PPT - Eurecom

Lecture 7
Smart Scheduling and Dispatching Policies
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis
Single Server Model (M/G/1)
Poisson arrival process w/rate l
Load r = l E[X]<1
X: job size
(service requirement)
1
Bounded Pareto
Job sizes with huge variance are everywhere in CS:
Pr{ Job size x } ~
1 x
• Supercomputing job sizes [Schroeder, Harchol-Balter 00]
C
8
2
X
=
C
2
X
(
E X ]
2
)
50 is typical
½
¼
Huge
Variability D.F.R.
k x p
Top-heavy: top 1% jobs make up half load
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis
2
Outline
Smart scheduling
Performance metrics
Policies classification
Examples
Ladies first!
Scheduling policies comparison (Fairness, Latency)
+ they’ll go out first
Task assignment problem
Supercomputing and web server models
Optimal dispatching/scheduling policies
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
3 Eurecom, Sophia-Antipolis
Smart scheduling: Motivation (I)
Why scheduling matters?
Why doesn’t it work?!
Bla, bla, bla …
Why doesn’t it work?!
Why doesn’t it work?!
Bla, bla, bla …
!! Delay due to other users who are currently sharing the service !!
Eurecom, Sophia-Antipolis 4 Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Smart scheduling: Motivation (II)
The goal of smart scheduling is to reduce mean delay “for free”, i.e., by simply serving jobs in the “right order”, no additional resources
Which is the right order to schedule jobs?
The answer strongly depends on
- system load
- job size distribution
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 5
Smart scheduling: Performance metrics (I)
Common metrics to compare scheduling policies
E[T] , mean response time
E[N] , mean number (of jobs) in system
E[T
Q
] , mean waiting time (=
E[T]-E[S], where
E[S]
=service time)
Slowdown:
SD=T/S
(response time normalized by the running time)
- Meaning: if a job takes twice as long to run due to system load, it suffers from a Slowdown factor of 2, etc.
- Job response time should be proportional to its running time. Ideally:
• small jobs → small response times
• big jobs → big response times
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
6 Eurecom, Sophia-Antipolis
Smart scheduling: Performance metrics (II)
Starvation/fairness metrics
A low average Slowdown doesn’t necessarily mean fairness
(starvation of large jobs)
Good metric:
E[SD(x)] is the expected slowdown of a job of size x ,
i.e., mean slowdown as a function of x
E[SD]= E[T]/E[S]?
No! First we need to derive:
E [ SD ( x )]
=
E
T
S
Then, we get the mean SD:
| job has size S
= x
=
E
T ( x ) x
=
1 x
E [ T ( x )]
E [ SD ]
= x
E [ SD | job has size x ] f
S
( x ) dx
= x
E [ SD ( x )] f
S
( x ) dx
= x
1
E [ T ( x )] f
S
( x ) dx x
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 7
Scheduling policies: classification
Definitions:
Preemptive policy: a job may be stopped and then resumed later from the same point where it was stopped
Size-based policy: it uses the knowledge of job size
Classification
Non-Preemptive, Non-Size-Based Policies
Preemptive, Non-Size-Based Policies
Non-Preemptive, Size-Based Policies
Preemptive, Size-Based Policies
Focus on M/G/1 queue (General job size distribution)
Poisson, λ
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 8
Non
-Preemptive,
Non
-Size-Based Policies (I)
Non-preemptive policies (each job is run to completion), that don’t assume knowledge of job size, are:
FCFS (First-Come-First-Served) or FIFO
Jobs are served in the order they arrive. Each job is run to completion before next job receives service (e.g., call centers, supercomputing centers)
LCFS (Last-Come-First-Served non-preemptive)
When the server frees up, it always chooses the last arrived job and runs that job to completion (jobs piled onto a stack)
RANDOM
When the server frees up, it chooses a random job to run next (mostly of theoretical interest)
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
9 Eurecom, Sophia-Antipolis
Processor Sharing (PS)
μ
Poisson( λ)
CPUs time-sharing
All processes currently running, share the CPU time equally
Web Servers time-sharing
HTTP requests served in parallel (to give TCP the impression of continuity)
When k jobs in system each job served at rate μ/k
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 10
Network of PS Servers
Q: M/M/1/PS performance?
A: Exactly like M/M/1!!!
Q: What about M/G/1/PS?
A: Exactly like M/M/1
Key Result: Network of PS servers with general service has product form solution (like Jackson networks)
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 11
Non
-Preemptive,
Non
-Size-Based Policies (II)
Interesting property: All non-preemptive service orders that do not make use of job sizes have the same distribution on the number of jobs in the system (time until completion is equal in distribution for all these policies)
Hence, same
E[T], E[N]
What about
E[SD]?
Proportional to job size variability!
For all these policies (in an M/G/1):
Thus,
E [ SD ]
=
E
T
S
=
E [ T
Q
]
=
1
r r
E
T
Q
S
S
=
1
E [ T
Q
]
E
1
S
E [ S 2 ]
2 E [ S ]
Independently of
Since
E[S], E[T
Q
] is the same for each policy → They have the same
E[SD]
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
12 Eurecom, Sophia-Antipolis
Preemptive,
Non
-Size-Based Policies (I)
So far: non-preemptive/non-size-based service
E[T] can be very high when job size variability is high
Intuition: short jobs queue up behind long jobs
Processor-Sharing (PS): when a job arrives, it immediately shares the capacity with all the current jobs (Ex. R.R. CPU scheduling)
+ PS allows short jobs to get out quickly, helps to reduce
E[T], E[SD]
(compared to FCFS), increases system throughput (different jobs run simultaneously)
PS is not better than FCFS on every arrival sequence
+
Mean response time for PS is insensitive to job size variability:
E[T] M/G/1/PS = E[S] / (1-ρ) where ρ is the system utilization (load)
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
13 Eurecom, Sophia-Antipolis
Preemptive,
Non
-Size-Based Policies (II)
Performances of M/G/1/PS system
Response time
E [ T ( x )]
=
1
x r
- Think of Little’s law!
Mean Slowdown
E [ SD ( x )]
=
E [ SD ]
=
1
1 r
!!! Constant Slowdown (independent of the size x)
!!! In non-preemptive, non-size-based scheduling:
E[SD] for small jobs was greater than the one for large jobs
Under PS, all jobs have same Slowdown → FAIR Scheduling
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 14
Preemptive,
Non
-Size-Based Policies (III)
Preemptive-LCFS: a new arrival preempts the job in service, when that arrival completes, the preempted job is resumed
E[T(x)], E[SD(x)] as for the PS case
+ wrt PS: less # of preemptions (only 2 per job)
Can we drop
E[SD(x)]
?
→ lower SD for smaller jobs
!!! We don’t know the size of the jobs!
FB (Foreground-Background) or LAS - Least Attained Service
Idea: To reduce
E[SD] → use knowledge of job’s age (indicator of remaining CPU demand), and serve the job with lowest age
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
15 Eurecom, Sophia-Antipolis
Foreground-Background scheduling (cont’d)
Used to control execution of multiple processes on a single processor: two queues (F and B) and one server
Jobs enter queue F
(PS service)
When a job hits a certain age
a, it is moved to queue B
Jobs in B get service only when queue F is empty
Idea of FB: The job with the lowest CPU age gets the CPU to itself.
If several jobs have same lowest CPU age, they share the CPU using PS
Performance depends on how good is the predictor of the age of remaining size (depends on job size distribution)!!
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
16 Eurecom, Sophia-Antipolis
Non
-Preemptive, Size-Based Policies (I)
Size-based policies: special case of Priority Queueing
Often used in computer systems, e.g., database (differentiated levels of service), scheduling of HTTP requests, high/low-priority transactions
Size-based scheduling: it can improve the performance of a system tremendously!
Priority queueing (non-preemptive)
Consider an M/G/1 priority queue with n classes: class 1 has highest priority, n the lowest
Class k job arrival rate is
Waiting for the jobs in the queue of ≥ priority
E [ T
Q
Q
+ ( k k )]
λ = λ p
] FCFC
-class job only see load
( 1 k r r i
E [ S
)( k
Time in queue for jobs of priority k is
E[T (k)] k
NP-Priority
1
1
2 < E[T k
1
1 r i
Q k
Waiting for the job in service
Waiting for the jobs of higher priority arriving after k
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
17 Eurecom, Sophia-Antipolis
Non
-Preemptive, Size-Based Policies (II)
Question: If you want to minimize
E[T]
, who should have higher priority: large or small jobs?
Theorem: Consider an NP-Priority M/G/1 with two classes of jobs: small (S) and large (L). To minimize
E[T]
, class S jobs should have priority over class L jobs (since
E[S
S
]<E[S
L
]
)
SJF - Non-preemptive Shortest Job First
Whenever the server is free, it chooses the job with the smallest
size (once a job is running, it is never interrupted)
- Under heavy-tailed distributions,
E[T
Q
(since most jobs are small)
] is smaller than the FCFS one
- But, mean delay is proportional to the variance → large delays for very high variance
- Small jobs can still get stuck behind a big one (already running) → need of preemption!
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
18 Eurecom, Sophia-Antipolis
Preemptive, Size-Based Policies
So far: non-preemptive policies
→ higher delay under highly variable job size distributions
Preemptive priority queueing
Better compared to nonpreemptive, it depends only on the first k priority classes variability!
PSJF - Preemptive Shortest Job First
Similar to SJF policy, the job in service is the job with the smallest original size
A preemption occurs if a smaller job arrives
Mean response time far lower than under SJF (PSJF is far less sensitive to variability in job size distr.)
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 19
SRPT
SRPT - Shortest Remaining Processing Time
Whenever the server is free, the job chosen is the one with shortest remaining processing time
Preemptive policy: a new arrival may preempt the current job in service if it has shorter remaining processing time
Compared to PSJF
- SRPT takes into account of remaining service requirement and not just the original job size
- Overall mean response time is lower
Compared to FB
- In SRPT, a job gains priority as it receives more service
- In FB, a job has highest priority when it first enters
- In an M/G/1
→ E[T(x)] SRPT ≤ E[T(x)] FB
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
20 Eurecom, Sophia-Antipolis
Policies comparison: mean response time (I)
M/G/1 queue, job size distribution is Bounded Pareto
FCFS SJF
E[T] PS
LAS
Versus ρ
SJF/FCFS delay very high even for low ρ
SRPT/LAS delay slightly increases with ρ
SRPT has the lowest delay
SRPT r
C 2 = 12
(
C 2 , is the squared coefficient of variation)
Versus
C 2
SJF/FCFS delay increases with
C 2
LAS delay decreases with
C 2
(DFR needs higher
C 2
)
PS and SRPT are invariant to
C 2
Source : Prof. Mor Harchol-Balter , http://www.cs.cmu.edu/~harchol/
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 21
Policies comparison: mean response time (II)
Weibull distribution, ρ=0.7
Fast increase with
C 2
Invariant to job size variability
Requires higher
C 2 to perform well
Source : Prof. Mor Harchol-Balter , http://www.cs.cmu.edu/~harchol/
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 22
Exercise
M/G/1 queue
Job size distribution: Bounded Pareto
The load is ρ = 0.9
The (very) biggest job in the job size distribution has size x = 10 10
Question:
E[T(x)] is lower under SRPT scheduling or under PS scheduling?
Source : Prof. Mor Harchol-Balter , http://www.cs.cmu.edu/~harchol/
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 23
Exercise: Solution
Small jobs should favor SRPT
Large jobs have the lowest priority under SRPT, but they get treated equally under PS (equal time-sharing)
Thus, it seems much better for “Mr. Max” to go to the PS queue
E[T(x)] PS should be far lower than
E[T(x)] SRPT
Source : Prof. Mor Harchol-Balter , http://www.cs.cmu.edu/~harchol/
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 24
Exercise: Solution (cont’d)
The largest job prefers SRPT to PS, but almost all jobs (99.9999%) prefer SRPT to PS by more than a factor of 2
99% of jobs prefer SRPT to PS by more than a factor of 5
But how can this be? Can every job really do better in expectation under SRPT than under PS?
All-Can-Win Theorem! (for BP distribution holds for
ρ < 0.96
)
< 5 times
Source : Prof. Mor Harchol-Balter , http://www.cs.cmu.edu/~harchol/
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 25
SRPT: Fairness
SRPT is optimal wrt mean response time
In practice, not used for scheduling job
Job size is not always known
PS is preferred in web servers, unless serving static requests
What about Fairness?
A policy is fair if each job has the same expected SD, regardless of its size
SRPT vs PS? SRPT worse with large jobs?
All-Can-Win Theorem : in an M/G/1, if
ρ<0.5
,
→ E[T(x)] SRPT ≤ E [T(x)] PS
(for all distribution, for all x)
- Intuition: Once a large job starts to get the service, it gains priority; under light load even a job of large size x could do worse under PS than under SRPT
(because of higher residence time)
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
26 Eurecom, Sophia-Antipolis
Summary on scheduling single server (M/G/1): E[T]
Poisson arrival process
Load r
<1
Let’s order the policies based on
E[T]:
Smart scheduling greatly improves mean response time (e.g., SRPT )
SRPT < LAS < PS < SJF < FCFS key
OPT for all arrival sequences
Requires D.F.R.
(Decreasing
Failure Rate)
Insensitive to E[S 2 ]
Surprisingly bad:
(E[S 2 ] term)
No “Starvation!” Even the biggest jobs prefer SRPT to PS
Source : Prof. Mor Harchol-Balter , http://www.cs.cmu.edu/~harchol/
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis
~E[S 2 ]
(shorts caught behind longs)
27
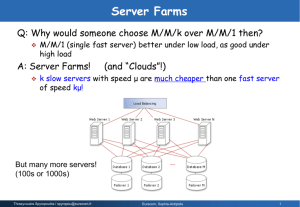
Multiserver Model
Server farms:
+ Cheap
+ Scalable capacity
Incoming jobs:
Poisson
Process
Routing
(assignment) policy
Router
Sched. policy
Sched. policy
Sched. policy
2 Policy Decisions
(Sometimes scheduling policy is fixed – legacy system)
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 28
Outline
I.
Review of scheduling in single-server
II. Supercomputing
FCFS
Router
FCFS
SRPT
IV. Towards Optimality …
&
Router
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
III. Web server farm model
PS
Router
PS
Eurecom, Sophia-Antipolis
SRPT
SRPT
Metric:
Mean
Response
Time,
E[T]
29
Supercomputing Model
Poisson
Process
Routing
(assignment) policy
Router
FCFS
FCFS
FCFS
Jobs are not preemptible .
Jobs processed in FCFS order .
Assume hosts are identical.
Jobs i.i.d. ~ G: highly variable size distribution.
Size may or may not be known. Initially assume known.
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 30
Q: Compare Routing Policies for E[T]?
Supercomputing
FCFS
1. Round-Robin
2. Join-Shortest-Queue
Go to host w/ fewest # jobs.
Poisson
Process
Routing policy
Router
FCFS
FCFS
3. Least-Work-Left
Go to host with least total work.
Jobs i.i.d. ~ G: highly variable
5. Central-Queue-Shortest-Job
(M/G/k/SJF)
Host grabs shortest job when free.
6. Size-Interval Splitting
Jobs are split up by size among hosts.
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 31
Supercomputing model (II)
High
E[T]
1. Round-Robin
Jobs assigned to hosts (servers) in a cyclical fashion
2. Join-Shortest-Queue
Go to host with fewest # jobs
3 . Least-Work-Left (equalize the total work)
Go to host with least total work (sum of sizes of jobs there)
4. Central-Queue-Shortest-Job (M/G/k/SJF)
Host grabs shortest job when free
Low
E[T]
5. Size-Interval Splitting
Jobs are split up by size among hosts. Each host is assigned to a size interval (e.g., Short/Medium jobs go to the first host, Long jobs go to the second host)
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis
Hp: Job size is known!
32
SITA and M/G/K-LWL comparison
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 33
What if job size is not known?
The TAGS algorithm “Task Assignment by Guessing Size” s
Host 1 m
Host 2
Outside
Arrivals
Host 3
Answer:
When job reaches size limit for host, then it is killed and restarted from scratch at next host.
[Harchol-Balter, JACM 02]
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis
34
Results of Analysis
Bounded Pareto Jobs
Random
Least-Work-Left
TAGS
High variability
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis
Lower variability
35
Supercomputing model (III)
Summary
This model is stuck with FCFS at servers. It is important to find a routing/dispatching policy that helps smalls not be stuck behind bigs → Size-Interval Splitting
By isolating small jobs, can achieve effects of smart single-server policies
Greedy routing policies (JSQ, LWL) are poor (don’t provide isolation for smalls, not good under high variability workloads)
Don’t need to know size (TAGS = Task Assignment by
Guessing Size)
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
36 Eurecom, Sophia-Antipolis
Web server farm model (I)
Examples: Cisco Local Director, IBM Network Dispatcher,
Microsoft SharePoint, etc.
PS
Poisson
Process
Routing policy
Router
PS
PS
HTTP requests are immediately dispatched to server
Requests are fully preemptible
Processor-Sharing (HTTP request receives “constant” service)
Jobs i.i.d. with distribution G (heavy tailed job size distr. for
Web sites)
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
37 Eurecom, Sophia-Antipolis
Web server farm model (II)
1. Random
2. Join-Shortest-Queue
Go to host with fewest # jobs
E[T]
8 servers, r = .9, C 2 =50
3. Least-Work-Left
Go to host with least total work
JSQ
LWL
Shortest-Queue is better (high variance distr.)
4. Size-Interval
Splitting
Jobs are split up by size among hosts
E T
PS farm =
Same for E[T], but not great
E T
M/G/1/PS
i p i r l
1
r
l
1 p i
1 r
r
Source : Prof. Mor Harchol-Balter , http://www.cs.cmu.edu/~harchol/
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 38
Optimal dispatching/scheduling scheme (I)
What is the optimal dispatching + scheduling pair?
Central-queue-SRPT looks very good
SRPT
Is Central-queue-SRPT always optimal for server farm?
No!! It does not minimize
E[T] on every arrival sequence!
Practical issue : jobs must be immediately dispatched
(cannot be held in a central queue)!!
Assumptions:
Jobs are fully preemptible within queue
Jobs size is known
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 39
Optimal dispatching/scheduling scheme (II)
Claim:
The optimal dispatching/scheduling pair, given immediate dispatch, uses SRPT at the hosts
SRPT
Incoming jobs
Immediately
Dispatch Jobs
Router SRPT
Intuition: SRPT is very effective at getting short jobs out → it reduces E[N] , thus the mean response time E[T] (Little’s law)
→ narrow search to policies with SRPT at hosts!
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 40
Optimal dispatching/scheduling scheme (III)
Optimal immediate dispatching policy is not obvious!
RANDOM task assignment performs well: each queue looks like an M/G/1/SRPT queue with arrival rate
λ/k
Idea: short jobs spread out over SRPT servers → IMD algorithm (Immediate Dispatching)
Divide jobs into size classes (e.g., small, medium, large) and assign jobs to the server with fewest # of jobs of that size class
Each server should have some small, some medium and some large jobs (so that SRPT can be maximally effective)
IMD performance is as good as Central-Queue-SRPT
Almost no stochastic analysis (analysis available for worstcases)!
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
41 Eurecom, Sophia-Antipolis
Summary
Supercomputing
FCFS
Web server farm model
PS
Router Router
FCFS PS
• Need Size-interval splitting to combat job size variability and enable good performance
• Job size variability is not an issue
• LWL, JSQ, performs well
Optimal dispatching/scheduling pair
SRPT
SRPT
+
Router
SRPT
• Both have similar worstcase
E[T]
• Almost exclusively worstcase analysis, so hard to compare with above results
• Need stochastic research
Source : Prof. Mor Harchol-Balter , http://www.cs.cmu.edu/~harchol/
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 42
Exercises
Ex. 1 – Slowdown
Jobs arrive at a server which services them in FCFS order. The average arrival rate is
λ = 1/2 job/sec. The job sizes (service times) are independently and identically distributed according to random variable S where:
S=1 with prob.
¾
,
S=2 o.w.
Suppose:
E[T] = 29/12
. Compute the mean slowdown,
E[SD]
, where the slowdown of job j is defined as
Slow(j) = T(j)/S(j)
, where
T(j) is the response time of job j and
S(j) is the size of job j
.
Solution:
Recall the definition of response time for a FCFS queue:
T = T
Here,
T
Q is the waiting or queueing time. Thus,
Q
+ S
.
E [ SD ]
=
E
T
Q
S
S
=
1
E
T
Q
S
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
43 Eurecom, Sophia-Antipolis
Exercises
Since the server is FCFS, a particular job’s waiting time is independent of its service time. This fact allows us to break up the expectation, giving us:
E [ SD ]
=
1
E [ T
Q
] E
1
S
=
1
( E [ T ]
E [ S ]) E
1
S
The distribution of
S is given, so we calculate
E[S] and
E[1/S] using the definition of expectation:
E[S] =5/4 and
E[1/S]=7/8
Then, we get
E[SD] =1+[(29/12 – 5/4)7/8]=97/48
.
If the service order had been SJF , would the same technique have worked for computing mean slowdown?
In the SJF case, S and T
Q are not independent , so we can’t split the expectation as we did above. The reason why they are not independent is because job size affects the queueing order: short jobs get to jump to the front of the queue under SJF, and hence their T
Q shorter.
is
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
44 Eurecom, Sophia-Antipolis
Exercises
Ex. 2 – FCFS-SJF-RR CPU scheduling
Compute the average waiting time for processes with the following next CPU burst times (ms) and ready queue order:
1. P1: 20
2. P2: 12
3. P3: 8
4. P4: 16
5. P5: 4
45 Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis
Exercises
Solution FCFS :
P1 P2 P3 P4 P5
0 20 32 40 56 60
Waiting time:
• T
• T
• T
• T
• T
1
=0
2
=20
3
=32
4
=40
5
=56
Average waiting time: 148/5= 29.6
+ Very simple algorithm
- Long waiting time!
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 46
Exercises
Solution SJF :
P5 P3 P2
0 4 12 24
Waiting time:
• T
• T
• T
• T
• T
1
=40
2
=12
3
=4
4
=24
5
=0
Average waiting time: 16
P4
40
P1
60
+ Shorter average waiting time
- Requires future knowledge
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 47
Exercises
Solution RR scheduling : Give each process a unit of time
(time slice, quantum) of execution on CPU. Then move to next process in the queue. Continue until all processes completed.
Hp: Time quantum of 4.
P5 completes P3 completes P2 completes P4 completes
P1 completes
P1 P2 P3 P4 P5 P1 P2 P3 P4 P1 P2 P4 P1 P4 P1
0 4 8 12 16 20 24 28 32 36 40 44 48 52 56 60
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 48
Exercises
Waiting time:
• T
• T
• T
• T
• T
1
: 60-20=40
2
: 44-12=32
3
: 32-8=24
4
: 56-16=40
5
: 20-4=16
0
P1
P5 completes P3 completes P2 completes P4 completes
P2 P3 P4 P5 P1 P2 P3 P4 P1 P2 P4 P1 P4 P1
4 8 12 16 20 24 28 32 36 40 44 48 52 56 60
Average waiting time: 30.4
- Ave. waiting time high
P1 completes
+ Good ave. response time
(Important for interactive/timesharing systems)
• Use of smaller quantum
(overhead increase)
Same exercise with other scheduling disciplines!
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
Eurecom, Sophia-Antipolis 49
Exercises
Ex. 3 - LCFS
Derive the mean queueing time E[T idle.
Q
] LCFS . Derive this by conditioning on whether an arrival finds the system busy or
Solution:
With probability 1 − ρ, the arrival finds the system idle. In that case E[T
Q
] = 0.
With probability ρ, the arrival finds the system busy and has to wait for the whole busy period started by the job in service.
The job in service has remaining size S to wait for the expected duration of a busy period started by S e
, which we denote by E[B(S e e
. Thus the arrival has
)] = E[S e
]/(1−ρ).
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
50 Eurecom, Sophia-Antipolis
Exercises
You can derive this fact by first deriving the mean length of a busy period started by a job of size x, namely E[B(x)]
= x /(1−ρ) , and then deriving E[B(S the probability that S e equals x.
e
)] by conditioning on
Putting these two pieces together, we have
E [ T
Q
]
LCFS =
( 1
r
)
0
r
E [
1
S r e
]
= r
( 1
r
)
E [ S e
]
As expected, this is exactly the mean queueing time under
FCFS.
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
51 Eurecom, Sophia-Antipolis
Exercises
Ex. 4 – Server Farm
Suppose you have a distributed server system consisting of two hosts. Each host is a time-sharing host. Host 1 is twice as fast as Host 2.
Jobs arrive to the system according to a Poisson process with rate
λ = 1/9
.
The job service requirements come from some general distribution D and have mean 3 seconds if run on Host 1.
When a job enters the system, with probability p = 3/4 it is sent to Host 1, and with probability 1 − p = 1/4 is sent to
Host 2.
Question : What is the mean response time for jobs?
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
52 Eurecom, Sophia-Antipolis
Exercises
PS
3/4
Poisson (1/9)
3 sec.
PS
1/4
Solution:
The mean response time is simply:
6 sec.
E[T] = ¾ (Mean response time at server 1)+ ¼ (Mean response time at server 2)
But server 1 (2) is just an M/G/1/PS server, which has the same mean response time as an M/M/1/FCFS server, namely just
E [ T
1
]
=
1
1
l
1
=
1
1
3
1
9
3
4
=
4
E [ T
2
]
=
2
1
l
2
=
1
1
6
1
9
1
4
=
36
5
Thus,
E [ T ]
=
3
4
4
1
4
36
5
=
24 sec
5
Thrasyvoulos Spyropoulos / spyropou@eurecom.fr
53 Eurecom, Sophia-Antipolis
54
55
56