PAKDD DATA MINING COMPETITION WRITE-UP:
advertisement

PAKDD DATA MINING COMPETITION WRITE-UP:
CLASSIFICATION OF MOBILE PHONE CUSTOMERS
Hanny Yulius Limanto,
Undergraduate Student
Nanyang Technological University
Singapore
Under the supervision of:
Dr. Tay Joc Cing, Nanyang Technological University, Singapore
Dr. Andrew Watkins, Mississippi State University, USA
1. Approach and Understanding of the Problem
A sample dataset 24000 mobile phone subscribers are provided, in which 20000 of them
are 2G network customers and the other 4000 are 3G network customers. The target field
is the customer type (2G/3G). Three quarters of the dataset have the target field available
and used for training purposes; while the remaining quarter of the dataset has missing
target field and is meant for prediction. The objective of the classification is to correctly
predict as many 3G customers as possible from the prediction set.
Each record in the dataset consists of 250 data fields. We categorize this data field into
two types, which are numerical and categorical. A numerical field takes any real number
(e.g. customer age); while on the other hand, a categorical field may only take in a value
in a finite set (e.g. gender). This set may be defined from the data dictionary (e.g. gender
(M/F)), or it takes all the values that appear in the dataset (e.g. type of handset).
Data preprocessing is done by normalizing numerical values, and converting categorical
values from literal string to integer index. For each numerical data field, we find the
minimum and maximum values that appear in the dataset. From the obtained extreme
values, we normalize the values in the numerical data field to the range of [0, 1]. The
1
values in a categorical data field will simply be changed from literal string to an integer
index to ease processing.
To predict the data, we use a immune-system-inspired data mining algorithm called
Artificial Immune Recognition System (AIRS) which is proposed and fully described in
[1] and improved in [5].
Since AIRS will rely heavily on finding the similarity (or difference) between a pair of
customer record, a proper distance measure need to be defined. A survey of distance
measure that can be used in conjunction with AIRS is presented in [2]. Based on this
survey, we use Heterogeneous Value Difference Metric (HVDM) as our distance
measure. HVDM measure uses Euclidean distance for numerical data field and Value
Difference Metric for categorical data field. Consider x and y as two customer records
that are going to be compared (also known as antibody in AIRS, to be elaborated later),
each having G data fields and having one of C classifications (C = 2, either 2G or 3G).
All numerical fields are normalized to the range of [0, 1]. The function HVDM(x, y)
returns the HVDM distance of x and y.
HVDM ( x, y )
1
G
G
hvdm( x , y
g 1
g
g
)
vdm( xg , y g ) ,
g is categorical field
xg y g ,
g is numerical field
hvdm( xg , y g )
C
vdm( xg , yg ) ( P(c | xg ) P(c | y g )) 2
c 1
P(c|xg) denotes the probability that a customer record has class c given the value xg.
2
For missing values that occurs in the dataset, we simply replace them with a global value
“MISSING”, other strategies such as statistical regression might be more effective. Due
to the time constraint we do not have time to experiment with other methods.
We also note that there are some data fields from which only 1 value would appear from
all
customer
records
in
the
entire
training
data
(e.g.
HS_CHANGE,
TOT_PAS_DEMAND for numerical data field, and VAS_SN_STATUS for categorical
data field). We would not get any useful information from this field since there are only 1
value that appears in the data and no other value to contrast it to. Therefore, for these data
fields, it can be safely removed from the data.
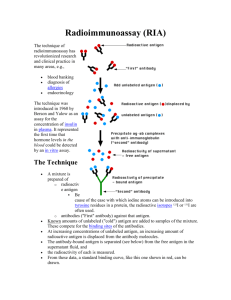
2. Brief Overview on Immune System
The function of the immune systems is to identify and destroy foreign invaders (antigens)
which are possibly harmful to the body. The immune system is composed of two types of
lymphocytes, B-Cells and T-Cells. However, AIRS is modeled based on the behavior of
B-Cells, hence only the B-Cells will be described here. Each B-cell has receptors that are
capable of recognizing the proteins on the surface of an antigen. The receptors are
antigen specific; therefore, a B-cell can only identify proteins of a specific antigen.
Through stimulation and suppression of each other, similar B-cells form networks that
can recognize similar antigen.
In AIRS, an artificial recognition ball (ARB) is used to represent a number of identical BCells to reduce duplication. The ARBs in the system will compete for B-Cells to survive;
an ARB with no B-cell is removed from the system. When a training data (antigen) is
presented to the system, Each B-cell is cloned in proportion to how well it matches the
antigen where the mutation rate is inversely proportional to how well it matches the
antigen. Eventually, the clone with the best fit to the presented antigen may be retained as
a memory cell. The memory cells are retained in the system to provide faster response
should the system become re-infected with similar antigen.
3
3. Technical Details of Algorithm
The description of the algorithm can be found in detail in [1], while this report try to
present the algorithm as concise as possible, further clarification may be seek in [1]
Definitions:
There are n antigens, and there are G data field and 1 class in each antigen, and the
class of the antigen may take the value of {1, 2, …, nc}.
MC represents the set of memory cells, mc represent an individual member of the set
and mc.c represents the class of the memory cell.
ag represents an antigen (training data), and ag.c represents the class of ag.
MCc ⊆ MC as the set of memory cells with the class c.
ag.fi represent the value of ith feature (data field) in the antigen and mc.fi the value of
ith feature in mc.
AB represents the set of ARBs and ab represents a single ARB, ab.c and ab.fi denotes
the class and the ith feature of the ARB, respectively.
ab.stim represent the stimulation level of the ARB
ab.resources represent the number of resources held by the ARB.
Parameters:
numEpochs: Number of passes through training data = 3
clonalRate: Number of mutated clones a given ARB is allowed to produce and also
used to assign resources to an ARB = 10
mutationRate: A value between [0, 1] that indicates the likelihood of any given
feature or class of an ARB to be mutated = 0.1
hypermutationRate: number of clones that a given memory cell is allowed to produce
= 10
distance: The used distance metric = Heterogeneous Value Difference Metric
ATS: affinity threshold scalar, a value between [0, 1] that will be multiplied with
affinity threshold (AT, see section 3.1) to produce the cut-off value for memory cell
replacement = 0.2
4
stimThreshold: a value between [0, 1] used as a stopping criterion for training on
specific antigen = 0.95
numRes: number of resources allowed in the system = 200
These parameter values are decided by performing multiple testing on the training data
(using 10-fold testing method) to verify the effectiveness of the parameter values.
The following discusses the various phases of the algorithm
3.1. Initialization
During initialization, all the data preprocessing steps described in section 1 is performed.
After the preprocessing, the affinity threshold (AT) of the system is calculated by
averaging the distance between all training data. It should be noted that the affinity
between two antigens should always be between 0 and 1.
AT
n
n
i 1
j i 1
affinity (agi , ag j )
n
C2
Where affinity(x, y) will return the distance of the two antigens x and y, depending on
which distance metric is used (HVDM for this specific case).
During the initialization phase, the initial ARB populations are also selected by randomly
choosing some antigens from the set of training data.
The initialization phase is only executed once in the beginning of the algorithm, however
the following phases will be executed repeatedly for each available training data.
3.2. Memory cell identification and ARB generation
During this phase, each element of the training data is presented to the algorithm.
The first step is to identify the memory cell mcmatch from MCag.c (the set of memory cells
with the same class label as the presented antigen ag) which has the highest stimulation.
5
The level of stimulation between x and y is defined as stimulation(x, y) = 1 – affinity(x, y)
If MCag.c = {}, then mcmatch = ag and add ag into MCag.c.
After mcmatch has been identified, NumClones clones of mcmatch will be produced as
ARBs. The number of clones NumClones = (hypermutationRate * clonalRate * stim)
where stim denotes the current stimulation level. It should be noted that NumClones is
proportional to the stimulation value of mcmatch to the antigen. Each numerical feature in
mcmatch can only mutate in a constrained range centered at the original value. The width
of the range is inversely proportional to the stimulation value stim. A categorical feature
does not have this constrain and can mutate freely. All of the produced clones are added
into the system as ARBs and will have the same class label as the original mcmatch.
The algorithm then proceeds to the next phase.
3.3. Competition for resources and development of a candidate memory cell
The objective of this phase is to find the ARB in the system (which is produced from the
previous phase) which is the most stimulated when presented with the antigen. This ARB
may be retained as a memory cell. To find the most stimulated ARB, we allocate
resources to all ARBs in the system based on their stimulation level to the current
antigen. As the resources allowed in the system are limited, the ARBs must compete for
the resources, and eventually ARBs with low stimulation level will not have any
resources left and removed from the system.
The surviving ARBs were examined by the algorithm to test whether the ARBs are
stimulated enough by the antigen to stop training on it. The average stimulation level s is
computed by averaging the stimulation level of all surviving ARBs. If s ≥ stimThreshold
then the stopping criterion is met.
Regardless of whether the stopping criterion is met or not, the surviving ARBs is allowed
to produce (stim * clonalRate) offspring, where stim denotes the stimulation of the ARB
6
to the antigen. Similar to the process of mutation of memory cell in section 3.2.,
numerical fields have constrained mutation range.
If the stopping criterion is met, the algorithm stops training on the antigen. Otherwise, the
algorithm repeats this phase from the beginning.until the stopping criterion is met. Once
the stopping criterion is met, the most stimulated ARB in the system is chosen as the
candidate memory cell mccandidate. The algorithm then proceeds to the next phase.
3.4. Memory cell introduction
In this phase, we will decide whether mccandidate should be retained as a memory cell and
whether mccandidate should replace mcmatch. mccandidate is retained as memory cell if it is
more stimulated compared to mcmatch with respect to the current antigen. Furthermore, if
the affinity between mccandidate and mcmatch is less than the threshold (AT * ATS), mcmatch is
going to be replaced by mccandidate.
Once the process finished, the algorithm completes training for one antigen. If there are
any other antigens that need to be trained, the algorithm returns to section 3.2 to train the
new antigen. If all antigens have been trained, the training phase is finished and the
produced memory cells can be used for classification.
4. Produced Classification Model
The algorithm produces a set of memory cells as a result of the training. In a clustering
algorithm, each of the memory cells may be visualized as a cluster center. Using the
parameter values shown in the beginning of section 3, the number of memory cells
produced is only around 10% of the number of training data.
Classification is performed using weighted k-nearest neighbor approach; where k most
stimulated memory cells have the right to vote for the presented antigen class. Since we
have an imbalanced training data (3000 3G customers against 15000 2G customers), we
can expect that there will be more memory cells representing the 2G customers compared
to 3G customers; hence un-weighted voting put the 3G customers at a high probability of
7
being incorrectly classified as 2G customers. To compensate for this, we set the ratio for
a vote of 3G:2G = 5:1 (proportional to the ratio of training data available). Testing has
shown that weighted k-nearest neighbor approach performs more effectively compared to
the un-weighted approach.
As for the k value used to determine how many neighbors get to participate in the voting
process, we used k = 15. In the experimentation, by varying the value of k, we noted that
from k = 1 to 15 the solution quality is increasing, and when k is higher than 15, there are
some cases where the solution quality is reduced.
5. Insight on Obtained Result
The discussion in this section will be based only on the training data, since we will need
to know whether a record is incorrectly classified as false positive (classified as 3G
although the actual class is 2G). Since our algorithm does not produce the characteristics
of 3G customers, therefore the false positives obtained in our experiment might be a
useful insight to decide the characteristics of customers that are likely to change their 2G
subscription to 3G.
To perform this experiment, we randomly divide the training data into 90% training set,
and 10% testing set. After training the algorithm with the training set, we classify the
testing set and obtain the false positives produced by the algorithm. This experimentation
is repeated for several times, and the statistics of the false positives obtained for each
experiment is compared to the statistics of the entire training data whether there are a
constant deviation between the statistics of the false positives and the entire data..
For numerical data field, we compared the average and standard deviation, while for
categorical data field, we compared the frequency count.
8
We find some almost-constant strong-deviation between the statistics of false positives
and the statistics of training data in the following fields:
MARITAL_STATUS: More singles can be found in the false positives compared to
the entire data; this suggests that singles are more likely to purchase 3G subscription.
OCCUP_CD: Less customers with other (OTH) occupation is found in the false
positives; therefore, customers with occupation {EXEC, POL, STUD, MGR, HWF,
ENG, CLRC, SELF, GOVT, TCHR, SHOP, FAC, AGT, MED} (this occupation
code are other codes that can be found in this data field) might be more likely to
change to 3G.
HIGHEND_PROGRAM_FLAG: More customers with high end program are found
in the false positives. This is expected since a 3G plan can also be considered a high
end program.
TOP1_INT_CD, TOP2_INT_CD, TOP3_INT_CD: Considerably more customers
in the false positives with values for this parameters set to other than NONE. It is
probable that customers who make international calls are more attracted and able to
afford 3G subscription.
VAS_GPRS_FLAG: More customers who own a GPRS Data Plan (code 1) can be
found in the false positives. This is expected, since customers without GPRS are less
likely to appreciate the improvement provided by 3G, and therefore, might not find
3G subscription attractive.
LOYALTY_POINTS_USAGE: Customers in the false positives set have
considerably higher average of loyalty points. Loyal customers might be more easily
persuaded to switch to 3G subscription.
TOT_TOS_DAYS: Customers in the false positives set have a lot less average total
temporarily on suspended days compared to the entire data. Customers who are
routinely using their mobile phone are more likely to purchase a 3G subscription.
AVG_CALL_FRW_RATIO: Less call forwarding is utilized by customers in the
false positives set. Customers which are carrying their mobile phone everywhere,
therefore they do not need call forwarding services; are more likely to purchase 3G
subscription which would enable them to do more with their mobile set.
9
AVG_MIN_OBPK, AVG_MIN_OBOP: More minutes are spent in outbound calls
in peak and off-peak period by customers in the false positives set. Customers who
make a lot of calls might be interested in the video phone feature provided by 3G
subscription.
AVG_MIN_FIX: More minutes are spent by customers to call fixed line numbers in
false positives set. Customers who are using their mobile phone actively are more
likely to purchase 3G subscription.
AVG_MIN_T1: More top 1 minutes spent by customers in false positives set.
Customers who are using their mobile phone actively are more likely to purchase 3G
subscription.
AVG_CALL_1900: Considerably more 1900 calls by customers in the false
positives set. Customers who are using their mobile phone for social use as well as
for communication are more likely to purchase 3G subscription.
AVG_REVPAY_AMT, REVPAY_FREQ: Slightly more reverse payment in
average for both the amount and the frequency can be detected in the false positives
set.
CONTRACT_FLAG: Slightly more customers with contract are found in the false
positives. This may be caused by the price of 3G mobile phones that are still
expensive; therefore, an attractive contract plan might attract more customers to
switch to 3G.
AVG_VAS_QTUNE: Customers in false positives set downloaded more quick tunes
than the average of entire data. However, other services such as quick games, text or
pix do not exhibit any statistical deviation from the data.
AVG_VAS_GBSMS: More Email SMSes are sent by customers in the false positives
set. These customers might be interested in the functionality provided by 3G.
10
6. References
[1]
A. Watkins, J. Timmis, L. Boggess. Artificial Immune Recognition System (AIRS):
AN Immune-Inspired Supervised Learning Algorithm. Genetic Programming and
Evolvable Machine. Springer. 2004
[2]
J. S. Hamaker, L. Boggess. Non-Euclidean Distance Measures in AIRS, an
Artificial Immune Classification System. Congress on Evolutionary Computation
2004. 19-23 June 2004.
[3]
J. Hamaker, A. Watkins. Artificial Immune Recognition System (AIRS) Java
source code. 2003.
[4]
A. Watkins. AIRS: A Resource Limited Artificial Immune Classifier. M.S. Thesis,
Department of Computer Science, Mississippi State University, November 2001.
http://nt.library.msstate.edu/etd/show.asp?etd=etd-11051001-102048
[5]
A. Watkins, J. Timmis. Artificial Immune Recognition System (AIRS): Revisions
and Refinements. In Proceedings of 1st International Conference on Artificial
Immune Systems (ICARIS), University of Kent at Canterbury, September 9-11
2002. pages 173-181
11