Document
advertisement

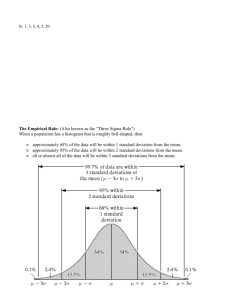
MM207 Statistics Welcome to the Unit 6 Seminar Wednesday, March 7, 2012 8 to 9 PM ET The Normal Shape • This is a histogram for a distribution of 300 natural births. The left vertical axis shows the number of births for each 4-day bin*. The right vertical axis shows relative frequencies * A bin is a group or class. The Normal Shape The distribution of the birth data has a fairly distinctive shape, which is easier to see if we overlay the histogram with a smooth curve. Characteristics of the Normal Curve • The distribution is single-peaked. Its mode, or most common birth date, is the due date. • The distribution is symmetric around its single peak; therefore, its median and mean are the same as its mode. The median is the due date because equal numbers of births occur before and after this date. The mean is also the due date because, for every birth before the due date, there is a birth the same number of days after the due date. • The distribution is spread out in a way that makes it resemble the shape of a bell, so we call it a “bell-shaped” distribution. • The total area under the curve is equal to 1.00 • The curve approaches the horizontal axis but never touches it Variation in Distributions Both distributions are normal and have the same mean of 75, but the distribution on the left has a larger standard deviation. When Can We Expect a Normal Distribution? A data set that satisfies the following four criteria is likely to be normally distributed 1. Most data values are clustered near the mean, giving the distribution a well-defined single peak. 2. Data values are spread evenly around the mean, making the distribution symmetric. 3. Larger deviations from the mean become increasingly rare, producing the tapering tails of the distribution. 4. Individual data values result from a combination of many different factors, such as genetic and environmental factors. An Example of a Normal Distribution Consider a Consumer Reports survey in which participants were asked how long they owned their last TV set before they replaced it. The variable of interest in this survey is replacement time for television sets. •Based on the survey, the distribution of replacement times has a mean of about 8.2 years, which we denote as µ (the Greek letter mu). •The standard deviation of the distribution is about 1.1 years, which we denote as σ (the Greek letter sigma). Television Replacement Distribution Making the reasonable assumption that the distribution of TV replacement times is approximately normal, we can picture it as shown “mu” = µ = 8.2 “sigma”= σ = 1.1 68-95-99.7 Rule or Empirical Rule This rule gives guidelines for the percentage of data values that will lie within 1, 2, and 3 standard deviations of the mean for any normal distribution. “mu” = µ = 8.2 “sigma”= σ = 1.1 That is from 7.1 years to 9.3 years That is from 6 years to 10.4 years That is from 4.9 years to 11.5 years Finding a Percentile On a visit to the doctor’s office, your fourth-grade daughter is told that her height is 1 standard deviation above the mean for her age and sex. What is her percentile for height? Assume that heights of fourth-grade girls are normally distributed. • • • • • Recall that a data value lies in the nth percentile of a distribution if n% of the data values are less than or equal to it (see Section 4.3). According to the 68-95-99.7 rule, 68% of the heights are within 1 standard deviation of the mean. Therefore, 34% of the heights (half of 68%) are between 0 and 1 standard deviation above the mean. We also know that, because the distribution is symmetric, 50% of all heights are below the mean. Therefore, 50% + 34% = 84% of all heights are less than 1 standard deviation above the mean (Figure 5.21). Your daughter is in the 84th percentile for heights among fourth-grade girls Finding a Percentile Interpretation: Find the percentile for 1 standard deviation above the mean for her age and sex. Assume that heights of fourth-grade girls are normally distributed. What is her percentile if she were 1 standard deviation BELOW the mean? Introduction to Standard Scores • Remember the Empirical Rule!!! • Sample Curve • μ = 500 • σ = 100 • How many Standard Deviations away from the mean is: • • • • • 300 800 250 500 650 200 300 400 500 600 700 800 -3 -2 -1 0 +1 +2 +3 Computing Standard Scores • The number of standard deviations a data value lies above or below the mean is called its standard score (or z-score), defined by data value – mean standard deviation z = standard score = = (x – µ) / σ • The standard score is positive for data values above the mean and negative for data values below the mean. Getting More Precise Standard Scores and Percentiles Once we know the standard score of a data value, the properties of the normal distribution allow us to find its percentile in the distribution. This is usually done with a standard score table. (In eText see “chapter BM” for Back matter to get Appendix A on pages 446-447) Example 1 Example 2 A college admissions test is scaled so that scores have a mean of 500 and a standard deviation of 100.(You will use StatCrunch, but you must understand theory.) Finding Z Scores from Percentiles i.e. (working backwards) Example: Given the mean cholesterol level of 178 and the standard deviation of 41, What cholesterol level corresponds to the 90th percentile? The 90th percentile would be on the POSITIVE Z table since it is larger than the 50th percentile. Right? Go to that table and SCAN the body looking for the value closest to .9000 (the 90th percentile). Move your fingers back to the left to get the x.y part of the Z xcore. Move you finger up to see the .0w part of the score. Now add these values to make the score x.yz. All z scores have 2 digits to the right of the decimal. So moving to left we get 1.2; moving up we see .08; add these gives 1.2 + .08 = 1.28 as our z score. Finding Z Scores from Percentiles i.e. (working backwards) Example: Given the mean cholesterol level of 178 and the standard deviation of 41, What cholesterol level corresponds to the 90th percentile? Now z = 1.28. Thus, the 90th percentile is about 1.28 standard deviations above the mean. Finally, give this z score in terms of the problem application or the x value. Use the formula z = (x – µ) / σ and solve for x. You can do the algebra or just trust me that is x = µ + (z)* σ For our problem, 178 + (1.28 * 41) = 230.48 Therefore, A cholesterol level of about 230.48 or 230 corresponds to the 90th percentile. The Central Limit Theorem Suppose we take many random samples of size n for a variable with any distribution (not necessarily a normal distribution) and record the distribution of the means of each sample. Then, 1. The distribution of means will be approximately a normal distribution for large sample sizes. n>30 is magic number 2. The mean of the distribution of means approaches the population mean, µ, for large sample sizes. 3. The standard deviation of the distribution of means approaches σ/√n for large sample sizes, where σ is the standard deviation of the population. The Interpretation of the Central Limit Theorem If you have a group of size n, instead of one individual selection (like the problems we did earlier) the only difference in working the problem is how you COMPUTE the Z Score. Use the formula z = (given sample mean – µ) / [σ/√n ] Also, see Example 1 of Section 5.3 called Predicting Test Score. Be sure to notice the difference in part a and part b. In part a, you have ONE person and in part b you have a group of 100 people. CLT Demonstrated (Figure 5.26) The Value of the Central Limit Theorem • The Central Limit Theorem allows us to say something about the mean of a group if we know the mean, µ, and the standard deviation, σ, of the entire population. This can be useful, but it turns out that the opposite application is far more important. • Two major activities of statistics are making estimates of population means and testing claims about population means. Is it possible to make a good estimate of the population mean knowing only the mean of a much smaller sample? • As you can probably guess, being able to answer this type of question lies at the heart of statistical sampling, especially in polls and surveys. The Central Limit Theorem provides the key to answering such questions. Computing Probabilities in MSL EASY! Example 1 Note: the icon here is not data for the problem but a standard scores for the specific distribution given in this problem. Example 1-Part a: find the percentage of scores greater than 1866. Choose Calculator -> Normal then put in the mean, st dev and value in question, 1866. Be sure to choose => for “greater than or equal”. Click Compute to get the graph and answer shown in the second picture below. The answer is .15865 which as a percentage is 15.865 and rounds to 15.87% with two decimals as asked for in the question. Example 1 - Part c: find the percentage of scores between 1389 and 2184. There are 3 steps to this one. To get area between you must subtract the Area of the LEFTMOST value FROM the area of the RIGHTMOST value. Compute percentage less than 2184; compute percentage of 1389; then Subtract. From below you see .97724986 - .30853754 = .66871232 Which is 66.871% and rounded to 2 places is 66.87%. Example 2 - Part c: find the probability the mean blood pressure is less than 111 for a sample of 280 women. Since n > 1, this is Central Limit Theorem. Be sure to compute new Standard deviation as sigma / sqrt(n) before plugging into StatCrunch. Standard deviation = 13.22 / sqrt(280) = 13.22 / 16.73 = .79 ~.8 Questions?