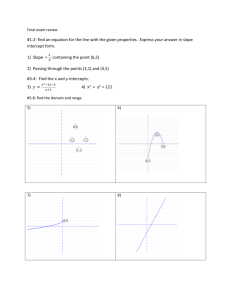
ECE 534: Elements of Information Theory, Fall 2011 Homework 1
advertisement

ECE 534: Elements of Information Theory, Fall 2011 Homework 1 Solutions Problem 2.2 (Hamid Dadkhahi) Let Y = g(X). Suppose PX (x) and PY (y) denote the probability mass functions of random variables X and Y , respectively. P If g is an injective mapping, then PY (y) = PX (x) and hence H(Y ) = H(X). Otherwise, PY (y) = x:g(x)=y PX (x). In this case, since multiple intervals in X are merged to generate one interval in Y , the entropy of Y is smaller than that of X. (a) H(Y ) = H(X), because g(X) = 2X is an injective map. (b) H(Y ) ≤ H(X), where we have equality if the domain of X is contained in [k π2 , (k + 1) π2 ] (k is an integer). Otherwise, the map g(X) = cos(X) is not injective and H(Y ) is smaller than H(X). Problem 2.6 (Hamid Dadkhahi) (a) If Z = X and Y is chosen such that H(X|Y ) < H(X) (i.e. X is not independent of Y ; for instance Y = X results in H(Y |X) = 0), then I(X; Y |Z) = 0, and I(X; Y ) > 0. Therefore, I(X; Y |Z) < I(X; Y ). (b) Suppose X and Y are independent of each other, and Z = g(X, Y ), where the function g is chosen such that it cannot be solved for X without the knowledge of Y (and can be solved for X with the knowledge of Y ). In this case, we have: I(x; Y ) = H(X) − H(X|Y ) = H(X) − H(X) = 0 and I(X; Y |Z) = H(X|Z) − H(X|Y, Z) = H(X|Z) − 0 = H(X|Z). H(X|Y, Z) = 0 because given Y , Z = g(X, Y ) can be solved for X. H(X|Z) > 0 since Z cannot be solved for X without the knowledge of Y . Two examples of this are given in textbook (page 35) and Mackay’s book (the page included in the course slides). Problem 2.11 (Hamid Dadkhahi) Since X1 and X2 are identically distributed, we have H(X1 ) = H(X2 ). (a) H(X2 |X1 ) H(X1 ) H(X1 ) − H(X2 |X1 ) H(X1 ) H(X2 ) − H(X2 |X1 ) H(X1 ) I(X1 ; X2 ) . H(X1 ) ρ = 1− = = = (b) Since both mutual information and entropy are non-negative identities, we have ρ ≥ 0. Thus, 1 it suffices to show ρ ≤ 1: I(X1 ; X2 ) = H(X2 ) − H(X2 |X1 ) ≤ H(X2 ) = H(X1 ). Dividing both sides of the inequality I(X1 ; X2 ) ≤ H(X1 ) by H(X1 ), yields ρ ≤ 1. (c) ρ = 0, when I(X1 ; X2 ) = 0, which occurs when X1 and X2 are independent of each other. (d) ρ = 1, when I(X1 ; X2 ) = H(X1 ) = H(X2 ), or equivalently H(X2 |X1 ) = H(X2 ), which occurs when knowledge of one random variable results in the knowledge of the other. In other words, X1 and X2 are dependent. Problem 2.12 (Pongsit Twichpongtorn) Problem 2.12 p(x,y) p(x=0) p(x=1) p(y=0) p(y=1) 1 3 1 3 1 3 0 (a) H(X), H(Y ) H(X) = − X p(x) log p(x) 2 1 1 2 = −( ) log( ) − ( ) log( ) 3 3 3 3 = 0.918 = H(Y ) Figure 1: H(X), H(Y ) 2 (b) H(X|Y ), H(Y |X) H(X|Y ) = X p(y)H(X|Y ) = p(Y = 0)H(X|Y = 0) + p(Y = 1)H(X|Y = 1) 1 2 1 1 = H(1) + H( , ) 3 3 2 2 2 1 1 1 1 = 0 + (−( ) log( ) − ( ) log( )) 3 2 2 2 2 2 2 1 1 = ( + ) = = 0.667 3 2 2 3 Figure 2: H(X|Y ) H(Y |X) = X p(x)H(Y |X) = p(X = 0)H(Y |X = 0) + p(X = 1)H(Y |X = 1) 1 1 1 2 = H( , ) + H(1) 3 2 2 3 2 1 1 1 1 = (−( ) log( ) − ( ) log( )) + 0 3 2 2 2 2 = 0.667 Figure 3: H(Y |X) (c) H(X, Y ) H(Y, X) = H(X) + H(Y |X) = H(Y ) + H(X|Y ) = 0.918 + 0.667 = 1.585 3 Figure 4: H(Y, X) Figure 5: H(Y ) − H(Y |X) (d) H(Y ) − H(Y |X) H(Y ) − H(Y |X) = 0.918 − 0.667 = 0.251 (e) I(X; Y ) I(X; Y ) = H(X) − H(X|Y ) = H(Y ) − H(Y |X) = 0.251 (f) Figures are shown already. Figure 6: I(X; Y ) Problem 2.18 (Nan Xu) Since A and B are equally matched and the games are independent. (1) 2 situations: holding 4 games and then have a winner(AAAA,BBBB): Each happens with prob1 ability ( 12 )4 = 16 4 (2) 8 = 2 43 situations: holding 5 games and then have a winner(????A,????B): Each happens with 1 probability ( 12 )5 = 32 (3) 20 = 2 54 situations: holding 6 games and then have a winner(?????A,?????B): Each happens 1 with probability ( 21 )6 = 64 (4) 40 = 2 65 situations: holding 7 games and then have a winner(??????A,??????B): Each happens 1 with probability ( 12 )7 = 128 The probability of holding 4 games(Y=4) is 2( 12 )4 = 1 8 The probability of holding 5 games(Y=5) is 8( 12 )5 = 1 4 The probability of holding 6 games(Y=6) is 20( 21 )6 = 5 16 The probability of holding 7 games(Y=7) is 40( 21 )7 = 5 16 H(X) = − X p(x) log2 p(x) 1 1 1 1 ) log2 16 + 8( ) log2 32 + 20( ) log2 64 + 40( ) log2 128 16 32 64 128 = 5.8125 X H(Y ) = − p(y) log2 p(y) = 2( 1 5 16 16 1 5 log2 8 + log2 4 + log2 ( ) + log2 ( ) 8 4 16 5 16 5 = 1.924 = since X there is no randomness in Y,or Y is a deterministic function of X, so H(Y |X) = 0 since H(X) + H(Y |X) = H(Y ) + H(X|Y ), so H(X|Y ) = H(X) + H(Y |X) − H(Y ) = 3.8885 5