File Organizations and Indexing
advertisement

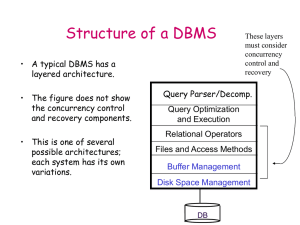
File Organizations and Indexing Lecture 4 R&G Chapter 8 "If you don't find it in the index, look very carefully through the entire catalogue." -- Sears, Roebuck, and Co., Consumer's Guide, 1897 Review: Memory, Disks, & Buffer Mgt • • • • • • Everything won’t fit in RAM (usually) Hierarchy of storage, RAM, disk, tape “Block” - unit of storage on disk “Frame” – a block-sized chunk of memory Allocate space on disk for fast access Buffer pool management – Frames in RAM to hold blocks – Policy to move blocks between RAM & disk Context Query Optimization and Execution Relational Operators Files and Access Methods Buffer Management Disk Space Management DB Files of Records • Blocks interface for I/O, but… • Higher levels of DBMS operate on records, and files of records. • FILE: A collection of pages, each containing a collection of records. Must support: – insert/delete/modify record – fetch a particular record (specified using record id) – scan all records (possibly with some conditions on the records to be retrieved) • Note: typically page size = block size = frame size. Record Formats: Fixed Length F1 F2 F3 F4 L1 L2 L3 L4 Base address (B) Address = B+L1+L2 • Information about field types same for all records in a file; stored in system catalogs. • Finding i’th field done via arithmetic. Record Formats: Variable Length • Two alternative formats (# fields is fixed): F1 F2 $ F3 F4 $ $ $ Fields Delimited by Special Symbols F1 F2 F3 F4 Array of Field Offsets Second offers direct access to i’th field, efficient storage of nulls (special don’t know value); small directory overhead. Page Formats: Fixed Length Records Slot 1 Slot 2 Slot 1 Slot 2 Free Space ... ... Slot N Slot N Slot M 1 . . . 0 1 1M N PACKED number of records M ... 3 2 1 UNPACKED, BITMAP number of slots Record id = <page id, slot #>. In first alternative, moving records for free space management changes rid; may not be acceptable. “Slotted Page” for Variable Length Records Data Rid = (i,N) Page i Rid = (i,2) Rid = (i,1) Slot Array • • • 20 N ... 16 2 24 N 1 # slots SLOT DIRECTORY Record id = <page id, slot #> Pointer to start of free space Can move records on page without changing rid; so, attractive for fixed-length records too. Page is full when data space and slot array meet. • Q: What if a record grows too big to fit in the page??? System Catalogs • For each relation: – name, file location, file structure (e.g., Heap file) – attribute name and type, for each attribute – index name, for each index – integrity constraints • For each index: – structure (e.g., B+ tree) and search key fields • For each view: – view name and definition • Plus statistics, authorization, buffer pool size, etc. Catalogs are themselves stored as relations! Attr_Cat(attr_name, rel_name, type, position) attr_name rel_name type position attr_name Attribute_Cat string 1 rel_name Attribute_Cat string 2 type Attribute_Cat string 3 position Attribute_Cat integer 4 sid Students string 1 name Students string 2 login Students string 3 age Students integer 4 gpa Students real 5 fid Faculty string 1 fname Faculty string 2 sal Faculty real 3 Alternative File Organizations Many alternatives exist, each good for some situations, and not so good in others: – Heap files: Suitable when typical access is a file scan retrieving all records. – Sorted Files: Best for retrieval in search key order, or only a `range’ of records is needed. – Clustered Files (with Indexes): A compromise between the above two extremes. Unordered (Heap) Files • Simplest file structure contains records in no particular order. • As file grows and shrinks, disk pages are allocated and de-allocated. • To support record level operations, we must: – keep track of the pages in a file – keep track of free space on pages – keep track of the records on a page • There are many alternatives for keeping track of this. – We’ll consider 2 Heap File Implemented as a List Data Page Data Page Data Page Full Pages Header Page Data Page Data Page Data Page Pages with Free Space • The header page id and Heap file name must be stored someplace. – Database “catalog” • Each page contains 2 `pointers’ plus data. Heap File Using a Page Directory Data Page 1 Header Page Data Page 2 DIRECTORY Data Page N • The entry for a page can include the number of free bytes on the page. • The directory is a collection of pages; linked list implementation is just one alternative. – Much smaller than linked list of all HF pages! • Q: How to find a particular record in a Heap file??? Cost Model for Analysis We ignore CPU costs, for simplicity: – B: The number of data blocks – R: Number of records per block – D: (Average) time to read or write disk block • Measuring number of block I/O’s ignores gains of pre-fetching and sequential access; thus, even I/O cost is only loosely approximated. • Average-case analysis; based on several simplistic assumptions. – Often called a “back of the envelope” calculation. Good enough to show the overall trends! Some Assumptions in the Analysis • Single record insert and delete. • Equality selection - exactly one match (what if more or less???). • Heap Files: – Insert always appends to end of file. – Delete just leaves free space in the page. • Sorted Files: – Files compacted after deletions. – Selections on search key. Cost of Operations Heap File Scan all records BD Equality Search 0.5 BD (unique key) Range Search Insert Delete BD 2D (0.5B+1)D B: The number of data pages R: Number of records per page D: (Average) time to read or write disk page Sorted File Clustered File Sorted Files • Q: When do Heap files perform well? When don’t they? • Heap files are lazy on update - you end up paying on searches. • Sorted files eagerly maintain the file on update. – The opposite choice in the trade-off • Let’s consider an extreme version – No gaps allowed, pages fully packed always – Q: How might you relax these assumptions? Cost of Operations B: The number of data pages R: Number of records per page D: (Average) time to read or write disk page Heap File Sorted File Scan all records BD BD Equality Search 0.5 BD (log2 B) * D Range Search BD Insert 2D [(log2 B) + #match pg]*D ((log2B)+B)D (unique key) (because rd,w0.5 File) Delete (0.5B+1)D Same cost as Insert Clustered File Indexes: avoiding the extremes • Hash files are great for lots of updates and scans. • Sorted files are great for lots of “rifle-shot” look ups on one particular search key. – Q: How do they do on look ups on other fields?? • Q: Is there a “goldilocks” solution???? • Clustered files are “sort of sorted”. – Need additional structure to help find things. • A Primary Index provides such structure. Index Overview • An Index is a collection of “data entries” plus a way to quickly find entries with given key values. • Two main families of indexes: Hash and Tree – Hash-based indexes only good for equality search. – Tree-based indexes best for range search; also good for equality search. (Files rarely kept sorted in practice; B+ tree index is better.) • Primary index is associated with file structure. – can have at most one per file • Can have any number of additional Secondary Indexes. – These can speed up other “Access Paths”. File Structure Summary • File Layer manages access to records in pages. – Record and page formats depend on fixed vs. variablelength. – Free space management is an important issue. – Slotted page format supports variable length records and allows records to move on page. • Many alternative file organizations exist, each appropriate in some situation. – We looked at Heap and Sorted so far. – If selection queries are frequent, sorting the file or building an index is important. • Back of the envelope calculations are imprecise, but can expose fundamental systems tradeoffs. – A technique that you should become comfortable with! • Next up: Indexes.