Solution

Exercises week 7
1. The data below are from an experiment comparing three different group conditions.
group 1 group 2 group 3
0 1 6
1
0
3
4
1
2
5
8
5
(a) Use an analysis of variance with α = 0 .
05 to determine whether these data indicate any significant mean differences omong the three treatments.
(b) Explain what would happen to the analysis of variance if 2 points were subtracted from each score in Treatment 3 (Note: the new scores would be 4, 3, 6, and 3).
(c) You can try to replicate your answers by doing an ANOVA in SPSS. Follow the guidelines at the end of the Chapter 13 (Ed. 7) or Chapter 12 (Ed. 8) in G&W.
Solution:
(a) Calculations give: X
1
= 1, X
2
= 2, X
3
= 6, and
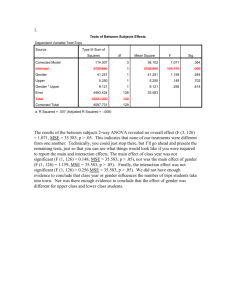
Source SS df MS
Between 56 2 28 F = 14 .
0
Within 18 9 2
Total 74 11
With df = 2 , 9 the critical value is 4.26. Reject H
0 significant differences between the treatments.
and conclude that there are
(b) Subtracting 2 points from each score in Treatment 3 would lower its mean, making it more similar to the other two treatment means. The smaller mean differences would lower the value of M S between and lower the value of the F-ratio.
2. The Internal Revenue Service (“Belastingdienst”) has a telephone helpdesk for income tax.
They have the impression that people in larger cities have relatively more questions than people in smaller cities.
A number of 24 cities are selected that can be considered to be grouped into 4 groups according to population size. During a period of three months the number of phone calls to the helpdesk of each of these 24 cities is registered. This number is standardised relative to 1000 overall tax statements per city. The raw data are as follows:
Population size (*1000)
> 200 100 − 200 50 − 100 < 50
45
35
23
19
25
17
8
18
41
42
37
28
27
21
26
34
19
28
31
36
14
17
10
23
(a) Formulate the hypotheses, determine the critical F -value and formulate the corresponding decision rule.
(b) Test whether the null hypothesis must be rejected.
(c) Determine how much of the variance in telephone calls rate can be explained by the factor population size .
(d) Report the results in text.
Solution:
(a) Hypotheses:
• H
0
: µ
1
= µ
2
= µ
3
= µ
4
(null hypothesis)
• H
1
: at least one µ different (alternative hypothesis)
Parameters:
• N = 24, k = 4, α = 0 .
05.
Test statistic
• F = s
2 b
/s
2 w
• s
2 b
= SS
( df between
= k − 1
/ ( k − 1),
, N − k = 3 , 20)
• s 2 w
= SS within
/ ( N − k ),
• SS between
= P j
N j
( X j
− X )
2
,
• SS within
= P j
P i
( X ij
− X j
)
2
,
• F crit
= 3 .
10
Decision rule
• Reject H
0 if F obs
≥ F crit
• Do not reject H + 0 if F obs
< F crit
(b) Calculations:
45 + 35 + 41 + 42 + 37 + 28
• X
1
= = 38,
6
23 + 19 + 27 + 21 + 26 + 34
• X
2
= = 25,
6
25 + 17 + 19 + 28 + 31 + 36
• X
3
=
• X
4
• X =
8 + 18 + 14 + 17 + 10 + 23
= = 15,
6
6 × 38 + 6 × 26 + 6 × 26 + 6 × 15
24
• SS between
6
= 6 ∗ (38 − 26)
2
= 26,
= 26,
+ 6 ∗ (25 − 26)
2
+ 6 ∗ (26 − 26)
2
+ 6 ∗ (15 − 26)
2
= 1596,
• s
2 b
= 1596 / 3 = 532,
Page 2
• SS within
= h
(45 − 38)
2
+(35 − 38)
2
+(41 − 38)
2
+(42 − 38)
2
+(37 − 38)
2
+(28 − 38)
2 i
+ h
(23 − 25)
2
+ (19 − 25)
2
+ (27 − 25)
2
+ (21 − 25)
2
+ (26 − 25)
2
+ (34 − 25)
2 i
+ h
(25 − 26)
2
+ (17 − 26)
2
+ (19 − 26)
2
+ (28 − 26)
2
+ (31 − 26)
2
+ (36 − 26)
2
]+ h
(8 − 15) 2 + (18 − 15) 2 + (14 − 15) 2 + (17 − 15) 2 + (10 − 15) 2 + (23 − 15) 2 ]
= 184 + 142 + 260 + 152 = 738,
• s
2 w
= 738 / 20 = 36 .
9
• F = 532 / 36 .
9 = 14 .
4
Decision:
• 14 .
4 > 3 .
10, so H
0 is rejected.
(c) • SS total
= SS between
+ SS within
= 1596 + 738 = 2234
• Effect size: η
2
=
SS between
SS total
=
1596
2234
• Percentage of explained variance: η
2
= 0 .
684
× 100% = 68 .
4%.
(d) There was a significant effect of population size on telephone calls rate ( F (3 , 20) = 14 .
4, p < .
05, η
2
= 0 .
68).
3. A researcher wants to investigate the effect of different kinds of user interfaces on the usability of a website. He measures the usability by counting number of relevant items found in a specified search task. For each user interface a number of test persons are asked to perform this search task. The results are presented in the following table:
User interface
A B C D
17 24 19 24
16 17 10 18
19 18 16 26
20 29 25 21
7 32 30 35
14 33 32
19 29
Test whether the type of user interface leads to different search scores ( α = 0 .
05).
(a) Formulate the hypotheses, determine the critical F -value and formulate the corresponding decision rule.
(b) Test whether the null hypothesis must be rejected.
(c) Determine how much of the variance in search scores can be explained by the factor user interface .
(d) Report the results in text.
Page 3
Solution:
(a) Hypotheses:
• H
0
: µ
1
= µ
2
= µ
3
= µ
4
(null hypothesis)
• H
1
: at least one µ different (alternative hypothesis)
Parameters:
• N = 25, k = 4, α = 0 .
05.
Test statistic
• F = s
2 b
/s
2 w
• s
2 b
• s
2 w
=
=
SS
SS
( df between within
/
/
=
(
( k
N k −
−
−
1), k
1 , N
),
− k = 3 , 21)
• SS between
= P j
N j
( X j
− X )
2
,
• SS within
= P j
P i
( X ij
− X j
)
2
,
• F crit
= 3 .
07
Decision rule
• Reject H
0 if F obs
≥ F crit
• Do not reject H + 0 if F obs
< F crit
(b) Calculations:
•
A
17
16
19
20
7
14
19
User interface
B
24
17
18
29
32
33
29
C
19
10
16
25
30
D
24
18
26
21
35
32
X
A
= 16 X b
= 26 X
C
= 20 X
D
= 26
• X
• SS
=
7 × between
16 + 7 × 26 + 5
25
= 7 × (16 − 22) 2
× 20 + 6 × 26
=
+ 7 × (26 − 22) 2
550
= 22.
25
+ 5 × (20 − 22) 2
• s
2 b
= 480 / 3 = 160
+ 6 × (26 − 22) 2 = 480 i X iA ( X iA
− X
A
)
2 X iB ( X iB
− X
B
)
2 X iC ( X iC
− X
C
)
2 X iD ( X iD
− X
D
)
2
1 17 1 24 4 19 1 24 4
2 16 0 17 81 10 100 18 64
•
3
4
5
19
20
7
6 14
7 19
9
16
81
4
9
120
18
29
32
33
29
64
9
36
49
9
252
16
25
30
16
25
100
242
26
21
35
32
0
25
81
36
210
Page 4
• SS within
= 120 + 252 + 242 + 210 = 824,
• s
2 w
= 824 / 21 = 39 .
2,
• F obs
= 160 / 39 .
2 = 4 .
08,
• 4 .
08 > 3 .
07, so H
0 is rejected.
(c) • SS total
= SS between
+ SS within
= 480 + 824 = 1304
• Effect size: η
2
=
SS between
SS total
=
480
1304
• Percentage of explained variance: η
2
= 0 .
368
× 100% = 36 .
8%
(d) There was a significant effect of user interface on search scores ( F (3 , 21) = 4 .
08, p < .
05, η
2
= 0 .
36).
4. In a research to the effect on literacy of some group characteristic the following ANOVA table was produced:
ANOVA
Literacy
Between Groups
Within Groups
Total
Sum of Mean
Squares df Square F
3 16.42
102.50
31
(a) Fill in the remaining empty cells.
(b) Are the group means different with a significance level of 0 .
05? Explain your answer.
Solution:
(a) The cells that need to filled in are indicated in the following table as A ,. . . , E .
Literacy
Between Groups
Within Groups
Total
Sum of Mean
Squares df Square F
A 3 16.42
E
102.50
C D
B 31
• s
2 b
= 16 .
42 =
SS between k − 1
• B = SS total
= SS between
=
+
A
3
, so
SS
A within
= 3 ×
= 49 .
16 .
42 = 49
26 + 102 .
.
26,
50 = 151 .
76,
• C = 31 − 3 = 28,
• D = s 2 w
=
SS within
N − k
=
102 .
50
28
= 3 .
66,
Page 5
• E = s
2 b s 2 w
= 4 .
49.
(b) F crit
(3 , 28) = 2 .
59 ( α = 0 .
05).
F obs
= 4 .
49 > F crit
, so the null hypothesis (Group means are the same) is rejected. The group means are significantly different.
5. Distinguish between:
(a) Statistic and Parameter
(b) Sample frame and population
(c) Restricted and unrestricted sampling
(d) Convenience and purposive sampling
(e) Sample precision and sample accuracy
(f) Proportionate and disproportionate samples
Solution:
(a) A parameter is a value of a population, while a statistic is a similar value based on sample data. For example, the population mean is a parameter, while a sample mean is a statistic.
(b) A population is the total collection of people, cases, or other elements which we define and about which we wish to make inferences. The sample frame is the actual pool from which we draw our sample. Ideally it is the same as the population but it often differs due to practical considerations of information availability.
(c) Unrestricted sampling occurs when sample elements are selected individually and directly from the population at large. Restricted sampling occurs when additional controls are placed on the process of element selection.
(d) Convenience sampling is nonprobability in nature: element selection is unrestricted and carried out usually on the basis of convenience alone. Purposive sampling is also nonprobability in nature, but involves a deliberate attempt to secure a sample that conforms to some determined criteria.
(e) Sample accuracy refers to the degree to which bias is absent from the sample. An accurate sample has a balance of underestimates and overestimates among the sample members. Precision, on the other hand, refers to the degree to which random error variance is estimated to exist in that sample.
(f) A proportionate sample, particularly within the context of stratified sampling, is one where each stratum is proportionate to its share of the total population. Disproportionate samples are departures from proportionate relationships among the strata.
6. What type of experimental design would you recommend in each of the following cases? Suggest in some detail how you would design each study.
Page 6
(a) A test of three methods of compensation for factory workers. The methods are hourly wage, incentive pay and weekly salary. The dependent variable is direct labour cost per unit of output.
(b) A study of the effect of various levels of advertising effort and price reduction on the sale of branded grocery products by a retail grocery chain.
(c) A study to determine whether it is true that the use of fast-paced music played over a store’s public address system will speed up the shopping rate of customers without an adverse effect on the amount spent per customer. In your design account for different traffic levels during the day.
Solution:
(a) Probably the most appropriate design is a quasi-experiment called the non- equivalent control group. One might assume that there are three different factories (e.g. assembly plants) and each one will use a different compensation method. While the specific method assigned to each plant could be done randomly, this limited randomisation does not give much equivalency assurance. The use of the same compensation system within each plant would at least partially guard against the contamination effect that might be found if one were to try three experimental patterns within the same plant.
(b) This case calls for a factorial design since there are two variables that are being tested simultaneously. This project might call for setting up the experiment in several cities so as to achieve different levels of advertising.
(c) An approach might be to use a randomised block design in which blocking are done on time periods with different traffic levels since this may affect shopping speed. Individuals entering the store during either control or experimental study periods would be timed.
Page 7