Example
advertisement

SEG 2106
SOFTWARE CONSTRUCTION
INSTRUCTOR: HUSSEIN AL OSMAN
THE COURSE MATERIAL IS BASED ON THE COURSE
CONSTRUCTED BY PROFS:
GREGOR V. BOCHMANN (HTTPS://WWW.SITE.UOTTAWA.CA/~BOCHMANN/)
JIYING ZHAO (HTTP://WWW.SITE.UOTTAWA.CA/~JYZHAO/)
COURSE SECTIONS
Section 0: Introduction
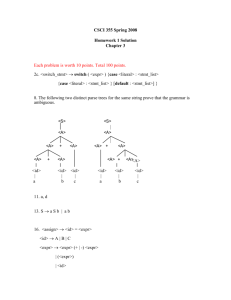
Section 1: Software development processes + Domain Analysis
Section 2: Requirements + Behavioral Modeling (Activity Diagrams)
Section 3: More Behavioral Modeling (State Machines)
Section 4: More Behavioral Modeling (Case Study)
Section 5: Petri Nets
Section 6: Introduction to Compilers
Section 7: Lexical Analysis
Section 8: Finite State Automata
Section 9: Practical Regular Expressions
Section 10: Introduction to Syntax Analysis
Section 11: LL(1) Parser
Section 12: More on LL Parsing (Error Recovery and non LL(1) Parsers)
Section 13: LR Parsing
Section 14: Introduction to Concurrency
Section 15: More on Concurrency
Section 16: Java Concurrency
Section 17: Process Scheduling
Section 18: Web Services
2
SECTION 0
SYLLABUS
3
WELCOME TO SEG2106
4
COURSE INFORMATION
Instructor: Hussein Al Osman
E-mail: halosman@uottawa.ca
Office: SITE4043
Office Hours: TBD
Web Site: Virtual Campus (https://maestro.uottawa.ca)
13:00 - 14:30
STE C0136
Lectures: Wednesday
Labs:
Friday
13:00 - 14:30
MRT 211
Monday
17:30 - 20:30
STE 2052
Tuesday
19:00 - 22:00
STE 0131
5
EVALUATION SCHEME
Assignments (4)
25%
Labs (7)
15%
Midterm Exam
20%
Final Exam
40%
Late assignments are accepted for a maximum of 24 hours
and they will receive a 30% penalty.
6
LABS
Seven labs in total
Three formal labs (with a report)
• Worth between 3 to 4%
The other labs are informal (without a report)
• 1% for each one
• You show you work to the TA at the end of the session
7
INFORMAL LABS
Your mark will be proportional to the number of task
successfully completed:
•
•
•
•
All the tasks are completed: 1%
More than half completed: 0.75%
Almost half is completed: 0.5%
You have tried at least (given that you attended the whole
session): 0.25%
8
MAJOR COURSE TOPICS
Chapter 1: Introduction and Behavioral Modeling
• Introduction to software development processes
• Waterfall model
• Iterative (or incremental) model
• Agile model
• Behavioral modeling
•
•
•
•
•
•
UML Use case models (seen previously)
UML Sequence diagrams (seen previously)
UML activity diagrams (very useful to model concurrent behavior)
UML state machines (model the behavior of a single object)
Petri Nets
SDL
9
MAJOR COURSE TOPICS
Chapter 2: Compilers, formal languages and grammars
• Lexical analysis (convert a sequence of characters into a sequence of tokens)
• Formal languages
• Regular expressions (method to describe strings)
• Deterministic and Non-deterministic Finite Automata
• Syntax analysis
• Context-free grammar (describes the syntax of a programming language)
• Syntactic analysis
• Syntax trees
10
MAJOR COURSE TOPICS
Chapter 3: Concurrency
•
•
•
•
•
Logical and physical concurrency
Process scheduling
Mutual exclusion for access to shared resources
Concurrency and Java programing
Design patterns and performance considerations
11
MAJOR COURSE TOPICS
Chapter 4: Cool topics! We will vote on one or more of these
topics to cover (given that we have completed the above
described material, with some time to spare)
•
•
•
•
•
•
Mobile programing (mostly Android)
Web services
J2EE major components
Spring framework
Agile programing (especially SCRUM)
Other suggestions…
12
CLASS POLICIES
Late Assignments
• Late assignments are accepted for a maximum of 24 hours
and they will receive a 30% penalty.
13
CLASS POLICIES
Plagiarism
• Plagiarism is a serious academic offence that will not be tolerated.
• Note that the person providing solutions to be copied is also
committing an offence as they are an active participant in the
plagiarism.
• The person copying and the person copied from will be reprimanded
equally according to the regulations set by the University of Ottawa.
•
• Please refer to this link for more information:
www.uottawa.ca/academic/info/regist/crs/0305/home_5_ENG.htm.
14
CLASS POLICIES
Attendance
• Class attendance is mandatory. As per academic regulations,
students who do not attend 80% of the class will not be
allowed to write the final examinations.
• All components of the course (i.e laboratory reports,
assignments, etc.) must be fulfilled otherwise students may
receive an INC as a final mark (equivalent to an F).
• Absence from a laboratory session or an examination
because of illness will be excused only if you provide a
certificate from Health Services (100 Marie Curie, 3rd Floor)
within the week following your absence.
15
SECTION 1
SOFTWARE
DEVELOPMENT
PROCESS AND
DOMAIN ANALYSIS
LECTURE TOPICS
This lecture will briefly touch on the
following topics:
• Software Development Process
• Domain Analysis
TOPIC 1
SOFTWARE
DEVELOPMENT
PROCESS
LIFE CYCLE
The life cycle of a software product
• from inception of an idea for a product through
•
•
•
•
•
•
•
domain analysis
requirements gathering
architecture design and specification
coding and testing
delivery and deployment
maintenance and evolution
retirement
MODELS ARE NEEDED
Symptoms of inadequacy: the software crisis
• scheduled time and cost exceeded
• user expectations not met
• poor quality
The size and economic value of software
applications required appropriate "process models"
PROCESS AS A
"BLACK BOX"
Informal
Requirements
Process
Product
PROBLEMS
The assumption is that requirements can be fully
understood prior to development
Unfortunately the assumption almost never holds
Interaction with the customer occurs only at the
beginning (requirements) and end (after delivery)
PROCESS AS A
"WHITE BOX"
Informal
Requirements
Process
Product
feedback
ADVANTAGES
Reduce risks by improving visibility
Allow project changes as the project progresses
• based on feedback from the customer
THE MAIN ACTIVITIES
They must be performed independently of
the model
The model simply affects the flow among
activities
WATERFALL MODELS
Invented in the late 1950s for large air defense
systems, popularized in the 1970s
They organize activities in a sequential flow
• Standardize the outputs of the various activities
(deliverables)
Exist in many variants, all sharing sequential flow
style
A WATERFALL MODELS
Domain analysis and feasibility study
Requirements
Design
Coding and module testing
Integration and system testing
Delivery, deployment, and
maintenance
WATERFALL STRENGTHS
Easy to understand, easy to use
Provides structure to inexperienced staff
Milestones are well understood
Sets requirements stability
WATERFALL WEAKNESSES
All requirements must be known upfront
Deliverables created for each phase are considered frozen –
inhibits flexibility
Can give a false impression of progress
Does not reflect problem-solving nature of software
development – iterations of phases
Integration is one big bang at the end
Little opportunity for customer to preview the system (until it
may be too late)
WHEN TO USE WATERFALL
Requirements are very well known
Product definition is stable
Technology is very well understood
New version of an existing product (maybe!)
Porting an existing product to a new platform
• High risk for new systems because of specification and
design problems.
• Low risk for well-understood developments using familiar
technology.
WATERFALL – WITH
FEEDBACK
Domain analysis and feasibility study
Requirements
Design
Coding and
module testing
Integration and
system testing
Delivery, deployment, and
maintenance
ITERATIVE DEVELOPMENT
PROCESS
Also referred to as incremental development process
Develop system through repeated cycle (iterations)
• Each cycle is responsible for the development of a small
portion of the solution (slice of functionality)
Contrast with waterfall:
• Water fall is a special iterative process with only one cycle
ITERATIVE DEVELOPMENT
PROCESS
Domain Analysis and
Initial Planning
Update Architecture
and Design
Requirements
Iteration
Planning
Cycle
Evaluation (involving
end user)
Deployment
Implementation
Testing
AGILE METHODS
Dissatisfaction with the overheads involved in software
design methods of the 1980s and 1990s led to the creation of
agile methods. These methods:
• Focus on the code rather than the design
• Are based on an iterative approach to software development
• Are intended to deliver working software quickly and evolve
this quickly to meet changing requirements
The aim of agile methods is to reduce overheads in the
software process (e.g. by limiting documentation) and to be
able to respond quickly to changing requirements without
excessive rework.
AGILE MANIFESTO
We are uncovering better ways of developing software by
doing it and helping others do it. Through this work we have
come to value:
•
•
•
•
Individuals and interactions over processes and tools
Working software over comprehensive documentation
Customer collaboration over contract negotiation
Responding to change over following a plan
That is, while there is value in the items on the right, we value
the items on the left more.
THE PRINCIPLES OF AGILE
METHODS
Principle
Customer involvement
Description
Customers should be closely involved throughout the development
process. Their role is to provide and prioritize new system
requirements and to evaluate the iterations of the system.
Incremental delivery
The software is developed in increments with the customer specifying
the requirements to be included in each increment.
People not process
The skills of the development team should be recognized and
exploited. Team members should be left to develop their own ways of
working without prescriptive processes.
Embrace change
Expect the system requirements to change and so design the system
to accommodate these changes.
Focus on simplicity in both the software being developed and in the
development process. Wherever possible, actively work to eliminate
complexity from the system.
Maintain simplicity
SCRUM PROCESS
PROBLEMS WITH AGILE
METHODS
It can be difficult to keep the interest of customers
who are involved in the process
Team members may be unsuited to the intense
involvement that characterizes agile methods
Prioritizing changes can be difficult where there
are multiple stakeholders
Minimizing documentation: almost nothing is
captured, the code is the only authority
TOPIC 2
DOMAIN ANALYSIS
DOMAIN MODELING
The aim of domain analysis is to understand the problem
domain independently of the particular system we intend to
develop.
We do not try to draw the borderline between the system and
the environment.
We focus on the concepts and the terminology of the
application domain with a wider scope than the future
system.
ACTIVITIES AND RESULTS
OF DOMAIN ANALYSIS
1. A dictionary of terms defining the common terminology
and concepts of the problem domain;
2. Description of the problem domain from a conceptual
modeling viewpoint
• We normally use UML class diagrams (with as little detail as
possible)
• Remember, we are not designing, but just establishing the
relationship between entities
3. Briefly describe the main interactions between the user
and the system
EXAMPLE – PROBLEM
DEFINITION
EXAMPLE – PROBLEM
DEFINITION
We want to design the software for a simple Point of Sale
Terminal that operates as follows:
• Displays that amount of money to pay for the goods to be
purchased
• Asks the user to insert a financial card (debit or credit)
• If the user inserts a debit card, he or she is asked to
choose the account type
• Asks the user to enter a pin number
• Verifies the pin number against the one stored on the chip
• Contacts the bank associated with the card in order to
perform the transaction
EXAMPLE – DICTIONARY
OF TERMS (1)
Point of Sale Terminal: machine that allows a retail transaction
to be completed using a financial card
Credit card: payment card issued to users as a system of
payment. It allows the cardholder to pay for goods and services
based on the holder's promise to pay for them
Debit card: plastic payment card that provides the cardholder
electronic access to his or her bank account
EXAMPLE – DICTIONARY
OF TERMS (2)
Bank: financial institution that issues financial cards and where the user
has at least one account into which he or she can withdraw or deposit
money
Bank Account: is a financial account between a user and a financial
institution…
User: client of that possesses a debit card and benefits from the use of a
point of sale terminal
Pin number: personal identification number (PIN, pronounced "pin";
often erroneously PIN number) is a secret numeric password shared
between a user and a system that can be used to authenticate the user
to the system
EXAMPLE – PROBLEM
DOMAIN
PinNumber
1
User
*
FinancialCard
*
1..2
BankAccount
*
DebitCard
CreditCard
1
PosTerminal
1..*
Bank
EXAMPLE – MAIN
INTERACTIONS
Inputs to POS Terminal: Insertion of Financial Card, Pin
Number, Specify Account, Confirm purchase…
Outputs from POS Terminal: Error Message (regarding pin or
funds), Confirmation of Purchase,
SECTION 2
REQUIREMENTS
BEHAVIORAL MODELING
TOPICS
Review of some notions regarding requirements
• Client requirements
• Functional requirements
• Non-functional requirements
Introduction to Behavioral Modeling
• Activity Diagrams
TOPIC 1
REQUIREMENTS
REQUIREMENTS
We will describe three types of requirements:
• Customer requirements (a.k.a informal or business
requirements)
• Functional requirements
• Non-functional requirements
CUSTOMER
REQUIREMENTS
We have completed the domain analysis, we are ready to get
our hands dirty
We need to figure out exactly what the customer wants:
Customer Requirements
• This is where the expectations of the customer are captured
Composed typically of high level, non-technical statements
Example
• Requirement 1: “We need to develop an online customer
portal”
• Requirement 2: “The portal must list all our products”
•…
FUNCTIONAL
REQUIREMENTS
Capture the intended behavior of the system
• May be expressed as services, tasks or functions the
system performs
Use cases have quickly become a widespread practice for
capturing functional requirements
• This is especially true in the object-oriented community where
they originated
• Their applicability is not limited to object-oriented systems
USE CASES
A use case defines a goal-oriented set of interactions
between external actors and the system under consideration
Actors are parties outside the system that interact with the
system
• An actor may be a class of users or other systems
A use case is initiated by a user with a particular goal in
mind, and completes successfully when that goal is satisfied
It describes the sequence of interactions between actors and
the system necessary to deliver the service that satisfies the
goal
USE CASE DIAGRAMS
USE CASE DIAGRAMS
Include relationship: use case fragment that is duplicated in
multiple use cases
Extend relationship: use case conditionally adds steps to
another first class use case
• Example:
USE CASE – ATM EXAMPLE
Actors:
• ATM Customer
• ATM Operator
Use Cases:
• The customer can
• withdraw funds from a checking or savings account
• query the balance of the account
• transfer funds from one account to another
• The ATM operator can
• Shut down the ATM
• Replenish the ATM cash dispenser
• Start the ATM
USE CASE – ATM EXAMPLE
USE CASE – ATM EXAMPLE
Validate PIN is an Inclusion Use Case
• It cannot be executed on its own
• Must be executed as part of a Concrete Use Case
On the other hand, a Concrete Use Case can be executed
USE CASE – VALIDATE PIN
(1)
Use case name: Validate PIN
Summary: System validates customer PIN
Actor: ATM Customer
Precondition: ATM is idle, displaying a Welcome
message.
USE CASE – VALIDATE PIN
(2)
Main sequence:
1.
2.
3.
4.
5.
Customer inserts the ATM card into the card reader.
If system recognizes the card, it reads the card number.
System prompts customer for PIN.
Customer enters PIN.
System checks the card's expiration date and whether the
card has been reported as lost or stolen.
6. If card is valid, system then checks whether the userentered PIN matches the card PIN maintained by the
system.
7. If PIN numbers match, system checks what accounts are
accessible with the ATM card.
8. System displays customer accounts and prompts customer
for transaction type: withdrawal, query, or transfer.
USE CASE – VALIDATE PIN
(3)
Alternative sequences:
Step 2: If the system does not recognize the card, the system ejects
the card.
Step 5: If the system determines that the card date has expired, the
system confiscates the card.
Step 5: If the system determines that the card has been reported lost
or stolen, the system confiscates the card.
Step 7: If the customer-entered PIN does not match the PIN number
for this card, the system re-prompts for the PIN.
Step 7: If the customer enters the incorrect PIN three times, the
system confiscates the card.
Steps 4-8: If the customer enters Cancel, the system cancels the
transaction and ejects the card.
Postcondition: Customer PIN has been validated.
USE CASE – WITHDRAW
FUNDS (1)
Use case name: Withdraw Funds
Summary: Customer withdraws a specific amount
of funds from a valid bank account.
Actor: ATM Customer
Dependency: Include Validate PIN use case.
Precondition: ATM is idle, displaying a Welcome
message.
USE CASE – WITHDRAW
FUNDS (2)
Main sequence:
1. Include Validate PIN use case.
2. Customer selects Withdrawal, enters the amount,
and selects the account number.
3. System checks whether customer has enough
funds in the account and whether the daily limit
will not be exceeded.
4. If all checks are successful, system authorizes
dispensing of cash.
5. System dispenses the cash amount.
6. System prints a receipt showing transaction
number, transaction type, amount withdrawn, and
account balance.
7. System ejects card.
8. System displays Welcome message.
USE CASE – WITHDRAW
FUNDS (3)
Alternative sequences:
Step 3: If the system determines that the account
number is invalid, then it displays an error message
and ejects the card.
Step 3: If the system determines that there are
insufficient funds in the customer's account, then it
displays an apology and ejects the card.
Step 3: If the system determines that the maximum
allowable daily withdrawal amount has been
exceeded, it displays an apology and ejects the card.
Step 5: If the ATM is out of funds, the system displays
an apology, ejects the card, and shuts down the ATM.
Postcondition: Customer funds have been withdrawn.
NON-FUNCTIONAL
REQUIREMENTS
Functional requirements define what a system is supposed
to do
Non-functional requirements define how a system is
supposed to be
• Usually describe system attributes such as security, reliability,
maintainability, scalability, usability…
NON-FUNCTIONAL
REQUIREMENTS
Non-Functional requirements can be specified in a separate
section of the use case description
• In the previous example, for the Validate PIN use case, there
could be a security requirement that the card number and PIN
must be encrypted
Non-Functional requirements can be specified for a group of
use cases or the whole system
• Security requirement: System shall encrypt ATM card
number and PIN.
• Performance requirement: System shall respond to actor
inputs within 5 seconds.
TOPIC 2
BEHAVIORAL MODELING
SOFTWARE MODELING
UML defines thirteen basic diagram types, divided into two
general sets:
• Structural Modeling
• Behavioral Modeling
Structural Models define the static architecture of a model
• They are used to model the “things” that make up a model –
the classes, objects, interfaces and physical components
• In addition they are used to model the relationships and
dependencies between elements
BEHAVIORAL MODELING
Behavior Models capture the dynamic behavior of a system
as it executes over time
They provide a view of a system in which control and
sequencing are considered
• Either within an object (by means of a finite state machine) or
between objects (by analysis of object interactions).
UML ACTIVITY DIAGRAMS
In UML an activity diagram is used to display the sequence of
actions
They show the workflow from start to finish
• Detail the many decision paths that exist in the progression of
events contained in the activity
Very useful when parallel processing may occur in the
execution of some activities
UML ACTIVITY DIAGRAMS
An example of an activity diagram is shown below
(We will come back to that diagram)
ACTIVITY
An activity is the specification of a parameterized sequence
of behavior
Shown as a round-cornered rectangle enclosing all the
actions and control flows
ACTIONS AND
CONSTRAINS
An action represents a single step within an activity
Constraints can be attached to actions
CONTROL FLOW
Shows the flow of control from one action to the next
• Its notation is a line with an arrowhead.
Initial Node
Final Node, two types:
Activity Final Node
Flow Final Node
OBJECTS FLOW
An object flow is a path along which objects or data can pass
• An object is shown as a rectangle
A short hand for the above notation
DECISION AND MERGE
NODES
Decision nodes and merge nodes have the same notation: a
diamond shape
The control flows coming away from a decision node will
have guard conditions
FORK AND JOIN NODES
Forks and joins have the same notation: either a horizontal or
vertical bar
• They indicate the start and end of concurrent threads of
control
• Join synchronizes two inflows and produces a single outflow
• The outflow from a join cannot execute until all inflows have
been received
PARTITION
Shown as horizontal or vertical swim lane
• Represents a group of actions that have some common
characteristic
UML ACTIVITY DIAGRAMS
Coming back to our initial example
ISSUE HANDLING IN
SOFTWARE PROJECTS
Courtesy of uml-diagrams.org
MORE ON ACTIVITY
DIAGRAMS
Interruptible Activity Regions
Expansion Regions
Exception Handlers
INTERRUPTIBLE ACTIVITY
REGION
Surrounds a group of actions that can be interrupted
Example below:
• “Process Order” action will execute until completion, when it
will pass control to the “Close Order” action, unless a “Cancel
Request” interrupt is received, which will pass control to the
“Cancel Order” action.
EXPANSION REGION
An expansion region is an activity region that executes
multiple times to consume all elements of an input collection
Example of books checkout at a library modeled using an
expansion region:
Checkout Books
Find Books to
Borrow
Checkout
Book
Show Due
Date
Place Books
in Bags
EXPANSION REGION
Another example: Encoding Video
Encode Video
Capture Video
Extract Audio
from Frame
Encode Video
Frame
Attach Audio
to Frame
Save Encoded
Video
EXCEPTION HANDLERS
An exception handler is an element that specifies what to
execute in case the specified exception occurs during the
execution of the protected node
In Java
• “Try block” corresponds to “Protected Node”
• “Catch block” corresponds to the “Handler Body Node”
SECTION 3
BEHAVIORAL MODELING
TOPICS
We will continue with the subject of Behavioral Modeling
Introduce the various components of UML state machines
ACTIVITY DIAGRAMS VS
STATE MACHINES
In Activity Diagrams
• Vertices represent Actions
• Edges (arrows) represent transition that occurs at the
completion of one action and before the start of another one
(control flow)
Vertex representing
an Action
Arrow implying
transition from one
action to another
ACTIVITY DIAGRAMS VS
STATE MACHINES
In State Machines
• Vertices represent states of a process
• Edges (arrows) represent occurrences of events
Vertex representing a
State
Arrow representing
an event
UML STATE MACHINES
Used to model the dynamic behaviour of a process
• Can be used to model a high level behaviour of an entire
system
• Can be used to model the detailed behaviour of a single
object
• All other possible levels of detail in between these extremes is
also possible
UML STATE MACHINE
EXAMPLE
Example of a garage door state machine
(We will come back to this example later)
STATES
Symbol for a state
A system in a state will remain in it until the occurrence of an
event that will cause it to transition to another one
• Being in a state means that a system will behave in a
predetermined way in response to a given event
Symbols for the initial and final states
STATES
Numerous types of events can cause the system to transition
from one state to another
In every state, the system behaves in a different matter
Names for states are usually chosen as:
• Adjectives: open, closed, ready…
• Present continuous verbs: opening, closing, waiting…
TRANSITIONS
Transitions are represented with arrows
TRANSITIONS
Transitions represent a change in a state in response to an
event
• Theoretically, it is supposed to occur in a instantaneous
manner (it does not take time to execute)
A transition can have”
• Trigger: causes the transition; can be an event of simply the
passage of time
• Guard: a condition that must evaluate to true for the transition
to occur
• Effect: an action that will be invoked directly on the system of
the object being modeled (if we are modeling an object, the
effect would correspond to a specific method)
STATE ACTIONS
An effect can also be associated with a state
If a destination state is associated with numerous incident
transitions (transitions arriving a that state), and every
transition defines the same effect:
• The effect can therefore be associated with the state instead
of the transitions (avoid duplications)
• This can be achieved using an “On Entry” effect (we can have
multiple entry effects)
• We can also add one or more “On Exit” effect
SELF TRANSITION
State can also have self transitions
• These self transition are more useful when they have an
effect associated with them
Timer events are usually popular with self transitions
Below is a typical example:
COMING BACK TO OUR
INITIAL EXAMPLE
Example of a garage door state machine
DECISIONS
Just like activity diagrams, we can use decisions nodes
(although we usually call them decision pseudo-states)
Decision pseudo-states are represented with a diamond
• We always have one input transition and multiple outputs
• The branch of execution is decided by the guards associated
with the transitions coming out of the decision pseudo-state
DECISIONS
COMPOUND STATES
A state machine can include several sub-machines
Below is an example of a sub-machine included in the
compound state “Connected”
Connected
Waiting
receiveByte
disconnect
byteProcessed
Disconnected
connect
ProcessingByte
closeSession
COMPOUND STATES
EXAMPLE
COMPOUND STATES
EXAMPLE
Same example, with an alternative notation
• The link symbol in the “Check Pin” state indicates that the
details of the sub-machine associated with “Check Pin” are
specified in an another state machine
ALTERNATIVE ENTRY
POINTS
Sometimes, in a sub-machine, we do not want to start the
execution from the initial state
• We want to start the execution from a “name alternative entry
point”
PerformActivity
ALTERNATIVE ENTRY
POINTS
Here’s the same system, from a higher level
• Transition from the “No Already Initialized” state leads to the
standard initial state in the sub-machine
• Transition from the “Already Initialized” state is connected to
the named alternative entry point “Skip Initializing”
ALTERNATIVE EXIT
POINTS
It is also possible to have alternative exit points for a
compound state
• Transition from “Processing Instructions” state takes the
regular exit
• Transition from the “Reading Instructions” state takes an
"alternative named exit point
USE CASE – VALIDATE PIN
(1)
Use case name: Validate PIN
Summary: System validates customer PIN
Actor: ATM Customer
Precondition: ATM is idle, displaying a Welcome
message.
USE CASE – VALIDATE PIN
(2)
Main sequence:
1.
2.
3.
4.
5.
Customer inserts the ATM card into the card reader.
If system recognizes the card, it reads the card number.
System prompts customer for PIN.
Customer enters PIN.
System checks the card's expiration date and whether the
card has been reported as lost or stolen.
6. If card is valid, system then checks whether the userentered PIN matches the card PIN maintained by the
system.
7. If PIN numbers match, system checks what accounts are
accessible with the ATM card.
8. System displays customer accounts and prompts customer
for transaction type: withdrawal, query, or transfer.
USE CASE – VALIDATE PIN
(3)
Alternative sequences:
Step 2: If the system does not recognize the card, the system ejects
the card.
Step 5: If the system determines that the card date has expired, the
system confiscates the card.
Step 5: If the system determines that the card has been reported lost
or stolen, the system confiscates the card.
Step 7: If the customer-entered PIN does not match the PIN number
for this card, the system re-prompts for the PIN.
Step 7: If the customer enters the incorrect PIN three times, the
system confiscates the card.
Steps 4-8: If the customer enters Cancel, the system cancels the
transaction and ejects the card.
Postcondition: Customer PIN has been validated.
ATM MACHINE EXAMPLE
Validate PIN:
ATM MACHINE EXAMPLE
Funds withdrawal:
SECTION 4
BEHAVIORAL MODELING
TOPICS
We will continue to talk about UML State Machine
We will go through a complete example of a simple software
construction case study with emphasis on UML State
Machines
End this section with some final words of wisdom!
LAST LECTURE
We have talked about UML State Machines
•
•
•
•
•
•
States and transitions
State effects
Self Transition
Decision pseudo-states
Compound states
Alternative entry and exit points
Today, we will tackle more advanced UML State Machines
Concepts
HISTORY STATES
A state machine describes the dynamic aspects of a process
whose current behavior depends on its past
A state machine in effect specifies the legal ordering of
states a process may go through during its lifetime
When a transition enters a compound state, the action of the
nested state machine starts over again at its initial state
• Unless an alternative entry point is specified
There are times you'd like to model a process so that it
remembers the last substate that was active prior to leaving
the compound state
HISTORY STATES
Simple washing machine state diagram:
• Power Cut event: transition to the “Power Off” state
• Restore Power event: transition to the active state before the
power was cut off to proceed in the cycle
CONCURRENT REGIONS
Sequential sub state machines are the most common kind of
sub machines
• In certain modeling situations, concurrent sub machines might
be needed (two or more sub state machines executing in
parallel)
Brakes example:
CONCURRENT REGIONS
Example of modeling system maintenance using concurrent
regions
Maintenance
Testing
testingCompleted
shutDown
Testing
devices
maintain
Idle
Commanding
Self
diagnosing
commandProcessed
[continue]
Waiting
command
Processing
Command
ORTHOGONAL REGIONS
Concurrent Regions are also called Orthogonal Regions
These regions allow us to model a relationship of “And”
between states (as opposed to the default “or” relationship)
• This means that in a sub state machine, the system can be in
several states simultaneously
Let us analyse this phenomenon using an example of
computer keyboard state machine
KEYBOARD EXAMPLE (1)
Keyboard example without Orthogonal Regions
KEYBOARD EXAMPLE (2)
Keyboard example with Orthogonal Regions
GARAGE DOOR – CASE
STUDY
Background
• Company DOORS inc. manufactures garage door
components
• Nonetheless, they have been struggling with the embedded
software running on their automated garage opener Motor
Unit that they developed in house
• This is causing them to loose business
• They decided to scrap the existing software and hire a
professional software company to deliver “bug free” software
CLIENT REQUIREMENTS
Client (informal) requirements:
• Requirement 1: When the garage door is closed, it must
open whenever the user presses on the button of the wall
mounted door control or the remote control
• Requirement 2: When the garage door is open, it must close
whenever the user presses on the button of the wall mounted
door control or the remote control
• Requirement 3: The garage door should not close on an
obstacle
• Requirement 4: There should be a way to leave the garage
door half open
• Requirement 5: System should run a self diagnosis test
before performing any command (open or close) to make sure
all components are functional
CLIENT REQUIREMENTS
Motor Unit
(includes a microcontroller
where the software will be
running)
Wall Mounted
Controller
(a remote controller
is also supported)
Sensor Unit(s)
(detects obstacles, when the door is
fully open and when it is fully closed)
USE CASE DIAGRAM
Use Case Diagram
Garage Door System
Open Door
Run
Diagnosis
Garage Door User
Close Door
RUN DIAGNOSIS USE CASE
Use Case Name: Run Diagnosis
Summary: The system runs a self diagnosis procedure
Actor: Garage door user
Pre-Condition: User has pressed the remote or wall mounted control button
Sequence:
1.
Check if the sensor is operating correctly
2.
Check if the motor unit is operating correctly
3.
If all checks are successful, system authorizes the command to be executed
Alternative Sequence:
Step 3: One of the checks fails and therefore the system does not authorize the
execution of the command
Postcondition: Self diagnosis ensured that the system is operational
OPEN DOOR USE CASE
Use Case Name: Open Door
Summary: Open the garage the door
Actor: Garage door user
Dependency: Include Run Diagnosis use case
Pre-Condition: Garage door system is operational and ready to take a command
Sequence:
1.
User presses the remote or wall mounted control button
2.
Include Run Diagnosis use case
3.
If the door is currently closing or is already closed, system opens the door
Alternative Sequence:
Step 3: If the door is open, system closes door
Step 3: If the door is currently opening, system stops the door (leaving it half open)
Postcondition: Garage door is open
CLOSE DOOR USE CASE
Use Case Name: Close Door
Summary: Close the garage the door
Actor: Garage door user
Dependency: Include Run Diagnosis use case
Pre-Condition: Garage door system is operational and ready to take a command
Sequence:
1.
User presses the remote or wall mounted control button
2.
Include Run Diagnosis use case
3.
If the door is currently open, system closes the door
Alternative Sequence:
Step 3: If the door is currently closing or is already closed, system opens the door
Step 3: If the door is currently opening, system stops the door (leaving it half open)
Postcondition: Garage door is closed
HIGH LEVEL BEHAVIORAL
MODELING
HIGH LEVEL STRUCTURAL
MODEL
«interface»
EventHandler
EventGenerator
*
Controller
*
Sensor
«interface»
ControllerEventHandler
«interface»
SensorEventHandler
WallMountedController
RemoteController
Motor
REFINED STRUCTURAL
MODEL
EventGenerator
-id : long
-eventHandlers: List
+EventGenerator(in id : long)
+getId() : long
+addEventHandler(in handler : EventHandler) : bool
#sendEvent(in eventId : int) : void
+run() : void
«interface»
EventHandler
*
*
«interface»
SensorEventHandler
+obstacleDetected() : void
+doorClosed() : void
+doorOpen() : void
Controller
Sensor
+Controller(in id : long)
+pressButton() : bool
+run() : void
#sendEvent(in eventId : int) : void
+Sensor(in id : long)
+run() : void
+isFunctioning() : bool
#sendEvent(in eventId : int) : void
WallMountedController
+isFunctioning() : bool
RemoteController
«interface»
ControllerEventHandler
+buttonPressed() : void
Motor
-eventGenerators: List
+buttonPressed() : void
+obstacleDetected() : void
+doorClosed() : void
+doorOpen() : void
+Motor()
-closeDoor() : bool
-openDoor() : bool
+getDoorState() : DoorState
+isFunctioning() : bool
+run() : void
1
1
«enumeration»
DoorState
+Open
+Opening
+Closed
+Closing
REFINE BEHAVIORAL
MODEL – MOTOR UNIT
Running
Open
buttonPressed()
[isFunctioning()]
Timer (180 s)
[! isFunctioning()]
doorOpen()
Closing
buttonPressed(),
[! isFunctioning()]
buttonPressed(),
obstacleDetected()
[isFunctioning()]
doorClosed()
Closed
Timer (180 s)
[isFunctioning()]
buttonPressed()
[isFunctioning()]
Opening
buttonPressed()
buttonPressed()
HalfOpen
WaitingForRepair
REFINE BEHAVIORAL
MODEL – SENSOR UNIT
CheckingForObstacles
[isObstacleDetected()]
SendingObstacleEvent
[!isObstacleDetected()]
CheckingIfDoorOpen
[isDoorOpen()]
SendingOpenDoorEvent
[!isDoorOpen()]
CheckingIfDoorClosed
[isDoorClosed()]
SendingDoorClosedEvent
[!isDoorClosed()]
Sleeping
Time (20 ms)
DO NOT FALL ASLEEP YET!
CODING
Whenever we are satisfied with the level of detail in our
behavioral models, we can proceed to coding
Some of the code can be generated directly by tools from the
behavioral model
• Some tweaking might be necessary (do not use the code
blindly)
• Humans are still the smartest programmers
EVENT GENERATOR CLASS
SENSOR CLASS
SENSOR CLASS
Sensor
State machine
Implementation
UMPLE ONLINE DEMO
UMPLE is a modeling tool to enable what we call ModelOriented Programming
• This is what we do in this course
You can use it to create class diagrams (structural models)
and state machines (behavioral models)
The tool was developed at the university of Ottawa
• Online version can be found at:
http://cruise.eecs.uottawa.ca/umpleonline/
• There’s also an eclipse plugin for the tool
UMPLE CODE FOR MOTOR
UNIT STATE MACHINE
class Motor {
status {
Running {
Open {buttonPressed[isFunctioning()]->Closing; }
Closing { buttonPressed()[isFunctioning()]->Opening;
ObstacleDetected()[isFunctioning()]->Opening;
doorClosed()->Closed;}
Closed { buttonPressed()[isFunctioning()]->Opening; }
Opening { buttonPressed()->HalfOpen;
doorOpen()->Open; }
HalfOpen{buttonPressed()->Opening;}
buttonPressed()[!isFunctioning()]->WaitingForRepair;
}
WaitingForRepair{
timer()[!isFunctioning()]->WaitingForRepair;
timer()[isFunctioning()]->Running;}
}
}
MOTOR CLASS SNIPPETS
Switching between
high level states
Switching between
nest states inside
the Running
compound state
WHEN TO USE STATE
MACHINES?
When an object or a system progresses through various
stages of execution (states)
• The behavior of the system differs from one stage to another
When you can identify clear events that change the status of
the system
They are ideal for event driven programming (less loops and
branches, more events generated and exchanged)
• Lots of event are being exchanged between objects
When using even driven programming
• Make sure you follow Observable or Event Notifier patterns
• Both are pretty simple (similar to what we have done for the
garage door example)
BEHAVIORAL OVERMODELING
Please model responsibly!!
Do not get carried out with modeling every single detail to
the point where you run behind schedule
• You sell code, not models…
BEHAVIORAL OVERMODELING
Now, be careful, you do not want over-model
• Modern software development processes are all about only
doing just enough modeling for a successful product
Therefore, start with a high level model of the behavior
• This model should give a clear overview of some (not
necessary all) of the important functionality of the system
• This would be similar to the first garage door state machine
we created
BEHAVIORAL OVERMODELING
Identify potential complex areas that require further
understanding
• We minimize the risk if we understand these components well
before we start programing
• Model these complex areas in more details until you are
satisfied that they are well understood
Use tools to generate code from your existing models
• Do not rely blindly on tools (at least not yet!)
DESIGNING CLASSES WITH
STATE DIAGRAMS
Keep the state diagram simple
• State diagrams can very quickly become extremely complex
and confusing
• At all time, you should follow the aesthetic rule: “Less is More”
If the state diagram gets too complex consider splitting it into
smaller classes
Think about compound states instead of a flat design
EXAMPLE OF A CD PLAYER
WITH A RADIO
On
Display Alarm
Displaying
Current Time
Displaying
Alarm Time
Timer (3 s)
Play CD
Playing
Radio
Playing CD
Play Radio
H
On
Off
On
off
MORE UML STATE
MACHINES EXAMPLES
Flight State Machine
MORE UML STATE
MACHINES EXAMPLES
Flight State Machine
Nested
SECTION 5
PETRI NETS
THESE SLIDES ARE BASED ON LECTURE NOTES
FROM:
DR. CHRIS LING ( H TTP: / / W W W.CSSE. M O NASH .EDU.AU /~SLI N G/ )
SEG2106 – Winter 2014 – Hussein Al Osman
151
TOPICS
Today we will discuss another type of state machine:
• Petri nets (this will be just an introduction…)
This will be the last behavioral modeling topic we cover
• We will start the next section of the course next week
SEG2106 – Winter 2014 – Hussein Al Osman
152
OK, LET’S START…
SEG2106 – Winter 2014 – Hussein Al Osman
153
INTRODUCTION
First introduced by Carl Adam Petri in 1962.
A diagrammatic tool to model concurrency and
synchronization in systems
• They allow us to quickly simulate complex concurrent
behavior (which is faster than prototyping!)
Fairly similar to UML State machines that we have seen so far
• Used as a visual communication aid to model the system
behavior
Based on strong mathematical foundation
SEG2106 – Winter 2014 – Hussein Al Osman
154
EXAMPLE: POS TERMINAL
(UML STATE MACHINE)
(POS= Point of Sale)
idle
1 digit
1 digit
d1
d2
1 digit
d3
1 digit
d4
OK
OK
OK
OK
OK
pressed
Rejected
Reject
Approved
SEG2106 – Winter 2014 – Hussein Al Osman
155
EXAMPLE: POS
TERMINAL (PETRI NET)
1 digit
Initial
1 digit
d1
1 digit
d2
1 digit
d4
d3
OK
OK
OK
OK
OK
pressed
Rejected!
Reject
approve
approved
SEG2106 – Winter 2014 – Hussein Al Osman
156
POS TERMINAL
Scenario 1: Normal
• Enters all 4 digits and press OK.
Scenario 2: Exceptional
• Enters only 3 digits and press OK.
SEG2106 – Winter 2014 – Hussein Al Osman
157
EXAMPLE: POS SYSTEM
(TOKEN GAMES)
1 digit
Initial
1 digit
d1
1 digit
d2
1 digit
d4
d3
OK
OK
OK
OK
OK
pressed
Rejected!
Reject
approve
approved
SEG2106 – Winter 2014 – Hussein Al Osman
158
A PETRI NET
COMPONENTS
The terms are bit different than UML state machines
Petri nets consist of three types of components: places
(circles), transitions (rectangles) and arcs (arrows):
• Places represent possible states of the system
• Transitions are events or actions which cause the change of
state (be careful, transitions are no longer arrows here)
• Every arc simply connects a place with a transition or a
transition with a place.
SEG2106 – Winter 2014 – Hussein Al Osman
159
CHANGE OF STATE
A change of state is denoted by a movement of token(s)
(black dots) from place(s) to place(s)
• Is caused by the firing of a transition.
The firing represents an occurrence of the event or an action
taken
The firing is subject to the input conditions, denoted by
token availability
SEG2106 – Winter 2014 – Hussein Al Osman
160
CHANGE OF STATE
A transition is firable or enabled when there are sufficient
tokens in its input places.
After firing, tokens will be transferred from the input places
(old state) to the output places, denoting the new state
SEG2106 – Winter 2014 – Hussein Al Osman
161
EXAMPLE: VENDING
MACHINE
The machine dispenses two kinds of snack bars – 20c and
15c
Only two types of coins can be used
• 10c coins and 5c coins (ah the old days!!)
The machine does not return any change
SEG2106 – Winter 2014 – Hussein Al Osman
162
EXAMPLE: VENDING MACHINE
(UML STATE MACHINE)
Take 15c snack bar
5 cents
inserted
Deposit 10c
15 cents
inserted
0 cent
inserted
10 cents
inserted
Deposit 10c
20 cents
inserted
Take 20c snack bar
SEG2106 – Winter 2014 – Hussein Al Osman
163
EXAMPLE: VENDING
MACHINE (A PETRI NET)
Take 15c bar
Deposit 10c
5c
15c
Deposit 5c
0c
Deposit
5c
Deposit
5c
Deposit 10c
10c
Deposit
5c
20c
Deposit 10c
Take 20c bar
SEG2106 – Winter 2014 – Hussein Al Osman
164
EXAMPLE: VENDING MACHINE (3
SCENARIOS)
Scenario 1:
• Deposit 5c, deposit 5c, deposit 5c, deposit 5c, take 20c snack
bar.
Scenario 2:
• Deposit 10c, deposit 5c, take 15c snack bar.
Scenario 3:
• Deposit 5c, deposit 10c, deposit 5c, take 20c snack bar.
SEG2106 – Winter 2014 – Hussein Al Osman
165
EXAMPLE: VENDING
MACHINE (TOKEN GAMES)
Take 15c bar
Deposit 10c
5c
15c
Deposit 5c
0c
Deposit
5c
Deposit
5c
Deposit 10c
10c
Deposit
5c
20c
Deposit 10c
Take 20c bar
SEG2106 – Winter 2014 – Hussein Al Osman
166
MULTIPLE LOCAL STATES
In the real world, events happen at the same time
A system may have many local states to form a
global state.
There is a need to model concurrency and
synchronization
SEG2106 – Winter 2014 – Hussein Al Osman
167
EXAMPLE: IN A RESTAURANT
(A PETRI NET)
Waiter
free
Customer 1
Customer 2
Take
order
Take
order
wait
Order
taken
wait
eating
eating
Serve food
SEG2106 – Winter 2014 – Hussein Al Osman
Tell
kitchen
Serve food
168
EXAMPLE: IN A RESTAURANT
(TWO SCENARIOS)
Scenario 1:
Waiter
1. Takes order from customer 1
2. Serves customer 1
3. Takes order from customer 2
4. Serves customer 2
Scenario 2:
Waiter
1. Takes order from customer 1
2. Takes order from customer 2
3. Serves customer 2
4. Serves customer 1
SEG2106 – Winter 2014 – Hussein Al Osman
169
EXAMPLE: IN A
RESTAURANT (SCENARIO 2)
Waiter
free
Customer 1
Customer 2
Take
order
Take
order
wait
Order
taken
wait
eating
eating
Serve food
SEG2106 – Winter 2014 – Hussein Al Osman
Tell
kitchen
Serve food
170
EXAMPLE: IN A
RESTAURANT (SCENARIO 1)
Waiter
free
Customer 1
Customer 2
Take
order
Take
order
wait
Order
taken
wait
eating
eating
Serve food
SEG2106 – Winter 2014 – Hussein Al Osman
Tell
kitchen
Serve food
171
NET STRUCTURES
A sequence of events/actions:
e1
e2
e3
e2
e3
e4
e5
Concurrent executions:
e1
SEG2106 – Winter 2014 – Hussein Al Osman
172
NET STRUCTURES
Non-deterministic events - conflict, choice
or decision: A choice of either e1, e2 … or
e3, e4 ...
e1
e2
e3
e4
SEG2106 – Winter 2014 – Hussein Al Osman
173
NET STRUCTURES
Synchronization
e1
SEG2106 – Winter 2014 – Hussein Al Osman
174
NET STRUCTURES
Synchronization and Concurrency
e1
SEG2106 – Winter 2014 – Hussein Al Osman
175
ANOTHER EXAMPLE
A producer-consumer system, consist of:
• One producer
• Two consumers
• One storage buffer
With the following conditions:
• The storage buffer may contain at most 5 items;
• The producer sends 3 items in each production;
• At most one consumer is able to access the storage buffer at
one time;
• Each consumer removes two items when accessing the
storage buffer
SEG2106 – Winter 2014 – Hussein Al Osman
176
A PRODUCERCONSUMER SYSTEM
k=2
k=1
accepted
ready
p1
produce
t2
t1
p4
Storage p3
3
2
accept
t3
t4
consume
send
p2
k=5
p5
idle
ready
k=1
Producer
SEG2106 – Winter 2014 – Hussein Al Osman
k=2
Consumers
177
A PRODUCER-CONSUMER
EXAMPLE
In this Petri net, every place has a capacity
and every arc has a weight.
This allows multiple tokens to reside in a
place to model more complex behavior.
SEG2106 – Winter 2014 – Hussein Al Osman
178
SHORT BREAK?
Are you here yet?
SEG2106 – Winter 2014 – Hussein Al Osman
179
BEHAVIORAL PROPERTIES
Reachability
• “Can we reach one particular state from another?”
Boundedness
• “Will a storage place overflow?”
Liveness
• “Will the system die in a particular state?”
SEG2106 – Winter 2014 – Hussein Al Osman
180
RECALLING THE VENDING
MACHINE (TOKEN GAME)
Take 15c bar
Deposit 10c
5c
15c
Deposit 5c
0c
Deposit
5c
Deposit
5c
Deposit 10c
10c
Deposit
5c
20c
Deposit 10c
Take 20c bar
SEG2106 – Winter 2014 – Hussein Al Osman
181
A MARKING IS A STATE ...
t8
p4
t4
p2
t1
p1
t3
t5
t
7
M0 = (1,0,0,0,0)
M1 = (0,1,0,0,0)
M2 = (0,0,1,0,0)
M3 = (0,0,0,1,0)
M4 = (0,0,0,0,1)
Initial marking:M0
t6
t2
p5
p3
t9
SEG2106 – Winter 2014 – Hussein Al Osman
182
REACHABILITY
t8
p4
t4
M0 = (1,0,0,0,0)
p2
M1 = (0,1,0,0,0)
t1
M2 = (0,0,1,0,0)
p1
t3
t
7
t5
p3
t6
t2
p5
M3 = (0,0,0,1,0)
M4 = (0,0,0,0,1)
Initial marking:M0
t9
M0
t1
M1
t3
SEG2106 – Winter 2014 – Hussein Al Osman
M2
t5
M3
t8
M0
t2
M2
t6
M4
183
REACHABILITY
A firing or occurrence sequence:
M0
t1
M1
t3
M2
t5
M3
t8
M0
t2
M2
t6
M4
“M2 is reachable from M1 and M4 is reachable from M0.”
In fact, in the vending machine example, all markings are
reachable from every marking.
SEG2106 – Winter 2014 – Hussein Al Osman
184
BOUNDEDNESS
A Petri net is said to be k-bounded or simply bounded if the
number of tokens in each place does not exceed a finite
number k for any marking reachable from M0.
The Petri net for vending machine is 1-bounded.
SEG2106 – Winter 2014 – Hussein Al Osman
185
LIVENESS
A Petri net with initial marking M0 is live if, no matter what
marking has been reached from M0, it is possible to
ultimately fire any transition by progressing through some
further firing sequence.
A live Petri net guarantees deadlock-free operation, no matter
what firing sequence is chosen.
SEG2106 – Winter 2014 – Hussein Al Osman
186
LIVENESS
The vending machine is live and the producer-consumer
system is also live.
A transition is dead if it can never be fired in any firing
sequence.
SEG2106 – Winter 2014 – Hussein Al Osman
187
AN EXAMPLE
t1
p3
p2
p1
t2
t3
t4
p4
M0 = (1,0,0,1)
M1 = (0,1,0,1)
M2 = (0,0,1,0)
M3 = (0,0,0,1)
A bounded but non-live Petri net
SEG2106 – Winter 2014 – Hussein Al Osman
188
ANOTHER EXAMPLE
M0 = (1, 0, 0, 0, 0)
p1
M1 = (0, 1, 1, 0, 0)
M2 = (0, 0, 0, 1, 1)
t1
M3 = (1, 1, 0, 0, 0)
p2
p3
t2
t3
p4
p5
t4
SEG2106 – Winter 2014 – Hussein Al Osman
M4 = (0, 2, 1, 0, 0)
An unbounded but live Petri net
189
OTHER TYPES OF PETRI
NETS
Object-Oriented Petri nets
• Tokens can either be instances of classes, or states of
objects.
• Net structure models the inner behaviour of objects.
SEG2106 – Winter 2014 – Hussein Al Osman
190
AN O-O PETRI NET
Producer
Consumer
accepted
ready
produce
send
Storage
accept
consume
ready
Producer
state: ProducerState
Consumer
state: ConsumerState
Item produce( )
accept( i: Item): void
send(i: Item): void
consume(i: Item) : void
SEG2106 – Winter 2014 – Hussein Al Osman
191
PETRI NET REFERENCES
• Murata, T. (1989, April). Petri nets: properties, analysis and
applications. Proceedings of the IEEE, 77(4), 541-80.
• Peterson, J.L. (1981). Petri Net Theory and the Modeling of
Systems. Prentice-Hall.
• Reisig, W and G. Rozenberg (eds) (1998). Lectures on Petri
Nets 1: Basic Models. Springer-Verlag.
• The World of Petri nets:
http://www.daimi.au.dk/PetriNets/
SEG2106 – Winter 2014 – Hussein Al Osman
192
SECTION 6
INTRODUCTION TO COMPILERS
TOPICS
Natural languages
• Lexemes or lexical entities
• Syntax and semantics
Computer languages
• Lexical analysis
• Syntax analysis
• Semantic analysis
Compilers
• Compiler’s basic requirements
• Compilation process
NATURAL LANGUAGES
BASICS
In a (natural) language:
• A sentence is a sequence of words
• A word (also called lexemes of lexical units) is a sequence of
characters (possibly a single one)
The set of characters used in a language is finite (know as
the alphabet)
The set of possible sentences in a language is infinite
A dictionary lists all the words (lexemes) of a language
• The words are classified into different lexical categories: verb,
noun, pronoun, preposition….
NATURAL LANGUAGES
BASICS
A grammar (also considered the set of syntax rules) to
determine which sequences of words are well formed
• Sequences must have a structure that obeys the grammatical
rules
Well formed sentences, usually have a meaning that humans
understand
• We are trying to teach our natural languages to machines
With mixed
results!!
ANALYSIS OF SENTENCES
Lexical Analysis: identification of words made up of
characters
• Words are classified into several categories: articles, nouns,
verbs, adjectives, prepositions, pronouns…
Syntax analysis: rules for combining words to form sentences
Analysis of meaning: difficult to formalize
• Easily done by humans
• Gives machines a hard time (although natural language
processing is evolving)
• Big research field for those interested in graduate studies…
COMPUTER LANGUAGE
PROCESSING
In computer (or programming) languages, one speaks about
a program (corresponding to a long sentence or paragraph)
• Sequence of lexical units or lexemes
• Lexical units are sequences of characters
Lexical rules of the language determine what the valid lexical
units of the language are
• There are various lexical categories: identifier, number,
character string, operator…
• Lexical categories are also known as tokens
COMPUTER LANGUAGE
PROCESSING
Syntax rules of the language determine what sequences of
lexemes are well-formed programs
Meaning of a well-formed program is also called its
semantics
• A program can be well-formed, but its statements are
nonsensical
• Example:
int x = 0;
x = 1;
x = 0;
• Syntactically, the above code is valid, but what does it
mean??
COMPUTER LANGUAGE
PROCESSING
Compilers should catch and complain about lexical and
syntax errors
Compilers might complain about common semantic errors:
public boolean test (int x){
boolean result;
if (x > 100)
result = true;
return result;
}
Error message:
The local variable result may
have not been initialized
Your coworkers or the client will complain about the rest!!
COMPILERS
What is a compiler?
• Program that translates an executable program in one
language into an executable program in another language
• We expect the program produced by the compiler to be better,
in some way, than the original
What is an interpreter?
• Program that reads an executable program and produces the
results of running that program
We will focus on compilers in this course (although many of
the concepts apply to both)
BASIC REQUIREMENTS
FOR COMPILERS
Must-Dos:
• Produce correct code (byte code in the case of Java)
• Run fast
• Output must run fast
• Achieve a compile time proportional to the size of the program
• Work well with debuggers (absolute must)
Must-Haves:
• Good diagnostics for lexical and syntax errors
• Support for cross language calls (checkout Java Native
Interface if you are interested)
ABSTRACT VIEW OF
COMPILERS
A compiler usually realizes the translation in several steps;
correspondingly, it contains several components.
Usually, a compiler includes (at least) separate components
for verifying the lexical and syntax rules:
COMPILATION PROCESS
Source Program
Lexical Analyser
Syntax Analyser
Semantic Analyser
Intermediate Code Generator
Code Optimizer
Code Generator
Machine Code
COMPILATION PROCESS
More than one course is required to cover the details of the
various phases
In this course, we will scratch the surface
• We will focus on lexical and syntax analysis
SOME IMPORTANT
DEFINITIONS
These definitions, although sleep inducing, are important in
order to understand the concepts that will be introduced in
the next lectures
So here we go…
ALPHABET
Recall from beginning of the lecture (or kindergarten): an
alphabet is the set of characters that can be used to form a
sentence
…
Since mathematicians love fancy Greek symbols, we will
refer to an alphabet as
ALPHABET
is an alphabet, or set of terminals
• Finite set and consists of all the input characters or
symbols that can be arranged to form sentences in
the language
English: A to Z, punctuation and space symbols
Programming language: usually some well-defined
computer set such as ASCII
STRINGS OF TERMINALS
IN AN ALPHABET
={a,b,c,d}
Possible strings of terminals from include
•
•
•
•
•
•
•
aaa
aabbccdd
d
cba
abab
ccccccccccacccc
Although this is fun, I think you get the idea…
FORMAL LANGUAGES
: alphabet, it is a finite set consisting of all input
characters or symbols
*: closure of the alphabet, the set of all possible
strings in , including the empty string
A (formal) language is some specified subset of *
SECTION 7
LEXICAL ANALYSIS
TOPICS
The role of the lexical analyzer
Specification of tokens
Finite state machines
From a regular expressions to an NFA
THE ROLE OF LEXICAL
ANALYZER
Lexical analyzer is the first phase of a
compiler
• Task: read input characters and produce a
sequence of tokens that the parser uses for
syntax analysis
• Remove white spaces
Source
Program
Lexical
Analyser
(scanner)
token
Get next token
Syntax
Analyser
(parser)
LEXICAL ANALYSIS
There are several reasons for separating
the analysis phase of compiling into lexical
analysis and syntax analysis (parsing):
• Simpler (layered) design
• Compiler efficiency
Specialized tools have been designed to
help automate the construction of both
separately
LEXEMES
Lexeme: sequence of characters in the source program that
is matched by the pattern for a token
• A lexeme is a basic lexical unit of a language
• Lexemes of a programming language include its
• Identifiers: names of variables, methods, classes, packages
and interfaces…
• Literals: fixed values (e.g. “1”, “17.56”, “0xFFE” …)
• Operators: for Maths, Boolean and logical operations (e.g.
“+”, “-”, “&&”, “|” …)
• Special words: keywords (e.g. “if”, “for”, “public” …)
TOKENS, PATTERNS,
LEXEMES
Token: category of lexemes
A pattern is a rule describing the set of
lexemes that can represent as particular
token in source program
EXAMPLES OF TOKENS
double pi = 3.1416;
The substring pi is a lexeme for the token “identifier.”
Token
Sample
Lexemes
Informal Description of Pattern
type
double
double
if
if
if
booelan_operator
<. <=, ==, >, >=
< or <= or == or > or >=
id
pi, count, d2
Letter followed by letters and digits
literal
3.1414, “test”
Any alpha numeric string of
characters
LEXEME AND TOKEN (MORE
DETAILED CATEGORIES)
Index = 2 * count +17;
Lexemes
Tokens
Index
variable
=
equal_sign
2
int_literal
*
multi_op
Count
variable
+
plus_op
17
int_literal
;
semicolon
LEXICAL ERRORS
Few errors are discernible at the lexical level alone
• Lexical analyzer has a very localized view of a source
program
Let some other phase of compiler handle any error
SPECIFICATION OF
TOKENS
We need a powerful notation to specify the patterns for the
tokens
• Regular expressions to the rescue!!
In process of studying regular expressions, we will discuss:
• Operation on languages
• Regular definitions
• Notational shorthands
RECALL: LANGUAGES
: alphabet, it is a finite set consisting of all input
characters or symbols
*: closure of the alphabet, the set of all possible
strings in , including the empty string
A (formal) language is some specified subset of *
OPERATIONS ON
LANGUAGES
OPERATIONS ON
LANGUAGES
Non-mathematical format:
• Union between languages L and M: the set of strings
that belong to at least one of both languages
• Concatenation of languages L and M: the set of all
strings of the form st where s is a string from L and t is a
string from M
• Intersection between languages L and M: the set of
all strings which are contained in both languages
• Kleene closure (named after Stephen Kleene): the set
of all strings that are concatenations of 0 or more strings
from the original language
• Positive closure : the set of all strings that are
concatenations of 1 or more strings from the original
language
REGULAR EXPRESSIONS
Regular expression is a compact notation for describing
string.
In Java, an identifier is a letter followed by zero or more letter
or digits letter (letter | digit)*
|: or
*: zero or more instance of
RULES
is a regular expression that denotes {}, the set containing
empty string
If a is a symbol in , then a is a regular expression that
denotes {a}, the set containing the string a
Suppose r and s are regular expressions denoting the
language L and M, then
• (r) |(s) is a regular expression denoting LM.
• (r)(s) is regular expression denoting LM
• (r) * is a regular expression denoting (L)*.
PRECEDENCE
CONVENTIONS
The unary operator * has the highest precedence and is left
associative.
Concatenation has the second highest precedence and is left
associative.
| has the lowest precedence and is left associative.
(a)|(b)*(c)a|b*c
EXAMPLE OF REGULAR
EXPRESSIONS
PROPERTIES OF REGULAR
EXPRESSION
REGULAR DEFINITIONS
If is an alphabet of basic symbols, then a regular
definition is a sequence of definitions of the form:
d1 r 1
d2 r 2
...
dn r n
Where each di is a distinct name, and each ri is a
regular expression over the symbols in
{d1,d2,…,di-1},
• i.e., the basic symbols and the previously defined
names.
EXAMPLE OF REGULAR
DEFINITIONS
NOTATIONAL
SHORTHANDS
Certain constructs occur so frequently in regular expressions that it
is convenient to introduce notational short hands for them
We have already seen some of these short hands:
1.
2.
3.
4.
One or more instances: a+ denotes the set of all strings of one
or more a’s
Zero or more instances: a* denotes all the strings of zero or
more a’s
Character classes: the notation [abc] where a, b and c denotes
the regular expresssion a | b | c
Abbreviated character classes: the notation [a-z] denotes the
regular expression a | b | …. | z
NOTATIONAL
SHORTHANDS
Using character classes, we can describe identifiers as being
strings described by the following regular expression:
[A-Za-z][A-Za-z0-9]*
FINITE STATE AUTOMATA
Now that we have learned about regular expressions
• How can we tell if a string (or lexeme) follows a regular
expression pattern or not?
We will again use state machines!
• This time, they are not UML state machines or petri nets
• We will call them: Finite Automata
The program that executes such state machines is called a
Recognizer
SHORT BREAK…
FINITE AUTOMATA
A recognizer for a language is a program that takes as input a
string x and answers
• “Yes” if x is a lexem of the language
• “No” otherwise
We compile a regular expression into a recognizer by
constructing a generalized transition diagram called a finite
automaton
A finite automaton can be deterministic or nondeterministic
• Nondeterministic means that more than one transition out of a
state may be possible on the same input symbol
NONDETERMINISTIC
FINITE AUTOMATA (NFA)
A set of states S
A set of input symbols that belong to alphabet
A set of transitions that are triggered by the processing of a
character
A single state s0 that is distinguished as the start (initial)
state
A set of states F distinguished as accepting (final) states.
EXAMPLE OF AN NFA
The following regular expression
(a|b)*abb
Can be described using an NFA with the following diagram:
EXAMPLE OF AN NFA
The previous diagram can be described using the following
table as well
Remember the regular expression was:
(a|b)*abb
ANOTHER NFA EXAMPLE
NFA accepting the following regular expression:
aa*|bb*
DETERMINISTIC FINITE
AUTOMATA (DFA)
A DFA is a special case of a NFA in which
• No state has an -transition
• For each state s and input symbol a, there is at most one
edge labeled a leaving s
ANOTHER DFA EXAMPLE
For the same regular expression we have seen before
(a|b)*abb
NFA VS DFA
Always with the regular expression: (a|b)*abb
NFA:
DFA:
EXAMPLE OF A DFA
Recognizer for identifier:
TABLES FOR THE
RECOGNIZER
To change regular expression, we can simply change
tables…
CODE FOR THE RECOGNIZER
SECTION 8
FINITE STATE AUTOMATA
TOPICS
Algorithm to create NFAs from regular expressions
Algorithm to convert from NFA to DFA
Algorithm to minimize DFA
Many examples….
CREATING DETERMINISTIC
FINITE AUTOMATA (DFA)
In order to create a DFA, we have to perform the following:
• Create a Non-deterministic Finite Automata (NFA) out of
the regular expression
• Convert the NFA into a DFA
NFA CREATION RULES
2
A
3
ε
A|B
1
6
ε
ε
4
AB
ε
1
A
5
B
B
2
3
ε
A*
1
ε
2
A
ε
3
ε
4
NFA CREATION EXAMPLES
x | yz
According to precedence rules, this is
equivalent to:
2
x | (yz)
A
3
ε
ε
This has the same form as A | B:
1
6
ε
ε
4
B
5
And B can be represented as:
y
1
2
z
2
3
ε
Putting all together:
3
x
ε
1
7
ε
ε
4
y
5
z
6
NFA CREATION EXAMPLES
ε
(x | y)*
We have seen A*:
ε
ε
A
ε
ε
Therefore, (x | y)*:
ε
1
ε
3
x
4
ε
2
7
ε
ε
5
6
y
ε
ε
8
NFA CREATION EXAMPLES
abb
NFA CREATION EXAMPLES
a*bb
ε
1
ε
2
a
ε
3
ε
4
b
5
b
6
NFA CREATION EXAMPLES
(a|b)*bc
ε
a
ε
0
ε
2
3
ε
1
6
ε
ε
4
5
b
ε
ε
7
b
8
c
9
CONVERSION OF AN NFA
INTO DFA
Subset construction algorithm is useful for
simulating an NFA by a computer program
In the transition table of an NFA, each entry is a set
of states
In the transition table of a DFA, each entry is just a
single state.
General idea behind the NFA-to-DFA conversion:
each DFA state corresponds to a set of NFA states
SUBSET CONSTRUCTION
ALGORITHM
Algorithm: Subset Construction - Used to
construct a DFA from an NFA
Input: An NFA “N”
Output: A DFA “D” accepting the same language
SUBSET CONSTRUCTION
ALGORITHM
Method:
• Let s be a state in “N” and “T” be a set of states,
and using the following operations:
SUBSET CONSTRUCTION
(MAIN ALGORITHM)
SUBSET CONSTRUCTION
(Ε-CLOSURE COMPUTATION)
CONVERSION EXAMPLE
ε
Regular Expression:
(x | y)*
ε
1
ε
3
x
4
ε
2
7
ε
ε
ε
5
6
y
ε
Dstates={A,B,C}, where
• A = (1,2,3,5,8)
• B = (2,3,4,5,7,8)
• C = (2,3,5,6,7,8)
x
y
A
B
C
B
B
C
C
B
C
8
CONVERSION EXAMPLE
Regular Expression:
(x | y)*
x
x
B
y
A
y
x
C
y
x
y
A
B
C
B
B
C
C
B
C
ANOTHER CONVERSION
EXAMPLE
Regular Expression:
(a | b)*abb
ANOTHER CONVERSION
EXAMPLE
Regular Expression:
(a | b)*abb
ANOTHER CONVERSION
EXAMPLE
Regular Expression:
(a | b)*abb
MINIMIZING THE NUMBER
OF STATES IN DFA
Minimize the number of states of a DFA by finding all groups
of states that can be distinguished by some input string
Each group of states that cannot be distinguished is then
merged into a single state
MINIMIZING THE NUMBER
OF STATES IN DFA
Algorithm: Minimizing the number of states of a DFA
Input: A DFA “D” with a set of states S
Output: A DFA “M” accepting the same language as “D” yet
having as few states as possible
MINIMIZING THE NUMBER
OF STATES IN DFA
Method:
1. Construct an initial partition Π of the set of states with two
groups:
•
•
The accepting states group
All other states group
2. Partition Π to Πnew (using the procedure shown on the next
slide)
3. If Πnew != Π, repeat step (2). Otherwise, repeat go to step
(4)
4. Choose one state in each group of the partition Π as the
representative of the group
5. Remove dead states
CONSTRUCT NEW
PARTITION PROCEDURE
for each group G of Π do begin
Partition G into subgroups such that two states s
and t of G are in the same subgroup if and only if for
all input symbols a, states s and t have transitions on
a to states in the same group of Π;
/* at worst, a state will be in a subgroup by itself*/
Replace G in Πnew by the set of all subgroups formed
end
EXAMPLE OF NFA
MINIMIZATION
A
c
B
a
a
C
b
D
a
b
b
a
E
b
F
A
A
B, C, D, E
B, C, D, E
F
F
A, B, C, D, E
Π=
F
EXAMPLE OF NFA
MINIMIZATION
Minimized DFA, where:
• 1: A
• 2: B, C, D, E
• 3: F
1
c
a
2
b
3
SECTION 9
PRACTICAL REGULAR EXPRESSIONS
TOPICS
Practical notations that are often used with regular
expression
Few practice exercises
PRACTICAL REGULAR
EXPRESSIONS TRICKS
We will see practical regular expressions tricks that are
supported by most regex libraries
Remember, regular expressions are not only used in the
context of compilers
• We often use them to extract information from text
Example: imagine looking in a log file that has been
accumulating entries for the past two months for a particular
error pattern
• Without regular expressions, this would be a tedious job
• Sooner or later, when you work in the industry, you will
encounter such issues regular expressions will come in
handy
MATCHING DIGITS
To match a single digit, as we have seen before, we can use
the following regular expression:
[0-9]
Nonetheless, since matching a digit is a common operation,
we can use the following notation:
\d
Slash is an escape character used to distinguish it from the
letter d
Similarly, to match a non-digit character, we can use the
notation:
\D
ALPHANUMERIC
CHARACTERS
To match an alphanumeric character, we can use the
notation:
[a-zA-Z0-9]
Or we can use the following shortcut
\w
Similarly, we can represent any non-alphanumeric character
as follows:
\W
WILDCARD
A wildcard is defined to match any single character (letter,
digit, whitespace …)
It is represented by the . (dot) character
Therefore, in order to match a dot, you have to use the
escape character: \.
EXCLUSION
We have seen that [abc] is equivalent to (a | b | c)
But sometimes we want to match everything except a set of
characters
To achieve this, we can use the notation: [^abc]
• This matches any single character other than a, b or c
This notation can also be used with abbreviated character
classes
• [^a-z] matches any character other than a small letter
REPETITIONS
How can we match a letter or a string that repeats several
times in a row:
• E.g. ababab
So far, we have implemented repetitions through three
mechanisms:
• Concatenation: simply concatenate the string or character
with itself (does not work if you do not know the exact number
of repetitions)
• Kleene star closure: to match letters or strings repeated 0 or
more times
• Positive closure: to match letters or strings repeated 1 or
more times
REPETITIONS
We can also specify a range of how many times a letter or
string can be repeated
Example, if we want to match strings of repetition of the letter
a between 1 and 3 times, we can use the notation: a {1,3}
• Therfore, a {1,3} matches the string aaa
We can also specify an exact number of repetitions instead
of a range
• ab {3} matches the string ababab
OPTIONAL CHARACTERS
The concept of the optional character is somewhat similar to
that of the kleene star
• The star operator matches 0 or more instances of the
operand
• The optional operator, denoted as ? (question mark),
matches 0 or one instances of the operand
Example: the pattern ab?c will match either the strings "abc"
or "ac" because the b is considered optional.
WHITE SPACE
Often, we want to easily detect white spaces
• Either to remove them or to detect the beginning or end of
words
Most common forms of whitespace used with regular
expressions:
• Space _, the tab \t, the new line \n and the carriage return \r
A whitespace special character \s will match any of the
specific whitespaces above
Similarly, you can match any non-white space character
using the notation \S
FEW EXERCISES
Given the sentence:
• Error, computer will not shut down…
Provide a regular expression that will match all the words in
the sentence
Answer:
\w*
FEW EXERCISES
Given the sentence:
• Error, computer will not shut down…
Provide a regular expression that will match all the nonalphanumeric characters
Answer:
\W*
FEW EXERCISES
Given the log file:
•
•
•
•
•
[Sunday Feb. 2 2014] Program starting up
[Monday Feb. 3 2014] Entered initialization phase
[Tuesday Feb. 4 2014] Error 5: cannot open XML file
[Thursday Feb. 6 2014] Warning 5: response time is too slow
[Friday Feb. 7 2014] Error 9: major error occurred, system will
shut down
Match any error or warning message that ends with the term
“shut down”
Answer:
(Error|Warning).*(shut down)
FEW EXERCISES
Given the log file:
•
•
•
•
•
[Sunday Feb. 2 2014] Program starting up
[Monday Feb. 3 2014] Entered initialization phase
[Tuesday Feb. 4 2014] Error 5: cannot open XML file
[Thursday Feb. 6 2014] Warning 5: response time is too slow
[Friday Feb. 7 2014] Error 9: major error occurred, system will
shut down
Match any Error or Warning before between 1 and 6th
February
Answer:
\[\w* Feb\. [1-6] 2014\] (Error|Warning)
SECTION 10
INTRODUCTION TO SYNTAX
ANALYSIS
286
TOPICS
Context free grammars
Derivations
Parse Trees
Ambiguity
Top-down parsing
Left recursion
287
THE ROLE OF PARSER
288
CONTEXT FREE
GRAMMARS
A Context Free Grammar (CFG) consists of
•
•
•
•
Terminals
Nonterminals
Start symbol
Productions
A language that can be generated by a grammar is said to be
a context-free language
289
CONTEXT FREE
GRAMMARS
Terminals: are the basic symbols from which strings are
formed
• These are the tokens that were produced by the Lexical
Analyser
Nonterminals: are syntactic variables that denote sets of
strings
• One nonterminal is distinguished as the start symbol
The productions of a grammar specify the manner in which
the terminal and nonterminals can be combined to form
strings
290
EXAMPLE OF GRAMMAR
The grammar with the following productions defines simple
arithmetic expressions
〈expr〉 ::= 〈expr〉 〈op〉 〈expr〉
〈expr〉 ::= id
〈expr〉 ::= num
〈op〉 ::= +
〈op〉 ::= 〈op〉 ::= *
〈op〉 ::= /
In this grammar, the terminal symbols are
num, id + - * /
The nonterminal symbols are 〈expr〉 and 〈op〉, and 〈expr〉 is
the start symbol
291
DERIVATIONS
〈expr〉 〈expr〉〈op 〉〈expr〉
is read “expr derives expr op expr”
〈expr〉
〈expr〉〈op 〉〈expr〉
id 〈op 〉〈expr〉
id *〈expr〉
id*id
is called a derivation of id*id from expr.
292
DERIVATIONS
If A::= is a production and and are arbitrary strings of
grammar symbols, we can say:
A
If 12... n, we say 1 derives n.
293
DERIVATIONS
means “derives in one step.”
* means “derives in zero or more steps.”
*
* and then
• if
+
means “derives in one or more steps.”
* , where may contain nonterminals, then we say
If S
that is a sentential form
• If does no contains any nonterminals, we say that is a
sentence
294
DERIVATIONS
G: grammar
S: start symbol
L(G): the language generated by G
Strings in L(G) may contain only terminal symbols of G
+
A string of terminals w is said to be in L(G) if and only if Sw
The string w is called a sentence of G
A language that can be generated by a grammar is said to be a
context-free language
• If two grammars generate the same language, the grammars are
said to be equivalent
295
DERIVATIONS
We have already seen the following production rules:
〈expr〉 ::= 〈expr〉〈op〉〈expr〉| id | num
〈op〉 ::= + | - | * | /
The string id+id is a sentence of the above grammar
because
〈expr〉
〈expr〉+〈expr〉
id +〈expr〉
id + id
* id+id
We write 〈expr〉
296
PARSE TREE
expr
This is called:
Leftmost derivation
expr
op
expr
id
+
id
297
TWO PARSE TREES
Let us again consider the arithmetic expression grammar.
For the line of code:
x+2*y
(we are not considering the semi colon for now)
x+z*y
Lexical
Analyser
id+id*id
Syntax
Analyser
parse tree
Grammar:
〈expr〉::=〈expr〉〈op〉〈expr〉| id | num
〈op〉::= + | - | * | /
298
TWO PARSE TREES
Let us again consider the arithmetic expression grammar.
The sentence id + id * id has two distinct leftmost
derivations:
〈expr〉
〈expr〉〈op〉〈expr〉
id 〈op〉〈expr〉
id +〈expr〉
id +〈expr〉〈op〉〈expr〉
id + id〈op〉〈expr〉
id + id *〈expr〉
id + id * id
〈expr〉 〈expr〉〈op〉〈expr〉
〈expr〉〈op〉〈expr〉〈op〉〈expr〉
id〈op〉〈expr〉〈op〉〈expr〉
id +〈expr〉〈op〉〈expr〉
id + id〈op〉〈expr〉
id + id *〈expr〉
id + id * id
Grammar:
〈expr〉::=〈expr〉〈op〉〈expr〉| id | num
〈op〉::= + | - | * | /
299
TWO PARSE TREES
expr
expr
op
id
+
Equivalent to:
id+(id*id)
expr
expr
expr
expr
op
expr
expr
op
expr
id
*
id
id
+
id
op
expr
*
id
Equivalent to:
(id+id)*id
Grammar:
〈expr〉::=〈expr〉〈op〉〈expr〉| id | num
〈op〉::= + | - | * | /
300
PRECEDENCE
The previous example highlights a problem in the grammar:
• It does not enforce precedence
• It has not implied order of evaluation
We can expand the production rules to add precedence
301
APPLYING PRECEDENCE
UPDATE
The sentence id + id * id has only one leftmost derivation
now:
expr
〈expr〉
〈expr〉 +〈term〉
〈term〉 +〈term〉
〈factor〉+〈term〉
id +〈term〉
id +〈term〉*〈factor〉
id +〈factor〉*〈factor〉
id + id *〈factor〉
id + id * id
expr
term
+
term
term
factor
factor
id
id
*
factor
id
Grammar:
〈expr〉
::=〈expr〉+ 〈term〉|〈expr〉- 〈term〉| 〈term〉
〈term〉
::=〈term〉*〈factor〉| 〈term〉/〈factor〉|〈factor〉
〈factor〉 ::= num | id
302
AMBIGUITY
A grammar that produces more than one parse tree for some
sentence is said to be ambiguous.
Example:
Consider the following statement:
It has two derivations
• It is a context free ambiguity
303
AMBIGUITY
A grammar that produces more than one parse tree for some
sentence is said to be ambiguous
304
ELIMINATING AMBIGUITY
Sometimes an ambiguous grammar can be rewritten to
eliminate the ambiguity.
• E.g. “match each else with the closest unmatched then”
• This is most likely the intention of the programmer
305
MAPPING THIS TO A JAVA
EXAMPLE
In Java, the grammar rules are slightly different then the
previous example
Below is a (very simplified) version of these rules
<stmnt>
::= <matched>
| <unmatched>
<matched>
::= if ( <expr> ) <matched> else <matched>
| other stmnts
<unmatched>
::= if ( <expr> ) < stmnt >
| if ( <expr> ) <matched> else <unmatched>
306
MAPPING THIS TO A JAVA
EXAMPLE
For the following piece of code
if (x==0)
if (y==0)
z = 0;
else
z = 1;
After running the lexical analyser, we get the following list of
tokens:
if ( id == num ) if (id == num) id = num ; else id = num ;
307
MAPPING THIS TO A JAVA
EXAMPLE
Token input string:
if ( id == num ) if (id == num) id = num ; else id = num ;
Building the parse tree:
stmnt
umatched
if
(
expr
)
stmnt
matched
if
(
expr
) matched
else
matched
308
MAPPING THIS TO A JAVA
(ANOTHER) EXAMPLE
Token input string:
if ( id == num ) else id = num ;
Building the parse tree:
stmnt
matched
if
(
expr
) matched
else
matched
309
TOP DOWN PARSING
A top-down parser starts with the root of the parse tree, labelled
with the start or goal symbol of the grammar
To build a parse tree, we repeat the following steps until the leafs
of the parse tree matches the input string
1. At a node labelled A, select a production A::=α and
construct the appropriate child for each symbol of α
2. When a terminal is added to the parse tree that does not
match the input string, backtrack
3. Find the next nonterminal to be expanded
310
TOP DOWN PARSING
Top-down parsing can be viewed as an attempt to find a
leftmost derivation for an input string
Example:
Grammar:
<S> ::= c<A>d
<A> ::= ab | a
Input string
cad
We need to backtrack!
311
EXPRESSION GRAMMAR
Recall our grammar for simple expressions:
Consider the input string:
id – num * id
312
EXAMPLE
Reference Grammar
313
EXAMPLE
Another possible parse for id – num * id
If the parser makes the wrong choices, expansion does not
terminate
• This is not a good property for a parser to have
• Parsers should terminate, eventually…
314
LEFT RECURSION
A grammar is left recursive if:
“It has a nonterminal A such that there is
+
a derivation AA for some string ”
Top down parses cannot handle leftrecursion in a grammar
315
ELIMINATING LEFT
RECURSION
Consider the grammar fragment:
Where α and β do not start with 〈foo〉
We can re-write this as:
Where 〈bar〉is a new non-terminal
This Fragment contains no left recursion
316
EXAMPLE
Our expression grammar contains two cases of left-recursion
Applying the transformation gives
With this grammar, a top-down parser will
•
•
Terminate (for sure)
Backtrack on some inputs
317
PREDICTIVE PARSERS
We saw that top-down parsers may need to backtrack when
they select the wrong production
Therefore, we might need predictive parsers to avoid
backtracking
This is where predictive parsers come in useful
• LL(1): left to right scan, left-most derivation, 1-token look
ahead
• LR(1): left to right scan, right most derivation, 1-token look
ahead
318
SECTION 11
LL(1) PARSER
319
TOPICS
LL(1) Grammar
Eliminating Left Recursion
Left Factoring
FIRST and FOLLOW sets
Parsing tables
LL(1) parsing
Many examples…
320
REVIEW: ROLE OF PARSER
321
PREDICTIVE PARSERS
We saw that top-down parsers may need to backtrack when
they select the wrong production
We want to avoid backtracking
This is where predictive parsers come in useful
• LL(1): left to right scan, left-most derivation, 1-token look
ahead
• LR(1): left to right scan, right most derivation, 1-token look
ahead
322
LL(1) GRAMMAR
In order to use LL(1) parsers, the Context-Free Grammar has
to be:
• Unambiguous (we have discussed ambiguity before)
• Without left recursion (we have discussed left recursion
elimination before)
• Left factored (we will discuss left factoring today)
CFG
Ambiguity
Removal
Left
Recursion
Removal
Left
Factoring
LL(1)
Grammar
The above methods will convert many grammars to LL(1)
form, but not all… There exit many exceptions.
323
REVIEW: LEFT RECURSION
A grammar is left recursive if:
“It has a nonterminal A such that there is
+
a derivation AA for some string ”
Top down parses cannot handle leftrecursion in a grammar
324
ELIMINATING LEFT
RECURSION
Consider the grammar fragment:
Where α and β do not start with 〈foo〉
We can re-write this as:
Where 〈bar〉is a new non-terminal
This Fragment contains no left recursion
325
LEFT FACTORING
For any two productions Aα | β, we would like a
distinct way of choosing the correct production to
expand
We define FIRST(α) as the set of terminals that
appear first in some string derived from α
For a terminal w, we can say:
*
w ∈ FIRST(α) iff α wz
326
LEFT FACTORING
Now going back to our two productions: Aα and
Aβ, we would like:
FIRST(α) ∩ FIRST(β) = f
This would allow the parser to make a correct
choice with a look ahead of only one symbol
327
LEFT FACTORING
Given this grammar:
1
2
3
4
5
6
7
8
The parser cannot choose between productions 1, 2 and 3 given an
input token of num or id
FIRST(1) ∩ FIRST(2) ∩ FIRST(3) ≠ f
Left factoring is required to solve this problem!
328
LEFT FACTORING
So how does it work?
For each non-terminal A, find the longest prefix α common to two or more
of its alternatives
If α ≠ ε, then replace all of the A productions
A αβ1| αβ2| αβ3| … | αβn
With
A α A’
A’β1| β2| β3| … | βn
Where A’ is a new non-terminal
Repeat until no two alternatives for a single non-terminal have a common
prefix
329
LEFT FACTORING
Therefore, in our grammar:
When we perform the left factoring (on expr and term), we get:
330
SHORT BREAK
Imagine, you are not in class, but on the beach, and I do not exist…
Doesn’t that feel good!!
331
LL(1) PARSER
So we now know how to take a Context-Free Grammar, and
transform it into an LL(1) grammar (at least we can try…)
CFG
Ambiguity
Removal
Left
Recursion
Removal
Left
Factoring
LL(1)
Grammar
332
LL(1) PARSER
We need to implement an LL(1) parser that can analyse the
syntax of an input string of tokens without backtracking
• Of course given that the grammar is compatible with such
parser
In order to do that, we need to find two sets for each nonterminal:
• FIRST (we have briefly discussed this set earlier)
• FOLLOW
333
FIRST SET CALCULATION
Rules to calculate the FIRST set:
1. FIRST(terminal){terminal}
2. If Aaα, and a is a terminal:
FIRST(A){a}
3. If ABα, and rule Bε does NOT exist:
FIRST(A)FIRST(B)
4. If ABα, and rule Bε DOES exist:
FIRST(A)[FIRST(B)- ε] υ FIRST(α)
334
FIRST SET CALCULATION
Let’s apply these rules to an example.
1) FIRST(terminal){terminal}
Given the grammar:
<S> ::= <A><B>
<A> ::= a
<B> ::= b
2) If Aaα, and a is a terminal:
FIRST(A){a}
FIRST(A) = {a} (applying 2nd rule)
3) If ABα, and rule Bε does NOT exist:
FIRST(A)FIRST(B)
4) If ABα, and rule Bε DOES exist:
FIRST(A)[FIRST(B)- ε] υ FIRST(α)
FIRST(B) = {b} (applying 2nd rule)
FIRST(S) = FIRST(A)
= {a} (applying 3rd rule)
335
FIRST SET CALCULATION
Another example…
1) FIRST(terminal){terminal}
Given the grammar:
<S> ::= <A><B>
<A> ::= a | ε
<B> ::= b
2) If Aaα, and a is a terminal:
FIRST(A){a}
FIRST(A) = {a, ε} (2nd rule)
3) If ABα, and rule Bε does NOT exist:
FIRST(A)FIRST(B)
4) If ABα, and rule Bε DOES exist:
FIRST(A)[FIRST(B)- ε] υ FIRST(α)
FIRST(B) = {b} (2nd rule)
FIRST(S) = [FIRST(A)- ε] υ FIRST(B)
= {a, b}
(4th rule)
336
FOLLOW SET
CALCULATION
Rules to calculate the FOLLOW set:
1. FOLLOW(S){$} (where S is the starting symbol)
2. If A αB:
FOLLOW(B) FOLLOW(A)
3. If AαBC, and rule Cε does NOT exist:
FOLLOW(B)FIRST(C)
4. If AαBC, and rule Cε DOES exist:
FOLLOW(B)[FIRST(C)- ε] υ FOLLOW(A)
337
FOLLOW SET
CALCULATION
Let’s apply these rules to an example.
1) FOLLOW(S){$}
Given the grammar:
<S> ::= <A><B>
<A> ::= a
<B> ::= b
2) If A αB:
FOLLOW(B) FOLLOW(A)
3) If AαBC, and rule Cε does NOT exist:
FOLLOW(B)FIRST(C)
4) If AαBC, and rule Cε DOES exist:
FOLLOW(S) = {$} (1st rule)
FOLLOW(B)[FIRST(C)- ε] υ FOLLOW(A)
FOLLOW(A) = FIRST(B)
= {b} (3rd rule)
FOLLOW(B) = FOLLOW (S)
= {$} (2nd rule)
338
FOLLOW SET
CALCULATION
Another example…
1) FOLLOW(S){$}
Given the grammar:
<S> ::= <A><B>
<A> ::= a
<B> ::= b | ε
2) If A αB:
FOLLOW(B) FOLLOW(A)
3) If AαBC, and rule Cε does NOT exist:
FOLLOW(B)FIRST(C)
4) If AαBC, and rule Cε DOES exist:
FOLLOW(S) = {$} (1st rule)
FOLLOW(B)[FIRST(C)- ε] υ FOLLOW(A)
FOLLOW(A) = [FIRST(B)- ε]υFOLLOW(S)
= {b, $} (4th rule)
FOLLOW(B) = FOLLOW (S)
= {$} (2nd rule)
339
FIRST AND FOLLOW
Grammar
Let’s calculate FIRST and FOLLOW for each nonterminal in our famous grammar:
Do the easy ones first:
FIRST(factor)={num, id}
FIRST(term’)={*, /, ε}
FIRST(expr’)={+, -, ε}
And then the more challenging ones:
FIRST(term)=FIRST(factor)={num, id}
FIRST(expr)=FIRST(term)={num, id}
FIRST “Rules”
1) FIRST(terminal){terminal}
2) If Aaα, and a is a terminal:
FIRST(A){a}
3) If ABα, and rule Bε does NOT exist:
FIRST(A)FIRST(B)
4) If ABα, and rule Bε DOES exist:
FIRST(A)[FIRST(B)- ε] υ FIRST(α)
340
FIRST AND FOLLOW
Grammar
Let’s calculate FIRST and FOLLOW for each nonterminal in our famous grammar:
Start with the easy ones:
FOLLOW(expr)={$}
FOLLOW(expr’)=FOLLOW(expr)={$}
FOLLOW “Rules”
1) FOLLOW(S){$}
2) If A αB:
FOLLOW(B) FOLLOW(A)
3) If AαBC, and rule Cε does NOT exist:
FOLLOW(B)FIRST(C)
4) If AαBC, and rule Cε DOES exist:
341
FOLLOW(B)[FIRST(C)- ε] υ FOLLOW(A)
FIRST AND FOLLOW
Grammar
Let’s calculate FIRST and FOLLOW for each nonterminal in our famous grammar:
Let’s do the harder ones:
FOLLOW(term)=[FIRST(expr’)-ε]υFOLLOW(expr)
= {+, -, $}
FOLLOW(factor)=[FIRST(term’)-ε]υFOLLOW(term)
= {*, /, +, -, $}
FOLLOW(term’)= FOLLOW(term)
FOLLOW “Rules”
1) FOLLOW(S){$}
2) If A αB:
FOLLOW(B) FOLLOW(A)
= {+, -, $}
3) If AαBC, and rule Cε does NOT exist:
FOLLOW(B)FIRST(C)
4) If AαBC, and rule Cε DOES exist:
342
FOLLOW(B)[FIRST(C)- ε] υ FOLLOW(A)
FIRST AND FOLLOW
Summary:
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
Using these sets, we build a parse table
• This parse table is necessary to perform LL(1) parsing
343
PARSE TABLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
We will add two entries associated with num and id
num
id
+
-
*
/
$
expr
expr’
term
term’
factor
344
PARSE TABLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
We will add two entries associated with num and id
expr
num
id
<expr>
<term><expr’>
<expr>
<term><expr’>
+
-
*
/
$
expr’
term
term’
factor
345
PARSE TABLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
Fill the expr’ in the same way
expr
num
id
<expr>
<term><expr’>
<expr>
<term><expr’>
+
-
*
/
$
expr’
term
term’
factor
346
PARSE TABLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
Fill the expr’ in the same way
expr
expr’
num
id
<expr>
<term><expr’>
<expr>
<term><expr’>
+
-
<expr’>
+<expr>
<expr’>
-<expr>
*
/
$
term
term’
factor
347
PARSE TABLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
What about the epsilon? Use the FOLLOW set to
add the epsilon rule…
expr
expr’
num
id
<expr>
<term><expr'>
<expr>
<term><expr'>
+
-
<expr’>
+<expr>
<expr’>
-<expr>
*
/
$
term
term’
factor
348
PARSE TABLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
What about the epsilon? Use the FOLLOW set to
add the epsilon rule…
expr
expr’
num
id
<expr>
<term><expr'>
<expr>
<term><expr'>
+
-
<expr’>
+<expr>
<expr’>
-<expr>
*
/
$
<expr’>
ε
term
term’
factor
349
PARSE TABLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
No, epsilon, just use the FIRST set
expr
expr’
num
id
<expr>
<term><expr'>
<expr>
<term><expr'>
+
-
<expr’>
+<expr>
<expr’>
-<expr>
*
/
$
<expr’>
ε
term
term’
factor
350
PARSE TABLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
No, epsilon, just use the FIRST set
expr
num
id
<expr>
<term><expr'>
<expr>
<term><expr'>
expr’
term
<term>
<factor><term’>
+
-
<expr’>
+<expr>
<expr’>
-<expr>
*
/
$
<expr’>
ε
<term>
<factor><term’>
term’
factor
351
PARSE TABLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
This one has an epsilon, use the FIRST and
FOLLOW sets
expr
num
id
<expr>
<term><expr'>
<expr>
<term><expr'>
expr’
term
<term>
<factor><term’>
+
-
<expr’>
+<expr>
<expr’>
-<expr>
*
/
$
<expr’>
ε
<term>
<factor><term’>
term’
factor
352
PARSE TABLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
This one has an epsilon, use the FIRST and
FOLLOW sets
expr
num
id
<expr>
<term><expr'>
<expr>
<term><expr'>
expr’
term
term’
<term>
<factor><term’>
+
-
<expr’>
+<expr>
<expr’>
-<expr>
<term’>
ε
<term’>
ε
*
/
$
<expr’>
ε
<term>
<factor><term’>
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
353
PARSE TABLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
Fill the row for factor…
expr
num
id
<expr>
<term><expr'>
<expr>
<term><expr'>
expr’
term
term’
<term>
<factor><term’>
+
-
<expr’>
+<expr>
<expr’>
-<expr>
<term’>
ε
<term’>
ε
*
/
$
<expr’>
ε
<term>
<factor><term’>
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
354
PARSE TABLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
Fill the row for factor…
expr
num
id
<expr>
<term><expr'>
<expr>
<term><expr'>
expr’
term
<term>
<factor><term’>
factor num
-
<expr’>
+<expr>
<expr’>
-<expr>
<term’>
ε
<term’>
ε
*
/
$
<expr’>
ε
<term>
<factor><term’>
term’
factor
+
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor id
355
PARSE TABLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
Add dashes to the remaining cells to indicate: no entry
expr
num
id
<expr>
<term><expr'>
<expr>
<term><expr'>
expr’
term
<term>
<factor><term’>
factor num
-
<expr’>
+<expr>
<expr’>
-<expr>
<term’>
ε
<term’>
ε
*
/
$
<expr’>
ε
<term>
<factor><term’>
term’
factor
+
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor id
356
PARSE TABLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
357
PARSING USING LL(1)
In order to implement an LL(1) parser, we need to use the
following data structures:
• Parsing table (can be implemented with a 2D array or
something fancier)
• Stack (that will contain the derivations)
• List (that will contain the token input stream)
358
PARSING USING LL(1)
Example:
id
num
-
*
id
$
Token stream list
Derivation Stack
Parse Table
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
$
-
359
PARSING USING LL(1)
Example:
id
num
-
*
id
$
Start by pushing the starting symbol (goal) into the stack
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
$
-
360
PARSING USING LL(1)
Example:
id
num
-
*
id
$
Start by pushing the starting symbol (goal) into the stack
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr
$
-
361
PARSING USING LL(1)
Example:
id
num
-
*
id
$
On the head of the input stream, we have id
On the top of the stack, we have expr
Using the parsing table, we retrieve the rule: <expr><term><expr’>
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr
$
-
362
PARSING USING LL(1)
Example:
id
num
-
*
id
$
POP expr and PUSH term and expr’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr
$
-
363
PARSING USING LL(1)
Example:
id
num
-
*
id
$
On the head of the input stream, we have id
On the top of the stack, we have term
Using the parsing table, we retrieve the rule: <term><factor><term’>
term
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
364
PARSING USING LL(1)
Example:
id
num
-
*
id
$
POP term and PUSH factor and term’
term
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
365
PARSING USING LL(1)
Example:
id
num
-
*
id
$
On the head of the input stream, we have id
On the top of the stack, we have factor
Using the parsing table, we retrieve the rule: <factor>id
factor
term’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
366
PARSING USING LL(1)
Example:
id
num
-
*
id
$
Whenever we have a terminal on top of the stack, we check if it matches
the head of the list
If it does not syntax does not follow grammar
If it does, REMOVE head of the list and POP the stack
id
term’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
367
PARSING USING LL(1)
Example:
num
-
*
id
$
Whenever we have a terminal on top of the stack, we check if it matches
the head of the list
If it does not syntax does not follow grammar
If it does, REMOVE head of the list and POP the stack
term’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
368
PARSING USING LL(1)
Example:
num
-
*
id
$
On the head of the input stream, we have On the top of the stack, we have term’
Using the parsing table, we retrieve the rule: <term’>ε
Therefore, we should simply POP
term’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
369
PARSING USING LL(1)
Example:
num
-
*
id
$
And continue the same way…
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
370
PARSING USING LL(1)
Example:
num
-
*
id
$
And continue the same way…
-
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr
$
-
371
PARSING USING LL(1)
Example:
num
*
id
$
And continue the same way…
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr
$
-
372
PARSING USING LL(1)
Example:
num
*
id
$
And continue the same way…
term
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
373
PARSING USING LL(1)
Example:
num
*
id
$
And continue the same way…
factor
term’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
374
PARSING USING LL(1)
Example:
num
*
id
$
And continue the same way…
num
term’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
375
PARSING USING LL(1)
Example:
*
id
$
And continue the same way…
term’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
376
PARSING USING LL(1)
Example:
*
id
$
And continue the same way…
*
term
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
377
PARSING USING LL(1)
Example:
id
$
And continue the same way…
term
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
378
PARSING USING LL(1)
Example:
id
$
And continue the same way…
factor
term’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
379
PARSING USING LL(1)
Example:
id
$
And continue the same way…
id
term’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
380
PARSING USING LL(1)
Example:
$
And continue the same way…
term’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
381
PARSING USING LL(1)
Example:
$
And continue the same way…
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
expr’
$
-
382
PARSING USING LL(1)
Example:
$
We have verified that the input string is a sentence of
the grammar!!
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
$
-
383
SECTION 12
MORE ON LL PARSING
384
TOPICS
Non LL(1) Grammar
Error Recovery
LL(K) Parsers
385
A NON LL(1) GRAMMAR
Consider the grammar:
<stmt> ::= if <expr> then <stmt>
| if <expr> then <stmt> else <stmt>
Needs left factoring, which gives:
<stmt> ::= if <expr> then <stmt><stmt’>
<stmt’> ::= else <stmt> | ε
Let’s get the FIRST and FOLLOW sets
FIRST(stmt) = {if}
FIRST(stmt’)={else, ε}
FOLLOW(stmt) = {$, else}
FOLLOW(stmt’)={$, else}
Note: This is a partial grammar (used to demonstrate a concept), therefore we did not specify the
production rules associated with expr. Consequently, its FIRST and FOLLOW sets will not be
calculated.
386
A NON LL(1) GRAMMAR
FIRST(stmt) = {if}
FIRST(stmt’)={else, ε}
…
FOLLOW(stmt) = {$, else}
FOLLOW(stmt’)={$, else}
…
<stmt> ::= if <expr> then <stmt><stmt’>
<stmt’> ::= else <stmt> | ε
if
then
else
$
stmt
stmt’
387
A NON LL(1) GRAMMAR
FIRST(stmt) = {if}
FIRST(stmt’)={else, ε}
…
FOLLOW(stmt) = {$, else}
FOLLOW(stmt’)={$, else}
…
<stmt> ::= if <expr> then <stmt><stmt’>
<stmt’> ::= else <stmt> | ε
stmt
if
then
else
$
<stmt>
if <expr> then
<stmt><stmt’>
-
-
-
stmt’
388
A NON LL(1) GRAMMAR
FIRST(stmt) = {if}
FIRST(stmt’)={else, ε}
…
FOLLOW(stmt) = {$, else}
FOLLOW(stmt’)={$, else}
…
<stmt> ::= if <expr> then <stmt><stmt’>
<stmt’> ::= else <stmt> | ε
stmt
stmt’
if
then
else
$
<stmt>
if <expr> then
<stmt><stmt’>
-
-
-
<stmt’>
else <stmt>
389
A NON LL(1) GRAMMAR
FIRST(stmt) = {if}
FIRST(stmt’)={else, ε}
…
FOLLOW(stmt) = {$, else}
FOLLOW(stmt’)={$, else}
…
<stmt> ::= if <expr> then <stmt><stmt’>
<stmt’> ::= else <stmt> | ε
stmt
stmt’
if
then
else
$
<stmt>
if <expr> then
<stmt><stmt’>
-
-
-
<stmt’>
else <stmt>
<stmt’>
390
ε
A NON LL(1) GRAMMAR
FIRST(stmt) = {if}
FIRST(stmt’)={else, ε}
…
FOLLOW(stmt) = {$, else}
FOLLOW(stmt’)={$, else}
…
<stmt> ::= if <expr> then <stmt><stmt’>
<stmt’> ::= else <stmt> | ε
if
then
else
$
stmt
<stmt>
if <expr> then
<stmt><stmt’>
-
-
-
stmt’
-
-
<stmt’>
else <stmt>,
<stmt’>
ε
<stmt’>
391
ε
A NON LL(1) GRAMMAR
The problem arises because for an input token else and
stack top of stmt, we do not know which production to
choose:
• <stmt’>else <stmt>
• <stmt’>ε
Therefore, this is not an LL(1) grammar
if
then
else
$
stmt
<stmt>
if <expr> then
<stmt><stmt’>
-
-
-
stmt’
-
-
<stmt’>
else <stmt>,
<stmt’>
ε
<stmt’>
392
ε
LL(1) ERROR RECOVERY
What happens when the parser discovers an error?
• Approach 1: stop all parsing activity and return an error
message
• Approach 2: try to continue parsing (if possible) and see if
there are more errors along the way
At Nothing!
Which approach does your compiler take?
393
LL(1) ERROR RECOVERY
An error is detected when:
• The terminal on top of the stack does not match the next input
token
• The parsing table cell from which we are supposed to pull the
next production is empty
What does the parser do?
• It enters the panic-mode error recovery
• Based on the idea of skipping symbols on the input until a
token in a selected set of synchronizing tokens appears
394
LL(1) ERROR RECOVERY
Let S be a set of tokens called a synchronization set.
Let s ∊ S s is called a synchronization token
Million dollar question: how to construct the synchronization
set?
• Many heuristics have been proposed
• We will cover a simple method
Place all symbols in FOLLOW(A) into the synchronizing set
for nonterminal A
• If we skip tokens until an element of FOLLOW(A) is seen and
we pop A from the stack, it’s likely that parsing can continue.
395
LL(1) ERROR RECOVERY
The panic-mode error recovery can be implemented using
the synchronization set(s) as follows:
1.
2.
If there is a nonterminal at the top of the stack, discard input
tokens until you find a synch token, then pop the non-terminal
If there is a terminal at the top of the stack, we could try popping it
to see whether we can continue
•
Assume that the input string is actually missing that terminal
396
LL(1) ERROR RECOVERY
EXAMPLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
-
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε
term
<term>
<factor><term’>
<term>
<factor><term’>
-
-
-
-
-
term’
-
-
<term’>
ε
<term’>
ε
<term’>
*<term>
<term’>
/<term>
<term’>
ε
factor
factor num
factor id
-
-
-
-
-
SEG2106 - Hussein Al Osman - Winter 2014
397
LL(1) ERROR RECOVERY
EXAMPLE
FIRST Sets
Grammar
FOLLOW Sets
FIRST(expr)= {num, id}
FIRST(expr’)= {+, -, ε}
FIRST(term)= {num, id}
FIRST(term’)= {*, /, ε}
FIRST(factor)= {num, id}
FOLLOW(expr)={$}
FOLLOW(expr’)={$}
FOLLOW(term)= {+, -, $}
FOLLOW(term’)= {+, -, $}
FOLLOW(factor)= {*, /, +, -, $}
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
(s)
SEG2106 - Hussein Al Osman - Winter 2014
398
PARSING USING LL(1)
Example:
id
*
/
/
+
num
+
id
$
String of errors
expr
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
399
PARSING USING LL(1)
Example:
id
term
expr’
*
/
/
+
num
+
id
$
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
400
PARSING USING LL(1)
Example:
id
*
/
/
+
num
+
id
$
num
id
+
-
*
/
$
factor
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
term'
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
expr’
$
(s)
401
PARSING USING LL(1)
Example:
id
*
/
/
+
num
+
id
$
num
id
+
-
*
/
$
id
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
term'
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
expr’
$
(s)
402
PARSING USING LL(1)
Example:
*
term'
expr’
/
/
+
num
+
id
$
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
403
PARSING USING LL(1)
Example:
*
/
/
+
num
+
id
$
num
id
+
-
*
/
$
*
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
term
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
expr’
$
(s)
404
PARSING USING LL(1)
Example:
/
/
+
num
+
id
$
Error: the cell corresponding to row term and column / is empty!
Start discarding tokens, until you find a synch token
term
expr’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
405
PARSING USING LL(1)
Example:
/
+
num
+
id
$
Error: the cell corresponding to row term and column / is empty!
Start discarding tokens, until you find a synch token
term
expr’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
406
PARSING USING LL(1)
Example:
+
num
+
id
$
Error: the cell corresponding to row term and column / is empty!
Start discarding tokens, until you find a synch token
term
expr’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
407
PARSING USING LL(1)
Example:
+
num
+
id
$
We have found a synch token!
Pop term from the stack and attempt to continue…
term
expr’
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
408
PARSING USING LL(1)
Example:
+
expr’
num
+
id
$
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
409
PARSING USING LL(1)
Example:
+
+
expr
num
+
id
$
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
410
PARSING USING LL(1)
Example:
expr
num
+
id
$
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
411
PARSING USING LL(1)
Example:
term
expr'
num
+
id
$
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
412
PARSING USING LL(1)
Example:
factor
term’
expr'
num
+
id
$
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
413
PARSING USING LL(1)
Example:
num
term’
expr'
num
+
id
$
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
414
PARSING USING LL(1)
Example:
+
term’
expr'
id
$
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
415
PARSING USING LL(1)
Example:
+
expr'
id
$
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
416
PARSING USING LL(1)
Example:
+
+
expr
id
$
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
417
PARSING USING LL(1)
Example:
id
expr
$
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
418
PARSING USING LL(1)
Example:
id
term
expr'
$
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
419
PARSING USING LL(1)
Example:
id
$
num
id
+
-
*
/
$
factor
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
term'
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
expr'
$
(s)
420
PARSING USING LL(1)
Example:
id
$
num
id
+
-
*
/
$
id
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
term'
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
expr'
$
(s)
421
PARSING USING LL(1)
Example:
$
term'
expr'
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
422
PARSING USING LL(1)
Example:
$
expr'
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
423
PARSING USING LL(1)
Example:
$
We did our best to continue parsing…
num
id
+
-
*
/
$
expr
<expr>
<term><expr'>
<expr>
<term><expr'>
-
-
-
-
(s)
expr’
-
-
<expr’>
+<expr>
<expr’>
-<expr>
-
-
<expr’>
ε (s)
term
<term>
<factor><term’>
<term>
<factor><term’>
(s)
(s)
-
-
(s)
term’
-
-
<term’>
ε (s)
<term’>
ε (s)
<term’>
*<term> (s)
<term’>
/<term> (s)
<term’>
ε (s)
factor
factor num
factor id
(s)
(s)
(s)
(s)
$
(s)
424
LL(K) PARSERS
We have already studies LL(1) parser
• With 1 token look-ahead
We will touch briefly on LL(k) parsers
• With “k” tokens look-ahead
• This is useful since not all grammars are LL(1) compatible
425
LL(K) PARSERS
Consider the following grammar:
<Z> ::= <X><Y><Z>| a | ab
<Y> ::= c | ε
<X> ::= a | b<Y>c
First and Follow sets:
FIRST(Z)={a,b}
FOLLOW(Z)={$}
FIRST(Y)={c, ε}
FOLLOW(Y)={a,b,c}
FIRST(X)={a,b}
FOLLOW(X)={a,b,c}
426
LL(K) PARSERS
Grammar
FIRST
FOLLOW
<Z> ::= <X><Y><Z>| a | ab
FIRST(Z)={a,b}
FOLLOW(Z)={$}
<Y> ::= c | ε
FIRST(Y)={c, ε}
FOLLOW(Y)={a,b,c}
<X> ::= a | b<Y>c
FIRST(X)={a,b}
FOLLOW(X)={a,b,c}
a
b
c
$
X
Y
Z
427
LL(K) PARSERS
Grammar
FIRST
FOLLOW
<Z> ::= <X><Y><Z>| a | ab
FIRST(Z)={a,b}
FOLLOW(Z)={$}
<Y> ::= c | ε
FIRST(Y)={c, ε}
FOLLOW(Y)={a,b,c}
<X> ::= a | b<Y>c
FIRST(X)={a,b}
FOLLOW(X)={a,b,c}
X
a
b
c
$
Xa
XbYc
-
-
Y
Z
428
LL(K) PARSERS
Grammar
FIRST
FOLLOW
<Z> ::= <X><Y><Z>| a | ab
FIRST(Z)={a,b}
FOLLOW(Z)={$}
<Y> ::= c | ε
FIRST(Y)={c, ε}
FOLLOW(Y)={a,b,c}
<X> ::= a | b<Y>c
FIRST(X)={a,b}
FOLLOW(X)={a,b,c}
a
b
c
$
X
Xa
XbYc
-
-
Y
Yε
Yε
Yc,
Yε
-
Z
429
LL(K) PARSERS
Grammar
FIRST
FOLLOW
<Z> ::= <X><Y><Z>| a | ab
FIRST(Z)={a,b}
FOLLOW(Z)={$}
<Y> ::= c | ε
FIRST(Y)={c, ε}
FOLLOW(Y)={a,b,c}
<X> ::= a | b<Y>c
FIRST(X)={a,b}
FOLLOW(X)={a,b,c}
a
b
c
$
X
Xa
XbYc
-
-
Y
Yε
Yε
Yc,
Yε
-
Z
Za
Zab
ZXYZ
-
-
Not an LL(1) Grammar
430
LL(K) PARSERS
Grammar
<Z> ::= <X><Y><Z>| a | ab
<Y> ::= c | ε
<X> ::= a | b<Y>c
We have shown that the above grammar is not LL(1)
Maybe it is an LL(2) grammar
• Re-create the sets FIRST(α) while considering a max of TWO
terminals appearing first in a string derived from α
• Re-create the sets FOLLOW (α) while considering a max of
TWO terminals appearing after α in a sentential form
• Make sure that a single production exists in every table cell
431
SECTION 13
LR PARSING
432
TOPICS
Bottom Up parsing
Right Most Derivation
Shift and Reduce Operations
LR Parsers
433
TOP DOWN PARSING
So far we have studied Top Down Parsing extensively
Nonetheless, we have not seen Top Down Parsing with right
most derivation
• We have worked exclusively so far with left most derivation
• We always eliminate non-terminals in the parsing tree from
left to right
434
RIGHT MOST DERIVATION
Grammar
Derivation
<expr> <term><expr’>
<term>+<expr>
<term>+<term><expr’>
<term>+<term>
<term>+<factor><term’>
<term>+<factor>
<term>+id
Input String:
id+id
<factor><term’>+id
<factor>+id
id+id
435
BOTTOM UP PARSING
A bottom up parser builds a parsing tree starting from the
input string
• Input string will constitute the leafs of the tree
A parent node A can be added to the tree if:
• There exists several “parentless” neighboring nodes (n1, n2, …
nn) for which there exists a production:
<A> ::= n1n2 … nn
• A is added as the parent of nodes n1, n2, … nn
This action is called REDUCTION
436
BOTTOM UP PARSING
Example:
We can build the parsing tree as follows:
Reached the
starting symbol!
A
Given the grammar:
<A> ::= a<B>
B
<B> ::= b | cd<B>
B
And the input string:
B
acdcdb
a
c
d
c
d
b
437
LR PARSER
LR parser is a bottom up parser
It provides a mechanism to build a parse tree incrementally,
without backtracking
Advantages of LR parsing (over LL parsing):
• No need to eliminate left recursion
• No need for left factoring
The previous example of the bottom up parser lacks this
predictive quality
• See example at the next slide…
438
NON PREDICTIVE BOTTOM
UP PARSER
Example:
We can build the parsing tree as follows:
Given the grammar:
<A> ::= a<B> | acd
<B> ::= b | cd<B>
Reached the starting
symbol too early!
We did not process the
rest of the string…
A
And the same input string:
acdcdb
a
c
d
c
d
b
439
BACK TO LR PARSERS
LR parsers rely on two main actions they perform during
parsing:
• Shift: advances the input string by one symbol
• Reduce: we have discussed this action earlier
(taking a group of symbols and reducing them to a single
non-terminal)
If the input string has no errors (is a sentence of the
grammar):
• The parser continues to perform these actions until all of the
input has been consumed
• At which point, the parse tree is complete, with the starting
symbol as its root
440
LR PARSERS
LR parsers MUST know when to shift and when to reduce…
• This quality makes them predictive
• Prevents them from backtracking (avoids guessing)
LR parsers often look ahead (rightwards) at the next scanned
symbol, before deciding what to do with previously scanned
ones
441
SHIFT AND REDUCE
LR Parsers split the sentential form into two parts:
• Analysed part: sequence of terminals and non-terminals
• Un-analyzed part: sequence of terminals
For example, for the following sentential form:
Analyzed
part
Un-Analyzed
part
a A b c d
marker
442
SHIFT AND REDUCE
Therefore, we define the operation:
• Shift: as moving the marker to the right
a A b c d
• Reduce: as replacing a string in the right-most portion of
the analyzed part by its equivalent non-terminal
Suppose I have a production:
<Z> ::= <A>bc
a A b
a c
Z dd
443
USING SHIFT AND REDUCE
Consider the following grammar:
<E> ::= <T> + <E> | <T>
<T> ::= id*<T> | id | ( <E> )
Using Shift and Reduce operations, parse the following input
string:
id*id+id
444
USING SHIFT AND REDUCE
Sentential Form
id * id + id
Action
Shift
id * id + id
Shift
id * id + id
Shift
id * id + id
Reduce using Tid
id * T + id
Reduce using Tid*T
T + id
Shift
T + id
Shift
T + id
Reduce using Tid
T + T
Reduce using ET
T + E
Reduce using ET+E
Grammar
<E> ::= <T> + <E> | <T>
<T> ::= id*<T> | id | ( <E> )
E
445
USING SHIFT AND REDUCE
INCORRECTLY
Sentential Form
Action
id * id + id
Shift
id * id + id
Reduce using Tid
T * id + id
Shift
T * id + id
Shift
T * id + id
Reduce using Tid
T * T + id
Reduce TE
T * E + id
Shift
T * E + id
Shift
T * E + id
Reduce using Tid
T * E + T
We are stuck!
Grammar
<E> ::= <T> + <E> | <T>
<T> ::= id*<T> | id | ( <E> )
One bad operation and
it’s all over…
446
LR PARSER
We now know how to shift and reduce!
But we do not know when to shift and when to reduce
• Once we know that, we achieve our purpose of never
backtracking
447
HANDLE
We reduce if the rightmost portion of the analysed part is a
valid handle
• Otherwise, we shift
Properties of the handle:
1. Should match the right hand side of a production
2. Its reduction should allow us to eventually reach the
starting symbol
Reducing the handle must constitute a step in the reverse
direction of a right most top down derivation
448
HANDLE
Grammar
<E> ::= <T> + <E>
| <T>
<T> ::= id*<T>
Derivation
<E>
<T>+<E>
<T>+<T>
| id
<T>+id
| ( <E> )
id*<T>+id
id*id+id
Input String:
id*id+id
449
SHIFT AND REDUCE WITH
HANDLE
Sentential Form
id * id + id
Action
Shift
id * id + id
Shift
id * id + id
Shift
id * id + id
Reduce using Tid
id * T + id
Reduce using Tid*T
T + id
Shift
T + id
Shift
T + id
Reduce using Tid
T + T
Reduce using ET
T + E
Reduce using ET+E
E
Grammar
<E> ::= <T> + <E> | <T>
<T> ::= id*<T> | id | ( <E> )
Derivation:
<E>
<T>+<E>
<T>+<T>
<T>+id
id*<T>+id
id*id+id
450
SECTION 14
INTRODUCTION TO
CONCURRENCY
451
TOPICS
Concepts of concurrency
Subprogram-level concurrency
Semaphores
Deadlocks
452
CONCEPT OF
CONCURRENCY
Concurrency can be achieved at different levels:
•
•
•
•
Instruction level
Statement level
Unit level
Program level
Concurrent execution of program units can be
performed:
• Physically on separate processors,
• or Logically in some time-sliced fashion on a single processor
computer system
453
WHY STUDY
CONCURRENCY?
Computing systems solve real world problems,
where things happen at the same time:
• Railway Networks (lots of trains running, but that have to
synchronize on shared sections of track)
• Operating System, with lots of processes running concurrently
• Web servers
Multiple processor or multi-core computers are
now being widely used
• This creates the need for software to make effective use of
that hardware capability
454
SUBPROGRAM-LEVEL
CONCURRENCY
A task is a unit of program that can be executed
concurrently with other units of the same program
• Each task in a program can provide one thread of
control
A task can communicate with other tasks through:
• Shared nonlocal variables
• Message passing
• Parameters
455
SYNCHRONIZATION
A mechanism to control the order in which tasks
execute
Cooperation synchronization is required between
task A and task B when:
• Task A must wait for task B to complete some specific activity
before task A can continue execution
• Recall the producer-consumer petri net problem
Competition synchronization is required between
two tasks when:
• Both require the use of some resource that cannot be
simultaneously used
456
THE NEED FOR COMPETITION
SYNCHRONIZATION
Value of Total = 3
4
6
Task A
Fetch
Total
Add 1
Store
Total
Task B
Fetch
Total
Multiply
by 2
Store
Total
Time
457
CRITICAL SECTION
A segment of code, in which the thread may be:
• Changing common variables,
• Updating a table,
• Writing to a file,
• Or updating any shared resource
The execution of critical sections by the threads is
mutually exclusive in time
458
TASK (THREAD) STATES
New: it has been created, but has not yet begun its
execution
Runnable or ready: it is ready to run, but is not
currently running
Running: it is currently executing, it has a processor
and its code is being executed
Blocked: it has been running, but its execution was
interrupted by one of several different events
Dead: no longer active in any sense
459
SEMAPHORES
Semaphore is a technique used to control access
to common resource for multiple tasks
• It is a data structure consisting of an integer and a
queue that stores task descriptors
A task that requires access to a critical section
needs to “acquire” the semaphore
Classically: a system of sending messages by holding the arms of two
flags in certain positions according to an alphabetic code
460
SEMAPHORES
Two operations are always associated with
Semaphores
Operation “P” is used to get the semaphore, and
“V” to release it
• P (proberen, meaning to test and decrement the
integer)
• V (verhogen, meaning to increment) operation
Alternatively, these operations are called: wait and
release
461
SEMAPHORES
Operating systems often distinguish between
counting and binary semaphores
The value of a counting semaphore can range over
an unrestricted domain.
The value of a binary semaphore can range only
between 0 and 1
462
SEMAPHORES
The general strategy for using a binary semaphore
to control access to a critical section is as follows:
Semaphore aSemaphore;
P(aSemaphore);
Critical section();
V(aSemaphore);
463
COOPERATION
SYNCHRONIZATION
wait(aSemaphore);
if aSemaphore’s counter > 0 then
Decrement aSemaphore’s counter
else
Set the task’s state to blocked
Put the caller in aSemaphore’s queue
end
464
COOPERATION
SYNCHRONIZATION
release(aSemaphore);
if aSemaphore’s queue is empty then
increment aSmaphore’s counter
else
set the state of the task at the queue head to ready
Perform a dequeue operation
end
465
PRODUCER AND
CONSUMER
466
ADDING COMPETITION
SYNCHRONIZATION
467
COMPETITION
SYNCHRONIZATION (II)
468
DEADLOCKS
A law passed by the Kansas legislature early in
20th century:
“…… When two trains approach each other at a
crossing, both shall come to a full stop and
neither shall start up again until the other
has gone. ……”
469
DEADLOCK
Classic case of traffic deadlock. This is
a gridlock where not vehicle can move
forward to clear the traffic jam
470
CONDITIONS FOR
DEADLOCK
Mutual exclusion: the act of allowing only one process to
have access to a dedicated resource
Hold-and-wait: there must be a process holding at least one
resource and waiting to acquire additional ones that are
currently being held by other processes
No preemption: the lack of temporary reallocation of
resources, can be released only voluntarily
Circular waiting: each process involved in the impasse is
waiting for another to voluntarily release the resource
471
DEADLOCK EXAMPLE
BinarySemaphore s1, s2;
Task A:
wait(s1)
// access resource 1
wait (s2)
// access resource 2
release(s2)
release(s1)
end task
Task B:
wait(s2)
// access resource 2
wait(s1)
// access resource 1
release(s1)
release(s2)
end task
472
STRATEGY FOR HANDLING
DEADLOCKS
Prevention: eliminate one of the necessary
conditions
Avoidance: avoid if the system knows ahead of
time the sequence of resource quests associated
with each active processes
Detection: detect by building directed resource
graphs and looking for circles
Recovery: once detected, it must be untangled and
the system returned to normal as quickly as
possible
• Process termination
• Resource preemption
473
SECTION 15
MORE ON CONCURRENCY
474
TOPICS
Monitors
Monitor Examples
Asynchronous Message Passing
Synchronous Message Passing
Intro to Java Threads
475
MONITOR
A monitor is a set of multiple routines which are protected by
a mutual exclusion lock
• None of the routines in the monitor can be executed by a
thread until that thread acquires the lock
Any other threads must wait for the thread that is currently
executing to give up control of the lock
476
MONITOR
A thread can actually suspend itself inside a monitor and
then wait for an event to occur
• If this happens, then another thread is given the opportunity to
enter the monitor
Usually, a thread suspends itself while waiting for a condition
• During the wait, the thread temporarily gives up its exclusive
access
• It must reacquire it after the condition has been met.
477
MONITOR VS SEMAPHORE
A semaphore is a simpler construct than a monitor because
it’s just a lock that protects a shared resource
• Not a set of routes like a monitor
An task must acquire (or wait for) a semaphore before
accessing a shared resource
A task must simply call a routine (or procedure) in the
monitor in order access a shared resource
• When done, you do not have to release anything
• Remember you have to release semaphores (if you forget
deadlock)
478
COMPETITION
SYNCHRONIZATION
One of the most important features of monitors is that shared
data is resident in the monitor
• All synchronization code is centralized in one location
• This is in contrast to being in the competing tasks
The monitor guarantees synchronization by allowing access
to only one task at time
• Remember that using counting semaphores, we are able to allow
multiple tasks access, not necessarily only one
Calls to monitor procedures are implicitly queued if the
monitor is busy at the time of the call
479
COOPERATION
SYNCHRONIZATION
Although mutually exclusive access to shared data is
intrinsic with a monitor:
• Cooperation between processes is still the task of the
programmer
Programmer must guarantee that a shared buffer does not
experience underflow or overflow
480
EXAMPLE OF USING
MONITOR
Monitor
procedure_1
Task A
Queue
Task B
procedure_2
Task C
procedure_3
Task D
procedure_4
Monitor Owner: none
481
EXAMPLE OF USING
MONITOR
Monitor
procedure_1
Task A
Queue
Task B
procedure_2
Task C
procedure_3
Task D
procedure_4
Monitor Owner: none
482
EXAMPLE OF USING
MONITOR
Monitor
procedure_1
Task A
Queue
Task B
procedure_2
Task C
procedure_3
Task D
procedure_4
Monitor Owner: Task A
483
EXAMPLE OF USING
MONITOR
Monitor
procedure_1
Task A
Queue
Task B
procedure_2
Task C
procedure_3
Task D
procedure_4
Monitor Owner: Task A
484
EXAMPLE OF USING
MONITOR
Monitor
procedure_1
Task A
Queue
Task B
procedure_2
Task C
Task C
procedure_3
Task D
procedure_4
Monitor Owner: Task A
485
EXAMPLE OF USING
MONITOR
Monitor
procedure_1
Task A
Queue
Task B
procedure_2
Task C
Task C
procedure_3
Task D
procedure_4
Monitor Owner: Task A
486
EXAMPLE OF USING
MONITOR
Monitor
procedure_1
Task A
Queue
Task B
procedure_2
Task C
Task B
Task C
procedure_3
Task D
procedure_4
Monitor Owner: Task A
487
EXAMPLE OF USING
MONITOR
Monitor
Task A
return
procedure_1
Queue
Task B
procedure_2
Task C
Task B
Task C
procedure_3
Task D
procedure_4
Monitor Owner: Task A
488
EXAMPLE OF USING
MONITOR
Monitor
procedure_1
Task A
Queue
Task B
procedure_2
Task C
Task B
Task C
procedure_3
Task D
procedure_4
Monitor Owner: none
489
EXAMPLE OF USING
MONITOR
Monitor
procedure_1
Task A
Queue
Task B
procedure_2
Task B
Task C
procedure_3
Task D
procedure_4
Monitor Owner: Task C
490
EXAMPLE OF USING
MONITOR
Monitor
procedure_1
Task A
Queue
Task B
procedure_2
Task B
Task C
procedure_3
Task D
procedure_4
Monitor Owner: Task C
491
EXAMPLE OF USING
MONITOR
Monitor
procedure_1
Task A
Queue
Task B
procedure_2
Task B
Task C
procedure_3
Task D
procedure_4
Monitor Owner: none
492
EXAMPLE OF USING
MONITOR
Monitor
procedure_1
Task A
Queue
Task B
procedure_2
Task C
procedure_3
Task D
procedure_4
Monitor Owner: Task B
493
EXAMPLE: A SHARED
BUFFER
MONITOR: BufferMonitor
const bufferSize = 100
buffer = array [0.. bufferSize-1]
next_in = 0, next_out = 0, filled = 0
procedure void deposit (item )
begin
while filled == bufferSize then
wait() // blocks thread in the monitor
end
buffer[next_in] = item
next_in = (next_in + 1) mod bufferSize
filled = filled + 1
signal() // free a task that has been waiting on a condition
end procedure
494
EXAMPLE: A SHARED
BUFFER
procedure Item fetch()
begin
while filled == 0 then
wait() // block thread in the monitor
end
item = buffer[next_out]
next_out = (next_out + 1) mod bufferSize
filled = filled – 1
signal() // free a task that has been waiting on a condition
return item
end procedure
495
EXAMPLE: A SHARED
BUFFER
PRODUCER
CONSUMER
Task Producer
Task Consumer
begin
begin
Loop Forever
Loop Forever
// produce new item
newItem = bufferMonitor.fetch()
…
// consume new item
bufferMonitor.deposit(newItem)
end
End Task
…
end
End Task
496
MESSAGE PASSING
Message passing means that one process sends a message
to another process and then continues its local processing
• The message may take some time to get to the other process
The message may be stored in the input queue of the
destination process
• If the latter is not immediately ready to receive the message
497
MESSAGE PASSING
The message is received by the destination process, when:
• The latter arrives at a point in its local processing where it is
ready to receive messages.
This is known as asynchronous message passing (because
sending and receiving is not at the same time)
E-mail communication is a form of message passing…
498
ASYNCHRONOUS
MESSAGE PASSING
Blocking send and receive operations:
• A receiver will be blocked if it arrives at the point where it may
receive messages and no message is waiting.
• A sender may get blocked if there is no room in the message queue
between the sender and the receiver
• However, in many cases, one assumes arbitrary long queues, which
means that the sender will almost never be blocked
499
ASYNCHRONOUS
MESSAGE PASSING
Non-blocking send and receive operations:
Send and receive operations always return immediately
They return a status value which could indicate that no message has
arrived at the receiver
The receiver may test whether a message is waiting and possibly do
some other processing.
500
SYNCHRONOUS MESSAGE
PASSING
One assumes that sending and receiving takes place at the
same time
• There is often no need for an intermediate buffer
This is also called rendezvous and implies closer
synchronization:
• The combined send-and-receive operation can only occur if
both parties are ready to do their part.
The sending process may have to wait for the receiving
process, or the receiving process may have to wait for the
sending one.
501
RENDEZVOUS
(NOT AS ROMANTIC AS IT SOUNDS!)
502
JAVA THREADS
503
MULTIPLE THREADS
A thread is a flow of execution, with a beginning and an end, of a task in a
program
With Java, multiple threads from a program can be launched concurrently
Multiple threads can be executed in multiprocessor systems, and singleprocessor systems
Multithreading can make program more responsive, interactive, as well as
enhance performance
504
THREAD STATES
505
CREATING THREADS
BY EXTENDING THE THREAD
CLASS
506
CREATING THREADS
BY IMPLEMENTING THE
RUNNABLE INTERFACE
507
THREAD GROUPS
A thread group is a set of threads
Some programs contain quite a few threads with similar
functionality
• We can group them together and perform operations in the
entire group
E.g., we can suspend or resume all of the threads in a group
at the same time.
508
USING THREAD GROUPS
Construct a thread group:
ThreadGroup g = new ThreadGroup(“thread
group”);
Place a thread in a thread group:
Thread t = new Thread(g, new
ThreadClass(),”this thread”);
Find out how many threads in a group are currently running:
System.out.println(“the number of runnable
threads in the group “ + g.activeCount());
Find which group a thread belongs to:
theGroup = myThread.getThreadGroup();
509
PRIORITIES
The priories of threads need not all be the same
The default thread priority is:
• NORM_PRIORITY(5)
The priority is an integer number between 1 and 10, where:
• MAX_PRIORITY(10)
• MIN_PRIORITY(1)
You can use:
• setPriority(int): change the priority of this thread
• getPriority(): return this thread’s priority
510
SECTION 16
JAVA CONCURRENCY
511
TOPICS
More on Java Threads Basics
• Sleep
• Join
• Interrupt
Java Semaphores
Java Intrinsic Locks
Monitors Implemented with Intrinsic Locks
Monitors Implemented with Lock and Condition Interfaces
Atomic Variables
512
JAVA THREAD BASICS
Making a thread sleep for a number of milliseconds
• Very popular with gaming applications (2D or 3D animation)
Thread.sleep(1000);
Thread.sleep(1000, 1000); (accuracy depends on
system)
• Notice that these methods are static
• They thrown an InterruptedException
513
JAVA THREAD BASICS
If you create several threads, each one is responsible for
some computations
You can wait for the threads to die
• Before putting together the results from these threads
To do that, we use the join method defined in the Thread
class
try {thread.join();}
catch (InterruptedException e){e.printStackTrace();}
Exception is thrown if another thread has interrupted the
current thread
514
JOIN EXAMPLE
public class JoinThread {
public static void main(String[] args) {
Thread thread2 = new Thread(new WaitRunnable());
Thread thread3 = new Thread(new WaitRunnable());
thread2.start();
try {thread2.join();} catch (InterruptedException e) {e.printStackTrace();}
thread3.start();
try {thread3.join(1000);} catch (InterruptedException e) {e.printStackTrace();}
}
}
515
JOIN EXAMPLE
public class WaitRunnable implements Runnable {
@Override
public void run() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
516
INTERRUPTING THREADS
In Java, you have no way to force a Thread to stop
• If the Thread is not correctly implemented, it can continue its
execution indefinitely (rogue thread!)
But you can interrupt a Thread with the interrupt()
method
• If the thread is sleeping or joining an other Thread, an
InterruptedException is thrown
• In this case, the interrupted status of the thread is cleared
517
INTERRUPT EXAMPLE
public class InterruptThread {
public static void main(String[] args) {
Thread thread1 = new Thread(new WaitRunnable());
thread1.start();
try {Thread.sleep(1000);}
catch (InterruptedException e){e.printStackTrace();}
thread1.interrupt();
}
518
INTERRUPT EXAMPLE
private static class WaitRunnable implements Runnable {
@Override
public void run() {
System.out.println("Current time millis: " + System.currentTimeMillis());
try {Thread.sleep(5000);}
catch (InterruptedException e) {
System.out.println("The thread has been interrupted");
System.out.println("The thread is interrupted: "+Thread.currentThread().isInterrupted());
}
System.out.println("Current time millis: " + System.currentTimeMillis());
}
}
Sample Output:
Current time millis : 1274017633151
The thread has been interrupted
The thread is interrupted : false
Current time millis : 1274017634151
519
JAVA SEMAPHORES
Java defines a semaphore class:
java.util.concurrent.Semaphore
Creating a counting semaphore:
Semaphore available = new Semaphore(100);
Creating a binary semaphore:
Semaphore available = new Semaphore(1);
We will later implement our own Sempahore class
520
SEMAPHORE EXAMPLE
public class Example {
private int counter= 0;
private final Semaphore mutex = new Semaphore(1)
public int getNextCount() throws InterruptedException {
try {
mutex.acquire();
return ++counter;
} finally {
mutex.release();
}
}
}
521
QUESTION??
Why do we need the try-finally construct in
the previous example?
522
INTRINSIC LOCKS
Any piece of code that can be simultaneously modified by several
threads must be made Thread Safe
Consider the following simple piece of code:
public int getNextCount(){
return ++counter;
}
An increment like this, is not an atomic action, it involves:
• Reading the current value of counter
• Adding one to its current value
• Storing the result back to memory
523
INTRINSIC LOCKS
If you have two threads invoking getNextCount(), the following
sequence of events might occur (among many possible scenarios):
1
Thread 1 : reads counter, gets 0, adds 1, so counter = 1
2
Thread 2 : reads counter, gets 0, adds 1, so counter = 1
3
Thread 1 : writes 1 to the counter field and returns 1
4
Thread 2 : writes 1 to the counter field and returns 1
Therefore, we must use a lock on access to the “value”
You can add such lock to a method by simply using the keyword:
synchronized
public synchronized int getNextCount(){
return ++counter;
}
This guarantees that only one thread executes the method
If you have several methods with the synchronized keyword, only
one method can be executed at a time
• This is called an Intrinsic Lock
524
INTRINSIC LOCKS
Each Java object has an intrinsic lock associated with it (sometimes
simply referred to as monitor)
In the last example, we used that lock to synch access to a method
• But instead, we can elect to synch access to a block (or segment) of
code
public int getNextValue() {
synchronized (this) {return value++;}
}
• Or alternatively, use the lock of another object
public int getNextValue() {
synchronized (lock) {return value++;}
}
• The latter is useful since it allows you to use several locks for thread
safety in a single class
525
INTRINSIC LOCKS
So we mentioned that each Java object has an intrinsic lock
associated with it
What about static methods that are not associated with a
particular object?
• There is also an intrinsic lock associated with the class
• Only used for synchronized class (static) methods
526
JAVA MONITORS
Bad news: In Java, there is no keyword to directly create a
monitor
Good news: there are several mechanisms to create monitors
• The simplest one, uses the knowledge that we have already
gathered regarding the intrinsic locks
527
JAVA MONITORS
The intrinsic locks can be effectively used for mutual
exclusion (competition synchronization)
We need a mechanism to implement cooperation
synchronization
• In particular, we need to allow threads to suspend themselves
if a condition prevents their execution in a monitor
• This is handled by the wait() and notify() methods
These two methods are so important, they have been defined
in the Object class…
528
“WAIT” OPERATIONS
wait()
Tells the calling thread to give up the monitor and wait until some other
thread enters the same monitor and calls notify()or notifyAll()
wait(long timeout)
Causes the current thread to wait until another thread invokes the
notify() or notifyAll() method, or the specified amount of time
elapses
529
“NOTIFY” OPERATIONS
notify()
Wakes up a single thread that is waiting on this object's monitor (intrinsic
lock). If more than a single thread is waiting, the choice is arbitrary (is this
fair?)
The awakened thread will not be able to proceed until the current thread
relinquishes the lock.
notifyAll()
Wakes up all threads that are waiting on this object’s monitor.
The awakened thread will not be able to proceed until the current thread
relinquishes the lock.
The next thread to lock this monitor is also randomly chosen
530
INTRINSIC LOCK BASED
MONITOR EXAMPLE
public class BufferMonitor{
int [] buffer = new int [100];
int next_in = 0, next_out = 0, filled = 0;
public synchronized void deposit (int item ) throws InterruptedException{
while (buffer.length == filled){
wait(); // blocks thread
}
buffer[next_in] = item;
next_in = (next_in + 1) % buffer.length;
filled++;
notify(); // free a task that has been waiting on a condition
}
531
INTRINSIC LOCK BASED
MONITOR EXAMPLE
public synchronized int fetch() throws InterruptedException{
while (filled == 0){
wait(); // block thread
}
int item = buffer[next_out];
next_out = (next_out + 1) % buffer.length;
filled--;
notify(); // free a task that has been waiting on a condition
return item;
}
}
532
SEMAPHORE EXERCISE
Although a Semaphore class is included in the standard Java
library, nonetheless, with the knowledge you can accumulated so
far,
can you create a Counting Semaphore class using
Intrinsic Locks?
533
SEMAPHORE EXERCISE
public class Semaphore{
private int value;
public Semaphore () {
value = 0;
}
public synchronized void v(){
public synchronized void p(){
++value;
while (value <=0){
notify();
try {
wait();
}
}
}
catch (InterruptedException e){}
}
value--;
}
534
ANOTHER MECHANISM TO
CREATE MONITORS
You can also create a monitor using the Java Lock interface
• ReentrantLock is the most popular implementation of Lock
ReentrantLock defines two constructors:
• Default constructor
• Constructor that takes a Boolean (specifying if the lock is fair)
In a fair lock scheme, the threads will get access to the lock
in the same order they requested it (FIFO)
• Otherwise, the lock does not guarantee any particular order
• Fairness is a slightly heavy (in terms of processing), and
therefore should be used only when needed
To acquire the lock, you just have to use the method lock,
and to release it, call unlock
535
“LOCK” EXAMPLE
public class SimpleMonitor {
private final Lock lock = new ReentrantLock();
public void testA() {
lock.lock();
try {//Some code}
finally {lock.unlock();}
}
public int testB() {
lock.lock();
try {return 1;}
finally {lock.unlock();}
}
}
536
ANOTHER MECHANISM TO
CREATE MONITORS
What about conditions?
• Without being able to wait on a condition, monitors are
useless…
• Cooperation is not possible
There is a specific class that has been developed just to this
end: Condition class
• You create a Condition instance using the
newCondition() method defined in the Lock interface
537
BUFFER MONITOR
EXAMPLE (AGAIN)
public class BufferMonitor {
int [] buffer = new int [100];
int next_in = 0, next_out = 0, filled = 0;
private final Lock lock = new ReentrantLock();
private final Condition notFull = lock.newCondition();
private final Condition notEmpty = lock.newCondition();
538
BUFFER MONITOR
EXAMPLE (AGAIN)
public void deposit (int item ) throws InterruptedException{
lock.lock(); // Lock to ensure mutually exclusive access
try{
while (buffer.length == filled){
notFull.await(); // blocks thread (wait on condition)
}
buffer[next_in] = item;
next_in = (next_in + 1) % buffer.length;
filled++;
notEmpty.signal(); // signal thread waiting on the empty condition
}
finally{
lock.unlock();// Whenever you lock, you must unlock
}
}
539
BUFFER MONITOR
EXAMPLE (AGAIN)
public void fetch () throws InterruptedException{
lock.lock(); // Lock to ensure mutually exclusive access
try{
while (filled == 0){
notEmpty.await(); // blocks thread (wait on condition)
}
int item = buffer[next_out];
next_out = (next_out + 1) % buffer.length;
filled--;
notFull.signal(); // signal thread waiting on the full condition
}
finally{
lock.unlock();// Whenever you lock, you must unlock
}
return item;
}
}
540
“LOCK” VS
“SYNCHRONIZED”
Monitors implemented with Lock and Condition classes have
some advantages over the “synchronized” based implementation:
1. Ability to have more than one condition variable per monitor (see
previous example)
2. Ability to make the lock fair (remember, synchronized blocks or
methods do not guarantee fairness)
3. Ability to check if the lock is currently being held (by calling the
isLocked()method)
• Alternatively, you can call tryLock() which acquires the
lock only if it is not held by another thread
4. Ability to get the list of threads waiting on the lock (by calling the
method getQueuedThreads())
The above list is not exhaustive…
541
“LOCK” VS
“SYNCHRONIZED”
Disadvantages of Lock and Condition :
1. Need to add lock acquisition and release code
2. Need to add try-finally block
542
ATOMIC VARIABLES
In case you require synch for only a variable in your class,
you can use an atomic class to make it thread safe:
•
•
•
•
AtomicInteger
AtomicLong
AtomicBoolean
AtomicReference
These classes make use of low level hardware mechanisms
to ensure synchronization
• This results in better performance
543
ATOMIC VARIABLES
EXAMPLE
public class AtomicCounter {
private final AtomicInteger value = new AtomicInteger(0);
public int getValue(){
return value.get();
}
public int getNextValue(){
return value.incrementAndGet();
}
public int getPreviousValue(){
return value.decrementAndGet();
}
}
Other possible operations:
getAndIncrement(), getAndAdd(int i), addAndGet()…
544
ANOTHER ATOMIC
VARIABLE EXAMPLE
public class Stack {
private final AtomicReference<Element> head = new AtomicReference<Element>(null);
public void push(String value){
Element newElement = new Element(value);
while(true){
Element oldHead = head.get();
newElement.next = oldHead;
//Trying to set the new element as the head
if(head.compareAndSet(oldHead, newElement)){
return;
}
}
}
545
ANOTHER ATOMIC
VARIABLE EXAMPLE
public String pop(){
while(true){
Element oldHead = head.get();
//The stack is empty
if(oldHead == null){
return null;
}
Element newHead = oldHead.next;
//Trying to set the new element as the head
if(head.compareAndSet(oldHead, newHead)){
return oldHead.value;
}
}
}
}
546
SECTION 17
PROCESS SCHEDULING
547
TOPICS
CPU Scheduling
First Come First Serve (FCFS) Scheduling
Round Robin (RR) Scheduling
FCFS vs RR
548
CPU SCHEDULING
How does the OS decide which of several tasks to take off a
queue?
Scheduling: deciding which threads are given access to
resources from moment to moment.
549
ASSUMPTIONS ABOUT
SCHEDULING
CPU scheduling big area of research in early ‘70s
Many implicit assumptions for CPU scheduling:
• One program per user
• One thread per program
• Programs are independent
These are unrealistic but simplify the problem
Does “fair” mean fairness among users or programs?
• If I run one compilation job and you run five, do you get five times as
much CPU?
• Often times, yes!
Goal: distribute CPU time to optimize some desired parameters of
the system
• What parameters?
550
ASSUMPTION: CPU
BURSTS
551
ASSUMPTION: CPU
BURSTS
Execution model: programs alternate between bursts of CPU and I/O
• Program typically uses the CPU for some period of time, then does I/O, then
uses CPU again
• Each scheduling decision is about which job to give to the CPU for use by its
next CPU burst
• With time slicing, thread may be forced to give up CPU before finishing
current CPU burst.
552
WHAT IS IMPORTANT IN A
SCHEDULING ALGORITHM?
553
WHAT IS IMPORTANT IN A
SCHEDULING ALGORITHM?
Minimize Response Time
• Elapsed time to do an operation (job)
• Response time is what the user sees
• Time to echo keystroke in editor
• Time to compile a program
• Real-time Tasks: Must meet deadlines imposed by World
554
WHAT IS IMPORTANT IN A
SCHEDULING ALGORITHM?
Maximize Throughput
• Jobs per second
• Throughput related to response time, but not identical
• Minimizing response time will lead to more context switching
than if you maximized only throughput
• Minimize overhead (context switch time) as well as efficient
use of resources (CPU, disk, memory, etc.)
555
WHAT IS IMPORTANT IN A
SCHEDULING ALGORITHM?
Fairness
• Share CPU among users in some equitable way
• Not just minimizing average response time
556
SCHEDULING ALGORITHMS:
FIRST-COME, FIRST-SERVED
(FCFS)
“Run until Done:” FIFO algorithm
In the beginning, this meant one program runs nonpreemtively until it is finished (including any blocking for I/O
operations)
Now, FCFS means that a process keeps the CPU until one or
more threads block
Example: Three processes arrive in order P1, P2, P3.
• P1 burst time: 24
• P2 burst time: 3
• P3 burst time: 3
Draw the Gantt Chart and compute Average Waiting Time and
Average Completion Time.
557
SCHEDULING ALGORITHMS:
FIRST-COME, FIRST-SERVED
(FCFS)
Example: Three processes arrive in order P1, P2, P3.
• P1 burst time: 24
• P2 burst time: 3
• P3 burst time: 3
Waiting Time
P1
0
P2 P3
24
27
30
• P1: 0
• P2: 24
• P3: 27
Completion Time:
• P1: 24
• P2: 27
• P3: 30
Average Waiting Time: (0+24+27)/3 = 17
Average Completion Time: (24+27+30)/3 = 27
558
SCHEDULING ALGORITHMS:
FIRST-COME, FIRST-SERVED
(FCFS)
What if their order had been P2, P3, P1?
• P1 burst time: 24
• P2 burst time: 3
• P3 burst time: 3
559
SCHEDULING ALGORITHMS:
FIRST-COME, FIRST-SERVED
(FCFS)
What if their order had been P2, P3, P1?
• P1 burst time: 24
• P2 burst time: 3
• P3 burst time: 3
Waiting Time
P2 P3 P1
0
3
6
30
• P2: 0
• P3: 3
• P1: 6
Completion Time:
• P2: 3
• P3: 6
• P1: 30
Average Waiting Time: (0+3+6)/3 = 3 (compared to 17)
Average Completion Time: (3+6+30)/3 = 13 (compared to 27)
560
SCHEDULING ALGORITHMS:
FIRST-COME, FIRST-SERVED
(FCFS)
Average Waiting Time: (0+3+6)/3 = 3 (compared to 17)
Average Completion Time: (3+6+30)/3 = 13 (compared to 27)
FCFS Pros and Cons:
• Simple (+)
• Short jobs get stuck behind long ones (-)
• If all you’re buying is milk, doesn’t it always seem like you are
stuck behind a cart full of many items
• Performance is highly dependent on the order in which jobs
arrive (-)
561
HOW CAN WE IMPROVE ON
THIS?
562
ROUND ROBIN (RR)
SCHEDULING
FCFS Scheme: Potentially bad for short jobs!
• Depends on submit order
• If you are first in line at the supermarket with milk, you don’t care
who is behind you; on the other hand…
Round Robin Scheme
• Each process gets a small unit of CPU time (time quantum)
• Usually 10-100 ms
• After quantum expires, the process is preempted and added to the
end of the ready queue
• Suppose N processes in ready queue and time quantum is Q ms:
• Each process gets 1/N of the CPU time
• In chunks of at most Q ms
• What is the maximum wait time for each process
• No process waits more than (N-1)Q time units
563
ROUND ROBIN (RR)
SCHEDULING
Performance Depends on Size of Q
• Small Q => interleaved
• Large Q is like FCFS
• Q must be large with respect to context switch time,
otherwise overhead is too high
• Spending most of your time context switching!
564
EXAMPLE OF RR WITH
TIME QUANTUM = 4
Process Burst Time
P1
24
P2
3
P3
3
The Gantt chart is:
P1
0
P2
4
P3
7
P1
10
P1
P1
14 18 22
P1
P1
26 30
565
EXAMPLE OF RR WITH
TIME QUANTUM = 4
Process
Burst Time
P1
24
P2
3
P3
3
Waiting Time:
• P1: (10-4) = 6
• P2: (4-0) = 4
• P3: (7-0) = 7
Completion Time:
P1
0
P2
4
P3
7
P1
10
P1
14
P1
18 22
P1
P1
26
30
• P1: 30
• P2: 7
• P3: 10
Average Waiting Time: (6 + 4 + 7)/3= 5.67
Average Completion Time: (30+7+10)/3=15.67
566
TURNAROUND TIME VARIES WITH
THE TIME QUANTUM
567
EXAMPLE OF RR WITH
TIME QUANTUM = 20
Process
Burst Time
P1
53
P2
8
P3
68
P4
24
568
EXAMPLE OF RR WITH
TIME QUANTUM = 20
Waiting Time:
•
•
•
•
P1: (68-20)+(112-88) = 72
P2: (20-0) = 20
P3: (28-0)+(88-48)+(125-108) = 85
P4: (48-0)+(108-68) = 88
Process
Burst Time
P1
53
P2
8
P3
68
P4
24
Completion Time:
•
•
•
•
P1: 125
P2: 28
P3: 153
P4: 112
Average Waiting Time: (72+20+85+88)/4 = 66.25
Average Completion Time: (125+28+153+112)/4 = 104.5
569
RR SUMMARY
Pros and Cons:
• Better for short jobs (+)
• Fair (+)
• Context-switching time adds up for long jobs (-)
• The previous examples assumed no additional time was
needed for context switching – in reality, this would add to
wait and completion time without actually progressing a
process towards completion.
• Remember: the OS consumes resources, too!
If the chosen quantum is
• too large, response time suffers
• infinite, performance is the same as FCFS
• too small, throughput suffers and percentage overhead grows
570
RR SUMMARY
Actual choices of timeslice:
• UNIX: initially 1 second:
• If there were 3 compilations going on, it took 3
seconds to echo each keystroke!
• In practice, need to balance short-job
performance and long-job throughput:
• Typical timeslice 10ms-100ms
• Typical context-switch overhead 0.1ms – 1ms (about 1%)
571
COMPARING FCFS AND RR
Assuming zero-cost context
switching time, is RR always
better than FCFS?
Assume 10 jobs, all start at the
same time, and each require
100 seconds of CPU time
RR scheduler quantum of 1
second
Job #
FCFS CT
RR CT
1
100
991
2
200
992
…
…
…
9
900
999
10
1000
1000
Completion Times (CT)
• Both FCFS and RR finish at the same time
• But average response time is much worse under RR!
• Bad when all jobs are same length
• Total time for RR longer even for zero-cost context switch!
572
POTENTIAL LAST
LECTURE TOPICS
We will vote on one or more of these topics to cover:
• Agile programing (especially SCRUM)
• Mobile programing (mostly Android)
• Web services
• J2EE major components
• Spring framework
• Cover more material about scheduling
• Other suggestions…
Or:
• None, too overwhelmed with projects and assignments
573
SECTION 18
WEB SERVICES
574
TOPICS
Dreams of a Programmer
What is a Web Service
How to Create a Web Service
How to Call a Web Service
WSDL and SOAP
Why are Web Services Important
575
DREAMS OF A
PROGRAMMER
What if there was a way I can call code residing on a different
computer…
What if that code was written in a different programing
language, yet I can still invoke it…
• There must be a common language that everybody can
understand
Wouldn't the world be a better place
• Probably not, it just would make it easier to build complex
interconnected systems
We can achieve all of that and more with Web Services
576
WHAT IS A WEB SERVICE ?
Web service is a means by which computers talk to each
other over the web
• Using HTTP and other universally supported protocols
A Web service is an application that:
• Runs on a Web server
• Exposes Web methods to interested callers
• Listens for HTTP requests representing commands to invoke
Web methods
• Executes Web methods and returns the results
577
WHAT IS A WEB SERVICE ?
Web Service Components
• WSDL (Web Services Description Language): a document
describing the service that can be rendered by a web service
• SOAP (Simple Object Access Protocol): a protocol used for
interaction between the web service and other systems
Therefore, any system that wants to call a Web Service, must
acquire the WSDL describing the latter service
• Using that description, relevant SOAP messages can be
exchanged
Both WSDL and SOAP are XML Based
578
CREATING AND USING
WEB SERVICES
If you are the Web Service Provider:
• Use tools (look up JBossWS) to generate a WSDL file out of a
Java interface
• Generate Server Stubs to handle SOAP requests for you
• Publish the WSDL file so that potential clients can download it
and used to call your service
If you are a Web Service Client
• Download WSDL file from provider’s public server
• Generate Client Stubs to handle SOAP requests for you
• Generated stubs contain an interface that matches the
interface on which the WSDL was based
• This way you can call the remote functions defined on the
server as if you are performing a local call
579
HIGH LEVEL PERSPECTIVE
Client Stubs
Client Stubs
WSDL
Client code that generates SOAP requests and
interprets SOAP responses sent by the server
Server Stubs
Server Stubs
Server code that interprets SOAP requests and set by
the client and generates SOAP responses
580
HIGH LEVEL PERSPECTIVE
Client
Client
Program
Internet
Client
Stubs
Server
Server
Stubs
Web Service
Implementation
581
WEB SERVICE CALL
Execute Client Code
Client Needs To Invoke Remote
Service
Server Waiting for Requests
Call the Local Stub Interface
Stub Generates Appropriate SOAP
MSG to Match Call
Time
Stub Sends SOAP MSG over HTTP
SOAP Message Received
Stub Translates SOAP Call Into
Local Call
Client Waits for Response
Server Executes Relevant Operation
and Generates Results
Results are Taken by Stub and
Inserted into Response Soap MSG
Stub Sends SOAP MSG over HTTP
SOAP Message Received
Stub Translates SOAP MSG into
Return Value of Original Call
582
IDEAL WORLD SCENARIO:
DISCOVERY SERVICE
Web Services standards were initially accompanied with
grand plans regarding service discovery:
• A client may have no prior knowledge of what Web Service
it is going to invoke
• So therefore, it needs to discover a Web Service that
meets the requirements it needs to accomplish
•
Example: locate a Web Service that can supply me with
the weather forecast for different Canadian cities
• Therefore, a discovery service is required
583
DISCOVERY SERVICE
Conversation Between Servers
(based on a true story):
Server A
Discovery
Service
Server B: Hey Server A, I just started providing a
new service
Server A: Send me a listing, I’ll post it publicly
Server B: Here’s my listing: “Server B now
provides weather inquiry services”
Server B
Web
Service
Server A: Confirmed, I just posted it
584
DISCOVERY SERVICE
Server A
Where can I find a
“Weather Service”?
There’s a good “Weather
Service” on Server B
Discovery
Service
Server B
Client
How exactly can I
use your services
Take a look at this
WSDL
SOAP request:
getWeatherInfo(“Ottawa”)
Web
Service
SOAP response:
“Freezing”
585
DISCOVERY SERVICE
Universal Description, Discovery and Integration (UDDI):
registry by which businesses worldwide can list themselves
on the Internet
• Allows clients to locate relevant Service Providers
UDDI has not been as widely adopted as its designers had
hoped
Nonetheless, you can still find UDDI servers within the
confines of a company
• Definitely on a smaller scale than the grand future imagined
for this service
586
WSDL
How can a WSDL document describe a
service?
Let’s look at a sample…
587
SAMPLE WSDL
<definitions name="HelloService"
targetNamespace="http://www.examples.com/wsdl/HelloService.wsdl"
xmlns="http://schemas.xmlsoap.org/wsdl/"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:tns="http://www.examples.com/wsdl/HelloService.wsdl"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<message name="SayHelloRequest">
<part name="firstName" type="xsd:string"/>
</message>
<message name="SayHelloResponse">
<part name="greeting" type="xsd:string"/>
</message>
<portType name="Hello_PortType">
<operation name="sayHello">
<input message="tns:SayHelloRequest"/>
<output message="tns:SayHelloResponse"/>
</operation>
</portType>
588
SAMPLE WSDL
<definitions name="HelloService"
targetNamespace="http://www.examples.com/wsdl/HelloService.wsdl"
xmlns="http://schemas.xmlsoap.org/wsdl/"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:tns="http://www.examples.com/wsdl/HelloService.wsdl"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
URL where the .WSDL
file can be obtained
<message name="SayHelloRequest">
<part name="firstName" type="xsd:string"/>
</message>
<message name="SayHelloResponse">
<part name="greeting" type="xsd:string"/>
</message>
<portType name="Hello_PortType">
<operation name="sayHello">
<input message="tns:SayHelloRequest"/>
<output message="tns:SayHelloResponse"/>
</operation>
</portType>
589
SAMPLE WSDL
<definitions name="HelloService"
targetNamespace="http://www.examples.com/wsdl/HelloService.wsdl"
xmlns="http://schemas.xmlsoap.org/wsdl/"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:tns="http://www.examples.com/wsdl/HelloService.wsdl"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
Reference to the WSDL
and SOAP schemas
(standard XML stuff…)
<message name="SayHelloRequest">
<part name="firstName" type="xsd:string"/>
</message>
<message name="SayHelloResponse">
<part name="greeting" type="xsd:string"/>
</message>
<portType name="Hello_PortType">
<operation name="sayHello">
<input message="tns:SayHelloRequest"/>
<output message="tns:SayHelloResponse"/>
</operation>
</portType>
590
SAMPLE WSDL
<definitions name="HelloService"
targetNamespace="http://www.examples.com/wsdl/HelloService.wsdl"
xmlns="http://schemas.xmlsoap.org/wsdl/"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:tns="http://www.examples.com/wsdl/HelloService.wsdl"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<message name="SayHelloRequest">
<part name="firstName" type="xsd:string"/>
</message>
<message name="SayHelloResponse">
<part name="greeting" type="xsd:string"/>
</message>
<portType name="Hello_PortType">
<operation name="sayHello">
<input message="tns:SayHelloRequest"/>
<output message="tns:SayHelloResponse"/>
</operation>
</portType>
Describes the data being exchanged between
the Web service providers and consumers
Two message elements are defined.
The first represents a request message:
SayHelloRequest
The second represents a response message:
SayHelloResponse
591
SAMPLE WSDL
<definitions name="HelloService"
targetNamespace="http://www.examples.com/wsdl/HelloService.wsdl"
xmlns="http://schemas.xmlsoap.org/wsdl/"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:tns="http://www.examples.com/wsdl/HelloService.wsdl"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<message name="SayHelloRequest">
<part name="firstName" type="xsd:string"/>
</message>
<message name="SayHelloResponse">
<part name="greeting" type="xsd:string"/>
</message>
<portType name="Hello_PortType">
<operation name="sayHello">
<input message="tns:SayHelloRequest"/>
<output message="tns:SayHelloResponse"/>
</operation>
</portType>
<portType> can combine one request and one response
message into a single request/response operation
sayHello operation consists of a request and
response service
592
SAMPLE WSDL
<binding name="Hello_Binding" type="tns:Hello_PortType">
<soap:binding style="rpc"
transport="http://schemas.xmlsoap.org/soap/http"/>
<operation name="sayHello">
<soap:operation soapAction="sayHello"/>
<input>
<soap:body
encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
namespace="urn:examples:helloservice"
use="encoded"/>
</input>
<output>
<soap:body
encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
namespace="urn:examples:helloservice"
use="encoded"/>
</output>
</operation>
</binding>
<binding> provides specific details on
how a portType operation will actually be
transmitted
Provides info. about what protocol is
being used to transfer portType
operations (HTTP here)
593
SAMPLE WSDL
<binding name="Hello_Binding" type="tns:Hello_PortType">
<soap:binding style="rpc"
transport="http://schemas.xmlsoap.org/soap/http"/>
<operation name="sayHello">
<soap:operation soapAction="sayHello"/>
<input>
<soap:body
encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
namespace="urn:examples:helloservice"
use="encoded"/>
</input>
<output>
<soap:body
encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
namespace="urn:examples:helloservice"
use="encoded"/>
</output>
</operation>
</binding>
Information about the
SOAP messages that
will be exchanged
There are the more interesting components, there are few more…
594
SOAP MESSAGE
POST /InStock HTTP/1.1
Host: www.example.org
Content-Type: application/soap+xml;
charset=utf-8
Content-Length: 299
SOAPAction:
"http://www.w3.org/2003/05/soap-envelope"
<?xml version="1.0"?>
<soap:Envelope
xmlns:soap="http://www.w3.org/2003/05/so
ap-envelope">
<soap:Header> </soap:Header>
<soap:Body>
<m:GetStockPrice
xmlns:m="http://www.example.org/stock">
<m:StockName>IBM</m:StockName>
</m:GetStockPrice>
</soap:Body>
</soap:Envelope>
595
WHY IS IT SO USEFUL?
Pay Pal
Web Service
Warehouse
Web Service
Done
Charge Card
Credit Check
Web Service
Online
Electronics
Store
Currency
Conversion
Web Service
Shipping
Web Service
Buy
Laptop
Purchase
Confirmed
Client
596
WHY IS IT SO USEFUL?
The latter example is called Service Oriented Architecture:
SOA (buzzword)
Refers simply to a software architecture based on discrete
pieces of software that provide services to other applications
• Vendor, product and technology independent
597
WHY IS IT SO USEFUL?
Another example inspired from real life:
Canada Revenue Agency
Server
Shared Services
Canada
They need
to talk!!!
Remote Modern
Client
Old FORTRAN Code
(AKA the untouchable)
598
WHY IS IT SO USEFUL?
Another example inspired from real life:
SOAP
Remote Modern
Client
We Service Layer
Canada Revenue Agency
Server
Shared Services
Canada
Old FORTRAN Code
(AKA the untouchable)
599
THANK YOU!
QUESTIONS?
600