Lab 2 Evolutionary Stable Solutions
advertisement

Program 3 Evolutionary Stable Solutions (30 points)
Description:
You will conduct a series of experiments that determine which types of strategies are likely to evolve
under various selection dynamics and interaction models for a two games. Use any programming
language you like.
Background:
In evolutionary games, the two main factors that contribute to what is learned are:
1. The types of interactions that occur between the agents in a population.
2. The rules that are applied to determine which strategies within the population are good ones
and therefore likely to be learned by the population.
Descriptions of these concepts can be found in the lecture notes.
The Experiment:
You will conduct a large series of experiments to evaluate what types of strategies evolve in various
games. You will perform experiments on the following games:
Prisoner's Dilemma (as seen in class)
Battle of the Sexes
Battle of the sexes
The Battle of the Sexes is a two player game used in game theory.
Imagine a couple, Kelly and Chris. Kelly would most of all like to go
to the football game. Chris would like to go to the opera. Both would
prefer to go to the same place rather than different ones. If they cannot
communicate where should they go?
Battle of the Sexes
Opera
Football
3, 2
1, 1
Opera
Football
0, 0
2, 3
The payoff matrix labeled "Battle of the sexes " is an example of
Battle of the Sexes, where Chris chooses a row and Kelly chooses a
column. In order to account for both going to the activity they don’t like, the opera/football choice is
preferred to football/opera.
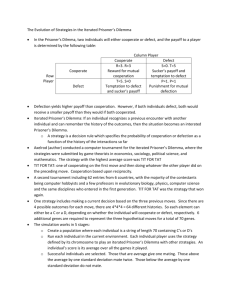
We will restate the problem so that cooperate/defect are defined so the agent knows what to do
regardless of whether he/she is player 1 or player 2. So defecting for player 1 in battle of the sexes is
picking opera, while defecting for player 2 in battle of the sexes is picking football. Cooperate refers
to being nice while defect refers to being selfish.
Battle of the Sexes
Defect
Coop
Defect
1,1
3,2
Coop
2,3
0,0
Agent Strategies
We will have 900 agents of having one of four different strategies. The strategies are such that agents
remember only the previous action of the other agent and then use this action to determine their next
action. Thus, the set of all agents strategies are
Action of other agent
on previous round Agent 1 (Always
Cooperate)
My action on current round
Agent 2 (Always Agent 3 (Tit
Defect)
for Tat)
Agent 4 (Not Tit
for Tat)
Coop
Coop
Defect
Coop
Defect
Defect
Coop
Defect
Defect
Coop
Assume that Agent 1 and Agent 3 play Coop on the first round, and that Agent 2 and Agent 4 play
Defect on the first round.
Repeated Play
We want agents to play with the same partner multiple times because the agent strategies depend on
repeated play with the same partner. In order to make the length of an interaction vary, let gamma
represent the probability that the agents will play each other again. For our tests, gamma = .95 After
every interaction, generate a random number between 0 and 1. If the number is greater than gamma,
stop. Otherwise, continue with the same two players. Assume the score for an agent (in a repeated
game) is the average score per game played. Thus, agents who only played a few games will not be
penalized.
A round consists of every player playing other players and then tallying the results.
Replicator Dynamics
Use 900 agents.
Replicator dynamics refers to picking the percent of each agent type to match the percent of total
utility earned by agents of that type. So if 50% of the agents use strategy A and earn 60% of the
utility, in the next round, 60% of the agents should be strategy A. It doesn’t matter which agent has
which type, but only the percentages of each.
Begin with some initial percentage of each agent type. Do you get the same results regardless of what
you started with?
So I coded a round of play as
OneInteraction(p1,p2)
{
setupGame();
float test = 0.0;
while (test < gamma)
{
play(p,partner);
test = randomFloat(0,1);
}
}
PlayRoundReplicator
{
for (int p=0; p < 900; p++)
{ partner = randomInt(0,900);
OneInteraction(p,partner);
}
for (int i=0; i < 900; i++)
{ agent[i];.perGameUtil = agent[i];.util/ agent[i];.gamesPlayed;
totalUtil += agent[i];.perGameUtil;
util[agent[i];.agentType]+= agent[i];.perGameUtil;
}
}
Between rounds I reassign agent types to be consistent with the replicator philosophy. I will keep
playing rounds until I feel like stopping – (a) things seem to be stabilizing or (b) things are not
stabilizing and I don’t think they will.
So my experiment might look like:
Experiment()
{assign agents to types
while (ct < ROUNDMAX && not stable)
{ PlayRoundReplicator();
Evaluate utility
reassign agents types
if the percents of each type aren’t changing, stable = true;
}
report findings
}
Imitator Dynamics
Repeat the experiment using a different way of picking partners and assigning agent types.
Consider the agents to be in a 30 x 30 grid.
Pick your partner by playing with each of your eight neighbors (in repeated play using gamma as
before). If you are on the edge of the grid, find your neighbors by wrapping so that everybody always
has 8 neighbors.
Picking Partners: In a round, each of 900 agents will play each of 8 neighbors (repeatedly, until
gamma is exceeded). Let’s call each repeated game an “interaction”. Thus, there will be 900*8/2
interactions (as when A plays B it also counts for B playing A).
Assigning Agent Types: Each agent will look at its 8 neighbors and decide to take on the strategy of
the most successful neighbor
So the pseudo code might look like:
ImitatorRound()
{
For each player
for each neighbor
OneInteraction(player,neighbor);
}
Experiment()
{assign agents to types
while (ct < ROUNDMAX && not stable)
{ PlayRoundImitator();
Evaluate utility
For each player:
take on strategy of best of my 8 neighbors
if few agents are changing types, stable = true;
}
report findings
}
What to Turn in:
You will be conducting a very large experiment. There are two types of selection/interaction dynamics,
two games, one type of game durations (gamma=0.95), and four types of agents. This means that you
will be doing 2x1x2x4 evaluations, and you will do these multiple times to account for variabilities in
the initial populations. Turn in a summary of your data, and discuss the more interesting results. I
suggest comparing and contrasting the effects of selection/interaction dynamics over the various
games. I also suggest writing your code so that you can do experiments with different initial
populations and then show what evolves as a function of the balance between agents in the initial
populations.
Additionally, do something that you think will be interesting, like add some
mutations, try a different strategy, or try a different interaction dynamic. Turn in
both your code and the analysis of your results.
For ease in grading, please fill out the following summary (in addition to any other analysis you do).
You will state what final percents you ended up with and label the results as (stable) or (unstable),
where stable means this result is generated a reasonable share of the time. Unstable means the results
tend to change wildly with small variations of initial percentages. You can add other information to
this chart as you like.
The final percent
of each agent
type when you
start with equal
percents of each
type.
Prisoner's Dilemma Replicator 95
Coop
Prisoner's Dilemma Replicator 95
Defect
Prisoner's Dilemma Replicator 95
Tit for Tat
Prisoner's Dilemma Replicator 95
!Tit for Tat
Prisoner's Dilemma Imitator 95
Coop
Prisoner's Dilemma Imitator 95
Defect
Prisoner's Dilemma Imitator 95
Tit for Tat
Prisoner's Dilemma Imitator 95
!Tit for Tat
Battle Replicator 95
Coop
Battle Replicator 95
Defect
Battle Replicator 95
Tit for Tat
Battle Replicator 95
!Tit for Tat
Battle Imitator 95
Coop
Battle Imitator 95
Defect
Battle Imitator 95
Tit for Tat
Battle Imitator 95
!Tit for Tat
The final
percent of each
agent type
when you start
with unequal
percents of
each type.
Your
analysis
(Is this a
stable or
repeatable
result?)