Internal Consistency & Reliability: Statistics Explained
advertisement

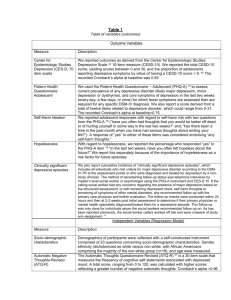
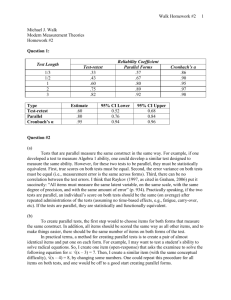
Internal consistency From Wikipedia, the free encyclopedia Jump to: navigation, search In statistics and research, internal consistency is a measure based on the correlations between different items on the same test (or the same subscale on a larger test). It measures whether several items that propose to measure the same general construct produce similar scores. For example, if a respondent expressed agreement with the statements "I like to ride bicycles" and "I've enjoyed riding bicycles in the past", and disagreement with the statement "I hate bicycles", this would be indicative of good internal consistency of the test. Internal consistency is usually measured with Cronbach's alpha, a statistic calculated from the pairwise correlations between items. Internal consistency ranges between zero and one. A commonly-accepted rule of thumb is that an α of 0.6-0.7 indicates acceptable reliability, and 0.8 or higher indicates good reliability. High reliabilities (0.95 or higher) are not necessarily desirable, as this indicates that the items may be entirely redundant. The goal in designing a reliable instrument is for scores on similar items to be related (internally consistent), but for each to contribute some unique information as well. URL: http://en.wikipedia.org/wiki/Internal_consistency Reliability (statistics) From Wikipedia, the free encyclopedia Jump to: navigation, search In statistics, reliability is the consistency of a set of measurements or measuring instrument, often used to describe a test. This can either be whether the measurements of the same instrument give or are likely to give the same measurement (test-retest), or in the case of more subjective instruments, such as personality or trait inventories, whether two independent assessors give similar scores (inter-rater reliability). Reliability is inversely related to random error. Reliability does not imply validity. That is, a reliable measure is measuring something consistently, but not necessarily what it is supposed to be measuring. For example, while there are many reliable tests of specific abilities, not all of them would be valid for predicting, say, job performance. In terms of accuracy and precision, reliability is precision, while validity is accuracy. In experimental sciences, reliability is the extent to which the measurements of a test remain consistent over repeated tests of the same subject under identical conditions. An experiment is reliable if it yields consistent results of the same measure. It is unreliable if repeated measurements give different results. It can also be interpreted as the lack of random error in measurement.[1] In engineering, reliability is the ability of a system or component to perform its required functions under stated conditions for a specified period of time. It is often reported in terms of a probability. Evaluations of reliability involve the use of many statistical tools. See Reliability engineering for further discussion. An often-used example used to elucidate the difference between reliability and validity in the experimental sciences is a common bathroom scale. If someone that weighs 200 lbs. steps on the scale 10 times, and it reads "200" each time, then the measurement is reliable and valid. If the scale consistently reads "150", then it is not valid, but it is still reliable because the measurement is very consistent. If the scale varied a lot around 200 (190, 205, 192, 209, etc.), then the scale could be considered valid but not reliable. Estimation Reliability may be estimated through a variety of methods that couldn't fall into two types: Single-administration and multiple-administration. Multiple-administration methods require that two assessments are administered. In the test-retest method, reliability is estimated as the Pearson product-moment correlation coefficient between two administrations of the same measure. In the alternate forms method, reliability is estimated by the Pearson product-moment correlation coefficient of two different forms of a measure, usually administered together. Single-administration methods include split-half and internal consistency. The split-half method treats the two halves of a measure as alternate forms. This "halves reliability" estimate is then stepped up to the full test length using the Spearman-Brown prediction formula. The most common internal consistency measure is Cronbach's alpha, which is usually interpreted as the mean of all possible split-half coefficients.[2] Cronbach's alpha is a generalization of an earlier form of estimating internal consistency, KuderRichardson Formula 20.[2] Each of these estimation methods isn't sensitive to different sources of error and so might not be expected to be equal. Also, reliability is a property of the scores of a measure rather than the measure itself and are thus said to be sample dependent. Reliability estimates from one sample might differ from those of a second sample (beyond what might be expected due to sampling variations) if the second sample is drawn from a different population because the true reliability is different in this second population. (This is true of measures of all types--yardsticks might measure houses well yet have poor reliability when used to measure the lengths of insects.) Reliability may be improved by clarity of expression (for written assessments), lengthening the measure,[2] and other informal means. However, formal psychometric analysis, called the item analysis, is considered the most effective way to increase reliability. This analysis consists of computation of item difficulties and item discrimination indices, the latter index involving computation of correlations between the items and sum of the item scores of the entire test. If items that are too difficult, too easy, and/or have near-zero or negative discrimination are replaced with better items, the reliability of the measure will increase. R(t) = 1 − F(t). R(t) = exp( − λt). (where λ is the failure rate) [edit] Classical test theory In classical test theory, reliability is defined mathematically as the ratio of the variation of the true score and the variation of the observed score. Or, equivalently, one minus the ratio of the variation of the error score and the variation of the observed score: where ρxx' is the symbol for the reliability of the observed score, X; , , and are the variances on the measured, true and error scores respectively. Unfortunately, there is no way to directly observe or calculate the true score, so a variety of methods are used to estimate the reliability of a test. Some examples of the methods to estimate reliability include test-retest reliability, internal consistency reliability, and parallel-test reliability. Each method comes at the problem of figuring out the source of error in the test somewhat differently. [edit] Item response theory It was well-known to classical test theorists that measurement precision is not uniform across the scale of measurement. Tests tend to distinguish better for testtakers with moderate trait levels and worse among high- and low-scoring testtakers. Item response theory extends the concept of reliability from a single index to a function called the information function. The IRT information function is the inverse of the conditional observed score standard error at any given test score. Higher levels of IRT information indicate higher precision and thus greater reliability. URL: http://en.wikipedia.org/wiki/Reliability_(statistics) Cronbach's alpha From Wikipedia, the free encyclopedia Jump to: navigation, search Cronbach's α (alpha) is a statistic. It has an important use as a measure of the reliability of a psychometric instrument. It was first named as alpha by Cronbach (1951), as he had intended to continue with further instruments. It is the extension of an earlier version, the Kuder-Richardson Formula 20 (often shortened to KR-20), which is the equivalent for dichotomous items, and Guttman (1945) developed the same quantity under the name lambda-2. Cronbach's α is a coefficient of consistency and measures how well a set of variables or items measures a single, unidimensional latent construct. Definition Cronbach's α is defined as where N is the number of components (items or testlets), observed total test scores, and is the variance of the is the variance of component i. Alternatively, the standardized Cronbach's α can also be defined as where N is the number of components (items or testlets), equals the average variance and is the average of all covariances between the components. Cronbach's alpha and internal consistency Cronbach's alpha will generally increase when the correlations between the items increase. For this reason the coefficient is also called the internal consistency or the internal consistency reliability of the test. Cronbach's alpha in classical test theory Alpha is an unbiased estimator of reliability if and only if the components are essentially τ-equivalent (Lord & Novick, 1968[1]). Under this condition the components can have different means and different variances, but their covariances should all be equal - which implies that they have 1 common factor in a factor analysis. One special case of essential τ-equivalence is that the components are parallel. Although the assumption of essential τ-equivalence may sometimes be met (at least approximately) by testlets, when applied to items it is probably never true. This is caused by the facts that (1) most test developers invariably include items with a range of difficulties (or stimuli that vary in their standing on the latent trait, in the case of personality, attitude or other non-cognitive instruments), and (2) the item scores are usually bounded from above and below. These circumstances make it unlikely that the items have a linear regression on a common factor. A factor analysis may then produce artificial factors that are related to the differential skewnesses of the components. When the assumption of essential τ-equivalence of the components is violated, alpha is not an unbiased estimator of reliability. Instead, it is a lower bound on reliability. α can take values between negative infinity and 1 (although only positive values make sense). Some professionals, as a rule of thumb, require a reliability of 0.70 or higher (obtained on a substantial sample) before they will use an instrument. Obviously, this rule should be applied with caution when α has been computed from items that systematically violate its assumptions. Further, the appropriate degree of reliability depends upon the use of the instrument, e.g., an instrument designed to be used as part of a battery may be intentionally designed to be as short as possible (and thus somewhat less reliable). Other situations may require extremely precise measures (with very high reliabilities). Cronbach's α is related conceptually to the Spearman-Brown prediction formula. Both arise from the basic classical test theory result that the reliability of test scores can be expressed as the ratio of the true score and total score (error and true score) variances: Alpha is most appropriately used when the items measure different substantive areas within a single construct. Conversely, alpha (and other internal consistency estimates of reliability) are inappropriate for estimating the reliability of an intentionally heterogeneous instrument (such as screening devices like biodata or the original MMPI). Also, α can be artificially inflated by making scales which consist of superficial changes to the wording within a set of items or by analyzing speeded tests. Cronbach's alpha in generalizability theory Cronbach and others generalized some basic assumptions of classical test theory in their generalizability theory. If this theory is applied to test construction, then it is assumed that the items that constitute the test are a random sample from a larger universe of items. The expected score of a person in the universe is called the universum score, analogous to a true score. The generalizability is defined analogously as the variance of the universum scores divided by the variance of the observable scores, analogous to the concept of reliability in classical test theory. In this theory, Cronbach's alpha is an unbiased estimate of the generalizability. For this to be true the assumptions of essential τ-equivalence or parallelness are not needed. Consequently, Cronbach's alpha can be viewed as a measure of how well the sum score on the selected items capture the expected score in the entire domain, even if that domain is heterogeneous. Cronbach's alpha and the intra-class correlation Cronbach's alpha is equal to the stepped-up consistency version of the Intra-class correlation coefficient, which is commonly used in observational studies. This can be viewed as another application of generalizability theory, where the items are replaced by raters or observers who are randomly drawn from a population. Cronbach's alpha will then estimate how strongly the score obtained from the actual panel of raters correlates with the score that would have been obtained by another random sample of raters. Cronbach's alpha and factor analysis As stated in the section about its relation with classical test theory, Cronbach's alpha has a theoretical relation with factor analysis. There is also a more empirical relation: Selecting items such that they optimize Cronbach's alpha will often result in a test that is homogeneous in that they (very roughly) approximately satisfy a factor analysis with one common factor. The reason for this is that Cronbach's alpha increases with the average correlation between item, so optimization of it tends to select items that have correlations of similar size with most other items. It should be stressed that, although unidimensionality (i.e. fit to the one-factor model) is a necessary condition for alpha to be an unbiased estimator of reliability, the value of alpha is not related to the factorial homogeneity. The reason is that the value of alpha depends on the size of the average inter-item covariance, while unidimensionality depends on the pattern of the inter-item covariances. Cronbach's alpha and other disciplines Although this description of the use of α is given in terms of psychology, the statistic can be used in any discipline. Construct creation Coding two (or more) different variables with a high Cronbach's alpha into a construct for regression use is simple. Dividing the used variables by their means or averages results in a percentage value for the respective case. After all variables have been re-calculated in percentage terms, they can easily be summed to create the new construct. URL: http://en.wikipedia.org/wiki/Cronbach%27s_alpha Kuder-Richardson Formula 20 From Wikipedia, the free encyclopedia (Redirected from Kuder) Jump to: navigation, search In statistics, the Kuder-Richardson Formula 20 (KR-20) is a measure of internal consistency reliability for measures with dichotomous choices, first published in 1937. It is analogous to Cronbach's α, except Cronbach's α is used for nondichotomous (continuous) measures. [1] A high KR-20 coefficient (e.g., >0.90) indicates a homogeneous test. Values can range from 0.00 to 1.00 (sometimes expressed as 0 to 100), with high values indicating that the examination is likely to correlate with alternate forms (a desirable characteristic). The KR20 is impacted by difficulty, spread in scores and length of the examination. In the case when scores are not tau-equivalent (for example when there is not homogeneous but rather examination items of increasing difficulty) then the KR-20 is an indication of the lower bound of internal consistency (reliability). Note that variance for KR-20 is If it is important to use unbiased operators then the Sum of Squares should be divided by degrees of freedom (N − 1) and the probabilities are multiplied by Since Cronbach's α was published in 1951, there has been no known advantage to KR-20 over Cronbach. KR-20 is seen as a derivative of the Cronbach formula, with the advantage to Cronbach that it can handle both dichotomous and continuous variables. URL: http://en.wikipedia.org/wiki/Kuder Estimating Reliability Estimating Reliability - Forced-Choice Assessment The split-half model and the Kuder-Richardson formula for estimating reliability will be described here. Given the demands on time and the need for all assessment to be relevant, school practitioners are unlikely to utilize a test-retest or equivalent forms procedure to establish reliability. Reliability Estimation Using a Split-half Methodology The split-half design in effect creates two comparable test administrations. The items in a test are split into two tests that are equivalent in content and difficulty. Often this is done by splitting among odd and even numbered items. This assumes that the assessment is homogenous in content. Once the test is split, reliability is estimated as the correlation of two separate tests with an adjustment for the test length. Other things being equal, the longer the test, the more reliable it will be when reliability concerns internal consistency. This is because the sample of behavior is larger. In split-half, it is possible to utilize the Spearman-Brown formula to correct a correlation between the two halves--as if the correlation used two tests the length of the full test (before it was split), as shown on the next page. For demonstration purposes a small sample set is employed here--a test of 40 items for 10 students. The items are then divided even (X) and odd (Y) into two simultaneous assessments. Student Score (40) X Even (20) Y Odd (20) x y x2 y2 xy A 40 20 20 4.8 4.2 23.04 17.64 20.16 B 28 15 13 -0.2 -2.8 0.04 7.84 0.56 C 35 19 16 3.8 0.2 14.44 0.04 0.76 D 38 18 20 2.8 4.2 7.84 17.64 11.76 E 22 l0 12 -5.2 -3.8 27.04 14.44 19.76 F 20 12 8 -3.2 -7.8 10.24 60.84 24.96 G 35 16 19 0.8 3.2 0.64 10.24 2.56 H 33 16 17 0.8 1.2 0.64 1.44 0.96 I 31 12 19 -3.2 3.2 10.24 10.24 -10.24 J 28 14 14 -1.2 -1.8 1.44 3.24 2.16 MEAN 31.0 15.2 15.8 95.60 143.60 73.40 3.26 3.99 SD From this information it is possible to calculate a correlation using the Pearson Product-Moment Correlation Coefficient, a statistical measure of the degree of relationship between the two halves. Pearson Product Moment Correlation Coefficient: where x is each student's score minus the mean on even number items for each student. y is each student's score minus the mean on odd number items for each student. N is the number of students. SD is the standard deviation. This is computed by squaring the deviation (e.g., x2 ) for each student, summing the squared deviations (e.g., x2 ); dividing this total by the number of students minus 1 (N-l) and taking the square root. The Spearman-Brown formula is usually applied in determining reliability using split halves. When applied, it involves doubling the two halves to the full number of items, thus giving a reliability estimate for the number of items in the original test. Estimating Reliability using the Kuder-Richardson Formula 20 Kuder and Richardson devised a procedure for estimating the reliability of a test in 1937. It has become the standard for estimating reliability for single administration of a single form. Kuder-Richardson measures inter-item consistency. It is tantamount to doing a split-half reliability on all combinations of items resulting from different splitting of the test. When schools have the capacity to maintain item level data, the KR20, which is a challenging set of calculations to do by hand, is easily computed by a spreadsheet or basic statistical package. The rationale for Kuder and Richardson's most commonly used procedure is roughly equivalent to: 1) Securing the mean inter-correlation of the number of items (k) in the test, 2) Considering this to be the reliability coefficient for the typical item in the test, 3) Stepping up this average with the Spearman-Brown formula to estimate the reliability coefficient of an assessment of k items. ITEM (k) 1 2 Student (N) 3 4 5 6 7 8 1=correct 9 10 11 12 x=X- X x2 mean (score(Score) mean) 0=incorrect A 1 1 1 1 1 1 1 0 1 1 1 1 11 4.5 20.25 B 1 1 1 1 1 1 1 1 0 1 1 0 10 3.5 12.25 C 1 1 1 1 1 1 1 1 1 0 0 0 9 2.5 6.25 D 1 1 1 0 1 1 0 1 1 0 0 0 7 0.5 0.25 E 1 1 1 1 1 0 0 1 1 0 0 0 7 0.5 0.25 F 1 1 1 0 0 1 1 0 0 1 0 0 6 -0.5 0.25 G 1 1 1 1 0 0 1 0 0 0 0 0 5 -1.5 2.25 H 1 1 0 1 0 0 0 1 0 0 0 0 4 -2.5 6.25 I 1 1 1 0 1 0 0 0 0 0 0 0 4 -2.5 6.25 J 0 0 0 1 1 0 0 0 0 0 0 0 2 -4.5 20.25 = 9 9 8 7 7 5 5 5 4 3 2 1 65 0 74.50 x2 74.50 mean 6.5 P-values 0.9 0.9 0.8 0.7 0.7 0.5 0.5 0.5 0.4 0.3 0.2 0.1 Q-value 0.1 0.1 0.2 0.3 0.3 0.5 0.5 0.5 0.6 0.7 0.8 0.9 pq pq 0.09 0.09 0.16 0.21 0.21 0.25 0.25 0.25 0.24 0.21 0.16 0.09 2.21 Here, Variance Kuder-Richardson Formula 20 p is the proportion of students passing a given item q is the proportion of students that did not pass a given item 2 is the variance of the total score on this assessment x is the student score minus the mean score; x is squared and the squares are summed ( x2); the summed squares are divided by the number of students minus 1 (N-l) k is the number of items on the test. For the example, Estimating Reliability Using the Kuder-Richardson Formula 21 When item level data or technological assistance is not available to assist in the computation of a large number of cases and items, the simpler, and sometimes less precise, reliability estimate known as Kuder-Richardson Formula 21 is an acceptable general measure of internal consistency. The formula requires only the test mean (M), the variance ( 2) and the number of items on the test (k). It assumes that all items are of approximately equal difficulty. (N=number of students) For this example, the data set used for computation of the KR 20 is repeated. Student (N=l0) X (Score) x= X-mean (score-mean) x2 A 11 4.5 20.25 B 10 3.5 12.25 C 9 2.5 6.25 D 7 0.5 0.25 E 7 0.5 0.25 F 6 -0.5 0.25 G 5 -1.5 2.25 H 4 -2.5 6.25 I 4 -2.5 6.25 2 -4.5 J mean = 6.5 Variance Kuder-=Richardson formula 21 20.25 x2 = 74.50 M - the assessment mean (6.5) k - the number of items in the assessment (12) 2 - variance (8.28). Therefore; in the example: The ratio [ mean (k-mean)] / k2 in KR21 is a mathematical approximation of the ratio pq/2 in KR20. The formula simplifies the computation but will usually yield, as evidenced, a lower estimate of reliability. The differences are not great on a test with all items of about the same difficulty. In addition to the split-half reliability estimates and the Kuder-Richardson formulas (KR20, KR21) as mentioned above, there are many other ways to compute a reliability index. Another one of the most commonly used reliability coefficients is Cronbach's alpha ( ). It is based on the internal consistency of items in the tests. It is flexible and can be used with test formats that have more than one correct answer. The split-half estimates and KR20 are exchangeable with Cronbach's alpha. When examinees are divided into two parts and the scores and variances of the two parts are calculated, the split-half formula is algebraically equivalent to Cronbach's alpha. When the test format has only one correct answer, KR20 is algebraically equivalent to Cronbach's alpha. Therefore, the split-half and KR20 reliability estimates may be considered special cases of Cronbach's alpha. Given the universe of concerns which daily confront school administrators and classroom teachers, the importance is not in knowing how to derive a reliability estimate, whether using split halves, KR20 or KR21. The importance is in knowing what the information means in evaluating the validity of the assessment. A high reliability coefficient is no guarantee that the assessment is well-suited to the outcome. It does tell you if the items in the assessment are strongly or weakly related with regard to student performance. If all the items are variations of the same skill or knowledge base, the reliability estimate for internal consistency should be high. If multiple outcomes are measured in one assessment, the reliability estimate may be lower. That does not mean the test is suspect. It probably means that the domains of knowledge or skills assessed are somewhat diverse and a student who knows the content of one outcome may not be as proficient relative to another outcome. Establishing Interrater Agreement for Performance-Based or Product Assessments (Complex Generated Response Assessments) In performance-based assessment, where scoring requires some judgment, an important type of reliability is agreement among those who evaluate the quality of the product or performance relative to a set of stated criteria. Preconditions of interrater agreement are: 1) A scoring scale or rubric which is clear and unambiguous in what it demands of the student by way of demonstration. 2) Evaluators who are fully conversant with the scale and how the scale relates to the student performance, and who are in agreement with other evaluators on the application of the scale to the student demonstration. The end result is that all evaluators are of a common mind with regard to the student performance and that one mind is reflected in the scoring scale or rubric and that all evaluators should give the demonstration the same or nearly the same ratings. The consistency of rating is called interrater reliability. Unless the scale was constructed by those who are employing the scale and there has been extensive discussion during this construction, training is a necessity to establish this common perspective. Training evaluators for consistency should include: A discussion of the rating scale by all participating evaluators so that a common interpretation of the scale emerges and so diverse interpretations can be resolved or referred to an authority for determination. The opportunity to review sample demonstrations which have been anchored to a particular score on the scale. These representative works were selected by a committee for their clarity in demonstrating a value on the scale. This will provide operational models for the raters who are being trained. Opportunities to try out the scale and discuss the ratings. The results can be used to further refine common understanding. Additional rounds of scoring can be used to eliminate any evaluator who cannot enter into agreement relative to the scale. Gronlund (1985) indicated that "rater error" can be related to: 1) Personal bias which may occur when a rater is consistently using only part of the scoring scale, either in being overly generous, overly severe or evidencing a tendency to the center of the scale in scoring. 2) A "halo effect" which may occur when a rater's overall perception of a student positively or negatively colors the rating given to a student. 3) A logical error which may occur when a rater confuses distinct elements of an analytic scale. This confounds rating on the items. Proper training to an unambiguous scoring rubric is a necessary condition for establishing reliability for student performance or product. When evaluation of the product or performance begins in earnest, it is necessary that a percentage of student work be double scored by two different raters to give an indication of agreement among evaluators. The sample of performances or products that are scored by two independent evaluators must be large enough to establish confidence that scoring is consistent. The smaller the number of cases, the larger the percentage of cases that will be double scored. When the data on the double-scored assessments is available, it is possible to compute a correlation of the raters' scores using the Pearson Product Moment Correlation Coefficient. This correlation indicates the relationship between the two scores given for each student. A correlation of .6 or higher would indicate that the scores given to the students are highly related. Another method of indicating the relationship between the two scores is through the establishing of a rater agreement percentage--that is, to take the assessments that have been double scored and calculate the number of cases where there has been exact agreement between the two raters. If the scale is analytic and rather extensive, percent of agreement can be determined for the number of cases where the scores are in exact agreement or adjacent to each other (within one point on the scale). Agreement levels should be at 80% or higher to establish a claim for interrater agreement. Establishing Rater Agreement Percentages Two important decisions which precede the establishment of a rater agreement percentage are: How close do scores by raters have to be to count as in "agreement?" In a limited holistic scale, (e.g., 1-4 points) it is most likely that you will require exact agreement among raters. If an analytic scale is employed with 30 to 40 points, it may be determined that exact and adjacent scores will count as being in agreement. What percentage of agreement will be acceptable to ensure reliability? 80% agreement is promoted as a minimum standard above, but circumstances relative to the use of the scale may warrant exercising a lower level of acceptance. The choice of an acceptable percentage of agreement must be established by the school or district. It is advisable that the decision be consultative. After agreement and the acceptable percentage of agreement have been established, list the ratings given to each student by each rater for comparison: Student A B C D E F G H I J Score: Rater 1 6 5 3 4 2 7 6 5 3 7 Score: Rater 2 6 5 4 4 3 7 6 5 4 7 Agreement X X X X X X X Dividing the number of cases where student scores between the raters are in agreement (7) with the total number of cases (10) determines the rater agreement percentage (70%). When there are more than two teachers, the consistency of ratings for two teachers at a time can be calculated with the same method. For example, if three teachers are employed as raters, rater agreement percentages should be calculated for Rater 1 and Rater 2 Rater 1 and Rater 3 Rater 2 and Rater 3 All calculations should exceed the acceptable reliability score. If there is occasion to use more than two raters for the same assessment performance or product, an analysis of variance using the scorers as the independent variable can be computed using the sum of squares. In discussion of the various forms of performance assessment, it has been suggested how two raters can examine the same performance to establish a reliability score. Unless at least two independent raters have evaluated the performance or product for a significant sampling of students, it is not possible to obtain evidence that the score obtained is accurate to the stated criteria. URL: http://www.gower.k12.il.us/Staff/ASSESS/4_ch2app.htm