 212 190, 211, 212 203, 209, 211 203, 209, 212 203, 211, 212 209, 211, 212 n = 4: 190, 203, 209, 211 190, 203, 209, 212 190, 209, 211, 212 190, 203, 211, 212 203, 209, 211, 212 n = 5: 190, 203, 209, 211, 212 c Find the means for the different samples. n = 1: The means are 190, 203, 209, 211 and 212 respectively. n = 2: The means are 196.5, 199.5, 200.5, 201, 206, 207, 207.5, 210, 210.5 and 211.5 respectively. (For each sample, add the values and divide by 2.) n = 3: The means are 200 and 210 2 1 2 1 2 1 2 2 , 201 , 201 , 203 , 203 , 204 , 207 , 208, 208 3 3 3 3 3 3 3 3 2 respectively. (For each sample, add the values and divide by 3.) 3 n = 4: The means are 203.25, 203.5, 205.5, 204 and 208.75 respectively. (For each sample, add the values and divide by 4.) n = 5: The mean is 205. (Add the sample values and divide by 5.) To find the mean of the sample means, add all of the sample means then divide by 31, the total number of samples. x = (190 + 203 + 209 + 211 + 212 + 196.5 + 199.5 + 200.5 + 201 + 206 + 207 + 2 1 2 1 2 + 201 + 201 + 203 + 203 + 3 3 3 3 3 1 2 2 2 204 + 207 + 208 + 208 + 210 + 203.25 + 203.5 + 205.5 + 204 + 3 3 3 3 208.75 + 205) ÷ 31 207.5 + 210 + 210.5 + 211.5 + 200 = 205 d The population mean and the mean of the sample means are both 205. 3 a μ 68 74 72 3 71 b 1 3 i There are three samples of size n = 1. ii There are 3 2 3 samples of size n = 2. 2 1 iii There is one sample of size n = 3. c n = 1: 68 74 72 n = 2: 68, 74 68, 72 74, 72 n = 3: 68, 74, 72 d Find the means for the different samples. n = 1: The means are 68, 74 and 72 respectively. n = 2: The means are 71, 70 and 73 respectively. (Add each pair of sample values then divide by 2) 1 n = 3: The mean is 71 . (Add the three sample values then divide by 3.) 3 μx 68 74 72 71 70 73 71 71 1 3 7 1 3 1.85 1.68 1.80 1.89 1.95 1.68 1.66 1.91 1.82 1.85 2.03 1.95 12 = 1.84 4 a μ The mean height of the basketball players is 1.84 m. b Answers will vary. Check with your teacher. An example for n = 3 is 1.89, 1.91, 1.95. c Answers will vary. Check with your teacher. i An example for n = 4 is 1.68, 1.89, 1.66, 2.03. ii An example for n = 5 is 1.89, 1.95, 1.91, 1.82, 1.95. d Answers will vary. Check with your teacher. For the three examples given in parts b and c, the means are: 1.89 1.91 1.95 1.916 6666 3 1.68 1.89 1.66 2.03 1.815 4 1.89 1.95 1.91 1.82 1.95 1.904 5 e The population mean is 1.84. For the samples given as examples, two of the sample means are above the population mean and one is below the population mean. f The mean of all of the sample means will be the same as the population mean, 1.84 m. 5 a μ= 0.1 6 0.42 0.34 0.43 0.40 0.32 0.52 0.37 0.37 0.35 0.54 0.35 0.31 0.45 0.29 0.24 0.28 0.51 0.48 0.34 20 = 0.3735 b Answers will vary. Check with your teacher. Four possible samples of size n = 5 are: • 0.31, 0.52, 0.34, 0.24, 0.43 • 0.35, 0.31, 0.32, 0.16, 0.45 • 0.42, 0.31, 0.52, 0.43, 0.48 • 0.35, 0.31, 0.37, 0.16, 0.51 c Answers will vary. Check with your teacher. The means for the four samples given in part b are: 0.31 0.52 0.34 0.24 0.43 0.368 5 0.35 0.31 0.32 0.16 0.45 0.318 5 0.42 0.31 0.52 0.43 0.48 0.432 5 0.35 0.31 0.37 0.16 0.51 0.34 5 The mean of the sample means is: 0.368 0.318 0.432 0.34 0.3645 4 d i No, the sample means cannot be used for an estimate of the population mean since we have not considered every possible sample of size n = 5. ii The mean of the sample means is 0.3645 and the population mean is 0.3735. The means are not the same. e Answers will vary. Check with your teacher. Four possible samples of size n = 6 are: • 0.24, 0.31, 0.45, 0.52, 0.35, 0.40 • 0.24, 0.51, 0.54, 0.48, 0.40, 0.42 • 0.35, 0.54, 0.28, 0.48, 0.34, 0.37 • 0.32, 0.35, 0.31, 0.34, 0.24, 0.35 The sample mean for each sample is found by adding all of the values in the sample then dividing by 6. The sample means are 0.3783, 0.4317, 0.3933 and 0.3183. 0.3783 0.4317 0.3933 0.3183 4 0.3804 μx The population mean is 0.3735 so the mean of the sample means is greater than this value. Exercise 11-03: The capture-recapture technique 1 Let P be the population of lobsters in the lake. 100 11 P 80 P 80 100 11 P 80 100 11 727.27... An estimate of the number of lobsters in the lake is 727. The correct answer is B. 2 Let P be the deer population in the forest. 30 14 P 160 P 160 30 14 P 160 30 14 342.86 An estimate of the number of deer in the forest is 343. 3 Let P be the blue starfish population in the lagoon. 200 8 P 50 P 50 200 8 P 50 200 8 1250 An estimate of the number of blue starfish in the lagoon is 1250. 4 Let P be the kangaroo population. 160 17 P 120 P 120 160 17 P 120 160 17 1129.41... The estimated kangaroo population is 1129. 5 Let P be the salmon population. 2000 12 P 600 P 600 2000 12 P 600 2000 12 100 000 The estimated salmon population in the lake is 100 000. 6 Let P be the possum population. 800 45 P 640 P 640 800 45 P 640 800 45 11 377.77... 11 400 The estimated possum population is 11 400 (to the nearest hundred). 7 Let P be the grasshopper population. 15 13 P 65 P 65 15 13 P 65 15 13 75 The estimated grasshopper population is 75. The correct answer is D. 8 Let P be the blackfish population. 1500 P P 1500 P 20 250 250 20 250 1500 20 18 750 The estimated blackfish population is 18 750. 9 a Let P be the moose population. 150 12 P 100 P 100 150 12 P 100 150 12 1250 The estimated moose population is 1250. b 12% is 150. 1% is 150 . 12 150 100 1250 12 100% is The estimated moose population is 1250. 10 Let P be the butterfly population. 300 15 P 200 P 200 300 15 P 200 300 15 4000 An estimate of the butterfly population is 4000. 11 Let P be the rabbit population. 15 P P 15 P 7 48 48 7 48 15 7 102.857... An estimate of the rabbit population is 103. 12 a Let P be the trout population. 4410 15 P 100 P 100 4410 15 P 100 4410 15 29 400 An estimate of the trout population is 29 400. b 15% is 4410. 1% is 4410 . 15 100% is 4410 100 29 400 15 An estimate of the trout population is 29 400. 13 Let P be the snake population. 200 51 P 110 P 110 200 51 P 110 200 51 431.37... An estimate of the snake population is 431, so the snake catcher is correct. 14 Let P be the crocodile population. 150 12 P 20 P 20 150 12 P 20 150 12 250 An estimate of the crocodile population is 250. Exercise 11-04: The normal distribution 1 a The graph that is further to the right has the highest mean, so graph Y has the higher mean. b The wider graph has the higher standard deviation, so graph Z has the higher standard deviation. 2 a 68% of nails will have a length between 5.00 0.01 = 4.99 cm and 5.00 + 0.01 = 5.01 cm. b 95% of nails will have a length between 5.00 2 0.01 = 4.98 cm and 5.00 + 2 0.01 = 5.02 cm. c 99.7% of nails will have a length between 5.00 3 0.01 = 4.97 cm and 5.00 + 3 0.01 = 5.03 cm. 3 x 300, s 2 x 3s 300 3 2 x 3s 300 3 2 306 294 So diameters greater than 306 mm are rejected and diameters less than 294 mm are rejected. The diameter of 307 mm would be rejected. The correct answer is B. 4 x 14.5, s 1.2 x s 14.5 1.2 x s 14.5 1.2 13.3 15.7 The percentage of nicotine content between 13.3 mg and 15.7 mg is the percentage between x s and x s , which is 68%. The correct answer is C. 5 a x 8000 95% of light globes last between x 2 s and x 2 s. x 2 s 8300 8000 2 s 8300 2 s 8300 8000 2 s 300 300 2 150 s The standard deviation is 150 hours. b x 8000, s 150 68% of values lie between x s and x s . x s 8000 150 x s 8000 150 7850 8150 68% of values lie between 7850 hours and 8150 hours. c 7850 hours = x s 13.5% + 2.35% + 0.15% = 16% of light globes are expected to last for less than 7850 hours. Expected number 16% 12 000 1920 6 a s 49 2.5% of skull widths are less than x 2 s. x 2 s 1297 x 2 49 1297 x 1297 2 49 1395 The mean skull width is 1395 mm. b x 2 s 1297 x 3s 1395 3 49 1542 We require the percentage between x 2 s and x 3s . 95% + 2.35% = 97.35%. So 97.35% of adults in the group have a skull width between 1297 mm and 1542 mm. 97.35 8000 100 7788 Number of adults 7788 adults in the group have a skull width between 1297 mm and 1542 mm. 7 a Pipes with a length greater than x 3s or less than x 3s are rejected. 99.7% of pipes have lengths between x 3s and x 3s and are accepted. 100% 99.7% = 0.3% of pipes are, therefore, rejected. b x 148.4, s 0.03 x 2 s 148.4 2 0.03 148.34 x s 148.4 0.03 148.43 The percentage of pipes that are accepted by this customer is the percentage between x 2 s and x s . Percentage accepted = 13.5% + 34% + 34% = 81.5% 8 a 95% of gestation periods lie between x 2 s and x 2 s. x 266, s 16 x 2 s 266 2 16 x 2s 266 2 16 234 298 95% of gestation periods lie between 234 days and 298 days. b x s 266 16 282 The percentage above x s is: 13.5% + 2.35% + 0.15% = 16% So 16% of pregnancies last for more than 282 days. c x 3s 266 3 16 314 0.15% of pregnancies last more than 314 days. It is possible to have a gestation period of 320 days, but this is highly unlikely because 320 days is more than 3 standard deviations from the mean. 9 a x 490, s 10 x s 490 10 500 The advertised weight is 500 g which is one standard deviation to the right of the mean. The percentage of packets expected to be below this weight is 50% + 34% = 84%. b The product seems to be labelled unfairly because, only 16% of the packets are equal to or over the advertised weight. 10 a x 255, s 2.5 x 2s 255 2 2.5 250 The labelled weight is two standard deviations to the left of the mean. The percentage above the labelled weight = 13.5% + 34% + 50% = 97.5% b 97.5% of the cheese wedges contain more than the labelled weight, so 2.5% contain less than the labelled weight. Number containing less than the labelled weight 2.5 6000 100 150 11 a x 1.015, s 1.015 x s 1.015 0.015 1000 labelled weight The percentage with less than the labelled weight = 13.5% + 2.35% + 0.15% = 16% b x 1.030, s 1.015 x 2 s 1.030 2 0.015 1000 labelled weight The percentage with less than the labelled weight = 2.35% + 0.15% = 2.5% Exercise 11-05: z-scores 1 The raw score is the actual score or value, whereas the z-score shows the number of standard deviations that the raw score is above or below the mean. 2 a 34% of scores are shaded. b 34% + 34% = 68% of scores are shaded. c 13.5% + 34% = 47.5% of scores are shaded. d 99.7% of scores are shaded. e 34% + 34% + 13.5% + 2.35% = 83.85% of scores are shaded. f 13.5% + 2.35% + 0.15% = 16% of scores are shaded. 3 a x 70, s 6 i Bill: xx s 76 70 6 1 z ii Mary: xx s 52 70 6 3 z iii Elsie: xx s 91 70 6 3.5 z b xx s x 70 2.5 6 2.5 6 x 70 15 x 70 x 15 70 85 z Esma is 85 years old. xx s 82 70 6 2 c z The percentage of bingo players that are more than 82 years old is 2.35% + 0.15% = 2.5%. xx s 64 70 6 1 d z xx s 88 70 6 3 z The percentage of bingo players between 64 and 88 years of age is 34% + 34% + 13.5% + 2.35% = 83.85%. 4 xx s x 70 1.8 15 1.8 15 x 70 27 x 70 x 27 70 97 z The correct answer is A. 5 a Sam’s z-score of –1 means that Sam’s blood pressure is one standard deviation below the mean blood pressure. b xx s x 130 1 20 1 20 x 130 20 x 130 x 20 130 110 z Sam’s blood pressure is 110. xx s 145 130 20 c z 0.75 Zac’s z-score is 0.75. 6 a i Jamal: xx s 86 90 10 0.4 z ii Maria: xx s 125 90 10 3.5 z b xx s x 90 2.2 10 2.2 10 x 90 z 22 x 90 x 22 90 112 Ann is 122 cm or 1.22 m tall. c xx s x 90 1.4 10 1.4 10 x 90 14 x 90 x 14 90 76 z Drew is 76 cm tall. d Find the z-scores for each height. xx s 70 90 10 2 z xx s 90 90 10 0 z Percentage of children who are between 70 cm and 90 cm tall is: 13.5% + 34% = 47.5% e Find the z-score for 100 cm. xx s 100 90 10 1 z The percentage of children who are more than 1 m tall is: 13.5% + 2.35% + 0.15% = 16% 7 a z xx s So x zs x . Mass (g) z-score 94 2 2 100 96 98 100 1 2 100 102 104 3 2 100 106 94 100 –2 98 100 0 1 104 100 3 2 3 b 2 1 i Percentage with mass more than 100 g = 50% 2 2 ii Percentage with mass between 98 g and 102 g = 34% + 34% = 68% iii Percentage with mass less than 96 g = 2.35% + 0.15% = 2.5% c Percentage with mass greater than 104 g = 2.35% + 0.15% = 2.5% Expected number 2.5 2500 100 62.5 xx s 100 100 16 0 8 a i z xx s 132 100 16 2 ii z b Percentage with an IQ above 132 = 2.35% + 0.15% = 2.5% 2.5 30 000 000 100 750 000 Expected number c i A z-score of 4 means 4 standard deviations above the mean. ii xx s x 100 4 16 4 16 x 100 64 x 100 x 64 100 164 z A z-score of 4 corresponds to an IQ of 164. 9 a z xx s So x zs x . Weight (kg) 3 0.4 1.2 0 0.4 1 0.4 1.2 0.8 1.2 1 0.4 1.2 1.6 2.0 3 0.4 1.2 2.4 z-score –3 0.4 1.2 –1 1.2 1.2 1 0.4 0 0.4 2 2.0 1.2 0.4 2 b Percentage of flathead weighing between 0.4 kg and 1.6 kg = 13.5% + 34% + 34% = 81.5 % c Percentage of flathead with weight above 2 kg = 2.35% + 0.15% = 2.5% Number weighing over 2 kg 2.5 4800 100 120 d Percentage weighing less than 0.8 kg = 13.5% + 2.35% + 0.15 % = 16% 16 4800 100 768 Number returned 10 a Trigonometry: z xx s 65 64 6.2 0.16 Probability: z xx s 70 59 6.1 1.8 xx s 70.2 64 6.2 1 b z Percentage with a z-score less than 1 is: 50% + 34% = 84% 84 56 100 47 Number expected to score less than 70.2 Exercise 11-06: Comparing z-scores 3 1 Since the z-scores for each test are the same, the students both performed the same. The correct answer is C. 2 a English: z xx s 65 75 14 0.71 Maths: z xx s 72 65 10 0.7 Science: z xx s 58 62 16 0.25 Art: z xx s 78 85 8 0.875 b Ranked subjects (highest z-score to lowest z-score): Maths, Science, English, Art. 3 a Subject Visual Arts Peta 48 66 16 Legal Studies 67 68 12 1.125 0.083 Mel 60 66 16 82 68 12 0.375 1.17 Joe 70 66 16 74 68 12 0.25 0.5 Maths General 2 70 70 9 0 79 70 9 1 55 70 9 1.67 b Mel’s best subject was Legal Studies. c Joe’s mark in Visual Arts is better than Peta’s mark in Maths General 2. This can be seen by the higher z-score. d The best result overall was Mel’s result in Legal Studies. 4 a Pattie: xx s z 86.4 83 6 0.57 Jim: z xx s 97.2 93 7.5 0.56 Pattie is more overweight. This can be seen by her slightly higher z-score. b xx s x 83 2 6 2 6 x 83 12 x 83 x 12 83 95 z Jill’s weight is 95 kg. c xx s x 93 2 7.5 2 7.5 x 93 15 x 93 x 15 93 108 z Ty’s weight is 108 kg. He weighs 13 kg more than Jill who is 95 kg. 5 Find the z-score for 1100 mm of rain in each town. Downtown: z xx s 1100 950 420 0.357 Uptown: z xx s 1100 1325 283 0.945 Rainfall of 1100 mm is more likely to occur in the town where the z-score is closer to 0. So Downtown would be more likely to have an annual rainfall of 1100 mm. 6 Find the z-score for each car. 2-year-old model: z xx s 17000 18000 1500 0.667 3-year-old model: z xx s 13000 15000 1600 1.25 The one with the greater z-score is the better car. So the 2-year-old model is the better car. Sample HSC problem a z xx s 59 65 10 0.6 xx s 55 65 10 xx s 65 65 10 b z z 0 1 Percentage in the 55 to 65 range is the same as the percentage between z = –1 and z = 0. So 34% of Modern History marks lie within the 55 to 65 range. c i A z-score of 2.3 means 2.3 standard deviations above the mean so his mark was 2.3 standard deviations above the mean mark of 65. ii xx s x 65 2.3 10 2.3 10 x 65 23 x 65 x 23 65 88 z Raad’s actual mark in Modern History was 88. Revision 1 When every 100th bag of lollies is weighed, it is systematic sampling. The correct answer is C. 2 a i Bus 8 100% 20 40% ii Car 8 100% 20 40% iii Walk 4 100% 20 20% b–d Answers will vary. Teacher to check. e Rail has not been included in the survey. In the area where the survey was taken there may not have been access to a railway line. 3 a n = 1: 190 161 170 162 176 n = 2: 190, 161 190, 170 190, 162 190, 176 161, 170 161, 162 161, 176 170, 162 170, 176 162, 176 n = 1: The means are 190, 161, 170, 162 and 176 respectively. n = 2: The means are 175.5, 180, 176, 183, 165.5, 161.5, 168.5, 166, 173 and 169 respectively. (Add each pair of sample values then divide by 2.) b μx 190 161 170 162 176 175.5 180 176 183 165.5 161.5 168.5 166 173 169 15 171.8 190 161 170 162 176 5 171.8 μ The mean of the distribution of sample means is equal to the population mean. 4 Let P be the kangaroo population. 40 12 P 100 P 100 40 12 100 P 40 12 333.33... The size of the kangaroo population is estimated to be 333. 5 a 68% of rods will have a diameter between 4.00 0.02 = 3.98 cm and 4.00 + 0.02 = 4.02 cm. b 95% of rods will have a diameter between 4.00 2 0.02 = 3.96 cm and 4.00 + 2 0.02 = 4.04 cm. c 99.7% of rods will have a diameter between 4.00 3 0.02 = 3.94 cm and 4.00 + 3 0.02 = 4.06 cm. 6 x 75, s 2 x 3s 75 3 2 x 3s 75 3 2 81 69 So lengths greater than 81 mm are rejected and lengths less than 69 mm are rejected. The length of 88 mm would be rejected. The correct answer is D. 7 a The widest graph has the highest standard deviation. The correct answer is C. b The thinnest graph has the smallest standard deviation. The correct answer is A. c The distributions with the same mean have their maximum points aligning with the same distance along the horizontal axis. The correct answers are A, B and C. d The distributions with the same standard deviations have graphs with the same width. The correct answers are B and D. 8 a Leonardo’s score of 2.5 means that his result was 2.5 standard deviations above the mean. b xx s 82 68 2.5 s 2.5s 14 z s 14 2.5 5.6 xx s 62 68 5.6 1.07 c z Michaelangelo’s z-score was –1.07. d xx s x 68 0.8 5.6 0.8 5.6 x 68 4.48 x 68 x 4.48 68 72.48 z Raphael’s score was 72, correct to the nearest whole number. 9 z xx s So x zs x . Time (h) 3 2 8 2 2 8 2 4 z-score –3 6 8 1 2 8 3 28 12 10 –2 68 2 1 0 1 14 12 8 2 2 b i Percentage between 10 and 14 hours = 13.5% + 2.35% = 15.85% ii Percentage less than 6 hours = 13.5% + 2.35% + 0.15% = 16% iii Percentage more than 12 hours = 2.35% + 0.15% = 2.5% iv Percentage between 4 and 10 hours = 13.5% + 34% + 34% = 81.5% 10 a Drama: z xx s 80 75 16 0.3125 Photography: 3 z xx s 60 54 12 0.5 Textiles: z xx s 70 78 10 0.8 b Tom performed best in Photography. His z-score was highest for this subject. c © Cengage Learning Australia Pty Ltd 2013 MAT12DSWS10031 distribution; Sampling and populations www.nelsonnet.com.au Data and Statistics: The normal