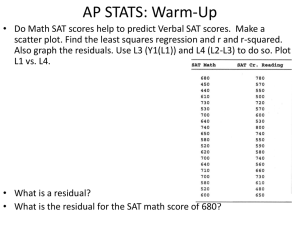
Multiple Regression I Multiple Regression II Multiple Regression III
advertisement

Multiple Regression I
Multiple Regression II
Regression with graphics - A second Course in Applied Statistics , Chapter 3, L. C.
Hamilton, 1991.
Now imagine you have n observations {( y( i) , x1( i) , · · · , x(Ki)−1 )} i=1,··· ,n , so the linear
Definition (Multiple Regression Models)
system to solve is
The linear model is:
y(1) = θ0 + θ1 x1(1) + θ2 x2(1) + · · · + θK −1 x(1)
+ ǫ(1)
K −1
y(2) = θ0 + θ1 x(2) + θ2 x(2) + · · · + θK −1 x(2) + ǫ(2)
1
2
K −1
y = θ0 + θ1 x1 + θ2 x2 + · · · + θK −1 xK −1 + ǫ
with
y is the dependent variable,
..
.
y(n) = θ0 + θ1 x1(n) + θ2 x2(n) + · · · + θK −1 x(Kn−) 1 + ǫ(n)
x1 , x2 , · · · , xk−1 are the independent or explanatory variables,
θ = (θ0 , θ1 , θ2 , · · · , θK −1 ) are the K parameters in the model.
Multiple Regression III
Multiple Regression IV
Using vectors and matrices, we define:
y(1)
y(2)
y=
..
.
y(n)
ǫ(1)
ǫ(2)
, ǫ =
..
.
ǫ( n )
, X =
x1(1)
x2(1)
···
x(1)
K −1
1
x1(2)
x2(2)
···
x(2)
K −1
( n)
xK −1
..
.
1
x1(n)
x2(n)
···
1
and
θ =
θ0
θ1
θ2
..
.
θK −1
The Least Squares estimate is computed by:
³
´−1
θ = XT X
XT y
θ̂
Note that θ̂θ is minimizing the error sum of squares.
and the system can be rewritten:
y = Xθ + ǫ
Multiple Regression V
Multiple Regression VI
Definition (Error Sum of Squares)
Definitions:
The error sum of squares is defined as:
SSE = kǫ k2 =
n
X
Note that:
ǫ( i )
=
=y
Fitted Values
2
The hat matrix
3
Residuals/errors using the hat matrix notation
4
Analysis of variation
(ǫ( i) )2
i =1
y( i) − (θ̂0 + θ̂1 x1( i) + θ̂2
( i)
( i)
1
x2( i) + · · · + θ̂K −1
x(Ki)−1 )
SST
− ŷ
Pn
( i)
2
i =1 ( y − y)
where the prediction by the linear model is defined as
( n − 1)
ŷ( i) = θ̂0 + θ̂1 x1( i) + θ̂2 x2( i) + · · · + θ̂K −1 x(Ki)−1
5
SSR
=
=
Pn
=
The Analysis of variance (ANOVA)
( i)
2
i =1 ( ŷ − y)
(K − 1)
SSE
+
+
+
Pn
i =1 (ǫ
( i) 2
)
(n − K )