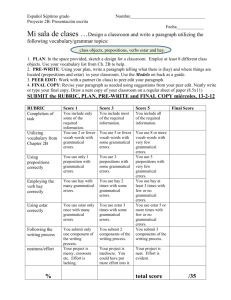
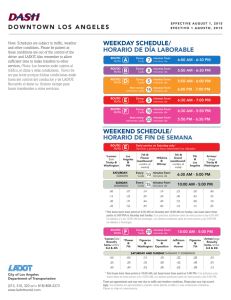
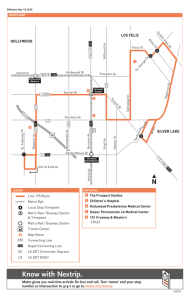
Parámetros cualimétricos de métodos analíticos que utilizan
advertisement

UNIVERSITAT ROVIRA I VIRGILI Departament de Química Analítica i Química Orgànica PARÁMETROS CUALIMÉTRICOS DE MÉTODOS ANALÍTICOS QUE UTILIZAN REGRESIÓN LINEAL CON ERRORES EN LAS DOS VARIABLES Tesis Doctoral F RANCISCO J AVIER DEL R ÍO B OCIO Tarragona, 2001 Parámetros Cualimétricos de Métodos Analíticos que Utilizan Regresión Lineal con Errores en las Dos Variables Tesis Doctoral U NIVERSITAT ROVIRA I V IRGILI UNIVERSITAT ROVIRA I VIRGILI Departament de Química Analítica i Química Orgànica Àrea de Química Analítica PARÁMETROS CUALIMÉTRICOS DE MÉTODOS ANALÍTICOS QUE UTILIZAN REGRESIÓN LINEAL CON ERRORES EN LAS DOS VARIABLES Memoria presentada por Francisco Javier del Río Bocio para conseguir el grado de Doctor en Química Tarragona, 2001 Prof. FRANCESC XAVIER RIUS I FERRÚS, Catedrático del Departament de Química Analítica i Química orgánica de la Facultat de Química de la Universitat Rovira i Virgili, y el Dr. JORDI RIU I RUSELL, Becario post doctoral del mismo Departamento, CERTIFICAN: Que la presente memoria que tiene por título: “PARÁMETROS CUALIMÉTRICOS DE MÉTODOS ANALÍTICOS QUE UTILIZAN REGRESIÓN LINEAL CON ERRORES EN LAS DOS VARIABLES”, ha sido realizada por FRANCISCO JAVIER DEL RÍO BOCIO bajo nuestra dirección en el Área de Química Analítica del Departament de Química Analítica i Química Orgánica de esta Universidad y que todos los resultados presentados son fruto de las experiencias realizadas por dicho doctorando. Tarragona, marzo de 2001 Prof. F. Xavier Rius i Ferrús Dr. Jordi Riu i Rusell AGRADECIMIENTOS Soy consciente de que los siguientes párrafos van a ser los más leidos de la Tesis. Por este motivo voy a aprovechar y mostrar mi gratitud hacia todas aquellas personas que de una manera u otra me han ayudado a poder llegar a este momento tan esperado. En primer lugar me gustaría agradecer a F. Xavier Rius el empujón que me dio en su día para entrar en este mundillo de la investigación cuando yo había dejado de creer en la química. Muchas gracias por eso y por la ayuda que me has prestado en todos estos años de trabajo. También me gustaría darle las gracias a Jordi Riu. Muchas gracias por tu ayuda, por tu colaboración pero, sobretodo, muchas gracias por ofrecerme tu amistad. Espero que te vaya muy bien en el post-doc y que a tu vuelta triunfes tanto como investigador como ... bueno, como en todo lo demás. Muchas gracias a mis compañeros del grupo de Quimiometría. Quiero empezar por los que me han acompañado en el labo 9 desde el primer día, y que me han aguantado en mis buenos y en mis malos días. Muchas gracias a Jaume (los del Burger echarán de menos al consumidor de Long Chicken, ¿eh?) y a Santi (siempre disponible para ayudar y resolver dudas en cualquier momento ...). No quiero olvidar al resto de compañeros del grupo, empezando por Ángel que es con el que he trabajado más (¡aúpa BLS!). Alicia Pulido (... anda que no hemos pasado ratos criticando a troche y moche en el pasillo, ¿eh?), a la otra Alicia (otra que tal, ¿eh?), Enric (anímate y hazte merengue, que tendrás menos disgustos, ¡hombre!), a Mari, a Toni, a Josep Lluís, a Floren, a Joan, a Ricard, a Pilar, a Marisol, a Iciar, y a todos los que han pasado por el grupo y que ya no están. De estos me gustaría hacer mención especial a Sara y Barbara; estuvisteis poco tiempo, pero habéis dejado huella, ¿eh?. No me quiero olvidar (porque no sería justo) de mis amigos. Dentro de este apartado me gustaría mencionar muy especialmente a Noe (a pesar de haberme viciado con los talladets y la carmanyola he disfrutado mucho de ellos en compañía de una gran Amiga), a Pepe (esas comidas juntos no se olvidan fácilmente, ¿eh?. Por cierto, mucha suerte en tu nueva vida) y a Fernando (¡vaya ratos hemos pasado sentados en la escalera frente a orgánica!). Entre los tres habéis aguantado todos mis malos momentos en Tarragona y me habéis ayudado a superarlos. Tampoco me quiero olvidar de Juan Antonio, Jorge, Jordi, Merche, Eva, Núria y Olga (¡ese equipazo de enólogas! que siempre me han ayudado cuando lo he necesitado), Joan (¡firrrmes!) y Eva, ni tampoco de Vanessa y otros tantos que no enumeraré porque necesitaría demasiado espacio para no dejarme a nadie. Muchas gracias a todos por ser mis amigos. No me quiero olvidar de los momentos buenos y de ocio que he pasado durante este periodo de tiempo, así que también quiero agradecer los buenos ratos que he pasado en los tres coros (el de la URV, el Mare Nostrum y el de los Paúles), tocando la flauta o en el cine. Muchas gracias a los responsables de que me queden estos buenos recuerdos: Mònica, Marisol, Arancha, Quim, Laura, ... y un muy largo etcétera. Por último quiero agradecer muchísimo el apoyo y la ayuda de toda mi familia. Empezando por la más cercana: Papá, Mamá, Carlos, Inma, Marga y Yaya, y siguiendo por los tíos y primos. Muchas gracias a todos por ser como sois, por aguantarme y por ayudarme a llegar a esto. Sólo vosotros sabéis cuánto os agradezco todo lo que me habéis dado. A la hora de agradecer normalmente se piensa en toda la gente que te ha ayudado. Sin embargo cinco años son muchos y mi memoria demasiado flaca como para estar seguro de que no me he dejado a nadie. Por este motivo, quiero dar las gracias a todos aquellos que en algún momento han pensado en mi o me han querido ayudar. Muchas gracias a todos “Pedí a Dios de todo para disfrutar de la vida y Él me dio la vida para disfrutar de todo” A Papá, Mamá, Yaya, Carlos, Inma y Marga Os quiero muchísimo Índice ÍNDICE 1 2 Introducción 1 1.1 Objetivos y justificación 3 1.2 Estructura de la Tesis 3 Fundamentos teóricos 2.1 7 Notación 2.1.1.1 Símbolos del alfabeto latino 9 10 2.1.1.2 12 Símbolos del alfabeto griego 2.2 Regresión lineal 12 2.2.1 Métodos que consideran los errores en una sola variable 15 2.2.1.1 Mínimos cuadrados ordinarios (OLS) 15 2.2.1.2 Mínimos cuadrados ponderados (WLS) 18 2.2.2 Métodos que consideran los errores en dos variables 19 2.2.2.1 Estimaciones por máxima verosimilitud 21 2.2.2.2 Estimaciones por mínimos cuadrados 25 2.2.2.3 Método de mínimos cuadrados bivariantes (bivariate least squares, BLS). 26 2.2.3 Aplicaciones de la regresión lineal considerando los errores en las variables predictora y respuesta 28 2.2.3.1 Calibración lineal 29 2.2.3.2 Comparación de métodos 29 2.3 Distribución de la población de una medida experimental 2.3.1 Distribución normal o Gaussiana 30 33 2.4 Tests estadísticos para la comprobación de la normalidad de una distribución 34 2.4.1 Test de normalidad en Cetama 34 2.4.2 Test de Kolmogorov 36 2.4.3 Gráficos de probabilidad normal 37 2.5 Predicción en regresión lineal 39 XI Índice 2.5.1 Intervalos de predicción considerando solamente los errores en la variable respuesta 39 2.5.2 Intervalos de predicción considerando los errores en las variables predictora y respuesta 44 3 2.6 Límites de detección 2.6.1 Test de hipótesis 2.6.2 Etapa de decisión 2.6.3 Etapa de detección 45 47 47 48 2.7 Regresión lineal en presencia de puntos discrepantes 2.7.1 Técnicas de detección de puntos discrepantes 2.7.2 Robustez en regresión lineal 51 52 53 2.8 Simulación de Monte Carlo 56 2.9 Referencias 57 Normalidad de los coeficientes de regresión 3.1 Introducción 3.2 Detecting proportional and constant bias in method comparison studies by using linear regression with errors in both axes 4 65 67 69 3.3 Conclusiones 96 3.4 Referencias 96 Predicción en BLS 4.1 Introducción 99 101 4.2 Prediction intervals in linear regression taking into account errors on both axes 104 5 4.3 Conclusiones 133 4.4 Referencias 134 Límite de detección en BLS 5.1 XII Introducción 137 139 Índice 5.2 concentration 6 Limits of detection in linear regression with errors in the 142 5.3 Conclusiones 163 5.4 Referencias 164 Regresión lineal en presencia de puntos discrepantes 6.1 Introducción 6.2 Detección de puntos discrepantes 6.2.1 Introducción 6.2.2 Outlier detection in linear regression taking into account errors in both axes 6.2.3 Comprobación de la aplicación del criterio gráfico 165 167 169 169 172 190 6.3 Regresión robusta 195 6.3.1 Introducción 195 6.3.2 Robust linear regression taking into account errors in both axes 6.3.3 BLMS 6.3.4 197 Comparación de diversos algoritmos de cálculo de la recta 213 Robustez de la recta BLS 214 6.4 Protocolo de actuación en regresión lineal en presencia de puntos discrepantes 217 6.4.1 Introducción 217 6.4.2 Linear regression taking into account errors in both axes in presence of outliers 218 7 6.5 Conclusiones 234 6.6 Referencias 236 Conclusiones 239 7.1 Conclusiones 241 7.2 Perspectivas futuras 244 XIII Índice 8 Anexos 247 8.1 Anexo 1. Comparación de los métodos OLS, WLS y BLS 249 8.1.1 Comparación de las rectas de regresión obtenidas con los métodos OLS, WLS y BLS 249 8.1.2 Comparación de los métodos OLS, WLS y BLS 250 8.1.3 Referencias 254 8.2 Anexo 2. Presentaciones en congresos Índice temático XIV 255 257 1 Capítulo Introducción 1.1 Objetivos y justificación 1.1 Objetivos y justificación En el presente trabajo se pretende ampliar el conocimiento existente sobre la comparación de métodos analíticos y la calibración lineal, mediante la utilización de la técnica de regresión de mínimos cuadrados bivariantes (BLS, bivariate least squares) en la que se consideran los errores experimentales individuales asociados a las variables predictora y respuesta, incidiendo especialmente en las características cualimétricas de las metodologías que utilizan la regresión lineal con errores en las dos variables. Con esta finalidad se han planteado los siguientes objetivos principales: 1.- Estudio y caracterización de las distribuciones de los coeficientes de regresión (ordenada en el origen y pendiente) encontrados mediante el método BLS con el fin de conocer qué tipo de tests estadísticos derivados se deben aplicar en el campo de la química analítica. 2.- Desarrollo de las expresiones para el cálculo de las varianzas asociadas a la predicción tanto de la variable predictora como de la variable respuesta utilizando los errores cometidos en ambas variables. 3.- Cálculo del límite de detección de una metodología analítica en que la recta de calibración se construye mediante el método de BLS. 4.- Establecer el procedimiento que se ha de seguir ante la posible presencia de puntos discrepantes en una recta de regresión considerando los errores en las dos variables, desarrollando para ello un método de regresión robusto y un criterio gráfico para la detección de puntos discrepantes. 1.2 Estructura de la Tesis La presente Tesis Doctoral se estructura de la siguiente forma: 3 1. Introducción • Capítulo 1. Este capítulo incluye una descripción de los objetivos de la Tesis Doctoral, incluyendo una breve justificación de los mismos. Este segundo apartado intenta clarificar la estructura de la Tesis. • Capítulo 2. El segundo capítulo pretende recoger los fundamentos teóricos que se han utilizado en el desarrollo de la presente Tesis Doctoral. En cada caso se ha pretendido hacer una revisión bibliográfica de los precedentes, pasando posteriormente a una descripción de los métodos más utilizados en cada uno de los campos desarrollados. Tras una introducción a la notación (sección 2.1) utilizada en el resto de la Tesis Doctoral, los demás apartados de este capítulo pretenden ilustrar cada uno de los temas que se tratan en ella. Así, por ejemplo, el siguiente apartado (2.2) es el más general, pues incluye un estudio de los diversos métodos de regresión que se han utilizado a lo largo del tiempo, tanto considerando los errores en una como en dos variables. De estos últimos, el método de BLS se explica con más detenimiento pues será el utilizado en el resto del trabajo. Los siguientes apartados explican el estado actual de otros aspectos tratados en el presente trabajo, tales como la normalidad de las distribuciones y los diversos tests existentes para su determinación (apartados 2.3 y 2.4), una introducción a los diferentes métodos de cálculo de los intervalos de predicción (apartado 2.5), un estudio de los diferentes criterios utilizados para el cálculo de los límites de detección, incluyendo las definiciones básicas necesarias para su comprensión (apartado 2.6) y una revisión bibliográfica de los métodos de regresión robusta y de detección de puntos discrepantes (apartado 2.7). El último apartado de este capítulo hace una breve introducción al método de Monte Carlo que se utiliza en varios capítulos de esta Tesis Doctoral. • Capítulos 3-6. En estos capítulos se presenta el núcleo del trabajo realizado en esta Tesis Doctoral. En todos los casos se presentan los resultados en forma de artículos publicados en revistas científicas de difusión internacional. La estructura de los capítulos empieza con una breve introducción a la investigación incluida en el artículo con el fin de contextualizar su contenido. A continuación se presenta cada uno de los artículos, para finalmente presentar las conclusiones a 4 1.2 Estructura de la Tesis cada uno de los artículos destinadas a enlazar los contenidos presentados en cada capítulo. En el tercer capítulo se presenta un estudio realizado sobre las distribuciones de los coeficientes de regresión, con el fin de comprobar si pueden ser asimiladas a una distribución normal. El cuarto capítulo incluye el desarrollo de las expresiones para el cálculo de los intervalos de predicción, mientras que en el quinto se utilizan estos mismos intervalos para encontrar el límite de detección cuando se consideran los errores experimentales en las variables predictora y respuesta. El sexto capítulo presenta una discusión cuyo principal objetivo es la búsqueda de la mejor recta de regresión cuando se consideran los errores en las dos variables en presencia de puntos discrepantes. • Capítulo 7. En este capítulo se enumeran las conclusiones extraídas a partir de los objetivos que se han planteado inicialmente para la presente Tesis Doctoral. • Capítulo 8. Este capítulo incluye una serie de anexos. En ellos se presentan algunos cálculos que por su longitud o complejidad se ha considerado que no se debían incluir en los capítulos anteriores. En el último apartado de este capítulo se citan las participaciones que se han presentado en congresos como consecuencia del trabajo realizado en esta Tesis Doctoral. Todas las simulaciones y programas definidos a lo largo de la presente Tesis Doctoral se han llevado a cabo utilizando el programa Matlab1, que es un entorno matemático destinado a simplificar el cálculo matricial. 5 2 Capítulo Fundamentos teóricos 2.1 Notación Este segundo capítulo intenta dar una noción general de los aspectos teóricos utilizados en el resto de la Tesis Doctoral. En primer lugar, y tras un apartado dedicado a aclarar la notación utilizada, se dan unas nociones básicas sobre la regresión lineal, para profundizar finalmente en la regresión lineal considerando los errores en las dos variables, y más concretamente en el método de los mínimos cuadrados bivariantes (bivariate least squares, BLS), que será utilizado como base en todos los capítulos de la presente Tesis Doctoral. A continuación se citarán las principales aplicaciones de la regresión lineal, con el fin de introducir conceptos que a continuación se irán adaptando para el caso en que se consideran los errores experimentales en las variables predictora y respuesta. En concreto se explicarán brevemente los diferentes tests para el estudio de la normalidad de distribuciones, el cálculo de los intervalos de predicción y del límite de detección y las diferentes aplicaciones existentes para la regresión lineal en presencia de puntos discrepantes cuando se tienen en cuenta los errores en las variables predictora y respuesta. 2.1 Notación En general, los valores verdaderos de las diferentes variables usadas a lo largo de este trabajo se representan por caracteres griegos, mientras que sus estimaciones se representan por caracteres latinos. De esta forma, los valores de los coeficientes de regresión están representados por β0 (ordenada en el origen) y β1 (pendiente), mientras que sus respectivas estimaciones se representan por b0 y b1. Por otra parte, las predicciones de las variables experimentales se definen con un acento circunflejo ( ŷi ). Las matrices se representan por una letra mayúscula en negrita (como por ejemplo la matriz de puntos experimentales de la variable predictora X), los vectores por una letra minúscula en negrita (por ejemplo el vector b de los coeficientes de la recta de regresión), y las variables y escalares por una letra en cursiva (por ejemplo la estimación de la ordenada en el origen, b0). A lo largo de la presente Tesis Doctoral la notación decimal sigue la norma anglosajona de separar con puntos los números decimales. Se ha tomado esta decisión para homogeneizar la presentación de los resultados, teniendo en cuenta 9 2. Fundamentos teóricos que la mayoría de ellos se presentan en forma de artículos en publicaciones internacionales, donde se exige la utilización de esta norma. A continuación se enumeran los símbolos más utilizados a lo largo de la Tesis Doctoral. 2.1.1.1 Símbolos del alfabeto latino ar Momento adimensional centrado de orden r de una distribución b0 Estimación de la ordenada en el origen de la recta de regresión b1 Estimación de la pendiente de la recta de regresión b Vector de las estimaciones de los coeficientes de regresión e Vector de las estimaciones de los residuales de la variable respuesta f dist Función de probabilidad de una distribución Estimación del coeficiente i de Fisher (i=1,2) fi F(p,n-p,1-α) Valor aleatorio perteneciente a una distribución F H0 Hipótesis nula H1 Hipótesis alternativa k xi Coeficiente de fiabilidad L Valor real en términos de concentración o señal neto L̂ Cantidad estimada en términos de concentración o señal neto LC Valor crítico en términos de concentración o señal neto LD Límite de detección en términos de concentración o señal neto LR Límite normativo en términos de concentración o señal neto M Función de probabilidad en regresión por máxima verosimilitud m m Número de puntos que forman una distribución 0 r Momento de orden r de una distribución mr Momento centrado de orden r de una distribución n Número de puntos experimentales p Número de parámetros que deben ser estimados en un modelo pi Estimación del coeficiente i de Pearson (i=1,2) q Número de repeticiones del análisis de una muestra S Suma del cuadrado de los residuales de la recta de regresión 10 2.1 Notación s2 Estimación del error experimental de la recta de regresión s 02 Estimación de la varianza al nivel de concentración cero sb20 Estimación de la varianza de la ordenada en el origen de la recta de regresión sb21 Estimación de la varianza de la pendiente de la recta de regresión 2 s dist Estimación de la varianza de una distribución s D2 Estimación de la varianza al nivel de concentración del límite de detección s δ2 Estimación de la varianza relacionada con el error de la variable predictora s e2 Estimación de la varianza del error instrumental se2i Estimación de la varianza del i-ésimo residual s ε2 Estimación de la varianza relacionada con el error de la variable respuesta s y2i Estimación de la varianza de la variable respuesta en el punto i t α,ν Valor aleatorio perteneciente a una distribución t de Student V Matriz diagonal con las varianzas experimentales de la variable respuesta W Matriz diagonal con los pesos (wi) wi Coeficiente de ponderación del punto i X Matriz de la variable predictora xi Valor medido de la variable predictora en el punto i x̂i Valor predicho de la variable predictora en el punto i x Valor medio de los valores experimentales de la variable predictora x p Valor medio ponderado de los valores experimentales de la variable predictora Y Matriz de la variable respuesta yi Valor medido de la variable respuesta en el punto i ŷi Valor predicho de la variable respuesta en el punto i y Valor medio de los valores experimentales de la variable respuesta y p Valor medio ponderado de los valores experimentales de la variable respuesta zα Valor aleatorio perteneciente a una distribución normal 11 2. Fundamentos teóricos 2.1.1.2 Símbolos del alfabeto griego α Nivel de significancia; Probabilidad de cometer un error de primera especie; falso positivo β Probabilidad de cometer un error de segunda especie; falso negativo β0 Valor verdadero de la ordenada en el origen de la recta de regresión β1 Valor verdadero de la pendiente de la recta de regresión δi Error aleatorio asociado al punto i en la variable predictora εi Valor del residual en el punto i γi Error aleatorio asociado al punto i en la variable respuesta ηi Valor verdadero de la variable respuesta en el punto i ϕi Coeficiente i de Fisher (i=1,2) λ Relación de varianzas de las variables respuesta y predictora µ dist Valor medio real de una distribución ν Número de grados de libertad πi Coeficiente i de Pearson (i=1,2) σ Valor verdadero del error experimental de la recta de regresión 2 σ 02 Varianza al nivel de concentración cero σ 2D Varianza al nivel de concentración del límite de detección 2 σ dist Varianza asociada a una distribución σ 2xi Varianza de la variable predictora en el punto i σ 2yi Varianza de la variable respuesta en el punto i ξi Valor verdadero de la variable predictora en el punto i 2.2 Regresión lineal La regresión se considera como un conjunto de técnicas estadísticas utilizadas para estudiar las relaciones existentes entre varias variables. La regresión lineal es un caso particular de la regresión en que las relaciones entre las variables pueden definirse mediante una línea recta o por generalizaciones de una línea recta a diferentes dimensiones. Estas técnicas se utilizan en muchos campos, entre los 12 2.2 Regresión lineal que se pueden citar las ciencias sociales, la física, la biología, la economía, la tecnología o las humanidades. Un ejemplo de utilización en el campo de la química es la absorción de una muestra coloreada a una determinada longitud de onda, cuya relación con la concentración se mide a partir de la ley de Lambert-Beer. Al tomar un conjunto de valores de una de las variables y hacer una transformación sobre la otra variable, su dispersión aumenta, mientras que su valor medio es más próximo a la media de la distribución, y lo hará en mayor o menor medida dependiendo de la correlación entre las variables.2 Por este motivo se dice que se produce un fenómeno de ”retroceso” o de “vuelta atrás”. De ahí se introduce el concepto de “regresión”. El primero en utilizarlo fue Galton3 (1887) que observó que los hijos de padres altos tienden a ser menos altos y los hijos de padres bajos a ser menos bajos. Se producía una regresión hacia la media de la población. Hoy se sigue manteniendo este término, aunque su significado original de “retroceso” hacia algún promedio estacionario no está necesariamente implicado. La regresión lineal univariante considera el caso particular en que se pretende conocer la relación lineal entre dos variables, y postula que la relación entre el valor i de la variable predictora (ξ) y el valor i de la variable respuesta (η) se expresa:4-6 ηi = β 0 + β1ξ i (2.1) donde β 0 y β1 son la ordenada en el origen y la pendiente que definen la recta que relaciona las variables predictora y respuesta reales. Sin embargo, debido a que experimentalmente no pueden obtenerse exactamente los valores de las variables reales ξi y ηi, únicamente se puede utilizar una estimación de dichas variables (xi e yi respectivamente). La relación entre los valores verdaderos y los experimentales de los coeficientes de regresión puede expresarse de la siguiente manera:7 xi = ξ i + δ i (2.2) y i = ηi + γ i (2.3) 13 2. Fundamentos teóricos donde δi y γi representan los errores aleatorios asociados a la medida de las variables observables, de manera que: δ i ~ N(0, σ 2xi ) y γ i ~ N(0, σ 2yi ) ,5 donde N indica que las variables siguen una distribución con las medias y varianzas indicadas dentro del paréntesis, tal como se verá posteriormente en la sección 2.3.1. Introduciendo estas ecuaciones en la ecuación 2.1, y aislando la variable yi se obtiene la siguiente expresión:4,8,9 yi = β 0 + β1 xi + ε i (2.4) Esta ecuación representa la ecuación de la recta de regresión verdadera a partir de los valores experimentales de las dos variables. El término εi es el error residual verdadero del i-ésimo punto cumpliendo ε i ~ N(0, σ ε2i ) ,10 y que puede expresarse como función de las variables γi, β1 y δi.5 ε i = γ i − β1δ i (2.5) De esta forma, las variables observadas se relacionan entre sí de la siguiente forma: yi = b0 + b1 xi + ei (2.6) donde ei es el error residual del punto i, mientras que b0 y b1 son la ordenada en origen y la pendiente que definen la recta de regresión que relaciona entre sí las variables observadas. Debido a la simplicidad de su utilización, la ecuación anterior también puede presentarse en forma matricial: y = Xb + e 2 1 y n 14 X n 1 1 b = (2.7) 2 + e n 2.2 Regresión lineal donde el vector y, de dimensión n contiene los valores de la variable respuesta, mientras que la matriz X, de dimensión nx2, la forman: una primera columna de unos y una segunda con los valores de la variable predictora. El vector b, de dimensión 2, representa los dos coeficientes de regresión, y e es un vector de dimensión n que incluye los valores de los residuales de la variable respuesta. El uso de matrices tiene una serie de ventajas, de forma que cuando un problema de regresión se soluciona en forma matricial, la solución puede aplicarse a cualquier problema de regresión sin tener en cuenta el número de términos que incluya. Para encontrar las estimaciones de los coeficientes de la recta que relaciona las variables reales, se han desarrollado una gran cantidad de métodos. Algunos de ellos se describen a continuación. 2.2.1 Métodos que consideran los errores en una sola variable La calibración es uno de los pasos que, generalmente, deben aplicarse en un análisis químico, y suele asociar a la variable predictora la concentración de los patrones de calibrado, y a la variable respuesta los valores de la medida instrumental. Generalmente, el error asociado a la preparación de los patrones es mucho menor que el asociado a la medida instrumental. Por este motivo, se suelen utilizar técnicas de regresión lineal univariantes que únicamente consideran los errores asociados a la variable respuesta. De los métodos de regresión que consideran los errores en una sola variable hay que destacar los métodos de mínimos cuadrados ordianarios (ordinary least squares, OLS) y mínimos cuadrados ponderados (weighted least squares, WLS) que se explican a continuación. 2.2.1.1 Mínimos cuadrados ordinarios (OLS) Se considera que el método de mínimos cuadrados ordinarios se descubrió independientemente por Carl Friedrich Gauss y Adrien Marie Legendre, que Gauss lo utilizó antes de 1803 y que la primera publicación corresponde a 15 2. Fundamentos teóricos Legendre el año 1805. Por este motivo, el descubrimiento del método de OLS ha llevado siempre asociada una dura controversia.11-14 Rigurosamente, para poder utilizar el método de OLS, deben cumplirse las siguientes condiciones:15 - El error, expresado en términos de varianza, para cada valor de la variable respuesta debe ser mucho mayor que el correspondiente a la varianza de la variable predictora multiplicado por el cuadrado de la pendiente. σ 2yi >> σ 2xi b12 ⇒ σ 2xi ≈ 0 (2.8) - Las varianzas de los valores de la variable respuesta deben ser constantes a lo largo de todo el intervalo de linealidad (homoscedasticidad). σ 2yi = σ 2y j ∀i, j (2.9) - Los errores asociados a la variable respuesta deben ser mutuamente independientes. Si se cumplen estas condiciones, los valores de la ordenada en el origen y la pendiente obtenidas mediante el método de OLS dan lugar a las estimaciones más precisas no sesgadas de la ordenada en el origen y de la pendiente.4,16,17 Para encontrar las expresiones de la ordenada en el origen y la pendiente, el método de OLS minimiza la suma de los cuadrados de los residuales de los puntos experimentales a la recta de regresión: n S= ∑ i =1 ei2 = n n i =1 i =1 ∑ ( yi − yˆ i )2 = ∑ ( yi − b0 − b1 xi )2 (2.10) El cálculo de los coeficientes de regresión, consistirá en igualar a cero las derivadas parciales de S respecto a la ordenada y la pendiente: n ∂ 2 ( yi − b0 − b1 xi ) = 0 ∂b0 i =1 ∑ 16 (2.11) 2.2 Regresión lineal n ∂ 2 ( yi − b0 − b1 xi ) = 0 ∂b1 i =1 ∑ (2.12) Desarrollando las expresiones 2.11 y 2.12 se obtienen las estimaciones de la ordenada en el origen y de la pendiente de la recta de regresión de OLS: n n ∑ ∑ xi2 b0 = i =1 yi − i =1 n n ∑ i =1 b1 = n ∑ ∑x y xi i i =1 x − 2 i n n n ∑ n ∑ i =1 xi y i − i =1 n n ∑ i =1 = y − b1 x xi n ∑ ∑y x − (2.13) n xi i =1 2 i i i =1 2 i i =1 n ∑ i =1 xi (2.14) 2 donde x e y representan el valor medio de las variables predictora y respuesta respectivamente y el punto ( x, y ) corresponde al centroide de la recta de regresión, que tiene la propiedad de pertenecer a la recta OLS. Mediante la expresión matricial (ecuación 2.15), OLS permite encontrar los coeficientes de regresión: b = ( X' X) −1 X' y (2.15) Si los errores son independientes y se cumple que ε i ~ N(0, σ ε2i ) , b es una solución de máxima verosimilitud, es decir, que minimizar la suma del cuadrado de los residuales es equivalente a maximizar la función de probabilidad: n M= n ∏ i =1 −1 / 2 σ 2 ∑ ε i2 2 2 1 1 i =1 e −εi / 2 σ = e σ(2π)1 / 2 σ n ( 2 π) n / 2 (2.16) 17 2. Fundamentos teóricos 2.2.1.2 Mínimos cuadrados ponderados (WLS) En ciertos casos algunas de las observaciones instrumentales asociadas a algunos puntos experimentales en regresión lineal son más fiables que otras. Esta característica del conjunto de datos implica que los errores asociados a la variable respuesta no son siempre iguales, o lo que es lo mismo, se debe considerar heteroscedasticidad en la variable respuesta. El método de WLS permite la existencia de heteroscedasticidad en la variable respuesta, si bien los errores entre sus valores no pueden estar correlacionados.15,18 El método WLS minimiza la suma de los cuadrados de los residuales ponderados expresados de la siguiente forma: S= n ∑ i =1 n ( yi − b0 − b1 xi ) ei2 = wi i =1 wi ∑ 2 (2.17) donde wi (factor de ponderación) se corresponde con la varianza experimental asociada a cada punto en la variable respuesta ( s 2yi ). De esta forma, tienen más influencia sobre la recta aquellos puntos cuyos errores en la variable respuesta sean menores. Procediendo de la misma forma que en OLS, se obtienen las expresiones de la ordenada en el origen y de la pendiente: xi2 ⋅ wi n b0 = ∑ i =1 n ∑ i =1 ∑ i =1 i =1 n ∑ i =1 1 ⋅ wi n ∑ i =1 18 yi − wi ∑ 1 ⋅ wi n b1 = n n ∑ i =1 x − wi 2 i n ∑ i =1 1 ⋅ wi xi ⋅ wi n ∑ i =1 xi y i − wi n ∑ i =1 n i =1 xi wi n ∑ i =1 x − wi 2 i yi ∑w i 2 xi ⋅ wi n ∑ i =1 = y p − b1 x p n ∑ i =1 xi wi xi y i wi 2 (2.18) (2.19) 2.2 Regresión lineal donde x p y y p son la media ponderada de las variables predictora y respuesta respectivamente: n xp = i =1 n i ∑ 1 wi n yi i =1 yp = xi ∑w ∑w i =1 n ∑ i =1 i 1 wi (2.20) (2.21) ( x p , y p ) definen el centroide ponderado, punto por el que pasa la recta de regresión obtenida mediante el método WLS. Utilizando la notación matricial, la estimación de los coeficientes de regresión pueden encontrarse según la siguiente ecuación: b = ( X' V −1 X) −1 X' V −1y (2.22) donde V es una matriz diagonal de dimensión nxn, que incluye los valores de la varianza experimental de la variable respuesta ( s y2i ). 2.2.2 Métodos que consideran los errores en dos variables Las hipótesis necesarias para utilizar los métodos de OLS y WLS no siempre se cumplen. Así, por ejemplo, debido a los avances tecnológicos, cada vez es más fácil encontrar casos en que el error asociado a la medida instrumental ha disminuido tanto que su valor no puede despreciarse frente al asociado a la preparación de patrones. Esto ocurre, por ejemplo, en análisis que utilizan técnicas de absorción o emisión atómica19 pues tienen asociado un error que en muchos casos es al menos comparable al asociado a la preparación de los patrones. Existen otras técnicas analíticas, como por ejemplo la fluorescencia de rayos X,20 donde 19 2. Fundamentos teóricos debido a la complejidad de las muestras reales (por ejemplo muestras geológicas), la recta de calibración se suele construir utilizando materiales de referencia certificados del analito de interés en vez de los patrones puros. En este caso, cada material de referencia presenta un error asociado a la concentración,21-24 cuyo valor normalmente no es despreciable frente a los errores asociados a la respuesta instrumental. Otro caso similar son los análisis que se basan en las técnicas de datación por radiocarbono,25,26 donde los errores asociados a la variable predictora suelen ser grandes y, por tanto, difícilmente despreciables frente a los cometidos en la variable respuesta. Esto mismo ocurre al utilizar la regresión lineal para realizar una comparación de métodos analíticos a diferentes niveles de concentración, pues al representar los resultados de analizar una serie de muestras con dos métodos diferentes, los errores asociados a cada uno de ellos suelen ser de un orden de magnitud similar. Por este motivo, en estos casos es necesario utilizar técnicas de regresión que consideran los errores asociados a las dos variables.4,5 Si se utiliza el método de mínimos cuadrados para obtener la recta de regresión sobre alguno de estos casos en que los errores en la variable predictora son, al menos, del mismo orden de magnitud que en la variable respuesta, los coeficientes de regresión se obtendrán sesgados. Este sesgo vendrá determinado por el factor entre el valor verdadero y observado de la varianza de la variable predictora. Este factor se llama coeficiente de fiabilidad y se define según la siguiente expresión: k xi = σ 2xi s x2i (2.23) Por este motivo se han desarrollado una serie de técnicas para encontrar la recta de regresión teniendo en cuenta los errores cometidos en las dos variables. Dichos métodos se han clasificado en dos grupos dependiendo del proceso seguido para obtener sus coeficientes. El primero de ellos son métodos de máxima verosimilitud, mientras que el segundo lo conformarán los métodos de mínimos cuadrados. 20 2.2 Regresión lineal 2.2.2.1 Estimaciones por máxima verosimilitud Una estimación por máxima verosimilitud pretende encontrar los coeficientes de regresión con máxima probabilidad de ser iguales a los verdaderos. Para ello estos estimadores maximizan la función de probabilidad de los coeficientes. De esta forma, las predicciones de la variable respuesta serán aquellas que presenten una máxima probabilidad de ser iguales a las verdaderas. Los métodos de máxima verosimilitud asumen que las dos variables son inobservables y que se pueden medir solo aquellas que están afectadas por errores aleatorios. En este sentido, pueden distinguirse, básicamente, tres tipos de modelos con errores en las medidas dependiendo de las asunciones realizadas sobre los valores de la variable predictora:5,27 - Modelo funcional, que supone los valores de la variable predictora ( ξi ) como constantes desconocidas. - Modelo estructural, que considera los valores de la variable predictora como variables aleatorias independientes distribuidas idénticamente e independientes de sus errores experimentales. - Modelo ultraestructural,5,28 que asume que los valores de la variable predictora son variables aleatorias independientes (como en el modelo estructural), pero no distribuidas idénticamente, además de tener la posibilidad de poseer diferentes medias ( µ i ) y una varianza común ( σ 2 ). De entre los modelos presentados, los funcionales son los más apropiados para el caso del análisis químico, pues los valores de la variable predictora (concentraciones en el caso de una calibración o resultados analíticos en el caso de una comparación de métodos), suelen asociarse con valores desconocidos correspondientes a los diversos niveles de concentración de los analitos. Por este motivo, en adelante trataremos con detenimiento el caso del modelo funcional dejando de lado los otros dos modelos descritos. 21 2. Fundamentos teóricos En la bibliografía se encuentran seis asunciones que pueden realizarse con el fin de encontrar la recta de máxima verosimilitud en el caso de tener en cuenta los errores en las dos variables. Estos son: a) La relación de los errores de las varianzas ( λ = σ 2xi σ 2yi ) es conocida. b) El coeficiente de fiabilidad ( k xi ) es conocido. c) σ 2xi son conocidas. d) σ 2yi son conocidas. e) Los valores de las varianzas de las dos variables σ 2xi y σ 2yi son conocidas. f) La ordenada en el origen ( β 0 ) es conocida. Existe cierta confusión en la bibliografía acerca de la consistencia de las estimaciones de máxima verosimilitud para el modelo funcional. En el caso en que se conoce la relación de las varianzas (caso a), el estimador de los coeficientes de regresión es consistente. Sin embargo, el estimador de una varianza desconocida no lo es. En los casos c y d las estimaciones de máxima verosimilitud fallan en la consistencia de los parámetros encontrados. El motivo principal es que las estimaciones de máxima verosimilitud tienen problemas cuando el número de parámetros de incidencia aumenta con el tamaño de muestra. Por este motivo, la consistencia de los resultados se puede considerar como un efecto aleatorio en el caso de conocer la relación de las varianzas en las dos variables.5 En el caso de conocerse las varianzas asociadas a las dos variables (caso e) es equivalente al ya comentado de conocerse la relación entre las mismas. La única diferencia consistiría en que en el último caso no deberá estimarse ninguna de las varianzas experimentales. El caso b en el que se supone conocido el factor de fiabilidad es un caso que no tiene demasiado sentido en el caso del modelo funcional, pues la fiabilidad no está bien definida para este tipo de modelo. Esta situación se resolvió cuando Gleser29 introdujo una definición más general de la fiabilidad. El último caso (caso f) en que se conoce la ordenada en el origen también conduce a estimaciones no consistentes, que únicamente podrían serlo bajo el modelo 22 2.2 Regresión lineal estructural, del que ya se ha comentado que queda fuera de los objetivos de la presente Tesis Doctoral. A continuación se estudia la regresión bajo las asunciones en que el modelo funcional obtiene estimaciones consistentes de máxima verosimilitud, que son aquellas en que se conoce la relación de las varianzas de las variables predictora y respuesta, y cuyos resultados son equivalentes a utilizar el modelo estructural. A esta regresión se la conoce como relación constante de varianzas. Método de la relación constante de varianzas (constant variance ratio, CVR). El problema de la regresión lineal cuando se consideran los errores en las variables predictora y respuesta data de finales del siglo XIX, siendo Adcock30,31 la primera persona que trató el problema de la regresión cuando se consideran los errores en ambas variables. El método desarrollado por Adcock suponía que las varianzas de las variables predictora y respuesta son iguales y es conocido como el método de la regresión ortogonal (orthogonal regression, OR). Este método se ha reinventado en varias ocasiones y en diversas disciplinas.32-35 Entre estos redescubrimientos el método de la regresión ortogonal también se ha renombrado de diversas maneras, tales como regresión de la distancia ortogonal (orthogonal distance regression, ODR)36 o como método de mínimos cuadrados totales (total least squares, TLS)37,38. Más adelante Kummel39 (1879) extendió los resultados de Adcock al caso en que se conoce la relación entre las varianzas. Esta extensión se conoce por el nombre de método de la relación constante de varianzas (constant variance ratio, CVR). La relación entre las varianzas experimentales de las variables respuesta ( s 2yi ) y predictora ( s x2i ) se representa por la siguiente expresión: λ= s y2i s x2i (2.24) En el caso particular de la regresión ortogonal, la relación entre las varianzas es la unidad, y por tanto se cumple que λ=1. Una de las principales aplicaciones de la recta de regresión obtenida mediante el método de OR es que ésta coincide con el primer componente principal en el análisis por componentes principales (PCA, principal component analysis).17 23 2. Fundamentos teóricos Debido a que el método de CVR es un método de máxima verosimilitud con los errores de la variable predictora siguiendo un modelo funcional, para encontrar los coeficientes de la recta de regresión se deberá maximizar la función de probabilidad M: n − −1 M ∝ λ 2 σ −x 2 n exp 2 2σ x n ∑ (x i − ξi ) 2 + i =1 n ∑(y i =1 i − β 0 − β1ξ i ) 2 (2.25) donde el símbolo de proporcionalidad aparece debido a que se ha omitido la constante de normalización. En el caso de la regresión ortogonal, a partir de las ecuaciones 2.2 y 2.3 puede observarse cómo maximizar la función de probabilidad es equivalente a minimizar la suma del cuadrado de las distancias ortogonales de cada uno de los puntos a la recta de regresión. Las expresiones de la ordenada en el origen y la pendiente (donde se asume que la correlación entre la variable predictora y la variable respuesta es nula) obtenidas según la aproximación desarrollada por Mandel40 son las siguientes: b1 = S yy − λ S xx + (S yy − λ S xx )2 + 4 λ S xy2 2S xy b0 = y − b1 x (2.26) (2.27) donde Sxx, Sxy y Syy son sumatorios de los datos experimentales: n S xx = ∑ (x − x ) 2 i (2.28) i =1 n S yy = ∑ (y − y) 2 i (2.29) i =1 n S xy = ∑ (x − x)(y i i =1 24 i − y) (2.30) 2.2 Regresión lineal 2.2.2.2 Estimaciones por mínimos cuadrados Algunos autores han desarrollado procedimientos para estimar los coeficientes de la recta de regresión basados en una aproximación de máxima verosimilitud cuando están presentes errores en las dos variables.4,6,41,42 En la mayoría de los casos, estos métodos requieren modelar cuidadosamente la variable predictora.41 Sin embargo, esta situación no suele ser posible en análisis químicos, donde los valores verdaderos de la variable predictora ( ξi ) no se suelen distribuir aleatoriamente (es decir, se asumen modelos funcionales5). Además, existen casos en los que el comportamiento de los datos experimentales es heteroscedástico, y las estimaciones de los errores de medida únicamente pueden obtenerse a partir de réplicas en el análisis (es decir que la relación σ xi σ yi es no constante, o incluso desconocida). Estas condiciones, comunes en los datos químicos, hacen muy complicada la aplicación rigurosa del principio de máxima verosimilitud para estimar los coeficientes de la recta de regresión. Por otra parte, Sprent10 presentó un método para estimar los coeficientes de la recta de regresión utilizando una aproximación de máxima verosimilitud, incluso considerando el modelo como funcional. Sin embargo este método no es rigurosamente aplicable cuando se consideran los errores heteroscedásticos individuales en cada punto experimental. Además, puede comprobarse que cuando se asume σ xi = λσ yi para cada valor de i, los métodos basados en la aproximación de mínimos cuadrados obtienen los mismos resultados de los coeficientes de regresión que los basados en el principio de máxima verosimilitud.43 Por todas estas razones, para llevar a cabo este trabajo, se ha elegido un método iterativo basado en la aproximación de mínimos cuadrados, ya que éstos métodos pueden utilizarse sobre cualquier conjunto de datos sin hacer asunciones acerca de las distribuciones de probabilidad que tienen asociados.43 Esto permite la aplicación de este método en casos químicos reales cuando se consideran los errores individuales heteroscedásticos en las variables predictora y respuesta. De todos los métodos de regresión que consideran los errores heteroscedásticos en las dos variables basados en el principio de mínimos cuadrados44-52 el seleccionado para este trabajo es el método de Lisý, también conocido como método BLS53,54, debido sobretodo a su rapidez en la correcta 25 2. Fundamentos teóricos obtención de los coeficientes de regresión (la matriz varianza-covarianza se obtiene de una forma sencilla), así como a la simplicidad de la programación del algoritmo. 2.2.2.3 Método de mínimos cuadrados bivariantes (bivariate least squares, BLS). El método de BLS considera que las variables experimentales xi e yi se expresan como función de las variables predictora y respuesta reales según las ecuaciones 2.2 y 2.3. El término ei es el valor residual que aparece en la ecuación 2.6 y se define como el error individual asociado al punto i del conjunto de datos. La varianza de ei es se2i y se considerará a partir de ahora como factor de ponderación (wi). En el método BLS, este parámetro considera las varianzas de cada punto individual en las dos variables ( s x2i y s 2yi ) obtenidas a partir de réplicas del análisis. La covarianza entre las variables para cada punto (xi, yi), que normalmente se asume que es nula, también se considera: wi = se2i = s 2yi + b12 s x2i − 2b1 cov( xi , yi ) (2.31) El método de regresión de BLS encuentra las estimaciones de los coeficientes de regresión minimizando la suma de los residuales ponderados, S, expresados en la ecuación 2.32: S= n ( xi − xˆ i ) 2 ( y i − yˆ i ) 2 n ei2 + = = 2 s y2i i =1 wi s xi ∑ i =1 ∑ n ∑ i =1 ( y i − yˆ i ) 2 =(n − 2) s 2 (2.32) wi donde n es el número de datos experimentales, x̂i e ŷi representan el valor predicho para los valores xi e yi experimentales y s 2 es la estimación de la varianza experimental. Minimizando la suma de los residuales ponderados, expresados en la ecuación 2.32, con respecto a la ordenada en el origen y a la pendiente, e incluyendo las derivadas parciales de los cuadrados de los residuales, se obtienen dos ecuaciones no lineales, que se expresan: 26 2.2 Regresión lineal n i =1 n i =1 n ∑ 1 wi ∑ ∑ xi wi ∑ i =1 n i =1 2 n yi + 1 ei ∂ wi xi wi b0 i =1 wi 2 wi ∂b0 × = xi2 b1 n x y 1 e 2 ∂ w i i i + i wi 2 wi ∂b1 i =1 wi ∑ (2.33) ∑ o en forma matricial: R ⋅b = g (2.34) Aislando el vector b de la ecuación 2.34, se obtiene la ecuación 2.35 para calcular los valores de la ordenada en el origen y la pendiente de la recta de regresión que considera los errores individuales en las variables predictora y respuesta: b = R −1 ⋅ g (2.35) El término wi, correspondiente al factor de ponderación (que aparece en las matrices g y R-1) incluye la pendiente de la recta de BLS. Por este motivo, con el fin de calcular los coeficientes de regresión utilizando el método de BLS se necesita resolver un proceso iterativo. Este proceso, tal como se ha indicado con anterioridad es fácil de programar y converge rápidamente. Además, mediante la multiplicación de la matriz R-1 por la estimación del error experimental ( s 2 en la ecuación 2.32), se obtiene de forma sencilla la matriz varianza-covarianza de los coeficientes de regresión. De esta forma, las desviaciones estándar de la ordenada en el origen y la pendiente se calculan como se detalla en las ecuaciones 2.36 y 2.37 respectivamente: n sb20 = ∑ i =1 n ∑ i =1 1 ⋅ wi n ∑ i =1 xi2 wi x xi − wi i =1 wi 2 i n ∑ 2 ⋅ s2 (2.36) 27 2. Fundamentos teóricos n sb21 = 1 ∑w i =1 n ∑ i =1 1 ⋅ wi n ∑ i =1 i x xi − wi i =1 wi 2 i n ∑ 2 ⋅ s2 (2.37) Otra característica importante del método BLS es que la recta de regresión no varía al hacer un intercambio entre los ejes. Este hecho tiene una importancia particular en procesos de comparación de dos métodos analíticos mediante regresión lineal, donde la decisión acerca de si los dos métodos estudiados son o no comparables, no debería verse influida por el método analítico que se asigna a cada eje. Por tanto, la invariabilidad respecto al intercambio de ejes del método BLS, permite concluir que la asignación de uno u otro método como variable respuesta o predictora carece de importancia, pues las conclusiones extraídas tras el uso de la recta BLS coinciden exactamente en los dos casos. En el Anexo 1 de la Tesis Doctoral está desarrollado el proceso de transformación de las expresiones de cálculo de la ordenada en el origen y de la pendiente de la recta BLS en las expresiones del cálculo de los coeficientes de regresión de WLS y OLS. Para ello, en primer lugar se han supuesto nulos los errores asociados a la variable predictora (condiciones WLS) y a continuación se ha añadido la necesidad de homoscedasticidad en la variable respuesta (condiciones OLS). De esta forma se comprueba que cuando el conjunto de datos cumple las condiciones requeridas por WLS y OLS, los resultados de utilizar la recta BLS son coincidentes con los obtenidos al utilizar los otros dos métodos. 2.2.3 Aplicaciones de la regresión lineal considerando los errores en las variables predictora y respuesta Existen una serie de aplicaciones dentro del campo de la química analítica, que utilizan la regresión lineal como herramienta. A su vez hay una parte de estas técnicas que requieren que la regresión lineal sea utilizada considerando los errores experimentales cometidos en las variables predictora y respuesta (tal como hace el método BLS). A continuación se presentan una serie de aplicaciones 28 2.2 Regresión lineal donde deben considerarse los errores cometidos en ambas variables al utilizar la regresión lineal. 2.2.3.1 Calibración lineal La calibración metodológica es uno de los procesos más importantes en el análisis químico. Unas buenas precisión y exactitud sólo pueden obtenerse si, entre muchos otros procesos, se utiliza un buen procedimiento para llevar a cabo la calibración. En una calibración, generalmente se busca la relación entre la concentración de patrones (representada en el eje de abscisas) y la medida instrumental (generalmente representada en el eje de ordenadas). Esta es quizás la aplicación de la regresión lineal donde es menos necesario considerar los errores en las dos variables, pues considerar únicamente los errores en la variable respuesta supone considerar la concentración libre de error. Esta es una suposición generalmente aceptada, pues los errores asociados a la medida experimental suelen ser claramente superiores a los asociados a los patrones. Sin embargo hay una serie de casos en los que esta suposición no se puede hacer dentro de los procesos de calibración. Algunos de los casos ya se han especificado, y se corresponden, por ejemplo, con aquellos análisis en los que la variable predictora la definen materiales de referencia certificados (como por ejemplo en análisis de muestras de origen geológico por medio de fluorescencia de rayos X)20, aquellos análisis en que la respuesta instrumental tiene un error muy pequeño debido a los avances técnicos en el proceso de medida, o aquellos procesos de datación por radiocarbono, en que los patrones suelen ser bastante inestables con el tiempo. 2.2.3.2 Comparación de métodos La comparación de métodos analíticos a diversos niveles de concentración es otra de las aplicaciones de la regresión lineal más utilizadas. En este caso se construye la recta de regresión entre los resultados de los dos métodos analíticos en comparación, y comparando sus coeficientes de regresión con los teóricos de ordenada en el origen cero y de pendiente unitaria, se concluye si los métodos comparados son o no equivalentes. La comparación de métodos es la 29 2. Fundamentos teóricos aplicación de la regresión lineal donde la utilidad de considerar los errores en las dos variables es más clara, pues generalmente los dos métodos en comparación presentan errores que son, cuando menos, del mismo orden de magnitud. 2.3 Distribución de la población de una medida experimental La extracción de información de los datos generalmente empieza con una descripción de los datos obtenidos experimentalmente.17 En muchas ocasiones estos resultados forman parte de una población, y la razón de hacer las medidas experimentales es intentar deducir alguna de las características de esta población, ya sea la media o la desviación estándar, por ejemplo. En otras ocasiones se pretende conocer si los datos siguen una distribución, ya sea la distribución normal u otra distribución cualquiera. Otra aplicación de estudiar la población de los datos es la detección de puntos discrepantes en los resultados experimentales. Aquellos casos en que se desconocen los parámetros estadísticos que definen la población de los datos forman parte de la estadística no paramétrica. En muchas ocasiones, los tests realizados sobre un conjunto de datos experimentales requieren del conocimiento de parámetros estadísticos referidos a la población de los datos. De esta manera se justifica la necesidad de conocer la población a la que pertenece un conjunto de medidas experimentales. En una determinación analítica, debido al error aleatorio, se obtiene un grado de dispersión de los resultados del análisis. Estos resultados pueden considerarse como una población de datos. Como objetivo de los análisis, normalmente se pretenden conocer el valor medio y la desviación estándar de la población definida por los resultados. La media para conocer el valor real de una muestra y la desviación estándar para conocer la precisión de la determinación. Estos dos parámetros se consideran los parámetros de la muestra. Para resumir las características de una distribución, pueden utilizarse los momentos. El r-ésimo momento de un conjunto de datos (x1, ... , xn) se calcula de la siguiente forma: 30 2.3 Distribución de la población de una medida experimental n ∑x mro = r i i =1 (2.38) n El r-ésimo momento centrado o sobre la media del mismo conjunto de datos se calcula de igual forma pero sustituyendo el valor xi por su resta respecto a la media: n ∑ (x − x ) r i mr = i =1 n (2.39) El r-ésimo momento adimensional centrado se define como: ar = mr m = rr r sdist m2 (2.40) donde sdist es la desviación estándar de la distribución definida como la raíz cuadrada del momento centrado de orden 2. De esta forma, el primer momento de un conjunto de datos ( m1o ) es igual a la media, mientras que el primer momento centrado (m1) es igual a cero. El segundo momento centrado de cualquier distribución es la varianza de la misma: n ∑ (x − x ) 2 i m2 = i =1 n 2 = s dist (2.41) El tercer momento centrado es una medida de la asimetría (skeewness) de la distribución.16,17 El tercer momento centrado se utiliza en su forma adimensional; por tanto, el coeficiente de asimetría se expresa de la siguiente forma: 31 2. Fundamentos teóricos xi − x m3 i =1 s dist = a3 = n m23 n ∑ 3 (2.42) Se dice que una distribución es simétrica si la media, la mediana y la moda son iguales (a3=0). Una distribución con una cola más larga por la derecha que por la izquierda hace que la media sea mayor que la mediana y ésta mayor que la moda, entonces se dice que dicha distribución tiene un coeficiente de asimetría positivo. En el caso en que la cola mayor esté a la izquierda, se dirá que la distribución posee un coeficiente de asimetría negativo.16,17 Una gráfica en la que se visualiza esta diferencia se representa en la figura 2.1. Simétrica a3=0 Positiva a3>0 Negativa a3<0 Figura 2.1.- Visualización de una asimetría positiva (media menor que la moda) y negativa (media mayor que la moda). El cuarto momento centrado adimensional se usa como una medida del aplastamiento de la distribución (kurtosis): xi − x m4 i =1 s dist a4 = 2 = m2 n n ∑ 4 (2.43) El aplastamiento da idea de la distribución de las observaciones alrededor de la media y permite apreciar si la distribución estudiada es llana o con forma de pico.16,17 Un ejemplo de la influencia del cuarto momento centrado adimensional de 32 2.3 Distribución de la población de una medida experimental una distribución, sobre la altura de pico se encuentra en la figura 2.2, donde a4=3 se corresponde con una distribución normal. a4>3 a4=3 a4<3 Figura 2.2.- Influencia del cuarto momento centrado adimensional sobre el aplastamiento de la distribución. 2.3.1 Distribución normal o Gaussiana La distribución de probabilidad más conocida es la distribución normal.17 En notación corta se escribe: 2 ) x ~ N (µ dist , σ dist (2.44) Esto quiere decir que los valores de la población x se distribuyen según 2 . La función de la densidad una distribución normal con media µdist y varianza σ dist de probabilidad de una distribución normal es: M ( x) = 1 σ dist 1 x − µ dist exp − 2 2π σ dist 2 (2.45) El teorema del límite central es uno de los teoremas más importantes dentro del campo de la matemática estadística. Este teorema nos dice que la suma 33 2. Fundamentos teóricos de n variables independientes de media µi y varianza σ i2 (donde i es un valor comprendido entre 1 y n) sigue una distribución normal con media varianza ∑σ 2 i ∑µ i y , cuando n tiende a infinito. Este resultado es importante para el campo de la química analítica pues explica porqué las distribuciones de los errores suelen tender aproximadamente a la distribución normal. Esto se debe a que, en general, el error total se puede expresar como una función de muchas componentes de error. Una condición importante es que todas las componentes de error tengan un peso de similar orden de magnitud entre sí. 2.4 Tests estadísticos para la comprobación de la normalidad de una distribución La mayoría de los tests estadísticos utilizados en el campo de la química se basan en la asunción de la normalidad en la distribución de los datos. Sin embargo las distribuciones pueden no ser normales, en cuyo caso se dispone de diversos tests que permiten detectar las desviaciones de la normalidad en una distribución de datos. En la bibliografía se encuentran indicaciones sobre la desviación de la normalidad de las distribuciones asociadas a la ordenada en el origen y a la pendiente cuando se consideran los errores en las variables predictora y respuesta,55 pero sin especificar el grado de desviación respecto a la normalidad. Para estudiar la normalidad de las distribuciones asociadas a los coeficientes de regresión de la recta BLS, así como su grado de desviación en el caso que su comportamiento difiera de la normalidad, se utilizarán los tests estadísticos que se explican a continuación. 2.4.1 Test de normalidad en Cetama Este test de normalidad56 permite, no sólo decidir si una distribución es o no normal, sino que permite encontrar parámetros de su distribución, tales como la media, la mediana o la ecuación de su distribución. Para ello, este test utiliza los 34 2.4 Tests estadísticos para la comprobación de la normalidad coeficientes de Pearson y Fisher, que son función de los momentos centrados de orden dos, tres y cuatro (mi, i=2-4): ϕ1 = m3 m = 3 3 = a3 3/ 2 m2 sdist (2.46) ϕ2 = m4 − 3 = a4 − 3 m22 (2.47) sdist es la desviación estándar de la distribución. Los coeficientes ϕ1 y ϕ2 son los coeficientes de Fisher. El primer coeficiente de Fisher es un coeficiente de asimetría (skeewness). El segundo coeficiente de Fisher se llama coeficiente de aplastamiento (kurtosis). Los coeficientes de Fisher se pueden reemplazar por los coeficientes de Pearson (π1 y π2) según las siguientes expresiones: m32 = ϕ12 m23 (2.48) m4 = ϕ2 + 3 m22 (2.49) π1 = π2 = Según los valores de los coeficientes de Fisher o de Pearson pueden caracterizarse todas las distribuciones posibles. Un caso concreto es la distribución normal en la que se cumple que los coeficientes de Fisher son nulos. Los coeficientes de Fisher ϕ1 y ϕ2 se estiman por medio de f1 y f2: f1 = f2 = k3 k 23 k4 k 22 (2.50) (2.51) Los coeficientes de Pearson pueden estimarse por p1 y p2: 35 2. Fundamentos teóricos p1 = f12 = k 32 (2.52) k 23 p2 = f 2 + 3 (2.53) donde los coeficientes k2, k3 y k4 se calculan de la siguiente forma: k2 k3 = m ∑ (x = − x) 2 i ∑ (x − x) 3 i (m − 1)(m − 2) k4 = = (m − 1) = m2 ∑ (x m(m + 1) m ∑ x − (∑ x ) 2 2 i m(m − 1) ∑x 3 i − 3m 2 = s dist ∑x ∑x 2 i i +2 m(m − 1)(m − 2 ) (2.54) (∑ x ) 3 i [∑ (x − x ) ] − x ) − 3(m − 1) 4 i i (m − 1)(m − 2)(m − 3) (2.55) 2 2 i (2.56) donde xi se refiere a cada uno de los m puntos de la distribución que se desea estudiar, y sdist representa la estimación de la desviación estándar real de la distribución de cada uno de los coeficientes de regresión ( σ dist ). 2.4.2 Test de Kolmogorov Existen dos modalidades del test: la gráfica y la numérica.57 En este trabajo se ha utilizado la segunda debido sobretodo a la sencillez a la hora de programar su algoritmo.58 Además, ya se utiliza otro test de tipo gráfico (sección 2.4.3) y, aunque los tests gráficos son más sensibles a posibles desviaciones de la normalidad, su información es menos concreta y más difícil de interpretar que la obtenida por los tests numéricos. El test evalúa la normalidad de una distribución, mediante la comparación de los datos experimentales con unos datos teóricos tabulados que dependen del número de datos y del nivel de significancia (α) que se acepta. Para realizar el test de Kolmogorov hay que seguir los siguientes pasos: 36 2.4 Tests estadísticos para la comprobación de la normalidad - En primer lugar se ordenan de forma ascendente los datos que conforman la distribución que se quiera estudiar en cada caso. - A continuación se calcula el valor de Di para cada uno de los valores experimentales a partir de la siguiente expresión: Di = N ( xi ) − i m (2.57) donde i es el orden del valor estudiado dentro de la secuencia ordenada (frecuencia), m es el número de puntos totales de la distribución, mientras que N(xi) es el valor correspondiente a la distribución normal acumulativa. - El siguiente paso es encontrar el valor máximo Dmáx de todos los Di, y una vez obtenido Dmáx, se debe comparar con los valores de D tabulados para un valor de α determinado. Si el valor Dmáx es mayor que el tabulado, se considera la distribución como no normal con una probabilidad dada por el valor α seleccionado. 2.4.3 Gráficos de probabilidad normal Es interesante utilizar como mínimo un test gráfico para la comprobación de la normalidad en los coeficientes de regresión de la recta BLS, ya que los tests de tipo gráfico son más sensibles frente a posibles desviaciones de la normalidad que los tests numéricos.59 Los gráficos de probabilidad normal (normal probability plots o test de Rankit),18,59 están diseñados para detectar las desviaciones de la normalidad de las distribuciones. En ellos se representan los residuales ordenados frente al orden estadístico normal con el tamaño apropiado para la muestra. Este orden lo forman los valores esperados de las observaciones ordenadas provenientes de una distribución normal con media cero y desviación estándar unitaria. Una línea recta en estos gráficos representa una distribución normal (figura 2.3), mientras que una desviación de la línea recta esperada indica la ausencia de normalidad en la distribución. Una distribución no simétrica (con skeewness) se representa por una curva cuya dirección la determina el sentido de la 37 2. Fundamentos teóricos 0.999 0.999 0.99 0.99 0.90 0.90 Probabilidad Probabilidad asimetría (figura 2.4). Una curva en forma de “S” da idea de una distribución de grandes colas o de colas muy pequeñas (distribución con aplastamiento o kurtosis) dependiendo de la dirección de la “S” (figura 2.5). Las distribuciones con grandes colas tienen relativamente mayores frecuencias en las observaciones extremas que la distribución normal, mientras que las distribuciones con colas pequeñas las tienen relativamente menores. El hecho de tener una distribución con colas pequeñas se puede deber a la aparición de algún punto discrepante o a la heterogeneidad de los errores en las dos variables. 0.50 0.10 0.50 0.10 0.01 0.01 0.001 0.001 -2 0 2 4 0 Datos experimentales 4 8 12 Datos experimentales Figura 2.3.- Representación del test de Rankit Figura 2.4.- Representación del test de Rankit para una distribución normal. para una distribución asimétrica. 0.999 0.99 Probabilidad 0.90 0.50 0.10 0.01 0.001 -1 -0.5 0 0.5 1 Datos experimentales Figura 2.5.- Representación del test de Rankit para una distribución con colas grandes. Un caso particular de los gráficos de distribución normal, la forman los gráficos de percentiles de la distribución (quantile-quantile plots)59 útiles para la caracterización de una distribución como una previamente conocida. El método representa los residuales ordenados de las dos distribuciones (generalmente una distribución problema y una de las teóricas), y por tanto, una línea recta en la 38 2.4 Tests estadísticos para la comprobación de la normalidad gráfica equivale a poder considerar la coincidencia entre las dos distribuciones comparadas. 2.5 Predicción en regresión lineal La etapa de predicción es una de las etapas más importantes dentro del proceso de utilización de la recta de regresión. Su uso más generalizado se da en procesos de calibración, donde la concentración de una muestra y su intervalo de confianza asociado se predicen a partir de un valor de la respuesta y su error experimental. Sin embargo, también se utilizan en procesos de comparación de métodos analíticos. En estos casos los resultados, y su intervalo de confianza asociado, que se obtendrían al analizar una muestra mediante un método ya establecido en un laboratorio (por ejemplo considerado de referencia), se predicen a partir de los obtenidos mediante un método de reciente implantación. De esta manera se podría comprobar si los resultados a cada uno de los niveles de concentración pueden considerarse como equivalentes o no utilizando los dos métodos. A continuación presentaremos las expresiones desarrolladas para el cálculo de la predicción considerando los errores en la variable predictora, tanto considerando la heteroscedasticidad en la variable respuesta como manteniendo la hipótesis de homoscedasticidad. 2.5.1 Intervalos de predicción considerando solamente los errores en la variable respuesta La predicción de la variable predictora a partir de un valor dado de la variable respuesta y viceversa, así como el cálculo de sus intervalos de predicción están ampliamente desarrollados en la bibliografía para el método de regresión OLS.15,60,61 El intervalo de predicción de la variable respuesta (y0) a partir de q réplicas de la variable predictora (x0) utilizando el método de OLS se obtiene con la siguiente expresión: 39 2. Fundamentos teóricos y = y 0 ± t α / 2,n−2 ⋅ s ( x − x) 2 1 1 + + n 0 q n ( xi − x ) 2 ∑ (2.58) i =1 La expresión del cálculo del intervalo de predicción para un valor considerado como verdadero (realizando infinitas réplicas) de la variable respuesta se correspondería con la misma expresión en la que se elimina el término 1/q ( q = ∞ ).62 y = y 0 ± t α / 2 ,n − 2 ⋅ s ( x − x) 2 1 + n 0 n ( xi − x ) 2 (2.59) ∑ i =1 Estas expresiones se encuentran de igual manera en su forma matricial.15 La ecuación 2.60 representa el intervalo de predicción de una muestra obtenida a partir de q réplicas de la variable predictora (x0), mientras que la ecuación 2.61 representa el intervalo de predicción de una muestra considerada como verdadera ( q = ∞ ): 1 −1 y = y 0 ± t α / 2 ,n − 2 ⋅ s + X′0 ⋅ (X′ ⋅ X ) ⋅ X 0 q (2.60) ( (2.61) y = y 0 ± t α / 2 ,n −2 ⋅ s X′0 ⋅ (X′ ⋅ X ) ⋅ X 0 −1 ) Los intervalos de predicción para la variable respuesta se representan por medio de las clásicas hipérbolas de confianza, tal como se ve en el ejemplo representado en la figura 2.6. 40 2.5 Predicción en regresión lineal 30 20 y 10 0 5 10 x 15 20 25 Figura 2.6.- Representación gráfica de los intervalos de predicción de la variable respuesta encontrados según el método OLS. La predicción de un valor de la variable predictora (x0) a partir de un valor dado de la variable respuesta (y0) es la llamada predicción inversa. El intervalo de predicción inversa se expresa de la siguiente forma:15 ( x0 − x) ⋅ g ± t α / 2,n −2 ⋅ s ⋅ (1 − g ) ⋅ b1 ( x − x) 2 n / q +1 + n 0 n ( xi − x ) 2 ∑ i =1 x = x0 + 1− g (2.62) donde el parámetro g se corresponde con: t α2 / 2,n − 2 g= b12 n s2 / ∑ (x i − x) 2 = t α2 / 2,n −2 b12 sb21 (2.63) i =1 Los intervalos de predicción encontrados a partir de la ecuación 2.62 no siempre son simétricos. Su simetría dependerá del valor del coeficiente g. El término g está relacionado con el test de significancia para la pendiente de la recta de regresión. Si dicho test es significativo al nivel α escogido (es decir, si b1 / sb1 > t α / 2,n − 2 ), se concluye que la pendiente es significativa y el parámetro g será 41 2. Fundamentos teóricos menor que 1. Si el test es altamente significativo (es decir g es suficientemente pequeño), puede eliminarse el parámetro g de la ecuación 2.62, y ésta se reduce a:15,63,64 x = x0 ± t α / 2,n−2 ⋅ s b1 ⋅ ( x − x) 2 1 1 + + n 0 q n ( xi − x ) 2 ∑ (2.64) i =1 que proporciona unos intervalos de predicción simétricos alrededor del punto x0. Los intervalos de predicción encontrados por medio de la regresión con el método OLS no son invariables ante un intercambio de los ejes. Esta conclusión es importante pues hay muchos casos en que la elección de la variable predictora y la variable respuesta no es trivial, mientras que los resultados derivados de la recta de regresión son diferentes según se haga la elección. Un ejemplo es la comparación de métodos analíticos, donde debería ser indiferente cual de los métodos se elija como variable respuesta y cual como variable predictora. Los intervalos de predicción de la variable respuesta a partir de q réplicas de una muestra de concentración x0, considerando heteroscedasticidad en la variable respuesta se pueden calcular utilizando el método de WLS: y = y 0 ± t α / 2,n−2 ⋅ s ⋅ w0 + q 1 n ∑ i =1 1 wi + ( x0 − x p ) 2 n ( xi − x p ) 2 wi i =1 ∑ (2.65) Teniendo en cuenta los errores heteroscedásticos en la variable respuesta se han desarrollado más métodos de cálculo de los intervalos de predicción de la variable respuesta que de la variable predictora. El método de regresión WLS es el más utilizado. La expresión del intervalo de predicción de la variable predictora (x0) a partir de q réplicas sobre un valor conocido de la variable respuesta (y0) utilizando el método de WLS es la siguiente: 42 2.5 Predicción en regresión lineal x = x0 ± t α / 2,n−2 ⋅ s b1 w0 + q ⋅ 1 n 1 wi ∑ i =1 + ( x0 − x p ) 2 n ( xi − x p ) 2 wi i =1 ∑ (2.66) Otros autores65,66 proponen métodos de cálculo alternativos que también consideran la heteroscedasticidad en la variable respuesta. La siguiente ecuación es un ejemplo: x = x0 ± t α / 2 , n + q −3 ⋅ s b1 ⋅ x0p + q 1 n ∑ i =1 1 wi + ( x0 − x p ) 2 n ( xi − x p ) 2 wi i =1 ∑ (2.67) donde p es la potencia del factor de ponderación (wi). En la bibliografía se definen diversos factores de ponderación que pueden utilizarse.67 A este método para calcular los intervalos de predicción se le conoce como método paramétrico aproximado (aproximate parametric method, APM). Otra de las propuestas es una solución paramétrica asimétrica, que se conoce como método exacto paramétrico (exact parametric method, EPM). Este método encuentra el intervalo de predicción de la variable predictora mediante un procedimiento iterativo en los extremos superior e inferior del intervalo hasta minimizar las funciones de diferencias. El método no paramétrico de bootstrap16,68,69 es una técnica de computación intensiva que proporciona una estimación no paramétrica del error estadístico de un modelo en términos de sesgo y varianza. El procedimiento imita el proceso de seleccionar un número elevado de muestras del mismo tamaño a partir de una población dada con el fin de calcular un intervalo de predicción. El conjunto de datos compuesto por n observaciones no se considera una muestra de la población, sino la misma población, a partir de la cual muestras de tamaño n, llamadas muestras bootstrap, se seleccionan con sustitución. Esto se consigue asignando un número a cada observación del conjunto de datos y después generando muestras aleatorias emparejando los datos a los números correspondientes a las observaciones. Mediante este método se obtienen unos intervalos de predicción cuyo balance entre precisión y exactitud es aceptable cuando el número de réplicas sobre la variable respuesta está comprendido entre 2 y 4. 43 2. Fundamentos teóricos 2.5.2 Intervalos de predicción considerando los errores en las variables predictora y respuesta Generalmente los errores en la variable predictora no se tienen en cuenta a la hora de buscar los intervalos de predicción. Sin embargo hay una serie de casos en que sí se consideran. Por ejemplo, Spiegelman y colaboradores19 desarrollaron las expresiones para el cálculo de los intervalos de predicción en procesos de calibración para la determinación de potasio por medio de espectrometría de emisión de llama (FES), donde la respuesta instrumental (variable respuesta) suele ser tan estable que difícilmente se pueden eliminar los errores cometidos en la preparación de los patrones de calibración (variable predictora). Estos intervalos de predicción se obtienen a partir de un ensanchamiento de los calculados utilizando únicamente los errores cometidos en la respuesta instrumental. Dichas expresiones se basan en un procedimiento desarrollado por Lwin y Spiegelman70 aplicable cuando los errores en la variable predictora son muy bajos. Asumiendo un error máximo (ϕi) asociado a los patrones de calibración del 0.5% del valor individual de la concentración de cada patrón (ϕi = 0.5% · xi), los intervalos de predicción aumentan en un valor ∆(x): ∆ ( xi ) = ϕ i n ∑c i m( xi ) (2.68) i =1 donde m(xi) es una función positiva dada y las constantes ci dependen de los valores verdaderos de la concentración de los patrones. La aproximación CVR también se ha utilizado para calcular los intervalos de predicción de las variables respuesta y predictora:40 1 ( x − x) 2 2 s y20 = b12 s δ2 + + (1 + kb1 ) 2 ⋅ 0 ⋅ se S uu n (2.69) donde: S uu = n ∑ i =1 44 ( xi − x ) 2 + 2k n ∑ i =1 ( xi − x)( y i − y ) + k 2 n ∑(y i =1 i − y) 2 (2.70) 2.5 Predicción en regresión lineal 2 b1 se = n ∑ ( xi − x) 2 − 2b1 i =1 n ∑ ( xi − x)( y i − y ) + i =1 n ∑(y i =1 n−2 sδ = se b + λ − 2b1θ 2 1 i − y ) 2 (2.71) (2.72) El parámetro k de las ecuaciones 2.69 y 2.70 se introduce en el proceso de cálculo de los coeficientes de regresión y se corresponde con:40 k= b1 − θ λ − b1θ (2.73) donde λ es la relación entre las varianzas de las variables respuesta y predictora y θ es la covarianza entre las varianzas de las dos variables multiplicada por el factor λ .40 El valor sδ está relacionado con el error asociado a la variable predictora, mientras que se está asociado a la estimación del error instrumental. La expresión para el cálculo de la varianza asociada a la predicción del valor de la variable predictora x0, a partir del punto y0 de la variable respuesta, viene dada por la siguiente expresión: s x20 = 2 s ε2 1 1 2 ( y0 − y) 2 ( 1 ) kb + + + ⋅ ⋅ se 1 b12 b12 n b12 S uu (2.74) donde sε, que está relacionado con el error asociado a la variable respuesta, viene dado por la siguiente expresión: sε = sδ λ (2.75) 2.6 Límites de detección En el campo químico, durante los últimos años, se ha adquirido conciencia de la importancia de establecer correctamente el límite de detección de un método analítico. La capacidad de un método para detectar la presencia o 45 2. Fundamentos teóricos ausencia de un determinado analito en una muestra es uno de los posibles parámetros a optimizar en el proceso de comprobar si una metodología se ajusta a un propósito (fit for purpose).71,72 El desarrollo de técnicas de análisis más sensibles, o la utilización de materiales de referencia certificados en lugar de patrones en la variable predictora en el proceso de la calibración, han incrementado la necesidad de examinar los actuales procedimientos para establecer los límites de detección. A lo largo de la historia se han propuesto multitud de técnicas destinadas a calcular el límite de detección de una metodología. Una de las primeras la propuso Kaiser73 (1947), quien relacionaba el límite de detección con la desviación estándar del ruido de fondo. Sobre esta teoría se han ido haciendo modificaciones y diferentes propuestas hasta llegar a la situación actual en que Currie74 hizo una serie de recomendaciones para el cálculo del límite de detección. Debido a los errores aleatorios (los errores sistemáticos deben haber sido previamente detectados y eliminados) presentes en todo procedimiento analítico, únicamente es posible obtener una estimación del límite de detección, y por tanto se puede llegar a conclusiones erróneas al utilizar dicho límite de detección. Por este motivo, siempre existirán unas determinadas probabilidades de cometer un error de primera especie (también llamado falso positivo o error α), que se corresponden con la situación en que se detecta un analito cuando en realidad este no está presente en la muestra, o unas determinadas probabilidades de cometer un error de segunda especie (también llamado falso negativo o error β), que se corresponden con la situación en que no se detecta un analito que está presente en la muestra. Según las últimas recomendaciones de la IUPAC74 el cálculo del límite de detección se desglosa en dos etapas. La primera de ellas es la etapa de decisión (apartado 2.6.2), mientras que la segunda es la etapa de detección (apartado 2.6.3). Previamente a la explicación de estas dos etapas en el apartado 2.6.1 se explican brevemente los conceptos de test de hipótesis y de errores de primera y segunda especie que son utilizados en el cálculo del límite de detección. 46 2.6 Límites de detección 2.6.1 Test de hipótesis En un test de hipótesis, las decisiones suelen estar basadas en muestras que siguen un determinado tipo de distribución. En el caso concreto de una distribución unidimensional, en algunos casos de interés práctico es necesario verificar si la media y la desviación estándar (por ejemplo), tienen en realidad un valor conocido de antemano. Mediante los tests de hipótesis se puede decidir si el valor estimado ( θ̂ 0 ) es significativamente diferente del valor θ 0 de un parámetro θ cualquiera.17 El procedimiento para llevar a cabo estos tests de hipótesis empieza por fijar una hipótesis nula (H0).75 Al definir la hipótesis nula hay que fijar un nivel de significancia (α), que representará la probabilidad de rechazar erróneamente H0. Este error es conocido con el nombre de error de primera especie o error α. Para el caso en que la hipótesis nula no sea cierta, habrá que definir una hipótesis alternativa (H1)75, que se aceptará al rechazar la hipótesis nula. De igual forma que para la hipótesis nula, habrá unas probabilidades de aceptar erróneamente la hipótesis alternativa. A este error se le conoce con el nombre de error de segunda especie o error β. Es decir, el hecho de aceptar una hipótesis no implica que se haya probado que dicha hipótesis es cierta, sino que no se tienen evidencias para rechazarla. La tabla 2.1 esquematiza las probabilidades de cometer errores de primera o segunda especie. Conclusión del test Situación real H0 cierta H0 falsa H0 cierta Decisión correcta Error α H0 falsa Error β Decisión correcta Tabla 2.1.- Representación de las diferente situaciones derivadas del uso de un test de hipótesis. 2.6.2 Etapa de decisión El valor crítico (LC) se define como el valor mínimo de una señal neta (sin la contribución del blanco) o de una concentración, que puede considerarse 47 2. Fundamentos teóricos significativamente diferente del blanco. matemáticamente de la siguiente forma: Esta Pr (Lˆ > LC | L = 0 ) = α definición se expresa (2.76) Si la cantidad estimada ( L̂ ) tanto en términos de concentración como de señal neta, sigue una distribución normal, con una varianza conocida, la ecuación 2.76 se reduce a la siguiente expresión: LC = z1−α σ 0 (2.77) donde z1-α es el valor crítico de la distribución normal y σ0 es la desviación estándar verdadera de la cantidad estimada. Si no se conoce el valor de la desviación estándar y se estima su valor a partir de s0, con ν grados de libertad, entonces la cantidad estimada sigue una distribución t de Student: LC = t1−α ,ν s 0 (2.78) Como conclusión, la decisión sobre si un analito es detectado o no se produce mediante la comparación de la cantidad estimada en términos de señal neta o de concentración ( L̂ ) con el valor crítico ( LC ) de la distribución respectiva, de manera que la probabilidad de exceder este valor no sea mayor que α si el analito no se encuentra en la muestra. 2.6.3 Etapa de detección La IUPAC, en sus últimas recomendaciones,74 define el límite de detección, con el nombre de valor mínimo detectable, como la capacidad de detección inherente que tiene un proceso de medida químico. Desde el punto de vista matemático, se define el límite de detección como el valor LD para el cual la probabilidad de cometer un error de segunda especie es β, dado un LC (o α). Esta definición se expresa de la siguiente forma: Pr (Lˆ ≤ LC | L = LD ) = β 48 (2.79) 2.6 Límites de detección Si la cantidad estimada ( L̂ ) sigue una distribución normal, con una varianza conocida, la ecuación 2.79 se reduce a la siguiente expresión: LD = LC + z1−β σ D = z1−α σ 0 + z1−β σ D (2.80) donde z1-β es el valor crítico de la distribución normal y σD es la desviación estándar verdadera de la cantidad estimada. Si no se conoce el valor de la desviación estándar y se estima su valor a partir de sD, con ν grados de libertad, entonces la cantidad estimada sigue una distribución t de Student: LD = LC + t 1−β,ν s D = t1−α ,ν s 0 + t1−β,ν s D (2.81) Una vez definidos el valor crítico y el límite de detección, en la bibliografía pueden encontrarse multitud de ejemplos de aplicación. Currie,76 presenta un ejemplo que clarifica el uso de estos dos conceptos. A continuación se explica una adaptación de dicho ejemplo al campo de la química analítica. Imaginemos que se pretende detectar la presencia de un contaminante en agua de consumo, y supongamos un límite para dicho contaminante extraído de una normativa (LR). Sobre este valor, la toxicidad puede ser peligrosa para la salud de los consumidores. Evidentemente, el método analítico seleccionado debería tener un límite de detección (LD) inferior al valor normativo (LR). Los límites normativos se escogen teniendo en cuenta los riesgos que conlleva la comisión de un error tanto de primera como de segunda especie. En la figura 2.7 se representa un esquema del proceso. De tal manera que en la parte superior podríamos encontrar una relación hipotética entre la concentración del contaminante en el agua de consumo y el coste social que se derivaría de su presencia. Lógicamente resulta imposible analíticamente suponer el límite normativo como nulo (lo que implicaría un coste social también nulo). La parte inferior de la figura representa el análisis químico en términos de concentración. El límite de detección LD requerido por el método ha de estar por debajo de LR y es función del valor crítico (LC) establecido y de la probabilidad β prefijada de cometer un error de segunda especie. 49 2. Fundamentos teóricos Coste social Aceptable 0 Concentración de contaminante LR σ0 σD β 0 α LC LD Concentración de contaminante Figura 2.7.- Representación del nivel crítico (LC), del límite de detección (LD) y del nivel normativo (LR) y sus relaciones con las probabilidades de error α y β. Hubaux y Vos77 fueron pioneros en la evaluación de los límites de detección utilizando regresión lineal. Su aproximación sigue las propuestas de Currie,78 y definen el límite de decisión en respuestas como la señal mínima que puede distinguirse de la señal del blanco, y el límite de detección en concentraciones como la señal mínima por debajo de la cual cualquier muestra puede considerarse erróneamente como un blanco. Zorn y colaboradores79 realizaron una aproximación en la que se tiene en cuenta la posible heteroscedasticidad de los datos en la respuesta. Esta propuesta se basa en la descrita de Hubaux y Vos (representada en la figura 2.8), donde la variabilidad del error en las respuestas se tiene en cuenta mediante un modelado de las varianzas experimentales. Esta aproximación minimiza los límites de detección en un proceso, debido a que utiliza información ignorada en las anteriores aproximaciones, y que tienen una especial incidencia en los niveles de concentración cercanos al límite de detección. 50 Respuesta 2.6 Límites de detección y = b0 + b1 x α yC β y0 0 LC LD Concentración Figura 2.8.- Representación gráfica de la recta de regresión y de los intervalos de predicción, así como de los límites de decisión y de detección según la aproximación de Hubaux y Vos. 2.7 Regresión lineal discrepantes en presencia de puntos Desde siempre ha habido una preocupación por la presencia de observaciones no representativas, aberrantes o alejadas de la media en un conjunto de datos, pues estos puntos contaminan los datos reduciendo o distorsionando la información que contienen. Por este motivo es comprensible la búsqueda de mecanismos para interpretar y clasificar los puntos discrepantes, o de métodos que consigan rechazar los puntos discrepantes con el fin de restablecer la información que contienen los datos o, como mínimo, métodos que minimicen su impacto.80 Legendre, en 1805, en la primera publicación sobre el método de mínimos cuadrados, hace referencia a los puntos discrepantes, diciendo: “Si entre los errores hay algunos que son demasiado grandes para ser admisibles, las observaciones que producen estos errores se deben eliminar, como si provinieran de experimentos defectuosos, mientras que las observaciones desconocidas deberán encontrarse a partir del resto de observaciones, que tienen asociados errores mucho menores.” Más adelante, Peirce81 en una cita que data del año 1852 51 2. Fundamentos teóricos expresa la inquietud ante la presencia de observaciones discrepantes: “En casi todas las series reales de observaciones, se encuentran observaciones que difieren mucho de las demás indicando una fuente anormal de error no contemplada en las discusiones teóricas, y cuya inclusión en las investigaciones únicamente pueden servir ... para confundir y desconcertar al investigador.” Para solucionar este problema existen dos posibilidades: la solución de rechazar los puntos discrepantes, con lo que se corre el riesgo de perder información que puede llegar a ser genuina y en algunos casos útil, o incluirlos en al análisis, lo que conlleva el riesgo de contaminación de los datos. Para remediar el problema surgido ante la presencia de puntos discrepantes, se han desarrollado técnicas estadísticas que no se afectan fácilmente por la presencia de estos puntos discrepantes. Estas son las llamadas técnicas robustas, debido a que sus resultados son fiables a pesar de tener una cierta cantidad de los datos contaminados. Además, pueden considerarse como técnicas de detección de puntos discrepantes, pues hacen que estos puntos tengan los mayores residuales. Una alternativa es la construcción de métodos para diagnosticar la presencia de puntos discrepantes. Son dos soluciones con el mismo fin pero que actúan de forma totalmente opuesta: una intentando localizar los puntos discrepantes mientras que la otra pretende ignorar su presencia.82 2.7.1 Técnicas de detección de puntos discrepantes Las técnicas de detección de puntos discrepantes se dividen básicamente en dos grupos: las que se basan en los residuales a la recta de regresión (como por ejemplo los residuales estandardizados) y los que se basan en ir eliminando puntos del conjunto de datos inicial. De estos últimos el más conocido es el test de la distancia al cuadrado de Cook,17,62,82,83,84 que pasa por ser la técnica más utilizada en la actualidad para la detección de puntos discrepantes en regresión lineal. El test de Cook mide los cambios que sufren los coeficientes de regresión cuando se eliminan una o varias observaciones del conjunto de datos. Para ello utiliza la conocida distancia al cuadrado de Cook, que es la distancia que existe entre los coeficientes de regresión antes y después de eliminar los puntos 52 2.7 Regresión lineal en presencia de puntos discrepantes sospechosos de ser discrepantes, de manera que un valor elevado de la distancia de Cook indica que la observación eliminada (o las observaciones eliminadas en el caso de tener múltiples observaciones sospechosas de ser puntos discrepantes), tiene una considerable influencia en la determinación de los coeficientes de regresión. Para llevar a cabo esta comparación, se representa el intervalo de confianza conjunto de los coeficientes de regresión de la recta obtenida a partir del conjunto de datos inicial, y se observa si los valores de los coeficientes de regresión una vez eliminados los puntos sospechosos caen dentro de la elipse representada. En el caso de pertenecer a la elipse de confianza, se diría que los puntos eliminados no tienen una gran influencia sobre la recta y en el caso contrario deberían ser considerados como puntos discrepantes. De entre las aplicaciones desarrolladas para la detección de puntos discrepantes cuando se consideran los errores en las variables predictora y respuesta, cabe destacar la propuesta de Barnett85 (1985), que introduce un método de detección basado en el modelo estructural, y cuya importancia se debe a que dicho modelo presenta problemas de identificación para observaciones sin réplicas y ante una estructura normal de errores. 2.7.2 Robustez en regresión lineal La mayoría de los autores se decantan por las ventajas de la utilización de las técnicas de regresión robusta frente a las técnicas de detección de puntos discrepantes,86-88 de tal forma que entre ellos Huber89 destaca que la regresión robusta es capaz de suavizar la transición entre aceptar y rechazar un punto sospechoso de ser discrepante. La primera aproximación a la robustez en regresión lineal corre a cargo de Edgeworth90 el año 1887. Observó que el método de OLS se veía rápidamente afectado por la presencia de puntos discrepantes y propuso encontrar la recta de regresión minimizando la suma de los residuales absolutos, de igual forma que había propuesto Laplace el 1812 para el caso unidimensional. La recta de regresión resultó ser robusta ante puntos discrepantes en la dirección de las respuestas, pero se ve inmediatamente afectado si los puntos discrepantes lo son en la dirección de 53 2. Fundamentos teóricos las x. Otra solución al problema es la de los estimadores basados en procesos de máxima verosimilitud o estimadores-M (M-estimators) que se basan en sustituir el cuadrado de los residuales por otra función de los residuales. Entre estos métodos destacó el de Huber91 en 1973. Sin embargo estos métodos se caracterizan por ser vulnerables ante la presencia de puntos influyentes, motivo por el que se introdujeron los estimadores-M generalizados (GM-estimators), que intentan superar la presencia de puntos discrepantes en el eje de abscisas mediante la inclusión de una función de pesos. Entre las propuestas destacan las de Mallows92 del año 1975 o la de Schweppe93 del año 1977. Optimizando los pesos y la función incluidos en los residuales a minimizar se obtuvieron aproximaciones óptimas de los estimadores-GM.94-97 Desde entonces, a estos métodos se los conoce como estimadores de influencia definida. A lo largo de la historia se han desarrollado, básicamente, otros dos tipos de estimadores:98 los estimadores-L y los estimadoresR. Los primeros estimadores se obtienen a partir de combinaciones lineales de órdenes estadísticos, obteniendo los mejores resultados la propuesta realizada por Chernoff, Gastwirth y Johns99 datada el año 1967. Por su parte, los estimadores-R se derivan a partir de tests de rangos. Las principales aproximaciones son las propuestas por Chernoff y Savage100 (1958), Hodges y Lehmann101 (1963) y Hájek y Šidák102 (1967). Rousseeuw,103 el año 1984 desarrolló el conocido como método de la mínima mediana de cuadrados (least median of squares, LMS), basándose en la robustez intrínseca de la mediana frente a la suma de los residuales, minimizada en OLS para encontrar la recta de regresión, y en una idea anterior de Hampel104 del año 1975. LMS resultó ser un estimador robusto ante la presencia de puntos discrepantes tanto en el eje de abscisas como en el eje de ordenadas. Su robustez se demuestra pues su punto de ruptura (breakdown point)105,106 es del 50%.82 El método de LMS es en la actualidad el método de regresión robusta más conocido y extendido. Este método encuentra la recta de regresión minimizando la mediana de los residuales a la recta de regresión, donde la mediana se encuentra como el ([n/2]+1)-ésimo valor de los residuales ordenados, donde [n/2] representa la parte entera del valor n/2 y n es el número de puntos presentes en el conjunto de datos. Para ello, encuentra las rectas que pasan por todos los pares de puntos del conjunto de datos, y encuentra la mediana de los residuales de cada uno de los puntos a las 54 2.7 Regresión lineal en presencia de puntos discrepantes rectas. La recta cuya mediana sea mínima se considera como la recta de regresión robusta de LMS. La profundidad (depth) de una recta de regresión107 se define como el menor número de observaciones que se deben eliminar de un conjunto de datos para convertir la recta en una recta no ajustada, donde por una recta no ajustada se entiende aquella en la que para valores menores a uno determinado (v) todos los residuales son positivos y para valores mayores a v los residuales de todos los puntos son negativos (o viceversa). De una forma más gráfica, se define la profundidad de una recta de regresión como el número mínimo de puntos que debe cruzar la recta de regresión en su transformación, mediante una rotación, en una línea vertical. Recientemente Rousseeuw y Hubert108 han desarrollado un método de regresión llamado regresión profunda (deepest regression, DR) basado en este concepto, y consistente en encontrar la recta de regresión con máxima profundidad. Van Aelst y Rousseeuw109 estudiaron la robustez del método de la regresión profunda concluyendo que su punto de ruptura es del 33.33%. De este resultado se concluye que este método de regresión incluye bastante robustez, obteniéndose la recta de regresión sin hacer suposiciones acerca de la distribución ni de la magnitud de los residuales, pues únicamente considera la situación de los puntos y el signo de sus residuales. En la actualidad se han desarrollado un conjunto de técnicas de regresión robusta que consideran los errores en las dos variables. La mayoría están basados en métodos de regresión de máxima verosimilitud, teniendo como principal inconveniente la necesidad de tener los datos distribuidos de alguna determinada forma, según si se trata de un modelo funcional, estructural o ultraestructural. Brown110 (1982) propone un método de regresión robusta basado en la regresión ortogonal. Más adelante Hartmann111 (1996) hace una aplicación del LMS ortogonal desarrollado según las ideas de Rousseeuw y Leroy82 y Hu112. En el caso del modelo funcional, destacan también las propuestas realizadas por Carroll113 (1982) y Abdullah114,115 (1989), pues desarrollaron estimadores robustos de máxima verosimilitud. En el caso del modelo estructural aparecen problemas de identificación del modelo robusto116 (1984). Sin embargo Nyquist117 (1987) propone un método alternativo al método de los momentos para la obtención de la 55 2. Fundamentos teóricos recta de regresión robusta para el modelo estructural, donde estos problemas de identificación se ven solventados. Más próxima en el tiempo está la estimación propuesta por Feldmann118 (1992) que propone un método para el cálculo de la recta de regresión robusta mediante una generalización del método LMS. 2.8 Simulación de Monte Carlo Se trata de una técnica destinada a imitar el proceso de selección aleatoria de muestras a partir de una población predefinida con el fin de obtener estimaciones de los parámetros de la población. A partir de una fórmula matemática que no se puede evaluar fácilmente, normalmente es posible encontrar un proceso para generar variables estadísticas con distribuciones de frecuencia que pueden relacionarse con la fórmula matemática. La simulación genera una muestra, determina su distribución empírica y la usa en la evaluación numérica de la fórmula.16,119-121 La simulación se utiliza en muchos casos para evaluar el comportamiento de un método estadístico, para comparar varios métodos estadísticos similares o para resolver problemas matemáticos. La ventaja de la utilización de la simulación en vez de conjuntos de datos reales radica en que en el caso de los datos simulados se conoce la distribución de su población. Una de las principales utilidades del método de Monte Carlo en esta Tesis Doctoral, es la comprobación de diversas expresiones encontradas empíricamente. En el caso tratado más directamente en este trabajo, el método de Monte Carlo es un método de simulación que permite encontrar m nuevos conjuntos de datos a partir del inicial. A la hora de encontrar estos nuevos conjuntos de datos, el método de Monte Carlo considera los errores asociados a las dos variables. Para generar estos conjuntos de datos el método de Monte Carlo utiliza las siguientes expresiones: 56 xin = xi + zs xi (2.82) yin = yi + zs yi (2.83) 2.8 Simulación de Monte Carlo donde xin e yin representan un nuevo punto generado por el método de Monte Carlo, a partir del punto inicial (xi, yi) con desviaciones estándar s xi y s yi , mientras que z es un valor aleatorio extraído a partir de una distribución normal con media 0 y desviación estándar unitaria. Este proceso se aplica a cada uno de los n puntos del conjunto de datos experimentales. A modo de ejemplo, en la figura 2.9 se presenta el esquema seguido a lo largo del capítulo tercero de la presente Tesis Doctoral al utilizar la simulación de Monte Carlo: Conjunto de datos inicial: x i , y i x in= x i ± zsxi y in= y i ± zsyi BLS m iteraciones Coeficientes de regresión, b0 y b1 Se encuentran m b0 y b1 nuevas Figura 2.9.- Esquema de la utilización de la simulación de Monte Carlo en el capítulo 3 de la presente Tesis Doctoral. 2.9 Referencias 1.- Mathworks Inc., Newark, Massachussets, USA. 2.- B. Visante, P. Batallé, Métodos Estadísticos Aplicados. Tomo 1. Estadística Descriptiva, PPU, S.A., Barcelona (1991). 3.- Sir F. Galton, Journal of Anthropological Institute, 15 (1885) 246-263. 4.- W.A. Fuller, Measurement Error Models, John Wiley & Sons, New York (1987). 5.- C.L. Cheng, J.W. Van Ness, Statistical Regression with Measurement Error, Arnold, London (1999). 57 2. Fundamentos teóricos 6.- C.L. Cheng, J.W. van Ness, Journal of the Royal Statististical Society, Series B, 56 (1994) 167-183. 7.- G.A.F. Seber, Linear Regression Analysis, John Wiley & Sons, New York (1977). 8.- S.D. Edland, Biometriks, 52 (1996) 243-248. 9.- G.B. Schaalje, R.A. Butts, Biometriks, 49 (1993) 1262-1267. 10.- P. Sprent, Models in Regression and Related Topics, Methuen & Co. Ltd., London (1969). 11.- R.L Plackett, Biometrica, 59 (1972) 239-251. 12.- C. Eisenhart, Journal of the Washington Academy of Sciences, 54 (1964) 2433. 13.- S M Stigler, Ann. Statist., 9 (1981) 465-474. 14.- S M Stigler, Historia Mathematica, 4 (1977) 31-35. 15.- N. Draper, H. Smith, Applied Regression Analysis, 2ªed., John Wiley & Sons, New York (1996). 16.- I.E. Frank, R. Todeschini, The Data Analysis Handbook, Elsevier, Amsterdam (1994). 17.- D.L. Massart, B.G.M. Vandeginste, L.M.C. Buydens, S. de Jong, P.J. Lewi, J. Smeyers-Verbeke, Handbook of Chemometrics and Qualimetrics: Part A, Elsevier, Amsterdam (1997). 18.- J.O. Rawlings, Applied Regression Analysis, Wadsworth & Brooks/Cole Advanced Books & Software, Belmont (1988). 19.- C.H. Spiegelman, R.L.Watters, L. Hungwu, Chemometrics and Intelligent Laboratory Systems, 11 (1991) 121. 20.- H. Bennett, G. Olivier, XRF Analysis of Ceramics, Minerals and Allied Materials, John Wiley & Sons, New York (1992). 21.- K. Govindaraju, I. Roelandts, Geostandards Newsletter, 13 (1989) 5-67. 22.- X. Xie, M. Yan, L. Li, H. Shen, Geostandards Newsletter, 9 (1985) 83-159. 23.- X. Xie, M. Yan, L. Li, H. Shen, Geostandards Newsletter, 13 (1989) 83-179. 24.- E.S. Gladney, I. Roelandts, Geostandards Newsletter, 13 (1989) 217-268. 25.- R.M. Clark, Journal of the Royal Statististical Society, Series A, 142 (1979) 47-62. 26.- R.M. Clark, Journal of the Royal Statististical Society, Series A, 143 (1980), 177-194. 27.- P.Sprent, Contemporary Mathematics, 112 (1990) 3-15. 28.- G.R. Dolby, Biometrica, 63 (1976) 39-50. 58 2.9 Referencias 29.- L.J. Gleser, Journal of the American Statistical Association, 87 (1992) 696707. 30.- R.J. Adcock, Analyst, 4 (1877) 183-184. 31.- R.J. Adcock, Analyst, 5 (1878) 53-54. 32.- K. Pearson, Philos. Mag., 2 (1901) 559-572. 33.- T.C. Koopmans, Linear Regression Analysis of Economic Time Series, De Erven F. Bohn, N.V. Haarlem, The Netherlands (1937). 34.- A. Madansky, Journal of the American Statistical Association, 54 (1959) 173205. 35.- D. York, Canadian Journal of Physic, 44 (1966) 1079-1086. 36.- P.T. Boggs, J.E.Rogers, Contemporary Mathematics, 112 (1990) 183-194. 37.- G.H. Golub, C.F. Van Loan, SIAM Journal of Numerical Analysis, 17 (1980) 883-893. 38.- S. Van Huffel, J. Vandewalle, The Total Least Squares Problems. Computational Aspects and Analysis, Siam, Philadelphia (1991). 39.- C.H. Kummel, Analyst, 6 (1879) 97-105. 40.- J. Mandel, Journal of Quality Technology, 16 (1984) 1-14. 41.- D.W. Schafer, K.G. Puddy, Biometrika, 83 (1996) 813-824. 42.- K.C. Lai, T.K. Mak, Journal of the Royal Statististical Society, Series B, 41 (1979) 263-268. 43.- D.V. Lindley, Journal of the Royal Statististical Society / London Suppl., Series B, 9 (1947) 218-244. 44.- J. Riu, F.X. Rius, Journal of Chemometrics, 9 (1995) 343-362. 45.- C. Brooks, I. Went, W. Harre, J. Geophys. Res. 73 (1968) 6071. 46.- M. Lybanon, Am. Journal Phys., 52 (1984) 22. 47.- M. Lybanon, Comput. Geosci., 11 (1985) 501. 48.- W.H. Jeffreys, Astron. Journal, 85 (1980) 177. 49.- W.H. Jeffreys, Astron. Journal, 86 (1981) 149. 50.- D.R. Powell, J.R. Macdonald, Comput. Journal, 15 (1972) 148. 51.- D.R. Powell, J.R. Macdonald, Comput. Journal, 16 (1973) 51. 52.- G.L. Cumming, J.S. Rollett, F.J.C. Rossotti, R.J. Whewell, Journal Chem. Soc., 23 (1972) 2652. 53.- J.M. Lisý, A. Cholvadová, J. Kutéj, Computers and Chemistry, 14 (1990) 189192. 54.- J. Riu, F.X. Rius, Analytical Chemistry, 68 (1996) 1851-1857. 59 2. Fundamentos teóricos 55.- A.H. Kalantar, R.I. Gelb, J. S. Alper, Talanta, 42 (1995) 597-603. 56.- Commission d’Établissement des Méthodes d’Analyses du Commissariat à l’Énergie Atomique (Cetama), Statistique Appliquée à l’Exploitation des Mesures, 2ª ed., Masson, Paris (1986). 57.- G. Kateman, F.W. Pijpers, Quality Control in Analytical Chemistry, John Wiley & Sons, New York (1981). 58.- J.C. Olucha, F.X. Rius, Trends in Analytical Chemistry, 9 (1990) 77-79. 59.- M. Meloun, J. Militký, M. Forina, Chemometrics for Analytical Chemistry, Ellis Horwood limited, Chichester (1992). 60.- S.J. Haswell (ed.), Practical Guide to Chemometrics, Marcel Dekker Inc., New York (1992). 61.- M. Meloun, J. Militký, M. Forina, Chemometrics for Analytical Chemistry. Volume 2. PC-aided Regression and Related Methods, Ellis Horwood, London (1994). 62.- S. Weisberg, Applied Linear Regression, 2nd Ed., John Wiley & Sons, New York (1985). 63.- G.W. Snedecor, W.G. Cochran, Statistical Methods, 8th ed., Iowa State University Press, Ames (1989). 64.- P.D. Lark, B.R. Crowen, R.L.L. Bosworth, The Handling of Chemical Data, Pergamon Press, Oxford (1968). 65.- J.C. Miller, J.N. Miller, Statistics for Analytical Chemists, Ellis Horwood, Chichester (1984). 66.- J.N. Miller, Analyst, 116 (1991) 3. 67.- A.G. Asuero, A.G. González, Microchemical Journal, 40 (1989) 216. 68.- P.L. Bonate, Analytical Chemistry, 65 (1993) 1367. 69.- P. Hall, The Annals of Statistics, 14 (1986) 1431. 70.- T. Lwin, C.H. Spiegelman, Journal of the Royal Statistical Society Series C, 35 (1986) 256. 71.- ISO/IEC 17025 General Requirements for the Competence of Testing and Calibration Laboratories ISO, Geneva (1999). 72.- M. Sargent, Anal. Proc. 32 (1995) 201-202. 73.- H. Kaiser, Z. Anal. Chem., 3 (1947) 40. 74.- L.A. Currie, (IUPAC Recomendations). Pure & Applied Chemistry, 67 (1995) 1699-1723. 60 2.9 Referencias 75.- C. Liteanu, I. Rica, Statistical Theory and Methodology of Trace Análisis, Ellis Horwood, Chichester (1980). 76.- L.A. Currie, Ed., Detection in Analytical Chemistry: Importance, Theory, and Practice, cap.1, ACS Sympos. Serie 361, American Chemical Society, Washington (1988). 77.- A. Hubaux, G. Vox, Analytical Chemistry, 42 (1970) 586. 78.- L.A. Currie, Analytical Chemistry, 40 (1968) 849. 79.- M.E. Zorn, R.D. Gibbons, W.C. Sonzogni, Analytical Chemistry 69 (1997) 3069-3075. 80.- V. Barnett, T. Lewis, Outliers in Statistical Data, 3ª ed., John Willey & Sons, Chichester (1994). 81.- B. Peirce, Astr. Journal, 2 (1852) 161-163. 82.- P.J. Rousseeuw, A.M. Leroy, Robust Regression & Outlier Detection, John Willey & Sons, New York (1987). 83.- R.D. Cook, Technometrics, 19 (1977) 15-18. 84.- F.X. Rius, J. Smeyers-Verbeke, D.L. Massart, Trends in Analytical Chemistry, 8 (1989) 8-11. 85.- V. Barnett, Austral. J. Statist., 27 (1985) 151-162. 86.- C.L.Cheng, J.W. Van Ness, Technometrics, 39 (1997) 401-411. 87.- D.J. Cummings, C.W. Andrews, Journal of Chemometrics, 9 (1995) 489-507. 88.- F.R. Hampel, E.M. Ronchetti, P.J. Rousseeuw, W.A. Stahel, Robust Statistics, John Willey & Sons, New York (1986). 89.- P.J. Huber, Robust Statistics, John Willey & Sons, New York (1981). 90.- F.Y. Edgeworth, Hermathena, 6 (1887) 279-285. 91.- P.J. Huber, Ann. Stat. 1 (1973) 799-821. 92.- C.L. Mallows, Technometrics, 15 (1973) 661-678. 93.- R.W. Hill, Robust Regression when there are Outliers in the Carriers, Tesis Doctoral no publicada, Universidad de Harvard, Moston (1977). 94.- F.R. Hampel, Proceedings of the Statistical Computing Section of the American Statistical Association, ASA, Washington, D.C., (1978) 59-64. 95.- W.S. Krasker, R.E. Welsch, Journal of the American Statistical Association, 77 (1982) 595-604. 96.- E. Ronchetti, Statistical Probability Letters, 3 (1985) 21-23. 97.- A.M. Samarov, Journal of the American Statistical Association, 80 (1985) 1032-1040. 98.- P.J. Huber, The Annals of Mathematical Statistics, 43 (1972) 1041-1067. 61 2. Fundamentos teóricos 99.- H. Chernoff, J.L. Gastwirth, M.V. Johns, The Annals of Mathematical Statistics, 38 (1967) 52-72. 100.- H. Chernoff, I.R. Savage, The Annals of Mathematical Statistics, 29 (1958) 972-994. 101.- J.L. Hodges Jr., E.L. Lehmann, The Annals of Mathematical Statistics, 34 (1963) 598-611. 102.- J. Hájek, Z. Šidák, Theory of Rank Tests, Academic Press, New York (1967). 103.- P.J. Rousseeuw, J. Am. Stat. Assoc., 79 (1984) 871-880. 104.- F.R. Hampel, Bull. Int. Stat. Inst., 46 (1975) 375-382. 105.- D.L. Donoho, P.J. Huber, The notion of breakdown point, en A Festschrift for Erich Lehmann, editado por P. Bickel, K. Doksum, J.L. Hodges, Jr, Wadsworth, Belmont (1983). 106.- F.R. Hampel, Contributions to the Theory of Robust Estimation, Tesis Doctoral, University of California (1968). 107.- R.Y. Liu, The Annals of Statistics, 18 (1990) 405-414. 108.- P.J. Rousseeuw, M. Hubert, Journal of the American Statistical Association, 94 (1999) 388-402. 109.- S. Van Aelst, P.J. Rousseeuw, Journal of Multivariate Analysis, 73 (2000) 82-106. 110.- M.L. Brown, Journal of American Statistical Association, 77 (1982) 71-79. 111.- C. Hartmann, P. Vankeerberghen, J. Smeyers.Verbeke, D.L. Massart, Analytica Chimica Acta, 344 (1997) 17-28. 112.-Y. Hu, Expert Systems for Method Development in Analytical Chemistry, Tesis Doctoral, Vrije Universiteit Brussels (1989) 113.- R.J. Carroll, P.P. Gallo, Commun. Statist. Theor. Meth., 11 (1982) 25732585. 114.- M.B. Abdullah, Commun. Statist. Theory Meth., 18 (1989) 287-314. 115.- M.B. Abdullah, J. Statist. Comput. Sim., 33 (1989) 101-123. 116.- R.H. Ketellapper, A.E. Ronner, Metrika, 31 (1984) 33-41. 117.- H. Nyquist, Metrika, 34 (1987) 177-183. 118.- U. Feldmann, Eur. J. Clin. Chem. Clin. Biochem., 30 (1992) 405-414. 119.- P.C. Meier, R.E. Zünd, Statistical Methods in Analytical Chemistry, John Wiley & Sons, New York (1993). 120.- O. Güell, J.A. Holcombe, Analytical Chemistry, John Wiley & Sons, New York (1993). 62 2.9 Referencias 121.- H.A. Meyer (editor), Symposium on Monte Carlo Methods, Willey, Chichester, New York, 1956. 63 3 Capítulo Normalidad de los coeficientes de regresión 3.1 Introducción 3.1 Introducción A pesar del reciente desarrollo de los intervalos de confianza conjuntos de los coeficientes de la recta de regresión cuando se utiliza el método de regresión de BLS,1 no existen tests paramétricos que aseguren de forma individual la ausencia de sesgo en los coeficientes de regresión, cuando se tienen en cuenta los errores experimentales heteroscedásticos en cada punto. Con el fin de obtener las expresiones que permitan llevar a cabo dichos tests, es imprescindible conocer las distribuciones de los coeficientes de regresión. Dicha importancia se acrecienta en la regresión lineal considerando los errores en las dos variables pues en la bibliografía se encuentran indicaciones de que los coeficientes de regresión se distribuyen de una forma no Gaussiana2. En estudios de comparación de métodos analíticos, en ocasiones es interesante comprobar la existencia de errores sistemáticos proporcionales o constantes. Para comprobarlo a lo largo de un intervalo de concentraciones, se analizan una serie de muestras reales mediante el método que se tiene a prueba (lo llamaremos método candidato) y mediante un método del que se tiene certeza que da lugar a resultados exactos (por ejemplo un método de referencia), y se representan los resultados obtenidos con ambos métodos. Si el nuevo método (o método candidato) no presenta errores sistemáticos constantes, la ordenada en el origen no debe diferir significativamente de cero. Si el método candidato no presenta errores proporcionales sistemáticos, la pendiente de la recta no debe ser significativamente diferente de la unidad. Ambas situaciones pueden comprobarse mediante un test individual para la ordenada en el origen y la pendiente respectivamente. Otras aplicaciones de los tests individuales para la ordenada en el origen o la pendiente en calibración pueden ser la necesidad de efectuar correcciones del blanco, la comprobación de efectos matriz o la aplicación de constantes de recuperación. Sin embargo, si lo que se pretende es comparar dos métodos de análisis, se deben comparar simultáneamente los dos coeficientes de regresión. Para ello se debe utilizar el test conjunto para la ordenada en el origen y la pendiente.3 67 3. Normalidad de los coeficientes de regresión En el siguiente apartado de este capítulo se presenta el artículo: “Detecting proportional and constant bias in method comparison studies by using linear regression with errors in both axes”, que se ha publicado en la revista Chemometrics and intelligent laboratory systems. La investigación que se presenta en el artículo ha sido llevada a cabo en colaboración con Ángel Martínez, miembro del Grupo de Quimiometria i Qualimetria de la Universitat Rovira i Virgili. Mi contribución en el artículo se corresponde con el objetivo del presente capítulo y es estudiar la normalidad de los coeficientes de regresión de la recta BLS. Además, en el artículo se utiliza la información extraída del estudio de la normalidad de los coeficientes de regresión, para poder detectar un sesgo constante o proporcional en los procesos de comparación de métodos utilizando regresión lineal cuando se consideran los errores experimentales en las variables predictora y respuesta. También se han desarrollado las expresiones para el cálculo del tamaño de muestra necesario para obtener unos errores α y β fijados en la predicción de ambos coeficientes de regresión individualmente. Como dato de nomenclatura, hay que destacar que el artículo de la siguiente sección presenta una notación ligeramente diferente de la detallada en la sección 2.1. Esto es debido a que dicho artículo se realizó con anterioridad a un perfeccionamiento de la notación llevado a cabo tras una exhaustiva revisión bibliográfica sobre el tema. Las siguientes secciones del capítulo presentan la bibliografía y las conclusiones que se extraen al analizar el capítulo en el contexto de la Tesis Doctoral. 68 3.2 Chemom. Intell. Lab. Sys. 49 (1999) 179-193 3.2 Detecting proportional and constant bias in method comparison studies by using linear regression with errors in both axes Chemometrics and Intelligent Laboratory Systems 49 (1999) 179-193 Ángel Martínez*, F. Javier del Río, Jordi Riu, F.Xavier Rius Department of Analytical and Organic Chemistry. Universitat Rovira i Virgili. Pl. Imperial Tarraco, 1. 43005-Tarragona. Spain. Constant or proportional bias in method comparison studies using linear regression can be detected by an individual test on the intercept or the slope of the line regressed from the results of the two methods to be compared. Since there are errors in both methods, a regression technique that takes into account the individual errors in both axes (bivariate least squares, BLS) should be used. In this paper we demonstrate that the errors made in estimating the regression coefficients by the BLS method are fewer than with the OLS or WLS regression techniques and that the coefficient can be considered normally distributed. We also present expressions for calculating the probability of committing a β error in individual tests under BLS conditions and theoretical procedures for estimating the sample size in order to obtain the desired probabilities of α and β errors made when testing each of the BLS regression coefficients individually. Simulated data were used for the validation process. Examples for the application of the theoretical expressions developed are given using real data sets. Keywords: Bivariate least-squares; Linear regression; Probability Received 12 November 1998; received in revised form 10 June 1999; accepted 11 June 1999 69 3. Normalidad de los coeficientes de regresión 1. Introduction Linear regression is widely used in the validation of analytical methodologies. In method comparison studies, for example, a set of samples of different concentration levels are analysed by the two methods to be compared, and the results are regressed on each other. Ordinary least-squares (OLS), or weighted least-squares (WLS), which considers heteroscedasticity in the response variable, are the most widely used regression techniques. However, these techniques have a limited scope, since they consider the x-axis to be free of error. OLS and WLS should not usually be applied, for instance, in method comparison studies, since the uncertainties associated with the methods to be compared are usually of the same order of magnitude. An alternative is the errors-in-variables regression [1], also called CVR approach [2-4], which considers the errors in both axes. It does not take into account the individual uncertainties of each experimental point but considers the ratio of the variances of the response to predictor variables to be constant for every experimental point (λ=sy2/sx2). A particular case of the CVR approach is the orthogonal regression (OR) [5], in which the errors are of the same order of magnitude in the response and predictor variable (i.e. λ=1). Another option is a bivariate least squares (BLS) regression technique [6,7], which takes into account individual non-constant errors in both axes to calculate the regression coefficients. Despite the recent development of a joint confidence interval test for the BLS regression method [8], no statistical test to individually assess the presence of bias in the regression coefficients which takes into account the individual uncertainties in every experimental point has yet been described. For this reason, we present expressions for the application of the individual tests which take into account individual errors in both axes. Although the distributions of the BLS slope and intercept have been reported to be nongaussian [9], in this paper we show that the results of applying statistical tests based on the assumption of normality of the BLS regression coefficients do not show significant errors and that these errors are fewer than those obtained with the OLS or WLS regression techniques. 70 3.2 Chemom. Intell. Lab. Sys. 49 (1999) 179-193 Of the two types of error associated with the statistical tests (α and β), the β error, related to the probability of not detecting an existing proportional or constant bias is seldom considered. However, the theoretical background and the expressions which enable its calculation in the individual tests which use the OLS method have already been developed [5]. In this paper we describe the expressions for estimating the probability of β error when performing an individual test on one of the regression coefficients to detect a set proportional or constant bias based on the BLS regression technique. These expressions take into account the different distributions that may be associated to the reference and to the selected biased regression coefficient values. These estimates are compared with the ones from the OLS and the WLS techniques for several real data sets. Finally, we describe the procedure for estimating the sample size, i.e. the number of experimental data pairs necessary for detecting the specific selected bias when performing an individual test with set probabilities of making α and β errors when the BLS regression method is used. Simulated data sets have been used to validate the theoretical expressions. 2. Background and theory 2.1. Notation In general, the true values of the different variables used in this work are represented with greek characters, while their estimates are denoted with latin letters. In this way, the true values of the BLS regression coefficients are represented by β0 (intercept) and β1 (slope), while their respective estimates are denoted as a and b. The estimates of the standard deviation of the slope and the intercept for the BLS regression line, are symbolised as sb and sa respectively. The experimental error, expressed in terms of variance for the n experimental data pairs (xi,yi), is referred to as σ2, while its estimate is s2. By analogy, ŷi represents the estimated value for the yi predicted. The estimated variance-covariance matrix of the regression coefficients related to the BLS regression technique is denoted as B. 71 3. Normalidad de los coeficientes de regresión In the individual tests, the terms a H 0 , a H1 , bH 0 and bH1 represent the values of the theoretical regression coefficients from which the null (H0) and the alternative hypothesis (H1) are assumed. The distance between a H 0 and a H1 or between bH 0 and bH1 , known as bias, is denoted by ∆ and represents the value of the systematic error that the experimenter wants to check. By analogy, the values of the standard deviations of the theoretical regression coefficients defining H0 and H1 are denoted as saH (or sbH ) and saH (or sbH ). 0 0 1 1 2.2. BLS BLS is the generic name given to a set of regression techniques applied to data which contain errors in both axes. From all the different existing approaches for calculating the regression coefficients, Lisý’s method [6] was found to be the most suitable [7]. This technique assumes the true linear model to be: ηi = β 0 + β1ξ i . (1) The true variables ξi and ηi are unobservable and instead, one can only observe the experimental variables: xi = ξ i + δ i and yi = ηi + γ i . (2) Variables δi and γi are random errors committed in the measurement of variables xi and yi respectively, where δ i ~ N (0, σ x2i ) and γ i ~ N (0, σ y2i ) . In this way, the observed variables xi and yi are related as follows: yi = a + bxi + ε i , (3) where εi is the ith residual error. The BLS regression method finds the estimates of the regression line coefficients by minimising the sum of the weighted residuals, S, expressed in Eq. (4): 72 3.2 Chemom. Intell. Lab. Sys. 49 (1999) 179-193 ( yi − yˆ i ) 2 = ( n − 2) s 2 . 2 s i =1 εi n S=∑ (4) The weighting factor sε2i is expressed as the variance of the ith residual ε i and takes into consideration the variances of any individual point in both axes ( s x2i and s 2yi ) obtained from the replicate analysis of each sample by both methods. The covariance between the variables for each (xi,yi) data pair, which is normally assumed to be zero, is also taken into account: var (ε i ) = var( yi − a − bxi ) = sε2i = s 2yi + b 2 s x2i − 2b cov( xi , yi ) . (5) For this reason, the BLS regression technique assigns higher weights to those data pairs with larger s x2i and s 2yi values, i.e. the most imprecise data pairs. By minimising the sum of the weighted residuals (Eq. (4)), two non-linear equations are obtained, from which the regression coefficients a and b can be estimated by an iterative process [8]. 2.3. Characterisation of the distribution of the BLS regression coefficients The distribution functions of the regression coefficients a and b found by the BLS regression technique have been reported to be nongaussian [9]. This influences the individual tests on the regression coefficients, since they are usually performed under the assumption of normality. To determine the degree of nonnormality of the distributions of the BLS coefficients, three different statistical tests were used: Cetama [10] (which also allows the actual probability function to be characterised), the Kolmogorov test [11] and the normal probability plot (or Rankit test) [12]. These tests were applied to different types of real data sets to find a relationship between their structure and the degree of non-normality. Furthermore, to characterise their distribution, the real distributions and some theoretical distributions were compared. These comparisons were carried out with the quantile-quantile graphic method (Q-Q plot) [12]. 73 3. Normalidad de los coeficientes de regresión 2.4. β error in the individual tests for the BLS regression coefficients According to the theory of hypothesis testing, when an individual test is applied on a regression coefficient, the null hypothesis H0 is usually defined as the one that considers the estimated regression coefficient to belong to the distribution of a hypothetical regression coefficient ( a H 0 or bH 0 ) equal to the reference value, or in other words, that there are no proportional or constant systematic errors in the method being tested. On the other hand, the alternative hypothesis H1 considers that the estimated regression coefficient belongs to the distribution of a hypothetical regression coefficient ( a H1 or bH1 ) with a given value. This value, which has to be set by the experimenter according to the systematic error one wants to detect in the analytical method being tested, defines the distance between a H 0 (or bH 0 ) and a H1 (or bH1 ), or in other words the so-called bias [13]. The standard deviations saH (or sbH ) and saH (or sbH ) can be calculated for a given data set 0 0 1 1 with the values of a H 0 (or bH 0 ) and a H1 (or bH1 ). The expressions developed for estimating the probability of committing a β error in the application of an individual test to one of the regression coefficients calculated by using the OLS regression technique are established [5]. Analogous expressions can be adapted for the BLS technique by considering the appropriate standard deviation values: ∆ b = tα 2 ⋅ sbH 0 + t β ⋅ sbH1 Ö t β = ∆ a = tα 2 ⋅ saH 0 + t β ⋅ saH1 Ö t β = ∆ b − tα 2 ⋅ sbH 0 sbH 1 ∆ a − tα 2 ⋅ saH 0 saH (6) . (7) 1 The probability of committing a β error under the assumption of normality is finally given by the Student’s t value for n-2 degrees of freedom for a fixed level of significance α. The standard deviations saH (or sbH ) and saH (or 0 74 0 1 3.2 Chemom. Intell. Lab. Sys. 49 (1999) 179-193 sbH ) can be estimated in a similar way to the standard deviations of the intercept 1 and the slope, and are easily obtained from the B variance-covariance matrix [8] calculated while estimating the regression coefficients with the BLS technique: xi2 ∑ s2 i =1 ε i n sa = sb = 2 ×s (8) 2 ×s. (9) n xi x 1 × − ∑ s 2 ∑ s ∑ s 2 i =1 ε i i =1 i =1 ε i n 2 i 2 εi n n 1 i =1 εi ∑ s2 x x 1 ∑ s 2 × ∑ s − ∑ s 2i i =1 ε i i =1 i =1 εi n 2 i 2 εi n To calculate the values of saH 0 n (or sbH ) and saH (or sbH ) it is only 0 1 1 necessary to recalculate the value of the weighting factor (Eq. (5)) according to the new slope value. Due to the dependence of the weighting factor on the slope, the values of saH 0 and saH will be equal to the standard deviation obtained for the 1 estimated regression coefficient ( sa = saH = saH ), which is not true for the slope. 0 1 2 The experimental error s remains unchanged. 2.5. Estimating the sample size Relating Eqs. (8-9) with the number of data pairs n it is possible to estimate the number of data pairs required to detect certain bias with set probabilities of committing α and β errors. This can only be achieved if the individual uncertainties, and hence the weighting factors are considered constant for all the data pairs ( sε2a , sε2b H0 H0 or sε2b = ct): H1 75 3. Normalidad de los coeficientes de regresión n saH = 0 sbH 0 = sbH = 1 ∑ xi2 ⋅ sε2 aH i =1 0 n n a ⋅ ∑ x − ∑ xi i =1 i =1 n ⋅s. 2 (10) 2 i nb ⋅ sε2bH ⋅ s or 0 n n b ⋅ ∑ x − ∑ xi i =1 i =1 n 2 2 i nb ⋅ sε2bH 1 n nb ⋅ ∑ x − ∑ xi i =1 i =1 n 2 ⋅s . (11) 2 i Introducing these two expressions in Eq. (6-7) respectively it is possible to isolate n in terms of the desired variables α, β and ∆: na = (tα / 2 + t β ) 2 ⋅ sε2a H ∆2a 0 n xi ∑ i =1 2 ⋅s + n ∑ xi2 2 (12) i =1 nb = n ∆ ⋅ ∑ xi i =1 2 2 b n ∆2b ⋅ ∑ xi2 −(tα / 2 ⋅ sε bH + t β ⋅ sε bH ) 2 ⋅ s 2 0 i =1 Initial estimates of the terms sε2a H0 . (13) 1 or sε2b H0 and sε2b , s2 and both sums H1 involving x data coordinates can be set from an initial data set containing few data pairs. After an iterative calculation (due to the dependence of the tα/2 and tβ values on the number of data pairs) an estimate of na or nb is obtained. It is then important to recalculate the sample size adding more data to the initial data set, as the estimates of the terms mentioned in Eqs. (12-13) are likely to change. In this way a 76 3.2 Chemom. Intell. Lab. Sys. 49 (1999) 179-193 new estimate of na or nb is obtained. The estimation process ends when the differences between two consecutive na or nb values are below a set threshold value. 2.6. Validation The objective of the validation process is twofold. Firstly, to show that, despite the non-normal distribution of the BLS regression line coefficients, the confidence interval computed using the t-distribution can generally be accepted without committing relevant errors. Secondly, to assess whether the theoretical estimate of either the β error and the number of data pairs required to perform the individual tests, based on BLS under defined statistical conditions, provides correct results. a1 b1 1 a2 Initial data set Monte Carlo b2 2 3 n straight lines Tests of normality a b a3 b3 n ·· · ·· · an bn Figure 1. Scheme of the procedure followed to check the normality of the BLS regression coefficients using the Monte Carlo simulation method and the three selected test for checking the normality. To show the degree of non-normality of the intercept and the slope distributions under real regression conditions, six real data sets with errors in both axes were studied. The Monte Carlo method [14] was applied to generate 200,000 data sets from each of the six initial ones (Figure 1). This method adds a random error to every data pair based on the individual uncertainties in both axes. In this way, 200,000 simulated data sets were randomly generated. This gave rise to 200,000 regression lines, to which the three selected tests for assessing the 77 3. Normalidad de los coeficientes de regresión normality of the distributions were applied. The error made in estimating the BLS regression coefficients when their respective distributions were assumed to be normal (when in fact they are not) was quantified and compared with the error made in estimating the regression coefficients by OLS and WLS techniques. Figure 2 illustrates the comparison procedure. Once the distribution of the regression coefficients corresponding to the real data set is obtained by the Cetama method, we can determine its left (xlr) and right (xrr) limits for a chosen level of significance α. The shaded areas in Figure 2 represent the errors made by estimating the regression coefficients with each of the three regression techniques studied. Real distribution xlr xrr BLS xrbls xlbls WLS xlwls xrwls OLS xlols xrols Figure 2. Error made in estimating the BLS regression coefficients assuming normal distributions. Comparison with errors made using OLS and WLS regression techniques. 78 3.2 Chemom. Intell. Lab. Sys. 49 (1999) 179-193 To validate the expressions for the estimation of the probability of β error, 24 initial simulated data sets were used with all the data pairs perfectly fit to an straight line with either biased slope or intercept values. From each of these initial data sets, 100,000 simulated new ones were randomly generated by adding a random error to every individual data pair (xi,yi) in the initial data set with the Monte Carlo method. An individual test was then applied on one of the regression coefficients for every one of these 100,000 data sets to check whether H0 could be accepted in each case for a fixed level of significance α. So every time H0 was accepted, a β error was being committed because the data set had been generated from an initial biased one, but due to the application of random errors by the Monte Carlo method, however, the bias could not be detected. The value of the bias was chosen to provide a probability of β error similar to the level of significance α in each of the four cases. In this way, if the estimate of the probability of β error from the theoretical expressions was similar to the one from the simulation process, we may conclude that the stated expressions provide correct results. Once the estimates of the probability of β error were proved to be correct, the expressions to estimate the sample size were validated. The probabilities of β error estimated for the different levels of significance α, the calculated standard deviations and the experimental error from the iterative process (terms tβ , tα/2 , sε2a , sε b or sεb H0 H0 H1 and s2 respectively) for each of the initial data sets in the validation process were introduced in expressions 12 and 13. If the estimated sample size required to achieve the chosen probabilities of α and β error was similar to the number of data pairs in each data set, results were considered correct. To show the applicability of the procedure, a real data set was used as a case study. 3. Experimental 3.1. Data sets and software Six real data sets with different characteristics (such as number of data pairs, heteroscedasticity or position within the experimental domain) were used to check the distribution of the BLS regression coefficients. Twenty-four different 79 3. Normalidad de los coeficientes de regresión simulated data sets were considered to validate the expressions for the estimates of the probability of β error (Eqs. (6-7)). Finally, one of the six former real data sets was used to show the different estimates of the probability of β error between BLS, OLS and WLS regression techniques and provide an example of the sample size estimation procedure using data with errors in both axes. Data Set 1 [15]. Data set obtained from the study of the supercritical fluid extraction (SFE) recoveries of policyclic aromatic hydrocarbons (PAHs) from railroad bed soil using two different modifiers; CO2 (on the x-axis) and a mixture of CO2 with 10% of toluene (on the y-axis). The data set is composed of seven data pairs. The standard deviations ( s xi and s yi ) were the result of a triplicate supercritical fluid extraction at each level of concentration. The units are expressed in terms of µg/g of soil. The data set and the regression lines obtained by the OLS, WLS and BLS regression techniques are shown in Figure 3a. Data Set 2 [16]. Comparative study of mercury determination using gas chromatography coupled to a cold vapour atomic fluorescence spectrometer following derivatization with sodium tetraethylborate. One (x-axis) and two (yaxis) amalgamation steps were used to obtain five data pairs with their respective uncertainties ( s xi and s yi ) generated from six replicates performed at each point. Units are expressed in terms of pg of recovered mercury. The data set and the regression lines generated by the three regression techniques are shown in Figure 3b. Data Set 3 [17]. Twenty-seven data pairs obtained from a method comparison study which analysed Ca(II) in water by atomic absorption spectroscopy (AAS), taken as the reference method (x-axis), and sequential injection analysis (SIA), taken as the tested method (y-axis). The data set and the regression lines generated by OLS, WLS and BLS regression techniques are shown in Figure 3c. Units are expressed in mg/l. The uncertainties associated with the AAS method were derived from the analytical procedure, including the linear calibration step [18]. The uncertainties of the SIA results were calculated with a multivariate regression model and the PLS technique using the Unscrambler program (Unscrambler-Ext, ver. 4.0, Camo A/S, Trondheim, Norway). 80 3.2 Chemom. Intell. Lab. Sys. 49 (1999) 179-193 Data Set 4 [19]. Comparative study for determining arsenic in natural waters from two techniques: continuous selective reduction and atomic absorption spectrometry (AAS) as the reference method (x-axis) and non-selective reduction, cold trapping and atomic emission spectrometry (AES) as the tested method (yaxis). Thirty experimental data pairs were obtained with three replicates per data pair. The units are expressed in terms of µg/l. The data set and the regression lines obtained using all three regression techniques are shown in Figure 3d. Data Set 5 [20]. Data set obtained by measuring the CO2 JouleThompson coefficient. The data was acquired from thermocouple-measured voltage differences (∆mV, on the y-axis) as a function of pressure increments (∆kPa, on the x-axis). Eleven equally-distributed data pairs were obtained with estimated unity x-axis uncertainties. The y-axis uncertainties were estimated to be between one and two units. The data set and the three regression lines found by using the stated regression techniques are shown in Figure 3e. Data Set 6 [21]. Comparative study of the average recoveries for organochlorine pesticides present in solvent (on the x-axis) or in solvent/soil suspension (on the y-axis) after microwave-assisted extraction (MAE) analysis. Twenty-one data pairs were used in the analysis. The uncertainties were obtained from triplicate MAE analysis at each point. The data set and the straight lines regressed by the three regression techniques are shown in Figure 3f. To validate the estimates of the probability of β error, twenty-four different initial data sets showing different values of bias in the intercept or in the slope were built to cover several analytical situations; different linear ranges, number of data pairs and uncertainty patterns. Linear Ranges: Two linear ranges were considered during validation, a short one for values from 0 to 10 units, and a large one for values from 0 to 100 units. Number of data pairs: Data sets containing five, fifteen, thirteen and a hundred data pairs were selected. In all cases the data pairs were randomly distributed throughout the two different linear ranges. 81 3. Normalidad de los coeficientes de regresión 30 1000 (a) 25 800 140 (b) 120 (c) 100 15 600 80 SIA 2 amalgamations CO2 / 10% toluene 20 400 60 10 200 5 0 40 0 0 5 10 15 20 25 30 20 -200 -200 0 CO2 (d) 60 800 30 0 20 10 40 15 AAS / selective reduction 20 25 10 40 60 80 100 120 AAS 200 (e) (f) 150 40 5 5 20 solvent / soil 10 0 0 0 1000 50 ∆ mV AES / cold trapping 600 70 15 -5 -5 400 1 amalgamation 25 20 200 100 60 80 100 ∆ kPa 120 140 160 50 80 85 90 95 100 105 110 115 120 125 solvent Figure 3. OLS (dashed line), WLS (dotted line) and BLS (solid line) regression lines obtained for the six real data sets. Uncertainties: Homoscedastic and heteroscedastic data sets were considered. The homoscedastic data sets were comprised of data pairs with constant standard deviations on both x and y values. In the short linear ranges the standard deviations presented half unity values, whereas in the large linear ranges they showed unity values. The heteroscedastic data sets were divided into two other different types. On one hand those with increasing standard deviations and on the other hand, those which presented random standard deviations. In both cases however, the standard deviation values were never higher than the 10% of each individual xi and yi value. For every one of the twenty four different simulated data sets, four levels of significance α were considered: 10, 5, 1 and 0.1%. Depending on the regression coefficient being tested and on the level of significance, the slope ( bH1 ) or the intercept value ( a H1 ) of the selected bias changed in such a way that the probabilities of β error from the iterative process were similar to the specified α 82 3.2 Chemom. Intell. Lab. Sys. 49 (1999) 179-193 values. In this way the accuracy of estimates of different magnitudes from Eqs. (67) was also tested. All the computational work was performed with home-made Matlab subroutines (Matlab for Microsoft Windows ver. 4.0, The Mathworks, Inc., Natick, MA). 4. Results and discussion 4.1. Distribution of the regression coefficients The results of studying the distributions of the slope (b) and the intercept (a) using the three tests to check normality are summarised in Table 1. The variation in the number of iterations needed to achieve non-normality can be used to identify the degree of normality. The more iterations needed to achieve nonnormality (if finally achieved) the more normal the distribution is. Data set 1 presents non-normal distributions mainly due to the high lack of fit of the data pairs to the regression line. Data sets 2 and 5 present the best goodness of fit of all the sets, which helps the distribution of the regression coefficients to be normal. In data set 3, the data structure and the errors in both axes make the regression line mainly change the intercept value, which leaves the slope almost unmodified. In this way the intercept value shows a major uncertainty which leads to a non-normal distribution, whereas a much lower uncertainty is associated to the slope value. In data set 4, the slope of the regression line does not follow a normal distribution since the remarkable heteroscedasticity along the experimental range causes the regression line to move along a conical-shaped region when considering errors in both axes. This varies the slope and leaves the intercept almost unmodified. Finally, data set 5 has normal distributions and data set 6 presents non-normal ones due to the irregular disposition of the points in the space and the high heteroscedasticity. The more similar the error pattern to OLS conditions (i.e. larger errors in the y axis than in the x axis, homoscedasticity) and the better the goodness of fit, the more normal the distribution is. It has to be 83 3. Normalidad de los coeficientes de regresión pointed out that the Cetama method was the most sensitive in detecting deviations from normality. Cetama data set Iterations 1 10.000 30.000 50.000 100.000 200.000 10.000 30.000 50.000 100.000 200.000 10.000 30.000 50.000 100.000 200.000 10.000 30.000 50.000 100.000 200.000 10.000 30.000 50.000 100.000 200.000 10.000 30.000 50.000 100.000 200.000 2 3 4 5 6 a$ b$ NSNL NSLRL NSNL NSNL NSNL NSNL NSNL NSNL NSNL NSNL N NSNL N NSLRL N NSNL NSNL NSNL NSLRL NSLL NSNL NSLRL NSNL NSLRL NSNL NSNL NSLRL NSLRL NSNL NSNL N NSNL N NSNL N NSNL N NSNL N NSNL N N N N N N N N N N NSNL NSNL NSNL NSNL NSNL NSNL NSNL NSNL NSNL NSNL α=1% a$ b$ N NN NN NN NN NN NN NN NN NN N N N N N N N N N N N N N N NN N NN N NN N N N N NN N NN N NN N NN N N N N N N N N N N N NN N NN NN NN NN NN NN NN Kolmogorov α=5% a$ b$ NN NN NN NN NN NN NN NN NN NN N N N N N N N N N N N N N N NN N NN N NN N N N N NN N NN N NN N NN N N N N N N N N N N N NN NN NN NN NN NN NN NN NN α=10% b$ NN NN NN NN NN NN NN NN NN NN N N N N N N N N N N N N N N NN N NN N NN N N N N NN N NN N NN N NN N N N N N N N N N N N NN NN NN NN NN NN NN NN NN a$ Rankit Plot a$ b$ NN NN NN NN NN NN NN NN NN NN NN NN N N N N N N N N NN NN NN N NN N NN N NN N N N N NN N NN N NN N NN N N N N N N N N N N NN NN NN NN NN NN NN NN NN NN N: Normal distribution. NN: Non-normal distribution. NSNL: Non-symmetric and non-limited. NSLRL: Non-symmetric and left and right limited. NSLL: Non-symmetric and left limited. Table 1. Normality study results for the BLS regression coefficients. Table 2 shows the quantification of the error made in estimating the BLS regression coefficients when normality in their distributions is assumed, and the comparison with the analogous results from OLS and WLS regression techniques. The error is calculated according to the shaded areas in Figure 2 (where the error is considered to be the part that belongs to the OLS, WLS or BLS distribution for a fixed α level and which does not belong to the real distribution, and the part that 84 3.2 Chemom. Intell. Lab. Sys. 49 (1999) 179-193 does not belong to the OLS, WLS or BLS distribution for the same α level and belongs to the real one). This table shows that the error made from assuming normality for the BLS regression technique is low, and significantly lower than the ones obtained for the OLS and WLS regression methods for all the data sets. The data sets that present BLS regression coefficients as normally distributed have errors equal to zero. We can also see that the error committed when using the WLS method is usually lower than when using OLS. % Error data set Coefficient BLS WLS OLS 1 a$ b$ a$ b$ a$ b$ a$ b$ a$ b$ a$ b$ 4.69 4.46 0 0 0.53 0.58 0 2.79 0 0 2.48 2.48 26.84 14.59 9.81 5.51 1.37 6.20 5.11 14.97 0.26 0.25 2.31 3.75 58.29 16.43 44.35 3.66 11.42 11.03 88.50 25.28 0.62 3.28 6.60 6.45 2 3 4 5 6 Table 2. Difference between the theoretical and estimated regression coefficients by the three regression techniques (normal distributions assumed). Once the BLS regression coefficients have been found, in most cases, to be non-normally distributed, their distributions were compared with some theoretical ones (beta, binomial, chi-squared, exponential, F, gamma, geometric, hypergeometric, normal, Poisson, t-Student, uniform, uniform discrete and Weibull distributions) using the quantile-quantile plot graphic method (Q-Q plot) [12]. As the results provided by the Cetama method (Table 1) indicate that the regression coefficients that do not follow a normal distribution are mainly non-symmetric and non-limited, it seems reasonable to suppose that the regression coefficient distributions follow some kind of constant pattern. However, the results given by the Q-Q plot indicate that the theoretical distributions that are most similar to the 85 3. Normalidad de los coeficientes de regresión real ones are the chi-squared, normal and t-Student since their differences are very difficult to appreciate. 4.2. β error and sample size validation Tables 3 and 4 summarise the results from 100,000 iterations using the Monte Carlo method for the four levels of significance in the twenty four simulated data sets. Columns a H1 and bH1 show the regression coefficient values which define the chosen bias (distance between H0 and H1). The values in the βexp column are those from the simulation process, whereas the values shown in the βpred column are the ones obtained with the theoretical expressions to be validated (Eqs. (6-7)). Finally, the values in the column npred are the estimated sample sizes of the different simulated data sets for the different levels of significance. To detect significant differences between the estimated probabilities of β error and the values from the simulation process, paired t-tests [22] (with α=1%) were applied on the β error values obtained for the different number of data points (since it is the most critical factor for achieving good predictions of probabilities of β error) at the same level of significance. In this way significant differences between the values in the βexp and βpred columns were found only in the data sets with five data pairs for the slope and intercept at the four levels of significance. The possible sources of error and some important observations concerning the results from the simulation process can be summarised as follows: (i) In most cases the predicted probabilities of β error from Eqs. (6-7) are higher than the experimental values from the simulation process. This overestimation may be due to a lack of information, since the overestimation is higher in those data sets with fewer data pairs (where the experimental error, and thus the uncertainty of the regression coefficient is higher [23]), and lower in those data sets with a larger number of points. In this latter case however, small disagreements still exist due to the assumption of the normality of the regression coefficients. Figure 4 plots the differences between the experimentally-obtained probabilities of β error (from the simulation process) and the predicted probabilities against the number of data pairs of each data set for the slope and intercept with a level of significance of 5%. Only the results corresponding to the 86 3.2 Chemom. Intell. Lab. Sys. 49 (1999) 179-193 low range are shown in Figure 4 since the results for the high range where identical. (ii) Results for the intercept show a higher agreement than the ones for the slope (Figure 4). This may be because estimating the slope is more complex since two different distributions have to be considered for bH 0 and bH1 , whereas only one is needed when the probabilities of β error are estimated for the intercept, as saH = saH . 0 1 (iii) There is no clear relationship between the uncertainty patterns and the error made in predicting the β error (in percent) for the different simulated data sets. As Figure 4 shows, the three lines depicting the three patterns of uncertainty do not maintain a constant relative position as they cross each other. Results for the intercept seem to follow a steadier pattern for the different uncertainties. As previously stated, the number of data pairs on the regression line is the key factor for obtaining a better estimate of the β error. (iv) Results from the predicting the probabilities of β error (Eqs. (6-7)) and sample size (Eqs. (12-13)) for data sets with a high linear range were identical to the ones with a low linear range. Results shown in Tables 3 and 4 correspond to the low linear range, while the ones from the high linear range have been omitted. These results can be explained because the distribution of the data pairs in data sets (for a given uncertainty and number of data pairs) with different linear ranges is identical. So the only difference between data sets with different linear ranges is that the values of the individual data pairs and their respective uncertainties (taken as standard deviations) are ten times higher in the high linear range than in the low linear range. Only the standard deviation values for the intercept were exactly ten times higher in the high linear range than the ones in the low linear range. This is due to the direct dependence of the standard deviation for the intercept on the sum of the x-axis values (Eq. (8)). 87 3. Normalidad de los coeficientes de regresión 180 %∆β 160 Slope 140 homoscedasticity 120 heteroscedasticity random heteroscedasticity 100 80 60 40 20 0 0 20 40 60 80 100 Number of data pairs 100 %∆β 90 Intercept 80 homoscedasticity 70 heteroscedasticity 60 random heteroscedasticity 50 40 30 20 10 0 0 20 40 60 80 100 Number of data pairs Figure 4. Difference between the experimentally-obtained probabilities (simulation process) and the predicted probabilities of β error for the slope and the intercept (in percent) in relation to the number of data pairs for each data set. If we look at the results of estimating the sample size in Tables 3 and 4 (npred columns), we can see that the predicted results in all cases provide the correct number of data pairs of the different initial data sets considered. From these results we can conclude that the expressions for estimating the sample size provide correct results for the three kinds of distribution of uncertainties considered. 88 3.2 Chemom. Intell. Lab. Sys. 49 (1999) 179-193 n Uncertainty α(%) aH 1 saH βexp. βpred. npred. 5 homo. 10 5 1 0.1 2.4 3.2 5.2 10.5 0.641 9.97 5.02 2.22 0.13 12.91 8.39 5.38 2.03 5 5 5 5 hetero. 10 5 1 0.1 0.7 0.95 1.5 3 0.189 10.11 4.32 2.75 0.74 13.67 8.26 6.53 3.14 5 5 5 5 heter. rnd. 10 5 1 0.1 1 1.3 2.1 4.3 0.261 8.36 4.80 2.23 0.11 11.77 8.48 5.71 2.59 5 5 5 5 homo. 10 5 1 0.1 1 1.3 1.9 2.6 0.341 13.24 5.73 0.93 0.10 13.34 6.14 1.19 0.24 15 15 15 15 hetero. 10 5 1 0.1 5e-2 1.69e-2 6.5e-2 9.5e-2 0.125 12.02 4.98 0.57 0.10 12.99 4.9 1.11 0.28 15 15 15 15 heter. rnd. 10 5 1 0.1 2.5e-2 8.79e-3 3.4e-2 4.5e-2 6.4e-2 13.95 4.39 1.81 0.13 15.12 5.56 2.75 0.45 15 15 15 15 homo. 10 5 1 0.1 0.262 12.93 4.36 1.74 0.12 12.82 4.43 1.84 0.17 30 30 30 30 hetero. 10 5 1 0.1 5.5e-3 1.92e-3 7e-3 9.5e-3 1.2e-2 12.19 5.53 1.43 0.54 12.62 5.99 1.84 0.76 30 30 30 30 heter. rnd. 10 5 1 0.1 1.9e-2 6.48e-3 2.4e-2 3.2e-2 4.3e-2 11.07 4.97 1.50 0.16 11.46 5.47 1.92 0.31 30 30 30 30 homo. 10 5 1 0.1 0.142 12.78 6.61 1.77 0.35 12.68 6.51 1.70 0.32 100 100 100 100 hetero. 10 5 1 0.1 1.5e-5 5.37e-6 1.9e-5 2.6e-5 3.4e-5 12.89 6.02 1.41 0.19 12.98 6.16 1.45 0.20 100 100 100 100 heter. rnd. 10 5 1 0.1 1.9e-4 6.41e-5 2.4e-4 3e-4 4.2e-4 9.49 3.86 1.91 0.07 9.76 4.07 2.13 0.10 100 100 100 100 15 30 100 0.75 1 1.3 1.8 0.4 0.5 0.68 0.88 0 Table 3. Estimated and experimentally obtained probabilities of β error for individual tests on the intercept. Predicted sample size to achieve the probabilities of α and β error for each data set. 89 3. Normalidad de los coeficientes de regresión n Uncertainty α (%) bH1 s bH sbH βexp. 5 homo. 10 5 1 0.1 1.45 1.6 2 3.1 0.118 0.147 0.157 0.187 0.272 10.39 5.87 3.09 0.62 16.44 12.60 9.87 6.37 5 5 5 5 hetero. 10 5 1 0.1 1.27 1.36 1.65 2.3 7.48e-2 8.55e-2 9.02e-2 0.102 0.132 12.67 4.56 1.11 0.22 17.64 10.70 6.42 4.36 5 5 5 5 heter. rnd. 10 5 1 0.1 1.27 1.4 1.67 2.35 7.59e-2 9.07e-2 9.80e-2 0.113 0.153 14.41 3.76 1.19 0.26 19.44 10.24 6.99 4.78 5 5 5 5 homo. 10 5 1 0.1 0.8 0.75 0.68 0.55 6.92e-2 6.26e-2 6.11e-2 5.86e-2 5.58e-2 10.84 5.11 3.75 0.48 11.91 6.21 2.14 0.71 15 15 15 15 hetero. 10 5 1 0.1 0.93 0.91 0.87 0.83 2.49e-2 2.41e-2 2.39e-2 2.34e-2 2.29e-2 14.59 6.98 1.14 0.35 15.2 7.73 1.78 0.72 15 15 15 15 heter. rnd. 10 5 1 0.1 0.965 0.955 0.94 0.915 1.19e-2 1.16e-2 1.153e1.19e-2 1.12e-2 11.77 5.07 1.98 0.15 12.72 5.98 2.74 0.42 15 15 15 15 homo. 10 5 1 0.1 1.12 1.16 1.23 1.32 4.27e-2 4.53e-2 4.62e-2 4.78e-2 4.99e-2 14.92 5.44 0.99 0.10 15.22 6.38 1.32 0.14 30 30 30 30 hetero. 10 5 1 0.1 1.02 1.026 1.036 1.05 7.18e-3 7.25e-3 7.27e-3 7.31e-3 7.36e-3 14.22 5.92 1.29 0.082 14.61 6.59 1.77 0.17 30 30 30 30 heter. rnd. 10 5 1 0.1 1.037 1.047 1.065 1.085 1.26e-2 1.28e-2 1.29e-2 1.30e-2 1.31e-2 10.79 4.82 0.95 0.14 11.62 5.48 1.35 0.31 30 30 30 30 homo. 10 5 1 0.1 0.93 0.951 0.89 0.85 2.41e-2 2.32e-2 2.30e-2 2.28e-2 2.23e-2 10.39 5.81 2.35 0.16 9.94 5.47 2.13 0.14 100 100 100 100 hetero. 10 5 1 0.1 0.995 0.993 0.991 0.988 1.89e-3 1.88e-3 1.88e-3 1.87e-3 1.87e-3 15.92 4.17 1.56 0.16 16.16 4.31 1.68 0.18 100 100 100 100 heter. rnd. 10 5 1 0.1 0.986 0.983 0.979 0.972 4.85e-3 4.82e-3 4.81e-3 4.80e-3 4.79e-3 11.02 6.45 4.39 0.81 11.07 6.48 4.48 0.90 100 100 100 100 15 30 100 0 1 βpred. npred. Table 4. Estimated and experimentally obtained probabilities of β error for individual tests on the slope. Predicted sample size to achieve the probabilities of α and β error for each data set. 90 3.2 Chemom. Intell. Lab. Sys. 49 (1999) 179-193 4.3.Procedure for β error and estimation of sample size in a real data set Table 5 summarises the results of estimating the probabilities of committing a β error in the individual tests for the BLS slope and intercept for a level of significance of 5% (β column, in percent) for data set 3. Columns a H 0 − a and bH 0 − b show the distance between the estimated regression coefficients and the reference values ( a H 0 = 0 and bH 0 = 1 ). The columns t ⋅ saH and 0 t ⋅ sbH (α=5%) show the values of the confidence intervals associated to the 0 reference values. Columns a H1 and bH1 represent the bias that the experimenter wants to check in the regression coefficient being tested. Bias is detected in the regression coefficient whenever the difference a H 0 − a and bH 0 − b is higher than its associated confidence interval. Probabilities of β error are not calculated if bias is detected. BLS WLS OLS BLS WLS OLS a H0 − a t ⋅ saH 2.94 4.38 3.97 a H1 β 5.35 5.19 7.11 6 40.2 37.6 62.5 bH 0 − b t ⋅ sbH 0 bH 1 β 0.0364 0.0571 0.0656 0.0991 0.100 0.110 1.2 2.77 2.60 5.30 0 Table 5. Results obtained in estimating the probability of β error in the individual tests for the intercept and the slope in data set 3. Table 5 shows that neither constant nor proportional bias are found in the SIA methodology in the analysis of Ca(II) in water according to the results from the three regression techniques. The highest probability of β error is estimated at 62.5% for the OLS technique, due to the highest standard deviation value. On the other hand, the probabilities of β error for BLS and WLS are lower and similar to each other although the WLS intercept value is nearer the upper confidence interval limit. This means that the results are less reliable, although this is not reflected in 91 3. Normalidad de los coeficientes de regresión the estimated probabilities of β error. Results for the slope show that the estimated probabilities of β error in the three cases are very similar, despite the differences in the slope values from the three regression methods. However, if we look at the slope values we can be more confident about the accuracy of the one estimated by the BLS method as it is the closest to the reference value bH 0 . iteration 1 2 3 4 5 6 7 8 9 10 11 12 13 nb0 sˆbH 5 9 13 18 22 24 25 26 0.0974 0.131 0.0753 0.0666 0.0609 0.0530 0.0511 0.0492 0 sˆbH 1 0.0992 0.134 0.0769 0.0678 0.0622 0.0542 0.0522 0.0502 nb f na0 sˆ aH <0 <0 18 22 24 25 26 26 5 9 11 13 16 18 20 22 23 24 25 26 27 6.369 3.694 3.511 3.728 3.403 3.391 3.199 3.103 3.103 2.954 2.887 2.838 2.657 0 na f 9 11 13 16 18 20 22 23 24 25 26 27 27 Table 6. Iterations during estimation of the sample size for the slope and the intercept performed in data set 3. The process for estimating the sample size to achieve the calculated probabilities of β error in the slope (2.77%) and intercept (40.2%) for a level of significance of 5% is shown in Table 6. For the intercept, starting with an initial data set of five data pairs ( na0 column), thirteen iterations were needed to end up with twenty-seven data pairs. For the slope, twenty-six data pairs were needed to achieve convergence and there was no estimate of the data pairs until 13 had been considered ( nb0 column) since, according to the denominator of Eq. (13), high experimental errors may produce negative estimates of sample size for the slope (denoted by <0 in Table 6). 92 3.2 Chemom. Intell. Lab. Sys. 49 (1999) 179-193 5. Conclusions The results of this work show that, in spite of the non-normality of the distributions of the BLS regression coefficients, the errors made in the calculating the confidence intervals for the BLS regression coefficients are lower than the ones made with OLS or WLS techniques for data with uncertainties in both axes. Thus, the probability of β error in the individual tests on the BLS regression coefficients can be estimated under the hypothesis of normality. We have also demonstrated that the expressions for estimating the probability of committing a β error when testing an individual regression coefficient with the BLS regression technique and considering different distributions for the reference ( a H 0 or bH 0 ) and for the biased ( a H1 or bH1 ) regression coefficients, provide correct results. Some sources of error have also been detected and identified to explain the disagreements produced in validating the results. The number of data pairs of the regression line appear to be crucial for better estimating the probability of β error. In addition, results in real data show that in some cases it may be interesting to calculate the probability of β error not with the set α threshold value, but with the maximum level of significance α for which no bias is detected in the regression coefficient. One would be more confident of the regression coefficient value being accurate than when it falls near one of the boundaries of the confidence interval (in this way the probabilities of α error would be higher but the probabilities of β error would be lower than in the usual way). Finally, we found that it is advisable to estimate the sample size, since it allows the experimenter to control the probabilities of committing α and β errors that they consider reasonable for the analytical problem in question. The iterative process for estimating the sample size guaranteed the chosen probabilities of making α and β errors when an individual test is applied to one of the estimated BLS coefficients and produced correct results for those data sets with moderate heteroscedasticity, but not for those with high heteroscedasticity. The experimenter also has to weigh up the pros and cons of performing the discontinuous series of experiments that this iterative procedure requires. 93 3. Normalidad de los coeficientes de regresión Acknowledgments We would like to thank the DGICyT (project no. BP96-1008) for financial support, and the Rovira i Virgili University for providing a doctoral fellowship to A. Martínez and F. J. del Río. References [1] W.A. Fuller, Measurement Error Models, John Wiley & Sons, New York, 1987. [2] R.L. Anderson, Practical Statistics for Analytical Chemists, Van Nostrand Reinhold, New York, 1987. [3] M.A. Creasy, Confidence limits for the gradient in linear in the linear functional relationship, J. Roy. Stat. Soc. B 18 (1956) 65-69. [4] J. Mandel, Fitting straight lines when both variables are subject to error, J. Qual. Tech. 16 (1984) 16 1-14. [5] C. Hartmann, J. Smeyers-Verbeke, W. Penninckx, D.L. Massart, Detection of bias in method comparison by regression analysis, Anal. Chim. Acta 338 (1997) 19-40. [6] J.M. Lisý, A. Cholvadová, J. Kutej, Multiple straight-line least-squares analysis with uncertainties in all variables, Comput. Chem. 14 (1990) 189-192. [7] J. Riu, F.X. Rius, Univariate regression models with errors in both axes, J. Chemom. 9 (1995) 343-362. [8] J. Riu, F.X. Rius, Assessing the accuracy of analyticas methods using linear regression with errors in both axes, Anal. Chem. 68 (1996) 1851-1857. [9] A.H. Kalantar, R.I. Gelb, J.S. Alper, Biases in summary statistics of slopes and intercepts in linear regression with errors in both variables, Talanta 42 (1995) 597-603. [10] Cetama, Statistique appliquée à l’exploitation des mesures, 2nd ed., Masson, Paris, 1986. [11] G. Kateman and L. Buydens, Quality Control in Analytical Chemistry, 2nd ed., John Wiley & Sons, New York, 1993. 94 3.2 Chemom. Intell. Lab. Sys. 49 (1999) 179-193 [12] M. Meloun, J. Militký and M. Forina, Chemometrics for Analytical Chemistry. Volume 1: PC-aided statistical data analysis, Ellis Horwood ltd., Chichester, 1992. [13] M.R. Spiegel, Theory and Problems of Statistics; McGraw-Hill, New York, 1988. [14] O. Güell, J.A. Holcombe, Analytical applications of Monte Carlo techniques, Anal Chem. 62 (1990) 529A - 542A. [15] J.J. Langenfeld, S.B. Hawthorne, D.J. Miller, J. Pawliszyn, Role of modifiers for analytical-scale supercritical fluid extraction of environmental samples, Anal. Chem. 66 (1994) 909-916. [16] I. Saouter, B. Blattmann, Analyses of organic and inorganic mercury by atomic fluorescence spectrometry using a semiautomatic analytical system, Anal. Chem. 66 (1994) 2031-2037. [17] I. Ruisánchez, A. Rius, M.S. Larrechi, M.P. Callao, F.X. Rius, Automatic simultaneous determination of Ca and Mg in natural waters with no interference separation, Chemom. Intell. Lab. Syst. 24 (1994) 55-63. [18] R. Boqué, F.X. Rius, D.L. Massart, Straight line calibration: something more than slopes, intercepts and correlation coefficients, J. Chem. Educ. (Comput. Ser.) 71 (1994) 230-232. [19] B.D. Ripley, M. Thompson, Regression techniques for the detection of analytical bias, Analyst 112 (1987) 337-383. [20] P.J. Ogren, J.R. Norton, Applying a simple linear least-squares algorithm to data with uncertainties in both variables, J. Chem. Educ. 69 (1992) 130-131. [21] V. López-Ávila, R. Young, F.W. Beckert, Microwave-assisted extraction of organic compounds from standard reference soils and sediments, Anal. Chem. 66 (1994) 1097-1106. [22] D. L. Massart, B.M.G. Vandeginste, L.M.C. Buydens, S. de Jong, P.J. Lewi, J. Smeyers-Verbeke, Handbook of Chemometrics and Qualimetrics: Part A, Elsevier, Amsterdam, 1997. [23] G.J. Hahn, W. Q. Meeker. Statistical Intervals, a guide for practitioners, John Wiley & Sons, New York, 1991. 95 3. Normalidad de los coeficientes de regresión 3.3 Conclusiones Tras el estudio de los coeficientes de regresión de la recta que considera los errores en las variables predictora y respuesta, se concluyó en primer lugar que dichas distribuciones difieren de la distribución normal. Tras comparar las distribuciones con otras distribuciones teóricas se pudo comprobar que tampoco se asemejan a ellas, reforzándose la hipótesis de que la diferencia entre las distribuciones reales y la normal es pequeña. Es por este motivo, que se intentó cuantificar el error cometido al utilizar dichas distribuciones bajo la hipótesis de normalidad. El error obtenido es pequeño y en cualquier caso menor que el cometido utilizando otros métodos de regresión estudiados (OLS y WLS). Por lo tanto el test individual sobre los coeficientes de regresión de la recta BLS puede llevarse a cabo bajo la hipótesis de normalidad en los coeficientes de regresión. Una vez comprobado que las distribuciones de los coeficientes de regresión pueden asimilarse a una distribución Gaussiana, pueden utilizarse los diferentes tests sobre la ordenada en el origen y la pendiente que requieren de esta condición. A parte de los tests individuales que se explican en este capítulo, también se utiliza el test conjunto de la ordenada en el origen y la pendiente,1,4 que permite discernir si los resultados obtenidos mediante dos métodos analíticos no difieren estadísticamente entre sí a lo largo de un intervalo de concentraciones. Para ello se debe comprobar que la ordenada en el origen no difiera estadísticamente de cero y que simultáneamente la pendiente no difiera significativamente de la unidad. En el capítulo 6 de esta Tesis Doctoral, se presenta una aplicación de los intervalos de confianza conjuntos. Estos intervalos se utilizan para desarrollar un criterio gráfico para la detección de puntos discrepantes cuando se tienen en cuenta los errores cometidos en las dos variables. 3.4 Referencias 1.- J. Riu, F.X. Rius, Analytical Chemistry, 68 (1996), 1851-1857. 2.- A.H. Kalantar, R.I. Gelb, J. S. Alper, Talanta, 42 (1995), 597-603. 96 3.4 Referencias 3.- D.L. Massart, B.G.M. Vandeginste, S.N. Deming, Y. Michotte, L. Kaufman, Chemometrics: a textbook, Elsevier, Amsterdam (1988). 4.- J. Riu, F.X. Rius, Trends in Analytical Chemistry, 9 (1995) 343-363. 97 4 Capítulo Predicción en BLS 4.1 Introducción 4.1 Introducción Una vez desarrollados los tests individuales sobre la recta BLS, una aplicación importante que se puede llevar a cabo sobre la recta de regresión es la predicción. La etapa de predicción en calibración lineal, donde normalmente la concentración de una muestra desconocida se calcula a partir del valor de la respuesta instrumental de un análisis de dicha muestra, es una aplicación ampliamente conocida y desarrollada en el campo de la química analítica. Sin embargo, la predicción tiene otras aplicaciones en el campo de la regresión lineal. Por ejemplo, en el ámbito de la comparación de métodos,1 donde en determinadas ocasiones es útil conocer la concentración y el intervalo de predicción que tendría una determinada muestra al ser analizada por un método analítico de referencia, conociendo el valor de su concentración al ser analizada por un método analítico de nueva implantación (generalmente más preciso y sencillo de utilizar). Tanto en los procesos de comparación de métodos analíticos como en los de calibración lineal en que el error asociado a la variable predictora no sea despreciable frente al asociado a la variable respuesta, deberá aplicarse la regresión lineal considerando los errores cometidos en ambas variables. Un ejemplo en el que debería aplicarse la regresión lineal considerando los errores en ambas variables lo constituye la fluorescencia por rayos X en la cual, debido a la complejidad de las muestras reales (normalmente muestras geológicas), la recta de regresión se encuentra utilizando como patrones de calibración materiales de referencia certificados (CRM), cada uno de ellos con incertidumbres asociadas a su valor de concentración.2 Otro ejemplo lo suponen las técnicas espectroscópicas, donde la disminución del error de la variable respuesta hace que se deban considerar los errores en la variable predictora.3 La utilización de los intervalos de predicción considerando únicamente los errores experimentales cometidos en la variable respuesta tiene asociados una serie de problemas. A parte de los problemas derivados directamente de no considerar los errores experimentales asociados a la variable respuesta, tales como el sesgo introducido en los coeficientes de la recta de regresión, se puede destacar 101 4. Predicción en BLS el hecho de que los intervalos de predicción (y por consiguiente los resultados derivados de su utilización) varían dependiendo de cuál de las variables es considerada como predictora y cual como respuesta. En muchas ocasiones esta asignación se hace de forma rutinaria, como en los procesos de calibración, donde la concentración se asocia a la variable predictora y la respuesta instrumental a la variable respuesta, o en comparaciones de metodologías de análisis, donde se suele asociar como variable predictora al método considerado como de referencia y a la variable respuesta un método de nueva implantación. Sin embargo, esta clasificación no está clara en otros casos, como por ejemplo en la comparación de los resultados obtenidos por dos laboratorios del mismo nivel metrológico o de varios analistas dentro de un mismo laboratorio, y los resultados de utilizar una u otra asignación no deberían variar. Para solucionar todos estos problemas, en esta Tesis Doctoral se han desarrollado las expresiones para el cálculo del error asociado a la predicción cuando se consideran los errores en las dos variables. Para ello se han seguido dos caminos paralelos. El primero de ellos está basado en las expresiones, ampliamente descritas en la bibliografía1,4 para el cálculo de la varianza asociada a la predicción (tanto de la variable respuesta como de la variable predictora) cuando se consideran los errores cometidos únicamente en la variable respuesta mediante una regresión por mínimos cuadrados (es decir utilizando OLS o WLS), y que han sido introducidos en el apartado 2.5.1. Estas ecuaciones se han modificado para adaptarlas a la situación en que se consideran los errores asociados a las variables predictora y respuesta, mediante una ponderación debida a los errores individuales experimentales cometidos en las dos variables. La segunda vía ha sido a partir de la teoría de propagación de los errores5,6 sobre la ecuación de la recta de regresión ( y = b0 + b1 x ). Esta teoría permite calcular la varianza de una función matemática (en nuestro caso la expresión de la recta de regresión), a partir de la serie de Taylor, donde no se tienen en cuenta los términos de orden superior a dos. En este capítulo se presenta el artículo: “Prediction intervals in linear regression taking into account errors on both axes”, aceptado para su publicación en la revista Journal of Chemometrics. En este artículo, se explica el proceso seguido para obtener las expresiones para calcular los errores asociados a la predicción tanto de la variable respuesta como de la variable predictora. En primer 102 4.1 Introducción lugar se obtienen las expresiones del error asociado a la predicción de la variable respuesta mediante cada uno de los dos procedimientos explicados. Tras comparar sus resultados se concluye que dichas expresiones son equivalentes. La validación de las mismas se lleva a cabo a partir de la comparación con los valores de la varianza asociada a la predicción, obtenidos mediante una simulación por medio del método de Monte Carlo,6-9 que son considerados como reales. La utilización de un método de simulación se debe a la imposibilidad de conocer los valores reales de las varianzas asociadas a los valores predichos. Una vez validadas estas expresiones se siguió un proceso similar para desarrollar y validar una expresión para el cálculo de la varianza asociada a la predicción de la variable predictora. Tras obtener las expresiones del error al predecir cada una de las variables se procedió a comprobar la invariabilidad de los resultados al hacer un intercambio entre las variables (es decir al cambiar la asignación de las variables predictora y respuesta). En las siguientes secciones del capítulo se presentan las conclusiones que se extraen del artículo que se presenta a continuación, así como algunas perspectivas que se abren de los resultados obtenidos, para finalmente presentar brevemente la bibliografía referida en este capítulo. 103 4. Predicción en BLS 4.2 Prediction intervals in linear regression taking into account errors on both axes Journal of Chemometrics, aceptado para publicación F. Javier del Río*, Jordi Riu, F.Xavier Rius Department of Analytical and Organic Chemistry. Universitat Rovira i Virgili. Pl. Imperial Tarraco, 1. 43005-Tarragona. Spain. This study reports the expressions for the variances in the prediction of the response and predictor variables calculated with the bivariate least squares regression technique (BLS). This technique takes into account the errors on both axes. Our results are compared to those of a simulation process based on six different real data sets. The mean error in the results from the new expressions is between 4 and 5%. With weighted least squares, ordinary least squares, constant variance ratio approach and orthogonal regression, on the other hand, mean errors can be as high as 85%, 277%, 637% and 1697% respectively. An important property of the prediction intervals calculated with BLS is that the results are not affected when the axes are switched. Keywords: Prediction; linear regression; errors on both axes; confidence intervals; predictor intervals Received 10 March 2000; accepted 30 October 2000 104 4.2 J. Chemometrics, en prensa 1. INTRODUCTION The extraordinary mathematical properties of ordinary least squares, OLS, together with its practical performance characteristics, are the main reasons why this is the most commonly used regression technique among the analytical chemistry community. However, OLS is based on a set of mathematical hypotheses -the homoscedasticity on the y-axis or the absence of errors on the x-axis- that are not always fulfilled. This may lead to biased regression coefficients of the straight line and therefore to erroneous predictions [1,2]. Method comparison studies, where the errors from each method are usually of the same order of magnitude, or calibration lines where the errors on the instrumental responses are similar to those from the concentration values [3-5], are situations in which OLS often provides biased results. An improvement on the OLS technique is the weighted least squares (WLS) technique [1,6], which takes into account heteroscedasticity in the y-axis. However, WLS still considers the x-axis to be error free. Errors-in-variables regression [7], also called the constant variance ratio (CVR) approach [8-10], considers the errors on both axes. It does not take into account the individual errors of each experimental point but considers the ratio of the variances of the response to predictor variables to be constant for every experimental point (λ=sy2/sx2=ct). A particular case of the CVR approach is orthogonal regression (OR) [11], in which the errors are considered to be of the same order of magnitude in the response and predictor variable (i.e. λ=1). In the literature, this case is also called orthogonal distance regression (ODR) [2] or total least squares regression (TLS) [12]. The bivariate least squares (BLS) method [13,14] is a linear regression technique that can overcome the limitations of the previous methods i.e. the fact that the individual errors on both variables are not considered. This technique calculates the straight line regression coefficients by taking into account the 105 4. Predicción en BLS individual heteroscedastic errors on both axes (i.e. sy2 and sx2 for every experimental point). BLS has been applied, for instance, in method validation studies to detect bias in newly developed analytical methodologies [15], and in calibration stages where the errors associated to the predictor variable are of the same order of magnitude as the errors associated to the response variable [3]. This is the situation, for instance, of some AAS or EAS analyses, where the response variable has small errors, which are of the same order of magnitude as those associated to the predictor variable. Calculating predicted values in regression analysis by considering individual heteroscedastic errors on both axes is an important issue in practical instances that has been given little attention to date. Prediction intervals from linear regression taking into account errors on both axes, should be considered, for example, when calculating the results and confidence intervals of a new method from historical values recorded by a previously established methodology, or when evaluating the relationship between two dating methodologies, both of which incorporate errors, in order to determine the chronology of archaeological samples. Another situation in which BLS can be applied is the analysis of chemical elements in rocks using X-ray fluorescence. Because of the complexity of the samples (i.e. geological samples), certified reference materials (CRM) of the analyte of interest are often used to build the calibration line. If this is so, each CRM has errors associated to the concentration values and regression techniques which consider the errors on both axes should be used. This paper develops and validates new expressions for calculating the confidence and prediction intervals for the response variable given a value of the predictor variable, and for the predictor variable given a value of the response variable, using the BLS regression technique, i.e. by considering the individual errors of every experimental point. There are other procedures in the literature for estimating the regression parameters (as well as their underlying uncertainties) in linear regression taking into account heteroscedastic individual errors [7,14], but 106 4.2 J. Chemometrics, en prensa we are not aware of the expressions for calculating the variances for the predictor and response variables when this error structure is met. The expressions for the intervals when considering errors on both axes are derived from a generalisation of the existing OLS and WLS expressions. The same results have also been found with the error propagation theory [16]. To validate the suitability of the new confidence and prediction intervals, we used six real data sets in which random errors based on the individual variances of each real point were added to the data sets using the Monte Carlo method. The values obtained with the new expressions based on BLS agree with the theoretical values better than the results from the expressions based on OLS, WLS, OR or CVR. One of the most important properties of the BLS prediction intervals is that they do not vary when the axes are switched. 2. BACKGROUND AND THEORY 2.1. Bivariate least squares technique From all the least squares approaches for calculating the regression coefficients when there are errors on both axes, Lisý's method [13] (referred to as BLS) is the most suitable [14]. This technique assumes the true linear model to be ηi = β 0 + β1ξi (1) where β0 and β1 are the intercept and slope of the true linear model between the true variables ξi and ηi. These variables cannot be observed. Instead, one can only observe the experimental variables xi = ξi + δ i (2) yi = ηi + γ i (3) 107 4. Predicción en BLS where δi and γi are random errors made when measuring predictor and response variables respectively, and δ i ~ N (0, σ 2xi ) and γ i ~ N (0, σ 2yi ) . In this way, by introducing (2) and (3) into (1) and isolating yi, we obtain the following expression yi = β 0 + β1 xi + ε i (4) where εi is the ith true residual error with ε i ~ N (0, σ 2εi ) [17] and can be expressed as a function of δi, γi and β1: ε i = γ i − β1 δ i (5) Many authors have developed procedures to estimate the regression line coefficients based on a maximum likelihood approach whenever errors on both variables are present [5, 18-20]. In most cases these methods need the true predictor variable to be carefully modelled [18]. This is not usually possible in chemical analysis, where the predictor variables are often constant values (i.e. functional models are assumed). Moreover, there are cases in which the experimental data is heteroscedastic and estimates of measurement errors are only available through replicate measurements (i.e. the ratio σ xi σ yi is not constant or is unknown). These conditions, which are common in chemical data, make it very difficult to apply the principle of maximum likelihood rigorously to the estimation of the regression line coefficients. On the other hand, Sprent [17] presented a method for estimating the regression coefficients using a maximum likelihood approach even when a functional model is assumed. This method is not rigorously applicable when individual heteroscedastic measurement errors are considered. Moreover, when assuming σ yi = λσ xi for any i, least squares methods provide the same estimates for the regression coefficients as a maximum likelihood estimation approach [21]. For these reasons, we have chosen an iterative least squares method that can be used on any group of ordered pairs of observations with no assumptions about the probability distributions [21]. This allows the method to be used on real 108 4.2 J. Chemometrics, en prensa chemical data when individual heteroscedastic errors on both axes are considered. The BLS regression method then relates variables xi and yi as follows [22]: yi = b0 + b1 xi + ei (6) where b0 and b1 are the respective estimates of the intercept and the slope of the true linear model and ei is the ith residual error. The variance of ei is s e2i and will be referred to as the weighting factor (wi). This parameter considers the experimental variances of any individual point on both axes ( s x2i and s 2yi ) obtained from replicate analysis. It should be pointed out that it is very important to correctly estimate the individual errors by means of replicates of the experimental measurements in timedifferent intermediate conditions. If the variances associated with the experimental points are extremely low, the regression line will tend to fit these points perfectly. However, very slight deviations from the regression line may cause lack of fit in the data set, and hence the derived statistical test from the BLS regression coefficients may be invalid. The covariance between the variables for each (xi, yi) data pair, which is normally assumed to be zero, is also taken into account: 2 wi = se2i = s 2yi + b1 s x2i − 2b1 cov( xi yi ) (7) The BLS regression method finds the estimates of the regression line coefficients by minimising the sum of the weighted residuals, S, expressed as S= n ∑ i =1 ( y i − yˆ i ) 2 = ( n − 2) s 2 wi (8) where the estimation of the experimental error, s2, corresponds to S/(n-2). By minimising the sum of the weighted residuals (Equation (8)), two non-linear equations are obtained and by putting in the partial derivatives of the squared residuals the following can be written in matrix form: 109 4. Predicción en BLS Rb = g n n ∑ 1 s e2i ∑ ∑ xi s e2i ∑ i =1 n i =1 i =1 n i =1 2 ∂s e2i y i + 1 ei 2 2 2 b ∂ s s 0 i =1 e b0 ei i × = 2 2 2 xi b1 n xi y i 1 ei ∂s ei 2 + s ei s e2 2 s e2i ∂b1 i =1 i xi s e2i (9) n ∑ (10) ∑ To determine the slope and the intercept, which are the components of vector b in Equations (9) and (10), it is only necessary to carry out an iterative process [13,14] on the following matrix form: b = R −1g (11) With this method the variance-covariance matrix of the calibration straight line coefficients are obtained without having to use additional expressions, only by multiplying the final matrix R-1 by s2 Interestingly, whenever the variances of the predictor variable values are zero and all the variances on the response variable are the same (i.e., all errors are constant and only due to the experimental measurement in the y-axis), the results are identical to those from the OLS method. 2.2. Variance for the response variable In the OLS method, the well known expression for the variance of the predicted observation of a future sample of the response variable y0, obtained as the mean of q observations performed at x0, is given by [2]. 110 4.2 J. Chemometrics, en prensa s 2y0 2 ( x − x) 2 1 1 ⋅s = + + n 0 q n 2 ( xi − x ) i =1 ∑ (12) where x is the mean value of the predictor variable and s2 is the estimate of the true experimental error (σ2): n s2 = ∑( y i − yˆ i ) 2 i =1 n−2 (13) Equation (12) can also be expressed in matrix form: 1 s 2y0 = + X ′0 ⋅ ( X ′ ⋅ X ) −1 ⋅ X 0 ⋅ s 2 q (14) where X0 is a two-element column vector formed by a 1 in the first row and the predictor variable (x0) in the second row, and X is an nx2 matrix in which the first column is a column of ones and the second is formed by the n values of the predictor variable corresponding to the experimental points. For the WLS technique, which takes into account heteroscedastic errors on the response variable, the variance for the predicted observation y0, calculated as the mean of q observations performed at a selected value of x0 is given by [6] 1 s 2y0 = + X ′0 ⋅ ( X ′ ⋅ V −1 ⋅ X ) −1 ⋅ X 0 ⋅ s 2 q (15) where V is an nxn diagonal matrix whose ith element corresponds to the variance of yi ( s 2yi ), and s2, the estimate of the experimental error, now takes into account the variances of the response variable as the weighting factor: 111 4. Predicción en BLS n s2 = ∑ i =1 ( y i − yˆ i ) 2 s 2yi (16) n−2 In the CVR approach, the expression for the variance in the prediction of the response variable from a measured value of the predictor variable calculated as the mean of infinite observations (i.e. q=∞), is [10] s 2y0 1 = b12 s δ2 + + (1 + kb1 ) 2 n ( x0 − x) ⋅ s 2 (17) n n e ( x i − x ) 2 + 2k ( x i − x )( y i − y ) + k 2 ( y i − y ) 2 i =1 i =1 2 ∑ ∑ where k, s δ2 and s e2 are defined in the process of finding the regression coefficients ( s δ2 refers to the error for the predictor variable and s e2 is associated with the estimate of the experimental error). If λ, which appears in the coefficients k and b1 in Equation (17), is chosen to be unity, results for the OR method are obtained. Looking at the OLS and WLS expressions (Equations 14 and 15), we can see that the only difference between them is the V matrix which takes into account the errors on the response variable. Since BLS is also a least squares method and its results are consistent with the OLS and WLS ones when the structure of the errors is met (i.e. when there are no errors on the predictor variable and constant errors on the response variable for OLS or non-constant errors on the response variable for WLS) to find the BLS expressions it would only be necessary to introduce a term taking into account the errors on both axes. By adapting the OLS and WLS expressions, the variance in the prediction of the mean value of response variable given a value of the predictor variable for the BLS regression technique is given by s 2y0 = X ′0 ⋅ ( X ′ ⋅ W −1 ⋅ X ) −1 ⋅ X 0 ⋅ s 2 112 (18) 4.2 J. Chemometrics, en prensa where W is an nxn diagonal matrix whose ith-diagonal element is the weighting factor wi defined in (7). This weighting factor takes into account the errors on both axes. The estimate for the experimental error is now n s2 = ∑ i =1 ( y i − yˆ i ) 2 wi n−2 (19) However, in (18) there is still one term that needs to be considered to obtain the variance associated with predicting a mean value: the error associated to the predictor variable (x0) when its error is also taken into account (i.e. considering the errors on both axes). This term is obviously neglected in the OLS or WLS expressions. To correct the difference in ranges between the two axes, the square of the slope must be introduced, because the slope can be considered as a quotient between the value of the predictor and the response variable. The expression for the variance of the response mean value at a given observation x0 is ( ) s 2y0 = X ′0 ⋅ ( X ′ ⋅ W −1 ⋅ X ) −1 ⋅ X 0 + s x20 ⋅ b12 ⋅ s 2 (20) In the previous equation and the following ones in which the variance of x0 appears (i.e. s x20 ), this value is supposed to be known by replicate measurements in x0. Another way of calculating it, although it is not considered in this paper, may be by modelling the variances in the x-axis [23]. On the other hand, an independent expression for the variance for the predicted mean value of the response variable can be found by applying the error propagation theory [16] to the straight line model. This expression is given in (21). The covariances between the regression coefficients and x0 are assumed to be negligible. 113 4. Predicción en BLS s 2y0 = sb20 + x 02 sb21 + b12 s x20 + 2 x 0 cov(b0 , b1 ) (21) where sb20 and sb21 are the estimates of the variances of the intercept and the slope respectively, and cov(b0 , b1 ) is the covariance between the two regression coefficients. They can be found directly from the variance-covariance matrix using the BLS method (R-1·s2 in Equations (9)-(11)).13,14 Because of the two different ways of obtaining expressions (20) and (21), which calculate the variance in the prediction of the mean value of the response variable, the fact that their results match seems to be an internal validation of the expressions. The variance in the prediction of the response variable of a future sample using the BLS technique must take into account the variances in the regression line (Equations (20) or (21)) and the new observation. Equation (22) gives the final matrix expression for calculating the variance of the response variable y0 as the mean of q observations performed at x0: 1 s 2y0 = + X ′0 ⋅ ( X ′ ⋅ W −1 ⋅ X ) −1 ⋅ X 0 + s x20 ⋅ b12 ⋅ s 2 q (22) 2.3. Variance for the predictor variable Studying of the variance for the predictor variable given a value of the response variable is similar to studying of the prediction of the response variable. Only the new expressions developed for the BLS method are presented here. When errors on both axes are taken into account, and the same procedure as for the prediction of the response variable is used, the resulting expression for the variance of the predictor mean value at a given observation y0 is 114 4.2 J. Chemometrics, en prensa 1 s x20 = Y0′ ⋅ ( Y ′ ⋅ W −1 ⋅ Y ) −1 ⋅ Y0 + s 2y0 ⋅ 2 ⋅ s ′ 2 b1 (23) where Y0 is a two-element column vector with a 1 in the first row and the response variable y0 in the second row, Y is an nx2 matrix whose first column is a column of ones and whose second column is made up of the n values corresponding to the response variables of the experimental points, W is an nxn diagonal matrix whose ith-diagonal element is the weighting factor wi′ , and s ′2 is the experimental error associated with the predictions on the x-axis and corresponds to n s ′2 = ∑ i =1 ( y i − yˆ i ) 2 wi′ n−2 (24) The weighting factor wi′ is now defined as wi′ = s x2i + 1 2 1 s − 2 cov( xi , y i ) 2 yi b1 b1 (25) The variance of the prediction of the predictor variable of a future sample at y0, obtained as a mean of q observations, is found from 1 1 s x20 = + Y0′ ⋅ ( Y ′ ⋅ W −1 ⋅ Y ) −1 ⋅ Y0 + s 2y0 ⋅ 2 ⋅ s ′ 2 b1 q (26) 2.4. Prediction intervals When linear regression with errors on both axes is used, the distributions of both the intercept and the slope can be assumed to be normal [24] without any significant error being made. Furthermore, three methods for testing the normality of a given variable (Kolmogorov test [25], normal probability plots [16] and the Cetama method [26], in order to assure that conclusions are correct) were applied 115 4. Predicción en BLS to a group of simulated values of the response and predictor variables generated by the Monte Carlo simulation method. The results (not shown) indicate that, although the response and predictor variables may be non-normally distributed, in most cases they are normal or very close to normality. The hypothesis that their distribution is normal is therefore acceptable. The expressions of the confidence and prediction intervals for the response and predictor variables are then defined by y 0 ± t α , n − 2 s y0 (27) x 0 ± t α , n − 2 s x0 (28) where tα,n-2 is the t-value for a given level of significance α and n-2 degrees of freedom. The expressions validated in this paper are those for the prediction intervals for the predictor and response variables (where the future sample is obtained as a mean of infinite analyses, i.e. q=∞) [27], since no information is provided in the original data sets about prediction for a future sample or, hence, its associated replicates (i.e. there is no information about q, s x20 nor s 2y0 ). For example, the BLS prediction interval of the response variable for Data set 3 in the Experimental Section is shown in Figure 1, where the future sample is considered to be a consequence of infinite analysis (i.e. q=∞). In the linear regression in which errors on both axes are taken into account, the pattern of the prediction intervals is very irregular. This is due to the dependence between the prediction interval and the variance of the point in which the prediction is made (i.e. the final term in brackets in (22) or (26)). If these terms were constant throughout the regression interval, the prediction interval would be the classic hyperbola of the OLS regression technique. However, since both variables are usual to be heteroscedastic, these variances are not constant and the pattern for the prediction intervals which take into account errors on both axes can only be strictly calculated at points in which the individual experimental error is known. The continuous line for the prediction interval along the regression line is drawn by 116 4.2 J. Chemometrics, en prensa interpolating between contiguous points. Another way to obtain the pattern of the prediction intervals is to model the variances associated to both variables [23], but this solution may not be totally rigorous, since it forces the variances to follow a selected pattern. In this paper we have preferred to take the first option. 35 y 25 15 5 0 10 20 30 x Figure 1 Experimental points for Data set 3, BLS regression line and prediction intervals for the response variable. A significance level of α = 5% was selected. The vertical and horizontal lines at any experimental point are twice the standard deviation on each axis. 3. EXPERIMENTAL 3.1. Data sets and software Six real data sets were used to validate the expressions for calculating the variance for the response variable given a value of the predictor variable and for the predictor variable given a value of the response variable. In the data sets used, mainly in method comparison studies, the established method is normally placed on the x-axis while the new method is placed on the y-axis. Data sets 3 and 6 were introduced to show the usefulness of the new expressions in other fields. These six data sets are plotted in Figure 2. For the sake of clarity, only the BLS, OLS and WLS regression lines have been drawn in Figure 2. In most of the data sets studied 117 4. Predicción en BLS in this section the variances associated to the errors of the experimental points are found using a few replicates (for instance only three). In this paper we have preferred to take into account the individual errors (i.e. using the BLS expressions), although their estimation in some cases is far from optimal, rather than not take into account the individual errors even though they exist (i.e. using the OLS or WLS expressions). Data Set 1: Concentrations of polycyclic aromatic hydrocarbons (PAHs) recovered from railroad bed soil after supercritical fluid extraction (SFE) with CO2 as the modifier on the x-axis, and CO2/10% toluene as the modifier on the y-axis [28]. The standard deviations are obtained from three determinations at each of the 7 experimental points. The data set ranges from 1.4 to 26.9 µg/g of soil. The standard deviations for all experimental points are similar in both methods. Data Set 2: A method comparison study for analyzing Mg2+ in natural waters with atomic absorption spectrometry (AAS) on the x-axis, and sequential injection analysis (SIA) on the y-axis [29]. The errors on AAS are derived from four replicates in the analysis. The errors on the SIA method are calculated from the multivariate regression model developed using the partial least squares (PLS) technique. The comparison consists of 26 data pairs within the range 0.4 and 46.3 mg/l. In all cases, the errors from the SIA method are larger than those from AAS. Data Set 3: The composition of a set of archaeological samples of unknown origin (on the x-axis) is compared to a reference set of known origin (on the y-axis) with neutron activation analysis (NAA). Concentrations of six metal ions (Ce, Co, Cr, Fe, La and Sc) expressed in ppm (except for Fe which is in percent) are determined for a number of pottery jar handles found in Tell enNasbeh [30]. In this way the concentration of the six metal ions is placed in the x and y axes in an attempt to compare the origins of the two sets of samples based on these chemical analysis. 118 4.2 J. Chemometrics, en prensa 25 20 50 140 Undefined origin (ppm; Fe in %) 60 (1) SIA (µg/l) CO2/10% toluene (µg/g) 30 (2) 40 30 15 20 10 10 120 5 10 15 WLS:dotted line OLS:dashed line BLS:solid line 20 25 CO2 (µg/g) -20 -20 0 20 WLS:dotted line OLS:dashed line BLS:solid line 40 60 AAS (µg/l) 150 100 50 80 90 100 130 La Sc Co Fe 0 0 WLS:dotted line OLS:dashed line BLS:solid line 50 100 Reference group (ppm; Fe in %) 150 70 (5) (6) 20 60 15 50 10 40 5 30 0 WLS:dotted line OLS:dashed line BLS:solid line 110 120 Solvent (%) Ce 40 -20 -50 80 25 (4) 60 ∆µV 200 80 20 -10 30 AES (mg/l) Solvent and soil (%) 0 0 Cr 100 0 5 (3) -5 -5 20 0 5 WLS:dotted line OLS:dashed line BLS:solid line 10 15 20 AAS (mg/l) 25 10 40 60 80 WLS:dotted line OLS:dashed line BLS:solid line 100 120 140 ∆kPa 160 Figure 2 BLS (solid line), OLS (dashed line) and WLS (dotted line) regression lines for the six real data sets. The experimental points are shown with their associated errors. Data Set 4: The percentage of recovery for several organochlorine pesticides after microwave-assisted extraction (MAE) with solvent (hexane/acetone 1:1) on the x-axis, and solvent/soil suspensions spiked with the target compounds on the y-axis [31]. The standard deviations are obtained from three determinations at each point. The experiment consists of 20 points with recoveries ranging from 83 to 169%. The variances on both axes are quite large, and there is a possible outlier at high recovery values. Data Set 5: A method comparison study for determining arsenic in natural water using continuous selective reduction and atomic absorption spectrometry (AAS) on the x-axis, and reduction, cold trapping and atomic emission spectrometry (AES) on the y-axis [32]. The study consists of 30 points ranging from 0 to 19.3 µg/l. The errors are proportional to the concentration determined by both methods. 119 4. Predicción en BLS Data Set 6: Data from the measurement of the CO2 Joule-Thompson coefficient [33]. The data correspond to thermocouple measured voltage differences (∆ µV) on the y-axis, as a function of pressure increments (∆ kPa) on the x-axis. There were 11 equally distributed data pairs with estimated x-axis variances of one. The y-axis variances were estimated to range between one and two units. 3.2. Validation process A first step in validating the expressions to calculate the variances associated with the mean value of the response variable when considering errors on both axes (Equations (20) and (21)) is to compare the results from the two expressions. To check the expression obtained for calculating the variance of the predictor variable (Equation (23)), we compared the results from this expression with those from equations for calculating the variance of the response variable (Equations (20) and (21)) after switching the variables on the axes. This comparison can also be used to check the reversibility of the axes with the expressions for calculating the variances for both predictor and response variables. BLS straight line Obtention of y1 BLS straight line Obtention of y2 1 Initial data set Monte Carlo 2 Variance of the response 3 BLS straight line q ·· · Obtention of y3 ·· · BLS straight line ·· · Obtention of yq Figure 3 Scheme of the simulation using the Monte Carlo method followed to obtain the real variance of the response for a value of the predictor variable. Once the results from Equations (20) or (21) and (23), when the axes were switched, have been proved to be coincide, the Monte Carlo simulation 120 4.2 J. Chemometrics, en prensa technique [34] was used to check their validity in real cases. The Monte Carlo method was used to generate a value for the predicted variable from a value of the response variable and vice versa at two different random points for each of the six initial real data sets taking into account the individual variances of each experimental point on both axes. The process was repeated 10,000 times for each one of the two different points in each data set. For each of the 10,000 times, the BLS regression line was calculated and used to predict a value of the response or predictor variable, so we finally had 10,000 'replicates' and hence q=10,000 (Figure 3). The individual uncertainties on both axes were considered to be equal to the uncertainties of the real data pairs. This ensured that possible errors on estimating the variances for the response and predictor variables could only be due to the theoretical expressions and not due to inaccurately estimating the individual uncertainties on both axes. Finally, the variance of these 10,000 values for each real data set was calculated and compared with the predicted variance given by the theoretical expressions. The same simulation process was repeated for the other regression methods. Again the individual errors on both axes were considered (since the errors on both axes exist, although some regression methods ignore them) and the regression lines were calculated for the 10,000 'replicates' with the different regression methods. Again, the variance of these 10,000 values was calculated and compared with the predicted variance given by the theoretical expressions for each regression method. In the CVR approach, λ was chosen to be the ratio between the average of the variances of the response variable and the average of the variances of the predictor variable for each data set. All calculations were performed with customized software with MATLAB (The Mathworks, Inc., Natik, MA, USA). (The MATLAB code is available on request from the authors.) 121 4. Predicción en BLS 4. RESULTS AND DISCUSSION 4.1. Variance for the prediction of the response variable Table I shows the variance of the response variable calculated from the BLS expressions at two randomly selected values for the six data sets described in the Experimental Section. In order to have known variances of the predicted value, only the points of the real data set have been considered as candidates for the predicted value since we had no information nor replicates of points other than the ones used in the calibration line. All the results from (20) and (21) match up to the eighth decimal place. The two expressions must, therefore, be considered the same. This is an important step in the validation process because the fact that the results are identical can be considered an internal validation of the expressions. Table I.- Expressions 20 and 21 for calculating of the variance for the prediction of the response variable and the differences between them. Data Set 122 x0 sy20 sy20 Predicted Equation (20) Equation (21) 1 16.80 6.40655210 6.40655210 1 7.10 1.71674460 1.71674460 2 29.30 8.01060550 8.01060550 2 13.00 5.69862276 5.69862276 3 11.70 0.57148232 0.57148232 3 23.40 0.03850903 0.03850903 4 81.90 7.63379592 7.63379592 4 123.00 7.06714730 7.06714730 5 7.92 4.17691152 4.17691152 5 4.66 1.88624149 1.88624149 6 57.00 0.14971572 0.14971572 6 21.00 0.21554948 0.21554948 4.2 J. Chemometrics, en prensa 4.2. Reversibility of axes. Variance for the predictor and response variables An interesting feature of the BLS regression technique is that it is invariant when the axes are switched. OLS or WLS regression techniques do not have this feature, since only homoscedastic or heteroscedastic errors are taken into account on the y-axis, and two different regression lines with different confidence intervals are obtained according to the variable placed on each axis. The CVR and OR approaches, are also invariant when the axes are switched. To check the reversibility of the axes, the variance corresponding to the prediction of the response variable on the y-axis (e.g. for a new method in a method comparison study or the response variable in a calibration process) was calculated (from (20) or (21)) for a fixed value of the predictor variable on the x-axis (corresponding to an established method or to the concentration variable). The axes were then switched and the variance of the variable on the x-axis (formerly the so-called new method or the response variable) was the same as for the predictor variable (the established sy0 70 (a) Established Method New Method 80 60 40 (b) 60 50 40 30 20 20 0 10 -20 0 10 20 30 40 50 60 Established Method 70 0 -20 0 20 40 sx0 60 80 New Method Figure 4 The process of exchanging the axes in a method comparison analysis is presented in a generic case, where predictor intervals (broken lines) are plotted for an α value of 5% a) Standard deviation for the predicted value of a new method (response variable) at a given value of an established method (predictor variable) b) Predicted values upon switching axes. In this case the standard deviation is for the predicted value of the new method (predictor variable) at a given value of the established method (response variable). 123 4. Predicción en BLS Table II.- Expressions for calculating the variances of the predictor and response variables when their axes are switched and the differences between them. Data Set x0 / y0 sx20 s y20 Predicted Equations (20) and (21) Equation (23) 1 17.80 3.45781347 3.45781347 1 4.60 4.95883603 4.95883603 2 32.10 20.99017650 20.99017650 2 0.30 100.63858697 100.63858697 3 14.00 0.53514345 0.53514345 3 23.80 0.07533935 0.07533935 4 103.00 79.88020685 79.88020685 4 107.00 881.92789365 881.92789365 5 7.01 7.90043654 7.90043654 5 5.66 1.92173104 1.92173104 6 140.00 1.67904956 1.67904956 6 60.00 5.84275834 5.84275834 method on the y-axis or the concentration variable) using (23). This process can be seen in Figure 4. The reversibility of the axes was tested for two random points in each of the six data sets. Table II shows that placing the methods on either of the two axes does not change the results for the variances of the predicted value. Table 2 also shows the agreement between the expressions for calculating the variance of the predictor and response variables when the axes are switched, since the results are identical. These results show that (23) is also internally validated. 4.3. Validation of the results with the Monte Carlo simulation method The expressions for calculating the variance of the true mean of the predicted variables were validated by comparing the calculated variance values with those of the Monte Carlo simulations, which we considered were the correct ones. The values obtained from the simulation process were also compared with 124 4.2 J. Chemometrics, en prensa those from the expressions for OLS, WLS, CVR and OR. The differences may be significant if the techniques are used in situations in which there are heteroscedastic errors on both axes. Table III shows the results for the variance in the prediction of the true mean of the response variable, and Table IV shows the results for the variance in the true mean of the predictor variable. In all the individual cases (except two for the response variable and one for the predictor variable), the agreement between the simulated and calculated variances in the response and predictor variables obtained with BLS is significantly better than the agreement with the other four regression methods. The mean errors for the variances of the response and predictor variables found with BLS, WLS, OLS, CVR and OR are 4-5%, 57-85%, 277-205%, 444-637% and 1697-462%, respectively. The agreement between the simulated and the BLS results is not surprising since the BLS assumptions are always consistent (provided that estimates of the individual errors are good) with the structure of the data sets. If, for instance, the structure of the data sets had been of very small errors on the predictor variable and non-constant errors on the response variable, then the BLS and the WLS expressions would have given results which were very near to the simulated values for these hypothetical data sets. Table III.- Variance values of the new method (response variable), calculated from (20) and (21), with the experimental values from the simulation process on the six real data sets, and the results from OLS, WLS, CVR and OR regression methods. Data Set x0 s y20 s y20 Pred. Simul. BLS Error (%) s y20 Error (%) OLS s y20 Error (%) WLS s y20 Error (%) CVR s y20 Error (%) OR 1 17.80 6.9337 6.4066 7.60 0.8715 87.43 3.1740 54.22 1.9556 71.80 2.4708 64.37 1 4.60 1.7601 1.7167 2.47 0.6510 63.01 0.2547 85.53 1.7330 1.54 2.2459 27.60 2 32.10 8.0788 8.0106 0.84 2.9733 63.20 2.0940 74.08 5.0474 37.52 30.1071 272.67 2 0.30 6.4005 5.6986 10.97 5.5663 13.03 6.2511 2.33 7.6424 19.40 32.9836 415.33 3 14.00 0.5568 0.5715 2.64 0.7833 40.68 0.0366 93.43 1.1714 110.38 2.3364 319.61 3 23.80 0.0387 0.0385 0.52 1.0131 2517.83 0.0143 63.05 1.4007 3519.38 2.5659 6530.23 4 103.00 7.7837 7.6338 1.93 20.3506 161.45 5.0557 35.05 59.8349 668.72 976.4771 12445.15 4 107.00 7.3417 7.0671 3.74 17.0338 132.01 5.8768 19.95 56.3773 667.91 9.5010 29.41 5 7.01 4.4771 4.1769 6.71 0.0610 98.64 0.0289 99.35 0.4397 90.18 0.5412 87.91 5 5.66 2.0327 1.8862 7.21 0.0383 98.12 0.1176 94.21 0.4165 79.51 0.5178 74.53 6 140.00 0.1486 0.1497 0.74 0.1633 9.89 0.0832 44.01 0.2218 49.26 0.2873 93.34 6 60.00 0.2153 0.2186 1.53 0.1193 44.59 0.1622 24.66 0.1778 17.42 0.2433 Mean error (%): 3.91 277.49 57.49 444.42 13.01 1697.76 125 4. Predicción en BLS Table IV.- Variance values of the reference method (predictor variable), calculated from (23), with the experimental values from the simulation process on the six real data sets, and the results from OLS, WLS, CVR and OR regression methods. Data Set y0 sx20 sx20 Pred. Simul. BLS Error (%) sx20 Error (%) OLS sx20 Error (%) WLS sx20 Error (%) CVR sx20 Error (%) OR 1 16.80 3.6885 3.4578 6.25 0.7942 78.47 2.4092 34.68 3.6207 1.84 2.7991 24.11 1 7.10 5.0595 4.9588 1.99 0.6060 88.02 0.6077 87.99 3.3658 33.48 2.6145 48.32 105.20 2 29.30 21.3897 20.9902 1.87 4.2472 80.14 2.3623 88.96 87.7860 310.41 43.8907 2 13.00 103.0027 100.6386 2.30 7.8508 92.38 7.1846 93.02 91.7295 10.94 47.1192 54.25 3 11.70 0.5340 0.5351 0.21 0.9533 78.52 0.0289 94.59 4.3668 717.75 3.0540 471.91 3 23.40 0.0740 0.0753 1.76 1.1956 1515.68 0.0148 80.00 4.6337 6161.76 3.2965 4354.73 4 81.90 91.1230 77.2692 15.20 11.0476 87.88 5.2274 94.26 69.8071 23.39 4.5703 94.98 4 123.00 994.3954 870.0950 12.50 6.7616 99.32 23.7078 97.62 69.0507 93.06 3.2380 99.67 5 7.92 8.4438 7.9004 6.44 0.1242 98.53 0.4586 94.57 1.0325 87.77 0.9325 88.96 5 4.66 2.0086 1.9217 4.33 0.0510 97.46 0.1108 94.48 1.0018 50.12 0.8615 57.11 6 57.00 1.7145 1.6790 2.07 0.7621 55.55 0.3849 77.55 3.6430 112.48 3.3568 95.79 6 21.00 5.8198 5.8428 0.40 0.5833 89.98 0.7755 86.67 3.4417 40.86 3.1780 45.39 Mean error (%): 4.61 205.16 85.37 636.99 461.70 The lowest errors using the BLS expressions are obtained with Data sets 3 and 6. These seem to have the best goodness of fit for the experimental points to the regression line, which seems to confirm that the closeness of the experimental points to the regression line is an important factor for predicting the correct variances. On the other hand, the errors are highest for Data sets 2 and 4 (maximum around 15% for the predictor variable). The variance for the response variable in Data set 2 using the BLS expressions is overestimated by up to 11% whereas the error with the WLS expression was unusually low (2.3%). With Data set 4 we can examine the behaviour of the BLS technique to be examined in the presence of data sets with a low correlation between the variables, and with two possible outliers with very different variances at the limits of the regression range. Since the BLS technique weights the influence of points with high errors negatively, the point at the far end of the range affects the regression coefficients relatively. This feature is partially present in WLS but absent in the other methods because they do not take into account the individual errors. Therefore, the resulting regression coefficients and associated variances of the five techniques are quite different, and again, the variances corresponding to the variables predicted with 126 4.2 J. Chemometrics, en prensa BLS are closer to the simulated results than those calculated with the other methods. Data sets 1 and 5 give errors ranging from 1% to 7% for the response and predictor variables. 5. CONCLUSIONS We have developed and validated the new expressions for calculating the variance of the predicted values in the x and y axes taking into account heteroscedastic individual errors on both axes. This structure of errors (heteroscedastic individual errors on both axes) is common in some fields of chemical analysis, e.g. method comparison studies and some calibration procedures, so it is important to have expressions for calculating the variance in the predictor and response variables that take it into account. The validation has been made by comparing the results of the two expressions (Equations (20) and (21)) in the prediction of the response variable, and comparing the variance from (23) with those from (20) and (21) after switching the axes in the prediction of the predictor variable. Another more complete validation is made by comparing the results of these equations with an estimate of the real variance from the Monte Carlo simulation method applied to six real data sets. The comparison with the variance from the Monte Carlo simulation method applied to six real data sets confirms that these expressions are valid in real cases when errors on both axes are taken into account. These expressions are of a general nature and can be used to predict values and any kind of associated error, such as measurements from two different methods, analytical techniques, observers or laboratories. BLS-based calculations can be done rapidly with an iterative process. The main limitation of this technique is that the errors on both axes of each experimental point in the regression analysis need to be known. However, this will 127 4. Predicción en BLS probably not be unusual in the future, since the international standards recommend stating the errors for every measurement result [35]. One has to be aware of the importance of having correct estimates of the variances associated with the experimental points (which estimates are usually obtained by replicate analysis, preferably in time-different intermediate conditions, not in repeatability conditions, which tend to give rise to low variance estimators), since unusually low variances (for instance, from a low number of replicates) make the regression line fit these experimental points perfectly. Although in some of the real data sets used the number of replicates was very low (only three), this study has assumed that a comparison approach that accounts for approximate estimates of the individual heteroscedastic uncertainties is better than one that does not consider them at all when they really exist. Nevertheless, it is important to note that, when only the errors on one variable are considered, BLS gives results which are identical to those from OLS or WLS regression techniques. CVR and OR appear to produce acceptable results when the data structure meet their requirements, but as the individual errors are not taken into account, their results may be far different from the real ones. It should be pointed out that the high mean errors shown by CVR and OR methods in Tables 3a and 3b are mainly due to their application to Data set 3. If this data set had not been taken into account, the results from CVR and OR methods would have been more similar to those from the WLS and OLS expressions. A feature of the BLS method is that it provides results that are invariant when the axes are switched. This property is of practical importance since, in method comparison studies for instance which axis is used to represent the method to be compared should not be significant as long as all the errors on both axes are considered. Further studies based on these results are in progress. The development of estimators for detection and quantification limits may be of particular interest. 128 4.2 J. Chemometrics, en prensa ACKNOWLEDGMENTS The authors thank the Spanish Ministry of Education and Science (DGICyT project no. BP96-1008) for their financial support. REFERENCES 1.- N. Draper and H. Smith, Applied regression analysis, John Wiley, New York (1981). 2.- D. L. Massart, B. G. M. Vandeginste, L. M. C. Buydens, S. de Jong, P. J. Lewis and J. Smeyers-Verbeke, Handbook of Chemometrics and Qualimetrics: Part A, Elsevier, Amsterdam (1997). 3.- R. L. Watters, R. J. Carroll and C. H. Spiegelman, Error modeling and confidence interval estimation for inductively coupled plasma calibration curves. Anal. Chem. 59, 1639-1643 (1987). 4.- R. M Clark, Calibration, cross-validation and carbon-14. J. R. Statist. Soc. A, 142, 47-62 (1979). 5.- R. M Clark, Calibration, cross-validation and carbon-14. J. R. Statist. Soc. A, 143, 177-194 (1980). 6.- J. O. Rawlings, Applied Regression Analysis, Wadsworth & Brooks/Cole, Belmont (CA) (1988) 7.- W. A. Fuller, Measurement Error Models, John Wiley & Sons, New York (1987). 8.- R. L. Anderson, Practical Statistics for Analytical Chemists, Van Nostrand Reinhold, New York (1987). 9.- M. A. Creasy, Confidence limits for the gradient in linear in the linear functional relationship. J. Roy. Stat. Soc. B, 18, 65-69 (1956). 10.- J. Mandel, Fitting straight line when both variables are subject to error. J. Qual. Tech. 16, 1-14 (1984). 129 4. Predicción en BLS 11.- C. Hartmann, J. Smeyers-Verbeke, W. Penninckx and D. L. Massart, Detection of bias in method comparison by regression analysis. Anal. Chim. Acta, 338, 19-40 (1997). 12.- S. Van Huffel and J. Vandewalle, The Total Least Squares Problems. Computational Aspects and Analysis, Siam, Philadelphia (1991). 13.- J. M Lisý, A. Cholvadová and J. Kutej, Multiple straight-line least-squares analysis with uncertainties in all variables. Computers Chem. 14, 189-192 (1990). 14.- J. Riu and F. X. Rius, Univariate regression models with errors in both axes. J. Chemom. 9, 343-362 (1995). 15.- J. Riu and F. X. Rius, Assessing the accuracy of analytical methods using linear regression with errors in both axes. Anal. Chem. 68, 1851-1857 (1996). 16.- M. Meloun, J. Militký and M. Forina, Chemometrics for Analytical Chemistry. Volume 1: PC-aided statistical data analysis, Ellis Horwood, Chichester (1992). 17.- P. Sprent, Models in Regression and related topics, Methuen & Co. Ltd., London (1969). 18.- D. W. Schafer and K. G. Puddy, Likelihood analysis for errors-in-variables regression with replicate measurement. Biometrika, 83, 813-824 (1996). 19.- K. C. Lai and T. K. Mak, Maximum likelihood estimation of a linear structural relationship with replication. J. R. Statist. Soc. B, 41, 263-268 (1979). 20.- C. L. Cheng and J. W. Van Ness, On estimating linear relationships when both variables are subject to error. J. R. Statist. Soc. B, 56, 167-183 (1994). 21.- D. V. Lindley, Regression lines and the linear functional relationship. J. R. Statist. Soc./ London Suppl. Series B, 9, 218-244 (1947). 22.- G. A. F. Seber, Linear regression analysis, John Wiley & Sons, New York (1977). 23.- M. E. Zorn, R. D. Gibbons and W. C Sonzogni, Weighted least-squares approach to calculating limits of detection and quantification by modeling 130 4.2 J. Chemometrics, en prensa variability as a function of concentration. Anal. Chem. 69, 3069-3075 (1997). 24.- A. Martínez, F. J. del Río, J. Riu and F. X. Rius, Detecting proportional and constant bias in method comparison studies by using linear regression with errors in both axes. Chemolab, 49, 181-193 (1999). 25.- G. Kateman and F. W. Pijpers, Quality Control in Analytical Chemistry, John Wiley & Sons, New York (1981). 26.- Commission d’Établissement des Méthodes d’Analyses du Commissariat à l’Énergie Atomique (Cetama) Statistique Appliquée a l’exploitation des Mesures, Masson, Paris (1986). 27.- G. J. Hahn and W. Q. Meeker, Statistical intervals. A guide for practitioners, John Wiley & Sons, New York (1991). 28.- J. J. Langenfeld, S. B. Hawthorne, D. J. Miller and J. Pawliszyn, Role of modifiers for analytical-scale supercritical fluid extraction of environmental samples. Anal. Chem. 66, 909-916 (1994). 29.- I. Ruisánchez, A. Rius, M. S. Larrechi, M. P. Callao and F. X. Rius, Automatic simultaneous determination of Ca and Mg in natural waters with no interference separation. Chemom. Intell. Lab. Syst. 24, 55-63 (1994). 30.- J. Yellin, Neutron activation analysis: impact on the archaeology of the Holy Land. Trends Anal. Chem. 14, 37-44 (1995). 31.- V. López-Ávila, R. Young and W. F. Beckert, Microwave-assisted extraction of organic compounds from standard reference soils and sediments. Anal. Chem. 66, 1097-1106 (1994). 32.- B. D. Ripley and M. Thompson, Regression techniques for the detection of analytical bias. Analyst, 112, 377-383 (1987). 33.- P. J. Ogren and J. R. Norton, Applying a simple linear least-squares algorithm to data with uncertainties in both variables. J. Chem. Edu. 69, A130-A131 (1992). 34.- P. C. Meier, R. E. Zünd, Statistical Methods in Analytical Chemistry, John Wiley & Sons, New York (1993). 131 4. Predicción en BLS 35.- P. De Bièvre, R. Kaarls, H. S. Preiser, S. D. Rasberry and W. P. Reed, Measurement Results without Statements of Reliability (Uncertainty) should not to be taken Seriously. Accred. Qual. Assur. 2, 269 (Editorial) (1997). 132 4.3 Conclusiones 4.3 Conclusiones En el artículo de la sección anterior se ha presentado el desarrollo de las expresiones para el cálculo de las varianzas asociadas a la predicción de la variable predictora a partir de un valor conocido de la variable respuesta y viceversa, cuando se consideran los errores asociados a ambas variables. Estas expresiones se han utilizado sobre una serie de conjuntos de datos reales sobre los que se han encontrado los intervalos de predicción, con el fin de probar su aplicabilidad en el campo de la química analítica. Analizando las expresiones que se han desarrollado para el cálculo de la varianza asociada a la predicción, tanto de la variable respuesta como de la variable predictora, cuando se tienen en cuenta los errores en ambas variables, se observa que su principal inconveniente es que dichas varianzas únicamente pueden calcularse para aquellos puntos cuyo error experimental sea perfectamente conocido. Aunque esta suposición limita el uso de dichas expresiones, hay diversas soluciones al problema que se plantea. Una de ellas consiste en el modelado de las varianzas a lo largo de todo el intervalo de la variable predictora y de la variable respuesta (concentraciones y respuestas en una calibración o resultados de analizar utilizando un método de nueva implantación y un método de referencia en una comparación de métodos) a partir de los resultados experimentales. De esta forma, el valor de la varianza experimental se conoce para todo el intervalo de cada una de las dos variables, y por tanto puede calcularse la varianza asociada a la predicción de la variable respuesta partiendo de cualquier punto de la variable predictora (o viceversa). Esta solución se aplicará en el siguiente capítulo, donde se utilizan los intervalos de predicción para calcular el límite de detección en regresión lineal considerando los errores en las variables predictora y respuesta. Una solución menos rigurosa al problema descrito es utilizar la experiencia para fijar los valores de las varianzas a cada nivel de concentración. Sin embargo, esta solución suele llevar asociado un importante error pues se añade la incertidumbre del analista a la propia de los análisis, si bien sigue sin aportar información en aquellos lugares de los que no se tiene suficiente información. 133 4. Predicción en BLS En el presente capítulo también se ha tratado la representación de los intervalos de predicción en el campo de la comparación de métodos analíticos. Sin embargo, su principal aplicación es la correspondiente a los procesos de calibración, donde la concentración de los patrones se representa frente a su respuesta instrumental. A lo largo de esta Tesis Doctoral se han presentado una serie de conjuntos de datos en los que deben considerarse los errores cometidos en las dos variables, siendo un buen número de ellos calibraciones llevadas a cabo en el ámbito de la química analítica. Una aplicación de los intervalos de predicción, tal como se ha introducido con anterioridad, es el cálculo del límite de detección de una metodología, donde dicho límite se extrae a partir de los intervalos de predicción fijados a los niveles de confianza α y β. En el próximo capítulo se explicará el proceso seguido para encontrar las expresiones para su cálculo, si bien su aplicación se plasmará, básicamente, sobre procesos de calibración (es decir, se representan concentraciones frente a respuestas instrumentales). 4.4 Referencias 1.- D.L. Massart, B.G.M. Vandeginste, L.M.C. Buydens, S. de Jong, P.J. Lewi, J. Smeyers-Verbeke, Handbook of Chemometrics and Qualimetrics: Part A, Elsevier, Amsterdam (1997). 2.- H. Bennett, G. Olivier, XRF Analysis of Ceramics, Minerals and Allied Materials, John Wiley & Sons, New York (1992). 3.- C.H. Spiegelman, R.L.Watters, L. Hungwu, Chemometrics and Intelligent Laboratory Systems, 11 (1991) 121. 4.- N. Draper, H. Smith, Applied Regression Analysis, 2ªed., John Wiley & Sons, New York (1996). 5.- M. Meloun, J. Militký, M. Forina, Chemometrics for Analytical Chemistry, Ellis Horwood limited, Chichester (1992). 6.- I.E. Frank, R. Todeschini, The Data Analysis Handbook, Elsevier, Amsterdam (1994). 7.- P.C. Meier, R.E. Zünd, Statistical Methods in Analytical Chemistry, John Wiley & Sons, New York (1993). 134 4.4 Referencias 8.- O. Güell, J.A. Holcombe, Analytical Chemistry, John Wiley & Sons, New York (1993). 9.- H.A. Meyer (editor), Symposium on Monte Carlo Methods, Willey, Chichester, New York, 1956. 135 5 Capítulo Límite de detección en BLS 5.1 Introducción 5.1 Introducción Los resultados de los análisis químicos han adquirido una gran importancia debido a las demandas de la sociedad actual. Recientemente, en toda la Europa occidental ha surgido una grave problemática acerca del riesgo derivado del consumo de carne procedente del ganado vacuno que padezca la encefalopatía espongiforme bovina (EEB) (conocida popularmente como “mal de las vacas locas”). En estadísticas oficiales realizadas en España, y concretamente en el barómetro de noviembre de 2000 (estudio 2402) del Centro de Investigaciones Sociológicas (CIS), esta enfermedad se sitúa como una de las veinte mayores preocupaciones de la sociedad, a pesar de que en esas fechas era un problema incipiente y no excesivamente conocido por el conjunto de la población. En las citadas estadísticas, se demuestra que el problema afecta tanto a los individuos como a la sociedad en general, y que su repercusión se puede ver tanto desde el punto de vista económico como de política internacional. Por este motivo, los resultados de los análisis llevados a cabo sobre los animales sospechosos de poseer la enfermedad son portada diariamente en los periódicos de toda Europa. Existen algunos estudios económicos con un carácter más general que revelan que la generación de información analítica comporta hasta un 5% del producto interior bruto mundial. Conocer si un alimento está adulterado, la presencia de un contaminante en el aire, o incluso conocer el contenido de colesterol en la sangre son otros ejemplos en que se consideran importantes los resultados de los análisis químicos, en los que frecuentemente se necesita poder detectar un analito a concentraciones extremadamente bajas. Los químicos son conscientes desde hace muchos años de la importancia de establecer límites de detección a las metodologías analíticas.1 Sin embargo, el desarrollo de técnicas de análisis más sensibles y la reciente promulgación de leyes que regulan la exposición de los seres humanos a niveles bajos de elementos químicos que pueden ser dañinos, han servido para acentuar la necesidad de calcular dichos límites. En el apartado 2.6 de la presente Tesis Doctoral, se presentan una serie de técnicas desarrolladas para calcular el límite de detección a lo largo de los años. Cada una de ellas introduce sutiles cambios en la terminología 139 5. Límites de detección en BLS y en los conceptos, o diferencias en el cuidado y la atención que merecen las asunciones necesarias para calcular el límite de detección. Durante mucho tiempo muchos analistas no han tenido conciencia de estas sutiles diferencias, pero estas se han hecho patentes cuando se han realizado intercomparaciones entre laboratorios a niveles de trazas.2 Un ejemplo ocurrió en un proceso de intercomparación llevado a cabo por la Agencia Internacional de Energía Atómica,3 donde se analizó el contenido de As en un riñón de caballo (medido en niveles de µg/g). Varios laboratorios obtuvieron resultados no cuantificables (por debajo del límite de detección), a pesar de que los límites de detección que presentaron eran claramente menores que resultados cuantitativos presentados por otros laboratorios. Como consecuencia, el rango de los resultados presentados por todos los laboratorios se extendía hasta cerca de cinco órdenes de magnitud. Una aplicación con amplia repercusión social del límite de detección es la comprobación de si determinado contaminante está o no presente en unas aguas de consumo, o en un alimento determinado, o incluso conocer en qué concentraciones se encuentra. Otra aplicación es el estudio de elementos traza en la atmósfera. Además de las aplicaciones que se verán en este trabajo, el límite de detección tiene aplicabilidad en múltiples situaciones en otros campos de la ciencia. Sin embargo, en otros campos de la ciencia también se utiliza el límite de detección en multitud de situaciones. En algunos métodos analíticos en los que se necesita calcular el límite de detección deben considerarse los errores experimentales cometidos en las variables predictora y respuesta. Este es el caso de algunos procesos de calibración lineal donde la respuesta instrumental es tan estable que sus errores experimentales son comparables a los errores que llevan asociadas las concentraciones (tal como ocurre con los análisis radioquímicos),4,5 o aquellos casos en que, debido a la complejidad de las muestras, se deben utilizar materiales de referencia certificados en la variable predictora (tal como ocurre con el análisis de muestras geológicas utilizando fluorescencia de rayos X).6 En todos estos casos debe utilizarse el límite de detección calculado utilizando un método de regresión que considere los errores en las variables predictora y respuesta. 140 5.1 Introducción En este capítulo se presentan las expresiones desarrolladas para el cálculo de los límites de detección cuando se tienen en cuenta los errores experimentales cometidos en las variables predictora y respuesta. Para explicar el proceso, en la sección 5.2 se incluye el artículo: “Limits of detection in linear regression with errors in the concentration”, enviado para su publicación en la revista Analytical Chemistry, donde se desarrolla el cálculo de los límites de detección en los casos en que deben considerarse los errores en la concentración además de los asociados a las respuestas instrumentales. Dichos límites de detección se aplican sobre dos conjuntos de datos reales en que los límites de detección basados en los métodos de OLS y WLS son claramente sesgados por el hecho de no considerar los errores en las dos variables. Para el cálculo de los límites de detección se han utilizado las expresiones para el cálculo de los intervalos de predicción desarrollados en el capítulo anterior. Sin embargo, el cálculo del límite de detección involucra un proceso iterativo, de manera que deben conocerse los intervalos de predicción para diferentes valores de la concentración en los que la experimentación no se ha llevado a cabo. Para solucionar este problema, se ha propuesto modelar las varianzas experimentales asociadas a cada una de las variables. De esta forma se obtiene una aproximación al valor de dichas varianzas a lo ancho de todo el intervalo de concentraciones y puede calcularse el límite de detección. Este modelado se ha introducido de una manera similar a como se hace al calcular el límite de detección utilizando la recta de WLS, donde únicamente se consideran los errores heteroscedásticos en la variable respuesta.7 En las siguientes secciones de este capítulo se presentan las conclusiones que se extraen del artículo presentado, así como las referencias que se han citado a lo largo del capítulo. 141 5. Límites de detección en BLS 5.2 Limits of detection in linear regression with errors in the concentration Analytical Chemistry. Enviado para publicación F. Javier del Río*, Jordi Riu, R. Boqué, F.Xavier Rius Department of Analytical and Organic Chemistry. Universitat Rovira i Virgili. Pl. Imperial Tarraco, 1. 43005-Tarragona. Spain. This paper discusses a method for calculating the limit of detection using linear regression. This method takes into account the heteroscedastic individual errors in both axes, i.e. it uses the bivariate least squares (BLS) regression method. The expressions were applied to X-ray fluorescence (XRF) and capillary electrophoresis (CE) determinations to calculate the limits of detection of nine elements in solid rocks and three anions in water, respectively. The geological samples are habitually complex, so the calibration is usually performed using certified reference materials of the analyte of interest, all of which have uncertainties associated to the concentration values. When determining anions using capillary electrophoresis, errors in both axes are justified because of the small errors in measurement. The limits of detection with these expressions have been compared with those obtained with Ordinary Least Squares (OLS) and Weighted Least Squares (WLS). The results show that the limits of detection when the BLS procedure is used are smaller than when the other techniques are used. 142 5.2 Anal. Chem., enviado INTRODUCTION Chemists have long been aware of the importance of establishing the limits of detection of analytical methods. The ability of a method to detect the presence or absence of analytes in samples is one of the parameters that need to be verified when checking whether it is 'fit for purpose'.1 However, the development of more sensitive analytical techniques and the promulgation of statutory regulations on human or environmental exposure to low levels of chemical health hazards have increased the need to further examine the procedures used to establish these limits. In most laboratories, limits of detection are currently calculated from the standard deviation of replicate analyses using blank samples. There are, however, other good techniques for calculating the limits based on repetitions of analyses at different levels of concentration, and normally using linear regression.2 One of the most common techniques using different levels of concentration is based on the ordinary least squares (OLS)3 regression technique. This is based on a set of mathematical hypotheses, such as the presence of random errors with constant variance (homoscedasticity) on the y axis (normally the instrumental response) or the absence of errors on the x axis (normally the concentration level), that are sometimes not fulfilled in the chemical field.4,5 If these hypotheses are not fulfilled, there may be biased regression coefficients of the OLS straight line and, therefore, erroneous results. An improvement of the use of OLS is the weighted least squares (WLS) regression technique,4,6 which takes into account the presence of random errors with non-constant variance (heteroscedasticity) in the y axis. However, WLS still considers the x axis to be error-free. Procedures based on this latter regression technique7,8 have been developed to obtain a better approximation of the limits of detection when homoscedasticity in the instrumental responses cannot be assured. There are analytical methods using straight lines in the calibration stage whose errors in the instrumental responses are similar or even lower to the errors in the concentration values.9 These are situations in which OLS or WLS often provide biased results for the regression coefficients and therefore for parameters like the 143 5. Límites de detección en BLS limit of detection, because the mathematical hypotheses are not satisfied. In such cases, regression techniques that consider the errors in both axes, i.e. the errors in the instrumental responses and the concentration values, are recommended.10,11 Of the numerous regression techniques that consider the errors in both axes, we have chosen bivariate least squares (BLS) because it easily provides the coefficients of the regression line and their associated variance-covariance matrix, and because of the simplicity of programming its algorithm. The BLS regression technique12,13 can overcome the limitations of the OLS and WLS regression methods, i.e. the fact that the individual errors in both variables are not considered. This technique calculates the straight line regression coefficients by taking into account the heteroscedastic errors in both axes for every experimental point. In this paper we present a new method for calculating the limit of detection when errors in the concentration are present, i.e. using the BLS regression method. It is based on the prediction intervals developed for BLS,14 and adapts the procedures for calculating the limits of detection in OLS3 and WLS8. To demonstrate its applicability, the derived estimator has been used in the determination of nine elements in solid rocks using X-ray fluorescence (XRF). Due to the complexity of the real samples (i.e. geological samples), the calibration is usually performed using CRMs of the analyte of interest.15 The estimator has also been used in the analysis of three anions in waters using capillary electrophoresis (CE). BACKGROUND AND THEORY Notation. In general, the true values of the variables used in this paper are represented by Greek characters, while their estimates are represented by Latin characters. In this way, the true values of the straight line regression coefficients are represented by β0 (intercept) and β1 (slope), while their respective estimates are represented by b0 and b1. The estimates for the standard deviation of the intercept and the slope of the regression line are sb0 and sb1 respectively. The experimental data pairs of a data set are (xi, yi) and their respective errors in each axis are 144 5.2 Anal. Chem., enviado expressed in terms of variance as s x2i for the concentration and s 2yi for the response variable. The experimental error, also expressed in terms of variance for the n experimental data pairs, is σ2, while its estimate is s2. ŷi represents the estimated value for the yi predicted. Some expressions have the subscript 'OLS', 'WLS' or 'BLS' to denote the regression method from which they are calculated. σ 02 and σ 2D are the true errors, in terms of variance, associated with the prediction of the estimated quantity (net response or concentration) at zero concentration (under the null hypothesis, true value = 0) and at the level of the limit of detection, respectively, while s02 and s D2 are their estimates.2 In the calculation of the limit of detection, LC is the critical value of the estimated quantity in terms of net response or concentration, XC is the critical value in terms of concentration, and yC is the value of the response at the level of XC. LD is the limit of detection of the estimated quantity, XD is the limit of detection in terms of concentration and yD is the value of the response at the level of XD. In all cases m is the number of replicates performed on a future sample. Finally, z1-α represents the percentage point or critical value of the standard normal distribution for a significant level α, while t1-α is its equivalent for a one sided t-Student distribution. Bivariate least squares regression. The straight line model found with this regression technique is expressed in eq. 1: yi = b0 + b1 xi + ei (1) where ei is the residual for the i-th point in the data set of the regression line. In this form, the predicted value for the observed yi is: ŷi = b0 + b1 xi (2) The method consists of minimizing the squared sum of the weighted residuals of the experimental points to the regression straight line: S= n ∑ i =1 ei2 = wi n ∑ i =1 ( y i − yˆ i ) 2 = s 2 ⋅ ( n − 2) wi (3) 145 5. Límites de detección en BLS where s2 is the estimation of the experimental error and wi is the weighting factor that corresponds to the variance of the ith-residual: 2 wi = s e2i = s 2yi + b1 s x2i − 2b1 cov( x i , y i ) (4) cov(xi, yi) is the covariance between the predictor and the response variable for every experimental point, which is normally set to zero. Minimizing the sum of the weighted residuals in relation to the slope and the intercept gives eq. 5. Rb = g (5) Eq. 6 is obtained from eq. 5 by including the partial derivatives of the squared residuals: n 1 ∑s i =1 n ∑ i =1 2 ei xi s e2i n ∑ i =1 n ∑ i =1 2 ei ∂s e2i y 1 i + s e2 2 s e2 ∂b0 i 1 = b0 i i = 2 × 2 2 xi b1 n xi y i 1 ei ∂s ei 2 + s ei s e2 2 s e2i ∂b1 i =1 i xi s e2i n ∑ (6) ∑ The slope and the intercept, which are the components of vector b in eq. 5 and eq. 6, can be found by inverting matrix R and solving eq. 7: b = R −1g (7) An iterative process must be carried out to solve eq. 7, due to the weighting factor (including the slope) in every term of matrix R. With this method, and assuming that the straight line model is correct, the variance-covariance matrix of the calibration straight line coefficients is obtained by multiplying the final matrix R-1 by the estimate of experimental error, s2 (eq. 3). 146 5.2 Anal. Chem., enviado Whenever the variances of the concentration values are zero, the WLS solution is obtained. Furthermore, if the errors on the response variable are constant and the concentration is considered free of error, the OLS solution is obtained. Detection limit. The decision about whether an analyte is present in a sample or not is taken by comparing its estimated net response or concentration with the critical value (LC). The critical value is the minimum significant value of an estimated net signal or concentration. The probability of exceeding the critical value is no greater than the selected α level of significance if the analyte is absent.2 If data at zero concentration are normally distributed with known variance, the critical value can be expressed as follows, LC = z1−α σ 0 (8) where σ0 is defined from a sum of variances, one of which is due to the measurement of the sample ( σ 2y ) and the other to the uncertainty of the blank ( σ 2blank ): σ 02 = σ 2y + σ 2blank (9) The detection limit (LD) is the minimum value for which the false negative error is β, given LC (or α).2 These terms are shown in Figure 1. σ0 σD α β 0 LC LD Figure 1.- Graphical representation of the critical level (LC) and the detection limit (LD). The two distributions plotted represent the normal distribution at zero concentration and at the level of the limit of detection. 147 5. Límites de detección en BLS For data with a known variance structure, LD can be expressed as: LD = LC + z1−β σ D = z1−α σ 0 + z1−β σ D (10) Estimating limits of detection in linear regression. Response Ordinary least squares estimator. Figure 2 shows the relationship between the value of the response at the critical value (yC) and the limit of detection in terms of concentration (XD) according to Hubaux and Vos3. y=b0+b1x α yC β y0 XC XD Concentration Figure 2.- The Hubaux and Vos approach for calculating the limit of detection. The blank signal (y0) is obtained as the intercept (b0) of the OLS regression line, and the standard deviation of the blank is subsequently assumed to be sb0 . The value of the response in the critical value is the intersection between the upper prediction interval (for a fixed α) and the y-axis. Following the Hubaux and Vos development, the response at the critical value can be calculated from eq. 11: y C = b0OLS + t1−α s 0 = b0OLS + t (1−α,n −2 ) sOLS 1 1 + + m n x OLS ∑ (x n i =1 148 i 2 − x OLS ) 2 (11) 5.2 Anal. Chem., enviado where sOLS is the estimate of the experimental error and x OLS is the mean value of the concentration, and where the z-values in equation 8 are substituted by t-values. XC = y C − b0OLS (12) b1OLS This value is equivalent to the XC level given by Currie. The detection limit XD is obtained by projecting yC onto the lowest prediction interval of the regression line chosen for a fixed β probability of error, and is equivalent to the LD level defined by Currie. The limit of detection is calculated as follows: X D = t (1− α,n − 2 ) s0OLS + t (1−β,n − 2 ) s DOLS = = t (1− α,n − 2 ) sOLS b1OLS 1 1 + + m n 2 x OLS n ∑ (x i =1 − x OLS ) 2 i + t (1−β,n − 2 ) sOLS b1OLS 1 1 + + m n ( X D − xOLS )2 n ∑ (x (13) − x OLS ) 2 i i =1 s0OLS and s DOLS represent the standard deviation at zero concentration level and at the level of the limit of detection.4,5 Eq. 13 has an exact mathematical solution16 and can also be solved by an iterative process. Weighted least squares estimator. Oppenheimer et al.7 generalized the procedure to find the limit of detection when heterostedasticity in the response variable is allowed. The main difference from the OLS estimator is the inclusion of a weighting factor to take into account the heteroscedasticity in the response. The variances for the response variable can be found by modeling the experimental individual variance values versus the concentration level8 (i.e. the known s 2yi of the experimental points). The limit of detection in WLS regression can then be expressed as: 149 5. Límites de detección en BLS X D = t (1−α,n −2 ) s0WLS + t (1−β,n −2 ) s D WLS = = t (1−α,n −2 ) s WLS s 2y0 b1WLS m + n ∑ i =1 + t (1−β,n −2 ) s WLS s 2yD b1WLS m 2 1 + + 1 s 2yi ∑ ∑ i =1 (x i i =1 − x WLS s 2yi + ) 2 (14) (X − x ) (x − x ) 2 1 n n x WLS 1 s 2yi + WLS D n ∑ i =1 2 i WLS 2 s yi where s 2y0 and s 2yD are the variances in the response variable, associated with zero concentration and with the concentration at the limit of detection, respectively. Eq. 14 is solved by an iterative process, due to the limit of detection in both terms of the equation and the need to recalculate the experimental standard deviation at the level of yD. Due to the weighting factor, which includes the individual errors, the analytical solution is difficult to find. s WLS is the estimate of the experimental error (eq. 15) and x WLS is the mean weighted value of the concentration calculated from eq. 16. n s WLS = ∑ i =1 ( y i − yˆ i ) 2 s 2yi n−2 n x WLS = xi ∑s i =1 n ∑ i =1 (15) 2 yi 1 s 2yi (16) It must be pointed out that if the errors in the instrumental response are homoscedastic (i.e. s 2yi =ct.), the limit of detection is the same with OLS (eq. 13) and WLS (eq. 14). Bivariate least squares estimator. To find the limit of detection by considering heteroscedastic individual errors in both axes, we use the prediction intervals based on the BLS regression method,14 which takes into account the errors 150 5.2 Anal. Chem., enviado in both axes. These expressions are similar to the ones for OLS and WLS but include the uncertainty in the concentration. Using these expressions and the scheme in Figure 2, from eq. 17 we obtain the estimate of the response at the critical value (yC) as follows: y C = b0 + t1− α s0 = b0BLS + t (1−α,n − 2 ) s BLS w0 + m 1 n ∑ i =1 1 wi + x BLS n ∑ i =1 (x i 2 − x BLS wi ) 2 (17) where w0 is the weight associated with the signal at zero concentration and calculated using eq. 4. The variances of both the concentration and the instrumental response are calculated modeling the errors in both axes, as with the WLS expressions (see next section). s BLS is the estimate of the experimental error (eq. 18) and x BLS is the mean weighted value of the concentration calculated from eq. 19. n s BLS = ∑ i =1 ( y i − yˆ i ) 2 wi n−2 n x BLS = xi ∑w i =1 n ∑ i =1 (18) i 1 wi (19) Following the scheme in Figure 2, the critical value can be expressed in terms of concentrations, using eq. 12 with the regression coefficients of the BLS regression line. The limit of detection is obtained from eq. 10, where the real values of the standard deviations are substituted by their estimates and the z-values are replaced by t-values: 151 5. Límites de detección en BLS X D = t (1−α,n −2 ) s0BLS + t (1−β,n −2 ) s D BLS = = t (1−α,n −2 ) s BLS b1BLS w0 + m n ∑ i =1 + t (1−β,n −2 ) s BLS b1BLS 2 1 wD + m 1 wi + 1 n ∑ i =1 1 wi n ∑ (x x BLS i i =1 − x BLS wi + ) 2 (20) (X − x ) (x − x ) 2 + BLS D n ∑ i =1 2 i BLS wi where wD is the weight associated with the signal at the limit of detection, and is calculated from eq. 4. Eq. 20 has no analytical solution because XD appears in both sides of the equation. For this reason, the limit of detection is found using an iterative process. In this process, XD and wD are recalculated in each iteration until XD converges to the criterion set by the analyst (depending on the number of significant digits used to express the limit of detection). Modeling the errors. The errors associated to instrumental responses and concentrations in a calibration process normally increase as the concentration increases. We need to know the errors in the predictor and response variables (or just the errors associated with the response variable for the WLS limit of detection) at the levels of concentration and responses around the limit of detection (i.e. to calculate wD and w0 from eq. 4, we need the standard deviation of both variables at zero concentration level and the limit of detection). However, these are normally unknown. A way to get these values is by modeling the uncertainties in the response and the concentration.8 To model these standard deviations we propose some typical expressions: Lineal model (L): sv = a 0 + a1v Quadratic model (Q): s v = a 0 + a1v + a 2 v 2 Exponential model (E): s v = a 0 e a1v Squared quadratic model (S): sv = a 0 + a1v + a 2 v 2 where v represents both the predictor and response variables. 152 (21) (22) (23) (24) 5.2 Anal. Chem., enviado After trying to fit all the models to the experimental standard deviations of both the concentration and the response, the simplest model that provides positive values and the lowest residual errors to the regression model is chosen. EXPERIMENTAL SECTION To show how useful these expressions are we used them to calculate the limits of detection of nine elements in geological samples analyzed using X-ray fluorescence (XRF), and to the calculate the limits of detection of three anions in water determined using capillary electrophoresis (CE). Instrumentation. XRF was conducted using an X-ray sequential spectrophotometer Philips PW2400 (equipped with the program UniQuant® v2.53), which simultaneously detects each element of the periodic table whose atomic weights is greater or equal to that for Fluor. It is equipped with a filtered Rh-target X-ray guide with an aperture for analysing samples of about 40mm in diameter. The X-ray fluorimeter works at 60kV and 50 mA for all elements except Na2O (40kV and 75 mA) and Nb (60 kV and 30 mA). The capillary electrophoresis was performed using a Waters CIA (Capillary Ion Analyzer) system with a fused silica capillary of 75 µm x 60 cm. The detector was a UV set at 254 nm. The electrolyte was 5 mM cromate / 0.5 mM OFM (Osmotic Flow Modifier). Samples were injected hydrostatically (indirect detection mode) by applying 50 mbar for 10 s. The separation was performed at 20 kV (negative voltage supply) and 25 ºC. Samples. The calibration samples for the XRF determination were geological certified reference materials (CRM), supplied by the IGGE (Institute of Geophysical and Geochemical Prospection, Ministry of Geology, Beijing, China); their references were: GSD-2 to GSD-12 and GSR-1 to GSR-4. Nb, Zr, Y, Sr, Rb, Pb, Na2O, Ga and Ni were analyzed in each of the 15 CRMs to obtain 15 data pairs for every element. The errors in the CRMs were calculated from a worldwide certification interlaboratory trial, and the final results were presented by Xie et al.17,18. The error in the instrumental response was obtained from seven replicate 153 5. Límites de detección en BLS measurements of each CRM in different days performed in the SCT of the University of Barcelona (Barcelona, Spain). Interferences was taken into account and possible matrix effects were corrected with the incoherent radiation (Compton) of the sample. The samples used in the analysis of anions in waters were obtained from dilutions of CRMs; these were 3181, 3182 and 3185 from the National Institute of Standards & Technology (NIST). The uncertainty of these standards was calculated from the error propagation theory, taking into account the dilutions made. The uncertainty of the CRMs is based on the “combined uncertainty” calculated according with the ISO Guide to the Expression of Uncertainty in Measurement19. The anions were chloride, sulfate and nitrate. Forty replicates of each standard were obtained at time-intermediate conditions in the Public Health Laboratories of Valencian Autonomous Government (Albal, Valencia, Spain). Calculations. All calculations were made with customized software using MATLAB ver. 4.2 for Microsoft Windows20. Matlab files are available on request. RESULTS AND DISCUSSION Table 1 shows the results of the straight lines using the BLS regression technique for the XRF determination. The results for the OLS and WLS regression lines (which do not consider the uncertainties in the CRMs) are also given for comparison purposes. The table also shows the models chosen for the errors in the predictor and response variable according to eqs. 21-24 (the model for the errors in the x axis is used to calculate the BLS limits of detection; the model for the errors in the y axis is used in the BLS and WLS limits of detection). In every case, we chose the model that gives positive values and the lowest residual error to the regression model. Table 2 shows the same parameters for analysing anions with CE. 154 5.2 Anal. Chem., enviado Table 1.- Straight line regression coefficients for the nine analytes by XRF obtained with OLS, WLS and BLS regression techniques, and model regression coefficients of the standard deviations for the response and concentrations. See text for the meanings of the letters E, Q and S. OLS WLS BLS b0 b1 b0 b1 b0 b1 Ga 0.0219 0.0026 0.0197 0.0027 0.0163 0.0029 Na2O -0.3243 8.0820 -0.2607 7.9900 -0.1041 8.1178 Nb 0.0998 0.0013 0.0986 0.0013 0.0996 0.0013 Ni 0.0266 0.0020 0.0276 0.0020 0.0283 0.0020 Pb 0.0073 0.0001 0.0072 0.0001 0.0068 0.0001 Rb 0.0013 0.0034 0.0099 0.0033 0.0051 0.0033 Sr 0.1965 0.0043 0.2066 0.0042 0.2253 0.0041 Y -0.1162 0.0050 -0.1161 0.0049 -0.1127 0.0048 Zr 0.2685 0.0050 0.2346 0.0052 0.2096 0.0053 E E E Q E Q Q E Q Standard deviation of x a0 a1 a2 0.5321 0.0601 0.0012 0.0680 4.0448 0.0399 0.0000 0.2809 0.0043 3.3962 0.0634 12.3770 -0.0363 0.0049 379.1300 -3.9932 0.0111 2.9696 0.0561 484.2100 -4.8771 0.0197 Standard deviation of y a0 a1 a2 S 0.0000 9E-12 0.0000 Q 5E-04 -1E-04 6E-06 S 0.0000 3E-11 0.0000 S 2E-15 2E-13 5E-13 E 5E-07 2.3082 S 0.0000 6.00E-10 0.0000 S 0.0000 7.00E-11 0.0000 Q 2E-06 -3E-06 5E-05 S 7E-11 -7E-11 6E-11 Table 2.- Straight line regression coefficients for the three anions by capillary electrophoresis with OLS, WLS and BLS regression techniques, and model regression coefficients of the standard deviations for the response and concentrations. See text for the meanings of the letters E, Q and S. OLS b0 Cl- WLS b1 b0 BLS b1 b0 b1 Standard deviation of x a0 a1 a2 Standard deviation of y a0 a1 a2 212.8475 58.1534 186.3113 56.6524 141.8163 59.1845 Q 0.0138 -0.0004 3E-06 S 0.0000 NO3- 129.4625 30.4011 80.0630 31.1234 68.4495 31.2399 E 0.0270 Q 12.005 0.041 2E-06 SO42- 53.6780 31.1182 32.4993 31.2777 31.8384 31.2883 Q 0.0419 -0.0038 0.0001 S 2279.2 1.4942 0.0015 0.0320 - 2E-05 5E-09 XRF data sets: Table 3 shows the limits of detection of the nine elements (expressed in ppm and calculated with α and β fixed at 5%) for the three regression methods. Table 3.- Detection limits for the nine analytes studied by XRF when α and β errors are 5%. All results are expressed in ppm. α=5/β=5 Ga Na2O Nb Ni Pb Rb Sr Y Zr Range of LOD(OLS) concentrations 5.4 - 27.4 7.8 0.04 - 3.85 0.49 7 - 95 11.5 2.5 - 139 7.5 7.8 - 636 13.5 9.4 - 470 28.5 24.4 - 1107 31.5 9.4 - 67 3.1 70.4 - 490 56.8 LOD(WLS) 6.1 0.48 11.4 8.1 11.4 11.6 16.7 4.6 41.6 LOD(BLS) 5.2 0.24 4.8 2.6 4.7 11.8 24.5 2.0 31.8 The limits of detection of the three methods are different mainly because of the difference in the regression coefficients and experimental variances in predictor and response variables. As the limit of detection is based on the expressions of the prediction intervals, when the slope and intercept of BLS are 155 5. Límites de detección en BLS similar to those of OLS and WLS, the smallest limits of detection are those whose prediction intervals are smaller at levels of concentration near the limit of detection. The classical prediction intervals in OLS increase at small levels of concentration because they correspond to a branch of the hyperbola; this means that the limit of detection is also higher than in BLS. WLS normally provides lower detection limits than OLS because when the individual errors are modeled near the detection limit, the lower branch of the confidence interval (i.e. the branch of the hyperbola near the limit of detection) is lower than in OLS. In calibration the experimental errors in both variables are usually smaller when the level of concentration decreases. So, when errors in both axes are taken into account (i.e. with BLS), the prediction intervals around zero concentration are also usually smaller than at higher levels of concentration.14 Consequently, the limits of detection with BLS are expected to be smaller than with WLS and much smaller than with OLS. 6 5 XRF Response 4 3 2 1 0 WLS: OLS: BLS: 0 500 1000 Concentration (ppm) 1500 Figure 3.- Data pairs and their respective standard deviations (the half of the vertical and horizontal lines that crosses the data pairs) and the OLS, WLS and BLS straight lines for Sr. As we can see in Table 3, the detection limits calculated when errors in both axes are considered, are lower than when only the errors in the y axis. This is to be expected. Only with Sr (Figure 3) is the limit of detection with BLS higher 156 5.2 Anal. Chem., enviado than with WLS. Even so, this difference is considered small, due to the range of concentrations of the samples: the concentration ranges from 24.4 to 1107 ppm and the limit of detection ranges only from 16.7 ppm (WLS) to 24.5 ppm (BLS). These results can be explained because the straight lines obtained with OLS, WLS and BLS are quite different, and because the variances fit poorly to the model at low levels of concentration, which can cause the prediction intervals at the levels of concentration near the limit of detection in the BLS straight line to increase. This makes the limit of detection with BLS higher than with the WLS straight line. 35 30 XRF Response 25 20 15 10 5 0 WLS: OLS: BLS: 0 1 2 3 Concentration (ppm) 4 5 Figure 4.- Data pairs and their respective standard deviations (the half of the vertical and horizontal lines that crosses the data pairs) and the OLS, WLS and BLS straight lines for Na2O. The analysis of Na2O (see Figure 4) is an example of when the three straight lines are very similar and their limits of detection vary according to the regression method. If the straight lines from OLS, WLS and BLS are not similar, the limits of detection will not necessarily follow the order: LOD(BLS) < LOD(WLS) < LOD(OLS) because they are greatly affected by the position of the straight line. With Ga (Figure 5), the OLS limit of detection is smaller than with WLS because 157 5. Límites de detección en BLS the straight lines are different. In any case, for this example the limit of detection is smaller with BLS than with OLS or WLS. 0.1 XRF Response 0.08 0.06 0.04 0.02 WLS: OLS: BLS: 0 5 10 15 20 Concentration (ppm) 25 30 Figure 5.- Data pairs and their respective standard deviations (the half of the vertical and horizontal lines that crosses the data pairs) and the OLS, WLS and BLS straight lines for Ga. Due to the characteristics of the XRF data sets (uncertainties in the concentration are clearly higher than in the response), an inverse regression (i.e. concentrations in the y axis and responses in the x axis) using WLS would provide similar limits of detection to those with BLS. The comparison was therefore made with BLS and WLS inverse regressions, and the limits of detection were considered to be comparable. These results appear to prove that the new method is suitable. Figure 6 shows the characteristic curve of detection21 for a fixed α significance level of 5% for Pb. The limits of detection using the curves from the expressions that consider the errors in both axes are usually different than those from expressions that considering only the errors in the y axis, although the shape of the curves is the same for all the interval. As we have previously stated, the experience confirms that the values obtained with the BLS technique are usually smaller than those obtained with the OLS and WLS techniques. Figure 6 shows 158 5.2 Anal. Chem., enviado that, as expected, the values corresponding to the three curves tend to be most similar when β is increased 100 β-error 80 60 OLS 40 BLS WLS 20 0 0 5 10 15 Limit of detection (ppm) 20 25 Figure 6.- Characteristic curves of detection for α fixed at 5% using the estimates based on BLS, WLS and OLS regression methods for analyzing Pb. Figure 7 shows the BLS characteristic curves of detection for Pb when a sample is analyzed m times. We can see that the higher the number of repetitions, the smaller the detection limit. Figure 7 also shows that the main decrease in the limit of detection is achieved when most replicates are performed when m is low (for example, from m=1 to m=2), but this effect is not significant when m is high. 100 β-error 80 60 m=1,2,3 40 m=∞ 20 0 0 2 4 6 8 10 Limit of detection (ppm) Figure 7.- Characteristic curves of detection for α fixed at 5% and for different number of replicates (m=1,2,3 and m=∞) when analyzing Pb. 159 5. Límites de detección en BLS CE data sets: Table 4 shows the limits of detection for the three anions analyzed using CE. The limits of detection are expressed in ppm and are calculated with α and β fixed at 5%. The limits of detection with BLS are always smaller than with WLS, and are much smaller than with OLS, as we concluded for the data sets analyzed using XRF. Table 4.- Detection limits for the three anions analysed by CE when α and β errors are 5%. All results are expressed in ppm. α=5/β=5 - Cl NO3SO4 2- Range of LOD(OLS) concentrations 10 - 150 11.5 10 - 150 24.3 10 - 400 6.7 LOD(WLS) 4.6 10.3 4.3 LOD(BLS) 4.4 8.2 2.6 This data set is a genuine application in which the limit of detection should be calculated from the BLS expressions, because the structure of the data set does not allow us to perform inverse regression like the data sets from XRF did. In this case the errors in the two axes may be considered to be of the same order of magnitude, although the errors in the response are higher than those in the concentration. From eq. 20 with α and β fixed, the limit of detection can be decreased by minimizing the prediction intervals near the zero concentration level and around the level of the limit of detection, which are directly affected by the errors in the two variables. These intervals can be decreased by obtaining better approaches of the concentration and instrumental response values (and their associated errors) around the limit of detection. This usually implies more replicates in the laboratory (a minimum of ten replicates is recommended) to obtain good models for the experimental errors in both axes. CONCLUSIONS We have developed expressions for calculating the limit of detection in linear regression when the experimental errors in the concentration are taken into account. To show their applicability, the limits of detection have been calculated for a method of analysing nine elements in rocks using XRF and one for analysing 160 5.2 Anal. Chem., enviado three anions in water using capillary electrophoresis. We have compared the limits of detection of the XRF method (due to the structure of the data sets) with those from inverse regression and WLS. Results were identical. The determination of three anions using capillary electrophoresis is given as an example of the applicability of the new expressions when the errors in both variables are of the same order of magnitude. The limits of detection with the BLS method are usually smaller than with the methods developed for the OLS and WLS regression techniques. The process for calculating the limit of detection does not increase calculation time. The only thing that complicates the process is the need to model the errors in both variables. However, an iterative calculation is also needed when the WLS expressions are used, and in this case the calculation time is not significantly smaller than with the BLS expressions. One potential drawback is the fact that replicates in the instrumental responses and concentration are needed. However, when CRMs are used to obtain the calibration curves, the errors in the concentrations of these materials are generally published and known. This method also needs good estimates of the variances in the different levels of concentration of the CRMs (or in the concentration generally), and in the different levels of the variances in the response variable. This is because the variances in both axes are modeled according to generic models. Good estimates of these variances (so more replicates in the instrumental response) are needed for the model to have a good fit. ACKNOWLEDGEMENTS The authors would like to thank Montserrat Baucells of the SCT of the University of Barcelona and the Public Health Laboratories of Valencian Autonomous Government for providing the XRF and CE data, respectively. The Spanish Ministry of Education and Science (DGICyT project no. BP96-1008) is also acknowledged for its financial support. 161 5. Límites de detección en BLS REFERENCES 1.- Sargent M. Anal. Proc., 1995, 32, 201-2. 2.- Currie, L.A. (IUPAC Recomendations 1995) Pure & Appl. Chem., 1995, 67, 1699-723. 3.- Hubaux, A.; Vos, G. Anal. Chem., 1970, 42, 849-55. 4.- Draper, N.; Smith, H. Applied Regression Analysis, 2nd ed.; John Wiley & Sons: New York, 1981; pp 8-70, 108-17. 5.- Massart, D.L.; Vandeginste, B.G.M.; Buydens, L.M.C.; de Jong, S.; Lewis, P.J.; Smeyers-Verbeke, J. Handbook of Chemometrics and Qualimetrics: Part A; Elsevier: Amsterdam, 1997; pp 75-8, 422-35. 6.- Rawlings, J.O. Applied Regression Analysis; Wadsworth & Brooks/Cole: Belmont, 1988; pp 315-8. 7.- Oppenheimer, L.; Capizzi, T. P.; Weppelman, R.M.; Mehta, H. Anal. Chem., 1983, 55, 638-43. 8.- Zorn, M. E.; Gibbons, R.D.; Sonzogni, W. C. Anal. Chem., 1997, 69, 3069-75. 9.- Watters, R.L.; Carroll, R.J.; Spiegelman, C.H. Anal. Chem., 1987, 59, 1639-43. 10.- Clark, R.M. J. R. Statist. Soc. A, 1979, 142, 47-62. 11.- Clark, R.M. J. R. Statist. Soc. A, 1980, 143, 177-94. 12.- Lisý, J.M.; Cholvadová, A.; Kutej, J. Computers Chem., 1990, 14, 189-92. 13.- Riu, J.; Rius, F.X. J. Chemom., 1995, 9, 343-62. 14.- del Río, F.J.; Riu, J.; Rius, F.X. J. Chemom., In press. 15.- Bennett, H.; Oliver, G. XRF Analysis of Ceramics, Minerals and Allied Materials; John Willey & Sons: Chichester, 1992. 16.- Garner, F.C.; Robertson, G.L. Chemom. Intell. Lab. Syst., 1998, 3, 53-9. 17.- Xie, X.; Yan, M.; Li, L.; Shen, H. Geostandards Newsletter, 1985, 9, 83-159. 18.-Xie, X.; Yan, M.; Wang, Ch.; Li, L.; Shen, H. Geostandards Newsletter, 1989, 13, 83-179. 19.- BIPM, IEC, IFCC, ISO, IUPAC, IUPAP, OIML Guide to the expression of uncertainty in measurement. ISO, Geneva, 1993. 20.- Mathworks Inc., Natick, Massachussets, USA. 21.- Liteanu, C.; Rica, I. Statistical Theory and Methodology of Trace Analysis; Ellis Horwood: Chichester, 1980; p 208. 162 5.3 Conclusiones 5.3 Conclusiones Mediante el desarrollo de las expresiones para el cálculo del límite de detección cuando se tienen en cuenta los errores en la concentración, se produce un importante avance en la finalidad de estudiar los parámetros de calidad que se deben estudiar sobre una recta de regresión. De esta forma, se permite avanzar en la validación de metodologías en las que esté involucrado el método de regresión BLS. En este capítulo se ha perfeccionado la aplicabilidad de las expresiones desarrolladas para el cálculo de los intervalos de predicción presentadas en el capítulo anterior, pues se ha introducido la posibilidad de modelar las varianzas de las variables predictora y respuesta. De esta forma, se obtienen unos intervalos de predicción continuos a lo largo de todo el intervalo de concentraciones, en vez de unos intervalos discretos tal como se concluye en el capítulo 4 de esta Tesis Doctoral. Esta ampliación y perfeccionamiento permitirá el uso de los intervalos de predicción, no solo para predecir el valor de una muestra desconocida y su error asociado, sino también para otros procesos que requieren de los intervalos de predicción, como es el presentado en este capítulo, que es el cálculo de los límites de detección. Una vez obtenido el límite de detección, una perspectiva que queda abierta en el estudio de los parámetros cualimétricos de la regresión BLS es el tratamiento de puntos discrepantes, ya que su presencia conduce a resultados erróneos al utilizar la recta BLS, así como tests asociados a la misma. De esta forma, en el próximo capítulo, se tratará la regresión lineal considerando los errores en las variables predictora y respuesta cuando el conjunto de datos inicial presenta puntos discrepantes o sospechosos de serlo. 163 5. Límites de detección en BLS 5.4 Referencias 1.- C.A. Clayton, J.W. Hines, P.D. Elkins, Analytical Chemistry¸59 (1987) 25062514. 2.- L.A. Currie, Analytica Chimica Acta, 391 (1999) 127-134. 3.- L.A. Currie, Ed., Detection in Analytical Chemistry: Importance, Theory, and Practice, cap.9, ACS Sympos. Serie 361, American Chemical Society, Washington (1988). 4.- R.M. Clark, Journal of the Royal Statististical Society, Series A, 142 (1979) 4762. 5.- R.M. Clark, Journal of the Royal Statististical Society, Series A, 143 (1980), 177-194. 6.- H. Bennett, G. Olivier, XRF Analysis of Ceramics, Minerals and Allied Materials, John Wiley & Sons, New York (1992). 7.- M.E. Zorn, R.D. Gibbons, W.C. Sonzogni, Analytical Chemistry 69 (1997) 3069-3075. 164 6 Capítulo Regresión lineal en presencia de puntos discrepantes 6.1 Introducción 6.1 Introducción La regresión lineal es una herramienta estadística ampliamente utilizada en muchos campos de la ciencia. Sin embargo, existe una permanente preocupación por el peligro de llevar a cabo la regresión lineal en presencia de puntos discrepantes. Estos puntos discrepantes pueden ser consecuencia de errores en la medida, en la transcripción de los resultados, errores debido a fenómenos excepcionales, o errores debidos a considerar de la distribución alguna muestra extraviada perteneciente a una distribución diferente. En los análisis reales es muy frecuente la presencia de puntos discrepantes, que pueden fácilmente pasar inadvertidos debido a que los datos se tratan generalmente por ordenadores evitando la inspección visual de los mismos.1 En el contexto de la presente Tesis Doctoral, por el hecho de tener puntos discrepantes en el conjunto de datos, se puede llegar a cometer errores en la aplicación de los tests individuales sobre la ordenada en el origen o la pendiente, en la predicción o en el cálculo del límite de detección. A pesar de que BLS tiene cierto grado de robustez ante puntos discrepantes, debido principalmente a la propia naturaleza del algoritmo de dar más peso a aquellos puntos que tienen menores errores experimentales, hay una serie de puntos discrepantes que BLS es incapaz de detectar y, por tanto, de ignorar. Por este motivo, es importante tratar el tema de la regresión lineal, considerando los errores experimentales individuales cometidos en las variables predictora y respuesta, cuando puntos discrepantes (o sospechosos de serlo) están presentes en el conjunto de datos inicial. Este capítulo se ha dividido en tres partes. La primera de ellas trata del desarrollo de una nueva técnica para la detección de puntos discrepantes en regresión lineal (sección 6.2). En la sección 6.3 se presentará un método de regresión robusta basado en la regresión lineal considerando los errores experimentales cometidos en ambas variables. Por último, la sección 6.4 presenta un trabajo de síntesis en el que se pretende plasmar las diferentes pautas de uso de cada una de las técnicas desarrolladas en este capítulo, con el fin de encontrar la 167 6. Regresión lineal en presencia de puntos discrepantes recta de regresión correcta cuando se consideran los errores cometidos en las dos variables y el conjunto de datos incluye algún punto sospechoso de ser considerado como discrepante. Una vez se encuentra la recta de regresión correcta se tiene más seguridad acerca de la idoneidad de utilizar la recta BLS para realizar tests individuales sobre sus coeficientes de regresión, para realizar predicciones de muestras futuras o para calcular el límite de detección, que son los objetivos propuestos en esta Tesis Doctoral. Siguiendo el esquema de los capítulos previos, las secciones 6.5 y 6.6 incluyen las conclusiones que se extraen de este capítulo y las referencias citadas a lo largo del mismo, respectivamente. 168 6.2 Detección de puntos discrepantes 6.2 Detección de puntos discrepantes 6.2.1 Introducción Una solución ante la problemática debida a la presencia de puntos discrepantes es la utilización de alguna técnica estadística para la detección de los mismos. En el caso de considerar los errores heteroscedásticos individuales cometidos en las variables predictora y respuesta, no existe ningún test estadístico para discernir si un punto sospechoso de ser discrepante se debe considerar como tal o no. Por este motivo se pensó en la posibilidad de generalizar el conocido test de Cook1-5 al caso en que se tienen en cuenta los errores heteroscedásticos individuales cometidos en las variables predictora y respuesta. Con el fin de desarrollar una técnica para la detección de puntos discrepantes en el campo de la regresión lineal considerando los errores en las variables predictora y respuesta, una primera aproximación fue la generalización del test de Cook. El test de Cook está basado en la comparación de los coeficientes de las rectas de regresión obtenidas a partir de un conjunto de datos inicial y el mismo conjunto de datos eliminando los puntos sospechosos de ser considerados como discrepantes, tal como se ve en el apartado 2.7.1 de la presente Tesis Doctoral. Con el fin de generalizar este método al caso en que se tienen en cuenta los errores experimentales cometidos en las dos variables, se introdujo un término de ponderación en la expresión de la distancia al cuadrado de Cook. De esta forma, la expresión de la distancia de Cook, donde se elimina la i-ésima observación, se expresa de la siguiente forma: DiBLS = (b BLS − b iBLS )' ⋅ (X ′ ⋅ W ⋅ X ) ⋅ (b BLS − b iBLS ) 2 ps BLS (6.1) 169 6. Regresión lineal en presencia de puntos discrepantes donde p es el número de parámetros que deben estimarse (en el caso general de la regresión lineal p=2), bBLS es la matriz que incluye los coeficientes de regresión de la recta BLS y biBLS es la matriz que incluye los coeficientes de regresión una vez se ha eliminado el i-ésimo punto. DiBLS se compara con el valor F(p,n-p,1-α) para un valor definido de α; un valor mayor de DiBLS denota que la i-ésima observación se debe considerar como un punto discrepante. En el caso de tener más de un punto sospechoso de ser discrepante, la anterior expresión se generaliza únicamente eliminando el conjunto de observaciones (I) sospechosas en lugar de eliminar una única observación (i). Sin embargo, un estudio en profundidad de la interpretación gráfica de este test generalizado permitió concluir que la comparación que se lleva a cabo se da entre un intervalo de confianza conjunto de la ordenada en el origen y de la pendiente y unos valores (considerados exactos) de los coeficientes de regresión una vez los puntos sospechosos de ser discrepantes son eliminados. Con el fin de superar esta limitación se desarrolló el criterio gráfico que se presenta en el apartado 6.2.2 de esta Tesis Doctoral. En él se presenta el artículo: “ A graphical criterion for the detection of outliers in linear regression taking into account errors in both axes”, que ha sido aceptado para su publicación en la revista Analitica Chimica Acta, donde se presenta un nuevo método de detección de puntos discrepantes cuando se tienen en cuenta los errores en las dos variables. El criterio presentado en el artículo sigue la filosofía propuesta por Cook de comparar los coeficientes de las rectas de regresión obtenidas con y sin los puntos sospechosos de ser discrepantes. Se trata de un criterio gráfico en el que la decisión de considerar algún punto como discrepante o no está basada en la comparación de las elipses de confianza conjuntas de la ordenada en el origen y la pendiente de la recta BLS,6 obtenidas a partir del conjunto de datos inicial y del conjunto de datos una vez eliminados los puntos sospechosos de ser puntos discrepantes. Unas elipses de confianza de tamaño comparable (es decir, con varianzas de los coeficientes de regresión comparables) y con el centro (sus respectivas ordenadas en el origen y pendientes) en lugares cercanos, darían a entender que las dos rectas son comparables y por tanto los puntos eliminados no deben considerarse discrepantes. Sin embargo, en el caso contrario, en que las dos elipses tienen tamaños diferentes o sus centros están alejados, las dos rectas en comparación deberían considerarse 170 6.2 Detección de puntos discrepantes como diferentes y, por lo tanto, la recta de regresión se ve claramente afectada por los puntos inicialmente considerados como sospechosos. En este caso dichos puntos deben considerarse discrepantes. En el apartado 6.2.3 se pretende demostrar la aplicabilidad del criterio gráfico. Para ello se ha partido de un conjunto de datos real extraído de la bibliografía en el que no hay ningún punto discrepante y se han variado los valores experimentales (variables predictora y respuesta, así como sus respectivas varianzas experimentales) en uno de los puntos, con el fin de observar las conclusiones que se extraen mediante el criterio gráfico para la detección de puntos discrepantes desarrollado en el artículo del apartado 6.2.2. 171 6. Regresión lineal en presencia de puntos discrepantes 6.2.2 Outlier detection in linear regression taking into account errors in both axes Analytica Chimica Acta. Aceptado para publicación F. Javier del Río*, Jordi Riu, F.Xavier Rius Department of Analytical and Organic Chemistry. Universitat Rovira i Virgili. Pl. Imperial Tarraco, 1. 43005-Tarragona. Spain. Over the past few years linear regression taking into account the errors in both axes has become increasingly important in chemical analysis. It can be applied for instance in method comparison studies at several levels of concentration (where each of the two methods normally present errors of the same order of magnitude) or at calibration straight lines using reference materials as calibration standards, such as in X-ray fluorescence for analysing geological samples. However, the results obtained by using a regression line may be biased due to one or more outlying points in the experimental data set. These situations can be overcome by robust regression methods or techniques for detecting outliers. This paper presents a graphical criterion for detecting outliers using the bivariate least squares (BLS) regression method, which takes into account the heteroscedastic individual errors in both axes. This graphical criterion is based on a modification of Cook's well-known test for detecting outliers. This new technique has been checked using two simulated data sets where an outlier is added, and one real data set corresponding to a method comparison analysis. Keywords: Outliers; linear regression; errors in both axes; Cook’s test; confidence intervals 172 6.2.2 Analytica Chimica Acta, en prensa INTRODUCTION Linear calibration is widely used in analytical chemistry. It is used, for example, in relating the instrumental response with the analyte of interest and in method comparison studies at several levels of concentration [1]. The most widely used method for finding the coefficients of the straight line is ordinary least squares (OLS), but this considers that the predictor variable (x axis) is error-free and allows constant random errors only in the response variable (y axis). If the random errors in the predictor variable are not constant throughout the regression interval, weighted least squares (WLS) may be used, but this still considers the predictor variable to be error-free. Not taking into account the errors in the predictor variable may in some cases lead to biased results in the coefficients of the straight line. For instance, the instrumental responses may be so stable that the errors in the predictor variable cannot be neglected [2] or when the results of two methods at different concentration levels are compared using linear regression; both methods have associated errors and neglecting the errors in one of them (i.e. using the OLS or WLS regression methods) leads to biased results of the regression line. There are also a number of analytical techniques, e.g. X-ray fluorescence, in which, due to the complexity of the real samples, the calibration line is often built with certified reference materials (CRM), each of which has known errors associated to the predictor variable [3,4]. Here, one should use regression methods that take into account the errors in both axes. The bivariate least square (BLS) method [5,6] calculates the coefficients of the straight line by taking into account the individual heteroscedastic errors in both axes. BLS has been used in method validation studies, for instance, to detect bias in newly developed analytical methods. [1] Once the straight line has been found by any of the regression methods, the results may be biased due to one or more outlying points in the experimental data set. These points may result in poor estimates of the regression coefficients or a high experimental error of the data set (which also increases the variances of the regression coefficients [7]). Outliers can also cause significant bias in a new method in a method comparison study to remain undetected, i.e. they can increase the probability of committing a β error. These situations can be overcome by using techniques for detecting outliers or robust regression methods. In the literature, 173 6. Regresión lineal en presencia de puntos discrepantes there are several techniques for outlier detection (e.g. Cook’s test [8]) or robust regression techniques (e.g., the least median of squares, LMS [9,10]) that deal with regression considering errors only in the response variable, and other methods of robust regression in which the errors in both axes are considered under some restrictions [11,12]. However, there are no tests for detecting outliers and there are no robust regression methods that consider the individual heteroscedastic errors in both axes. In this paper we present a graphical criterion for detecting outliers using the BLS regression method. It is based on the same theoretical basis as Cook’s test, which compares two regression lines: one using the overall data set and the other using the data set without the suspected point. The main difference between the graphical criterion in this paper and Cook’s test is that the former compares the straight lines, not only by considering the regression coefficients, but also by considering their variances. We have used this graphical criterion on two simulated data sets in order to prove its suitability in the presence of outliers, and to two real data set to prove its suitability in chemical situations. BACKGROUND AND THEORY Bivariate least squares. Of the several regression techniques that consider errors in both axes [6], we chose bivariate least squares (BLS) because it can readily provide the regression coefficients as well as their associated variances and covariances, and because programming its algorithm is very simple. This technique assumes that true linear model is: ηi = β 0 + β1ξi (1) where β0 and β1 are the true intercept and slope of the regression line that relates the true predictor (ξi) and response (ηi) variables. The true variables are unobservable and instead, one can only observe the experimental variables: xi = ξ i + δ i 174 (2) 6.2.2 Analytica Chimica Acta, en prensa yi = ηi + γ i (3) Variables δi and γi are random errors committed when measuring the predictor and response variables respectively; where δ i ~ N (0, σ 2xi ) and γ i ~ N (0, σ 2yi ) . If we introduce eqs. 2 and 3 into eq. 1, the relationship between xi and yi is: y i = β 0 + β1 x i + ε i (4) where εi is the ith true residual error [13]. It can be expressed as a function of δi, γi and β1: ε i = γ i − β1 δ i (5) The BLS regression method relates the observed variables xi and yi as follows [14]: yi = b0 + b1 xi + ei (6) where ei is the observed ith residual error. The BLS regression method finds the estimates of the regression line coefficients by minimising the sum of the weighted residuals, S, expressed in eq. 7: S= n ∑ i =1 ( y i − yˆ i ) 2 = wi n ∑ i =1 ( y i − b0 − b1 xi ) 2 = ( n − 2) s 2 wi (7) where n is the number of experimental data pairs, ŷi is the prediction of the experimental variable yi, and wi is the weighting factor that corresponds to the variance of the ith-residual (ei): wi = s e2i = s 2yi + b12 s x2i − 2b1 cov( xi y i ) (8) where s x2i and s 2yi are, respectively, the experimental variances of the ith point for the predictor and response variables of the straight line expressed in eq. 6, and 175 6. Regresión lineal en presencia de puntos discrepantes cov(xi yi) is the covariance between the predictor and the response variable in the ith point, which is normally set to zero. Whenever the variances of the predictor variable are zero and all the variances on the response variable are equal (i.e., all the errors are constant and only due to the experimental measurement in the y axis), the results are identical to those with the ordinary least squares (OLS) method. Since BLS takes into account the errors in both axes and attaches greater importance to the points with small variances (i.e. the regression line fits closer to them), it may be considered to have a certain robustness. However, BLS may have some limitations for obtaining the correct regression line when the data set contains outliers with small variances or when they are placed at the end of the calibration interval (i.e. at points with high leverage). A graphical criterion for detecting outliers by considering errors in both axes. One of the most widely used tests for detecting influential and outlying points in linear regression is Cook’s test [7-9]. Although this test is originally presented in a numerical form, a graphical interpretation checks whether the data pair defined by the intercept and the slope of the regression line once the suspicious points have been removed (b0',b1') falls inside the joint confidence interval of the intercept and the slope (b0,b1) of the overall data set [15] (Figure 1), since the distance of Cook corresponds to the joint confidence interval for the intercept and the slope of the regression line. In the example in Figure 1, no outliers would be detected since the point (b0',b1') falls inside the joint confidence region for the intercept and the slope of the initial data set (i.e., no significant differences would be found between the two regression lines). The drawback of this test is that it looks at the position of the new intercept and slope relative to the initial ones and their confidence interval, but does not take into account the variances of the new regression coefficients once the suspicious points have been removed. While the new regression coefficients may be similar to the initial ones, their variances may be very different. This may provide in similar regression lines but very different results once statistical tests have been applied to the regression line, because these tests normally depend heavily on the variances of the regression coefficients. 176 6.2.2 Analytica Chimica Acta, en prensa α=5% Slope (b0 ' , b1 ' ) (b0 , b1 ) Intercept Figure 1.- Example of an application of Cook’s test. The point (b0,b1) corresponds to the intercept and the slope of the overall data set, and the ellipse is their joint confidence interval for an α level of significance. The point (b0',b1') corresponds to the intercept and the slope of the regression line once the suspicious point have been removed from the initial data set. The method proposed in this paper consists of comparing the joint confidence intervals for the intercept and the slope of two regression lines by considering the errors in both axes; the first one using the overall data set and the second one after removing the suspicious point. The joint confidence interval for the intercept and the slope of the overall data set, which is ellipse in shape, is calculated using the BLS regression method, and its expression is shown in eq. 9 [1]: n ∑ i =1 n 1 (b0 − B0 )2 + 2 xi (b0 − B0 )(b1 − B1 ) + wi i =1 wi ∑ n ∑ i =1 x i2 (b1 − B1 )2 = 2 s 2 F1−α (2,n −2 ) wi (9) where F1-α(2,n-2) is the tabulated F-value at a significance level of α with 2 and n-2 degrees of freedom, and B0 and B1 represent the values of the intercept and the slope that define the bounds of the ellipse. The expression for the joint confidence interval for the intercept and the slope once the suspected point has been removed is: n' 1 ∑ w (b' i =1 i 0 − B0 n' n' 2 )2 + 2∑ xi (b' 0 − B0 )(b'1 − B1 ) + ∑ xi (b'1 − B1 )2 i =1 wi i =1 wi = 2 s' 2 F1−α (2,n ' −2 ) (10) 177 6. Regresión lineal en presencia de puntos discrepantes where n' and s'2 are, respectively, the number of points and the estimate of the experimental error of the regression line once the suspicious point has been removed. The two joint confidence intervals (eqs. 9 and 10) are then compared in terms of the degree of overlapping between their areas. This criterion was chosen because the overlapped area can be seen as a measure of the similarity of the two joint confidence intervals and, consequently, of the regression coefficients and their associated variances at the same time. To find the coincident area between the two ellipses, we compute the ratio between the double of the intersected area (since this area belongs to both ellipses) and the sum of the area of the two ellipses: Coincidence (%) = 2 * Intersected area * 100 Area ellipse 1 + Area ellipse 2 (11) Slope Joint confidence intervals Data set without suspicious points A Overall data set A (b0',b1') (b0,b1) Intercept Figure 2.- The two confidence intervals for the intercept and the slope of the regression line obtained using the BLS regression method, one for the overall data set and the other after removing the suspicious point. A represents the area of intersection of the two ellipses. The figure shows a projection of the ellipse corresponding to the overall data set in order to make it clearer that the area A is doubled. This process is shown in Figure 2, in which one of the ellipses is projected in order to clarify how the double of the intersected area in Equation 11is used. The limit in overlapping for considering that the two straight lines as similar (and therefore that the suspicious point is not an outlier for the chosen α level of significance) is 2/3. This limit is chosen because it means that half of the largest 178 6.2.2 Analytica Chimica Acta, en prensa ellipse is completely intersected by the smallest one. This assures that the centre of each ellipse (the intercept and the slope of each straight line) is within the other joint confidence interval, and that the area of the smallest is at least half that of the largest. In this way, if two straight lines are considered coincident, the areas of the ellipses and the regression coefficients of the two straight lines are definitely similar at the same time. This criterion has been checked in several simulated and real data sets with encouraging results. The main advantages of this method are that it uses all the information about the straight line, and that the experimental points that can be detected as outliers are not only the ones that affect the regression coefficients, but also the ones that influence their variances (e.g. experimental points with high errors or ones that are outside the domain of the data set). EXPERIMENTAL SECTION Data sets. One simulated data set (data set 1) and two real data sets (data sets 2 and 3) were used to check the graphical criterion for detecting outliers we have developed in this paper. The simulated data set is one with quasi perfect fit of the points to the straight line and in which an outlier is introduced at two different locations. One of the two real data sets deals with method comparison studies using linear regression, while the other one is extracted from a calibration line. Data Set 1: This is a simulated data set made up of six data pairs obtained by assuming that five points have a good fit to a straight line, and that the sixth point is an outlier. The five points with good fit to the regression line range from 1 to 5 units in both axes following a straight line with unity slope and zero intercept and whose standard deviations are assumed to be 1 in both axes. The sixth data pair is placed in two different positions with standard deviations in both axes varying from 0.1 to 10 times those for the other five points in the data set. The straight lines resulting from the addition of these suspicious points in each case are shown in Figures 3a and 4a. 179 6. Regresión lineal en presencia de puntos discrepantes Data Set 2: [16] This data derives from comparing the analysis of a certified reference soil using a wet matrix (containing 20% water) and a dry matrix. The certified reference material is SRS 103-100 soil from Fisher Scientific (Fair Lawn, NJ), spiked with PAHs. PAHs were analysed using micro wave-assisted extraction (MAE) to six 5g portions of the reference material extracted simultaneously for 10 min at 115ºC. The extracted recoveries using both matrices were obtained after six determinations of any sample. These ranged from 79.0 to 150. The data set is plotted in Figure 5 where we can see the BLS regression line, and that the horizontal and vertical lines in each point are the double of the experimental standard deviation. 160 Wet matrix 140 120 100 80 60 100 Dry matrix 140 180 Figure 5.- Plot of data set 2 and the BLS regression line. The vertical and horizontal lines in every data pair represent the double of the standard deviations in both axes. Data Set 3: [17] This data set is obtained from the comparison of resist thickness measured using a nanospectometer/AFT (x axis) and an IRRAS spectra (infrared reflection absorption spectroscopy) (y axis) used to determine nine films of commercially available photoresists and silicon dioxide. Three replicates of IRRAS data were collected varying the location on the surface of the wafer, and the resulting thicknesses were averaged. As it is difficult to determine the absolute accuracy of the commercial instruments, uncertainties for all measurements represent the variations in film thickness over the surface of the wafer. The results range from 0.873 to 2.213 µm. The data set is plotted in Figure 6. The horizontal 180 6.2.2 Analytica Chimica Acta, en prensa and vertical lines in each data pair are the double of the experimental standard deviation and the regression line is calculated using the BLS regression method. 10 2.2 9 IRRAS 1.8 8 7 5 1.4 3 6 4 1 2 1 0.6 1 1.5 Nanospectometer/AFT 2 Figure 6.- Plot of data set 3 and the BLS regression line. The vertical and horizontal lines in every data pair represent the double of the standard deviations in both axes. All calculations were performed with customized software using MATLAB [18]. RESULTS AND DISCUSSION Data Set 1: The aim of the simulated data sets is to study the influence of the position and the errors associated with an outlier in the data set, and to prove the suitability of this new graphical criterion for detecting the outlying points. Figures 3a and 4a show the effect of adding a sixth point to a five-point data set of good fit to a straight line of unity slope and zero intercept. In figure 3a, this suspicious point is outside the limits of the interval defined for the other five data pairs, while figure 4a shows the suspicious point in the middle of the interval of the predictor variable with a wrong value in the response variable. 181 6. Regresión lineal en presencia de puntos discrepantes a) (b‘0,b‘1) Slope Response variable 1 4 0.6 2 (b0,b1) 0.1 0.5 1 0.2 5 10 0 1.4 -2 0 2 Predictor variable 4 0 37.22% d) 1.4 (b‘0,b‘1) Slope Slope 1 (b0,b1) 0.6 (b0,b1) 0.6 sxi = 0.5 -2 sxi = 1 0.2 0 2 4 -2 0 2 Intercept 82.92% e) 1.4 (b‘0,b‘1) 1 (b0,b1) 96.03% f) (b‘0,b‘1) 1 (b0,b1) 0.6 0.6 sxi = 10 sxi = 5 0.2 -2 4 Intercept Slope Slope 1.4 2 Intercept (b‘0,b‘1) 1 sxi = 0.1 -2 6 24.27% c) 0.2 11.97% b) 1.4 6 0 2 0.2 -2 Intercept 0 2 Intercept Figure 3.- a) Effect of adding a point with high leverage to the limits of the interval defined for the other five data pairs in the simulated data set defined in data set 1. The standard deviations of the suspicious point vary from 0.1 to 10 times the value of the standard deviation of the other data pairs. b to f) Application of the graphical criterion for detecting outliers in the different cases presented in Figure 3a. In each case the standard deviation of the leverage point, coincidence between two ellipses are presented. 182 s xi , and the percentage of 6.2.2 Analytica Chimica Acta, en prensa 8 6 a) 11.97% 4 Slope 4 Response variable b) 10 5 1 0 (b0,b1) 2 (b‘0,b‘1) 0.5 0 -4 sxi = 0.1 0.1 0 3 2 Predictor variable 4 -2 6 -10 0 10 Intercept c) 3 24.27% 37.22% d) 2 (b0,b1) (b‘0,b‘1) 1 0 Slope Slope 2 0 sxi = 0.5 -8 -4 0 Intercept 1.8 4 -4 -2 0 2 4 Intercept 1.8 1.4 f) 96.03% 1.4 (b0,b1) 1 Slope Slope (b‘0,b‘1) sxi = 1 -6 82.92% e) (b0,b1) 1 (b‘0,b‘1) 0.6 (b0,b1) 1 (b‘0,b‘1) 0.6 sxi = 10 sxi = 5 0.2 -2 0 Intercept 2 -2 -1 0 1 2 3 Intercept Figure 4.- a) Effect of adding an outlier in the middle of the data with an error in the response in the simulated data set defined in data set 1. The standard deviations of the suspicious point vary from 0.1 to 10 times the value of the standard deviation in the other data pairs. b to f) Application of the graphical criterion for detecting outliers in the different cases presented in Figure 4a. In each case the standard deviation of the outlier, s xi , and the percentage of coincidence between two ellipses are presented. 183 6. Regresión lineal en presencia de puntos discrepantes Figures 3b-3f and 4b-4f show the two confidence ellipses corresponding to the two straight lines being compared; one without the added point (b0', b1'), and one with the overall data set (b0, b1). Figures 3b-3d clearly detects the influential point, while in Figures 3e and 3f the variances of the influential point are high enough not to significantly affect the resulting BLS straight line. The same conclusion can be drawn from Figure 4, where the outlier is detected in the three cases with the smallest variances and is not detected in the other two cases. In conclusion, the graphical test for detecting outliers when errors in both axes are taken into account detects the sixth point as an outlier except when the standard deviation of the suspicious point is clearly higher than those of the other data pairs, so it does not significantly affect the regression line and there is therefore no need for the point to be removed. In the first situation (Figures 3b-3f), the outlier basically influences the uncertainties of the regression coefficients of the resulting straight line. For this reason the centres of the two ellipses rapidly get nearer, but there is a small degree of overlapping because of the differences in the uncertainties of the regression coefficients (which clearly affect the area of the two ellipses). The second situation (Figures 4b-4f) is one in which the area and the shape of the two ellipses rapidly converge, but there are different values for the regression coefficients. Data set 2: In this data set, the average recovery of pentachlorophenol (the first data pair) is clearly suspected as an outlier. The effect of this point on the straight line is considerable, and the graphical criterion detects it as an outlier because the coincidence (eq. 11) is 27.25%. This percentage is so small because of the influence of this point on the regression coefficients of the straight line (i.e. all the other points are good aligned, so this point forces the line to deviate from them). This is an example of a real data set with a data pair that clearly influences the straight line due to the closeness of the point to the straight line. When classical tests for detecting outliers (like Cook’s test) are applied to the data set, no outlier is detected in the data. Data set 3: Table 1 shows the results of using the graphical criterion to detect outliers in data set 3. The second and the sixth point are detected as outliers using the graphical criterion. Figure 6 shows that the second point can be 184 6.2.2 Analytica Chimica Acta, en prensa considered an influential point since its experimental variances are so much smaller than those of the other points. The sixth data pair may be also considered an outlier, although it also has small variances too, because its alignment is different from that of the other points in the data set. If we had used Cook’s test to detect the outliers, the conclusion for a 5% α level of significance would be that there was no outlier in the data set. This is because these two points greatly influence the variances of the coefficients of the regression line (not only the coefficients) mainly due to their errors in both axes, which are not detected by traditional tests. 1 Slope 0.96 Overall data set 0.92 0.88 -0.05 Data set without the second point 0 0.05 Intercept 0.1 0.15 Figure 7.- Result of the graphical criterion for detecting outliers over the second point in data set 3. As we have already mentioned, the second data pair is detected using the graphical criterion (Figure 7), but as the percentage of coincidence of the two regression lines for this point (see Table 1) is very close to the threshold level of 66.67%, it may or may not be detected as an outlier, depending on the α level of significance chosen. This is because the significance level affects the size of the joint confidence intervals, and therefore the percentage of coincidence. Figure 7 shows how eliminating this data pair basically affects the variances of the regression coefficients (i.e. the area of the joint confidence interval), as we stated previously. Figure 8 shows the results of using the graphical criterion on the sixth data pair. We may conclude that the main effect of this point being over the regression line is that it also affects the variances of the regression coefficients. The main difference between this figure and Figure 7 is that when the sixth data pair is eliminated, the regression coefficients are also affected (not only their variances). This is because this point is located far from the tendency of the other data pairs. 185 6. Regresión lineal en presencia de puntos discrepantes Table 1.- Percentage of coincidence of all data pairs after applying the graphical criterion to data set 3 with a level of significance of 5%. Data Pair % of coincidence 1 71.66 2 63.91 3 90.92 4 91.60 5 90.10 6 14.11 7 92.12 8 90.71 9 90.70 10 92.79 As this data set has two points that can be considered outliers, we can use multiple case diagnostics to detect both at the same time. Figure 9 compares the initial data set and the data set without the two suspected points. When the number of data pairs in the data set is small, the analyst should consider whether the small coincidence between the ellipses is due to how the number of points affects the variances of the regression coefficients. In this case, however, the small coincidence between the two ellipses (10.46%) is mainly due to the suspected outliers rather than to the smaller number of points in the data set. Figure 9 shows that the regression coefficients are clearly affected by the two suspected points. Therefore, by using the graphical criterion for the multiple case diagnostic, the conclusions are the same as for the single case diagnostic. This is mainly because the number of data pairs (ten data pairs reduced to eight by deleting the outliers) cannot be considered small. 1.1 1.05 1 Slope Overall data set 0.95 0.9 -0.05 Data set without the sixth point 0 0.05 Intercept 0.1 0.15 Figure 8.- Result of the graphical criterion for detecting outliers over the sixth point in data set 3. 186 6.2.2 Analytica Chimica Acta, en prensa 1.05 Slope 1 Overall data set 0.95 Data set without points 2 and 6 0.9 -0.05 0 0.05 Intercept 0.1 0.15 Figure 9.- Result of the graphical criterion for detecting outliers as multiple case diagnostic technique over the second and sixth point in data set 3. Another consequence of having more than one suspected point may be the masking effect between the suspected points. To see the masking effect in this data set, we can check the drop in coincidence when both outliers are detected at the same time (10.46% in the multiple case against 63.31% when the second point is deleted and 14.25% when the sixth one is deleted). CONCLUSIONS In this paper we have developed a graphical criterion for detecting outliers based on the BLS regression method, which takes into account the individual experimental errors in both axes. This new technique has been checked with three data sets (a simulated one and two real data sets taken from the literature) for detecting suspected points in different positions in the data set (with different degrees of leverage). When the α significance level decreases the probability of detecting a point as an outlier increases. If some data pairs have smaller individual experimental variances than the others, they will probably be detected as outliers by the graphical criterion (or in most cases as influential points), even though they were almost perfectly fitted with the other data pairs. In these cases, the causes of the small variances must be carefully studied. If they are due to especially careful measurement, the points 187 6. Regresión lineal en presencia de puntos discrepantes cannot be deleted from the data set. Otherwise, if the variances are extremely low because of an error in measuring or because the number of replicates is small, the points should be deleted from the data set, because the uncertainties of the regression coefficients may then be underestimated. This limitation of the graphical criterion must be overcome by studying of the suspected data pair by means of the analyst. In most cases, this allows us to detect outliers or influential points that would not be detected by classical detection techniques like Cook’s test. Another situation is when a data pair with high uncertainties is far from alignment with the other points of the data set. The graphical criterion may not detect this point, because it does not influence the BLS straight line, which considers those points with higher uncertainties to have minor weight. Otherwise, the graphical criterion is more sensitive to detecting points that are different very much from the other data pairs than the classical tests (especially when the suspected point has small variances). The main limitation of the graphical criterion its use in data sets with a small number of points (i.e. less than four or five data pairs). This is because the straight line is heavily affected (especially the variances of the regression coefficients) after a data pair has been removed, since a small number of data points provides little information, and an experimental point may be detected as an outlier when really it is not. Using the graphical criterion to detect more than one outlier is equivalent to the single case diagnostic. In this case, the analyst must be careful with the influence of the number of points in the data set. If a data set has many data pairs, more than one outlier can be detected by using the graphical criterion for the multiple case, because the difference between the number of points in the initial data set and the number of points in the final one is small. If the data set has a small number of data pairs, the multiple case diagnostic increases the risk of considering points as outliers when they are not. 188 6.2.2 Analytica Chimica Acta, en prensa ACKNOWLEDGEMENTS The authors thank the Spanish Ministry of Education and Science (DGICyT project no. BP96-1008) for their financial support. REFERENCES [1].- J. Riu, F.X. Rius, Anal. Chem. 68 (1996) 1851. [2].- R.L. Watters, R.J. Carroll, C.H. Spiegelman, Anal. Chem. 59 (1987) 1639. [3].- K. Govindaraju, I. Roelandts, Geostandards Newsletter 13 (1989) 5. [4].- X. Xie, M. Yan, L. Li, H. Shen, Geostandards Newsletter 9 (1985) 83. [5].- J.M. Lisý, A. Cholvadová, J. Kutej, Computers Chem. 14 (1990) 189. [6].- J. Riu, F.X. Rius, J. Chemom. 9 (1995) 343. [7].- S. Weisberg, Applied Linear Regression, John Wiley & Sons, 2nd edition, 1985, New York, p 119. [8].- R.D. Cook, Technometrics 19 (1977) 15. [9].- D.L. Massart, B.G.M. Vandeginste, L.M.C. Buydens, S. de Jong, P.J. Lewi, J. Smeyers-Verbeke, Handbook of Chemometrics and Qualimetrics: Part A, Elsevier, Amsterdam, 1997, p 203, 300. [10].- P.J. Rousseeuw, A.M. Leroy, Robust Regression & Outlier Detection, John Willey & Sons, New York, 1987. [11].- C. Hartmann, P. Vankeerberghen, J. Smeyers-Verbeke, D.L. Massart, Anal. Chim. Acta 344 (1997) 17. [12].- M.L. Brown, Journal of the American Statistical Association 377 (1982) 71. [13].- P. Sprent, Models in Regression and Related Topics, Methuen & Co. Ltd., London, 1969. [14].- G.A.F. Seber, Linear Regression Analysis, John Wiley & Sons, New York, 1977 p 160. [15].- J. Mandel, F.J. Linnig Anal. Chem. 29 (1957) 743. [16].- V. Lopez-Avila, R. Young, W.F. Beckert, Anal. Chem. 29 (1994) 1097. [17].- C.J. Gamski, G.R. Howes, J.W. Taylor Anal. Chem. 66 (1994) 1015. [18].- Mathworks Inc., Natick, Massachussets, USA. 189 6. Regresión lineal en presencia de puntos discrepantes 6.2.3 Comprobación de la aplicación del criterio gráfico Con el fin de comprobar la aplicabilidad del criterio gráfico presentado en el apartado anterior, se planteó la posibilidad de estudiar cómo varían las conclusiones que se extraen del mismo al variar ligeramente las condiciones de un conjunto de datos. Para llevar a cabo este estudio, se partió de un conjunto de datos obtenido de la comparación del contenido de aminas biogénicas en anchoas frescas antes (eje de abscisas) y después de almacenarlas congeladas durante dos días (eje de ordenadas).7 Para llevar a cabo esta comparación se analizó la concentración de diez aminas en el músculo del pescado, una vez eliminadas la cabeza, las espinas y las tripas, utilizando como técnica analítica la cromatografía líquida. Los resultados están expresados en mg/kg y sus valores están comprendidos entre los 0.10 y los 6.55 mg/kg. Una representación de este conjunto de datos, así como la recta de regresión de BLS, se presenta en la figura 6.1, donde las líneas verticales y horizontales representan el doble de la desviación estándar experimental en cada punto. 8 Dos días de almacén 6 4 2 Punto estudiado 0 0 4 Antes de almacenar 8 Figura 6.1.- Representación del conjunto de datos utilizado para la comprobación de la aplicabilidad del criterio gráfico para la detección de puntos discrepantes. 190 6.2.3 Comprobación de la aplicación del criterio gráfico Este conjunto de datos se escogió de entre los presentes en la bibliografía debido a la aparente ausencia de puntos que puedan considerarse discrepantes. Sobre él se escogió el quinto punto (el más próximo a poder ser considerado como sospechoso de ser discrepante), y se variaron sus valores con el fin de simular errores en la medida o en la toma de resultados. De esta forma, se variaron sus valores de la variable predictora y respuesta así como de sus respectivas varianzas experimentales. En la figura 6.2 se representa la variación de la coincidencia obtenida mediante el criterio gráfico para la detección de puntos discrepantes (cuando se considera un nivel de significancia del 5%) presentado en el apartado anterior. Se observa como al aumentar su valor rápidamente se debería considerar dicho punto como discrepante. Sin embargo, al disminuir su valor, la resistencia del punto a ser considerado como discrepante aumenta. Esta conclusión es lógica si se observa que inicialmente el punto está a la derecha de la recta de regresión. % coincidencia 100 90 80 Punto no discrepante 70 60 50 40 30 20 10 0 Punto discrepante Valor inicial -3 -2 -1 0 1 x5 2 3 4 5 Figura 6.2.- Representación del porcentaje de coincidencia al variar el valor de la variable predictora. 100 90 80 Punto no discrepante % coincidencia 70 60 50 Punto discrepante 40 30 20 Valor inicial 10 0 -4 -2 0 2 4 y5 6 8 10 12 Figura 6.3.- Representación del porcentaje de coincidencia al variar el valor de la variable respuesta. 191 6. Regresión lineal en presencia de puntos discrepantes En la figura 6.3 se observa que al modificar la variable respuesta las conclusiones son idénticas a las obtenidas al variar la variable predictora. En ambos casos el porcentaje de coincidencia entre las dos elipses aumenta a medida que el punto se cerca a la recta de regresión, excepto en el momento en que el punto pasa de estar de un lado al otro de la recta. En este momento, la coincidencia presenta una ligera disminución (que en ningún caso afecta a las conclusiones del criterio gráfico), debida a un ligero descenso del área de la elipse que no considera el punto sospechoso de ser discrepante, que a su vez se debe, principalmente, al efecto de la covarianza entre los coeficientes de la recta de regresión. Esta disminución se observa en los mínimos relativos de las figuras 6.2 y 6.3. 100 90 Punto no discrepante 80 % coincidencia 70 60 Punto discrepante 50 40 30 20 Valor inicial 10 0 0 0.5 1 var(x5) 1.5 2 2.5 Figura 6.4.- Representación del porcentaje de coincidencia al variar el valor de la varianza de la variable predictora. 100 90 80 Punto no discrepante % coincidencia 70 60 50 40 30 20 Valor inicial 10 0 0 0.2 0.4 0.6 var(y5) 0.8 1 1.2 Figura 6.5.- Representación del porcentaje de coincidencia al variar el valor de la varianza de la variable respuesta. 192 6.2.3 Comprobación de la aplicación del criterio gráfico Las siguientes figuras 6.4 y 6.5 representan el mismo estudio en que se varían las varianzas de la variable predictora y respuesta respectivamente. El efecto de variar las varianzas es mucho menor pues, si bien al disminuir la varianza de la variable predictora, el punto se acaba considerando como discrepante, al variar la varianza de la variable respuesta el criterio gráfico siempre detecta el punto sospechoso como no discrepante. La principal conclusión extraída de las figuras 6.4 y 6.5 es que la probabilidad de un punto de ser considerado como discrepante aumenta cuando disminuyen las varianzas experimentales (tanto de la variable predictora como de la variable respuesta). Es por este motivo que hay que tener un especial cuidado con aquellos puntos cuyas varianzas experimentales son extremadamente pequeñas. Sin embargo, la importancia de este análisis radica en que haciendo el mismo estudio de puntos discrepantes mediante el test de Cook, el punto en cuestión se considera no discrepante en todos los casos estudiados. De esta manera se comprueba la mayor sensibilidad del criterio gráfico ante la presencia de puntos discrepantes. Nº punto % de coincidencia 1 71.66 2 63.91 3 90.92 4 91.60 5 90.10 6 14.11 7 92.12 8 90.71 9 90.70 10 92.79 Tabla 6.1.- Porcentaje de coincidencia para todos los puntos pertenecientes al tercer conjunto de datos de la sección 6.2.2, utilizando un nivel de significancia del 5%. Sobre el tercer conjunto de datos de los presentados en el apartado 6.2.2,8 se ha realizado un estudio correspondiente a la variación de la coincidencia al variar el nivel de significancia (α) en el criterio gráfico. Para ello, en la tabla 6.1, están representadas las coincidencias, entre las dos elipses comparadas por el criterio gráfico, obtenidas para cada uno de los puntos del conjunto de datos cuando el nivel de significancia se supone del 5%. Se observa que el segundo y el sexto puntos tienen una coincidencia que hacen que la conclusión del criterio gráfico es considerarlos como puntos discrepantes. Por este motivo se seleccionó el 193 6. Regresión lineal en presencia de puntos discrepantes segundo de ellos para representar la coincidencia frente al nivel de significancia, tal como se puede observar en la figura 6.6. En la figura 6.6 se observa como el porcentaje de coincidencia entre las dos elipses comparadas disminuye cuando aumenta el nivel de significancia, tal como cabía esperar. En el caso estudiado, se puede comprobar que las probabilidades de considerar el segundo punto como discrepante aumentan cuando lo hace el nivel de significancia, dejando de ser considerado como un punto discrepante cuando el nivel de significancia disminuye del 3.5% aproximadamente. Estos resultados se pueden considerar como una prueba más de la bondad del funcionamiento del criterio gráfico presentado en la sección 6.2.2, pues sus resultados concuerdan con el comportamiento esperado de que las probabilidades de considerar un punto como discrepante aumenten al hacerlo el nivel de significancia (α). 80 % de coincidencia 75 Valor umbral 70 65 60 55 0 2 4 6 8 Nivel de significancia (%) 10 Figura 6.6.- Efecto de variar el nivel de significancia α en el proceso de detección de puntos discrepantes mediante el criterio gráfico sobre el segundo punto del tercer conjunto de datos de la sección 6.2.2. . 194 6.3 Regresión robusta 6.3 Regresión robusta 6.3.1 Introducción A lo largo de los años, muchos autores han criticado las técnicas de detección de puntos discrepantes,9-12 pues con su uso se corre el riesgo de eliminar puntos que contienen información debida a la singularidad de los resultados analíticos implicados, si bien admiten que estos puntos no deben influir en la recta de regresión.1 Para superar esta limitación, se han desarrollado las técnicas de regresión robusta. Estas técnicas encuentran una recta de regresión que minimiza el efecto de los puntos discrepantes, pero sin eliminarlos. De esta forma la limitación anteriormente mencionada de estos tests de detección de puntos discrepantes queda subsanada. Sin embargo, estos métodos de regresión robusta incluyen una serie de inconvenientes derivados del algoritmo de cálculo, tales como la propia complicación de los algoritmos, como la dificultad de utilizar tests asociados a la recta de regresión robusta, que en muchos casos no se han podido desarrollar. En el siguiente apartado de esta Tesis Doctoral, se presenta el artículo: “Robust linear regression taking into account errors in both axes”, que se ha enviado para su publicación en la revista Analyst en el que se presenta una aproximación robusta de la recta de regresión que considera los errores cometidos en las dos variables. Esta técnica de regresión robusta, llamada regresión bivariante por mínima mediana de los cuadrados (bivariate least median of squares, BLMS), es una generalización de la regresión por mínima mediana de los cuadrados (least median of squares, LMS) desarrollada por Rousseeuw y Leroy,13 donde se ha añadido un proceso de simulación, con el fin de salvar la limitación de LMS que impone que la recta de regresión robusta pase exactamente por dos puntos del conjunto de datos inicial. 195 6. Regresión lineal en presencia de puntos discrepantes En el apartado 6.3.3 se presenta la comparación de los dos métodos de simulación propuestos en el algoritmo de cálculo de la recta de regresión robusta, mientras que el apartado 6.3.4 presenta un estudio de la robustez de BLS. 196 6.3.2 Analyst, enviado 6.3.2 Robust linear regression taking into account errors in both axes Analyst. Enviado para publicación F. Javier del Río*, Jordi Riu, F.Xavier Rius Department of Analytical and Organic Chemistry. Universitat Rovira i Virgili. Pl. Imperial Tarraco, 1. 43005-Tarragona. Spain. In this paper we have developed a robust regression technique. It is a generalization of the LMS technique to the field in which the errors in both axes are taken into account. This simple generalization is limited in the sense that the resulting straight line is found by using only two points from the initial data set. In this way a simulation step is added by using the Monte Carlo method to generate the best robust regression line. We have called this new technique “bivariate least median of squares” (BLMS), following the notation of the LMS method. We checked the robustness of our new regression technique by calculating its breakdown point, which was 50%. This confirms the robustness of the BLMS regression line. In order to show its applicability to the chemical field we tested it on simulated data sets and real data sets with outliers. The BLMS robust regression line was not affected by many types of outlying points in the data sets. Keywords: Outliers; linear regression; errors in both axes; robust regression; least median squares 197 6. Regresión lineal en presencia de puntos discrepantes INTRODUCTION Linear calibration is widely used in analytical chemistry, for instance, for relating the instrumental response with the analyte of interest, or in method comparison studies at several levels of concentration.1 The method that is widely used for finding the coefficients of the straight line is ordinary least squares (OLS), but this considers that the predictor variable (x axis) is error-free and only allows constant random errors in the response variable (y axis). If the random errors in the predictor variable are not constant throughout the regression interval, weighted least squares (WLS) may be used, but this still considers that the predictor variable is error-free. Not taking into account the errors in the predictor variable may sometimes lead to biased results in the coefficients of the straight line. For instance, the instrumental responses are sometimes so stable that the errors in the predictor variable cannot be neglected.2 Similarly, when the results of two methods at different concentration levels are compared by linear regression3 and both methods have associated errors, neglecting the errors in one of them (i.e. using the OLS or WLS regression methods) may lead to biased results in the regression line. Also there are some analytical techniques, e.g. X-ray fluorescence,4 in which due to the complexity of the real samples to be analyzed, the calibration line is often built with certified reference materials (CRM) of the analyte of interest, each one of which has known errors associated to the predictor variable.5,6 In these cases, one should use regression methods that take into account the errors in both axes. The bivariate least square (BLS) method7,8 calculates the coefficients of the straight line by taking into account the individual heteroscedastic errors in both axes. BLS has been used, for example, in method validation studies to detect bias in new analytical methods.1 Once the straight line is found by any regression method that considers errors in both axes, the results derived may be biased because of one or more outlying points in the experimental data set. These points may cause, for example, a shift in the regression coefficients or a high experimental error associated with the regression line (which also increases the variances in the regression 198 6.3.2 Analyst, enviado coefficients9). Any significant bias in a new method may therefore not be detected in a method comparison study, i.e. the probability of committing a β error may increase. These problems may be overcome by techniques for detecting outliers or robust regression methods. The literature contains several techniques for detecting outliers (e.g., Cook’s test10) and some robust regression techniques (e.g., least median of squares, LMS3,11), that consider only errors in the response variable, and others methods of robust regression that consider errors in both axes are under some restrictions.12,13 Most authors recommend robust techniques rather than techniques for detecting outliers.14-16 In particular, Huber17 emphasizes that robust regression can smooth the transition from accepting to rejecting a suspected point in a data set. Furthermore, the advantage of using robust regression techniques when there is more than one outlier has been proved, because the one outlier can be hidden by another. Moreover, by rejecting a suspected point that is not an outlier, other points which were not initially suspected may appear as outliers. In this paper we present a new robust regression technique (BLMS, bivariate least median of squares), that follows the principles of the LMS technique and takes into account the individual experimental errors in both axes. We have calculated the breakdown point for BLMS to prove its robustness, and compared the result with the breakdown point of BLS, calculated over the same simulated data set. To check the goodness and applicability of the new robust regression technique, we used it on a simulated data set containing a point with high leverage and uncertainties values and on a real data set from the bibliography. BACKGROUND AND THEORY Bivariate least squares (BLS). Of the several regression techniques that consider errors in both axes,8 we chose BLS because it can readily provide the regression coefficients and their associated variances and covariances, and because programming its algorithm is simple. This technique assumes that the true linear model: 199 6. Regresión lineal en presencia de puntos discrepantes ηi = β 0 + β1ξi (1) where β0 and β1 are the true intercept and slope of the regression line that relates the true predictor (ξi) and response (ηi) variables. The true variables are unobservable; one can only observe the experimental variables: xi = ξ i + δ i (2) yi = ηi + γ i (3) where variables δi and γi are random errors made when measuring the predictor variable and response variable, respectively, where δ i ~ N (0, σ 2xi ) and γ i ~ N (0, σ 2yi ) . So, if we introduce eqs. 2 and 3 into eq. 1, variables xi and yi are related as follows: y i = β 0 + β1 x i + ε i (4) where β0 and β1 are the true values of the intercept and the slope, respectively, and εi is the ith true residual error,18 which can be expressed as a function of δi, γi and β1: ε i = γ i − β1 δ i (5) The BLS regression method relates the observed variables xi and yi as follows: yi = b0 + b1 xi + ei (6) where ei is the observed ith residual error. The BLS regression method finds the estimates of the regression line coefficients by minimising the sum of the weighted residuals, S, expressed in eq. 7: S= n ∑ i =1 200 ( y i − yˆ i ) 2 = ( n − 2) s 2 wi (7) 6.3.2 Analyst, enviado where s2 is the estimate of the experimental error, n is the number of experimental data pairs, ŷi is the prediction of the experimental variable yi and wi is the weighting factor that corresponds to the variance of the ith-residual (ei): wi = s e2i = s 2yi + b12 s x2i − 2b1 cov( xi y i ) (8) where s x2i and s 2yi are, respectively, the experimental variances of the ith point for the predictor and response variables of the straight line expressed in the eq. 1, and cov(xi yi) is the covariance between the predictor and the response variable in the ith point, which is normally set to zero. It is interesting that whenever the variances of the predictor variables are zero and all the variances on the response variable are equal (i.e., all the errors are constant and only due to the experimental measurement in the y axis), the results are identical to those of the ordinary least squares method (OLS). Since BLS takes into account the errors in both axes and attaches a greater importance to the points with small variance (i.e. the regression line fits them more closely), it can be considered to have some degree of robustness. However, BLS may have some limitations in obtaining the correct regression line when the data set contains outliers with small variances, or when they are located at the limits of the calibration interval (i.e. they have high leverage). Least median of squares (LMS).11 For a more robust regression technique than OLS, the Least Median of Squares technique replaces the “sum of squares” with the “median of squares” in the minimization process. In this way, the LMS regression line is found by minimizing the median of the sum of the squared residuals of the experimental data pairs to the robust regression line. This estimator is very robust with respect to outliers in x and y. Breakdown Point. Depending on how robust it is, an outlier can affect an estimator in several ways. The concept of the breakdown point was introduced by Hodges19 and generalized by Hampel20. It is a criterion for classifying the estimators according to their robustness. Donoho and Huber21 define it as the minimum percentage of the initial data set that can be contaminated (i.e. the minimum percentage of points that can be outliers) without the regression 201 6. Regresión lineal en presencia de puntos discrepantes coefficients being greatly affected. An estimator with a breakdown point of around 50% is considered robust, and an estimator whose breakdown point is around 0% is non robust. Rousseeuw and Leroy11 calculated the breakdown point for a series of estimators in linear regression methods, and concluded that OLS estimators are immediately affected when an outlier is introduced. The breakdown point for OLS depends on the number of points in the data set and is equal to 1/n.21 A breakdown point above this value is possible when systematic errors affect the data pairs. If there are a lot of data pairs, the breakdown point in OLS will be around 0%. LMS may be considered a robust regression technique because its breakdown point is 50%. Bivariate Least Median Squares (BLMS). To find a robust regression method that takes into account the errors in both variables, we followed the robust strategy when only the errors in the response variable were considered (i.e. the LMS method), and applied it to the BLS case. In this way, the straight lines between all the combinations of two data pairs of the initial data set were calculated using the BLS regression method: using a data set with n points, n(n1)/2 regression lines and therefore n(n-1)/2 estimates for the slope and intercept are found. For each of these regression lines, the median† of the n weighted residuals of the experimental points to the regression line is calculated, and the straight line with the minimum median of the weighted residuals is chosen. This regression line may be considered a robust regression line. So far, this technique is the analogue of LMS when the individual errors in both axes are considered. This strategy’s main limitation is that it (the same as LMS) forces the regression line to fit two points of the initial data set exactly. One way to solve this problem is to use a simulation method like Monte Carlo simulation method.22 With a simulation method, new data sets based on the initial one are generated by adding a random error based on the individual errors in both axes to each experimental point. In this way, and starting from the initial data set, m new data sets are generated. For each of these (m) new data sets, the straight lines between all the † where the median is defined as the ([n/2]+1)nth ranked value and [n/2] denotes the integer part of n/2 202 6.3.2 Analyst, enviado combinations of two data pairs of the initial data set are calculated by the BLS regression method. We therefore obtain n(n-1)/2 regression lines for each new data set. From each of these m sets of n(n-1)/2 regression lines, the regression line with minimum median of the squared weighted residuals is selected. Finally, of all these m robust regression lines, the one whose median of weighted residuals is the minimum is considered to be the BLMS regression line (this does not need to fit two points of the initial data set exactly). Figure 1 shows a scheme of this procedure for obtaining the robust regression straight line with the BLMS technique. In further calculations, the BLMS straight line was found with 100 iterations for the Monte Carlo simulation stage (i.e. m=100). We chose this number because we noticed that a higher number of iterations did not significantly improve the coefficients of the regression line for all the tested data sets, and may significantly increase the calculation time. n(n-1)/2 straight lines 1 1st robust straight line n(n-1)/2 straight lines 2nd robust straight line Initial data set Monte Carlo Minimum weighted residual 2 3 m n(n-1)/2 straight lines BLMS robust straight line 3rd robust straight line ·· · n(n-1)/2 straight lines ·· · mth robust straight line Figure 1 Steps followed to obtain the robust regression line using the BLMS regression technique. From the initial data set, m new data sets are generated using the Monte Carlo simulation method and varying all the initial experimental points. For each one of these new m data sets, the n(n-1)/2 straight lines through all the combinations of two points are found, and is chosen for each one the regression line with minimum median of the squared weighted residuals. Of these m BLMS straight lines, the one with the minimum median of weighted residuals is chosen as the correct robust regression line. We must point out that, depending on how the regression line is used in future, this robust method may have some disadvantages, since information about the variances of the regression coefficients is difficult to find and is not normally accurate (which means that developing future statistical tests over the regression coefficients may be difficult or inexact). This lost of information is due to the 203 6. Regresión lineal en presencia de puntos discrepantes algorithm of the method, which only uses two points to find the final straight line. With LMS an approximate value of the variances and covariances of both the intercept and the slope may be obtained using a sophisticate algorithm,11 but their values are never mathematically exact. Logically, there may be a similar with BLMS because the straight line is also obtained by using only two points, and because BLS is also a least squares technique. EXPERIMENTAL SECTION Data sets. We used extensive calculations on two simulated data sets to check the usefulness of the BLMS regression technique and to calculate its breakdown point and check its robustness. A real data set, from a method comparison study using linear regression, is also used as an example. Simulated data set 1: This simulated data set was obtained following the instructions of Rousseeuw and Leroy11 to check the breakdown point of several estimators. A data set of ninety data pairs was generated; thirty had a predictor variable from 1 to 3.9 at equally spaced 0.1 units, and their response variable followed the straight line: yi = 1xi + 2 + ri (9) where ri is obtained as a random number between -0.2 and 0.2. The uncertainties of these 30 data pairs (expressed as variances) are taken as a random number between 0 and 0.1 multiplied by the value of the predictor variable at each point. The other sixty data pairs were considered to be outlier points generated with a predictor variable of 7 and a response variable of 2, both of which had a random error of between –1 and +1. The experimental simulated variances were generated by multiplying a random value of between –0.1 and 0.1 with the value of the predictor or the response variable, respectively. All random values introduced to generate of the simulated data set were considered to be from a normal distribution so that the real conditions of a data set could be reproduced better. A plot of the data set is shown in Figure 2. 204 6.3.2 Analyst, enviado 6 y axis Data pairs generated with quasi-perfect fit 4 Outliers 2 0 0 2 4 x axis 6 8 Figure 2 The first simulated data set. The crosses represent twice the standard deviations in both the x and y axes. Simulated data set 2: This data set is made up of six points. Five of these data pairs are generated along a straight line, with added random errors, and the sixth pair is generated to be an outlier. The variances in both axes were considered constant and equal to one in the first five data pairs, and the variances of the sixth point changed from almost zero to ten times the value of the variances of the other points in the data set. The aim of this data set is to check the applicability of the robust regression technique when there is an outlier in the data set, and to check how an outlier with small and high variances affects the regression line. A plot of this data set is shown in Figure 3. 205 6. Regresión lineal en presencia de puntos discrepantes 6 y axis 4 2 BLS 0 BLMS -2 0 x axis 2 4 6 Figure 3 The second simulated data set. The lines at each point represent twice the standard deviation in both the x and y axes. The BLS and the BLMS straight lines are also plotted. Real data set: This is a method comparison study for determining As3+ in natural water using continuous selective reduction and atomic absorption spectrometry (AAS) on the x axis, and reduction, cold trapping and atomic emission spectrometry (AES) on the y axis.23 It consisted of 30 points ranging between 0 and 19.3 mg/l. The errors were proportional to the concentration in both methods. A plot of this data set is shown in Figure 4. 25 BLS 20 OLS LMS 15 AES BLMS 10 5 0 0 5 10 AAS 15 20 25 Figure 4 The OLS, LMS, BLS and BLMS regression lines for data set 2. The vertical and horizontal lines that cross every experimental point represent twice of the standard deviation in each experimental point. 206 6.3.2 Analyst, enviado All calculations were made using customized software with MATLAB 4.0 for Microsoft Windows.24 RESULTS AND DISCUSSION We must point out that another method, which is in fact a slight modification of the initial one, can also be followed to find the BLMS regression line. It consists of applying the Monte Carlo simulation method to the two experimental points that define the first robust regression line to obtain m new regression lines. Of these m new regression lines, the one whose median of weighted residuals is minimum will be the correct regression line. The only change from the first method is that the Monte Carlo simulation process is applied at a further stage, when the first robust regression line has been chosen, but the method remains the same (i.e. it is only a matter of calculation). Other approaches, such as sweeping the slope and intercept to find which straight line has the minimum median of residuals, would need considerable calculation time, and the resulting straight line would be no better than those from the two above methods. We compared the results obtained with the method outlined in the 'Background and Theory' section with those obtained with the second method, alongside with their calculation time, using the real data set. To summarize, both straight lines were similar and the time spent in calculating them (with a PC Pentium II with a 450 MHz processor) was of the same order of magnitude. In further calculations in this paper, we will therefore use the method in the Background and Theory section. Calculating the breakdown point: The first simulated data set was used to calculate the breakdown point. The results are shown in Figure 5, which plots the slope of the BLS and BLMS methods against the percentage of contamination with outlying points in the simulated data set. The Figure shows that adding an outlier to the BLS straight line affects the slope almost immediately. In fact, the BLS breakdown point is around 4.75% contamination (this is found from the inflexion point in the graph). Sometimes (e.g. when the uncertainties of outliers are similar to those of the other data pairs), we assume that the theoretical value of the 207 6. Regresión lineal en presencia de puntos discrepantes breakdown point for BLS is similar to that for OLS (1/n=3.33%), because BLS is also a least squares method. This value can be slightly higher when the data set is corrupted, i.e. when a systematic error is added21 as in this example. We may therefore conclude that the BLS regression technique is not robust for the simulated data set used in this paper. However, BLS has sometimes proved to be more robust, as when the outlying points have higher experimental variances than the other data pairs. The BLMS regression technique can be considered robust because its breakdown point is exactly 50%, as we can see in Figure 5, in which the BLMS straight line is not affected by outliers until contamination reaches 50% of the experimental points, as happens with the LMS straight line. BREAKDOWN POINT 1.5 BLMS 1 Slope 0.5 0 BLS -0.5 -1 -1.5 0 10 20 30 40 50 60 % of contamination Figure 5 Breakdown point of the BLS and BLMS regression techniques calculated over the first simulated data set. BLMS in a simulated data set: We used second simulated data set to check the applicability of the new robust regression technique when there is an outlier with different associated errors in both axes. In Figure 6 the slopes of the regression lines from BLS and BLMS are plotted when the variance of the outlier is varied from almost 0 to 10 times the variance of the other data pairs. The slope of the robust straight line is roughly constant when the variance of the outlier is varied (the small variations are due to the iterative process for finding the final regression line). This is important because it proves that the robust regression line is not affected by the outlier or the size of the variances in the variables. The BLS 208 6.3.2 Analyst, enviado straight line is affected by the outlier but, depending on the variance of the outlier, this effect is minimised. Figure 3 plots the BLS and BLMS straight lines when the variances of the outliers are the same as those of the other pairs. 1.2 1 BLMS Slope 0.8 BLS 0.6 0.4 0.2 0 0 2 4 6 Variance of the outlier 8 10 Figure 6 The change in the slope of the BLS and BLMS straight lines when the variances of the outlier in the second simulated data set are varied. BLMS in a real data set: Figure 4 shows the straight lines obtained when the OLS, BLS, LMS and BLMS regression techniques are used. The BLS straight line is mainly affected by the first data pair in the data set because their experimental errors are extremely small (the variances are over a thousand times lower than the smallest variances of the other data pairs), while the robust regression line (BLMS) tends not to fit this data pair or the others at the end of the experimental domain so closely, but to fit the other data pairs better. Extremely small variances must be treated with caution, because although they may be obtained by very accurate measurement on the part of the analyst, they may also be obtained if the sample is very close to the detection limit, when an instrumental error is made when measuring the sample or if other mistakes are made when handling the data. In any case, analysts should pay attention to these points because normally robust regression techniques tend not to consider them (due to the uniqueness of their information) concentrating instead on the other points to find the robust regression line. Therefore, if these special points are the result of some mistake, the robust regression line is the correct one, but if they have some chemical meaning, a robust regression method may not be the best option. The OLS and LMS straight lines are different to those that consider the errors in both axes because they do not consider the associated experimental errors. 209 6. Regresión lineal en presencia de puntos discrepantes CONCLUSIONS In this paper we have adapted the LMS regression technique to find a new way of obtaining a robust regression straight line when individual experimental errors in both axes are taken into account. This new technique includes a simulation step by the Monte Carlo method that increases the generality of the BLMS straight line since the final straight line does not fit two points of the initial data set exactly, as LMS does. We have used the breakdown point (50%) to check the robustness of the regression line obtained with the BLMS technique. Robust regression techniques are usually recommended above techniques for detecting outliers, which can present problems if there is more than one suspected point in the data set; this is because one outlier can hide the effect of another. On the other hand, the disadvantage of robust techniques is that the uncertainties of the regression coefficients are unknown or difficult to find (e.g. with LMS11) This makes it more difficult to use statistical tests on the regression coefficients. We also applied the BLMS technique to two data sets: a simulated one to show the behaviour of the robust straight line when there is an outlier in the data set, and a real one to check its applicability in the chemical field. Although BLS is fairly robust, there are cases when it is not (e.g. the example given in this paper). In conclusion, when BLS does not detect the outliers, the robust BLMS straight line does. The analyst must be wary of correct experimental points with extremely small variances, since the robust regression line will normally detect them as influential points. If the very small uncertainties are due to accurate measurement, this point must be considered highly relevant to the straight line, and the robust regression technique is not appropriate. On the other hand, if they are due to other reasons, such as a measurement near the detection limit, an small replicate measurement or an error in the measurement, the point should not be considered, and the robust regression line is a good solution. 210 6.3.2 Analyst, enviado ACKNOWLEDGEMENTS The authors thank the Spanish Ministry of Education and Science (DGICyT project no. BP96-1008) for their financial support. REFERENCES 1.- J. Riu and F. X. Rius, Anal. Chem., 1996, 68, 1851. 2.- R. L. Watters, R. J. Carroll and C. H. Spiegelman, Anal. Chem., 1987, 59, 1639. 3.- D. L. Massart, B. G. M. Vandeginste, L. M. C. Buydens, , S. de Jong, P. J. Lewi and J. Smeyers-Verbeke, Handbook of Chemometrics and Qualimetrics: Part A; Elsevier, Amsterdam, 1997, pp. 358-361, 379-414. 4.- H. Bennett and G. Olivier, XRF Analysis of Ceramics, Minerals and Allied Materials, Wiley, New York, 1992. 5.- K. Govindaraju and I. Roelandts, Geostand. Newsl., 1989, 13, 5. 6.- X. Xie, M. Yan, L. Li and H. Shen, Geostand. Newsl., 1985, 9, 83. 7.- J. M. Lisý, A. Cholvadová and J. Kutej, Comput. Chem., 1990, 14, 189. 8.- J. Riu, and F. X. Rius, J. Chemom., 1995, 9, 343. 9.- S. Weisberg, Applied linear regression, Willey, New York, 2nd edn, 1985, pp. 114-118. 10.- R. D. Cook, Technometrics, 1977, 19, 15. 11.- P. J. Rousseeuw and A. M. Leroy, Robust regression & outlier detection, Willey, New York, 1987, pp. 9-19, 30, 130. 12.- C. Hartmann, P. Vankeerberghen, J. Smeyers-Verbeke and D. L. Massart, Anal. Chim. Acta, 1997, 344, 17. 13.- M. L. Brown, J. Am. Stat. Assoc., 1982, 377, 71. 14.- C. L. Cheng and J. W. Van Ness, Technometrics, 1997, 39, 401. 15.- D. J. Cummings and C. W. Andrews, J. Chemom., 1995, 9, 489. 16.- F. R. Hampel, E. M. Ronchetti, P. J. Rousseeuw and W. A. Stahel, Robust Statistics, Willey, New York, 1986. 17.- P. J. Huber, Robust Statistics, Willey, New York ,1981. 18.- P. Sprent, Models in Regression and Related Topics, Methuen & Co. Ltd., London, 1969. 19.- J. L. Hodges Jr., Proc. Fifth Berkeley Symp. Math. Stat. Probab., 1967, 1, 163. 211 6. Regresión lineal en presencia de puntos discrepantes 20.- F. R. Hampel, Ann. Math. Stat., 1971, 42, 1887. 21.- D. L. Donoho and P. J. Huber, The notion of breakdown point, in A Festschrift for Erich Lehmann, edited by P. Bickel, K. Doksum and J. L. Hodges Jr., Wadsworth, Belmont, 1983. 22.- P.C. Meier and R.E. Zünd, Statistical Methods in Analytical Chemistry, Wiley, New York, 1993, pp. 145-150. 23.- B. D. Ripley and M. Thompson, Analyst, 1987, 112, 377. 24.- Mathworks Inc., Natick, Massachussets, USA. 212 6.3.3 Comparación de diversos algoritmos de cálculo de la recta BLMS 6.3.3 Comparación de diversos algoritmos de cálculo de la recta BLMS Tal como se ha explicado a lo largo del apartado anterior, el algoritmo de cálculo de la recta de BLMS incluye un proceso de simulación. Concretamente, en el artículo se citan dos propuestas de simulaciones orientadas a superar la limitación del método de LMS que fuerza a la recta de regresión a pasar por dos de los puntos del conjunto de datos (lo que implica una pérdida de generalidad de la recta de regresión). Las dos propuestas se basan en la simulación por el método de Monte Carlo,14-17 que se ha explicado en la sección 2.8 de la presente Tesis Doctoral, y consisten en generar m conjuntos de datos a partir de los valores experimentales y sus respectivas varianzas. La primera de ellas obtiene estos m conjuntos de datos a partir de variar los n puntos del conjunto de datos inicial, y encontrar las rectas de regresión robusta sobre cada uno de ellos, mientras que la segunda propone hacerlo variando únicamente aquellos dos puntos que definen la recta de regresión robusta en la primera iteración del algoritmo. Con el fin de seleccionar una de las dos técnicas basadas en la simulación utilizando el método de Monte Carlo, se llevó a cabo una comparación de los residuales obtenidos mediante cada una de ellas y del tiempo de cálculo utilizado por un ordenador con un procesador Pentium II a 350 MHz. En la tabla 6.2 se representan los resultados de aplicar las dos técnicas sobre un conjunto de datos real extraído de la bibliografía.18 BLMS (variando todos los puntos) BLMS (variando sólo un punto) Número de iteraciones Residual mínimo Tiempo (s) Residual mínimo Tiempo (s) 10 100 100 100 200 0.0682 0.0595 0.0559 0.0551 0.0568 18.40 121.05 119.74 119.35 265.68 0.0612 0.0568 0.0587 0.0559 0.0557 19.55 119.90 118.36 126.50 230.74 Tabla 6.2.- Comparación de los resultados de calcular la recta BLMS utilizando los dos algoritmos propuestos. 213 6. Regresión lineal en presencia de puntos discrepantes En la tabla 6.2 se observa que los resultados obtenidos mediante las dos propuestas pueden considerarse del mismo orden, tanto en lo que se refiere al valor de los residuales como en lo referente al tiempo de cálculo. Por este motivo la elección de uno u otro método de simulación es indiferente. En el artículo presentado en la sección anterior se ha utilizado el primero de los métodos propuestos, donde se ha considerado suficiente hacer 100 iteraciones, debido a que aumentando el número de iteraciones, se minimizan muy sensiblemente los residuales de la recta de regresión aumentando notablemente el tiempo de cálculo. Estas propuestas son una particularización de la metodología de hacer un barrido para generar pares de ordenadas en el origen y pendientes y seleccionar el que minimice los residuales de los puntos experimentales a la recta de regresión. Sin embargo, esta última técnica incluiría una disminución de la robustez de la recta de regresión, además de aumentar la complejidad del algoritmo y el tiempo de cálculo. 6.3.4 Robustez de la recta BLS A lo largo del capítulo se ha mencionado que el método de regresión de BLS tiene cierto grado de robustez debido a que ignora aquellos puntos con errores experimentales elevados. Sin embargo, el punto de ruptura de BLS para el conjunto de datos utilizado en el artículo presentado en el apartado 6.3.2 es del orden del 4.75%, por lo que se deduce la falta de robustez del método. Sin embargo, este valor del punto de ruptura puede cambiar drásticamente cuando los errores experimentales asociados a cada uno de los puntos o la distribución de los mismos varía. Para comprobar esta hipótesis, en la figura 6.7 se presentan cuatro curvas para el cálculo del punto de ruptura en BLS. Una de estas cuatro curvas coincide con la aparecida en el artículo anteriormente mencionado y las otras tres son las curvas obtenidas al modificar las varianzas experimentales del conjunto de datos. Estas modificaciones suponen, en el primero de los casos disminuir su valor diez veces y en los otros dos casos multiplicar su valor por diez y cien unidades respectivamente. 214 6.3.4 Robustez de la recta BLS 1.5 Pendiente 1 0.5 0 -0.5 -1 -1.5 0 *0.1 *1 20 *10 40 60 % de contaminación *100 80 100 Figura 6.7.- Variación del punto de ruptura del método BLS al modificar las varianzas experimentales de los puntos discrepantes. Observando los puntos de inflexión de la figura se pueden calcular los puntos de ruptura para todos los casos presentados. De esta forma se observa como para el caso en que las varianzas han sido disminuidas el punto de ruptura obtenido es del 1.6%, mientras que al aumentar las varianzas de los puntos discrepantes, el punto de ruptura aumenta hasta el 32.5% en el caso de multiplicar por un factor de 10 e incluso superar el 50% (llegando al 84.45%) al multiplicar las varianzas por un factor de 100. De esta manera se comprueba que el método BLS tiene cierto carácter robusto, que se ve acentuado cuando las varianzas de los puntos discrepantes son grandes. Por otro lado se comprueba que pierde sentido fijar el máximo teórico del punto de ruptura en el 50% al considerar los errores individuales en las variables predictora y respuesta, a pesar de que este valor es efectivamente un máximo en aquellos métodos que no incorporan la ponderación de los puntos experimentales en su algoritmo. En la figura 6.7 también se observa que si los puntos discrepantes tienen varianzas pequeñas, la pendiente vuelve a cambiar drásticamente cuando el porcentaje de contaminación se acerca al 90%. Esto se debe a que el método BLS tiende a ajustar en ese momento a los puntos discrepantes sin tener en cuenta los puntos inicialmente alineados. Es de suponer que en el resto de situaciones (con varianzas mayores) esta situación se repita cuando el punto de ruptura se acerque al 215 6. Regresión lineal en presencia de puntos discrepantes 100%. Sin embargo no ha sido posible observarlo debido a las limitaciones del software utilizado. 216 6.4 Protocolo de actuación en regresión lineal en presencia de puntos discrepantes 6.4 Protocolo de actuación en regresión lineal en presencia de puntos discrepantes 6.4.1 Introducción En los apartados 6.2 y 6.3 de la presente Tesis Doctoral se han desarrollado sendas técnicas para detectar y discriminar los puntos discrepantes en regresión lineal considerando los errores en ambas variables. Además se ha mostrado que el método BLS tiene cierto grado de robustez cuando los puntos discrepantes tienen unas determinadas características. Por todos estos motivos se presenta la necesidad de desarrollar un protocolo para la obtención de la mejor recta de regresión cuando en el conjunto de datos inicial hay algún punto sospechoso de ser discrepante. En la sección 6.4.2 se presenta el artículo titulado: “Linear regression taking into account errors in both axes in presence of outliers”, enviado para su publicación en la revista Analytical Letters. En este artículo se dan una serie de pautas para obtener la recta de regresión correcta, a partir de los datos experimentales obtenidos. En cada caso se explica cuál de las técnicas desarrolladas en los apartados anteriores debe utilizarse. En el proceso de búsqueda de la recta de regresión correcta cuando se tienen en cuenta los errores cometidos en las dos variables, surge la necesidad de hacer un análisis previo de los datos. Por este motivo, en el artículo citado se introduce una nueva técnica, necesaria para el estudio de los puntos discrepantes, que es el gráfico de residuales ponderados. Este método gráfico se ha adaptado a la situación en que se tienen en cuenta los errores cometidos en las variables predictora y respuesta, de manera que pueda utilizarse como etapa previa al cálculo de la recta de regresión. 217 6. Regresión lineal en presencia de puntos discrepantes 6.4.2 Linear regression taking into account errors in both axes in presence of outliers Analytical Letters. Enviado para publicación F. Javier del Río*, Jordi Riu, F.Xavier Rius Department of Analytical and Organic Chemistry. Universitat Rovira i Virgili. Pl. Imperial Tarraco, 1. 43005-Tarragona. Spain. This paper presents guidelines for obtaining the correct regression line by taking into account the errors in both axes when there are outliers in the data set. We have adapted the weighted residual plots to take into account the experimental errors in both axes, and we have combined it with robust regression methods and methods for detecting outliers. The protocol has been checked with real data sets from the literature to show how it can be used to find the best regression line when there are outliers in the data set. In all cases the errors in both axes are taken into account. Keywords: Outliers; linear regression; errors in both axes; robust regression; weighted residual plot 218 6.4.2 Analytical Letters, enviado 1. INTRODUCTION Linear regression is widely used in analytical chemistry, for example in calibration stages and when comparing two analytical methods at several concentrations (1). To find the coefficients of the regression straight line, the ordinary least squares (OLS) method is normally used. The disadvantage of this method is that it considers the predictor variable (the x variable, which is normally the concentration in calibration stages or the reference method in method comparison studies) to be error free and only allows constant random errors in the response variable (the y variable, which is normally the instrumental response in calibration stages or the method being tested in method comparison studies). An improvement on OLS is the weighted least squares method (WLS). This allows non-constant random errors in the response variable, but still considers the predictor variable to be error-free. Sometimes the errors in the response variable should not be neglected; for example in method comparison studies, where the two methods normally have errors of the same order of magnitude, or in calibration stages when certified reference materials (CRM) are used, each with uncertainties in the concentration of the analyte of interest. In such cases, one should use regression methods that take into account the errors in both axes, like the bivariate least square (BLS) method (2,3), which calculates the coefficients of the straight line by taking into account the individual heteroscedastic random errors in both axes. When the straight line is found by any of the regression methods, the results, due to the presence of one or more outlying points in the experimental data set, may be biased. This may cause a shift in the regression coefficients or a high experimental error associated to the regression line (which also increases the variances in the regression coefficients (4)). These effects may significantly affect further statistical tests over the regression coefficients leading to incorrect results. These problems can be overcome with techniques for detecting outliers or with robust regression methods. In the literature there are several methods of detecting outliers (e.g. Cook’s test (5)) or robust regression techniques (e.g. the least median of squares, LMS (6,7)). These deal with regression by considering only errors in the response variable. Other robust regression methods consider errors in both axes 219 6. Regresión lineal en presencia de puntos discrepantes under some restrictions (8,9). In the last few months, however a robust regression technique (10) and a graphical criterion for detecting outliers (11) have been developed. Both are based on the BLS method and therefore take into account the individual experimental errors in both axes. Several authors recommended using robust regression techniques rather than tests for detecting outliers (12-15) because with such tests, points with a great deal of information may be deleted. However, robust regression techniques also have their limitations. These derive from the difficulty in finding the variances associated to the regression coefficients (and hence the difficulty in deriving statistical tests based on the robust regression line). For this reason, in this paper we present guidelines for finding the correct regression line when there are one or more outliers in the data set in a regression procedure that should take into account errors in both axes. We have also used the plot of the weighted residuals taking into account the errors in both axes, and we have combined this with the robust regression technique and graphical criterion for detecting outliers to find the correct regression line. We have applied these guidelines to several real data sets from the literature that illustrate situations that analysts may find in their laboratory work. 2. BACKGROUND AND THEORY 2.1.- Bivariate Least Squares Of the regression techniques that consider errors in both axes (3), bivariate least squares (BLS) more readily provides the regression coefficients, as well as their associated variances and covariances. The BLS regression method relates the observed variables xi and yi as follows: yi = b0 + b1 xi + ei 220 (1) 6.4.2 Analytical Letters, enviado where ei is the observed ith residual error. The BLS regression method finds the estimates of the regression line coefficients by minimising the sum of the weighted residuals, S, expressed in eq. 2: S= n ∑ i =1 ( yi − yˆ i ) 2 = ( n − 2) s 2 wi (2) where n is the number of experimental data pairs, ŷi is the prediction of the experimental variable yi, s2 is the estimate of the experimental error and wi is the weighting factor that corresponds to the variance of the ith-residual: wi = s e2i = s 2yi + b12 s x2i − 2b1 cov( xi y i ) (3) where s x2i and s 2yi are, respectively, the experimental variances of the ith point for the predictor and response variables of the straight line expressed in eq. 1, and cov(xi yi) is the covariance between the predictor and the response variable in the ith point, which is normally set at zero. Since BLS takes into account the errors in both axes and, through the weighting factor, attaches greater importance to the points with small variance (i.e. the regression line fits them closer), it may be considered to have a certain degree of robustness. However, BLS may not obtain the correct regression line when the data set contains outliers with small variances or when they are outside the calibration interval. 2.2.- Detection of Outliers A graphical criterion for detecting outliers and influential points and taking into account the errors in both axes was developed by del Río et al. (11). This compares two joint confidence intervals associated to the regression coefficients: one that corresponds to the regression coefficients of the regression line of the overall data set and one that corresponds to the regression coefficients of the regression line without the suspected point(s). The comparison is made to find 221 6. Regresión lineal en presencia de puntos discrepantes out whether the suspected point(s) have a strong effect on the regression straight line. When comparing the confidence intervals (both of which are elliptical) two important aspects needs to be checked: whether the areas of the ellipses are similar (which would imply that the variances of the regression coefficients were the same size), and how close the centres of the ellipses are to each other (which indicates the coincidence of the regression coefficients of the straight lines). The criterion for deciding whether one or more data pairs are considered as outliers is whether the coincidence (expressed in percentage of area) between the ellipses is less than 66.67%. 2.3.- Bivariate Least Median Squares (BLMS) An alternative techniques for detecting outlying points are robust regression methods. Following the same strategy as when considering only errors in the response variable (i.e. the least median of squares method, LMS (7)), the BLMS robust technique (10) obtains a robust straight line by taking into account the individual experimental errors in both axes. In this method an iterative process is performed with the Monte Carlo simulation method (16) to obtain the BLMS straight line as the best line of a group of robust straight lines generated by taking into account the errors in both axes. In further calculations in this paper, 100 iterations were chosen for the Monte Carlo simulation stage to attain the BLMS robust regression line (i.e. m=100). Depending on how the regression line will be used, the BLMS method may have disadvantages because information about the variances of the regression coefficients is difficult to find and is usually non exact (so future statistical tests associated to the regression coefficients may be difficult to find or inexact). This loss of information is due to the method’s algorithm, which uses only two points to find the final straight line. With LMS the variances and covariances of both the intercept and the slope may be estimated using a complicated algorithm (7), but their values are not exact in any case. It is normal to suppose that BLMS has a similar problem because the straight line is also obtained with only two points and the BLS method is also a least squares method. 222 6.4.2 Analytical Letters, enviado 2.4.- Weighted Residual Plots The graphical analysis of residuals obtained by taking into account the errors in both axes may help the analyst to decide which is the correct regression line to use. This plots the weighted residuals (ei, eq. 1) against the experimental value of the predictor or response variable. The advise and warning levels are fixed, respectively at distances equal to two and three times the standard deviation of the weighted residuals ( se ) above and below the mean. Many problems can be detected by analysing the shape of the points. When there are outliers in a data set, an abnormal situation is usually detected when the weighted residual plot is used on the BLS straight line. Usually, however, we cannot deduce which points in the initial data set are the outliers. This is because the BLS straight line fits the points with the lowest variances more closely. In this way, two situations may be especially important. First, if the outliers have small variances, their weighted residuals will also be small because the straight line is close to this point. Second, if the outliers have large variances, their weighted residuals will probably be small because their values are divided by the weighting factor (proportional to the variances). The main advantage of the weighted residual plot that takes into account the errors in both axes appears when it is used on a robust straight line (e.g. with BLMS), where the point with the largest weighted residual has the greatest probability of being an outlier. This is because the robust regression method obtains the straight line without considering the outliers, and these will probably be away from the regression line (although their variances are small). If any weighted residual is greater than the advise level of the weighted residual plot using BLMS regression, the point is suspected as being an outlier. However, if any weighted residual is higher than the warning level of the weighted residual plot, this point should usually be considered to be an outlier. This interpretation is similar to when the straight line is obtained using OLS. A data set in which the points fit the straight line well will show a pattern in which the points are equally and randomly distributed up and down the mean, as in Figure 1a. A U-shaped weighted residuals 223 6. Regresión lineal en presencia de puntos discrepantes plot results from fitting a straight line to a data set that would be better fitted by a curve (Figure 1b). Figure 1c plots a data set in which the weighted residuals vary according to the predictor variable. This technique should only be used as a preliminary criterion for ascertaining whether there is a suspected point in the data. +3se +3se a) +2se +2se Mean Mean -2se -2se -3se -3se +3se b) c) +2se Mean -2se -3se Figure 1 Three examples of residual patterns, in which the weighted residuals that take into account the errors in both axes are plotted against the predictor or response variable: a) the experimental points have a good fit to the straight line, b) the experimental points do not fit to a straight line and c) the weighted residuals vary according to the predictor variable. 2.5.- Protocol to Obtain the Correct Regression Line in the Presence of Outliers The first step is a preliminary visual study of the experimental data set in the plot of the predictor and responses variables. One can find a data pair in a data set far from the tendency of the other points, or a data pair with their experimental variances very different from the others. These data pairs are suspected outliers. If some suspected points in the data set have been detected by visual analysis, the next step is to use the weighted residual plot taking into account the errors in both axes over the robust regression line (BLMS). If there are no suspected points 224 6.4.2 Analytical Letters, enviado outside the advise and warning levels (the plot is equivalent to those that fit the straight line well, as we can see in Figures 1a and 1c), the BLS regression line should be used as the best straight line INITIAL DATA SET Visual No suspected BLS CORRECT analysis for points REGRESSION LINE suspected points Suspected points Weighted residual plot over BLMS No suspected points Suspected points No statistical tests FUTURE USE BLMS CORRECT REGRESSION LINE Statistical tests (i.e. prediction, checking bias ...) Outliers detection No Outliers BLS CORRECT REGRESSION LINE Outliers REMOVE OUTLIERS Figure 2 Protocol for finding the correct regression line. If the user detects potential outliers with the weighted residual plot (or data pairs near the limit are suspected outliers), there are two possible solutions, depending on how the straight line will be used in future. If no information about the variances of the regression coefficients is needed, the robust regression line, which minimizes the effect of having outliers in the data set should be used. However, if information about the variances of the regression coefficients is 225 6. Regresión lineal en presencia de puntos discrepantes needed (e.g. for future tests over the straight line), the graphical criterion for detecting outliers together with the BLS regression method should be used. If after the graphical criterion has been used to detect outliers, some outlier must be deleted, the protocol should begin again to determine whether there are any others. After this protocol, the straight line is considered to be the best that can be obtained by taking into account the errors in both axes. These guidelines are summarized in Figure 2. 3. EXPERIMENTAL SECTION 3.1.- Data Sets The above protocol was applied to three real data sets to clarify how it can be used when some points are suspected as outliers in the data set. These data sets are concerned with method comparison studies using linear regression. 3.1.1.- Data sets 1 and 2 (17) These data sets were from the comparison of the analysis of organic compounds in two certified reference soils using a wet matrix (20% water) and a dry matrix, plotted on the x and y axis, respectively. The SRS 103-100 certified reference soil was analysed in the first data set (Figure 3a). The 15 organic compounds were analysed by microwave-assisted extraction (MAE) with six replicates of 5-g portions extracted simultaneously for 10 min at 115ºC from the reference material for each experimental point. The recoveries were obtained after six determinations of each sample, and ranged from 79.0 to 150%. The second data set (Figure 5a) was obtained from an equivalent comparison study that analysed 20 organic compounds in the certified reference material with lot number 321 from the Environmental Resource Associates (ERA). The number of replicates was six for the dry matrix and five for the wet matrix. All were extracted simultaneously for 10 minutes at 115ºC. The recoveries varied from 17.7 to 117%. 226 6.4.2 Analytical Letters, enviado 3.1.2.- Data set 3 (18) This data set was from the analysis, using a liquid chromatographic method (Figure 6a), of ten biogenic amines in fresh fish. The predictor and response variables were the recoveries for determining the ten biogenic amines using the standard addition procedure, in which two levels of addition were performed for each amine. The recoveries that used the smallest level of addition were assigned as the predictor variable and are plotted on the x axis, while recoveries that used the highest level are plotted on the y axis. The measurements are expressed in mg/kg and their values ranged from 14.54 to 320.67 mg/kg for the smallest level of addition and from 28.71 to 444.38 mg/kg for the highest level of addition. 3.2.- Results and Discussion 3.2.1.- Data set 1 Figure 3a shows a clearly suspected outlier. According to our proposed protocol, the first step is to use the weighted residual plot taking into account the errors in both axes over the BLMS robust straight line. This is shown in Figure 3b, which shows that the suspected point is clearly detected as an outlier. If future tests have to be used over the straight line, the next step should be to use the graphical criterion to detect outliers. Figure 3c shows the results of this graphical criterion. The coincidence between the ellipses is 27.54% when the α level of significance is 1%. As this coincidence is smaller than the proposed 66.67% limit, the suspected point should is considered to be an outlier. Once this point has been detected as an outlier, the next step is to use the BLS straight line without the outlier (Figure 4a). On the other hand, if information about the variances of the regression coefficients is not needed, the BLMS regression line should be used without the graphical criterion. 227 6. Regresión lineal en presencia de puntos discrepantes (a) 160 (b) 2 140 Residuals Wet matrix 1 120 0 -1 100 -2 80 60 100 Dry matrix 140 80 100 120 Recovery (%) 140 180 (c) Slope 1.2 1 0.8 -40 -20 0 Intercept 20 Figure 3 a) Regression line found using the BLS method for the first data set. The crosses on the experimental points are the associated errors (twice the standard deviations) in each axis b) weighted residual plot for the first data set and c) joint confidence interval for the intercept and the slope for the initial data set (solid line) and for the initial data set once the suspected points have been removed (dashed line). If the graphical criterion is used once the first outlier has been removed, we must check whether there is another outlier in the data set. This data set does not seem to have any other outlier (Figure 4a). However, we repeated the study to show the situation when there are no outliers. The weighted residual plot of the new data set (data set 1 without the previously detected outlier) is shown in Figure 4b. Although no outlier is detected using the weighted residual plot, there is one point whose weighted residual is almost detected as an outlier. This is why it is important to continue to consider whether this point is an outlier. To do this, we use the graphical criterion for detecting outliers. The result are shown in Figure 4c. The coincidence is 67.60% (α=1%), so we can conclude that this point is not an outlier. In any case, the difference between the coincidence and the proposed limit is so small that these conclusions may be different if a different level of significance is chosen. If this point is finally considered not to be an outlier, the BLS straight line (Figure 4a) should be used. 228 6.4.2 Analytical Letters, enviado (a) 160 (b) 0.4 0.2 Residuals Wet matrix 140 120 0 -0.2 100 -0.4 80 80 60 100 1.15 Dry matrix 140 160 100 120 Recovery (%) 140 180 (c) 1.1 Slope 1.05 1 0.95 0.9 -20 -10 Intercept 0 10 Figure 4 a) Regression line found using the BLS method for the first data set without the previously detected outlier. The crosses on the experimental points are the associated errors (twice the standard deviations) in each axis b) weighted residual plot for this data set and c) comparison of the two joint confidence intervals for the slope and the intercept using the overall data set (solid line) and the same data without the suspected point (third point of the data set, dashed line). 3.2.2.- Data set 2 This data set (Figure 5a) appears similar to the previous one. However, there is a big difference: the variances of the suspected outlier are higher than those in the first data set. If we look at the weighted residual plot over the BLMS robust regression line (Figure 5b), we can see that no points are suspected outliers. This is due to the high variances of the initially suspected point. However, if it were considered as an outlier, its influence on the BLS straight line would be minimum. We ought to conclude that the BLS straight line (Figure 5a) should be used. To show that this is correct we have plotted the result of using the graphical criterion for detecting outliers when the most suspected point in the data set is deleted (Figure 5c). We can see that the ellipses are practically identical, and that the coincidence is 93.92% when the significance level is 1%. 229 6. Regresión lineal en presencia de puntos discrepantes (a) 2 120 (b) Residuals Wet matrix 1 80 0 -1 40 -2 0 0 40 80 Dry matrix 20 40 60 80 Recovery (%) 100 120 120 (c) 1.4 Slope 1.3 1.2 1.1 -25 -20 -15 -10 Intercept -5 0 Figure 5 a) Regression line found using the BLS method for the second data set. The crosses on the experimental points are the associated errors (twice the standard deviations) in each axis b) weighted residual plot for the second data set and c) result of the comparison of the two joint confidence intervals for the slope and the intercept using the overall data set (solid line) and the same data without the suspected point (dashed line). 3.2.3.- Data set 3 This data set (Figure 6a) also presents a suspected point, but now the number of points is clearly smaller than in the other two data sets. After the weighted residual plot has been applied over the BLMS robust straight line (Figure 6b), we can see that there is one point near the advise level. This must be studied carefully. Figure 6c shows the plot of the graphical criterion detecting outliers, which must be applied if further statistical test are to be done over the regression line. The coincidence is 28.48% when the α level of significance is 1%. In this case the suspected point should be deleted because it is considered as an outlier (its coincidence is clearly smaller than the fixed limit of 66.67%). If we had used the graphical criterion, the next step would be to make sure that no more outliers were present in the data set. This study is not shown, but the data set was found to have 230 6.4.2 Analytical Letters, enviado only one outlier. In conclusion, the BLS straight line (after deleting the detected outlier) or the BLMS straight line (Figure 6d) can be used in this case, depending on how the straight line will be used in the future. 500 (a) 15 400 (b) 10 5 Residuals Highest level 300 200 0 -5 100 -10 0 -15 0 100 200 Smallest level 300 100 200 Recovery (mg/kg) 300 400 500 (d) 400 (c) 1.5 300 Highest level Slope 0 1.4 200 100 1.3 0 -10 0 10 Intercept 20 0 100 200 Smallest level 300 Figure 6 a) Regression line found using the BLS method for the third data set. The crosses on the experimental points are the associated errors (twice the standard deviations) in each axis b) weighted residual plot for the third data set c) comparison of the two joint confidence intervals for the slope and the intercept using the overall data set (solid line) and the same data without the suspected point (first point of the data set, dashed line) and d) regression line found using the robust regression method (BLMS) for the third data set after 100 iterations of Monte Carlo. 4. CONCLUSIONS In this paper we have presented guidelines for obtaining the correct regression line when taking into account the errors in both axes and when there may be outlying points in the experimental data set. Several situations that may be found in real data analysis are discussed by applying the protocol to three real data sets from the literature. In all cases, the best regression straight line has been found. 231 6. Regresión lineal en presencia de puntos discrepantes In obtaining the best straight line, we have explained the weighted residual plot, which takes into account the errors in both axes. Since no tests are involved, some experience may be needed to interpret the plots. We have explained how to interpret these plots when the BLS and the BLMS robust regression lines are used, although their main use is with the BLMS robust regression line. In order for it to work in the presence of points that are suspected outliers, we propose the BLMS robust straight line and a graphical criterion for detecting outliers. Experimental points with extremely small variances in the data set must be carefully studied, because they tend to be considered outliers if they are not very close to the regression line. If these extremely small variances are due to an accurate analysis, they should not be considered as outliers, and the BLS straight line should be used. If they are due, for instance, to errors in measurement, a small number of replicates, or a measurement near the detection limit, these points should be considered as outliers and should be deleted from the data set. 5. ACKNOWLEDGEMENTS The authors would like to thank the DGICyT (project num. BQU20001256) for financial support. 6. REFERENCES 1.- Riu, J.; Rius, F.X. Univariate regression models with errors in both axes. J. Chemom. 1995, 9, 343-362. 2.- Lisý, J.M.; Cholvadová, A.; Kutej, J. Multiple straight-line least-squares analysis with uncertainties in all variables. Computers Chem. 1990, 14, 189192. 3.- Riu, J.; Rius, F.X. Assessing the accuracy of analytical methods using linear regression with errors in both axes. Anal. Chem. 1996, 68, 1851-1857. 4.- Weisberg, S. Applied linear regression, 2nd Ed.; John Willey & Sons: Toronto, 1985, 114-118. 232 6.4.2 Analytical Letters, enviado 5.- Cook, R.D. Detection of Influential Observation in Linear Regression. Technometrics 1977, 19, 15-18. 6.- Massart, D.L.; Vandeginste, B.G.M.; Buydens, L.M.C.; de Jong, S.; Lewis, P.J.; Smeyers-Verbeke, J. Handbook of Chemometrics and Qualimetrics: Part A, Elsevier: Amsterdam, 1997, 339-377. 7.- Rousseeuw, P.J.; Leroy, A.M. Robust regression & outlier detection, Willey: New York, 1987, 1-18, 112-143. 8.- Hartmann, C.; Vankeerberghen, P.; Smeyers-Verbeke, J.; Massart, D.L. Robust orthogonal regression for the outlier detection when comparing two series of measurement results. Anal. Chim. Acta 1997, 344, 17-28. 9.- Brown, M.L. Robust line equation with errors in both variables. Journal of the American Statistical Association 1982, 377, 71-79. 10.- del Río, F.J.; Riu, J.; Rius, F.X. Robust Linear Regression Taking into Account Errors in Both Axes. Submitted for publication 11.- del Río, F.J.; Riu, J.; Rius, F.X. A Graphical Criterion for the Detection of Outliers in Linear Regression Taking into Account Errors in Both Axes. Analytica Chimica Acta. In Press 12.- Cheng, C.L.; Van Ness, J.W. Robust Calibration. Technometrics 1997, 39, 401-411. 13.- Cummings, D.J.; Andrews, C.W. Iteratively Reweighted partial Least Squares: a Performance Analysis by Monte Carlo Simulation. Journal of Chemometrics 1995, 9, 489-507. 14.- Hampel, F.R.; Ronchetti, E.M.; Rousseeuw, P.J.; Stahel, W.A. Robust Statistics: the Approach Based on Influence Functions, John Willey & Sons: New York, 1986. 15.- Huber, P.J. Robust Statistics, John Willey & Sons: New York, 1981. 16.- Meier, P.C.; Zünd, R.E. Statistical Methods in Analytical Chemistry, John Wiley & Sons: New York, 1993, 145-50. 17.- Lopez-Avila, V.; Young, R.; Beckert, W.F. Microwave-assisted extraction of organic compounds from standard reference soils and sediments. Anal. Chem. 1994, 29, 1097-1106. 18.- Veciana, M.T.; Hernández, T.; Marine, A.; Vidal, M.C. Liquid Chromatographic Method for Determination of Biogenic Amines in Fish and Fish Products. Journal Of AOAC International 1995, 78, 1045-1050. 233 6. Regresión lineal en presencia de puntos discrepantes 6.5 Conclusiones En este capítulo se han desarrollado una nueva técnica para la detección de puntos discrepantes y un método de regresión robusta donde se consideran los errores experimentales cometidos en las variables predictora y respuesta. En el apartado 6.2.2 se presenta una técnica para la detección de puntos discrepantes. Se trata de un criterio gráfico que compara las rectas de regresión obtenidas antes y después de eliminar del conjunto de datos inicial los puntos sospechosos de ser discrepantes. Para ello considera las incertidumbres asociadas a la ordenada en el origen y la pendiente de las dos rectas de regresión (la obtenida a partir del conjunto de datos inicial y a partir del mismo conjunto de datos sin los puntos sospechosos de ser discrepantes). Mediante la utilización del criterio gráfico para la detección de puntos discrepantes, presentado en la sección 6.2.2, se garantiza que cuando un punto se considera discrepante es porque éste afecta, no solo a los coeficientes de regresión, sino también a sus varianzas y covarianzas asociadas, tal como se concluye de la sección 6.2.3. Además se ha comprobado que la sensibilidad del criterio gráfico supera la que ofrecen técnicas de detección de puntos discrepantes clásicas como el test de Cook, pues permite detectar puntos discrepantes que utilizando el test de Cook no se detectan. También se observa que la sensibilidad del criterio gráfico aumenta cuando disminuye la varianza experimental de los puntos sospechosos de ser discrepantes. Por este motivo hay que tener un especial cuidado al tratar puntos con varianzas experimentales extremadamente pequeñas, intentando conocer el motivo de estas varianzas. Así, por ejemplo, unas varianzas extremadamente pequeñas debidas a un exhaustivo proceso de análisis o a un elevado número de réplicas, hacen pensar que el punto no debe considerarse discrepante debido a la gran cantidad de información que contiene. Sin embargo, si estas varianzas extremadamente pequeñas se deben a un análisis con pocas réplicas, a un análisis cercano al límite de detección, o a algún error en la transcripción de los resultados, el punto deberá considerarse discrepante. 234 6.5 Conclusiones En el apartado 6.3.2 se ha presentado el método de regresión robusta de BLMS. Este método robusto está basado en el de LMS desarrollado por Rousseeuw y Leroy, adaptado para la situación en que se consideran los errores cometidos en las dos variables. Para ello se introduce un factor de ponderación que depende de las varianzas experimentales en cada una de las variables. Se ha utilizado un proceso iterativo mediante el método de Monte Carlo para generalizar la metodología y encontrar una mejor recta de regresión robusta, de manera que se evite la necesidad de que la recta de regresión robusta resultante pase exactamente por dos puntos del conjunto de datos inicial. Esta técnica de regresión se ha validado y probado sobre una serie de conjuntos tanto reales como simulados donde se sospecha de la presencia de puntos discrepantes. Se observa en todos ellos como la recta de regresión ajusta a la mayor parte de puntos dando menor importancia a los puntos discrepantes. La utilización del método de regresión de BLMS tiene asociada una serie de inconvenientes. Entre ellos cabe destacar el aumento de la complejidad en el algoritmo de cálculo de la recta de regresión, con respecto a la recta BLS, y la dificultad (si no imposibilidad) de conocer las varianzas asociadas a los coeficientes de regresión de la recta de regresión robusta (lo que impide la utilización de tests sobre los coeficientes de la recta de regresión robusta). En este capítulo se ha propuesto, además, una nueva técnica para el estudio de los datos, previa a la obtención de la recta de regresión. Se trata de una generalización del gráfico de residuales ponderados al caso en que se consideran los errores individuales cometidos en las variables predictora y respuesta. En el apartado 6.4.2 se explica su funcionamiento, tanto sobre la recta de regresión robusta (BLMS) como sobre la recta BLS. Una vez presentada esta nueva técnica, en el mismo apartado se propone un protocolo de actuación en el caso de tener puntos discrepantes en el conjunto de datos. Para ello se han utilizado una serie de casos reales extraídos de la bibliografía que representan cada uno de los supuestos realizados en el protocolo. En cada caso se ha obtenido la mejor de las rectas de regresión que se puede conseguir a partir de los datos experimentales y teniendo en cuenta los errores cometidos en las dos variables. 235 6. Regresión lineal en presencia de puntos discrepantes El principal problema presentado a lo largo de este capítulo se corresponde con la situación en que el conjunto de datos contiene puntos con varianzas experimentales extremadamente pequeñas. Estos puntos son los que incluyen una mayor información en regresión lineal considerando los errores cometidos en las dos variables. El problema de estos puntos es que los tests y técnicas desarrollados tienden fácilmente a considerarlos como puntos discrepantes cuando en realidad pueden no serlo (únicamente si se encuentran muy próximos a la recta de regresión no serán considerados como puntos discrepantes). Por este motivo, el analista deberá tener un especial cuidado con este tipo de observaciones, debiendo analizar en profundidad la causa de estas varianzas experimentales extremadamente pequeñas. Así, por ejemplo, si se concluye que dichas varianzas se deben a un minucioso proceso de análisis, a múltiples réplicas o a análisis a concentraciones pequeñas, estos puntos no deben considerarse discrepantes. Sin embargo, si el origen de que las varianzas sean extremadamente pequeñas es un análisis cerca del límite de detección, errores en el proceso de medida, análisis con un número de réplicas muy bajo, o errores de transcripción en cualquier momento del proceso, estos puntos deberán considerarse puntos discrepantes. 6.6 Referencias 1.- P.J. Rousseeuw, A.M. Leroy, Robust Regression & Outlier Detection, John Willey & Sons, New York (1987). 2.- R.D. Cook, Technometrics, 19 (1977) 15-18. 3.- F.X. Rius, J. Smeyers-Verbeke, D.L. Massart, Trends in Analytical Chemistry, 8 (1989) 8-11. 4.- D.L. Massart, B.G.M. Vandeginste, L.M.C. Buydens, S. de Jong, P.J. Lewi, J. Smeyers-Verbeke, Handbook of Chemometrics and Qualimetrics: Part A, Elsevier, Amsterdam (1997). 5.- S. Weisberg, Applied Linear Regression, 2nd Ed., John Wiley & Sons, New York (1985). 6.- J. Riu, F.X. Rius, Analytical Chemistry, 68 (1996) 1851-1857. 7.- M.T. Veciana, T. Hernández, A. Marine, M.C. Vidal, Journal Of AOAC International, 78 (1995) 1045-1050. 8.- C.J. Gamski, G.R. Howes, J.W. Taylor, Anal. Chem., 66 (1994) 1015-1020. 236 6.6 Referencias 9.- C.L.Cheng, J.W. Van Ness, Technometrics, 39 (1997) 401-411. 10.- D.J. Cummings, C.W. Andrews, Journal of Chemometrics, 9 (1995) 489-507. 11.- F.R. Hampel, E.M. Ronchetti, P.J. Rousseeuw, W.A. Stahel, Robust Statistics, John Willey & Sons, New York (1986). 12.- P.J. Huber, Robust Statistics, John Willey & Sons, New York (1981). 13.- P.J. Rousseeuw, J. Am. Stat. Assoc., 79 (1984) 871-880. 14.- I.E. Frank, R. Todeschini, The Data Analysis Handbook, Elsevier, Amsterdam (1994). 15.- P.C. Meier, R.E. Zünd, Statistical Methods in Analytical Chemistry, John Wiley & Sons, New York (1993). 16.- O. Güell, J.A. Holcombe, Analytical Chemistry, John Wiley & Sons, New York (1993). 17.- H.A. Meyer (editor), Symposium on Monte Carlo Methods, Willey, Chichester, New York, 1956. 18.- B.D. Ripley, M. Thompson, Analyst, 112 (1987) 377-383. 237 7 Capítulo Conclusiones 7.1 Conclusiones 7.1 Conclusiones A lo largo de la presente Tesis Doctoral se han presentado varias aportaciones a la regresión lineal considerando los errores cometidos en las dos variables, y concretamente sobre el método de regresión de BLS. De esta forma, se consigue aumentar la aplicabilidad de este método de regresión en el campo de la química analítica. Una de las principales conclusiones que se extraen de la utilización de estas técnicas sobre el método de BLS, es la necesidad de conocer los errores experimentales asociados a cada punto experimental. El proceso seguido para encontrar una buena estimación de estos errores suele añadir laboriosidad al proceso de análisis de las dos variables (si bien hay muchos casos en que el error experimental en las dos variables se obtiene directamente del análisis), ya que una buena estimación de estos errores se suele basar en un aumento del número de réplicas. A continuación se presentan las conclusiones que se extraen de analizar esta Tesis a partir de los objetivos propuestos en la sección 1.1: 1.- Estudio y caracterización de las distribuciones de los coeficientes de regresión (ordenada en el origen y pendiente) encontrados mediante el método BLS con el fin de conocer qué tipo de tests estadísticos derivados se deben aplicar en el campo de la química analítica. Se ha conseguido concluir que los coeficientes de regresión de BLS siguen una distribución que difiere estadísticamente de la distribución normal. Sin embargo esta diferencia se ha comprobado que es suficientemente pequeña, de manera que el error que se comete al utilizar la hipótesis de normalidad en los coeficientes de regresión puede considerarse despreciable. Este error se ha comparado con el cometido al utilizar los métodos de regresión que consideran los errores cometidos únicamente en la variable respuesta (es decir OLS y WLS) llegándose a la conclusión de que, a pesar de cometer un error debido a la asunción errónea de normalidad en las distribuciones de los coeficientes de regresión de 241 7. Conclusiones BLS, se produce una sustancial mejora en la determinación de los coeficientes de regresión. 2.- Desarrollo de las expresiones para el cálculo de las varianzas asociadas a la predicción tanto de la variable predictora como de la variable respuesta utilizando los errores cometidos en ambas variables. Se han desarrollado las expresiones para el cálculo de la varianza asociada a la predicción de la variable respuesta a partir de una valor dado de la variable predictora y viceversa, cuando se consideran los errores en las dos variables. La validación de las mismas se ha llevado a cabo a partir de una comparación interna y utilizando la simulación de la predicción sobre varios conjuntos de datos reales extraídos de la bibliografía. Estas expresiones se han utilizado para representar los intervalos de predicción tanto de la variable respuesta como de la variable predictora. A su vez, estos intervalos de predicción han permitido comprobar la invariabilidad del método de BLS ante un intercambio de ejes. Esta afirmación es muy importante pues permite concluir que es indiferente cual de las variables sea considerada como variable predictora y cual como variable respuesta. Un ejemplo donde este efecto es importante es la comparación de métodos analíticos en la que debería ser indiferente la ubicación de los resultados de utilizar cada uno de los dos métodos pues sus errores experimentales son generalmente del mismo orden de magnitud. 3.- Cálculo del límite de detección de una metodología analítica en que la recta de calibración se construye mediante el método de BLS. Se han desarrollado las expresiones para el cálculo del límite de detección en regresión lineal considerando los errores cometidos en las variables predictora y respuesta. Para ello se han utilizado los intervalos de predicción del capítulo anterior, sobre los que se añade el modelado de los errores de las dos variables, con el fin de subsanar la limitación de no conocer el intervalo de predicción en aquellos valores de la concentración de los que no se dispone de valores experimentales. Si bien el límite de detección se ha utilizado, básicamente, sobre casos de calibración, en otros campos de la ciencia hay otras aplicaciones en que su utilidad 242 7.1 Conclusiones está fuera de dudas y en las cuales deben considerarse los errores en las dos variables. En todos estos casos se puede calcular el límite de detección sin variar las expresiones presentadas en el capítulo 5. 4.- Establecer el procedimiento que se ha de seguir ante la posible presencia de puntos discrepantes en una recta de regresión considerando los errores en las variables predictora y respuesta, desarrollando para ello un método de regresión robusto y un criterio gráfico para la detección de puntos discrepantes. Con el fin de tratar los posibles puntos discrepantes que contiene un conjunto de datos a la hora de hacer una regresión lineal considerando los errores cometidos en las dos variables, se han desarrollado una serie de técnicas de detección y tratamiento de los mismos. Estas técnicas son: • Un criterio gráfico para la detección de puntos discrepantes basado en la comparación de las dos elipses de confianza conjunta de los coeficientes de regresión, de las rectas obtenidas a partir del conjunto de datos inicial con y sin los puntos sospechosos de ser discrepantes. Este criterio gráfico se ha probado sobre varios conjuntos de datos reales extraídos de la bibliografía, verificándose la bondad de sus resultados. Su principal aportación es que considera las varianzas y covarianzas asociadas a los coeficientes de regresión, con lo que se puede considerar como punto discrepante uno que varíe significativamente las varianzas de los coeficientes de regresión aunque no lo haga sobre el valor medio de los coeficientes de regresión. • Un método de regresión robusta (BLMS) que considera los errores experimentales individuales cometidos en las dos variables. Este método de regresión se ha probado sobre una serie de conjuntos de datos reales y simulados, y se ha comprobado su robustez mediante el cálculo del punto de ruptura (breakdown point). • Una generalización del gráfico de residuales al caso en que se consideran los errores en las variables predictora y respuesta, explicando su aplicación sobre la recta de regresión robusta (BLMS) y sobre la recta BLS. Este gráfico de residuales ponderados se utiliza como una técnica de estudio previo de los datos, antes de utilizar las técnicas descritas anteriormente. 243 7. Conclusiones Como última aportación de este apartado, se ha propuesto un protocolo de actuación en presencia de puntos discrepantes. Este protocolo se ha probado sobre una serie de conjuntos de datos reales del campo de la química analítica, sobre los que se ha encontrado la mejor recta de regresión, con los datos experimentales disponibles, teniendo en cuenta los errores en las variables predictora y respuesta y la posible presencia de puntos discrepantes. 7.2 Perspectivas futuras Una vez presentados los resultados y las conclusiones, se introducen una serie de temas sobre los que se podría profundizar, o incluso nuevas líneas de investigación que quedan abiertas. A continuación se citan algunas de ellas: • Cálculo de los límites de cuantificación en regresión lineal considerando los errores cometidos en la concentración, lo que supondría una ampliación en el campo del cálculo de los límites de detección. • Desarrollar las expresiones para el cálculo de las varianzas de los coeficientes de regresión de la recta obtenida a partir el método BLMS, y estudiar la distribución que tienen asociada dichos coeficientes. De esta forma se solventaría la limitación descrita a lo largo de la Tesis Doctoral derivada de la dificultad (o en muchos casos imposibilidad) de realizar tests tanto individuales como conjuntos sobre los coeficientes de regresión de la recta de regresión robusta. • Desarrollo del uso del criterio gráfico para la detección de puntos discrepantes, propuesto en el capítulo sexto de esta Tesis Doctoral, en el caso en que se utilizan otros métodos de regresión tales como OLS, WLS o CVR, por ejemplo. Este desarrollo tiene una gran importancia pues utilizando estos métodos de regresión no existe ningún criterio de detección de puntos discrepantes que utilice la información derivada de las varianzas y covarianzas de la recta de regresión. Una segunda aplicación de este criterio gráfico es la comparación de dos rectas, donde se quieran tener en cuenta las varianzas y covarianzas de los coeficientes de regresión, habiéndose encontrado dichas 244 7.2 Perspectivas futuras rectas de regresión a partir de cualquiera de los métodos propuestos a lo largo de esta Tesis Doctoral (OLS, WLS, BLS, etc.). • Estudio de la regresión no lineal considerando los errores en las variables predictora y respuesta. En este campo se deberían desarrollar los intervalos de predicción, los límites de detección y el tratamiento de puntos discrepantes entre otras aplicaciones. • Mejora del algoritmo del método BLS en su extensión al campo multivariante, en el método de mínimos cuadrados multivariantes (multivariate least squares, MLS), que considera los errores cometidos en todas las variables, con el fin de asegurar la obtención de un mínimo global en el cálculo del hiperplano de regresión. Sobre dicho hiperplano de regresión se deberían desarrollar los intervalos de predicción, los límites de detección y la detección de puntos discrepantes, de igual forma a como se ha llevado a cabo en esta Tesis Doctoral en el campo de la regresión lineal univariante con errores en las dos variables. Otra de las actuaciones que quedan abiertas es el desarrollo y divulgación de un programario donde se incluyan las aplicaciones y tests que se han presentado a lo largo de la presente Tesis Doctoral. 245 8 Capítulo Anexos 8.1 Anexo 1. Comparación de los métodos OLS, WLS y BLS 8.1 Anexo 1. Comparación de los métodos OLS, WLS y BLS 8.1.1 Comparación de las rectas de regresión obtenidas con los métodos OLS, WLS y BLS Tal como se ha explicado a lo largo de la presente Tesis Doctoral, la recta obtenida mediante el método de OLS minimiza los residuales de todos los puntos experimentales respecto a la recta, pero no tiene en cuenta los errores experimentales individuales asociados a la variable predictora ni los errores experimentales individuales asociados a la variable respuesta. Por otro lado, la recta obtenida a partir del método de WLS considera los errores individuales asociados a la variable respuesta, aunque sigue sin considerar los errores asociados a la variable predictora, y otorga un mayor peso en la regresión a los puntos experimentales cuyo error en la variable respuesta es menor, con lo que la recta WLS tenderá a acercarse más a estos puntos, independientemente de cómo sean los errores en la variable predictora. El método BLS, por el hecho de considerar los errores individuales en las variables predictora y respuesta, da una mayor importancia a aquellos puntos cuyas varianzas en ambas variables son menores. Un ejemplo de comparación de las rectas obtenidas a partir de los tres métodos descritos se encuentra en la figura 8.1, donde se representan los resultados de analizar la composición en seis elementos químicos de dos grupos diferentes de restos arqueológicos encontrados en Israel.1 En la figura se representan, además de los puntos experimentales (xi, yi), las desviaciones estándar asociadas a cada uno de ellos. Concretamente las líneas verticales y horizontales en cada punto experimental representan el doble de la desviación estándar en cada una de las dos variables. En la figura 2.4 se observa que en la recta obtenida mediante el método de OLS todos los puntos experimentales tienen igual importancia. La recta WLS pondera en la variable respuesta, por lo que se ajustan mejor los puntos del inicio, cuyos errores asociados son menores. De entre los puntos más influyentes para la 249 8. Anexos recta WLS se destaca el tercer punto experimental (correspondiente al análisis del Sc) pues es el punto con menor error asociado a la variable respuesta. Sin embargo, al representar la recta BLS, y por el hecho de considerar los errores en las dos variables, el tercer punto experimental pierde importancia pues su error asociado a la variable predictora es grande en relación a los puntos experimentales que le rodean. También se observa como el último punto (correspondiente al análisis del Cr), que es el que tiene mayores errores asociados tanto a la variable respuesta como a la variable predictora, por lo que la recta BLS prácticamente no tiene en cuenta este punto a la hora de ajustar los puntos experimentales y de calcular los coeficientes de regresión, de igual forma que ocurría con el método de WLS, si bien por la estructura del resto del conjunto de datos la recta BLS se ajusta mejor a este punto que la recta WLS. Variable respuesta 160 BLS 120 OLS WLS 80 40 0 0 40 80 Variable predictora 120 Figura 8.1.- Comparación de las rectas de regresión de los métodos de OLS, WLS y BLS. Las líneas horizontales y verticales representan el doble de la desviación estándar experimental de cada punto. 8.1.2 Comparación de los métodos OLS, WLS y BLS Una de las principales características del método de BLS, es que engloba tanto a OLS como a WLS, es decir: al considerar las varianzas asociadas a la variable predictora nulas y las varianzas asociadas a la variable respuesta como 250 8.1 Anexo 1. Comparación de los métodos OLS, WLS y BLS constante, la expresión para el cálculo de la recta de regresión utilizando BLS coincide con la obtenida por el método de OLS, mientras que al considerar la heteroscedasticidad en la variable respuesta, la recta de BLS (incluyendo las varianzas de los coeficientes de regresión) coincide con la obtenida con el método de WLS. Para demostrar esta afirmación, a continuación se presenta la transformación de las expresiones de cálculo de la recta BLS en las utilizadas por WLS y OLS, al suponer, en primer lugar, varianzas nulas en la variable predictora y a continuación imponiendo que varianzas en la variable respuesta sean constantes. Para ello se parte de la ecuación para el cálculo de los coeficientes de regresión de la recta BLS (ecuaciones 2.33 y 2.34), ahora renombradas como 8.1 y 8.2 respectivamente, y de la definición del factor de ponderación (ecuación 2.31), ahora renombrada como 8.3: n i =1 n i =1 n ∑ 1 wi ∑ ∑ xi wi ∑ i =1 n i =1 2 n yi + 1 ei ∂ wi xi wi b0 i =1 wi 2 wi ∂b0 × = xi2 b1 n x y 1 e 2 ∂ w i i i + i wi 2 wi ∂b1 i =1 wi ∑ (8.1) ∑ R ⋅b = g wi = se2i = s 2yi + b12 s x2i − 2b1 cov( xi , yi ) (8.2) (8.3) Al considerar las varianzas en la variable predictora nulas, y suponiendo nula la covarianza entre las variables respuesta y predictora, la ecuación 8.3 queda de la siguiente forma: wi = s e2i = s y2i (8.4) Estas condiciones son las requeridas por el método WLS para obtener la recta de regresión. De la expresión 8.4 se observa que las derivadas parciales del factor de ponderación respecto a cada uno de los coeficientes de regresión son nulas. De esta forma, la ecuación 8.1 se ve reducida a la siguiente: 251 8. Anexos n i =n1 i =1 xi n yi b0 i =1 wi i = 2 × xi b1 n xi y i i =1 w wi i n 1 ∑w ∑w ∑ i =1 n i xi wi ∑ (8.5) ∑ ∑ i =1 Para encontrar los coeficientes de regresión se debe invertir la matriz R de la ecuación 8.2, tal como se observa en la ecuación 8.6: b = R −1 ⋅ g (8.6) Introduciendo la matriz invertida, los coeficientes de regresión se obtienen a partir de la siguiente ecuación: b0 b = 1 n ∑ i =1 n 1 xi2 wi − x 2 i ∑w ∑w i =1 i n xi i =1 i 2 n n 1 x 1 wi n ∑ ∑ i =1 i =1 xi2 − wi 2 i ∑ w ∑ w ∑ w i =1 i =1 i i n ∑ n xi ∑w i =1 − i =1 i n xi − i =1 wi n n ∑ i =1 n ∑ i =1 xi wi 2 n n 1 wi ∑ ∑ i =1 i =1 i − 1 wi xi2 − wi n xi ∑w i =1 i 2 n yi × i =1 wi (8.7) n xi y i i =1 wi 2 ∑ ∑ n xi ∑w i =1 i Multiplicando las dos matrices se obtiene: n ∑ i =1 n b0 b = 1 ∑ i =1 n ∑ i =1 xi2 ⋅ wi n ∑ i =1 n yi wi x xi − i =1 wi i =1 wi n xi n xi y i − ⋅ i =1 wi i =1 wi ∑ ∑ n xi2 − wi 1 ⋅ wi 1 ⋅ wi n ∑ ∑ i =1 2 i n ∑ n ∑ i =1 xi wi 2 − ∑ i =1 n ∑ i =1 2 + xi ⋅ wi ∑ i =1 yi ∑w i =1 i x xi − i =1 wi i =1 wi n 1 n xi y i ⋅ i =1 wi i =1 wi 2 2 1 ⋅ wi n ∑ ∑ n n 1 ⋅ wi 2 i n ∑ (8.8) ∑ n ∑ i =1 xi2 − wi n ∑ i =1 xi wi Agrupando los valores de la segunda matriz se obtienen las expresiones de la ordenada en el origen y la pendiente obtenidas mediante el método WLS: 252 8.1 Anexo 1. Comparación de los métodos OLS, WLS y BLS xi2 n i =1 b0 = n yi n ∑ i =1 i =1 i n ∑ 1 ⋅ wi 1 ⋅ wi n i =1 b1 = n n xi yi ∑ w ⋅∑ w − ∑ w ⋅∑ w n i =1 ∑ i =1 ∑ i =1 n ∑ i =1 i =1 i x − wi 2 i n ∑ i =1 n xi y i − wi 1 ⋅ wi ∑ i =1 i n ∑ i =1 x − wi 2 i n n ∑ i =1 xi wi ∑ i =1 xi wi xi ⋅ wi i (8.9) 2 xi y i wi (8.10) 2 que coinciden con las ecuaciones 2.18 y 2.19 que definen los coeficientes de regresión obtenidos mediante el método de WLS. En el caso de considerar homoscedasticidad en la variable respuesta (condiciones de trabajo del método OLS), la ecuación 8.4 se transforma en un valor constante (w) y, por tanto, las ecuaciones 8.9 y 8.10 se expresan de la siguiente forma: b0 = b1 = 1 w n ∑x ⋅ i =1 1 w 1 w 2 i n ∑ 1 w ∑y 1 1⋅ w i =1 ∑ 1 w i 1 w − i =1 n 1⋅ i =1 n 1 w n ∑ n ∑ i =1 n 1 1⋅ w i =1 ∑ n ∑ i =1 i =1 n 1 w n 1 i 1 xi2 − w xi y i − i =1 n ∑x ⋅ w∑ y ∑ n ∑ i =1 xi ⋅ i =1 1 x − w 2 i n i =1 (8.11) xi 1 w ∑ i i =1 2 n ∑x y i i =1 2 xi i (8.12) de donde se obtienen las expresiones de la ordenada en el origen y la pendiente de la recta de regresión de OLS, y que coinciden con las ecuaciones 2.13 y 2.14: n n 2 i b0 = n n ∑x ∑y −∑x ∑x y i =1 i i =1 n n ∑ i =1 i i =1 xi2 − n ∑ i =1 i i =1 2 xi i (8.13) 253 8. Anexos n n b1 = n i i =1 i i i =1 n n ∑ i =1 8.1.3 n ∑x y −∑x ∑y xi2 − i i =1 n ∑ i =1 xi 2 Referencias 1.- J. Yellin, Trends in Analytical Chemistry, 14 (1995), 37-44. 254 (8.14) 8.2 Anexo 2. Presentaciones en congresos 8.2 Anexo 2. Presentaciones en congresos En esta sección se presentan diferentes colaboraciones, surgidas directamente del trabajo realizado en esta Tesis Doctoral, en diferentes congresos. El primero de ellos es una colaboración en forma de póster en el IV Colloquium Chimiometricum Mediterraneum, que se celebró en Burgos (España) entre el 8 y el 11 de junio de 1998. Esta colaboración trata sobre el desarrollo de los tests individuales para los dos coeficientes de regresión de la recta BLS. Dentro de este póster, se incluye el estudio y la evaluación de las distribuciones de los coeficientes de regresión de la recta BLS, que se han desarrollado en el capítulo 3 de esta Tesis Doctoral. A continuación se presentaron dos pósters presentados en el VII congreso internacional Chemometrics in Analytical Chemistry, celebrado en Amberes (Bélgica) entre el 16 y el 20 de octubre de 2000. El primero de ellos trata sobre el desarrollo de las expresiones para el cálculo de los límites de detección mediante el método BLS (desarrollado en el capítulo 5 de la presente Tesis Doctoral), mientras que el segundo consiste en el desarrollo del criterio gráfico para la detección de puntos discrepantes, desarrollado en el apartado 6.2 de la presente Tesis Doctoral. Además de las aportaciones en Congresos en forma de pósters, en el IV Colloquium Chimiometricum Mediterraneum, se participó con una presentación oral (Intervalos de confianza en regresión lineal considerando los errores en dos ejes) y una conferencia plenaria (Uncertainty and bias, two faces of the same analytical result) extraídas total o parcialmente del trabajo llevado a cabo en esta Tesis Doctoral. 255 Índice temático Índice temático A Análisis químicos APM 139 44 B BLMS 167, 195–214, 217, 234, 235, 243, 244 BLS 3, 4, 9, 26–28, 29, 67, 96, 163, 167, 170, 235, 241, 244, 249–254, 255 Bootstrap 44 C Calibración lineal 29, 40, 67, 101, 133, 134, 140 Coeficiente de aplastamiento 33, 35, 38 Coeficiente de asimetría 32, 35, 38 Coeficiente de fiabilidad 20, 22, 23 Coeficientes de Fisher 35, 36 Coeficientes de Pearson 35, 36 Comparación de métodos 28, 29–30, 40, 43, 67, 68, 96, 101, 133, 134 Covarianza 26, 27, 192 Criterio gráfico para la detección de puntos discrepantes 170, 171, 189–194, 234, 243, 255 CVR 23, 24, 45 D Detección de puntos discrepantes 3, 4, 53, 54, 167, 169–194 Distribución de una población Distribución normal 96, 241 DR 34, 36, 38, 58, 56 E EPM 44 Errores α y β 48, 68, 134 Estimaciones por máxima verosimilitud 25, 55, 57 Estimaciones por mínimos cuadrados 26 F Función de probabilidad 24, 34 G Gráfico de residuales ponderados 217, 235, 244 Gráficos de probabilidad normal 38–39 H Hipótesis alternativa Hipótesis nula 48 48 I Intervalo de confianza conjunto para la ordenada y la pendiente 54, 170 Intervalos de predicción 101, 102, 133, 134, 141, 163, 167, 242, 255 K 3 Kurtosis Ver Coeficiente de aplastamiento 259 Índice temático L Límite de detección 3, 5, 47–52, 167 Límite de detección en BLS 9, 133, 137–164, 242, 243, 255 Límites de detección 4 LMS 56, 57, 195, 213, 235 M Modelado de las varianzas experimentales 133, 141 Modelo estructural 21, 57 Modelo funcional 21, 22, 57 Modelo ultraestructural 21, 57 Momento 31 Momento centrado 31, 32, 35 Momento centrado adimensional 31, 33 Monte Carlo 4, 57–59, 103, 195, 213, 235 N Nivel de significancia 193, 194 Normalidad de los coeficientes de la recta BLS 4, 5, 9, 65–97, 241 O ODR 23 OLS 16–18, 28, 40, 42, 43, 53, 55, 96, 102, 141, 241, 249–254 OR 23 P Predicción en BLS 4, 5, 9, 99–135, 242 Predicción en regresión lineal 3, 39–46 Profundidad 56 260 Punto de ruptura Puntos discrepantes 217–233, 234, 243 56 5, 163, 167, R Regresión 13 Regresión lineal 9, 12–30, 51, 167 Regresión robusta 3, 4, 53, 55–57, 195 Robustez de BLS 167, 214–216, 217 S Skeewness asimetría Ver Coeficiente de T Teoría de propagación de los errores 102 Test conjunto para la ordenada y la pendiente 68, 96 Test de Cook 169 Test de Kolmogorov 37–38 Test en Cetama 35–37 Tests individuales para la ordenada y la pendiente 67, 167, 255 TLS 23 V Validación de metodologías 163 Valor crítico 49, 50, 51 W WLS 18–19, 28, 43, 96, 102, 141, 241, 249–254 Índice ÍNDICE 1 2 Introducción 1 1.1 Objetivos y justificación 3 1.2 Estructura de la Tesis 3 Fundamentos teóricos 2.1 7 Notación 2.1.1.1 Símbolos del alfabeto latino 9 10 2.1.1.2 12 Símbolos del alfabeto griego 2.2 Regresión lineal 12 2.2.1 Métodos que consideran los errores en una sola variable 15 2.2.1.1 Mínimos cuadrados ordinarios (OLS) 15 2.2.1.2 Mínimos cuadrados ponderados (WLS) 18 2.2.2 Métodos que consideran los errores en dos variables 19 2.2.2.1 Estimaciones por máxima verosimilitud 21 2.2.2.2 Estimaciones por mínimos cuadrados 25 2.2.2.3 Método de mínimos cuadrados bivariantes (bivariate least squares, BLS). 26 2.2.3 Aplicaciones de la regresión lineal considerando los errores en las variables predictora y respuesta 28 2.2.3.1 Calibración lineal 29 2.2.3.2 Comparación de métodos 29 2.3 Distribución de la población de una medida experimental 2.3.1 Distribución normal o Gaussiana 30 33 2.4 Tests estadísticos para la comprobación de la normalidad de una distribución 34 2.4.1 Test de normalidad en Cetama 34 2.4.2 Test de Kolmogorov 36 2.4.3 Gráficos de probabilidad normal 37 2.5 Predicción en regresión lineal 39 XI Índice 2.5.1 Intervalos de predicción considerando solamente los errores en la variable respuesta 39 2.5.2 Intervalos de predicción considerando los errores en las variables predictora y respuesta 44 3 2.6 Límites de detección 2.6.1 Test de hipótesis 2.6.2 Etapa de decisión 2.6.3 Etapa de detección 45 47 47 48 2.7 Regresión lineal en presencia de puntos discrepantes 2.7.1 Técnicas de detección de puntos discrepantes 2.7.2 Robustez en regresión lineal 51 52 53 2.8 Simulación de Monte Carlo 56 2.9 Referencias 57 Normalidad de los coeficientes de regresión 3.1 Introducción 3.2 Detecting proportional and constant bias in method comparison studies by using linear regression with errors in both axes 4 65 67 69 3.3 Conclusiones 96 3.4 Referencias 96 Predicción en BLS 4.1 Introducción 99 101 4.2 Prediction intervals in linear regression taking into account errors on both axes 104 5 4.3 Conclusiones 133 4.4 Referencias 134 Límite de detección en BLS 5.1 XII Introducción 137 139 Índice 5.2 concentration 6 Limits of detection in linear regression with errors in the 142 5.3 Conclusiones 163 5.4 Referencias 164 Regresión lineal en presencia de puntos discrepantes 6.1 Introducción 6.2 Detección de puntos discrepantes 6.2.1 Introducción 6.2.2 Outlier detection in linear regression taking into account errors in both axes 6.2.3 Comprobación de la aplicación del criterio gráfico 165 167 169 169 172 190 6.3 Regresión robusta 195 6.3.1 Introducción 195 6.3.2 Robust linear regression taking into account errors in both axes 6.3.3 BLMS 6.3.4 197 Comparación de diversos algoritmos de cálculo de la recta 213 Robustez de la recta BLS 214 6.4 Protocolo de actuación en regresión lineal en presencia de puntos discrepantes 217 6.4.1 Introducción 217 6.4.2 Linear regression taking into account errors in both axes in presence of outliers 218 7 6.5 Conclusiones 234 6.6 Referencias 236 Conclusiones 239 7.1 Conclusiones 241 7.2 Perspectivas futuras 244 XIII Índice 8 Anexos 247 8.1 Anexo 1. Comparación de los métodos OLS, WLS y BLS 249 8.1.1 Comparación de las rectas de regresión obtenidas con los métodos OLS, WLS y BLS 249 8.1.2 Comparación de los métodos OLS, WLS y BLS 250 8.1.3 Referencias 254 8.2 Anexo 2. Presentaciones en congresos Índice temático XIV 255 257 UNIVERSITAT ROVIRA I VIRGILI Departament de Química Analítica i Química Orgànica PARÁMETROS CUALIMÉTRICOS DE MÉTODOS ANALÍTICOS QUE UTILIZAN REGRESIÓN LINEAL CON ERRORES EN LAS DOS VARIABLES Tesis Doctoral F RANCISCO J AVIER DEL R ÍO B OCIO Tarragona, 2001 Parámetros Cualimétricos de Métodos Analíticos que Utilizan Regresión Lineal con Errores en las Dos Variables Tesis Doctoral U NIVERSITAT ROVIRA I V IRGILI UNIVERSITAT ROVIRA I VIRGILI Departament de Química Analítica i Química Orgànica Àrea de Química Analítica PARÁMETROS CUALIMÉTRICOS DE MÉTODOS ANALÍTICOS QUE UTILIZAN REGRESIÓN LINEAL CON ERRORES EN LAS DOS VARIABLES Memoria presentada por Francisco Javier del Río Bocio para conseguir el grado de Doctor en Química Tarragona, 2001 Prof. FRANCESC XAVIER RIUS I FERRÚS, Catedrático del Departament de Química Analítica i Química orgánica de la Facultat de Química de la Universitat Rovira i Virgili, y el Dr. JORDI RIU I RUSELL, Becario post doctoral del mismo Departamento, CERTIFICAN: Que la presente memoria que tiene por título: “PARÁMETROS CUALIMÉTRICOS DE MÉTODOS ANALÍTICOS QUE UTILIZAN REGRESIÓN LINEAL CON ERRORES EN LAS DOS VARIABLES”, ha sido realizada por FRANCISCO JAVIER DEL RÍO BOCIO bajo nuestra dirección en el Área de Química Analítica del Departament de Química Analítica i Química Orgánica de esta Universidad y que todos los resultados presentados son fruto de las experiencias realizadas por dicho doctorando. Tarragona, marzo de 2001 Prof. F. Xavier Rius i Ferrús Dr. Jordi Riu i Rusell AGRADECIMIENTOS Soy consciente de que los siguientes párrafos van a ser los más leidos de la Tesis. Por este motivo voy a aprovechar y mostrar mi gratitud hacia todas aquellas personas que de una manera u otra me han ayudado a poder llegar a este momento tan esperado. En primer lugar me gustaría agradecer a F. Xavier Rius el empujón que me dio en su día para entrar en este mundillo de la investigación cuando yo había dejado de creer en la química. Muchas gracias por eso y por la ayuda que me has prestado en todos estos años de trabajo. También me gustaría darle las gracias a Jordi Riu. Muchas gracias por tu ayuda, por tu colaboración pero, sobretodo, muchas gracias por ofrecerme tu amistad. Espero que te vaya muy bien en el post-doc y que a tu vuelta triunfes tanto como investigador como ... bueno, como en todo lo demás. Muchas gracias a mis compañeros del grupo de Quimiometría. Quiero empezar por los que me han acompañado en el labo 9 desde el primer día, y que me han aguantado en mis buenos y en mis malos días. Muchas gracias a Jaume (los del Burger echarán de menos al consumidor de Long Chicken, ¿eh?) y a Santi (siempre disponible para ayudar y resolver dudas en cualquier momento ...). No quiero olvidar al resto de compañeros del grupo, empezando por Ángel que es con el que he trabajado más (¡aúpa BLS!). Alicia Pulido (... anda que no hemos pasado ratos criticando a troche y moche en el pasillo, ¿eh?), a la otra Alicia (otra que tal, ¿eh?), Enric (anímate y hazte merengue, que tendrás menos disgustos, ¡hombre!), a Mari, a Toni, a Josep Lluís, a Floren, a Joan, a Ricard, a Pilar, a Marisol, a Iciar, y a todos los que han pasado por el grupo y que ya no están. De estos me gustaría hacer mención especial a Sara y Barbara; estuvisteis poco tiempo, pero habéis dejado huella, ¿eh?. No me quiero olvidar (porque no sería justo) de mis amigos. Dentro de este apartado me gustaría mencionar muy especialmente a Noe (a pesar de haberme viciado con los talladets y la carmanyola he disfrutado mucho de ellos en compañía de una gran Amiga), a Pepe (esas comidas juntos no se olvidan fácilmente, ¿eh?. Por cierto, mucha suerte en tu nueva vida) y a Fernando (¡vaya ratos hemos pasado sentados en la escalera frente a orgánica!). Entre los tres habéis aguantado todos mis malos momentos en Tarragona y me habéis ayudado a superarlos. Tampoco me quiero olvidar de Juan Antonio, Jorge, Jordi, Merche, Eva, Núria y Olga (¡ese equipazo de enólogas! que siempre me han ayudado cuando lo he necesitado), Joan (¡firrrmes!) y Eva, ni tampoco de Vanessa y otros tantos que no enumeraré porque necesitaría demasiado espacio para no dejarme a nadie. Muchas gracias a todos por ser mis amigos. No me quiero olvidar de los momentos buenos y de ocio que he pasado durante este periodo de tiempo, así que también quiero agradecer los buenos ratos que he pasado en los tres coros (el de la URV, el Mare Nostrum y el de los Paúles), tocando la flauta o en el cine. Muchas gracias a los responsables de que me queden estos buenos recuerdos: Mònica, Marisol, Arancha, Quim, Laura, ... y un muy largo etcétera. Por último quiero agradecer muchísimo el apoyo y la ayuda de toda mi familia. Empezando por la más cercana: Papá, Mamá, Carlos, Inma, Marga y Yaya, y siguiendo por los tíos y primos. Muchas gracias a todos por ser como sois, por aguantarme y por ayudarme a llegar a esto. Sólo vosotros sabéis cuánto os agradezco todo lo que me habéis dado. A la hora de agradecer normalmente se piensa en toda la gente que te ha ayudado. Sin embargo cinco años son muchos y mi memoria demasiado flaca como para estar seguro de que no me he dejado a nadie. Por este motivo, quiero dar las gracias a todos aquellos que en algún momento han pensado en mi o me han querido ayudar. Muchas gracias a todos “Pedí a Dios de todo para disfrutar de la vida y Él me dio la vida para disfrutar de todo” A Papá, Mamá, Yaya, Carlos, Inma y Marga Os quiero muchísimo