Reed6bVigenere
advertisement

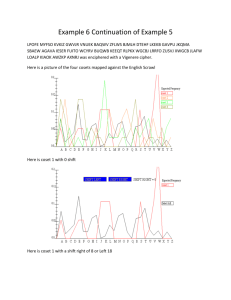
Scott Reed MATH 714 07/21/09 Vigenere Cipher This week, I started to look at the Vigenere cipher. A Vigenere cipher is one that uses a shifted alphabet, called a Caesar shift, in a periodic manner based on a keyword. I more difficult version of Vigenere cipher uses a keyword that is the same size as the original message, making decoding a message much more difficult. The type are sometimes called “one time pad”, as the encoding scheme can only be used for that message due to the number of characters being equal. The cipher is written mathematically by Bauer1 as: A : i with i Nn Nn Ai : Ai ( x) x i showing the cipher is a shift of the letters Ai based on the modulus of Nn. A less complicated mathematical definition is given by Hamilton2 using modular arithmetic as: c ( p k ) mod 26 where: c = ciphertext character value p = plaintext character value k = keyword character value A key to encoding and decoding messages using the Vignere cipher is the Vigenere Square shown in figure 1. The original message letters, or plaintext, form the column headings. The keyword letters are the labels of the rows. The letters are given a numeric value from 0 to 25, where A=0 continuing sequentially until Z=25. The letters of the plaintext are shifted the number of letters corresponding to the number of the letter in the key. The square shows the shifts for each letter, easing the encoding or decoding of the message when the key is known. As an example, the phrase “applied mathematics” will be encoded using the keyword of “math.” Using Hamilton’s formula, the first entry will be applied with A=0, M=12. So that: c = (0+12)mod26 c = 12mod26 c = 12 c=M A P Plaintext M A Keyword Ciphertext M P P T I L H S I E M A X E D M T H W T A T M A M T H T L E H L M M Y A A A T I C S T H M A M P O S The cipher text is then “mpisxewtmtllyampos”, which is very perplexing when seen and it is not known what it is. In my first attempt at using the cipher, I encoded the alphabet using randomized letters in the alphabet to get the following cipher text. Plaintext Keyword Ciphertext A K K B L M C X Z D C F E Y C F Z E G W C H A H I N V J H Q K I S L J U M B N N O B O G U P V K Q S I R E V S T K T M F U D X V U P W R N X P M Y F D Z Q P Figure 1 – Vigenere Square This would be an example of a one time pad, where the message size has an equally sized keyword that does not repeat as normal. Decoding messages using the cipher is the opposite of the encoding. Using the table, find the cipher text in the row of the keyword; then the heading of that column is the plaintext. Mathematically, it is found using the additive inverse in modular arithmetic so that2: p (c (26 k )) mod 26 The problem of decoding a message written in the Vigenere cipher without knowing the key is simplified if the keyword length is found. One method of determining the keyword length is called the Friedman test2. 0.0265n , w (0.065 IC ) n( IC 0.0385) where: w= keyword length n= message length IC= index of coincidence for relatively large n The incidence of coincidence is the “probability that two randomly selected letters from the text are identical.”2 For a Caesar shift, the IC is around 0.065, and for the Vigenere cipher about 0.0385. Another method for determining the keyword length is presented in Tilborg3. Kasiski’s method is based on repeated segments of the cipher text. The method is completed by finding a string of repeated characters, noting their positions in the text. The keyword length should divide the difference of the positions of the repeated characters. If more than one set of repeated characters can be found, then the keyword length is likely a common divisor of the differences in positions of the repeated character strings. Once the keyword length is found, Hamilton2 provides a method to determine the keyword. Since the size of the keyword is known, the cipher text can be split into subsets, one for each character of the keyword. If the index of coincidence of each subset is found, it should be around 0.065, indicating a Caesar shift, which each subset is. The relative frequencies of the letters in each coset are compared to the relative frequcncies of the letters in the standard English language. Let the vector b be the frequencies in standard English so the b=(b1,b2,. . .b26), where b1 is the frequency of the letter a and b26 is the frequency of the letter z. The vector a is the letter frequency of the shifted letters of a subset of the cipher text, where a=(a1,a2,. . .a26). To determine the keyword letter, the vector a is rotated so that: a 0 a (a1 , a 2 , , a 26 ) a1 (a 2 , a3 ,, a 25, a 26 , a1 ) a k (a k 1 , a k 2 ,, a 26 , a1 , , a k 1 , a k ) a 25 (a 26 , a1 , , a 24 , a 25 ) The scalar product for each ak and b is calculated. The index k with the greatest scalar product is likely the value of the letter of the keyword for that subset. This is due to the fact that parallel vectors should have the greatest dot product, as orthogonal vectors have a scalar product of zero. This is what I had found on the Vigenere cipher. I am not sure where it might head from here. Hamilton has developed a program to encode, decode, and decipher the Vigenere for the TI-83. I may look to develop a program also, or to look more into the one time pad problem. 1 Bauer, F.L. Decrypted Secrets: Methods and Maxims of Cryptology. Springer. New York, 1997. 2 Hamilton, Michael and Bill Yonkosky. “The Vigenere Cipher with the TI-83.” Mathematics and Computer Education. 38.1. Winter 2004. 3 Tilborg, Henk C.A. van. Fundamental of Cryptology. Kluwer Academic Publishers. Boston, 2000.