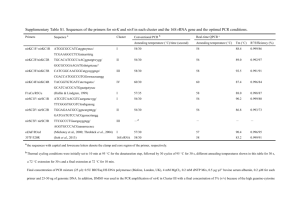
Species endemic to marine biogeographic transition zones: habitat

Journal of Biogeogaphy
SUPPORTING INFORMATION
Mitonuclear discordance in genetic structure across the
Atlantic/Indian Ocean biogeographical transition zone
Peter R. Teske, Isabelle Papadopoulos, Nigel P. Barker,
Christopher D. McQuaid and Luciano B. Beheregaray
Appendix S1 Supplementary methods.
DNA extraction
Muscle tissue from the legs of live specimens was placed directly into CTAB extraction buffer
(Doyle & Doyle, 1990) in the field, proteinase K was added for digestion, and the extraction procedure was continued on return to the laboratory (no more than three days after sampling).
Primers used
The COI gene was amplified using universal primers (Folmer et al.
, 1994). In the case of samples that did not amplify with these primers (approximately 20%), we used COI primers for crustaceans
(CrustCOI-F, 5′-TCA ACA AAT CAY AAA GAY ATT GG-3′; PeracCOI-R, 5′-TAT WCC TAC
WGT RAA TAT ATG ATG-3′; Teske et al.
, 2006). Amplification of 10% of the samples sequenced using universal primers was repeated using these alternative primers, and all had identical sequences. This suggests that non-amplification was due to mismatches between primers and annealing sites rather than the presence of alternative templates such as nuclear mitochondrial sequences
(numts). Ten percent of the samples were amplified using exon-primed, intron-crossing primers that amplify a portion of the ANT gene and its complete intron in decapod crustaceans (DecapANT-F,
5′-CCT CTT GAY TTC GCK CGA AC-3′; DecapANT-R, 5′-TCA TCA TGC GCC TAC GCA
C-3′; Teske & Beheregaray, 2009). The intron of H. orbiculare contained several large indels and it was often difficult to fully resolve the resulting sequences in individuals that were heterozygous for alleles of different lengths because the electropherogram peaks present at a particular position were not always perfectly aligned; the remaining samples were therefore amplified using two internal primers (forward primer HorbIntF2, 5′-GCG TTT ACA ACA CTG CCA AA-3′; reverse primer
HorbIntR1b, 5′-CAW AAG AAT GRT AAA CGG GAA A-3′) that anneal to a region located between two common indels.
Polymerase chain reaction (PCR)
PCR included 5
L of 10
NH
4
standard reaction buffer (Promega, Madison, WI, USA), 6 m M
( COI ) or 3 m
M
( ANT intron) of MgCl
2
, 0.16 m
M
of each dNTP (Bioline, Tauntaon, MA, USA),
3 pmol/
L of each primer, 2
L of 10 mg/mL bovine serum albumin, 1 U of GoTaq polymerase
(Promega) and 5
L of DNA extract in a total volume of 50
L. The PCR profile comprised an initial denaturation step (3 min at 94 °C), 35 cycles of denaturation (30 s at 94 °C), annealing (45 s at 50 °C for COI or 60 °C for the ANT intron) and extension (45 s at 72 °C), followed by a final extension step (15 min at 72 °C). PCR products were purified with MSB Spin PCRapace (Invitek,
Berlin, Germany) clean-up system (35
L eluate), cycle-sequenced in both directions using BigDye
Terminator v3.1 Cycle Sequencing Kit (Applied Biosystems, Foster City, CA, USA) following the manufacturer’s instructions, and visualized on an ABI 3100 Genetic Analyser. Cycle sequencing reactions included either 5
L of PCR product per 20
L reaction and 30 cycles ( COI ) or 1
L of
PCR product and 25 cycles ( ANT intron). If the signal in the resulting chromatograms from ANT intron sequences was still too strong, cycle sequencing was repeated using 1 : 5 dilutions of PCR products.
IM A 2 analyses
IM
A
2 runs were performed in ‘M-mode’ (Markov chain simulation mode) using the following specifications: ‘-d 50’ (genealogies saved every 50 generations); ‘-b 100000’ (burn-in, i.e. the initial number of steps that is discarded); ‘-n 150’ (number of heated chains); ‘-f g’ (geometric heating scheme); and ‘-g1 0.999 -g2 0.3’ (terms of the geometric heating increment model). The upper bounds for all scaled demographic parameters were determined individually for each data set following a number of test runs. Because the different character positions of genes evolve at different rates, we only used the most informative third character positions of the COI gene for these and all subsequent analyses. The HKY (Hasegawa et al.
, 1985) model was specified for both loci. Each run was repeated three times with different random starting seeds, and convergence on similar values was considered to be an indication that results were not affected by priors or an inefficient heating scheme. Runs were terminated when a joint total of at least 100,000 genealogies were saved. To determine whether a model of panmixia explained the COI data better than one in which sequences were divided into biogeography-based groups, we created three data sets in which the original COI sequences were randomly shuffled between groups. Each data set was then run in IM A 2 for a minimum of 1 million generations, and the resulting estimates of t were considered different from those of the original data set if their 95% highest posterior densities (HPDs) did not overlap.
REFERENCES
Doyle, J.J. & Doyle, J.L. (1990) Isolation of plant DNA from fresh tissue. Focus , 12 , 13–15.
Folmer, O., Black, M., Hoeh, W., Lutz, R. & Vrijenhoek, R. (1994) DNA primers for amplification of mitochondrial cytochrome c oxidase subunit I from diverse metazoan invertebrates. Molecular Marine Biology and Biotechnology , 3 , 294–299.
Hasegawa, M., Kishino, H. & Yano, T-A. (1985) Dating of the human–ape splitting by a molecular clock of mitochondrial DNA. Journal of Molecular Evolution , 22 , 160–174.
Teske, P.R., McQuaid, C.D., Froneman, P.W. & Barker, N.P. (2006) Impacts of marine biogeographic boundaries on phylogeographic patterns of three South African estuarine crustaceans. Marine Ecology Progress Series , 314 , 283–293.
Teske, P.R. & Beheregaray, L.B. (2009) Intron-spanning primers for the amplification of the nuclear ANT gene in decapod crustaceans. Molecular Ecology Resources , 9 , 774–776.