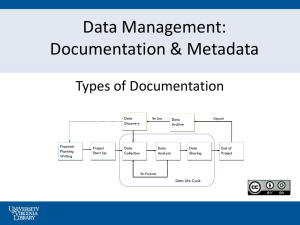
SKETCH FOT THE INFOTMATION GRID ON DATASET PROCESSING
advertisement

SKETCH FOR THE INFORMATION GRID ON DATASET PROCESSING QUESTION GRID ON DATASET PROCESSING GENERALITIES Definition, coverage and scope of dataset processing, Ev. differentiating according to projects and data series. Decision on how well survey will be processed depends on the importance of the survey. If survey is of great national importance or will be used a lot we try to do full processing, if not processing stage might depend either on decision at data archive staff meeting or on how much information you actually have on the survey. Some surveys come in ADP well documented, for other it might be a while until you get all necessary information for writing full Study description or perhaps you never are able to attain full documentation. At beginning we do basic document description, than we continue with basic cleaning data set, and preparing “data description” part of Codebook. Stage of processing is written down in database. Whenever any changes on the data file are made this would normally be written in database and in the “paper” file of the survey. There exist different treatments for some series, like Politbarometer monthly surveys. For monthly surveys “data description” part of Codebook is processed just by basic output from Nesstar Publisher. So the labels are as they are in SPSS data file (normally this would be the format we receive data set in). At the end of the year, yearly data file with all surveys from that year is generated (in this kind of surveys half of the questionnaire stays always the same and other half changes depending of topical issues of that month). This data file if fully described in a Codebook (full question text is added). Since these are CATI surveys and BLAISE is used for questionnaires, we use a program that converge questions from Blaise to data description part of Codebook. STANDARDS Level of control: labelling and content In ADP four levels of data processing exists: docS1 - "Basic Study description" docS2 - "Full Study description" docS3 - "Full Study description + Codebook Data description generated from SPSS data file" docS4 - "Full Study description + Codebook Data description with full questions text" Stages are inserted in Codebook as entities so no mistyping is possible. Standard categories for access conditions: formulation and definition; special cases link - http://www.adp.fdv.uni-lj.si/en/use.htm General restrictions: 1. ADP provides data only to users, which specify their purpose, comply with the professional code of ethics, agree with the condition that the author and ADP are fully cited in the publications which are based on the received data, and pay the required fees. This means that copies of the received materials may not be distributed to anyone without prior written consent of the ADP. This holds also for password for Nesstar. To prevent possible misuse of data, the latter shall be erased from the electronic carrier after the assignment is completed. The user must fill out another order-form and specify the purpose if he/she plans to use the materials again. 2. The user must carefully read the accompanying documentation before using the received data. 3. Every user is obliged to notify ADP of any defects in the materials, supply ADP with any additions to the original files, and send two copies of the resulting texts to ADP (when published inform us about bibliographic information). 4. By signing the order-form the user commits him/herself to respecting the rules and regulations described above. 5. Materials may be used exclusively for the specified purpose. Attempts to identify individuals are prohibited. Authors of studies usually impose the following specific regulations: 1. Limited for the use of the funding agency and the study group. Written permission of the depositor/author is required. Usually this type of restriction is waived after a certain period of time. 2. The use of data is allowed for scientific and educational purposes exclusively. Standard variable names Not used. As given by depositor. Standard order of variables in data files Not used. As given by depositor. Standard coding and labelling of missing values Normally not used. As given by depositor. In some series when we know how labelling is used we would additionally code value “8 as DK”, “9 as NA”, if it is a system missing - sys, and if the value written is not likely to be correct (for example – answer 0 on how many people live in your household) are coded as 9999. Standard coding of scales Not used. As given by depositor. Standard coding of closed variables Not used. As given by depositor. Standard data file formats; exceptions and special cases; store / distribution Input data files are not as diverse as they might be in other larger countries. Nowadays they come in as SPSS or Excel format. Some old data files may be in old versions of SPSS (*.sys) or ASCII format. Stored data files are first – the original we receive, and second, in the format that they are distributed in, in most cases that would be SPSS portable (*.por) file. If some special coding was done or so, we also store information that is necessary for understanding data itself. Saved data file might also be in *.sav, *.sys or *.raw format. For all this formats entities are used again (while writing codebook). Type of the data file is written in database, from which File Description part of Codebook is generated. If data file is changed and this change is marked in database, than next time we produce output of database (with parts of XML DTD description of Codebooks such as File description part or Other Material part) files will automatically change on the server. No more additional editing is necessary. Since most of the important data files are put on Nesstar, user can download all formats that are available in Nesstar, also for SAS and STATA. We do not have special programmes for transposing data files in different programs. Standard documentation file formats; exceptions and special cases; store / distribution Standard documentation file formats - again entities are used (again in data base first – they could be added manually in XML file) - *.txt, *.doc, *.rtf, *.htm, *.xml, printed, *.pdf, graphical – picture. Deposited format is saved (also some old files in Word perfect, or Word Star), distribution formats nowadays are mostly searchable Adobe Acrobat files. Some old Study description may still have questionnaires either is pictures (*.tif) or MS Word file. Both were usually put on-line as archived (*.zip). The above goes for things like questionnaires, documents related to the survey, instructions for interviewers and a like. If some changes to data file are done in ADP we save SPSS syntax (program lines) for those changes. In most cases changes in data files are done if some labels are missing, or values that are missing codes are not defined as such. And in order to use them properly in Nesstar they need to be defined as such. Standard treatment of constructed variables: handling, documentation Not used. As given by depositor. Sometimes depositors provide us with SPSS syntax file where constructed variables are described. Those files are saved, linked under survey in database; sometimes even put on web and linked under Other study-related material part of Codebook. Standard processing and documentation of filters (filtered variable and filtering question) Not used. As given by depositor. Additional to above : 1) Standard saving and naming of data files on the disk. If we have a questionnaire we add –vp (to the Study ID) (vp – abbreviation for vprasalnik – questionnaire). For example EVS99-vp.pdf. Directories for saving documents are also structured. Directory is always named by letters (first part) of Study ID. For ex. data/ISSP/. Inside all files for distribution are saved. Special directory is used for all other undistributed (and original)documents linked to this survey. Structure of Study ID – 8 characters – usually 6 letters 2 numbers (year of the survey) if there are more surveys in one year 3 or 4 numbers are used (for ex. PBSI0102). 2) Standard bibliographic citation format MRDF is used. 3) In Codebook processing part of Data Processing – standard topics classification is used (again as entities- define by CESSDA DDI GROUP). – recommended Date standard is used YYYY-MM-DD – recommended XML-lang standard is used – ISO 3116 TECHNICAL ISSUES We propose that someone (that have the means and possibilities) take care for old machines. Even thou that quite some year passed by from really old formats they always tend to come from somewhere. (Professor is cleaning up his/hers cabinet at the University or so.) If someone (organisation) had enough space and means I guess archives are also willing to pay for this kind of services. Card images, multipunch We have them but do not have the machine to read them. Idea was to scan them and write a program that could read them (still did not get to do it). Raw data with file info In most cases this is solved by program transportation. Raw data file should be saved if they are deposited files. But also program for conversion of them should be save somewhere. If there are more versions of one data set they should be saved and information about this should be made. So not just hardware, but also software should be saved and offered for other CESSDA archives. Tapes for various operating system Also reading magnetic tapes. There are probably still larger firms that have machines saved for their needs. Format conversions: typical cases and difficult cases For distribution purposes – if user would want formats that are not SPSS or Excel formats, we would use Nesstar as conversion tool. Since it has possibility for data to be downloaded also in other formats. Character encoding (Mac vs. ANSI or ASCII) Documents are saved in UTF-8. Data files and labels are kept as supplied by depositor. Unsolved problems / TYPES OF PROBLEMS ACTUALLY LOOKED FOR First of all let me state here that detailed and deep checking can be done only in the archives where they have enough staff and means. In ADP it is a policy that the depositors should give us data files ready for distribution. They also sign this in the depositor form. Never the less we do some checking but not as detailed as large archives like UKDA or ZA do it. All of below might be checked out with depositors. In some cases depositors are not reachable any more (deceased, abroad etc.). If we do not get any help from their assistants we would have to leave information / data as we got it. In some cases we would write down comments in a Codebook. Undocumented variables We would ask depositors (sometimes to long time is passed from the survey – and data file construction and even they do not know it). In some cases you may even know in advance what labels are – in case this are postal codes, or standard Slovene municipality codes, or telephone network codes. Some researchers use standard codes also for some coded variables and if we know it in advance we add it ourselves. It is a policy that we check (try to get confirmation) for this additional documentation from depositor - that goes for all below cases. This is additional from those descriptions of the variables that are missing and are available in questionnaire. "Missing" variables (questions without output) We would again ask depositor. If no information is available just mark that in Codebook. Definition of constructed variables If there is some and if it is received from depositor we would add it in Other Study-related materials part of Codebook; or at least write it down in our internal database so if anyone would be looking for it we would know it is there. We would also write information about this in data description part (as variable description). Undocumented filters – Appropriate definition of INAPS We would again ask depositor. If no information is available just mark that in Codebook. If would do the documenting we would ask depositor to confirm this. Undefined missing, system missing We would ask depositor. If no information is available just mark that in Codebook. If would do the documenting we would ask depositor to confirm this. Undefined values, wild codes We would ask depositor. If no information is available just mark that in Codebook. If would do the documenting we would ask depositor to confirm this. Inconsistencies between data and external metadata We would check if there is consistency between data and questionnaire, or perhaps older Codebook, or one got from other archives (especially when international data sets are into consideration). Tracking the data source (question in questionnaire) When “half-automatic” joining of data and questionnaire is done. Then we would “manually” check if things correspond to each other (if answer codes in data file are the same as in the questionnaire and so). Plausibility If you know in advance that survey have a question that might have this kind of problems. Since we do not check all summary statistics we would notice plausibility problems only while checking for missing codes or by chance. Confidentiality and disclosure Identification of critical variables: standard (location), test procedures Suppression or replacement of variables We tend to exclude the obvious identifiers, like telephone numbers, names, addresses even municipality codes since they are to detailed. If a survey exist (like survey of high governmental officials) where releasing almost any demographic information would cause a disclosure and if depositor itself does not put a restriction on it we would suggest putting it. Not to have it completely (without and restrictions) available to everyone. Sometimes (in a case of Slovene statistical office) depositor does these. They do suppress data or represent them with artificial grouping code. Most of the data files that come in ADP are clean and documented good enough for distributing. Especially when we get data from permanent depositors. VARIABLE LEVEL METADATA PRESENTATION Distributing the questionnaire with variable names Most of the times (90%) questionnaire is distributed freely - put on-line. Newer files are already in computer readable formats that are distributed as rich text files (*.rtf). Older questionnaires are scanned (in some cases even word recognition with (OmniPage) is made. They would normally be distributed as *.pdf files. Adding questions to DDI-XML files produced with Publisher This is done for most important surveys. It takes a while to do “hand” transferring and there are a lot possibilities for mistakes. It is still easier thou than putting information in manually in XML documents. Filling a multiple scope database / THE GENERAL APPROACH: LOOKING FOR PROBLEMS… Problems looked for (data file, documentation (files), data-documentation consistency, plausibility) Some checking – consistency with question text and data file (especially if data description part of Codebook was generated separately with available program) may be made when transporting all information in Nesstar. Tool or technique for identification Visual inspection of frequencies and output fields is done. Typical solution Obvious, easy to solve things you would do on your own (like mistyping or so). Sometimes we would delete a part or just mark down that there is something missing and you could not get it solved. Tool or technique applied for correction / Documentation of the identified problem (database/report) Sometimes written in the database. Most of the time problems would be written in paper file of the survey and in Codebook (as comments in file or data description part). Documentation of the intervention on the data (database/report) Write it in “paper” file the database. We save program (SPSS syntax) in electronic and print copy. We notify (and ask for acceptance) the depositor. TECHNIQUES, TOOLS AND CHECK-LIST Inventory of tools, techniques and checklists of general interest We have some “converters” from *.doc or SPSS files to Data description part of Codebook; and from Blaise (Cati surveys) to Data description. WORKFLOW CONTROL Control from other colleagues in ADP may be performed. Check-list Check-list is connected with steps and sub-steps described below. For example you would write here ID number of the survey, or the data when finished versions are published etc. You would save this check-list printed in “paper” file of the survey. If someone else is continuing your work they know what was done. Database Special instructions are prepared as recommended entering of information in database (Access 2000). Person needs to be especially careful with sub-links. Steps and sub-steps Steps from receiving data to final product are written down. - When you get a new survey in define fist its ID number (discuss this with the head of ADP). - Find a (paper) folder for all documents you have on this survey. Put them there and write ID of the Survey on it. - Book the study in the database. Write in also all documentation (regardless if they are in paper or electronic format) connected with the survey. - Check data file. Do the cleaning, define missing codes, etc. Discussion with researcher about anything strange. Make a distribution version of data set. Write this information in the database. - Extract all the information available in database to XML DTD predefined form of the survey. Check if all entities (new author, organization) that you will need, already exist. - Write Codebook (most of the time, stage of production of Codebooks (see first page) is defined in advance). Before writing codebook on your own you might reconsider asking depositor to do first description. Format for describing survey for depositor is similar to the one UKDA have. Some depositors are willing to do that. When you finish your Codebook do check all information again with depositor. In this stage we would also check library system if there was anything published from that survey, and scan questionnaires if they are not already in electronic format. “Final” Codebook should be checked also by the head of ADP. - Write a report of all documents we are saving about the survey written in database. Write a contract for depositor with pre-agreed distribution agreement and get it signed. - Put the study description (XML) on the web. Start preparing study for distribution via Nesstar. - Make a backup of everything you did until now. Special instructions are prepared with mentioned parts of Codebook; where special attention is needed. Like in date format, or where you need to change one of the attributes – such as source (let say from “producer” – which is predefined to “archive” if we did the work). Distribution of work All employed do full processing of a particular survey. DOCUMENTATION OF DATA PROCESSING If “larger” changes of the data file were done in ADP and we never get authorisation (that goes also for whole Study description) for depositor or author we would make a mark in notes as for example “Study description is not authorised” or “Data file was changed in the Archive – for details contact a person responsible for the survey.” or something similar. We also document which version of the data file or Codebook it is available (or distributed), and what was changed from previous one. Media Data files and all electronic documentation of the survey are saved on computer disks and several back-up CD’s. Some times – for a series of Slovene Public Opinion Survey – distribution CD with whole series until 2002 was produced. Format Documentation is either added in Codebook description or written down in paper file of the survey. Sometimes both. Also syntax (programmes) files are produced and saved. See Standard section of this report for more details. Distribution If someone would request this documentation they would probably have access to it. TRAINIG OF DATA ARCHIVISTS When describing a survey – the best way to start is with completely empty form and follow all instruction available at DDI web page – which fields should be used and how they follow, and what should be stated in them. Latter on when you get some of this information in your mind you may work with predesign Codebook. Training material Most of the times we direct new data archivist to visit DDI web page, since there are many information on it, to read FAQ and links. To check out our web page and web pages of some others most “documented” archives and try to compare them. There are some internal documents (some already described above) – as standard for bibliographic citation (with examples); Processing of Study description – Codebook; How to write information in the database; Where in writing Codebook special attention is needed; Additional agreements – as to which directories you need to save different data and documents, what to do with special signs (as in Slovene alphabet or &, < or >). Guide on the Nesstar page on how to use Nesstar Publisher is also used. Training courses, seminars, workshops No special. We do not have so much new people coming and going that this would be necessary. But if someone is attending a conference of data archive’s nature they might attend workshops that would give them some additional information and knowledge. ??? Also “education” in larger archives such as UKDA, ZA etc is a great addition. Specific (archive specific resources) / unspecific (general interest academic resources) - Additional to mentioned papers there might be some comments / agreement form staff meetings that are important for whole work. Special papers about that are produced also (with the day of the meeting – so we know when change did actually took place). MIGRATION EXPERIENCE (DATA AND DOCUMENTATION) Possibilities offered by Nesstar! Standard starting from Description of the problem New standard Migration strategy /technique .. Standard policy Non standard formats yet in use Expected difficulties Use of open source solutions STANDARDS OF DOCUMENTATION PROPOSED TO THE DATA DEPOSITOR Available documents, language, accessibility, links We prepared standard form for survey description for depositors. There is also preferable standard for data description (used by most researchers in Slovenia). We always require questionnaire and show cards (if they exist). FEEDBACK FROM DATA USER ON DATA PROCESSING? The best data processing is the least visible, isn’t it? So, we should have more feed-back on unprocessed or badly processes data… Open question. ??? Should we not think of saving data files in formats and with program extensions of the program that might be more easily (cheaper) available for the users. What will happen in data archive do not have enough money on its own to even afford to pay SPSS licence, not to mentioned some programmes that just large data archive are using? Problems of translation. Should we have someone that will check translation (into English language) for us? Of how good quality should this translations be? Is there a possibility to employ CESSDA archive computer engineer - XML, XSL and so specialist. There is not enough money for all small archives to have someone employed, but we may work with English instructions and files and share costs???? Changes of formats and standards?? Who will deal with this? Should we transform data files every 5th year????