ETAP Project Status Report December 2000
advertisement

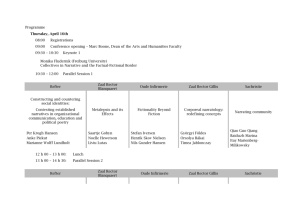
23 Reports from the ETAP project Editor: Lars Borin ETAP Project Status Report December 2000 Lars Borin with contributions by others p eta research report etap-rr-06 2000 ETAP project status report December 2000 Lars Borin with contributions by Camilla Bengtsson Maria Borg Sephorah Graves Camilla Löfling Leif-Jöran Olsson Gustav Öquist Henrik Oxhammar Susanne Viestam WP CL&LE 23 The ETAP project Research reports ETAP is short for Etablering och annotering av parallellkorpus för igenkänning av översättningsekvivalenter (“Creating and annotating a parallel corpus for the recognition of translation equivalents”). The basic aim of the project is to develop a computerized multilingual translation corpus, made up of Swedish source text representing different styles and domains, together with its translations into several languages, which can be used in bilingual lexicographic work and in methodological studies directed towards the development and evaluation of corpus formats and computational tools for the automatic recognition and extraction of translation equivalents from text. The project is part of the research programme Översättning och tolkning som språk- och kulturmöte (“Translation and Interpreting—a Meeting between Languages and Cultures”), financed by the Bank of Sweden Tercentenary Foundation. This research programme “. . . started in 1996. It involves a great variation of research topics within the domain of translation and interpreting and has an overall aim of seeing translation and interpreting as activities that are related not only to linguistic and textual aspects but to cultural, historical, social and communicative phenomena as well. [It℄ is a result of a collaboration between two big and well-known Swedish universities, Stockholm University and Uppsala University.” (From the WWW homepage of the programme: <http://www.translation.su.se/abstract.html>) WWW: http://stp.ling.uu.se/etap/ etap-rr-04 ( WP CL & LE 21) ETAP research reports 2000: Seeing double: using parallel corpora for linguistic research Papers by Borin, Olsson, Prütz etap-rr-05 ( WP CL & LE 22) Segmenting and tagging parallel corpora Papers by Bengtsson, Borin, Oxhammar etap-rr-06 ( WP CL & LE 23) ETAP project status report December 2000 Lars Borin, with contributions by others ETAP project status report December 2000 Lars Borin with contributions by Camilla Bengtsson Maria Borg Sephorah Graves Camilla Löfling Leif-Jöran Olsson Gustav Öquist Henrik Oxhammar Susanne Viestam 1 Introduction ETAP is the acronym of the project title “Etablering och annotering av parallellkorpus för igenkänning av översättningsekvivalenter”' (in English: “Creating and annotating a parallel corpus for the recognition of translation equivalents”). This project is a part of a joint research programme between the universities in Stockholm and Uppsala, Translation and Interpreting – A Meeting between Languages and Cultures financed by the Bank of Sweden Tercentenary Foundation (Riksbankens Jubileumsfond); see <http://ww.translation.su.se>, Översättning 1995, 1998, and Svane 1996. The project started in 1996, and will go on with the present funding until the end of 2001. The main goal of the project, ever since it was formulated in 1995 (Sågvall Hein 1995), has been the creation of a corpus of annotated parallel texts. This corpus, as it appears at the time of writing of this report, consists of a number of subcorpora, described below. Common to all the subcorpora is that Swedish is one of the languages in the subcorpus, normally the source language (SL), typically combined with more than one other language, mostly in the role of target languages (TL), i.e. translated from the SL. The annotations made on the ETAP texts are of three kinds, (1) SGML or XML markup of sentences, paragraphs, etc., (2) part-of-speech (POS) tags, i.e., an annotation for each text token (words and punctuation marks), showing its word class and possibly morphological information, and (3) sentence and word alignment, i.e., the establishment of explicit ‘links’ between equivalent units—sentences and words/phrases, respectively —in the two language versions making up the parallel text (see section 3.2, below). The work towards the main project goal has included a fair amount of groundwork on capturing, converting and cleaning up texts delivered in various formats on various media (section 3.1). The annotation (tagging and alignment) of the texts has also—both by necessity and choice—prompted some methodological work on tagging and alignment, as well as general software development; especially, we would like to point to the development of interactive web-based software for viewing and searching aligned parallel texts (section 4). The work and results of the ETAP project have been reported in a number of contexts. Research reports (the present status report being one), conference and symposium 1 2 Borin, with contributions by others presentations, and a number of scientific publications have been produced by project members (section 5). Overlapping with the ETAP project in time, in goals and in people, there has been another parallel corpus project going on in the Department of Linguistics, the PLUG project (Parallel corpora in Linköping, Uppsala, Göteborg; see Sågvall Hein 1999). This has made possible the sharing of resources, such as corpora (section 3) and software (section 4), as well as ideas—at regular joint “corpus project meetings”—between the two projects. ETAP project researchers and technical staff have acted in the capacity of consultants on matters relating to (parallel) corpus processing for other projects in the Translation Programme, viz. projects no. 9 (Magnusson 1998), 6 (Jonasson 1998), and 13 (Wande 1998). This status report was written by Lars Borin, with the inclusion of (edited) material from work reports submitted by project co-workers Camilla Bengtsson, Maria Borg, Sephorah Graves, Camilla Löfling, Leif-Jöran Olsson, Gustav Öquist, Henrik Oxhammar and Susanne Viestam (see section 2). ETAP status report December 2000 2 3 ETAP people The following people have at various times been working in the ETAP project in different capacities. Many of them are students in the department’s Language Engineering Programme (“LE student” in the list), who have been employed in the project for a specific task or for a short time period (1–2 months). name role / task Kristina Apelqvist Anna Andjic LE student / Finnish IVT (section 3.3), 1998 LE student / Serbian-Bosnian-Croatian IVT (section 3.3), 1998 LE student / Spanish IVT (section 3.3), tagger evaluation (section 3.2), 1999 LE student / tagging (section 3.2), 2000 researcher / research, 1996–97; PI, 1998–2000 research engineer / software development and systems support, 1996– LE student / Finnish IVT (section 3.3), 1998 LE student / tagging (section 3.2), 2000 LE student / software development, 2000 LE student / English IVT, text conversion (section 3.3); sentence and word alignment (section 3.2), 1999 LE student / tagger training (section 3.2), 1997 project assistant / software development, 1999– LE student / software development, 1999 project assistant / software development, 1999 Ph.D. student / research on tagging and translationese, 1996–2000 researcher / research on tagging, 1996–97 researcher / PI, 1996–97, 2001– research engineer / software development and systems support, 1996– LE student / PKS99 website building and maintenance (section 5.1), 1999 researcher / text conversion and markup (section 3.1), sentence alignment (section 3.1) 1996–98 LE student / English IVT, text conversion (section 3.3); sentence and word alignment (section 3.2), 1999 LE student / Finnish IVT (section 3.3), 1998 LE student / Polish IVT (section 3.3), 1998 Camilla Bengtsson Maria Borg Lars Borin Bengt Dahlqvist Anna Eklund Sephorah Graves Mattias Lingdell Camilla Löfling Stina Nylander Leif-Jöran Olsson Gustav Öquist Henrik Oxhammar Klas Prütz Hong Liang Qiao Anna Sågvall Hein Per Starbäck Sten Thaning Erik Tjong Kim Sang Susanne Viestam Satu Ylinen Natalia Zinovjeva 4 Borin, with contributions by others 3 The ETAP corpus 3.1 Text collection and markup Generally, the ETAP texts go through a number of processing stages. First, they are captured, which may mean that the publisher provides the text in a machine-readable format, but which also may imply keying or scanning in the texts from a printed version. Both capturing methods have been used for the ETAP texts. In the first case, conversion routines may have to be written for conversion from whatever word processing format the texts are provided in. In the second case, the texts will need proofreading. After capture, the texts are segmented into sentences and larger units, such as articles, pages, and paragraphs (by no means a trivial task; see Grefenstette and Tapanainen 1994; Tjong Kim Sang 1999a; Oxhammar and Borin 2000), and provided with markup. In the ETAP texts, two markup schemes have been used: TEI LITE SGML (Tjong Kim Sang 1999a) and PLUG XML (Tiedemann 1999). 3.2 Text annotation For the ETAP texts, annotation consists of part-of-speech (POS) tagging, sentence alignment and word alignment. In the project, we have explored the methodology of these annotation steps. Sentence alignment is done with a method due to Gale and Church (1994; see Tjong Kim Sang 1999b), and word alignment with the Uppsala Word Aligner (UWA), developed by Tiedemann (2000) in the PLUG project. The UWA presupposes sentence aligned input. In ETAP, the main contribution to word alignment methodology has been that of pivot alignment (Borin 2000a, 2000b), i.e. the use of additional parallel texts for enhancing bilingual word alignment, but the role of word similarity for word alignment has also been investigated (Borin 1998). POS tagging is done with existing (free) taggers; it is not within the brief of the project to train taggers for all the ETAP corpus languages. Swedish has been a special case, however; here, Prütz (1999a, 1999b) has experimented with training a Swedish Brill tagger using tagsets of differing granularity. The two main contributions of the ETAP project to tagging methodology have been, (1) the exploration of linguistically motivated combination of taggers, as opposed to the classifier combination schemes normally encountered in the literature on tagger combination (Qiao 1999; Bengtsson et al 2000; Borin 2000c, to appear), and (2) the use of a POS tagged SL text and word alignment for (partially) tagging a TL text for which no tagger is available (Borin 1999). ETAP status report December 2000 3.3 5 The ETAP subcorpora: processing status The ETAP corpus material currently consists of 5 subcorpora, in various stages of processing (see section 3.3). Here, we give a brief characteristic of each subcorpus, including an account of the processing stages it has gone through, indicating what has been done with the material and what still remains to be done. (1) ETAP subcorpus SGP This is the Swedish Statement of Government Policy, issued by each new Swedish government in a number of language versions simultaneously. This small subcorpus has been part of the joint ETAP/PLUG corpus for a long time, and it is completely processed. (2) ETAP subcorpus EU ETAP subcorpus EU consists of legislative EU text in Swedish and German. It was provided by Bettina Jobin (see section 3.3) in machine-readable form in 1998 (German umlauts are written <ae> and <oe>). It is not known which text is the SL, although it is probably not the Swedish. This small subcorpus is completely processed. (3) ETAP subcorpora IVT1 and IVT2 ETAP subcorpora IVT1 and IVT2 consist of articles from issues 1–25 1997 (half a year’s worth) of Invandrartidningen, a periodical for immigrants published by the Invandrartidningen Foundation (Stiftelsen Invandrartidningen), which graciously put this text material at our disposal. Invandrartidningen is published in 8 languages: Arabic, English, Finnish, Persian, Polish, Serbian-Bosnian-Croatian, Spanish, and easy Swedish. All these versions are produced by translation (adaptation in case of easy Swedish) from an original which itself is not published, even though it is produced in a desktop publishing program as if it would be. The Invandrartidningen Foundation have provided us with the Swedish original text in addition to the published language versions. A smaller portion of the material—issues 21–25 of some language versions— came in machine-readable form, provided as PageMaker documents, but most of the the material was captured by scanning and subsequent proofreading. Thus, in 1998, issues 1–20 1997 of the Finnish version were captured by the LE students Kristina Apelqvist, Anna Eklund and Satu Ylinen, the same issues of the Swedish original by LE student Anna Eklund, of the Polish version by LE student Natalia Zinovjeva, and of the Serbian-Bosnian-Croatian version by LE student Anna Andjic. In 1999, issues 1–20 of the Spanish version were scanned and proofread by Camilla Bengtsson, and the same issues of the English version by Camilla Löfling and Susanne Viestam, all LE students. Issues 21–25 of the English, Finnish, Polish, Serbian-Bosnian-Croatian, Spanish and Swedish versions were converted from PageMaker format to Unix text files by Susanne Viestam and Camilla Löfling in 1999. The IVT texts are almost completely processed. The Finnish, Polish and Serbian-Bosnian-Croatian texts are not POS tagged. On the other hand, the IVT1 subcorpus goes beyond ‘complete processing’, in that it is exhaustively cross-aligned on the sentence and word levels, i.e. all language versions are aligned with all other language version, in both directions (normally, ‘complete processing’ is understood to include only alignments Swedish–other languages). This is because the IVT1 corpus was used for the experiments with pivot alignment (Borin 2000a, 2000b). The Arabic and Persian language versions have not been processed at all, and the version in easy Swedish was not considered for inclusion, because it does not stand in a translation relation sensu stricto to the Swedish original. 6 Borin, with contributions by others (4) ETAP subcorpora Scania 1995 and Scania 1998 The Scania texts consist of maintenance manuals and user guides for the products of Swedish truck manufacturer Scania AB. These subcorpora are shared with the PLUG project. The texts were provided in machine-readable form, as FrameMaker documents, which were subsequently converted by Erik Tjong Kim Sang (1999a) to Unix text files. The Swedish version has been aligned with some of the other language versions by Jörg Tiedemann in the PLUG project. Several, but not all, language versions have been POS tagged in the ETAP project. (5) ETAP subcorpus Sienkiewicz The Sienkiewicz subcorpus consists of polish literary texts by classical Polish author Henryk Sienkiewicz, together with their Swedish translations. The texts have been provided by Ewa Gruszczynska (see section 3.3). They have undergone no processing so far. 3.3 The ETAP subcorpora at a glance Abbreviations used in the tables Languages SE DE EN ES FI FR IT NL PL SBC Swedish German English Spanish Finnish French Italian Dutch Polish Serbian–Bosnian–Croatian Taggers A B M Prütz Tn TT Alignment Other W S (p) word alignment sentence alignment Amalgam (Atwell et al. 2000) Brill tagger (Brill 1995) Memory Based Tagger (Daelemans et al. 1994) Klas Prütz’s Swedish Brill tagger (Prütz 1999a, 1999b) TnT (Brants 2000) TreeTagger (Schmid 1994) partially (tagged/aligned) (1) ETAP subcorpus SGP Text type: political-administrative Total size: 19,000 words Source language: SE Target languages: DE, EN, FR Remarks: Shared corpus with the PLUG project language(s) SE (SE–)DE (SE–)EN (SE–)FR words 5210 4250 4490 5220 tagged with Prütz, M M, TT, Tn B, TT, Tn, M, A TT alignment — S, W S, W S, W ETAP status report December 2000 7 (2) ETAP subcorpus EU Text type: political-administrative Total size: 56,500 words Source language: ? Target languages: ? Remarks: From project no. 9 in the Translation Programme (see Magnusson 1998), provided by Bettina Jobin. Texts are in translation relation, but the source language is not known; probably not SE. language(s) SE (SE–)DE words 28088 28565 tagged with Prütz, M M, TT, Tn alignment — S, W (3) ETAP subcorpora IVT1 and IVT2 The Polish and Serbian-Bosnian-Croatian texts in the IVT subcorpora use a custom character encoding. Instead of Latin-2 (ISO 8859–2), a modified Latin-1 (ISO 8859–1) representation is used, so that all the currently processed IVT texts use the same ISO 8859 subset. The following table shows the coding used (for all languages in the IVT subcorpora except English). Polish ą, Ą ć, Ć S-B-C Spanish Swedish Finnish ä,Ä á,Á å,Å ä,Ä á,Á ć, Ć č, Č đ, Đ ę, Ę é,É í,Í ł, Ł ń, Ń ó,Ó é,É ñ,Ñ ó,Ó ö,Ö ś, Ś š, Š ú, Ú ź, Ź ż, Ż ž, Ž ¡ ¿ ö,Ö Latin-1 (char code) â (126), Â (194) å (229), Å (197) ä (228), Ä (196) á (225), Á (193) þ (254), Þ (222) ç (231), Ç (199) ð (240), Ð (208) ê (234), Ê (202) é (233), É (201) í (237), Í (205) £ (163), ÷ (247) ñ (241), Ñ (209) ó (243), Ó (211) ö (246), Ö (214) ¢ (162), © (169) ú (250), Ú (218) § (167), ¬ (172) $ (36), ® (174) ¡ (161) ¿ (191) 8 Borin, with contributions by others (3:1) ETAP subcorpus IVT1 Text type: newstext Total size: 470,000 words Source language: SE Target languages: EN, ES, PL, SBC Remarks: — language(s) SE (SE–)EN (SE–)ES (SE–)PL (SE–)SBC EN–ES EN–PL EN–SBC EN–SE ES–EN ES–PL ES–SBC ES–SE PL–EN PL–ES PL–SBC PL–SE SBC–EN SBC–ES SBC–PL SBC–SE words 85736 105492 107047 81988 90750 — — — — — — — — — — — — — — — — tagged with Prütz, M B, TT, Tn, M, A M — — — — — — — — — — — — — — — — — — alignment — S, W S, W S, W S, W S, W S, W S, W S, W S, W S, W S, W S, W S, W S, W S, W S, W S, W S, W S, W S, W (3:2) ETAP subcorpus IVT2 Text type: newstext Total size: 63,000 (SE + FI; total about 200,000) Source language: SE Target languages: EN, ES, FI, PL, SBC Remarks: IVT2 is wholly included in IVT1 except for the FI texts. language(s) SE (SE–)EN (SE–)ES (SE–)FI (SE–)PL (SE–)SBC tokens 35465 n.a. n.a. 27516 n.a. n.a. tagged with Prütz, M B, TT, Tn, M, A M — — — alignment — — — S, W — — ETAP status report December 2000 9 (4:1) ETAP subcorpus Scania 1995 Text type: technical (workshop manuals) Total size: 1.66 million words Source language: SE Target languages: DE, EN, FR Remarks: Shared corpus with the PLUG project. Aligned by Jörg Tiedemann in the PLUG project. language(s) SE (SE–)DE (SE–)EN (SE–)ES (SE–)FI (SE–)FR (SE–)IT (SE–)NL words 220248 184588 222211 220631 143381 234467 233791 201289 tagged with Prütz, M TT, Tn B, TT, Tn, M — — TT — — alignment — S, W S, W S S S S S (4:2) ETAP subcorpus Scania 1998 Text type: technical (workshop manuals) Total size: 2.7 million words (SE + EN) Source language: SE Target languages: DE, EN, ES, FR, IT, NL Remarks: Scania 1998 is a PLUG project corpus, which has been part-of-speech tagged in the ETAP project. language(s) SE (SE–)DE (SE–)EN (SE–)ES (SE–)FR (SE–)IT (SE–)NL words 1542729 n.a. 1183512 n.a. n.a. n.a. n.a. tagged with Prütz, M TT, TnT B, TT, Tn, M M TT TT M alignment — S (p) S, W — — S (p) — (5) ETAP subcorpus Sienkiewicz Text type: literary/fiction Total size: not known Source language: PL Target languages: SE Remarks: From project no. 4 of the Translation Programme (see Gustavsson 1998). So far only unprocessed text in word processor format provided by Ewa Gruszczynska. language(s) PL (PL–)SE words tagged with ? — ? — alignment — — 10 4 Borin, with contributions by others ETAP method and software development ETAP method and software development has been concentrated in three areas: (1) text tokenization; (2) annotation, i.e. alignment and POS tagging; (3) (computational) linguistic use of parallel corpora. In the area of text tokenization, Oxhammar and Borin (2000) have investigated ways of improving sentence splitting algorithms. See also section 3.1, above. The methodological work done in the ETAP project in the areas of alignment and POS tagging has already been mentioned in section 3.2, above. As for the (computational) linguistic use of parallel corpora, we have developed tools for browsing and searching word-aligned parallel texts, but also explored ways of using the POS tagged ETAP corpus for more sophisticated linguistic investigations than can be done on unannotated texts, i.e. conventional corpora. Figure 1: Visualising the distribution of a particular word alignment in the Swedish– Finnish IVT2 ETAP subcorpus (from Olsson and Borin 2000) ETAP status report December 2000 11 The ETAP–WebTEq alignment browser (Olsson and Borin 2000) was developed specifically for browsing word-aligned parallel corpora, and thus represents a further development in comparison to existing parallel corpus browsers, e.g. those described by Ebeling (1998) and Tiedemann (p.c.; see <http://stp.ling.uu.se/~corpora/plug/> and Sågvall Hein 1999), which work with sentence-aligned corpora. ETAP–WebTEq at present allows word searches, as illustrated in Figure 1. The figure shows the graphical interface, which provides a quick overview of the search results. Each square in the figure represents one sentence alignment unit, and those units which contain the word alignment in question are shown in a different colour from the rest (yellow instead of grey; in Figure 4, there is one yellow square, in the third row from the top), and if clicked, show the actual sentence alignment unit, as in the example in Figure 2, where the sentence alignment units containing the word alignments for the word “svensk” (Swedish; Swede) in the Swedish–Finnish IVT2 ETAP subcorpus. The kind of overview illustrated in Figure 1 in combination with the more detailed information in Figure 2 is valuable for many reasons, e.g. for finding thematically defined parts of the corpus, but also for isolating systematic failures in the word alignment software. Figure 2: Details of the word alignments for “svensk” (Swede; Swedish) in the Swedish–Finnish IVT2 ETAP subcorpus with ETAP–WebTEq (from Olsson and Borin 2000) 12 Borin, with contributions by others As a small illustration of the kinds of linguistic investigations made possible by the existence of annotated parallel corpora, Borin and Prütz (2000) show that the so-called ‘translationese’ phenomenon (Gellerstam 1985) can profitably be investigated not only as a phenomenon on the lexical level—which has been done frequently with the use of unannotated corpora, both by Gellerstam and others (e.g. Johansson and Hofland 1994; Johansson forthcoming)—but also on the syntactic level. In this investigation, using the ETAP IVT1 subcorpus, a word class distributional influence was discernible in the English IVT newstext (a translation from Swedish), as compared to original British and American English newstext. ETAP status report December 2000 5 ETAP conference presentations and publications 5.1 Conference presentations 13 The results of the research done in the ETAP project have been presented at a number of national and international conferences and symposia, notably the Nordic biennal Computational Linguistics conference (Nodalida – 1998: nos. 1 and 10; 1999: no. 5) and the international COLING (no. 7) and LREC (no. 6) Computational Linguistics conferences. (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) Borin, Lars. Linguistics isn't always the answer: Word comparison in computational linguistics. The 11th Nordic Conference on Computational Linguistics – NODALIDA '98, Copenhagen, 28–29 January 1998. Borin, Lars. Alignment and tagging. PKS99 – Symposium on parallel and comparable corpora, Uppsala, 22–23 April 1999. Borin, Lars. ETAP-projektet. PKS99 – Symposium on parallel and comparable corpora, Uppsala, 22–23 April 1999. Borin, Lars. Enhancing tagging performance by combining knowledge sources. ASLA-symposiet Korpusar i forskning och undervisning – KORFU 99, Växjö 11–12 November 1999. Borin, Lars. Pivot alignment. The 12th ”Nordiske datalingvistikkdager” – NODALIDA ’99. Trondheim, 9–10 December 1999. Borin, Lars. Something borrowed, something blue: Rule-based combination of part-of-speech taggers. Second International Conference on Language Resources and Evaluation – LREC 2000. Aten, 31 May – 2 June 2000. Borin, Lars. You'll take the high road and I'll take the low road: Using a third language to improve bilingual word alignment. The 18th International Conference on Computational Linguistics – COLING 2000. Saarbrücken, 31 July – 4 August 2000. Borin, Lars and Klas Prütz. Through a glass darkly: Part of speech distribution in original and translated text. Computational Linguistics in the Netherlands – CLIN 2000, Tilburg, 3 November 2000. Olsson, Leif-Jöran and Lars Borin. A web-based tool for exploring translation equivalents on word and sentence level in multilingual parallel corpora. 20th VAKKI Symposium, Vaasa, 12–13 February 2000. Prütz, Klas. Evaluation of the syntactic parsing performed by the ENGCG parser. The 11th Nordic Conference on Computational Linguistics – NODALIDA '98, Köpenhamn, 28–29 January 1998. Prütz, Klas. Part-of-speech tagging for Swedish. PKS99 – Symposium on parallel and comparable corpora, Uppsala, 22–23 April 1999. Further, a symposium on parallel and comparable corpora (PKS99) was arranged at Uppsala University in April 1999 as part of the ETAP project activities, with additional funding from the Faculty of Languages, Uppsala University and the research programme Translation and Interpreting – A Meeting between Languages and Cultures. The symposium attracted speakers from Finland, Great Britain, Norway and Sweden. A volume containing selected contributions to the symposium is in preparation and will be 14 Borin, with contributions by others published by Rodopi in 2001 (see section 5.2.3, below). Here, we reproduce the program of the symposium: Thursday, 22nd April 1999 9.00 REGISTRATION 10.00 Introduction Lars Borin 10.20 Invited speaker: Multilingual corpusbased extraction Gregory Grefenstette 11.00 From parallel corpus to semantic representations Helge Dyvik 11.30 The English-Norwegian parallel corpus: Current work and new directions Stig Johansson 12.00 PLUG-projektet (The PLUG project) Anna Sågvall Hein 12.30 LUNCH 14.00 The PLUG link annotator—interactive construction of data from parallel corpora Magnus Merkel, Mikael Andersson and Lars Ahrenberg 14.30 The lexical profile of Swedish reflected in parallel corpus data Åke Viberg 15.00 The INTERSECT project Raphael Salkie 15.30 Building parallel texts Peter Stahl 16.00 BREAK 16.30 Uplug - a modular corpus tool for parallel corpora Jörg Tiedemann 17.00 ETAP-projektet (The ETAP project) Lars Borin 20.00 SYMPOSIUM DINNER Friday, 23rd April 1999 9.00 Parallelle korpora som verkty for utvikling av minoritetsspråk, med samisk som eksempel (Parallel corpora as tools for investigating and developing minority languages: The case of Sámi) Trond Trosterud 9.30 How can linguists profit from parallel corpora? Raphael Salkie 10.00 The English-Swedish Parallel Corpus (ESPC) Karin Aijmer and Bengt Altenberg 10.30 PARTITUR: Att bygga, bearbeta och utnyttja parallellkorpusar (PARTITUR: Building, processing, and using parallel corpora) Mattias Agnesund, Mia Boström Aronsson, Pernilla Danielsson, Anna-Lena Fredriksson, Katarina Mühlenbock, P-O Nilsson, Lene Nordrum, Kristina Svensson and Annelie Ädel 11.00 BREAK 11.30 Alignment and tagging Lars Borin 12.00 Reversing a Swedish-English dictionary for the Internet Christer Geisler 12.30 LUNCH 14.00 Ordklasstaggning på svenska (Part of speech tagging for Swedish) Klas Prütz 14.30 Personbeteckningar i jämförbara och parallella korpora. Några exempel på lingvistiska resultat av kontrastiva korpusstudier tyska-svenska (Words denoting persons in comparable and parallel corpora. Some linguistic findings from contrastive German-Swedish corpus studies) Bettina Jobin 15.00 Uppsala Student English Project (USE) Margareta Westergren Axelsson and Ylva Berglund 15.30 En muntlig inlärarkorpus inom projektet LINDSEI (A learner corpus of spoken language: The LINDSEI project) June Miliander 16.00 Conclusion ETAP status report December 2000 5.2 15 Publications 5.2.1 Research reports (1) (2) (3) (4) (5) (6) etap-rr-01 1999 = Sågvall Hein, Anna (ed.). Reports from the ETAP project: Converting, aligning and tagging for ETAP. Papers by Erik Tjong Kim Sang, Hong Liang Qiao. Working Papers in Computational Linguistics & Language Engineering 18. Department of Linguistics, Uppsala University. etap-rr-02 1999 = Sågvall Hein, Anna (ed.). Reports from the ETAP project. Klas Prütz: Sammanställning av en träningskorpus på svenska för träning av ett automatiskt ordklasstaggningssystem. Working Papers in Computational Linguistics & Language Engineering 19. Department of Linguistics, Uppsala University. etap-rr-03 1999 = Borin, Lars (ed.). Reports from the ETAP project: Tagging and alignment. Papers by Lars Borin, Klas Prütz. Working Papers in Computational Linguistics & Language Engineering 20. Department of Linguistics, Uppsala University. etap-rr-04 2000 = Borin, Lars (ed.). Reports from the ETAP project: Seeing double: using parallel corpora for linguistic research. Papers by Lars Borin, Leif-Jöran Olsson and Klas Prütz. Working Papers in Computational Linguistics & Language Engineering 21. Department of Linguistics, Uppsala University. etap-rr-05 2000 = Borin, Lars (ed.). Reports from the ETAP project: Segmenting and tagging parallel corpora. Papers by Camilla Bengtsson, Lars Borin, Henrik Oxhammar. Working Papers in Computational Linguistics & Language Engineering 22. Department of Linguistics, Uppsala University. etap-rr-06 2000 = Borin, Lars (ed.). Reports from the ETAP project. Lars Borin, with contributions by others: ETAP project status report December 2000. Working Papers in Computational Linguistics & Language Engineering 23. Department of Linguistics, Uppsala University. 5.2.2 Research reports, individual articles (1) (2) (3) Bengtsson, Camilla, Lars Borin and Henrik Oxhammar 2000. Comparing and combining part of speech taggers for multilingual parallel corpora. In: Lars Borin (ed.), Working Papers in Computational Linguistics & Language Engineering 22. Reports from the ETAP project: Segmenting and tagging parallel corpora. Department of Linguistics, Uppsala University. Borin, Lars 1999. Alignment and tagging. In: Lars Borin (ed.), Working Papers in Computational Linguistics & Language Engineering 20. Reports from the ETAP project: Tagging and alignment. Department of Linguistics, Uppsala University, 1–10. Borin, Lars 2000 (with contributions by others). ETAP project status report December 2000. In: Lars Borin (ed.), Working Papers in Computational Linguistics & Language Engineering 23. Reports from the ETAP project. Department of Linguistics, Uppsala University. 16 Borin, with contributions by others (4) Borin, Lars and Klas Prütz 2000. Through a glass darkly: Part of speech distribution in original and translated text. In: Lars Borin (ed.), Working Papers in Computational Linguistics & Language Engineering 21. Reports from the ETAP project: Seeing double: using parallel corpora for linguistic research. Department of Linguistics, Uppsala University. 9–30. Olsson, Leif-Jöran and Lars Borin 2000. ETAP–WebTEq: a web-based tool for exploring translation equivalents on word and sentence level in multilingual parallel corpora. In: Lars Borin (ed.), Working Papers in Computational Linguistics & Language Engineering 21. Reports from the ETAP project: Seeing double: using parallel corpora for linguistic research. Department of Linguistics, Uppsala University. 1–8. Oxhammar, Henrik and Lars Borin 2000. Sentence splitting and SGML tagging of the ETAP corpora. In: Lars Borin (ed.), Working Papers in Computational Linguistics & Language Engineering 22. Reports from the ETAP project: Segmenting and tagging parallel corpora. Department of Linguistics, Uppsala University. Prütz, Klas 1999. Sammanställning av en träningskorpus på svenska för träning av ett automatiskt ordklasstaggningssystem. In: Anna Sågvall Hein (ed.), Working Papers in Computational Linguistics & Language Engineering 19. Reports from the ETAP project. Department of Linguistics, Uppsala University, 1–15. Prütz, Klas 1999. Part-of-speech tagging for Swedish. In: Lars Borin (ed.), Working Papers in Computational Linguistics & Language Engineering 20. Reports from the ETAP project: Tagging and alignment. Department of Linguistics, Uppsala University. 11–15. Qiao, Hong Liang 1999. Comparing the tagging performance between the AGTS and Brill taggers. In: Anna Sågvall Hein (ed.), Working Papers in Computational Linguistics & Language Engineering 18. Reports from the ETAP project: Converting, aligning and tagging for ETAP. Department of Linguistics, Uppsala University, 1–9. Tjong Kim Sang, Erik 1999. Converting the SCANIA Framemaker documents to TEI SGML. In: Anna Sågvall Hein (ed.), Working Papers in Computational Linguistics & Language Engineering 18. Reports from the ETAP project: Converting, aligning and tagging for ETAP. Department of Linguistics, Uppsala University, 1–14. Tjong Kim Sang, Erik 1999. Aligning the Scania corpus. In: Anna Sågvall Hein (ed.), Working Papers in Computational Linguistics & Language Engineering 18. Reports from the ETAP project: Converting, aligning and tagging for ETAP. Department of Linguistics, Uppsala University, 1–7. (5) (6) (7) (8) (9) (10) (11) ETAP status report December 2000 17 5.2.3 Other publications (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) Borin, Lars 1998. ETAP: Etablering och annotering av parallellkorpus för igenkänning av översättningsekvivalenter. ASLA-information, 24(1):33–40. Borin, Lars 1998. Linguistics isn't always the answer: Word comparison in computational linguistics. In: The 11th Nordic Conference on Computational Linguistics. NODALIDA '98. Proceedings. Center for Sprogteknologi and Department of General and Applied Linguistics, University of Copenhagen, 140–151. Borin, Lars 2000. Pivot alignment. In: NODALIDA ’99. Proceedings from the 12th ”Nordiske datalingvistikkdager”. Trondheim: Department of Linguistics, NTNU. 41–48. Borin, Lars 2000. Something borrowed, something blue: Rule-based combination of part-of-speech taggers. In: Second International Conference on Language Resources and Evaluation. Proceedings, Volume I. Athens: ELRA. 2000. 21–26. Borin, Lars 2000. You'll take the high road and I'll take the low road: Using a third language to improve bilingual word alignment. In: Proceedings of the 18th International Conference on Computational Linguistics, Vol. 1. Saarbrücken: Universität des Saarlandes. 2000. 97–103. Borin, Lars to appear. Enhancing tagging performance by combining knowledge sources. In: Proceedings of KORFU 1999. ASLA, Växjö University. Borin, Lars (ed.) to appear. Parallel corpora, parallel worlds. Papers presented at a symposium on parallel and comparable corpora at Uppsala University. Amsterdam: Rodopi. Borin, Lars to appear. … and never the twain shall meet. In: Lars Borin (ed.), Parallel Corpora, Parallel Worlds. Amsterdam: Rodopi. Olsson, Leif-Jöran and Lars Borin 2000. A web-based tool for exploring translation equivalents on word and sentence level in multilingual parallel corpora. In: Erikoiskielet ja kännösteoria – Fackspråk och översättningsteori – LSP and Theory of Translation. 20th VAKKI Symposium. 2000, Vasa 11.–13.2.2000. Publications of the Research Group for LSP and Theory of Translation at the University of Vaasa, No. 27, 2000. 76–84. Prütz, Klas 1998. Evaluation of the syntactic parsing performed by the ENGCG parser. In: The 11th Nordic Conference on Computational Linguistics. NODALIDA '98. Proceedings. Center for Sprogteknologi and Department of General and Applied Linguistics, University of Copenhagen, 87–93. Sågvall Hein, Anna fortcoming. Using parallel corpora in multilingual lexical acquisition. In: Brynja Svane (ed.), Translation as Intercultural Communication. Stockholm/Uppsala: Reports from the Research Programme “Translation and Interpreting – A Meeting between Languages and Cultures”. 18 Borin, with contributions by others References Atwell, Eric, George Demetriou, John Hughes, Amanda Schiffrin, Clive Souter and Sean Wilcock 2000. A comparative evaluation of modern English corpus grammatical annotation schemes. ICAME Journal 24:7–23. Bengtsson, Camilla, Lars Borin and Henrik Oxhammar 2000. Comparing and combining part of speech taggers for multilingual parallel corpora. In: Lars Borin (ed.), Working Papers in Computational Linguistics & Language Engineering 22. Reports from the ETAP project: Segmenting and tagging parallel corpora. Department of Linguistics, Uppsala University. XX–YY. Borin, Lars 1998. Linguistics isn't always the answer: word comparison in computational linguistics. In: The 11th Nordic Conference on Computational Linguistics. NODALIDA '98. Proceedings. Center for Sprogteknologi and Department of General and Applied Linguistics, University of Copenhagen, 140–151. Borin, Lars 1999. Alignment and tagging. In: Lars Borin (ed.), Working Papers in Computational Linguistics & Language Engineering 20. Reports from the ETAP project: Tagging and alignment. Department of Linguistics, Uppsala University, 1– 10. Forthcoming in: L. Borin (ed), Parallel Corpora, Parallel Worlds. Papers Presented at a Symposium on Parallel and Comparable Corpora at Uppsala University, Sweden, 22–23 April, 1999. Amsterdam: Rodopi. Borin, Lars 2000a. Pivot alignment. In: NODALIDA ’99. Proceedings from the 12th ”Nordiske datalingvistikkdager”. Trondheim: Department of Linguistics, NTNU. 41–48. Borin, Lars 2000b. You'll take the high road and I'll take the low road: Using a third language to improve bilingual word alignment. Proceedings of the 18th International Conference on Computational Linguistics, Vol. 1. Saarbrücken: Universität des Saarlandes. 2000. 97–103. Borin, Lars 2000c. Something borrowed, something blue: rule-based combination of POS taggers. Second International Conference on Language Resources and Evaluation. Proceedings, Volume I. Athens: ELRA. 21–26. Borin, Lars to appear. Enhancing tagging performance by combining knowledge sources. In: Proceedings of KORFU 1999. ASLA, Växjö University. Borin, Lars and Klas Prütz 2000. Through a glass darkly: Part of speech distribution in original and translated text. In: Lars Borin (ed.), Working Papers in Computational Linguistics & Language Engineering 21. Reports from the ETAP project: Seeing double: using parallel corpora for linguistic research. Department of Linguistics, Uppsala University. 9–30. Brants, Torsten 2000. TnT – a statistical part-of-speech tagger. In: Proceedings of the 6th applied NLP conference, ANLP-2000. Seattle. Brill, Eric 1995. Transformation-based error-driven learning and natural language processing: a case study in part-of-speech tagging. Computational linguistics 21(4): 543–565. Daelemans, Walter, Jakub Zavrel, P. Berck and Steven Gillis 1996. MBT: a memorybased part of speech tagger generator. In: Eva Ejerhed and Ido Dagan (eds.), Proceedings of the fourth workshop on very large corpora. ETAP status report December 2000 19 Ebeling, Jarle 1998. The Translation Corpus Explorer: a browser for parallel texts. In: S. Johansson and S. Oksefjell (eds). Corpora and Cross-linguistic Research. Theory, Method, and Case Studies. Amsterdam: Rodopi. 101–112. Gale, William A. & Kenneth W. Church 1993. A program for aligning sentences in bilingual corpora. Computational linguistics, 19(1): 75–102. Gellerstam, Martin 1985. Translationese in Swedish novels translated from English. In: Lars Wollin and Hans Lindquist (eds.), Translation Studies in Scandinavia. Proceedings from the Scandinavian Symposium on Translation Theory (SSOTT) II, Lund 14–15 June, 1985. Department of English, Lund University. 88–95. Grefenstette, Gregory and Pasi Tapanainen 1994. What is a word, what is a sentence? Problems of tokenization. In: 3rd conference on computational lexicography and text research. COMPLEX'94, Budapest. Gustavsson, Sven 1998. Perception av polska skönlitterära texter via svenska översättningar – på grundval av översättningar av H. Sienkiewicz verk till svenska. Projekt nr 4. In Översättning 1998. 76–81. Johansson, Stig forthcoming. Towards a multilingual corpus for contrastive analysis and translation studies. In: Lars Borin (ed.), Parallel Corpora, Parallel Worlds. Papers Presented at a Symposium on Parallel and Comparable Corpora at Uppsala University, Sweden, 22–23 April, 1999. Amsterdam: Rodopi. Johansson, Stig and Knut Hofland 1994. Towards an English–Norwegian parallel corpus. Creating and Using English Language Corpora, ed. by U. Fries, G. Tottie & P. Schneider. Amsterdam: Rodopi. 25–37. Jonasson, Kerstin 1998. Konsten att översätta från franska. Projekt nr 6. In Översättning 1998. 88–94. Magnusson, Gunnar 1998. Genus och sexus i tyskan och svenskan i ett kontrastivt perspektiv och ett översättningsperspektiv. Projekt nr 9. In Översättning 1998. 100– 107. Översättning 1995. Översättning och tolkning som språk- och kulturmöte. Språkvetenskapligt forskningsprogram. Språkvetenskapliga sektionerna vid universiteten i Stockholm och Uppsala. Översättning 1998. Översättning och tolkning som språk- och kulturmöte. Rapportering perioden 1996–97. Planering perioden 1998–2001. Språkvetenskapliga sektionerna vid universiteten i Stockholm och Uppsala. Olsson, Leif-Jöran and Lars Borin 2000. ETAP–WebTEq: a web-based tool for exploring translation equivalents on word and sentence level in multilingual parallel corpora. In: Lars Borin (ed.), Working Papers in Computational Linguistics & Language Engineering 21. Reports from the ETAP project: Seeing double: using parallel corpora for linguistic research. Department of Linguistics, Uppsala University. 1–8. Also in Erikoiskielet ja kännösteoria – Fackspråk och översättningsteori – LSP and Theory of Translation. 20th VAKKI Symposium. 2000, Vasa 11.–13.2.2000. Publications of the Research Group for LSP and Theory of Translation at the University of Vaasa, No. 27, 2000. 76–84. Oxhammar, Henrik and Lars Borin 2000. Sentence splitting and SGML tagging of the ETAP corpora. In: Lars Borin (ed.), Working Papers in Computational Linguistics & Language Engineering 22. Reports from the ETAP project: Segmenting and tagging parallel corpora. Department of Linguistics, Uppsala University. XX–YY. 20 Borin, with contributions by others Prütz, Klas 1999a. Sammanställning av en träningskorpus på svenska för träning av ett automatiskt ordklasstaggningssystem. In: Anna Sågvall Hein (ed.), Working Papers in Computational Linguistics & Language Engineering 19. Reports from the ETAP project. Department of Linguistics, Uppsala University, 1–15. Prütz, Klas 1999b. Part-of-speech tagging for Swedish. In: Lars Borin (ed.), Working Papers in Computational Linguistics & Language Engineering 20. Reports from the ETAP project: Tagging and alignment. Department of Linguistics, Uppsala University. 11–15. Qiao, Hong Liang 1999. Comparing the tagging Brill taggers. In: Anna Sågvall Hein (ed.), Linguistics & Language Engineering 18. Converting, aligning and tagging for ETAP. University, 1–9. performance between the AGTS and Working Papers in Computational Reports from the ETAP project: Department of Linguistics, Uppsala Sågvall Hein, Anna 1995. Delprojekt 20: Etablering och annotering av parallellkorpus för igenkänning av översättningsekvivalenter. In Svane 1996. 76–80. Sågvall Hein, Anna 1999. The PLUG project. Parallel corpora in Linköping, Uppsala, Göteborg: aims and achievements. In: Anna Sågvall Hein (ed.), Working Papers in Computational Linguistics & Language Engineering 16. Reports from the PLUG project. Department of Linguistics, Uppsala University, 1–17. Forthcoming in: L. Borin (ed), Parallel Corpora, Parallel Worlds. Papers Presented at a Symposium on Parallel and Comparable Corpora at Uppsala University, Sweden, 22–23 April, 1999. Amsterdam: Rodopi. Schmid, Helmut 1994. Probabilistic part-of-speech tagging using decision trees. In: Proceedings of the International conference on new methods in language processing. Manchester. Svane, Brynja (ed.) 1996. Translation and interpreting. A meeting between languages and cultures. Stockholm University and Uppsala University. Tiedemann, Jörg 1999. Parallel corpora in Linköping, Uppsala and Göteborg (PLUG): the corpus. In: Anna Sågvall Hein (ed.), Working Papers in Computational Linguistics & Language Engineering 14. Reports from the PLUG project. Department of Linguistics, Uppsala University, 1–13. Tiedemann, Jörg 2000. Word alignment step by step. In: NODALIDA ’99. Proceedings from the 12th ”Nordiske datalingvistikkdager”. Trondheim: Department of Linguistics, NTNU. 216–227. Tjong Kim Sang, Erik 1999a. Converting the SCANIA Framemaker documents to TEI SGML. In: Anna Sågvall Hein (ed.), Working Papers in Computational Linguistics & Language Engineering 18. Reports from the ETAP project: Converting, aligning and tagging for ETAP. Department of Linguistics, Uppsala University, 1–14. Tjong Kim Sang, Erik 1999b. Aligning the Scania corpus. In: Anna Sågvall Hein (ed.), Working Papers in Computational Linguistics & Language Engineering 18. Reports from the ETAP project: Converting, aligning and tagging for ETAP. Department of Linguistics, Uppsala University, 1–7. Wande, Erling 1998. Textlingvistik, översättningsteori pch tolkning – modeller för analys av simultantolkad, fackspråklig diskurs. Projekt nr 13. In Översättning 1998. 142–150. Working Papers in Computational Linguistics & Language Engineering Uppsala University, Department of Linguistics, Box 527, SE-751 20 Uppsala, Sweden. URL: <http://www.ling.uu.se/> (e-mail: <info@ling.uu.se>) No. 1 Prütz, Klas: Disambiguation Strategies in Automatic Part of Speech Tagging Systems. A Probabilistic and a Rule Based System. 59 pp. Uppsala, May 1996. No. 2 Olsson, Fredrik: Tagging and Morphological Processing in the SVENSK System. 104 pp. Uppsala, June 1998. No. 3 Reports from the SCARRIE Project, Editor: Anna Sågvall Hein. Two Reports on CORRIE for SCARRIE: Tjong Kim Sang, Erik: Testing CORRIE for SCARRIE, Deliverable 1.2. 22 pp. Olsson, Leif-Jöran: Specification of Phonemic Representation, Swedish, Deliverable 4.1.3. 14 pp. Uppsala, December 1999. No. 4 Reports from the SCARRIE Project, Editor: Anna Sågvall Hein. Wedbjer Rambell, Olga: Error Typology for Automatic Proof-reading Purposes, Deliverable 2.1. 114 pp. Uppsala, December 1999. No. 5 Reports from the SCARRIE Project, Editor: Anna Sågvall Hein. Wedbjer Rambell, Olga, Dahlqvist, Bengt, Tjong Kim Sang, Erik, Hein, Nils: An Error Database of Swedish, Deliverable 2.1.3.2. 54 pp. Uppsala, December 1999. No. 6 Reports from the SCARRIE Project, Editor: Anna Sågvall Hein. The SCARRIE Swedish Newspaper Corpus. Dahlqvist, Bengt: A Swedish Text Corpus for Generating Dictionaries, Deliverable 3.1.3. 20 pp. Dahlqvist, Bengt: The Distribution of Characters, Bi- and trigrams in the Uppsala 70 Million Words Swedish Newspaper Corpus. 14 pp. Uppsala, December 1999. No. 7 Reports from the SCARRIE Project, Editor: Anna Sågvall Hein. Olsson, Leif-Jöran: A Swedish Hyphenation Marker, Deliverable 3.4.1. 37 pp. Uppsala, December 1999. No. 8 Reports from the SCARRIE Project, Editor: Anna Sågvall Hein. Wedbjer Rambell, Olga: Multi-word Expressions for Swedish, Deliverable 5.3.3. 34 pp. Uppsala, December 1999. No. 9 Reports from the SCARRIE Project, Editor: Anna Sågvall Hein. Wedbjer Rambell, Olga: A Study of Three Commercial Grammar Checkers, Deliverable 6.1. 76 pp. Uppsala, December 1999. No. 10 Reports from the SCARRIE Project, Editor: Anna Sågvall Hein. Wedbjer Rambell, Olga: Three Types of Grammatical Errors in Swedish, Deliverable 6.2.3. 39 pp. Uppsala, December 1999. No. 11 Reports from the SCARRIE Project, Editor: Anna Sågvall Hein. CORRIE-based Grammar Checking. Wedbjer Rambell, Olga: Swedish Phrase Constituent Rules. A Formalism for the Expression of Local Error Rules for Swedish, Deliverable 6.3.3, 6.4 and 6.4.3. 28 pp. Wedbjer Rambell, Olga: A Minor Grammar Checking Test for Swedish Using the Fragment Analysis Approach in CORRIE. 26 pp. Uppsala, December 1999. No. 12 Reports from the SCARRIE Project, Editor: Anna Sågvall Hein. Chart-Based Grammar Checking in SCARRIE. Sågvall Hein, Anna, Starbäck, Per: A Test Version of the Grammar Checker for Swedish, Deliverable 6.5.1. 44 pp. Sågvall Hein, Anna: A Specification of the Required Grammar Checking Machinery, Deliverable 6.5.2. 39 pp. Sågvall Hein, Anna: A Grammar Checking Module for Swedish, Deliverable 6.6.3. 24 pp. Starbäck, Per: ScarCheck – a Software for Word and Grammar Checking. 6 pp. Weijnitz, Per: Uppsala Chart Parser Light System Documentation. 20 pp. Uppsala, December 1999. No. 13 Reports from the SCARRIE Project, Editor: Anna Sågvall Hein. Evaluating the Swedish SCARRIE Prototype. Sågvall Hein, Anna, Leif-Jöran Olsson, Bengt Dahlqvist, Erik Mats: Evaluation Report for the Swedish Prototype, Deliverable 8.1.3. 16 pp. Ahlbom, Viktoria, Sågvall Hein, Anna: Test Suites Covering the Functional Specifications of the Sub-components of the Swedish Prototype, Deliverable 7.1.3. 28 pp. Uppsala, December 1999. No. 14 Reports from the PLUG Project, Editor: Anna Sågvall Hein. Tiedemann, Jörg: Parallel Corpora in Linköping, Uppsala and Göteborg (PLUG): The Corpus. 13 pp. Uppsala, December 1999. No. 15 Reports from the PLUG Project, Editor: Anna Sågvall Hein. Ahrenberg, Lars, Merkel, Magnus, Sågvall Hein, Anna, Tiedemann, Jörg: Evaluation of LWA and UWA. 28 pp. Uppsala, December 1999. No. 16 Reports from the PLUG Project, Editor: Anna Sågvall Hein. Sågvall Hein, Anna: The PLUG-project. Parallel Corpora in Linköping, Uppsala, Göteborg: Aims and Achievements. 17 pp. Uppsala, December 1999. No. 17 Reports from the PLUG Project, Editor: Anna Sågvall Hein. Tiedemann, Jörg: Uplug – A Modular Corpus Tool for Parallel Corpora. 16 pp. Uppsala, December 1999. No. 18 Reports from the ETAP Project, Editor: Anna Sågvall Hein. Converting, Aligning and Tagging for ETAP. Tjong Kim Sang, Erik: Converting the SCANIA Framemaker Documents to TEI SGML. 14 pp. Tjong Kim Sang, Erik: Aligning the Scania Corpus. 7 pp. Qiao, Hong Liang: Comparing the Tagging Performance Between the AGTS and Brill Taggers. 9 pp. Uppsala, December 1999. No. 19 Reports from the ETAP Project, Editor: Anna Sågvall Hein. Prütz, Klas: Sammanställning av en träningskorpus på svenska för träning av ett automatiskt ordklasstaggningssystem.15 pp. Uppsala, December 1999. No. 20 Reports from the ETAP Project, Editor: Lars Borin. Tagging and Alignment. Borin, Lars: Alignment and Tagging. 10 pp. Prütz, Klas: Part-of-Speech Tagging for Swedish. 5 pp. Uppsala, December 1999. No. 21 Reports from the ETAP Project, Editor: Lars Borin. Seeing Double: Using Parallel Corpora for Linguistic Research. Olsson, Leif-Jöran, Borin, Lars: ETAP-WebTEq: a Web-Based Tool for Exploring Translation Equivalents on Word and Sentence Level in Multilingual Parallel Corpora. 8 pp. Borin, Lars, Prütz, Klas: Through a Glass Darkly: Part of Speech Distribution in Original and Translated Text. 22 pp. Uppsala, December 2000. No. 22 Reports from the ETAP Project, Editor: Lars Borin. Segmenting and Tagging Parallel Corpora. Oxhammar, Henrik, Borin, Lars: Sentence Splitting and SGML Tagging. 10 pp. Bengtsson, Camilla, Borin, Lars, Oxhammar, Henrik: Comparing and Combining Part of Speech Taggers for Multilingual Parallel Corpora. 20 pp. Uppsala, December 2000. No. 23 Reports from the ETAP Project, Editor: Lars Borin. Borin, Lars, with contributions by others: ETAP Project Status Report December 2000. 20 pp. Uppsala, December 2000.