Macromolecules - Essentials Education

THEME 1
Macromolecules
THREADS
Organisation
Selectivity
Energy Flow
Perpetuation
Evolution
Human Awareness
8
9
10
11
12
5
6
3
4
7
1
2
WORKSHEETS
The structure of DNA
Chromosomes are made up of genes
DNA and protein synthesis
Structure and function of protein molecules in cells
The importance of polysaccharides and lipids
DNA replication
Enzymes
DNA and protein evidence for evolution
Mutations
Genetic manipulation
Some social consequences of genetic manipulation
Multiplying and sequencing DNA
KEY IDEAS
Students should know and understand the following:
M1.
The chemical unit of genetic information in most organisms is DNA
M2.
The structural unit of information in the cell is the chromosome
M3.
The functional unit of information on the chromosome is the gene
M4.
The flow of information from DNA to protein is unidirectional in most organisms
DNA Î RNA Î protein
M5.
The three-dimensional structure of a protein is critical to its function
M6.
Polysaccharides and lipids are important macromolecules in cells and organisms
M7.
Specific base-pairing is the mechanism of DNA replication
M8.
Enzymes are specific for their substrate
M9.
Molecular recognition is an important property for life processes
M10.
Enzymes increase reaction rates by lowering activation energy
M11.
Macromolecules are used as energy reserves
M12.
DNA carries genetic information from one generation to the next
M13.
The universal presence of DNA is strong evidence for the common ancestry of all living things
M14.
DNA and protein sequences usually show greater similarity between closely related groups of organisms than between distantly related groups
M15.
Change in the base sequence of DNA can lead to the alteration or absence of proteins, and to the appearance of new characteristics in the descendants
M16.
Human beings can manipulate DNA
M17.
Human beings can sequence even small amounts of DNA
(© SSABSA Stage 2 Biology Curriculum Statement 2006, p22-24 and used with permission.
Teachers and students are advised to check the website www.ssabsa.sa.edu.sa for any changes.)
6 SACE 2 BIOLOGY E ssentials WORKBOOK
Worksheet 1 The structure of DNA
DNA stands for ‘deoxyribonucleic acid’.
This molecule is found primarily in the nucleus of cells.
It is a double stranded molecule with the strands wound around each other to form a double helix.
The molecule is made up of repeating units called nucleotides.
A single nucleotide is made up of three components: a deoxyribose sugar, a phosphate and an organic base.
The diagram below is a representation of 2 nucleotides bonded together.
Bases
A T
Deoxyribose sugar
Phosphate
C
T
C
C
T
G
A
G
G
A
A
A
G
A
A
A
G
G
T
T
C
T
T
T
C
C
Weak hydrogen bonds between bases
There are four organic bases found in DNA: Adenine, Thymine, Guanine and
Cytosine.
The letters A, T, G and C represent these bases.
A single strand of DNA is a sequence of nucleotides joined together with alternating phosphate and sugar components.
The double helix molecule consists of two complementary strands that are joined by hydrogen bonds between the bases.
The bases always pair in specific ways:
Adenine always bonds with Thymine
Guanine always bonds with Cytosine
Thymine always bonds with Adenine
Cytosine always bonds with Guanine
The adjacent diagram shows the double helical model for DNA first proposed
by two scientists Watson and Crick in 1953.
1.
Write a concise statement to explain each of the following terms:
complementary ……………………………………………………………………………………………...
DNA
macromolecule
………………………………………………………………………………………..….…
………………………………………………………………………………………..….…
monomer
nucleic acid
nucleotide
organic
polymer
base
………………………………………………………………………………………..….…
………………………………………………………………………………………..….…
………………………………………………………………………………………..….…
………………………………………………………………………………………..….…
………………………………………………………………………………………..….…
………………………………………………………………………………………..….…
deoxyribose sugar ………………………………………………………………………………………..….…
phosphate ………………………………………………………………………………………..….…
©
Crierie A.
and Greig D.
2008
All rights are reserved, copying is prohibited by law.
Worksheet 1 THE STRUCTURE OF DNA
2.
The following sequence of bases was found in a segment of DNA
7
A A G G C T T G C
Write the sequence of bases that would be found in the complementary strand.
……………………………………………………………………………………………………………………….
3.
Name the four major organic bases found in DNA.
………………………………………………………………………………………..……………………………...
4.
Write down the four possible base pairings in DNA.
………………………………………………………………………………………..……………………………..
5.
If a sequence of DNA has 30% guanine bases in it what percentage of thymine would there be?
………………………………………………………………………………………..……………………………..
6.
Refer to the diagram below.
Sugar Phosphate Sugar Phosphate Sugar Phosphate Sugar Phosphate
Base Base Base Base
(a) Circle a nucleotide in the representation of a strand of DNA shown above.
(b) How many nucleotides are shown in the diagram?
……………………………………………………….
7.
Use the figure to label A B C and D in the diagram below.
A
A T
B
C
D
A …………………………………………………………………………………………………………………
B ………………………………………………………………………………………..………………………..
C ………………………………………………………………………………………..………………………..
D ………………………………………………………………………………………..………………………..
©
Crierie A.
and Greig D.
2008
All rights are reserved, copying is prohibited by law.
8 SACE 2 BIOLOGY Essentials WORKBOOK
Worksheet 2 Chromosomes are made up of genes
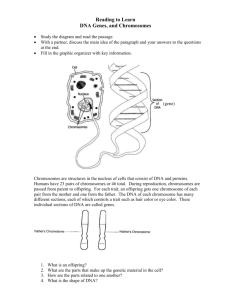
Chromosomes are thread ‐ like structures made up of DNA and proteins call histones.
These structures are found in the nucleus of eukaryotic cells and are visible as the cells start to divide.
The chromosome number is constant for each species, e.g.
46 in humans, 48 in a chimpanzee, 40 in a mouse and 38 in cabbage.
Chromosomes in non ‐ dividing cells are single stranded and the DNA is not condensed, that is, the DNA is spread out to make it easier to access genes in transcription, an important process in protein synthesis and replication, where another copy of the DNA is made.
When the chromosomes are visible during the Prophase stage of mitosis and/or meiosis they appear double stranded.
This doubling has occurred as the DNA has replicated in order that new cells can receive their complement of DNA.
A gene is the unit of heredity.
Genes represent sequences of the bases A T G and C on chromosomes and code for protein molecules or parts of protein molecules.
Each gene is found on a particular chromosome.
Genes prescribe the features of an organism: green eyes, skin colour or the shape of a nose.
In a human with 46 chromosomes it is thought that there are around 40,000 genes, each chromosome containing hundreds or thousands of genes.
A single gene usually contains between 300 to several thousand bases.
Each gene has a start and a finish to signal where transcription begins and ends.
The diagram below shows schematic representations of some human chromosomes and some of the gene locations that have been identified.
2 3
Familial
Colon Cancer
Retinitis
Pigmentosa
7 9
Cystic
Fibrosis
Malignant
Melanoma
11 12
Sickle Cell
Anemia
PKU
14 17
Alzheimer's
Disease
Breast
Cancer
The human genome project.
This is a project that was first proposed around 1987.
Its aim was to map the entire sequence of genes to chromosomes and sequence the human genome.
The figure above illustrates some of the known gene locations (loci).
In Adelaide a group of scientists at the Women and Children ʹ s Hospital is involved in studying chromosome 16.
This overall mapping is a major undertaking as there are approximately 3 billion building blocks or nucleotides in the total genome.
The first stage was completed in about June
2000.
This photograph shows a typical set of human chromosomes, which was taken from a prepared slide using a light microscope.
The images have been cut out and pasted together to show the homologous pairs.
Until recently this was done with scissors, it is now done with computer software They are generally numbered and arranged from longest to shortest.
The sex chromosomes are bottom right of this photo.
This is the male set of chromosomes or karyotype.
A female has two copies of the longer (X) sex chromosome instead of one long (X) and one short (Y).
©
Crierie A.
and Greig D.
2008 All rights are reserved, copying is prohibited by law.
Worksheet 2 CHROMOSOMES ARE MADE UP OF GENES 9
1.
Write a concise statement to explain each of the following terms:
.
chromatid ……………………………………………………………………………………………...
chromosome
gene
……………………………………………………………………………………………...
……………………………………………………………………………………………...
genome ……………………………………………………………………………………………...
2.
In what organelle are the chromosomes found in eukaryotic cells?
………………………………………
3.
Why are the chromosomes not usually visible in non ‐ dividing cells?
……………………………………………………………………………………………...………………………
……………………………………………………………………...………………………………………………
4.
Explain the differences between DNA, genes, chromosomes.
……………………………………………………………………………………………...………………………
……………………………………………………………………...………………………………………………
5.
What does it mean to say that a gene is linked to a chromosome?
……………………………………………………………………………………………...………………………
……………………………………………………………………...………………………………………………
6.
Explain the significance of different species having different numbers and types of chromosomes?
……………………………………………………………………………………………...………………………
……………………………………………………………………...………………………………………………..
7.
Approximately how many genes are there;
(a) on one human chromosome?
………………………...……………………………………………….
(b) in the human genome?
………………………...……………………………………………….
8.
Scientists have known for a considerable period of time that the gene for colourblindness is on the X
chromosome.
(a) Suggest how it was discovered that this was linked to the X chromosome.
……………………………………………………………………………………………...………………………
……………………………………………………………………...………………………………………………
(b) Genes like this are said to be ‘X ‐ linked’ and the characteristics are said to be sex ‐ linked.
Explain why this is so.
……………………………………………………………………………………………...………………………
……………………………………………………………………...………………………………………………
9.
Explain what it means to say that the structural unit of information in an organism is the chromosome.
……………………………………………………………………………………………...………………………
……………………………………………………………………...………………………………………………
……………………………………………………………………………………………...………………………
……………………………………………………………………...………………………………………………
©
Crierie A.
and Greig D.
2008 All rights are reserved, copying is prohibited by law.
10 SACE 2 BIOLOGY Essentials WORKBOOK
Worksheet 3 DNA and protein synthesis
Genes on the DNA code for a specific sequence of amino acids (aa) that comprise a polypeptide.
Several
poypeptides usually make up a protein.
They can also code for the production of an RNA molecule.
Protein synthesis requires two steps: transcription and translation .
Three main nucleic acids are involved .
DNA : provides the template for the production of the mRNA.
mRNA: transcribed from the DNA and provides a sequence of codons translated into a sequence of amino acids on the ribosomes.
that are able to be tRNA: there are more than 20 different types of these, each one capable of carrying only one type of amino acid.
Transcription
This process occurs in the nucleus of a cell and is where the DNA template acts as a code to transcribe a gene segment of DNA bases into a working copy of mRNA.
The enzyme involved is called RNA
Polymerase.
The diagram below shows the process of transcription.
C
C
T
T
C
T A
C
T
T
A
G
T
C
T
A
G
T A
RNA polymerase
A
C C G
U
U
C
A
A
G
C G
U A
U
C
C
C
G
C
U
U
C
T A
A
C
G
U
G
U
A
C
Nucleotides used to assemble the mRNA
DNA Template
Growing mRNA strand
T A
C G
mRNA nucleotides in the nucleus are binding to the exposed DNA bases to form a working copy of the gene that will be able to be translated on the ribosomes to form protein.
Translation
Is a process where the codon sequence on the mRNA is translated into an amino acid language.
tRNA molecules carry specific amino acids into position as the anti ‐ codon of the tRNA links with the codon on the mRNA.
The next diagram shows the process of translation.
©
Crierie A.
and Greig D.
2008 All rights are reserved, copying is prohibited by law.
Worksheet 3 DNA AND PROTEIN SYNTHESIS
Leucine Serine
Growing polypeptide chain tRNA molecule
11
A
U
A U
U A
U
A
C A
G U
Anti codon mRNA molecule codon ribosome
In the diagram above, leucine and serine are the first two amino acids that are joined together by peptide bonds to start the polypeptide or protein.
The steps involved in protein synthesis can be set out as follows.
1.
The double helix of the DNA unwinds and unzips at the required gene site exposing the nitrogenous bases on the template.
2.
mRNA nucleotide bases (A U G C) attach to the exposed DNA bases with the assistance of the enzyme RNA polymerase.
3.
Once the sequence for the mRNA has been completed, the mRNA is released and moves out of the nucleus into the cytoplasm.
4.
The DNA strands will rejoin and recoil themselves to form the double helix.
5.
The mRNA molecule attaches to the ribosomes in the cytoplasm.
6.
Specific amino acids combine with their appropriate tRNA molecules.
7.
The ribosome moves along the mRNA molecule attaching the appropriate tRNA anti ‐ codon to the codon on the mRNA.
8.
The amino acids join together to form a polypeptide sequence.
9.
When a stop codon is reached the translation is complete.
10.
The protein breaks away and is ready for use within the cell, or to be packaged and secreted from the cell.
1 Write a concise statement to explain each of the following terms:
amino acid ……………………………………………………………………………………………
anti ‐ codon
codon
……………………………………………………………………………………………
……………………………………………………………………………………………
RNA polymerase ……………………………………………………………………………………………
mRNA
ribosome
……………………………………………………………………………………………
……………………………………………………………………………………………
©
Crierie A.
and Greig D.
2008 All rights are reserved, copying is prohibited by law.
12
transcription
translation
SACE 2 BIOLOGY Essentials WORKBOOK
……………………………………………………………………………………………
……………………………………………………………………………………………
tRNA ……………………………………………………………………………………………
2.
To help you identify differences between DNA, mRNA, and tRNA, complete the following statements by writing the appropriate nucleic acid(s) after each one.
a.
is single stranded ……………..
b.
has a double helical structure
c.
is only found in the cytoplasm
d.
is found primarily in the nucleus of a cell
e.
contains the base thymine
f.
contains the base uracil
g.
is involved in the process of replication
h.
carries amino acids to the ribosomes
i has triplets of bases called codons
j is found in both the nucleus and cytoplasm
……………..
……………..
……………..
……………..
……………..
……………..
……………..
……………..
……………..
k has three bases which comprise the anticodon ……………..
3.
Explain the role of the following in the process of protein synthesis:
DNA ………………………………………………………………………………………………………..
…………………………………………………………………………………………………………………………...
mRNA ………………………………………………………………………………………………………..
…………………………………………………………………………………………………………………………...
tRNA ………………………………………………………………………………………………………..
…………………………………………………………………………………………………………………………...
amino acids ………………………………………………………………………………………………………..
…………………………………………………………………………………………………………………………...
ribosomes ………………………………………………………………………………………………………..
…………………………………………………………………………………………………………………………...
mitochondria……………………………………………………………………………………………………….
…………………………………………………………………………………………………………………………..
4.
Explain the difference between:
a) transcription and translation
………………………………………………………………………………………………………………………
………………………………………………………………………………………………………………………
b) a codon and an anti ‐ codon
………………………………………………………………………………………………………………………
………………………………………………………………………………………………………………………
©
Crierie A.
and Greig D.
2008 All rights are reserved, copying is prohibited by law.
Worksheet 3 DNA AND PROTEIN SYNTHESIS
5.
Use the diagram below, which shows a summary of the process of protein synthesis,to write the names and roles of the structures labelled:
NUCLEUS CYTOPLASM
13
T
C
A
G
T A
C
C
C
C
T
T
T A
C
T
A
G
T
T
A
C C G
U
U
C
A
A
G
C G
U A
U
C
C
C
G
C
U
U
C
T A
D
B
G
A
C
U
A
G
A
C
U
E
F
Leucine
J
Serine M
I
T A
C G
A
U
A
U
U
A
U
A
C
G
A
U
L
K
H G
A …………………………………………………………………………………………………………………
B …………………………………………………………………………………………………………………
C …………………………………………………………………………………………………………………
D …………………………………………………………………………………………………………………
E …………………………………………………………………………………………………………………
F …………………………………………………………………………………………………………………
G …………………………………………………………………………………………………………………
H …………………………………………………………………………………………………………………
I …………………………………………………………………………………………………………………
J …………………………………………………………………………………………………………………
K …………………………………………………………………………………………………………………
L …………………………………………………………………………………………………………………
M …………………………………………………………………………………………………………………
©
Crierie A.
and Greig D.
2008 All rights are reserved, copying is prohibited by law.
14 SACE 2 BIOLOGY Essentials WORKBOOK
6.
The table below shows which codons carry the information for each amino acid.
AUU
AUC
AUA
AUG
GUU
GUC
GUA
GUG
UUU
UUC
UUA
UUG
CUU
CUC
CUA
CUG ile ile ile
start/met val val val val leu leu leu leu phe phe leu leu
ACU
ACC
ACA
ACG
GCU
GCC
GCA
GCG
UCU
UCC
UCA
UCG
CCU
CCC
CCA
CCG ala ala ala ala thr thr thr thr ser ser ser ser pro pro pro pro
AAU
AAC
AAA
AAG
GAU
GAC
GAA
GAG
UAU
UAC
UAA
UAG
CAU
CAC
CAA
CAG asn asn lys lys asp asp glu glu his his gln gln tyr tyr stop stop
AGU
AGC
AGA
AGG
GGU
GGC
GGA
GGG
UGU
UGC
UGA
UGG
CGU
CGC
CGA
CGG
The table below shows the names of the amino acids together with the abbreviations used in the table above.
ala = arg = asn = asp = cys = gln = glu = alanine arginine asparagine aspartic acid cysteine glutamine
glutamic acid
gly his ile
=
=
=
glycine histidine isoleucine leu = leucine lys = lysine
met = methionine phe = phenylalanine
pro = proline ser = serine thr = threonine trp = tryptophan tyr = tyrosine val = valine
Now, use the table of the genetic code and names of the amino acids given to help you complete the following table.
DNA base triplets AGA ________ ________ ________
mRNA tRNA
codons anti ‐
codons
amino acid coded for
________
________
________
CGG
________
________
________
CUG
________
________
________
methionine gly gly gly gly ser ser arg arg cys cys stop trp arg arg arg arg
©
Crierie A.
and Greig D.
2008 All rights are reserved, copying is prohibited by law.
Worksheet 4 STRUCTURE AND FUNCTION OF PROTEINS 15
Worksheet 4 Structure and function of protein molecules
Protein molecules are large polymers made up of about 20 common building blocks called amino acids linked together.
Organisms typically, have thousands of these molecules.
Humans are thought to have between 50,000 ‐ 100,000 different proteins, each one with a unique three ‐ dimensional structure that is critical for its particular function.
Proteins can be placed into 2 main groups, fibrous or structural proteins, and globular proteins.
Protein structure can be studied at four levels
•
Primary structure ‐ the sequence of amino acids linked by peptide bonds.
Each protein is characterised by its own unique number, type and sequence of amino acids.
Typically proteins are made up of hundreds to thousands of amino acids, haemoglobin, a transport protein, is some 400 times bigger in size than a glucose molecule.
•
Secondary structure ‐ the coiling or folding of the polypeptide chain.
•
Tertiary structure ‐ the three ‐ dimensional structure, which is important for binding.
•
Quaternary structure ‐ applies to those proteins with more than one polypeptide strand.
It is the tertiary structure of each specific protein that determines its specific function.
If the delicate three ‐ dimensional shape of a protein is altered, it usually follows that the function of that protein is also
inhibited, this is called denaturation.
The diagram below gives a diagrammatic representation of the different levels of structure in a molecule of haemoglobin which is a protein found in blood.
ala
Polypeptide chain gly leu val lys
Heme
Polypeptide chain
PRIMARY
STRUCTURE
SECONDARY
STRUCTURE
TERTIARY
STRUCTURE
QUATERNARY
STRUCTURE
The structural proteins are more fibrous in nature and tend to have repeating units of amino acid sequences, whereas the globular proteins each have their own unique sequences giving them their particular shape that is so vital for their function.
Types of proteins.
Proteins can be placed into groups depending on their particular roles in the organism.
Structural
Examples include those that make up ligaments and tendons, while others assist in movement, for example muscle proteins.
Keratin is an important structural protein found in organisms, it makes up the outer layer of skin, and is the main component of hair, nails, wool, beaks and feathers.
Proteins embedded in the cell membrane are vital for the efficient functioning of cells.
Some have roles in acting as channel proteins allowing certain molecules to enter or leave cells, but not others.
Other proteins act as receptor proteins that can bind to chemicals like hormones, and thus bring about a particular response.
Defence
Specific protein molecules, called antibodies, are released from white blood cells and have a role in the inactivation and destruction of foreign antigen molecules that may invade our tissues.
The unique shape of the protein antibody means that the action of each antibody is specific for a particular antigen; one particular antibody can only bind with and inactivate one particular antigen.
©
Crierie A.
and Greig D.
2008 All rights are reserved, copying is prohibited by law.
16 SACE 2 BIOLOGY Essentials WORKBOOK
Communication
Certain molecules, including some hormones, bring about their specific action by binding to other molecules.
When the hormone insulin binds to receptor proteins in the cell membrane, the cell membrane
increase its permeability to glucose and the cell takes up more glucose to store as glycogen.
The diagram below represents the binding of a hormone to a surface receptor.
Hormone messenger molecule
Receptor molecule embedded into the bi-lipid layer of cell membrane
Lipid bi-layer
Binding leads to activation
Transport
Haemoglobin is a protein molecule found inside human red blood cells.
It has a specific role in the transport of oxygen molecules to the tissues of the body.
The particular shape of the molecule makes it ideal for the reversible binding that occurs with oxygen.
The control of metabolic reactions.
All reactions inside cells need specific enzyme molecules to ensure that they proceed.
Enzymes are protein molecules with a specific shape that is critical for the binding of the reactant or substrate molecules.
The three dimensional shape of the protein gives rise to an active site on the enzyme where an induced fit binding occurs.
1.
Write a concise statement to explain each of the following terms:
antibody ……………………………………………………………………………………………
antigen ……………………………………………………………………………………………
complementary strand ………………………………………………………………………………………..
denature ……………………………………………………………………………………………
enzyme ……………………………………………………………………………………………
haemoglobin
hormone
insulin
polypeptide
protein
surface receptor
……………………………………………………………………………………………
……………………………………………………………………………………………
……………………………………………………………………………………………
……………………………………………………………………………………………
……………………………………………………………………………………………
……………………………………………………………………………………………
©
Crierie A.
and Greig D.
2008 All rights are reserved, copying is prohibited by law.