compiler2
advertisement

Chapter 2
Chang Chi-Chung
2008.03 rev.1
A Simple Syntax-Directed Translator
This chapter contains introductory material to
Chapters 3 to 8
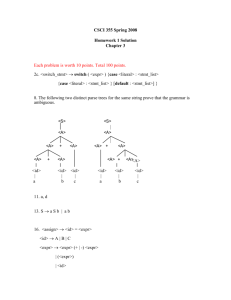
To create a syntax-directed translator that maps
infix arithmetic expressions into postfix
expressions.
Building a simple compiler involves:
Defining the syntax of a programming language
Develop a source code parser: for our compiler
we will use predictive parsing
Implementing syntax directed translation to
generate intermediate code
A Code Fragment To Be Translated
To extend syntax-directed translator to map code fragments into threeaddress code. See appendix A.
{
int i; int j;
float[100] a; float v; float x;
while (true) {
do i = i + 1; while ( a[i] < v );
do j = j – 1; while ( a[j] > v );
if ( i>= j ) break;
x = a[i]; a[i] = a[j]; a[j] = x;
}
}
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
i = i + 1
t1 = a [ i ]
if t1 < v goto 1
j = j -1
t2 = a [ j ]
if t2 > v goto 4
ifFalse i >= j goto 9
goto 14
x = a [ i ]
t3 = a [ j ]
a [ i ] = t3
a [ j ] = x
goto 1
A Model of a Compiler Front End
Source
program
Lexical
analyzer
Token
stream
Parser
Character
Stream
Symbol
Table
Syntax
tree
Intermediate
Code
Generator
Three-address
code
Two Forms of Intermediate Code
Abstract syntax trees
Tree-Address instructions
do-while
body
assign
[]
+
i
i
1:
2:
3:
>
a
1
v
i
i = i + 1
t1 = a [ i ]
if t1 < v goto 1
Syntax Definition
Using Context-free grammar (CFG)
BNF: Backus-Naur Form
Context-free grammar has four components:
A set of tokens (terminal symbols)
A set of nonterminals
A set of productions
A designated start symbol
Example of CFG
G = <T, N, P, S>
T = { +,-,0,1,2,3,4,5,6,7,8,9 }
N = { list, digit }
P=
list list + digit
list list – digit
list digit
digit 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
S = list
Derivations
The set of all strings (sequences of tokens)
generated by the CFG using derivation
Begin with the start symbol
Repeatedly replace a nonterminal symbol in the
current sentential form with one of the right-hand
sides of a production for that nonterminal
Example of the Derivations
list
list + digit
list - digit + digit
digit - digit + digit
9 - digit + digit
9 - 5 + digit
9-5+2
Production
list list + digit
list list – digit
list digit
digit 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Leftmost derivation
replaces the leftmost nonterminal (underlined) in each step.
Rightmost derivation
replaces the rightmost nonterminal in each step.
Parser Trees
Given a CFG, a parse tree according to the grammar is a tree
with following propertes.
The root of the tree is labeled by the start symbol
Each leaf of the tree is labeled by a terminal (=token) or
Each interior node is labeled by a nonterminal
If A X1 X2 … Xn is a production, then node A has immediate
children X1, X2, …, Xn where Xi is a (non)terminal or ( denotes
the empty string)
Example
A XYZ
A
X
Y
Z
Example of the Parser Tree
Parse tree of the string 9-5+2 using grammar G
list
list
list
digit
digit
digit
9
-
5
+
2
The sequence of
leafs is called the
yield of the parse tree
Ambiguity
Consider the following context-free grammar
G = <{string}, {+,-,0,1,2,3,4,5,6,7,8,9}, P, string>
P = string string + string | string - string | 0 | 1 | … | 9
This grammar is ambiguous, because more
than one parse tree represents the string 95+2
Ambiguity (Cont’d)
string
string
string
9
string
string
string
-
5
string
string
+
2
9
string
-
5
string
+
2
Associativity of Operators
Left-associative
If an operand with an operator on both sides of it, then it
belongs to the operator to its left.
Left-associative operators have left-recursive productions
string a+b+c has the same meaning as (a+b)+c
left left + term | term
Right-associative
If an operand with an operator on both sides of it, then it
belongs to the operator to its right.
string a=b=c has the same meaning as a=(b=c)
Right-associative operators have right-recursive productions
right term = right | term
Associativity of Operators (cont’d)
right
list
list
list
digit
letter
right
letter
digit
right
letter
digit
a
+
b
+
left-associative
c
a
=
b
right-associative
=
c
Precedence of Operators
String 9+5*2 has the same meaning as 9+(5*2)
* has higher precedence than +
Constructs a grammar for arithmetic
expressions with precedence of operators.
left-associative : + - (expr)
left-associative:* / (term)
Step 1:
Step 3:
factor digit | ( expr )
expr expr + term
| expr – term
| term
Step 2:
Step 4:
term term * factor
| term / factor
| factor
expr expr + term | expr – term | term
term term * factor | term / factor | factor
factor digit | ( expr )
An Example: Syntax of Statements
The grammar is a subset of Java statements.
This approach prevents the build-up of semicolons
after statements such as if- and while-, which end
with nested substatements.
stmt
|
|
|
|
|
id = expression ;
if ( expression ) stmt
if ( expression ) stmt else stmt
while ( expression ) stmt
do stmt while ( expression ) ;
{ stmts }
stmts stmts stmt
|
Syntax-Directed Translation
Syntax-Directed translation is done by attaching rules
or program fragments to productions in a grammar.
Translate infix expressions into postfix notation. ( in
this chapter )
Infix: 9 – 5 + 2
Postfix: 9 5 – 2 +
An Example
expr expr1 + term
The pseudo-code of the translation
translate expr1 ;
translate term ;
handle + ;
Syntax-Directed Translation (Cont’d)
Two concepts (approaches) related to
Syntax-Directed Translation.
Synthesized Attributes
Syntax-directed definition
Build up a translation by attaching strings (semantic
rules) as attributes to the nodes in the parse tree.
Translation Schemes
Syntax-directed translation
Build up a translation by program fragments which are
called semantic actions and embedded within production
bodies.
Syntax-directed definition
The syntax-directed definition associates
With each grammar symbol (terminals and nonterminals), a
set of attributes.
With each production, a set of semantic rules for computing
the values of the attributes associated with the symbols
appearing in the production.
An attribute is said to be
Synthesized
if its value at a parse-tree node is determined from attribute
values at its children and at the node itself.
Inherited
if its value at a parse-tree node is determined from attribute
values at the node itself, its parent, and its siblings in the parse
tree.
An Example: Synthesized Attributes
An annotated parse tree
Suppose a node N in a parse tree is labeled by
grammar symbol X.
The X.a is denoted the value of attribute a of X at
node N.
expr.t = “95-2+”
expr.t = “95-”
expr.t = “9”
term.t = “2”
term.t = “5”
term.t = “9”
9
-
5
+
2
Semantic Rules
Production
expr expr1 + term
expr expr1 - term
expr term
term 0
term 1
…
term 9
Semantic Rules
expr.t = expr1.t || term.t || ‘+’
expr.t = expr1.t || term.t || ‘-’
expr.t = term.t
term.t = ‘0’
term.t = ‘1’
…
term.t = ‘9’
|| is the operator for string concatenation in semantic rule.
Depth-First Traversals
Tree traversals
Breadth-First
Depth-First
Preorder: N L R
Inorder: L N R
Postorder: L R N
Depth-First Traversals: Postorder、From left to right
procedure visit(node N)
{
for ( each child C of N, from left to right )
{
visit(C);
}
evaluate semantic rules at node N;
}
Example: Depth-First Traversals
expr.t = 95-2+
expr.t = 95expr.t = 9
term.t = 2
term.t = 5
term.t = 9
9
-
5
+
2
Note: all attributes are the synthesized type
Translation Schemes
A translation scheme is a CFG embedded
with semantic actions
Example
rest + term { print(“+”) } rest
Embedded Semantic Action
rest
+
term
{ print(“+”) }
rest
An Example: Translation Scheme
expr
expr
expr
term
9
-
+
term
term { print(‘-’) }
5
{ print(‘9’) }
{ print(‘5’) }
2
{ print(‘+’) }
{ print(‘2’) }
expr expr + term
expr expr – term
expr term
term 0
term 1
…
term 9
{ print(‘+’) }
{ print(‘-’) }
{ print(‘0’) }
{ print(‘1’) }
{ print(‘9’) }
Parsing
The process of determining if a string of
terminals (tokens) can be generated by a
grammar.
Time complexity:
For any CFG there is a parser that takes at most O(n3)
time to parse a string of n terminals.
Linear algorithms suffice to parse essentially all
languages that arise in practice.
Two kinds of methods
Top-down: constructs a parse tree from root to leaves
Bottom-up: constructs a parse tree from leaves to root
Top-Down Parsing
Recursive descent parsing is a top-down method
of syntax analysis in which a set of recursive
procedures is used to process the input.
One procedure is associated with each nonterminal of a
grammar.
If a nonterminal has multiple productions, each production
is implemented in a branch of a selection statement based
on input lookahead information
Predictive parsing
A special form of recursive descent parsing
The lookahead symbol unambiguously determines the flow
of control through the procedure body for each nonterminal.
An Example: Top-Down Parsing
stmt expr ;
| if ( expr ) stmt
| for ( optexpr ; optexpr ; optexpr ) stmt
| other
optexpr
| expr
stmt
for
(
optexpr
ε
;
optexpr
expr
;
optexpr
expr
)
stmt
other
void stmt() {
switch ( lookahead ) {
case expr:
match(expr); match(‘;’); break;
case if:
match(if); match(‘(‘);
match(expr); match(‘)’);
stmt(); break;
case for:
match(for); match(‘(‘);
optexpr(); match(‘;’);
optexpr(); match(‘;’);
stmt expr ;
optexpr(); match(‘)’);
| if ( expr ) stmt
stmt(); break;
| for ( optexpr ; optexpr ; optexpr ) stmt
case other:
| other
match(other); break;
default:
report(“syntax error”);
}
}
Pseudocode For a
Predictive Parser
Use ε-Productions
optexpr | expr
void optexpr() {
if ( lookahead == expr ) match(expr);
}
void match(terminal t) {
if ( lookahead == t )
lookahead = nextTerminal;
else
report(“syntax error”);
}
Example: Predictive Parsing
Parse
Tree
for
LL(1)
stmt
(
optexpr
;
optexpr
optexpr
;
)
stmt
optexpr()match(‘;‘)
optexpr()
match(‘)‘) stmt()
match(for) match(‘(‘)
optexpr()match(‘;‘)
Input
for
(
lookahead
;
expr ;
expr
)
other
FIRST
FIRST() is the set of terminals that appear
as the first symbols of one or more strings
generated from
is Sentential Form
Example
FIRST(stmt) = { expr, if, for, other }
FIRST(expr ;) = { expr }
stmt
|
|
|
expr ;
if ( expr ) stmt
for ( optexpr ; optexpr ; optexpr ) stmt
other
Examples: First
type simple
| ^ id
| array [ simple ] of type
simple integer
| char
| num dotdot num
FIRST(simple) = { integer, char, num }
FIRST(^ id) = { ^ }
FIRST(type) = { integer, char, num, ^, array }
Designing a Predictive Parser
A predictive parser is a program consisting of a
procedure for every nonterminal.
The procedure for nonterminal A
It decides which A-production to use by examining
the lookahead symbol.
Left Factor
Left Recursion
ε Production
Mimics the body of the chosen production.
Applying translation scheme
Construct a predictive parser, ignoring the actions.
Copy the actions from the translation scheme into
the parser
Left Factor
Left Factor
One production for nonterminal A starts with the
same symbols.
Example:
stmt if ( expr ) stmt
| if ( expr ) stmt else stmt
Use Left Factoring to fix it
stmt if ( expr ) stmt rest
rest else stmt | ε
Left Recursion
Left Recursive
An Example:
A production for nonterminal A starts with a self
reference.
A Aα | β
expr expr + term | term
Rewrite the left recursive to right recursive by
using the following rules.
A βR
R αR | ε
Example: Left and Right Recursive
A
A
…
R
R
A
…
A
R
A
R
β
α
α
….
left recursive
α
β
α
α
….
right recursive
α
ε
Abstract and Concrete Syntax
+
-
2
expr
9
5
expr
expr
term
term
helper
term
9
-
5
+
2
Conclusion: Parsing and Translation Scheme
Give a CFG grammar G as below:
expr expr + term { print(‘+’) }
expr expr – term { print(‘-’) }
expr term
term 0
{ print(‘0’) }
term 1
{ print(‘1’) }
…
term 9
{ print(‘9’) }
Semantic actions for translating into postfix notation.
Conclusion: Parsing and Translation Scheme
Step 1
To elimination left-recursion
Technique
A Aα | Aβ | γ
into
A γR
R αR | βR | ε
Use the rule to transforms G.
Conclusion: Parsing and Translation Scheme
Left-Recursion-elimination
expr term rest
rest + term { print(‘+’) } rest
| – term { print(‘-’) } rest
| ε
term 0
term 1
…
term 9
{ print(‘0’) }
{ print(‘1’) }
{ print(‘9’) }
An Example: Left-Recursion-elimination
expr
rest
term
9
{ print(‘9’) }
-
term
{ print(‘-’) }
5 { print(‘5’) }
rest
term { print(‘+’) } rest
+
2
{ print(‘2’) }
expr term rest
rest + term { print(‘+’) } rest
| – term { print(‘-’) } rest
| ε
term 0 { print(‘0’) } | 1 { print(‘1’) } | … | 9 { print(‘9’) }
ε
Conclusion: Parsing and Translation Scheme
Step 2
Procedures for
Nonterminals.
void expr() {
term(); rest();
}
void rest() {
if ( lookahead == ‘+’ ) {
match(‘+’); term();
print(‘+’); rest();
}
else if ( lookahead == ‘-’ ) {
match(‘-’); term();
print(‘-’); rest();
}
else { } //do nothing with the input
}
void term() {
if ( lookahead is a digit ) {
t = lookahead; match(lookahead);
print(t);
}
else
report(“syntax error”);
}
Conclusion: Parsing and Translation Scheme
Step 3
Simplifying the Translator
void rest() {
if ( lookahead == ‘+’ ) {
match(‘+’); term();
print(‘+’); rest();
}
else if (lookahead == ‘-’) {
match(‘-’); term();
print(‘-’); rest();
}
else { }
void rest() {
while ( true ) {
if ( lookahead == ‘+’ ) {
match(‘+’); term();
print(‘+’); continue;
}
else if (lookahead == ‘-’) {
match(‘-’); term();
print(‘-’); continue;
}
break;
}
}
Conclusion: Parsing and Translation Scheme
Complete
import java.io.*;
class Parser {
static int lookahead;
public Parser() throws IOException {
lookahead = System.in.read();
}
void expr() {
term();
while ( true ) {
if ( lookahead == ‘+’ ) {
match(‘+’); term();
System.out.write(‘+’);
continue;
}
else if (lookahead == ‘-’) {
match(‘-’); term();
System.out.write(‘-’);
continue;
}
else return;
}
void term() throws IOException {
if (Character.isDigit((char)lookahead){
System.out.write((char)lookahead);
match(lookahead);
}
else throw new Error(“syntax error”);
}
void match(int t) throws IOException {
if ( lookahead == t )
lookahead = System.in.read();
else throw new Error(“syntax error”);
}
}