Objectives
advertisement

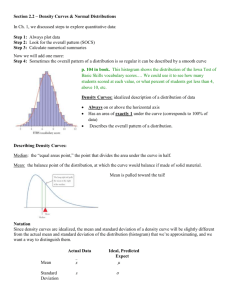
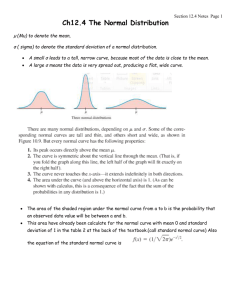
Objectives 1.3 Density curves and Normal distributions p Density curves p Measuring center and spread for density curves p Normal distributions p The 68-95-99.7 (Empirical) rule p Standardizing observations p p Calculating probabilities using the standard Normal Table (CIS Chapter 8, p 105 – mainly p114) Inverse Normal calculations Additional reading: http://onlinestatbook.com/2/normal_distribution/normal_distribution.html Histogram and density curves p p p p p As I have mentioned several times, underlying the histogram of the observations is the true (usually unknown) histogram of the population. If the data is a continuous numerical variable, it can take any value (eg. heights, weights, but not the number of M&Ms – as this is numerical discrete variable). For continuous numerical variables, the underlying distribution is known as the density curve. Like the histogram, the density tells us which outcomes are more likely. Unlike the relative frequency histogram the y-axis does not denote the chance/probability of an event -- the area gives the chance. We usually do not know the true density curve, but we can often get a good estimate based on the data using statistical software. Lab practice: Load the calf data into Statcrunch. Try fitting a range of different well known densities shapes to the data. In the third page on the histogram menu, there is an option called overlay density. This is a list of density shapes you can overlay your histogram to see which best fits your data. Density curves A density curve is a mathematical model of a distribution. The total area under the curve, by definition, is equal to 1.00, or 100%. The area under the curve for a range of values is the proportion of all observations for that range. Histogram of a sample with the smoothed, density curve describing theoretically the population. Calculation practice p p p p p p Make a sketch of a density plot of human heights with mean 67 inches and standard deviation 7 inches. What is the area below the entire curve? On this plot show the probability of a human height being less than 60 inches. On this plot show the probability of a human height being greater than 75 inches. On this plot show the probability of a human height lying between 60 and 75 inches. On the next slide we give an examples of different types of density curves. Match a variable to each plot. Density curves come in any imaginable shape. Some are well known mathematically and others aren’t. Review: Median and mean of a density curve The median of a density curve is the point that divides the area under the curve in half. The mean of a density curve is the balance point, at which the curve would balance if it were made of solid material. The median and mean are the same for a symmetric density curve. The mean of a skewed curve is pulled in the direction of the long tail. The normal family of density plots p p We now introduce a family of density functions which are extremely useful in statistics. It is called the normal distribution. There are various reasons that they are an important family p p p p Many variables (but not all NOT all) have a density which is close to a normal distribution. These include biological measurements, some type of exam scores etc. The normal distribution is a good approximation to the results of many types of chance outcomes (over the long run). For example, if you toss a coin many times the probability for the number of heads will look like normal distribution (if tossed enough times) – We come back to this later. If we can assume a variable is normally distributed, it allows us to calculate probabilities easily (for example, given that your weight is normal, you can easily calculate your percentile from the mean and standard deviation). The normal distribution forms the basis of statistical inference. For this reason you should become very familiar with all the normal calculations I do from now on. As we will be using these ideas throughout the course. De<inition: Normal density Normal distributions are a family of symmetrical, bell-shaped density curves defined by a mean µ (mu) and a standard deviation σ (sigma). We denote a normal distribution by Normal(µ,σ) or N(µ,σ). The formula for the density curve is somewhat complicated: 1 f (x) = e σ 2π € 1 ⎛ x − µ ⎞ − ⎜ ⎟ 2 ⎝ σ ⎠ 2 x e = 2.71828… the base of the natural logarithm π = pi = 3.14159… x Examples of normal density curves Here, means are the same (µ = 15) while standard deviations are different (σ = 2, 4, and 6). 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 Here, means are different (µ = 10, 15, and 20) while standard deviations are the same (σ = 3). 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 Statcrunch practice p Making normal density plots in Statcrunch: Stat -> Calculators -> Select the normal distribution. p Here you can choose the mean and standard deviation and calculate the area on the left or right. p q Load the calf data into Statcrunch. Here see whether the calf weights is close to normally distributed. Graphics -> Histogram and select a weight variable (such as 8 weeks), select relative frequency (in Type options). In overlay distrib choose normal density (don’t give a mean or sd and it will use the sample mean and standard deviation of the data to create the normal curve). You will see the relative frequency histogram and the best fitting normal density (with the same mean and standard deviation as the data) overlaying the histogram. Remember this is just a sample, the fit won’t be perfect. The 68-95-99.7% Rule for Normal Distributions p About 68% of all observations are within 1 standard deviation (1×σ) of the mean (µ). p Inflection point About 95% of all observations are within 2×σ of the mean µ. p Almost all (99.7%) observations are within 3×σ of the mean. p Also called the empirical rule because it works approximately for data and many other distributions. e.g., typically 90%-99% of data are within two st. dev.’s of the mean. mean µ = 64.5 standard deviation σ = 2.5 Normal(µ, σ) = Normal(64.5, 2.5) Notation: µ (mu) is the mean of the idealized curve, while xis the mean of a sample. σ (sigma) is the standard deviation of the idealized curve, while s is the s.d. of a sample. Do the weights of 8 week calves satisfy the empirical rule? p p p Load the calf data into Statcrunch, and make a relative frequency histogram of the calf data (use the bin width, say, 5). Now calculate the mean and standard deviation of the calf data and construct the intervals (one standard deviation from the mean, two standard deviations from the mean, three standard deviations form the mean). And count the proportion of calves in these intervals. This is just a small sample, but it would appear that calf weights `roughly’ satisfy this rule. You are presented with an 8 week calf with weight 95 pounds. From the calculation (below) we see he is -2.8 standard deviations below the mean: 142.6 = 2.8 17 Assuming normality of weights, we see that event of a healthy calf having such a low weight is very small. May be he is unwell? = 17, p µ = 142.6, z= 95 Z-­‐scores and the normal density p p p p The z-scores (defined at the end of Chapter 3) for variables which are normally distributed are useful for calculating probabilities. Example: The heights of women tend to be normally distributed with mean 64.5 inches and standard deviation 2.5 inches. Question: A women has a height of 71 inches, is she exceptionally tall? Answer: Calculate how close she is to the mean but take into account the spread. This is the z-transform. p p The z-transform is z= (71 – 64.5)/2.5 = 2.6, which is 2.6 standard deviations to right of the mean. From the 68-95-99.7 rule we know because heights are close to normally distributed, that roughly 5% of women are more than 2 standard deviations from the mean. Therefore she has to be in the top 2.5% (5% divided by two) of heights. She is tall, but what is the exact percentile? To do this we need to calculate the area to the RIGHT of 71 on the density curve. The beauty of the z-score, is that it can be used to calculate the percentile. The zscore of a normal variable has a distribution which is well documented. The standard Normal distribution Because all Normal distributions share the same shape properties, we can standardize our data to transform any Normal(µ,σ) curve into the standard normal curve: Normal(0,1). Normal(0,1) Normal(64.5, 2.5) => x Standardized height (no units) For each x we calculate a new value, z-score. z The area under the normal curve p p The area between two points on a normal curve gives the chance of an even lying between those two points. The z-transform is a useful tool: p p Determining the number of standard deviations an observation is from the mean. If the data is normal for calculating probabilities. In the next few slides slides we explain how the z-transform can be used to calculate probabilities. However, an online area calculator is given here (see the normal calculator link at the end of page): http://onlinestatbook.com/2/normal_distribution/areas_normal.html p and also in Statcrunch (Go to Stat -> Calculations -> Normal) Calculation: Women heights N(µ, σ) = N(64.5, 2.5) Women’s heights follow the N(64.5", 2.5") distribution. What percent of women are shorter than 71 inches Area = ??? tall? mean µ = 64.5" standard deviation σ = 2.5" x (height) = 71" µ = 64.5” x = 67” z=0 z=1 Always draw a picture of your problem! We calculate z, the standardized value of x: z= x µ , z= 71 64.5 = 2.6 2.6 s.d. above the mean 2.5 To find the percent of women are shorter than 71 inches tall, we need to find the area to the left of z = 2.6. For this, we must use a special table. Using the standard Normal table Table A gives the area under the standard Normal curve to the left of any z value. .0082 is the area under N(0,1) left of z = -2.40 .0080 is the area under N(0,1) left of z = -2.41 (…) 0.0069 is the area under N(0,1) left of z = -2.46 Percent of women shorter than 71″ For z = 1, the area under the standard Normal curve to the left of z is 84.13% For z = 2.6, the area under Conclusion: 99.53% of women are shorter than 71". the standard Normal curve By subtraction, 1 – 0.9953, or 0.46% of to the left of 2.6 is 99.53%. women are taller than 71". Tips on using Table A Because the Normal distribution is symmetric, there are 2 ways that you can calculate the area under the standard Normal curve to the right of a z value. Area = 0.9901 Area = 0.0099 z = -2.33 area to right of z = area to left of –z area to right of z = 1 – area to left of z Tips on using Table A To calculate the area between two z- values, first get the area under Normal(0,1) to the left of each z-value from Table A. Then subtract the smaller area from the larger area. A common mistake made by students is to subtract the z values instead of subtracting the areas. The area between z1 and z2 is the area left of z1 minus the area left of z2. Calculation Practice: p Question: What is the chance of randomly selecting a female whose height lies between 60 to 70 inches? p Answer: Calculate the z-transform corresponding to 60 and 70. 64.5 70 64.5 = 1.8 z2 = = 2.2 2.5 2.5 Make a plot with these numbers of the x-axis. Using tables: z1 corresponds to 3.6% percentile and z2 corresponds to the 98.6% percentile. The probability of a height being between 60 and 70 inches is (98.6-3.6) = 95%. z1 = p p p 60 More Calculations: Scores in SATs One way to get admitted to A&M requires a score of at least 1300 on the combined critical reading and mathematics SAT exams. The SAT scores for 2010 were approximately normal with mean 1016 and standard deviation 212. What proportion of students taking the SAT in 2010 have this requirement? x = 1300 µ = 1016 = σ = 212 ( x − µ) σ (1300 − 1016) z= 212 284 z= ≈ 1.34 212 Table A: area under − z= N(0,1) to the left of z = 1.34 is 0.9099. area right of 1300 0.0901 = = total area 1 − − area left of 1300 0.9099 Approximately 9.1% of students scored at least 1300. Side note: The actual data may contain students who scored exactly 1300. However, the proportion of scores exactly equal to 1300 is zero for a normal distribution. Students are considered for (but not guaranteed) admission if they have a combined (CR + M) SAT score of at least 1100. What proportion of all students who took the SAT in 2010 have (only) this requirement? That is, what proportion have scores between 1100 and 1300? x = 1100 µ = 1016 σ = 212 ( x − µ) σ (1100 − 1016) z= 212 84 z= ≈ 0.40 212 Table A: area under = z= N(0,1) to the left of z = 0.40 is 0.6554. area between 1100 and 1300 0.2545 − = area left of 1300 − area left of 1100 = 0.9099 − 0.6554 Approximately 25.5% of students scored between 1100 and 1300. Comparing exams using percentiles p p p p There are various ways to gain entrance into A&M. We mentioned on the previous slide SATs, but there are ACTs too. The ACTs have a different scoring system to the SATs, these range from 1-36. How to compare students who have taken different exams? The easiest way is by comparing their percentiles, p p Example: student A is in the top 10% SAT scores whereas student B is in the top 5% ACT scores. Based on this information, student B did better in their exams. How to obtain these percentiles? Example: Suppose that SAT and ACT scores are close to normally distributed. SAT scores are almost normally distributed with mean 1025 and standard deviation 200, whereas ACT scores are almost (in reality this is not true, since the scores can only take only integer values) normally distributed with mean 20 and standard deviation 5. p Betty scores 1400 on her SATs, whereas Jon scores 31 on his ACT. Which student did `better’. Using z-­‐scores to compare grades p Answer: We first make a z-score for both Betty and Jon: p p q q q Betty’s z-score is z = (1400 -1025)/200 = 1.875 Jon’s z-score is z = (31-20)/5 = 2.2. Using the tables we see that Betty is in the 96.7 percentile, whereas Jon is in the 98.6 percentile. So Jon did slightly better than Betty, since only 1.4% of students did better than Jon, whereas 3.3% students did better than Betty. Equivalently, we can just compare z-transforms, Jon did slightly better as his grade is 2.2 standard deviations right of the mean, whereas Betty is 1.875 standard deviations right of the mean. Since 2.2>1.875, Jon did better. We can also translate Jon’s grade into a SAT grade using the ztransform. Since Jon is 2.2 standard deviations from the mean, this means if he took the SAT he would be 2.2 standard deviations from the SAT mean. Thus Jon’s translated SAT grade = 1025 + 200 ×2.2 = 1465. Do these calculations make sense? p p In the previous question we compared Betty’s SAT score with Jon’s ACT score by comparing their percentiles (by making the z-transform). However, in all statistical analysis we need to take a step back and ask ourselves whether the calculations were meaningful. Lets go through them step by step: p p p p p Comparing the percentiles for the grades in both exams is a reasonable thing to do. Its gives us an idea of where each student stands with respect to the other students who took the exam. The percentiles were calculated by first calculating the z-transform and then looking up the z-values in the normal tables. This means we have assumed that the distribution of grades for both SATs and ACTs are normally distributed. While it can be argued that SATs are normally distributed as its maximum score is 2100 (even though one can only take integer scores, there 2100 is so large it is possible it is normal – this can be checked by making a QQplot). The assumption that ACT grades are normally distributed is clearly wrong. ACT grades are numerical discrete variable which can only take integer grades between 1-36. Therefore, using the normal distribution to calculate the Jon’s ACT percentile is liable to give inaccurate probabilities. Comparing normal approx. with the true probability Left, is the true distribution of ACT grades. By counting the height of the blocks which less than or equal to 31, we see that scoring 31 puts Jon in the 89% (percentile). This is the true probability. Comparing this to the normal approximation of 98.6% we see that using the normal approximation over estimated the percentile. In statistical inference we often calculate probabilities under the assumption of normality. We need to be mindful that these are approximations and the probabilities may not be correct. A calculation using the wrong distribution will give the wrong result. Calculation Practice p A farmer wants to enter either his cow or pig for the heaviest animal competition. The winning animal is the heaviest animal in its category (cows or pigs). It is known that the weight of cows is approximately normally distributed with mean 280 pounds and standard deviation 20 pounds (N(280,20)) and the weight of pigs is approximately normally distributed with mean 250 pounds and standard deviation 50 pounds (N(250,50)). His prize cow weighs 330 pounds and prize pig weighs 310 pounds. The contest only allows one animal per farmer, which animal should he enter? q q q q It makes sense to see how heavy the animal is relative to its species. The z-score for the cow = (330-280)/20 = 2.5 standard deviations from the mean. This corresponds to the 99.3% percentile. The z-score for the pig is (310-250)/50 = 1.2 this corresponds to the 88.4 percentile. Despite the pig’s weight lying further from the mean, there is a lot of variation in pig weight. The farmer should enter the cow, since only 0.7% of cows are heavier than her. Calculations based on the plot p Suppose we want to calculate the chance of randomly selecting a calf, whose weights at 0.5 weeks is less than 90 pounds. To calculate this chance, we need to know from what population we randomly selecting the calf. Probability calculations p p If we are selecting the calf from just our sample (the 44 calves that we were observing), then the chance is simply the sum of the heights of the bins less than 90, that is: § 0.341+0.159+0.068 = 0.568. Hence there is a 56.8% chance of selecting a calf from the sample of 44 which is less than 90 pounds (at week 0.5). On the other hand if we are sampling from the from the population of the calves, we need to use the density plot of the population to find the chance. If we believe density plot of calves is close to normal density plot, then we calculate the probability using z-transforms: § The mean and standard deviation of the density plot is 90.11 and 7.7 respectively. Thus to calculate the probability we make a z-transform z = (90 - 90.11)/7.7 = -0.014. Looking this up on the tables gives a probability very close to 0.49. Hence, assuming the density plot of calf weights are normal the chance of randomly selecting a calf from the population of calves which is less than 90 pounds is 49%. Inverse normal calculations We may also want to find the observed range of values that correspond to a given proportion/ area under the curve. For that, we use Table A backward: p We first find the desired area/ proportion in the body of the table. p We then read the corresponding z-value from the left column and top row. For an area of 1.25% (0.0125) to the left of z, the z-value is −2.24. Example: Female heights p p Female heights tend to be normally distributed with N(64.5,2.5). Questions: p p p p (a) How tall is a female in the 75% percentile? (b) How tall is a female who is in the top 10% percentile? (c) How tall is a female who is in the bottom 2.5% percentile? Answers: p p p (a) Look up 0.75 inside the z-table – 0.674. This means that someone who is in the 75 percentile is 0.674 standard deviations to the right of the mean. That person is 64.5 + 0.674×2.5 = 66.2 inches tall. (b) Top 10% = 90% percentile. Look up 0.9 in the z-table – 1.28. Using the same argument as above that person is 64.5 + 1.28×2.5 = 67.7 inches tall. (c) Look up 0.025 in the z-tables – 1.96. Using the same argument as above that person is 64.5 -1.96×2.5 = 59.6 inches tall. p q q (a) (b) (c) p Question: Construct an interval centered about the mean, where 95% of female heights lie. p p p p Answer: Look up 2.5% and 97.5% in z-tables – [-1.96, 1.96]. This means that 95% of heights will lie between 1.96 standard deviations (either way) from the mean. Translating this into heights. 95% of heights lie between [64.5 -1.96×2.5, 64.5 + 1.96×2.5] = [59.6,69.4] inches. Observe and compare 1.96 standard deviations from the mean to the 68-95-99.7% rule which corresponds to 1 standard deviation, 2 standard deviation and 3 standard deviations from the mean. p 2 standard deviations is in fact an approximation of 1.96 standard deviations from the mean. Using QQplots to check normality of data p p p p p By simply superimposing a normal distribution over a histogram it is very hard to see how close to normal the data is. Typically to check for normality of data we make a QQplot. The idea is behind the plot is similar to checking the 68-95-99.7% but extended to all multiples of the standard deviation not just 1,2, and 3. The data is close to normality if the points lie along the x=y line. In the following few slides we consider a few examples: QQplot of normal data Observe that most points lie close to x=y line. There are a few which lie far away. QQplot of right skewed data For right skewed data the Qqplot has a U-type shape QQplot for left skewed data QQplot for left skewed data looks like an inverted U QQplot for uniform data QQplot for uniform and thick tailed data (data whose tails are not much thinner than the center) have an S shape. QQplot for binary response data In this data set, the response is either 0 or 1. The vertical lines correspond to each of these responses. QQplot of calf data The horizontal lines we see are due to several weights having the same value (due to rounding). Eg. The first horizontal line corresponds to 5 calves with the same weight. The weights are not exactly normal, but it does not deviate massively from normality. Accompanying problems associated with this Chapter p p p Quiz 4 Quiz 4 – parts 2 Homework 2