AbstractSyntax
advertisement

Abstract Syntax Trees
COMP2010: Compiler Engineering
Bernd Fischer
b.fischer@ecs.soton.ac.uk
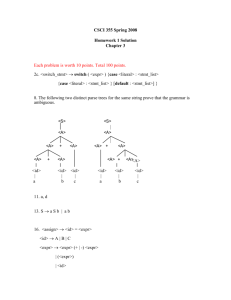
Parse trees represent derivations.
(a+1)*b
E
F
EC
T
(
E
)
F
FC
ID(a)
ε
+
ε
T
EC
*
ID(b) ε
EC
T
FC
F
EC
T
ε
• each path corresponds
to possible call stack
• contains “punctuation”
tokens: (, ), begin, ...
⇒ concrete syntax tree
• contains redundant
non-terminal symbols
⇒ chain rules: E → F → T
⇒ too much detail!
E
NUM(1)
E
EC
F
FC
T
→ F EC
→ + F EC | – F EC | ε
→ T FC
→ * T FC | / T FC | ε
→ ( E ) | ID | NUM
E
*
ID(b)
ID(a) + NUM(1)
?
How do we
get there?
Abstract syntax trees represent
the essential structure of derivations.
Abstract syntax drops detail: (a+1)*b
• punctuation tokens
• chain productions
ID(a)
E
EC
F
FC
T
→ F EC
→ + F EC | – F EC | ε
→ T FC
→ * T FC | / T FC | ε
→ ( E ) | ID | NUM
E
E
*
ID(b)
+ NUM(1)
E → E+E
|E–E
|E*E
|E/E
| ID | NUM
Abstract syntax rules can be ambiguous
• only describes structure of legal trees
• not meant for parsing
• usually allows unparsing (text reconstruction)
⇒ abstract syntax tree (AST) is clean interface
Manually building ASTs in Java
Design principle based on abstract syntax grammar:
• One abstract class per non-terminal
• One concrete class per rule
– One field per non-terminal on rhs
public abstract class Expr {}
public class Num extends Expr {
public int val;
public Num(int v) { val=v;}
}
public class Sum extends Expr {
public Expr left,right;
public Sum(Expr l, Expr r)
{left = l; right = r;}
}
public class Diff extends Expr {
…
Alternatively:
public class Binop extends Expr {
public Expr left,right;
public int op;
public Binop(Expr l, Expr r, int o; )
{left = l; right = r; op = o;}
}
Manually building ASTs in Java
Design principle based on abstract syntax grammar:
• One abstract class per non-terminal
• One concrete class per rule
– One field per non-terminal on rhs
public abstract class Expr {}
For error reporting:
public class Num extends Expr {
public int val;
public Num(int v) { val=v;}
}
public class Expr {
public FilePos start,end;
}
public class Sum extends Expr {
public Expr left,right;
public Sum(Expr l, Expr r)
{left = l; right = r;}
}
public class Diff extends Expr {
…
public class Sum extends Expr {
public Sum(Expr l,r)
{left = l; right = r;
start = l.start; end = r.end;}
}
Manually building ASTs in Java (II)
/* T -> ( E ) | Num */
public static Expr T() throws ParseException {
Expr r;
switch(token) {
case '(':
advance(); r = E(); eat(')'); return r;
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
return Num(); break;
default:
throw new ParseException("in T");
}
}
• change return value type from void
• add explicit returns
• add auxiliary variables for results of recursive calls
Problem: left-factorization
moves left arguments upwards.
-
???
+
E
3+2-1
3
T
NUM(3)
T
NUM(2)
E → T EC
EC → + T EC | – T EC | ε
T → ( E ) | ID | NUM
2
EC
+
EC
–
1
T
EC
NUM(1)
ε
Manually building ASTs in Java (III)
/* E -> F EC */
public static Expr E() throws ParseException {
Expr left = F();
return EC(left);
}
/* EC -> + F EC | - F EC | epsilon */
public static Expr EC(Expr left) throws ParseException {
Expr right;
switch(token) {
add semantic value as argument to
case ')': case '\n':
functions for left-factorized symbols
return left;
case '+':
advance(); right = F();
return EC(new Binop(left, right, PLUS);
case '-':
advance(); right = F();
return EC(new Binop(left, right, MINUS);
default: ...
}
}
ANTLR automates building ASTs.
Design principle: add tree building instructions to rules
rule: rule-elems1 -> build-instr1
| rule-elems2 -> build-instr2
...
| rule-elemsn -> build-instrn
;
• build instructions are automatically executed
when rule is applied
• build instructions return AST node or AST node list
• use with
options{output=AST;ASTLabelType=CommonTree;}
Basic AST building instructions
• reference: use AST node from parse element
trm: '(' exp ')' -> exp;
return exp AST,
ignore brackets
• named reference: resolve ambiguities
add: l=exp '+' r=exp -> $l $r;
• node construction: build tagged node
return list with
both exp ASTs
ext: 'exit' exp -> ^('exit’ exp);
tag token
children
dcl: type ID -> ^(VARDCL ID type);
virtual tag token
children
(must be defined in tokens)
‘exit'
exp
Collecting and duplicating elements
• list elements can be collected into a single list:
args: arg (',' arg)* -> arg+;
• individual elements can be copied into lists:
dcl: type ID (',' ID)*
-> ^(VARDCL type ID+);
VARDCL
type [ID, ID, ID, ...]
vs.
dcl: type ID (',' ID)*
-> ^(VARDCL type ID)+;
VARDCL→ VARDCL→
type
ID type
ID
Building alternative trees
• nodes can be null:
init: exp? -> ^(INIT exp)?;
• nodes can be built for empty input:
skip: -> ^SKIP;
'for'
dcl COND ITER stmts
• sub-trees can be added:
c
i
for: 'for' '(' dcl? ';' c=exp? ';' i=exp? ')' stmts
-> ^('for' dcl? ^(COND $c)? ^(ITER $i)? stmts);
• nodes can be built in rule alternatives:
if: 'if' '(' expr ')' s1=stmt
('else' s2=stmt -> ^(IFELSE expr $s1 $s2)
|
-> ^('if' expr $s1)
);
Updating trees
• nodes can be initialized in rule parts and updated:
exp: (INT
-> INT)
('+' i=INT -> ^('+' $exp $i))*;
1:
1+2:
1+2+3:
INT(1)
'+'
'+'
$exp
INT(2)
$exp
'+'
INT(1) INT(2)
INT(3)
'+'
'+'
INT(3)
INT(1) INT(2)