Compiler Design Test: Grammar, Parsing, LL(1)
advertisement
")
CSC 402
TEST #2, Some Sample Questions
COMPILER DESIGN
FALL, 2005
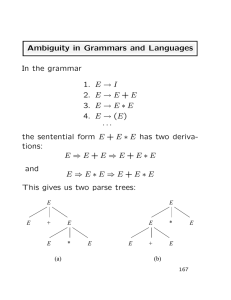
1. On the back of the next page, show that the following grammar is ambiguous by showing the appropriate derivations.
Show the syntax trees corresponding to the derivations. (16)
E --> E + E
E --> E * E
E --> ( E )
E --> a
2. Suppose we have a language over {i, @, #, $, (, )} where i stands for an identifier (or integer), @ stands for a unary
postfix operator (i.e., an operator which comes after its single argument) of highest precedence, # stands for a left
associative, binary infix operator (i.e., an operator which comes between its two arguments) of next highest
precedence, and $ stands for a right associative, binary infix operator of least highest precedence. Some examples of
legal expressions in the language are shown below. Note that the expressions i@@, i@@@, etc., are legal.
i, i@, i@@, i@@@, (i), (i@), (i@)@, i$i, i#i, i#i#i, i#i$i, i#i$i, (i$i@)#i, i#(i$i)@#(i$i)
a) Put explicit parentheses in the following expressions of the language to show how the components are implicitly
grouped by the rules of precedence specified above. (10)
(1)
i
#
i
$
(3)
i
#
i
@
i
(2)
$
i
@
@
#
i
$
i
$
i
$
i
@
#
i
$
i
i
b) Write a context free grammar for this language.The grammar must be unambiguous but need not (should not) be
LL(1). For consistency and readability, use E, T, F, P, Q, R, S, etc., as necessary for the non-terminals of the language.
(10)
3. Consider the following grammar (capitals are non-terminals, lower case are terminals):
PREDICT SET
1. S --> P
2. P --> p R
3. P --> p W
4. P --> P d
5. R --> s R
6. R --> b
7. W --> g
a) In the space provided, show the FIRST and FOLLOW sets for each non-terminal of the language. (8)
FIRST
FOLLOW
S
P
R
W
b) In the space provided next to each production above, give the PREDICT set for that production and show that the grammar
is not LL(1). (7)
c) Revise the grammar to make it LL(1) (Hint. Factor first, then remove left-recursions.) Write the revised grammar
neatly below. (10)
d) Draw up an LL(1) parse table for your revised grammar and give it neatly below. Order the columns of the table: p,
d, s, b, g, $. (10)
e)
Show the first ten steps in the parse of the string psbdd. (5)
Stack
Input
Action
1)
2)
etc.
4. Consider the following grammar.
1. P --> b S e
2. S --> s c S
3. S --> b S e c S
4. S --> ε
The table for a shift-reduce parser for this grammar is given below.
b
0
1
2
3
4
5
6
7
8
9
10
11
S1
S4
e
c
s
$
P
S
R4
S3
S5
2
R4
S5
7
S5
10
S6
11
A
S4
S6
S4
R4
S8
S4
R4
R2
R3
S9
In the space provided on the next page, fill in a trace of the parsing steps of this parser on the input b s c s c e $.
The parse takes ten steps. Part of the first step is filled in already. (10)
Step
1
2
3
4
5
6
7
etc
Parse Stack
0
Remaining Input
bscsce$
Action