Hearing-impaired perceivers` encoding and retrieval speeds for
advertisement

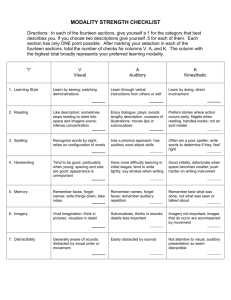
Hearing-impaired perceivers' encoding and retrieval speeds for auditory, visual, and audio-visual spoken words Philip F. Seitz and Ken W. Grant Army Audiology and Speech Center, Walter Reed Army Medical Center [Poster paper presented at the 133rd Meeting of the Acoustical Society of America, State College, PA, June 19, 1997. (Seitz, P.F. (1997). "Hearing-impaired perceivers' encoding and retrieval speeds for auditory, visual, and audiovisual spoken words," J. Acoust. Soc. Am. 101, 3155.)] Note: Full manuscript of this paper is currently in review. OBJECTIVES In older people with acquired hearing loss, investigate whether there are differences among auditory, visual (lipread), and audio-visual spoken words with respect to: • Perceptual encoding speed • Working memory representations. BACKGROUND Current theories of spoken word recognition assume implicitly that the same abstract phonological code underlies spoken words' memory representations irrespective of the sensory modality through which the representations are activated; that is, auditory (A), visual (V), and audio-visual (AV) speech signals differ with respect to the phonetic information they afford, but not the phonological representations they activate (Campbell, 1990). However, even if speech processing is not modality-bound, the phonetic informational differences associated with modality can be expected to affect the efficiency of perceptual encoding of spoken words, as informational differences between natural and synthetic speech do (e.g., Pisoni & Greene, 1990). To the extent that modality differences involve more than just phonetic information (e.g., Campbell, 1985, 1992), they might also affect the quality of words' working memory representations. Such modality-related effects could limit or potentiate the success of speech communication. Perceptual encoding speeds for A, V, and AV speech have not been compared previously. Assuming that 1) V tends to afford less phonetic information per unit of time than A or AV, and 2) the amount of useable phonetic information per unit of time is the main determinant of perceptual encoding costs for speech, then encoding V should be slower than encoding A or AV. Based on observations of 1) faster choice RT to phonetically richer than to phonetically poorer speech signals, e.g., natural vs. synthetic speech (see Pisoni and Greene, 1990); and 2) faster choice RT to bimodal than to unimodal nonspeech stimuli (e.g., Hughes et al., 1994), it would not be surprising to find faster perceptual encoding of AV than A spoken words. However, in a choice RT experiment using synthetic speech syllables, Massaro & Cohen (1983) found no speed "benefit" for AV versus A stimuli. The speed of retrieving information from working memory, as when a probe stimulus must be judged for membership in a short list of memorized items (Sternberg, 1966), can reveal characteristics of working memory representations. Typically, stimulus quality degradation slows encoding but does not slow retrieval. The classical account of this immunity of retrieval operations from stimulus quality factors is that the operands of the retrieval process are represented in an abstract internal code from which stimulus quality properties have been removed (Sternberg, 1967). Therefore, if it is appropriate to conceive of V speech stimuli simply as degraded (informationally poorer) forms of AV or A events, working memory representations arising from V speech signals should be retrieved with the same speed as representations arising from A or AV signals. If modality differences involve more than phonetic information, however, spoken words received in various modalities could have systematic representational differences which might be revealed by characteristic retrieval speeds. APPROACH Task: Sternberg "memory scanning": Subject is presented serially a "memory set" of 1-4 spoken words, then is presented a "probe" to which he/she makes a speeded YES/NO response to indicate whether the probe is a member of the memory set (Sternberg, 1966, 1967, 1969a, 1969b, 1975). See Figure 1. Fig. 1. Schematic representation of a typical memory scanning trial. Trial decpicted has a memory set size of 3 and a correct YES response. Design: All within-subjects. Dependent Variables: Intercept and slope of the memory set size-reaction time (RT) function, as fit to a linear model. Intercept relates to perceptual encoding cost. Slope relates to memory retrieval speed, i.e., the speed with which comparisons are made between working memory representations of the encoded memory set items and probe. Main Independent Variable: Modality (auditory, visual, audiovisual) of spoken word stimuli. Other Independent Variables: Subject age and 3-frequency pure-tone average audiometric threshold (PTA), a measure of severity of auditory disability. METHODS Subjects: • N = 26; • Mean age = 66.2 y., std. dev. = 6.12 • Mean 0.5, 1, 2 kHz average audiometric threshold = 37 dB HL, std. dev. = 11.6 (see Figure 2). Stimuli: Two tokens of each of 10 words from the CID W-22 list, spoken by one talker, professionally video recorded on optical disc: bread, ear, felt, jump, live, owl, pie, star, three, wool This set of words was selected so as to allow 100% accurate closed-set identification in A, V, and AV modalities. Procedure: • After passing a 20/30 vision screening test, subjects established their most-comfortable listening levels (MCL) for monotic, better-ear, linear-amplified presentation of the spoken words under an Etymotic ER-3A insert earphone. All subsequent auditory testing was done at individual subjects' MCLs. • In a screening test, subjects had to demonstrate perfect recognition of the 20 stimuli (10 words × 2 tokens) in A, V, and AV modalities, given advance knowledge of the words. Five subjects out of 33 recruited (15%) did not pass the V (lipreading) part of this screening. • After a 20-trial practice block in each modality, subjects completed three 80-trial A, V, and AV test blocks in counterbalanced order over three 2-hour sessions, thus providing 240 responses per modality and 60 responses per memory set size within a modality. See Figure 2 for trial design. • For each subject, 12 RT means were calculated (3 modalities × 4 memory set sizes). Incorrect responses were discarded, as were responses more than 2.5 standard deviations greater than the mean for each of the 12 cells (Ratcliff, 1993). Least-squares lines were fitted to the four data points representing each subject's memory set size-RT function. Two subjects out of 28 were dropped because of excessive errors or excessively long RT in testing. RESULTS Figure 3 displays the main RT results. Figure 4 summarizes response accuracy. Perceptual Encoding Speed: The intercept (b0) of the linear model of a subject's memory set size-RT function is assumed to represent the sum of encoding speed and motor execution speed. Motor execution speed is assumed to be constant within a subject, so it is relative differences among conditions within a subject that indicate factor effects. Wilcoxon Signed Ranks Tests (2-tailed) were performed on the intercepts of each modality pairing (AV-V, A-V, AV-A). The difference between each modality pairing was significant: • 25/26 subjects encoded AV faster than V (z = 4.41, p < .001) • 21/26 encoded A faster than V (z = 3.72, p < .001) • 21/26 encoded AV faster than A (z = 3.44, p < .001). Retrieval Speed: The slope (b1) of the linear model of a subject's memory set size-RT function is assumed to represent the time it takes to "scan" one item in working memory. The average r2 of linear models was greater than 0.9 for all three modalities, indicating that the data are well fit by a linear model. Wilcoxon Signed Ranks Tests (2-tailed) were performed on the slopes of each modality pairing, and showed that both AV and A scanning speed are significantly faster than V, but AV scanning speed is not significantly faster than A: • 20/26 subjects scanned AV faster than V (z = 3.39, p < .001) • 18/26 scanned A faster than V (z = 2.86, p < .004) • 14/26 scanned AV faster than A (z = 1.18, ns). Response Accuracy: Although subjects showed perfect AV, A, and V word identification accuracy during screening, in RT testing they made significantly more response errors in the V condition than in A or AV, as indicated in Figure 4 and in the outcomes of Wilcoxon Signed Ranks Tests (2-tailed). In V, number of errors was significantly correlated with memory set size (r = .351, p < .01). • 22/26 subjects made more errors in V than AV (z = 3.78, p < .001) • 21/26 subjects made more errors in V than A (z = 3.89, p < .001). Effects of Age: Age was significantly positively correlated with encoding speed only in V (r = .508, p < .01). Age was not significantly correlated with scanning speed in any modality. There were no significant correlations between age and modality-specific or overall error rates. Effects of Severity of Auditory Disability: The 3-frequency (0.5, 1, 2 kHz) pure-tone average audiometric threshold (PTA) was used as a measure of severity of auditory disability. PTA was not significantly correlated with encoding or scanning speed in any modality, nor with error rates. CONCLUSIONS Encoding Speed: • Encoding of lipread speech is slow, even with a closed set of words for which recognition accuracy is close to perfect. • Encoding of auditory speech is speeded up by the addition of visual speech information. This speed-up could partially underlie findings of superior understanding of audiovisual spoken discourse (e.g., Reisberg, McClean, and Goldfield, 1987). Working Memory Representations: • As measured by memory retrieval speed in the memory scanning task, representations of lipread words might be different from those of auditorily or audio-visually perceived words. • There is no evidence for representational differences between auditorily and audiovisually perceived words. Aging and Audiological Factors: • Aging affects speed of encoding visual speech. • Within the tested range of hearing loss, severity of auditory disability has no effect on modality-related encoding and retrieval speed. Alternative Accounts: Differences in error rates among the modalities suggest possible modality-related differences in attentional demands. Apparent representational differences could be due to under-rehearsal of memory set items due to competing demand of difficult encoding. However, this account is inconsistent with the classical claim of independent encoding and retrieval information processing stages. REFERENCES Campbell, R. (1985). "The lateralisation of lipread sounds: A first look," Brain and Cognition 5, 1-22. Campbell, R. (1990). "Lipreading, neuropsychology, and immediate memory," in Neuropsychological Impairments of Short-Term Memory, edited by G. Vallar and T. Shallice (Cambridge U. Press, New York), pp. 268-286. Campbell, R. (1992). "Lip-reading and the modularity of cognitive function: Neuropsychological glimpses of fractionation for speech and for faces," in Analytical Approaches to Human Cognition, edited by J. Alégria, D. Holender, J. Junça de Morais, and M. Radeau (Elsevier Science Publishers, Amsterdam), pp. 275-289. Hughes, H.C., Reuter-Lorenz, P.A., Nozawa, G., and Fendrich, R. (1994). "Visualauditory interactions in sensorimotor processing: Saccades versus manual responses," J. Exp. Psychol.: Human Percept. Perform. 20, 131-153. Massaro, D.W., and Cohen, M.M. (1983). "Categorical or continuous speech perception: A new test," Speech Commun. 2, 15-35. Pisoni, D.B., and Greene, B.G. (1990). "The Role of Cognitive Factors in the Perception of Synthetic Speech," In Research on Speech Perception Progress Report No. 16 (pp. 193-214). Indiana University. Ratcliff, R. (1993). "Methods for dealing with reaction time outliers," Psychol. Bull. 114, 510-532. Reisberg, D., McLean, J., and Goldfield, A. (1987). "Easy to hear but hard to understand: A lipreading advantage with intact auditory stimuli," in Hearing by Eye: The Psychology of Lipreading, edited by B. Dodd and R. Campbell (Lawrence Erlbaum Assoc., Hillsdale, NJ), pp. 97-114. Sternberg, S. (1966). "High-speed scanning in human memory," Science 153, 652-654. Sternberg, S. (1967). "Two operations in character recognition: Some evidence from reaction-time measurements," Percept. and Psychophys. 2, 45-53. Sternberg, S. (1969a). "The discovery of processing stages: Extensions of Donders' method," in Acta Psychologica 30, Attention and Performance II, edited by W.G. Koster (North Holland, Amsterdam), pp. 276-315. Sternberg, S. (1969b). "Memory scanning: Mental processes revealed by reaction-time experiments," American Scientist 57, 421-457. Sternberg, S. (1975). "Memory scanning: New findings and current controversies," Q. J. Exp. Psychol. 27, 1-32. ACKNOWLEDGMENT Supported by research grant numbers R29 DC 01643 and R29 DC 00792 from the National Institute on Deafness and Other Communication Disorders, National Institutes of Health. This research was carried out as part of an approved Walter Reed Army Medical Center, Department of Clinical Investigation research study protocol, Work Unit 2553, entitled "Scanning Memory for Auditory, Visual, and Audiovisual Spoken Words." The opinions and assertions contained herein are the private views of the authors and are not to be construed as official or reflecting the views of the Department of the Army or the Department of Defense. CONTACT INFORMATION Philip F. Seitz, Ph.D. Army Audiology and Speech Center Walter Reed Army Medical Center Washington, DC 20307-5001 (202) 782-8579 Philip-Franz_Seitz@wramc1-amedd.army.mil