Kaiser, E., & Munson, B. Social Selectivity in Adults' Novel Sound
advertisement

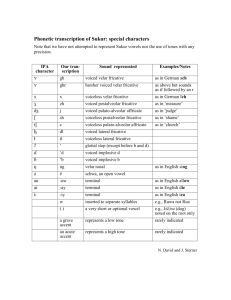
Laboratory Phonology 11 65 Kaiser & Munson Social Selectivity in Adults' Novel Sound Learning Eden Kaiser* & Benjamin Munson# *Linguistics Program, University of Minnesota; kaise113@umn.edu #Department of Speech-Language-Hearing Sciences, University of Minnesota; munso005@umn.edu There is a good deal of evidence for the existence of social identity-based differences in speech (Labov 1972, and others), especially differences based on talker gender (Perry, Ohde, & Ashmead, 2001; Patterson & Werker, 2002; Foulkes, Docherty, & Watt 2005, and others). However, the nature of the process by which these differences are acquired is still unknown. The purpose of this study is to investigate sex-specific phonetic learning in a laboratory-based novel-sound learning task. Specifically, we examined male and female participants' tendencies to emulate phonetically distinct variants of novel sounds produced by talkers who shared their biological sex, as opposed to the variant produced by the opposite sex. We believe that the outcome of this endeavor will be a better understanding of how these variables might be acquired during first-language acquisition. To examine this, we created one set of one-syllable nonwords whose onsets contained a voiceless lateral obstruent, and another set whose onsets contained a velar fricative. These non-English sounds were used in order to control for any previous sex-related biases people may have for familiar English sounds. Audio productions of these novel words were recorded by two trained linguists whose voices the authors judged as being prototypically female and male. The novel words were presented one at a time, by either the female voice or the male voice, and were associated with novel objects shown on a computer screen. Each participant was trained on one onset which the man and woman produced differently (hereafter called “sexbiased”), and one onset which they produced equally variably (hereafter called “random”). The two variants for the voiceless lateral obstruent were the voiceless lateral fricative [ɬ] and the voiceless lateral affricate [tɬ]. The two variants for the velar fricative were the voiced velar fricative [ɣ] and the voiceless velar fricative [x]. Participants were systematically exposed to variations of onsets: half the participants heard sex-biased variation for the lateral onset and random variation for the velar onset, while the other half heard random variation for the lateral onset and sex-biased variation for the velar onset. Three iterations of learning phases followed by test phases were presented to each participant, first for one onset, then for the other. During the learning phases, participants saw a novel object on the screen and heard over headphones “This object is a ____”, spoken by either the man or the woman, and onsets varied accordingly. During the test phases, participants were asked to name objects whose pictures appeared on the screen one at a time. Below is the counter-balancing scheme used to systematically expose participants to both sex-biased and random variation. There were five women and five men in each of four groups. Group 1 random [ɬ]/[tɬ] female-biased [ɣ] / male-biased [x] Group 2 random [ɬ]/[tɬ] female-biased [x] / male-biased [ɣ] Group 3 female-biased [tɬ] / male-biased [ɬ] random [x]/[ɣ] Group 4 female-biased [ɬ] / male-biased [tɬ] random [x]/[ɣ] Table 1: Sex-biasing counter-balancing scheme Results were coded in narrow phonetic transcription by an experienced transcriber who was blind to the purposes of the experiment. The dependent measures were calculated by one of the authors using the following criteria: onsets which contained a fricative were judged to be approximating the lateral fricative [ɬ], whereas onsets which contained an obstruent were judged to be approximating the lateral affricate [tɬ]; LabPhon11 abstracts edited by Paul Warren Wellington, New Zealand 30 June - 2 July 2008 Abstract accepted after review 66 Laboratory Phonology 11 Kaiser & Munson and onsets which contained a voiceless velar or voiceless glottal were judged to be approximating the voiceless velar fricative [x], whereas all onsets which contained either a voiced velar/glottal or a rhotic were judged to be approximating the voiced velar fricative [ɣ]. The authors found that, overall, both men and women tended to produce more approximations of the onsets [tɬ] and [x] over their respective variants, [ɬ] and [ɣ]. Group 1 Group 2 Group 3 Group 4 Females’ use of [tɬ] 71.212 Males’ use of [tɬ] 79.059 64.583 59.722 67.677 44.556 Females’ use of [ɣ] 18.519 14.293 3.819 Males’ use of [ɣ] 6.944 4.646 4.444 Table 2: Results (in percentages) The influence group and training condition on the percentage use of different variants did not achieve statistical significance using conventional alpha levels. However, there were some noteworthy trends in the data. For the lateral onset [ɬ]/[tɬ], women and men were more likely to attempt to produce [ɬ] when presented with sex-biased variation (either biased for or against production of [ɬ]). More interestingly, men were much more likely to produce [tɬ] than [ɬ] when presented with random variation, than when biased against producing [tɬ]. For the velar onset [x]/[ɣ], males rarely attempted to approximate the voiced velar fricative, opting instead for the unvoiced variant. Females were about four times as likely to attempt to approximate the voiced velar fricative when they were presented with sex-biased variation (especially when biased for the voiced variant). But when females were presented with random variation, their attempts to approximate the voiced variant were on par with the men's. Based on these results, we can conclude that women and men are sensitive to sex-biased differences when acquiring novel sounds. In other words, people learn new phonetic variants selectively, based on the socialindexical characteristics associated with the phonetic input, namely, one's own sex and the sex of the speaker. The next step along this line of research is to reproduce these results, removing the potentially complicating factor of production. Currently, we are designing a perception experiment to examine whether adults' perception is similarly biased by the perceived sex of the adults who model the novel sound. The result of these two experiments together will be an improved understanding of the extent to which adults' sound learning is indexed to perceived social characteristics of the people producing the sounds being learned. References Foulkes, P., Docherty, G., & Watt, D. (2005). Phonological variation in child directed speech. Language, 81, 177-206. Labov, W. (1972). Sociolinguistic Patterns. Philadelphia: University of Pennsylvania Press. Patterson, M. L. and Werker, J. F. (2002). Infants ability to match dynamic phonetic and gender information in the face and voice. Journal of Experimental Child Psychology, 81, 93-115. Perry, T., Ohde, R., and Ashmead, D. (2001). The acoustic bases for gender identification from children’s voices. JASA, 109, 2988-2998.