Document
advertisement

AUTOMATA & COMPILER DESIGN [IT-713]
Sem. VII
Examination, Dec.2014
Unit I
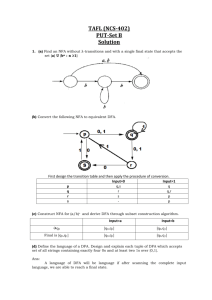
1.a)Explain the equivalence of NFA and DFA with suitable example.
Ans. For every non-deterministic finite automata, there exists an equivalent deterministic finite
automata. The equivalence between the two is defined in terms of language acceptance. Since an
NFA is a nothing more than a finite automata in which zero, one, or more transitions on an input
symbol is permitted, we can always construct a finite automata that will simulate all the moves
of the NFA on a particular input symbol in parallel. We then get a finite automata in which there
will be exactly one transition on an input symbol; hence, it will be a DFA equivalent to the NFA.
Since the DFA equivalent of the NFA parallels the moves of the NFA, every state of a DFA will
be a combination of one or more states of the NFA. Hence, every state of a DFA will be
represented by some subset of the set of states of the NFA; and therefore, the transformation
from NFA to DFA is normally called the "construction" subset. Therefore, if a given NFA has n
states, then the equivalent DFA will have 2n number of states, with the initial state
corresponding to the subset {q0}. Therefore, the transformation from NFA to DFA involves
finding all possible subsets of the set states of the NFA, considering each subset to be a state of a
DFA, and then finding the transition from it on every input symbol. But all the states of a DFA
obtained in this way might not be reachable from the initial state; and if a state is not reachable
from the initial state on any possible input sequence, then such a state does not play role in
deciding what language is accepted by the DFA. Hence, the amount of work involved in
transforming an NFA to a DFA can be reduced if we attempt to generate only reachable states of
a DFA. This can be done by proceeding as follows:
Let M = (Q, S, d, q0, F) be an NFA to be transformed into a DFA.
Let Q1 be the set states of equivalent DFA.
begin:
Q1old = F
Q1new = {q0}
While (Q1old Q1new)
{
Temp = Q1new - Q1old
Q1 = Q1new
for every subset P in Temp do
for every a in Sdo
If transition from P on a goes to new subset S of Q
then
(transition from P on a is obtained by finding out
the transitions from every member of P on a in a given
NFA
and then taking the union of all such transitions)
Q1 new = Q1 new È S
}
Q1 = Q1new
end
A subset P in Ql will be a final state of the DFA if P contains at least one member of F of the
NFA. For example,consider the following finite automata:
M= ({q0,q1,q2,q3},{0,1},δ, q0,{ q3})
where:
δ(q0,0) = { q1} δ(q0,1) = Φ
δ(q1,0) = { q1} δ(q0,1) = {q1,q2}
δ(q0,0) = Φ
δ(q0,1) = { q3}
δ(q0,0) = { q3} δ(q0,1) = { q3}
The DFA equivalent of this NFA can be obtained as follows:
{q0)
{q1}
{q1, q2}
*{q1, q2, q3}
*{q1, q3}
0
{q1}
{q1}
{q1}
{q1, q3}
{q1, q3}
1
{q1, q2}
{q1, q2, q3}
{q1, q2, q3}
{q1, q2, q3}
The transition diagram associated with this DFA is shown in Fig.
Figure. Transition diagram for M = ({q0, q1, q2, q3}, {0, 1} d, q0, {q3}).
(b)Give the minimized DFA for the following expression (a/a)*abb.
2. a) Explain Arden’s theorem?
Ans.2 a) Arden’s theorem: for every regular expression there exist a deterministic finite
automation. So we can say that regular languages, regular expressions and finite automata are all
different representation of the same thing. To convert a regular expression into a finite
automation; first know about Arden’s Theorem.
Statement: Let P and Q be two Regular Expression s over Σ. If P does not contain Λ, then for the
equation R = Q + RP has a unique (one and only one) solution R = QP*.
Proof: Now point out the statements in Arden's Theorem in General form.
(i) P and Q are two Regular Expressions.
(ii) P does not contain Λ symbol.
(iii) R = Q + RP has a solution, i.e. R = QP*
(iv) This solution is the one and only one solution of the equation.
If R = QP* is a solution of the equation R = Q + RP then by putting the value of R in the
equation we shall get the value ‘0’.
R=Q+RP
R-Q-RP=0
LHS
R-Q-RP
(Putting the value of R in the LHS we get)
QP*-Q-Q-P*P
=QP*-Q(^ +*PP)
=QP*-QP* =0
So from here it is proved that R = QP* is a solution of the equation R = Q + RP.
2.b) What is regular expression? State the rules, which define regular expression?
Ans.2 b) A regular expression is a notation to specify a regular set. Hence, for every regular
expression, there exists finite automata that accepts the language specified by the regular
expression. Similarly, for every finite automata M, there exists a regular expression notation
specifying L(M). Regular expressions and the regular sets they specify are shown in the
following table.
Hence, we only have three regular-expression operators: | or + to denote union operations,. for
concatenation operations, and * for closure operations. The precedence of the operators in the
decreasing order is: *, followed by., followed by | .
Unit-II
3. What is compiler? State various phases of a compiler and explain them in detail.
Ans. A compiler translates or compiles a program written in a high-level programming language
that is suitable for human programmers into the low-level machine language that is required by
computers. So, a compiler is basically a translator whose source language is a high-level
programming language i.e. a problem-oriented language target language is a machine language
or assembly language i.e. a machine-oriented language.
Compilation refers to the compiler's process of translating a high-level language program into a
low-level language program. This process is very complex; hence, from the logical as well as an
implementation point of view, it is customary to partition the compilation process into several
phases.
The two parts of compilation are:
1. Analysis
2. Synthesis
The analysis part breaks up the source program into constituent pieces and creates an
intermediate representation of the source program.
The synthesis part constructs the desired target program from the intermediate representation.
A typical compilation, broken down into phases, is shown in Fig.
Fig. Compiler Phases
The first three phases, forms the bulk of the analysis portion of a compiler. Symbol table
management and error handling, are shown interacting with the six phases.
The following are the various phases of a compiler:
1. Lexical Analyzer: This is the initial part of reading and analyzing the program text: The
text is read and divided into tokens, each of which corresponds to a symbol in the
programming language, e.g., a variable name, keyword or number.
2. Syntax Analyzer: This phase takes the list of tokens produced by the lexical analysis and
arranges these in a tree-structure (called the syntax tree) that reflects the structure of the
program. This phase is often called parsing.
3. Semantic Analyzer: This phase analyses the syntax tree to determine if the program
violates certain consistency requirements, e.g., if a variable is used but not declared or if
it is used in a context that doesn’t make sense given the type of the variable, such as
trying to use a boolean value as a function pointer.
4. Intermediate code generation: The program is translated to a simple machine independent
intermediate language. After syntax and semantic analysis, some compilers generate an
explicit intermediate representation of the source program. This intermediate
representation can have a variety of forms.
In three-address code, the source pgm might look like this,
temp1: = inttoreal (10)
temp2: = id3 * temp1
temp3: = id2 + temp2
id1: = temp3
5. Code optimizion: An optimizer reviews the code, looking for ways to reduce the number
of operations and the memory requirements. The code optimization phase attempts to
improve the intermediate code, so that faster running machine codes will result. Some
optimizations are trivial. There is a great variation in the amount of code optimization
different compilers perform. In those that do the most, called ‘optimizing compilers’, a
significant fraction of the time of the compiler is spent on this phase.
6. Code Generation: The final phase of the compiler is the generation of target code,
consisting normally of relocatable machine code or assembly code. Memory locations are
selected for each of the variables used by the program. Then, intermediate instructions
are each translated into a sequence of machine instructions that perform the same task. A
crucial aspect is the assignment of variables to registers. It produces either
Machine code for a specific machine or
Assembly code for a specific machine and assembler.
Symbol table management
An essential function of a compiler is to record the identifiers used in the source program and
collect information about various attributes of each identifier. A symbol table is a data structure
containing a record for each identifier, with fields for the attributes of the identifier. The data
structure allows us to find the record for each identifier quickly and to store or retrieve data from
that record quickly. When an identifier in the source program is detected by the lex analyzer, the
identifier is entered into the symbol table.
Error Detection and Reporting
Each phase can encounter errors. A compiler that stops when it finds the first error is not as
helpful as it could be. The syntax and semantic analysis phases usually handle a large fraction of
the errors detectable by the compiler. The lexical phase can detect errors where the characters
remaining in the input do not form any token of the language. Errors when the token stream
violates the syntax of the language are determined by the syntax analysis phase. During semantic
analysis the compiler tries to detect constructs that have the right syntactic structure but no
meaning to the operation involved.
4.a) Construct the predictive parser for the following grammar:
S→ (L) | a
L→ L,S | S
Ans. To built predictive parser follows the below steps:
1. Remove left recursion if present.
2. Remove left factoring if present.
3. Find the FIRST AND FOLLOW for each grammer.
4. Construct the predictive parsing table.
Step 1. Remove left recursion which is present in L.
L→ L,S | S
L→SL’
L’→ ,SL’ | ε
Step 2. No left factoring is present.
Step 3. Find the FIRST AND FOLLOW for each grammer.And the new grammer variables are
S→ (L) | a
L→SL’
L’→ ,SL’ | ε
First(S) = {( , a}
Follow(S) = {$ , )}
First(L) = {( , a }
Follow(L) = { ) }
First(L’) = {, , ε }
Follow(L’) = { )}
Step 4.
Construct the predictive parsing table.
Nonterminal
(
a
S
(L)
a
L
SL
SL
L’
,
)
,SL’
ε
$
4.b) What is FIRST AND FOLLOW? Explain in detail with an example.
Ans. Computing first and follow
These are the algorithms used to compute the first and follow sets:
FIRST
1. If X is terminal, then FIRST(X) IS {X}.
2. If X → ε is a production, then add ε to FIRST(X).
3. If X is non terminal and X → Y1, Y2..Yk is a production, then place a in FIRST(X) if for
some i , a is in FIRST(Yi) , and ε is in all of FIRST(Y1),…FIRST(Yi-1);
FOLLOW
1. Place $ in FOLLOW(S), where S is the start symbol and $ is the input right end marker.
2. If there is a production A → αBβ, then everything in FIRST (β) except for ε is placed in
FOLLOW (B).
3. If there is a production A → αB, or a production A→ αBβ where FIRST (β) contains ε, then
everything in FOLLOW (A) is in FOLLOW (B).
4. ε will never included in FOLLOW set of any variable.
Example:
E → TA
A → +TA | ε
T → FB
B → *FB | ε
F→ (E) | id
First(E) = {(, id} Follow(E) = {$, )}
First(A) = {+, ε} Follow(A) = {$, )}
First(T) = {(, id} Follow(B) = {+, ), $}
First(B) = {*, ε} Follow(B) = {+, ), $}
First(F) = {(, id} Follow(F) = {+,),*,$}
4.b) Explain the role Lexical Analyzer and issues of Lexical Analyzer.
Ans. In the lexical analysis phase, the compiler scans the characters of the source program, one
character at a time. Whenever it gets a sufficient number of characters to constitute a token of the
specified language, it outputs that token. In order to perform this task, the lexical analyzer must
know the keywords, identifiers, operators, delimiters, and punctuation symbols of the language
to be implemented. So, when it scans the source program, it will be able to return a suitable
token whenever it encounters a token lexeme. Lexeme refers to the sequence of characters in the
source program that is matched by language's character patterns that specify identifiers,
operators, keywords, delimiters, punctuation symbols, and so forth. Therefore, the lexical
analyzer design must:
1. Specify the token of the language, and
2. Suitably recognize the tokens.
Lexical Analyzer Design
Since the function of the lexical analyzer is to scan the source program and produce a stream of
tokens as output, the issues involved in the design of lexical analyzer are:
1. Identifying the tokens of the language for which the lexical analyzer is to be built, and to
specify these tokens by using suitable notation, and
2. Constructing a suitable recognizer for these tokens.
Lexical analyzer has input buffer , symbol table and DFA.
Input Buffer: Initially it is blank. Sometimes lexical analyzer needs to look ahead some symbols
to decide about the token to return. For example, in C language: we need to look after -, = or < to
decide what token to return. We need to introduce a two buffer scheme to handle large lookaheads safely.
Therefore, the first thing that is required is to identify what the keywords are, what the operators
are, and what the delimiters are. These are the tokens of the language. After identifying the
tokens of the language, we must use suitable notation to specify these tokens. This notation
should be compact, precise, and easy to understand. Regular expressions can be used to specify a
set of strings, and a set of strings that can be specified by using regular-expression notation is
called a "regular set." The token of a programming language constitutes a regular set. Hence, this
regular set can be specified by using regular-expression notation. Therefore, we write regular
expressions for things like operators, keywords, and identifiers. For example, the regular
expressions specifying the subset of tokens of typical programming language are as follows:
operators = +| -| * |/ | mod|div
keywords = if|while|do|then
letter = a|b|c|d|....|z|A|B|C|....|Z
digit = 0|1|2|3|4|5|6|7|8|9
identifier = letter (letter|digit)*
The advantage of using regular-expression notation for specifying tokens is that when regular
expressions are used, the recognizer for the tokens ends up being a DFA. Therefore, the next step
is the construction of a DFA from the regular expression that specifies the tokens of the
language. But the DFA is a flow-chart (graphical) representation of the lexical analyzer.
Therefore, after constructing the DFA, the next step is to write a program in suitable
programming language that will simulate the DFA. This program acts as a token recognizer or
lexical analyzer. Therefore, we find that by using regular expressions for specifying the tokens,
designing a lexical analyzer becomes a simple mechanical process that involves transforming
regular expressions into finite automata and generating the program for simulating the finite
automata.
Unit—III
5. a) Check Whether the following grammer is SLR(1) or not. Explain your answer with reasons.
S → L=R
S→R
L → *R
L→ id
R→L
Ans. Step 1.
First(S) = {*, id}
Follow(S) = {$ }
First(L) = {*, id}
Follow(L) = { =, $}
First(R) = {*, id}
Follow(R) = { =, $}
Step 2. Number of production and augmented the grammer
S' –> S
S –> L = R (1)
S –> R
(2)
L –> *R
(3)
L –> id
(4)
R –> L
(5)
Step 3.
Step 4.
=
*
id
$
S
L
0
S4
S5
1
2
1
acc
2
S6, r5
r5
3
R2
4
S4
S5
8
5
r4
r4
6
S4
S5
8
7
r3
r3
8
r5
r5
9
r1
In the above table, shift reduce conflict or multiple entries come in states 2.
R
3
7
9
5.b) For the operators given below, calculate the operator precedence relations and operator
precedence function: Id,+,*,$
Ans. Bottom-up parsers for a large class of context-free grammars can be easily developed using
operator grammars.Operator grammars have the property that no production right side is empty
or has two adjacent nonterminals. This property enables the implementation of efficient operatorprecedence parsers. These parser rely on the following three precedence relations:
Relation
Meaning
a <· b
a yields precedence to b
a =· b
a has the same precedence as b
a ·> b
a takes precedence over b
These operator precedence relations allow to delimit the handles in the right sentential forms: <·
marks the left end, =· appears in the interior of the handle, and ·> marks the right end. Let
assume that between the symbols ai and ai+1 there is exactly one precedence relation. Suppose
that $ is the end of the string. Then for all terminals we can write: $ <· b and b ·> $. If we
remove all non-terminals and place the correct precedence relation: <·, =·, ·> between the
remaining terminals, there remain strings that can be analyzed by easily developed parser. For
example, the following operator precedence relations can be introduced for simple expressions:
id
+
*
$
id
·>
·>
·>
+
<·
·>
<·
·>
*
<·
·>
·>
·>
$
<·
<·
<·
·>
6. a) Construct a canonical parsing table for the grammer given below.
S → CC
C → cC|d
Ans. Step 1.
First(S) = {c, d}
Follow(S) = {$ }
First(C) = {c, d}
Follow(C) = {c,d,$}
Step 2. Number of production and augmented the grammer
S' –>S
S –> CC
(1)
C –> cC
(2)
C –> d
(3)
Step 3.
I0
S’ → .S
$
S → CC
$
C → .cC
c| d
C → .d
c| d
I1
S’ → S.
$
I2
S → C.C
$
C → .cC
$
C → .d
$
I3
C → c.C
c| d
C → .cC
c| d
C → .d
c| d
I4
C → d.
c| d
I5
S → CC.
$
I6
C → c.C
$
C → .cC
$
C → .d
$
I7
C → d.
$
I8
C → cC.
c| d
I9
S → CC.
$
Step 4.
0
1
2
3
4
5
6
7
8
9
c
S3
d
S4
S6
S3
r3
S7
S4
r3
$
S
1
C
2
acc
5
6
r1
S6
S7
r3
r2
r2
r1
Step 4.
=
0
1
2
3
4
5
6
7
8
9
*
S4
id
S5
S
1
L
2
R
3
8
7
8
9
acc
r5
R2
S6, r5
S4
S5
S4
S5
r4
r3
r5
$
r4
r3
r5
r1
6.b) What is the three address code? Mention its types. How would you implement the the three
address statements? Explain with suitable examples.
Ans. Three address code is a sequence of statements of the form x = y op z. Since a statement
involves no more than three references, it is called a "three-address statement," and a sequence of
such statements is referred to as three-address code. For example, the three-address code for the
expression a + b * c + d is:
T1 = B * C
T2 = A + T2
T3 = T3 + D
Representing Three-Address Statements
Records with fields for the operators and operands can be used to represent three-address
statements. It is possible to use a record structure with four fields: the first holds the operator, the
next two hold the operand1 and operand2, respectively, and the last one holds the result. This
representation of a three-address statement is called a "quadruple representation".
Quadruple Representation
Using quadruple representation, the three-address statement x = y op z is represented by placing
op in the operator field, y in the operand1 field, z in the operand2 field, and x in the result field.
The statement x = op y, where op is a unary operator, is represented by placing op in the operator
field, y in the operand1 field, and x in the result field; the operand2 field is not used. A statement
like param t1 is represented by placing param in the operator field and t1 in the operand1 field;
neither operand2 nor the result field are used. Unconditional and conditional jump statements are
represented by placing the target labels in the result field. For example, a quadruple
representation of the three-address code for the statement x = (a + b) *(-c)/d is shown in Table 1.
The numbers in parentheses represent the pointers to the triple structure.
Table 1: Quadruple Representation of x = (a + b) *(-c)/d
Triple Representation
The contents of the operand1, operand2, and result fields are therefore normally the pointers to
the symbol records for the names represented by these fields. Hence, it becomes necessary to
enter temporary names into the symbol table as they are created. This can be avoided by using
the position of the statement to refer to a temporary value. If this is done, then a record structure
with three fields is enough to represent the three-address statements: the first holds the operator
value, and the next two holding values for the operand1 and operand2, respectively. Such a
representation is called a "triple representation". The contents of the operand1 and operand2
fields are either pointers to the symbol table records, or they are pointers to records within the
triple representation itself. For example, a triple representation of the three-address code for the
statement x = (a+b)*(- c)/d is shown in Table 2.
Table 2: Triple Representation of x = (a + b) * (- c)/d
Indirect Triple Representation
Another representation uses an additional array to list the pointers to the triples in the desired
order. This is called an indirect triple representation. For example, a triple representation of the
three-address code for the statement x = (a+b)*(-c)/d is shown in Table 3.
Table 3: Indirect Triple Representation of x = (a + b) * (- c)/d
UNIT-IV
7.a) Discuss about the run time storage management of a code generator. Describe about the
stack allocation in memory management.
Ans. One of the important tasks that a compiler must perform is to allocate the resources of the
target machine to represent the data objects that are being manipulated by the source program.
That is, a compiler must decide the run-time representation of the data objects in the source
program. Source program run-time representations of the data objects, such as integers and real
variables, usually take the form of equivalent data objects at the machine level; whereas data
structures, such as arrays and strings, are represented by several words of machine memory. The
run-time organization of the memory will be as shown in Figure.
Fig. Heap memory storage allows program-controlled data allocation.
The run-time storage has been subdivided to hold the generated target code and the data objects,
which are allocated statically for the stack and heap. The sizes of the stack and heap can change
as the program executes.
Each execution of a procedure is referred to as an activation of the procedure. This is different
from the procedure definition, which in its simplest form is the association of an identifier with a
statement; the identifier is the name of the procedure, and the statement is the body of the
procedure.If a procedure is non-recursive, then there exists only one activation of procedure at
any one time. Whereas if a procedure is recursive, several activations of that procedure may be
active at the same time. The information needed by a single execution or a single activation of a
procedure is managed using a contiguous block of storage called an "activation record"
consisting of the collection of fields.
Stack Allocation
In stack allocation, storage is organized as a stack, and activation records are pushed and popped
as the activation of procedures begin and end, respectively, thereby permitting recursive
procedures. The storage for the locals in each procedure call is contained in the activation record
for that call. Hence, the locals are bound to fresh storage in each activation, because a new
activation record is pushed onto stack when a call is made. The storage values of locals are
deleted when the activation ends.
1) The Call and Return Sequence: Procedure calls are implemented by generating what is
called a "call sequence and return sequence" in the target code. The job of a call sequence
is to set up an activation record. Setting up an activation record means entering the
information into the fields of the activation record if the storage for the activation record
is allocated statically. When the storage for the activation record is allocated dynamically,
storage is allocated for it on the stack, and the information is entered in its fields.
2) Access to Nonlocal Names: The way that the non-locals are accessed depends on the
scope rules of the language. There are two different types of scope rules: static scope
rules and dynamic scope rules. Static scope rules determine which declaration a name's
reference will be associated with, depending upon the program's language, thereby
determining from where the name's value will be obtained at run time. When static scope
rules are used during compilation, the compiler knows how the declarations are bound to
the name references, and hence, from where their values will be obtained at run time.
Whereas when dynamic scope rules are used, the values of nonlocal names are retrieved
at run time by scanning down the stack, starting at the top-most activation record.
3) Setting Up the Access Link: To generate the code for setting up the access link, a
compiler makes use of the following information: the nesting depth of the caller
procedure and the nesting depth of the callee procedure.
7.b) What are the various data structure used for implementing the symbol table?
Ans. A symbol table is a data structure used by a compiler to keep track of scope/ binding
information about names. This information is used in the source program to identify the various
program elements, like variables, constants, procedures, and the labels of statements. The symbol
table is searched every time a name is encountered in the source text. When a new name or new
information about an existing name is discovered, the content of the symbol table changes. There
are various data structure used for implementing the symbol table. These methods are given
below:
1. The Linear List
A linear list of records is the easiest way to implement a symbol table. The new names are added
to the table in the order that they arrive. Whenever a new name is to be added to the table, the
table is first searched linearly or sequentially to check whether or not the name is already present
in the table. If the name is not present, then the record for new name is created and added to the
list at a position specified by the available pointer, as shown in the Figure.
Fig. A new record is added to the linear list of records.
Search Trees
A search tree is a more efficient approach to symbol table organization. We add two links, left
and right, in each record, and these links point to the record in the search tree. Whenever a name
is to be added, first the name is searched in the tree. If it does not exist, then a record for the new
name is created and added at the proper position in the search tree.
Fig. The search tree organization approach to a symbol table.
Hash Tables
A hash table is a table of k pointers numbered from zero to k-1 that point to the symbol table and
a record within the symbol table. To enter a name into symbol table, we find out the hash value
of the name by applying a suitable hash function. The hash function maps the name into an
integer between zero and k-1, and using this value as an index in the hash table, we search the list
of the symbol table records that is built on that hash index. If the name is not present in that list,
we create a record for name and insert it at the head of the list. When retrieving the information
associated with the name, the hash value of the name is first obtained, and then the list that was
built on this hash value is searched for information about the name (Fig.).
Fig. Hash table method of symbol table organization.
8.a) List the various error recovery strategies for a syntactic analysis.
Ans. Recovery From Syntactic Phase Errors
A parser detects an error when it has no legal move from its current configuration. The LL(1) and
LR(1) parsers use the valid prefix property; therefore, they are capable of announcing an error as
soon as they read an input that is not a valid continuation of the previous input's prefix. This is
earliest time that a left-to-right parser can announce an error. But there are a variety of other
types of parsers that do not necessarily have this property.
The advantages of using a parser with a valid-prefix-property capability is that it reports an error
as soon as possible, and it minimizes the amount of erroneous output passed to subsequent
phases of the compiler.
Error Recovery In LR Parsing
A systematic method for error recovery in LR parsing is to scan down the stack until a state S
with a goto on a particular non-terminal A is found, and then discard zero or more input symbols
until a symbol a is found that can legitimately follow A. The parser then shifts the state goto [S,
A] on the stack and resumes normal parsing. There might be more than one choice for the nonterminal A. Normally, these would be non-terminals representing major program pieces, such as
statements.
Another method of error recovery that can be implemented is called "phrase level recovery".
Each error entry in the LR parsing table is examined, and, based on language usage, an
appropriate error-recovery procedure is constructed.
Predictive Parsing Error Recovery
An error is detected during predictive parsing when the terminal on the top of the stack does not
match the next input symbol, or when non-terminal A is on top of the stack and a is the next
input symbol. M [A, a] is the error entry used to for recovery. Panic mode recovery can be used
to recover from an error detected by the LL parser. The effectiveness of panic mode recovery
depends on the choice of the synchronizing token. Several heuristics can be used when selecting
the synchronizing token in order to ensure quick recovery from common errors:
1. All the symbols in the FOLLOW (A) must be kept in the set of synchronizing tokens,
because if we skip until an a symbol in FOLLOW (A) is read, and we pop A from the
stack, it is likely that the parsing can continue.
2. Since the syntactic structure of a language is very often hierarchical, we add the symbols
that begin higher constructs to the synchronizing set of lower constructs. For example, we
add keywords to the synchronizing sets of non-terminals that generate expressions.
3. We also add the symbols in FIRST (A) to the synchronizing set of non-terminal A. This
provides for a resumption of parsing according to A if a symbol in FIRST (A) appears in
the input.
4. A derivation by an Î-production can be used as a default. Error detection will be
postponed, but the error will still be captured. This method reduces the number of nonterminals that must be considered during error recovery.
8.b) Explain the various limitations of using static allocation.
Ans. In static allocation, the names are bound to specific storage locations as the program is
compiled. These storage locations cannot be changed during the program's execution. Since the
binding does not change at run time, every time a procedure is called, its names are bound to the
same storage locations. However, there are some limitations to using static allocation:
1. The size of the data object and any constraints on its position in memory must be known
at compile time.
2. Recursive procedures cannot be permitted, because all activations of a procedure use the
same binding for local names.
3. Data structures cannot be created dynamically, since there is no mechanism for storage
allocation at run time.
UNIT-V
9.a) Explain the principle sources of code optimization in detail.
Ans. Code optimization refers to the techniques used by the compiler to improve the execution
efficiency of the generated object code. It involves a complex analysis of the intermediate code
and the performance of various transformations; but every optimizing transformation must also
preserve the semantics of the program. That is, a compiler should not attempt any optimization
that would lead to a change in the program's semantics.
Optimization can be machine-independent or machine-dependent. Machine-independent
optimizations can be performed independently of the target machine for which the compiler is
generating code; that is, the optimizations are not tied to the target machine's specific platform or
language. On the other hand, machine-dependent optimization requires knowledge of the target
machine. An attempt to generate object code that will utilize the target machine's registers more
efficiently is an example of machine-dependent code optimization. Actually, code optimization
is a misnomer; even after performing various optimizing transformations, there is no guarantee
that the generated object code will be optimal. Hence, we are actually performing code
improvement. When attempting any optimizing transformation, the following criteria should be
applied:
1. The optimization should capture most of the potential improvements without an
unreasonable amount of effort.
2. The optimization should be such that the meaning of the source program is preserved.
3. The optimization should, on average, reduce the time and space expended by the object
code.
Loop Optimization
Loop optimization is the most valuable machine-independent optimization because a program's
inner loops are good candidates for improvement. The important loop optimizations are
elimination of loop invariant computations and elimination of induction variables. A loop
invariant computation is one that computes the same value every time a loop is executed.
Eliminating Loop Invariant Computations
To eliminate loop invariant computations, we first identify the invariant computations and then
move them outside loop if the move does not lead to a change in the program's meaning.
Identification of loop invariant computation requires the detection of loops in the program.
Whether a loop exists in the program or not depends on the program's control flow, therefore,
requiring a control flow analysis. For loop detection, a graphical representation, called a
"program flow graph," shows how the control is flowing in the program and how the control is
being used. To obtain such a graph, we must partition the intermediate code into basic blocks.
This requires identifying leader statements, which are defined as follows:
1. The first statement is a leader statement.
2. The target of a conditional or unconditional goto is a leader.
3. A statement that immediately follows a conditional goto is a leader.
A basic block is a sequence of three-address statements that can be entered only at the beginning,
and control ends after the execution of the last statement, without a halt or any possibility of
branching, except at the end.
9.b) How would you construct a DAG for a basic block? Explain with an example.
Ans. To partition three-address code into basic blocks, we must identify the leader statements in
the three-address code and then include all the statements, starting from a leader, and up to, but
not including, the next leader. The basic blocks into which the three-address code is partitioned
constitute the nodes or vertices of the program flow graph. The edges in the flow graph are
decided as follows. If B1 and B2 are the two blocks, then add an edge from B1 to B2 in the
program flow graph, if the block B2 follows B1 in an execution sequence. The block B2 follows
B1 in an execution sequence if and only if:
1. The first statement of block B2 immediately follows the last statement of block B1 in the
three-address code, and the last statement of block B1 is not an unconditional goto
statement.
2. The last statement of block B1 is either a conditional or unconditional goto statement, and
the first statement of block B2 is the target of the last statement of block B1.
For example, consider the following program fragment:
Fact(x)
{
int f = 1;
for(i = 2; i<=x; i++)
f = f*i;
return(f);
}
The three-address-code representation for the program fragment above is:
1. f = 1;
2. i = 2
3. if i <= x goto(8)
4. f = f *i
5. t1 = i + 1
6. i = t1
7. goto(3)
8. goto calling program
The leader statements are:
Statement number 1, because it is the first statement.
Statement number 3, because it is the target of a goto.
Statement number 4, because it immediately follows a conditional goto statement.
Statement number 8, because it is a target of a conditional goto statement.
Therefore, the basic blocks into which the above code can be partitioned are as follows, and the
program flow graph is shown in Figure 1.
Block B1:
Block B2:
Block B3:
Block B4:
Figure. Program flow graph
10.a) Write about Data Flow Analysis of structural programs.
Ans. Once an intermediate-code program is partitioned into basic blocks, we represent the flow
of control between them by a flow graph. The nodes of the flow graph are the basic blocks.
There is an edge from block B to block C if and only if it is possible for the first instruction in
block C to immediately follow the last instruction in block B. There are two ways that such an
edge could be justified:
• There is a conditional or unconditional jump from the end of B to the beginning of C.
• C immediately follows B in the original order of the three-address instructions, and B does not
end in an unconditional jump.
B is a predecessor of C, and C is a successor of B. Often we add two nodes, called the entry and
exit, that do not correspond to executable intermediate instructions. There is an edge from the
entry to the first executable node of the flow graph, that is, to the basic block that comes from the
first instruction of the intermediate code. There is an edge to the exit from any basic block that
contains an instruction that could be the last executed instruction of the program. If the final
instruction of the program is not an unconditional jump, then the block containing the final
instruction of the program is one predecessor of the exit, but so is any basic block that has a jump
to code that is not part of the program.
The set of basic blocks constructed yields the flow graph of Fig. 8.9. The entry points to basic
block B\, since B\ contains the first instruction of the program. The only successor of B\ is B2,
because B\ does not end in an unconditional jump, and the leader of B2 immediately follows the
end of B\.
Block B3 has two successors. One is itself, because the leader of B3, instruction 3, is the target of
the conditional jump at the end of £3, instruction 9. The other successor is B4, because control
can fall through the conditional jump at the end of B3 and next enter the leader of B±. Only BQ
points to the exit of the flow graph, since the only way to get to code that follows the program
from which we constructed the flow graph is to fall through the conditional jump that ends BG.
Flow graphs, being quite ordinary graphs, can be represented by any of the data structures
appropriate for graphs. The content of nodes (basic blocks) need their own representation. The
content of a node by a pointer to the leader in the array of three-address instructions, together
with a count of the number of instructions or a second pointer to the last instruction. However,
since we may be changing the number of instructions in a basic block frequently, it is likely to be
more efficient to create a linked list of instructions for each basic block. Many code
transformations depend upon the identification of "loops" in a flow graph. We say that a set of
nodes L in a flow graph is a loop if
1. There is a node in L called the loop entry with the property that no other node in L has a
predecessor outside L. That is, every path from the entry of the entire flow graph to any node in
L goes through the loop entry.
Figure. Flow graph
2. Every node in L has a nonempty path, completely within L, to the entry of L. The flow graph
of Fig. has three loops:
1. B3 by itself.
2. B6 by itself.
3. {B2, B3, B4}.
The first two are single nodes with an edge to the node itself. For instance, B3 forms a loop with
B3 as its entry. Note that the second requirement for a loop is that there be a nonempty path from
B3 to itself. Thus, a single node like B2, which does not have an edge B2 ->• B2, is not a loop,
since there is no nonempty path from B2 to itself within {B2}. The third loop, L = {B2, B3, B4},
has B2 as its loop entry.
10.b) Draw the DAG for a:=b*-c + b* -c.
Ans. Ans. Three address codes are: a=b*-c + b*-c
T1 = -c
T2 = b*T1
T5 = T2+T4
a:= T5
T3 = -c
T4 = b*T3
Fig. DAG