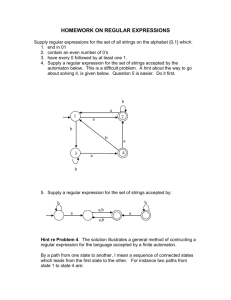
INTRODUCTION
advertisement

COMPUTATIONAL LINGUISTICS
Fred Landman
Class Notes, revised 2008
INTRODUCTION
Grammar: structure or rule-system which describes/explains the phenomena of a
language, constructions.
-Motivated by linguistic concerns.
-But also by computational concerns.
-a grammar supports the judgements about the data on the basis of which it is built.
-processing of sentences is rapid, online.
Suppose you have found a 'super grammar' for English, it works really well.
And then some nasty mathematician proves that your grammar cannot support a
mechanism for making the judgements that it is based on.
Or some nasty mathematician proves that your grammar cannot suppoty an online
processing mechanism to process online even the sentences that we know we process
online.
In that case, you have a super grammar, but apparently not the one that native
speakers of English use, because they do have the judgements they do, and they do
process online what they process online.
These are questions about the power of grammatical operations.
If the grammar doesn't have enough power, you can't describe what you want to
describe.
If the grammar has to much power, it becomes a system like arithmetics: you can
learn to do the tricks, but clearly native speakers do not have a lot of native
judgements about the outcome of arithmetical operations, nor are they natively very
good at doing arithmetics online. And, we know that there are good reasons why this
is so: Arithmetics is a very powerful system, provably too complex to support
systematically native judgements about the outcomes of the operations, and provably
to complex to do online (though bits of it can be done very fast by pocket calculators,
as we know).
So the queston is: How much power is needed, and how much power is too much?
Formal language theory provides a framework for comparing different grammatical
theories with respect to power.
2
PART 1. STRINGS, TREES AND REWRITE GRAMMARS.
ALPHABETS, STRINGS, AND LANGUAGES
Let A be a set.
The set of strings on A is the set:
A* ={<a1,…,an>: n 0 and a1,…,an A}
The operation * is called the Kleene closure.
Concatenation, , is a two-place operation on A*:
<a1,…,an> <b1,…,bm> = <a1,…,an,b1,…,bm>
-<>, the empty string, is in A*, we write e for the empty string.
Another characterization of A*:
A* = {α: for some α1...αn A such that n ≥0: α = α1...αn}
A*
if e A
A*{e}
if e A
A+ =
Facts: - is associative, but not commutative.
(α β) γ = α (β γ)
but not: α β = β α
- e is an identity element for :
for every α A*: e α = α e = e
This means that we understand, the bracket notation in such a way that, say, <a,e,b> is
a pair (and not a triple).
Notation: we write a1…an for <a1,…,an>, hence we also identify <a> and a.
Note that we can write, when we want to, ab as aeb or as eeeaeebeee.
This is the same string, by the fact that e is an identity element.
Example:
A = {a}
A* = {e, a, aa, aaa, aaaa, …}
A+ = {a, aa, aaa, aaa, …}
If α is a1…b1…bn…am, we call b1…bm a substring of α.
A prefix of α is an initial substring of α, a suffix of α is a final substring of α.
Fact: e is a substring of every string.
α is an atom in A* if αe and the only substrings of α in A* are e and α itself.
An alphabet is a set A such that every element a A is an atom in A*.
We call the elements of alphabet A symbols or lexical items.
3
Fact: If A is an alphabet, then every string in A* has a unique decomposition into
symbols of A.
Example: {a, b, ab} would not be an alphabet, since ab is in {a,b,ab}, but it is not an
atom. We restrict ourselves to alphabets, because then we can define the length of a
string:
Let A be an alphabet.
The length of string α in A*, |α|, is the number of occurrences
of symbols of A in α.
Let a A.
|a|α is the number of occurrences of symbol a in α.
Note that we do not allow the empty string to occur as a symbol in alphabet A.
(This means that, for alphabet A, A+ = A*{e}.)
Note further that in calculating the length of a string, we do not count e:
if A = {a,b}, |aaebbeaa| = |aabbaa| = 6
A language in alphabet A is a set of strings in A*:
L is a language in alphabet A iff L A*
Note: the theory is typically developed for languages in finite alphabets (important:
this does not mean finite languages). That is, the lexicon is assumed to be finite.
In linguistics, the usual assumption is that the lexicon is not finite (missile,
antimissile, antiantimissile,…). This is mainly a problem of terminology: the formal
notion of grammar that we will define here will not distinguish between lexical rules
and syntactic rules (but you can easily introduce that distinction when wanted). So,
if the grammar contains lexical rules, the alphabet would be the finite starting set of
irreducible lexical items.
4
TREES
A partial order is a pair <A, >, where A is a non-empty set and is a reflexive,
transitive, antisymmetric relation on A
Reflexive: for all a A: a a
Transitive: for all a,b,c A: if a b and b c then a c
Antisymmetric: for all a,b A: if a b and b a then a=b
A strict partial order is a pair <A,<>, where A is a non-empty set and < is an
irreflexive, transitive, asymmetric relation of A.
Irreflexive: for all a A: (a a)
Antisymmetric: for all a,b A: if a < b then (b < a)
Graphs of partial orders:
-We don't distinguish between reflexive and irreflexive.
-We don't write transitivity arrows.
-The direction of the graph is understood.
o
o
o
o
o
o
o
o
o
o
A tree is a structure <A,,O,L> where:
1. A is a finite set of nodes.
2. , the relation of dominance, is a partial order on A.
3. 0, the topnode or origin is the minimum in :
for every a A: 0 a
4. Non-branching upwards:
For every a,b,c A: if b a and c a then b c or c b
5. --This is the standard notion of tree in mathematics. For linguistic purposes, we are
interested in something more restricted. Up to now the following trees are exactly the
same tree:
o
o
A
o
o
o
B
o
o
C
o
B
o
A
o
C
5
We want to distinguish these, and do that by adding a leftness relation L:
5. L , the leftness relation is a strict partial order on A satisfying:
Semi-connectedness:
for all a,b A: (a b) and (b a) iff L(a,b) or L(b,a)
Fact: L satisfies monotonicity:
for all a,b,a1,b1 A: if a a1 and b b1 and L(a,b), then L(a1,b1)
Proof:
Assume a a1 and b b1 and L(a,b). We show: L(a1,b1).
First we show that: L(a1,b1) or L(b1,a1).
-Assume a1 b1. Then, by transitivity of , a b1. Then a b1 and b b1, and by
non-branching upward ,a b or b a. Then L(a,b).
This contradicts the assumption, so we have shown: (a1 b1).
-Assume b1 a1. Then, by transitivity of , b a1. Then a a1 and b a1, and by
non-branching upward, a b or b a. Then L(a,b).
This, again, contradicts the assumption, so we have shown: (b1 a1).
By semi-connectedness, it follows that: L(a1,b1) or L(b1,a1).
Next we show that L(a1,b).
-Assume a1 b. Then, by transitivity of , a b.
This contradicts the assumption that L(a,b), so we have shown that (a1 b).
-Assume b a1. Then a a1 and b a1 and, by non-branching upwards, a b or
b a. Again, this contradicts the assumption that L(a,b), so we have shown that
(b a1).
Hence, it follows, by semi-connectedness, that L(a1,b) or L(b,a1).
Assume L(b,a1). Then L(a,b) and L(b,a1), and, by transitivity of L, L(a,a1).
This contradicts the assumption that a a1, so we have shown that L(b,a1).
It follows indeed that L(a1,b).
Finally, we show that L(a1,b1).
Assume, L(b1,a1).
Since we have just shown that L(a1,b), it follows, by transitivity of L, that L(b1,b).
This contradicts the assumption that b b1. We conclude that L(b1,a1).
By the first part of the proof it now follows that: L(a1,b1).
We are done.
We make the convention of leaving out Leftness from the pictures of trees, and
assume it to be understood as left in the picture.
T1
o1
o
A
T2
o2
o
B
o1
2o
o
C
o
B
o
A
o
C
6
Thus the picture T1 summarizes the tree
T1 = <A,,0,L1>, where:
A = {1,2,A,B,C}
= {<1,1>, <1,A>, <1,2>, <1,B>, <1,C>, <A,A>,
<2,2>, <2,B>, <2,C>, <B,B>, <C,C>}
0T1 = 1
L1 = {<A,2>, <A,B>, <A,C>, <B,C>}
and the picture T2 summarizes the tree
T2 = <A,,0,L2>, where:
A = {1,2,A,B,C}
= {<1,1>, <1,A>, <1,2>, <1,B>, <1,C>, <A,A>,
<2,2>, <2,B>, <2,C>, <B,B>, <C,C>}
0T2 = 1
L2 = {<2,A>, <B,A>, <C,A>, <B,C>}
Given tree A.
A labeling function L for A is a function assiging to every node in A a label
usually a symbol or a string.
A labeled tree is a pair <A,L>, where A is a tree, and L a labeling function for
A.
Given tree A.
We know that A has a minimum 0.
The leaves of A are the maximal elements of A:
node a A is a leaf of A iff for no b A: a < b.
A chain in A is a subset of A linearly ordered by :
C A is a chain in A iff for all a,b C: a b or b a.
A path in A (or branch in A) is a maximal chain in A:
chain C in A is a maximal chain iff for every chain C' in A:
if C C' then C=C'.
A bar in A is a subset of A intersecting every path in A.
A cut in A is a minimal bar in A.
Fact: every cut in A is linearly ordered by L.
Proof: suppose C is a cut in A, but not linearly ordered by L.
Then for some a,b C, either L(a,b) or L(b,a). Then, by semi-connectedness
either a b or b a, say, a b.
Then C{b} is a bar in A. Since C{b} C, this contradicts the assumption that C
was minimal.
Corrollary: The set of leaves in A is linearly ordered by L.
Proof: the set of leaves is a cut in A.
Let T be a labeled tree in which each leaf is labeled by a string in A*. Let the
leaves be a1,…an in left right order, and for each node a, let l(a) be the label of
that node.
7
The yield of T is the string l(a1)… l(an).
So, the yield of a tree is the string that you get by concatenating the strings on the
leaves of the tree in left-right order.
Let T be a set of labeled trees of the above sort.
The yield of T is the set of strings: {α: for some T T: α is the yield of T}
8
STRING REWRITE GRAMMARS
A grammar is a tuple G = <VN,VT,S,P>, where:
1. VN, the set of non-terminal symbols, is a finite set of symbols (category
labels like, say, S, NP, VP, V).
2. VT, the set of terminal symbols is a finite set of symbols (lexical items)
3. VN VT = Ø.
V = VN VT is called the vocabulary.
4. S is a designated non-terminal symbol, the start symbol.
S VN.
5. P is a finite set of production rules.
Every production rule has the form:
φψ
where φ, ψ V*, φ e.
We read φ ψ as: rewrite string φ as string ψ.
What this means is the following:
Let G be a grammar and Let α, φ, ψ V* and let nφ be an occurrence of string φ in α
and let α[nψ/nφ] be the result of replacing occurrence nφ of φ by an occurrence nψ of ψ
in α.
A rule φ ψ allows us to rewrite string φ as string ψ in α if α contains an occurrence
nφ of φ, and this means: replace α by α[nψ/nφ].
Example: V NP V DET N
This rule allows us to rewrite the string: NP V NP PP as NP V DET N PP.
But it doesn't allow us to rewrite the string: John kissed NP in the garden
as: John kissed DET N in the garden.
Example: NP DET N
This rule allows us to rewrite the string: NP V NP PP as NP V DET N PP
And it allows us to rewrite the string: John kissed NP in the garden
as: John kissed DET N in the garden.
Let G be a grammar, α, β, φ, ψ V*, R P, where R = φ ψ, nφ an occurrence of
φ in α.
α G,R,n β, α directly dominates β by rule R at n iff β = α[nψ/nφ]
(β is the result of replacing occurrence nφ of φ in α by occurrence nψ of ψ.
α G,R β, α directly dominates β by rule R iff for some nφ in α, β = α[nψ/nφ]
α G β iff for some rule R P: α G,R β
Let G be a grammar, φ1,…,φn V*, R1…Rn-1 a sequence of rules from P (so rules
from P may occur more than once in the sequence), n1…nn-1 a sequence of occurences
of subformulas in φ1,…,φn-1 (with ni in φi)
9
<φ1,R1,1>….<φn-1,Rn-1,n-1><φn> is a derivation of φn from φ1 in G iff:
for every i<n: φi G,Ri,ni φi+1
Derivation <φ1,R1,1>….<φn-1,Rn-1,n-1><φn> is terminated in G iff there is no
derivation <φ1,R1,1>….<φn-1,Rn-1,n-1><φn,Rn,n><ψ> of some string ψ in G
Thus, a derivation of φn is terminated in G if no rule of G is applicable to φn anymore.
α is a terminal string generated by G iff
1. There is a terminated derivation in G which starts with S and ends with α,
<S,R1,1>….<α>.
2. α is a string of terminal symbols, i.e. α VT*.
The language generated by G, L(G), is the set of terminal strings generated by G.
Grammars G and G' are weakly equivalent iff L(G) = L(G')
In rule R = φ ψ, φ and every substring of φ occurs on the left side of R, ψ and
every substring of ψ occurs on the right side of R, φ itself occurs as the left side of R.
Grammar G is in reduced form iff startsymbol S does not occur on the right side of
any rule in G.
Theorem: For any grammar G, there is a grammar G' which is in reduced form such
that L(G)=L(G')
Proof:
Let G be any grammar.
Add a new symbol S0 to VN and replace in every rule every occurrence of S by S0.
This gives us a new set of rules P'. Call this grammar G'.
The language generated in G' from S0 is, of course, the same language as the language
generated in G from S.
Let R be a rule in the new set which contains S0 as the left side.
Let R[S/S0] be the result of replacing in R S0 as the left side by S, leaving the right
side unchanged.
Add to P', for every such rule R, rule R[S/S0] to the grammar.
Call this grammar GRED.
GRED is obviously a grammar which is in reduced form (S does not occur on the right
side of any rule, though S0 may well).
And GRED generates the same language as G.
This can be seen as follows.
Suppose that in G we had a terminated derivation of a terminal string α:
<S,R1,1><φ1,R2,2>….<φn-1,Rn-1,n-1><α>.
This means, that in G' we have a terminated derivation of α of the form:
<S0,R1*,1><φ1,R2*,2>….<φn-1,Rn-1*,n-1><α>
where Ri* is Ri if we didn't need to change it, otherwise it is the changed rule.
Since S0 directly dominates φ1 by R1*, and since S0 is a symbol, S0 occurs as the left
side of R1*. But this means that that GRED contains rule R1*[S/S0], and that means
that in GRED we have a terminated derivation of α:
10
<S,R1*[S/S0],1><φ1,R2*,2>….<φn-1,Rn-1*,n-1><α>.
Thus, GRED generates α.
Vice versa, we note that no rule in GRED contains S on the right side. This means that
there are no derivations in GRED where a rule R1*[S/S0] occurs in any other step
besides the first step. This means that for any derivation in GRED of the form:
<S,R,1><φ1,R2,2>….<φn-1,Rn-1,n-1><α>
there is some rule R1* in G' such that R = R1[S/S0] and G' contains a derivation of α
from S0: <S0,R1*,1><φ1,R2,2>….<φn-1,Rn-1,n-1><α>.
This derivation in G' only differs from the derivation in GRED in its first step.
This means that every derivation from S in GRED joins, in its second step, a derivation
in G'. And this means that GRED does not generate any terminal string from S that G'
doesn't generate as well from S0. And this means that indeed L(GRED)=L(G).
This proves the theorem.
Let G be a grammar in reduced form.
Ge = G + S e
Thus, Ge is the result of adding rule S e to Ge.
FACT: L(Ge) = L(G) {e}
Proof: Since S doesn't occur on the right side in any rule in G and the notion of
grammar doesn't allow the leftside of any rule to be e, the only derivation that we can
make in Ge that we (possibly) couldn't make before in G is the derivation:
<S,Se><e>. Thus we derive e in Ge, (and note that e does count as a terminal
string, since it is an empty string of terminal symbols).
I say 'possibly', because the fact also holds if L(G) already contained e.
Note the difference between: L(G)=Ø and L(G)={e}.
If G is a grammar with only rule: S e, then L(G)={e}.
If G is a grammar with only rule S NP VP, then L(G)=Ø.
Example
SSS
Sa
Generated language: {a}+
Reduced form:
S0 S0 S0
S0 a
+
S S0 S0
Sa
+
Se
Generated language: {a}*
11
TYPES OF GRAMMARS
Type 0: Unrestricted rewrite grammars.
Rules of the form: φ ψ, where φ, ψ V*, φ e.
Type 1: Context sensitive grammars.
a. Rules of the form: φ ψ, where φ, ψ V*, φ e and |φ||ψ|
b. If G is a context sentitive grammar in reduced form, Ge is a
context sentitive grammar.
Context sensitive grammars do not allow shortening rules: the output of a rule must
be at least as long as the input. The only exception that we make is that, if the
grammar is in reduced form, we can allow Se as the only shortening rule and still
call the grammar context sensitive.
The name context sensitive comes from a different, equivalent formalization
of the same class of grammars which we will mention below.
Type 2: Context free grammars:
a. Rules of the form: A ψ, where A VN and ψ V+.
b. If G is a context free grammar in reduced form, Ge is a
context free grammar.
In context free grammars, the rules have a non-terminal symbol on the left side, not a
string (so there is no context), and a non-empty string on the right.
As before, we allow Se in a context free grammar G if G S e is contextfree,
and in reduced form. (Note, later in these notes I will liberalize the concept of context
free grammar.)
Type 3: Right linear grammars:
a. Rules of the form: A αB or A α, where A,B VN and α VT+
b. If G is a right linear grammar in reduced form, Ge is a
right linear grammar.
In right linear grammars the rules have a non-terminal symbol on the left side of !,
like in context free grammars, and on the right, a non-empty string of terminal
symbols, or a non-empty string of terminal symbols followed by a non-terminal
symbol (i.e. one non-terminal symbol on the right side of the produced string).
Here too, we allow Se in a right linear grammar if the grammar is inreduced form,
(Note: also this notion will be liberalized later.)
A language L is type n iff there is a type n grammar G such that L = L(G).
So a language is context free if there exists a contextf ree grammar that generates it.
Note that every right linear language is context free, every context free language is
context sensitive, and every context sensitive grammar is type 0. This is because a
right linear grammar is a special kind of context free grammar, a context free
grammar a special kind of context sensitive grammar, a context sensitive grammar a
special kind of type 0 grammar.
12
[Note that there are languages that don't have a grammar (meaning, not even a type 0
grammar). Take alphabet {a,b}. {a,b}* is a countable set. The set of all languages in
alphabet {a,b} is the powerset of {a,b}*, pow({a,b}*, and Cantor has proved that that
set is uncoutable.
We can assume that the possible non-terminal symbols for grammars in alphabet
{a,b} come from a fixed countable set of non-terminals. Since grammars are finite,
we can represent each grammar in alphabet {a,b} as a string in a 'grammar alphabet':
say, a string:
VT={a}--VN={SAB}--R={SSS,S A,SB,Aa,Bb}
(so, literally think of this as a string of symbols, i.e. { is a bracket symbol, is an
arrow symbol …}
If the non-terminal symbols come from a fixed countable set you can prove that there
are only countably many such strings, and hence there are only countably many
grammars in alphabet {a,b}. This means that there are more languages in alphabet
{a,b} than there are grammars for languages in alphabet {a,b}, and this means by
necessity that there are more languages in alphabet {a,b} that don't have a (type
0) grammar at all than languages that do. ]
We call languages that don't have a grammar intractable languages.
EXAMPLE
G = <VN,VT,S,P>
VN = {S, A, B, C}
VT = {a,b,c,d}
P=
1. S ABC
2. A aA
3. A a
4. B Bb
5. B b
6. Bb ! bB
7. BC Bcc
8. ab d
9. d ba
(Context free rule)
(Right linear rule)
(Right linear rule) (Also left linear)
(Left linear rule)
(Right linear rule)
(Context sensitive rule)
(Context sensitive rule)
(Type 0 rule)
(Context sensitive rule)
This is a Type 0 grammar.
13
Derivations:
BCA
BccA
BbccA
BbccaA
Bbccaa
bbccaa
,7
,4
,2
,3
,5
This is a terminated derivation of bbccaa from BCA
S
ABC
aBC
aBcc
abcc
dcc
bacc
,1
,3
,7
,5
,7
,8
This is a terminated derivation of bacc from S, hence bacc is in the generated
language.
S
ABC
aBC
aBcc
abcc
,1
,3
,7
,5
This is a derivation of abcc from S, but not a terminated one. This derivation does not
guarantee that abcc is in the generated language (in fact, it is not).
S
,1
ABC ,3
aBC ,5
abC
This is a terminted derivation of abC from S. Since abC is not a string of terminals,
abC is not in the generated language, even though the derivation is from S and
terminated.
The generated language is: bnam cc (n,m 1)
This expresses that each string consists of a string of b's (minimally one), followed by
a string of a's (minimally one), where the number of b's and a's are unrelated,
followed by two c's.
We know that this language is type 0. But, in fact, the language is also generated by
the following grammar:
14
G = <{S,A,B,C},{a,b,c},P> where
P=
1. S bB
2. B bB
3. B aA
4. A aA
5. A cC
6. C c
Since this grammar is right linear, it follows that bnam cc (n,m 1) is a right linear
language.
DERIVATIONS AND PARSE TREES
I mentioned above that there is an equivalent formulation of context sensitive
grammars:
Context sensitive grammars in normal form:
Rules of the form: αAβ αφβ, where A VN, α,β V*, φ V*{e}.
Rewrite nonterminal symbol A into non-empty string φ, if A is flanked on
the leftside by string α and on the right side by β.
Here α…β is the context, hence the name.
Linguistically oriented books often give the latter definition of context sensitive
grammars, for historic reasons: rules in phonology used to have this format.
However, the format was by and large only used in phonology to summarize finite
paradigms, and it turns out to be a really rotten format to write grammars in for the
languages that we are actually going to show to be context sensitive, while writing
grammars in the no shortening format is easy. Since the formats are proved to be
equivalent, I will not ask you to give grammars in the second format.
Theorem: For every context sensitive grammar G, there is a context sensitive
grammar GN in normal form such that L(G)=L(GN).
Proof: omitted.
I will introduce one more new concept:
A context desambiguated rule is a pair <R,<α,β>>, where R is a context
senstive rule in normal form: αAβ αψβ.
A context desambiguated grammar is a structure G = <VN,VT,S,R>, with
VN,VT,S, as usual, and R a finite set of context desambiguated rules.
The notion of derivation stays exactly the same.
We now specify in all our context sentive rules what the context is. But, apart from
that, the notion of derivation doesn't do anything with that context specification. This
means that, if we leave out from our context desambiguated grammar, all the context
specifications, we get an equivalent context sensitive grammar in normal form.
15
Hence, the format of context desambiguated grammars puts no restriction on
the generated languages: the class of all languages generated by context sensitive
grammars is exactly the class of languages generated by context desambiguated
grammars.
The difference is as follows. We could, in a context sensitive grammar, have a
rule of the form: R: BC BcC. This rule is in fact in normal form, except that it isn't
uniquely in normal form. We can interpret this rule as:
αBβ αBcβ, where α=e and β=C: rewrite B as Bc, when followed by C.
but also as:
αCβ αbCβ, where α=B and β=e: rewrite C as cC, when preceded by B.
The only thing that the context desambiguated format does is specify which of these
interpretations is meant:
In the context desambiguated format we have two different rules:
R1: <BC BcC, <e,C>: rewrite B to Bc before C.
R2: <BC BcC, <B,e>: rewrite C to cB after B.
And the grammar may contain R1, or R2, or both. As said, this makes no difference in
generative capacity, since at each step of the derivation, the effect of applying R1 or
R2 to an input string is exactly the same as applying R to that input string: BC gets
rewritten as BcC.
But the context desambiguated format is useful when we want to assign parsetrees to derivations.
Let G be a context-desambiguated grammar, and let D = <B,R1,1>...<φn> be a
derivation in G of φ from B, with B VN of n steps.
The parse-tree determined by D is the tree TD with topnode labelel B, yield
φn, non-leaf nodes labeled by non-terminal symbols in VN constructed in
the following way:
1. We associate with the first step of D a tree T1 , which is a tree with a single
node labeled B.
2. Let <φ1αAβφ2,<Ri,<α,β>>,i> be step i in D,
let Ti be the tree constructed for step i,
and let <φ1αφβφ2,Ri+1,i+1> be step i+1 in D.
φ1αAβφ2 is the yield of Ti.
In this, αAβ is the occurrence i, so each symbol in φ1αAβφ2 unambiguously
labels a leafnode in Ti (this is the reason for mentioning the occurrence i in
the derivation). Take the leafnode in Ti that the mentioned occurrence of A
labels.
Call this node n.
Tree Ti+1 is the tree which you get from Ti by attaching to node n in Ti as
daughter nodes, nodes labeled by the symbols in φ, in left-right order, one
symbol per node. Clearly, the yield of Ti+1 is φ1αφβφ2.
3. The parse-tree determined by D is tree Tn.
16
Let G be a context-desambiguated grammar.
A parse tree of G is a tree which is the parse tree of some derivation of G.
It is easy to see that the following fact holds:
FACT: In a context desambiguated grammar each derivation determines a unique
parse tree.
This is, because in a context desambiguated grammar, the description of input step i:
<φ1αAβφ2,<Ri,<α,β>>,i> determines a unique node in Ti for A. This is not
necessarily the case for context sensitive grammars that are not in the context
desambiguated format. For example:
For a step like: <φ1BCφ2, BCBcC,i>, the algorithm for constructing the parse tree
wouldn't know whether to attach B and c as daughters to B or c and C as daughters to
C.
Desambiguation specifies precisely that information:
In a step: <φ1BCφ2, <BCBcC,<B,e>>,i>, you are instructed to attach c and C as
daughters to C.
In a step: <φ1BCφ2, <BCBcC,<e,C>>,i?, you are instructed to attach B and c as
daughters to B.
Since contex free grammars are context desambiguated (every rule has context
<e,e>), we get:
CORROLARY: In a context free grammar each derivation determines a unique
parse tree.
Let G be a context desambiguated grammar.
A constituent structure tree generated by G or I-tree generated by G is a
parse tree T for G with topnode S and yield(T) L(G), corresponding to a
terminated derivation in G of a terminal string from S
The tree set of G, T(G), is the set of all I- trees generated by G.
Let G and G' be context-desambiguated grammars.
G and G' are strongly equivalent iff T(G)=T(G').
It is easy to see that if G and G' are strongly equivalent, G and G' are weakly
equivalent. The inverse does not hold, though. Different grammars may generate the
same strings with different structures.
Also, the same grammar may generate a string with different structures:
Let G be a context desambiguated grammar and let φ L(G).
φ is syntactically ambiguous in G iff φ is the yield of two I-trees generated
by G.
G is syntactically ambiguous if some φ L(G) is syntactically ambiguous in
G.
17
There is an advantage to characterizing syntactic ambiguity in terms of I- trees rather
than directly in terms of derivations. I- trees do not reflect the order in which the
derivations build them.
If the grammar generates string aa with structure:
S
A
B
a
a
we want to call aa unambiguous, even though the grammar may well have different
derivations for this structure:
SABaBaa
SABAbaa
This is derivational ambiguity which is non-structural. With the notion of constituent
structure trees we can express the difference.
18
PART 2. REGULAR LANGUAGES, GRAMMARS AND AUTOMATA
RIGHT LINEAR LANGUAGES.
Right Linear Grammar: Rules of the form:
A α B, A α
A,B VN, α VT+
Left Linear Grammar: Rules of the form:
A Bα, A α
A,B VN, α VT+
Rewrite a nonterminal into a non-empty string of terminal symbols or a non-empty
string of terminal symbols followed by a nonterminal (right linear)/ a nonterminal
followed by a non-empty string of terminal symbols (left linear).
Restricted Right Linear Grammar: Rules of the form:
A aB, A a
A,B VN, a VT
Restricted Left Linear: Rules of the form:
A Ba, A a
A,B VN, a VT
Rewrite a nonterminal into a terminal symbol or a terminal symbol followed by a
nonterminal (right linear)/a non terminal followed by a terminal symbol (left linear)
Linear: A α B β, A,B VN, α VT* or A α, A VN, α VT+.
Rewrite a non-terminal into a non-empty string of terminal symbols, or into
a non-terminal flanked by two strings of terminals (possibly empty).
Remark 1: for all these type: we include in the type Ge for grammars G of the type in
reduced form.
Remark 2: Clearly, a restricted right linear grammar is right linear, a right linear
grammar is linear, a linear grammar is context free.
Remark 3: Linear grammars are stronger than right linear grammars. We will prove
shortly that language anbn (n>0) (all string consisting of a's followed by an equal
number of b's, at least 1 a and at least 1 b) cannot be generated by a right linear
grammar.
But S ab, S aSb is a linear grammar and generates anbn (n>0).
The terminology is explained by the generated parse trees:
Right linear:
A
α
A
α
α
Restricted right linear
A
a
A
A
a
A
A
a
A
α
A
a
A
α
a
A single spine of non-terminals on the right side.
19
Left linear:
Restricted left linear
A
A
a
A
a
A
a
A
a
a
A
α
A
A
α
A
α
A
α
α
A single spine of non-terminals on the left side.
Linear:
α
α
α
α
α
A
A
A
A
A
β
β
β
β
β
A single spine of non-terminals.
Theorem: For every right linear grammar there is an equivalent restricted right linear
grammar.
Proof:
Let G be a right linear grammar. The rules are of the form:
A α, A αB, where α = a1...an.
Take any such rule R. Add to the grammar new non-terminal symbols X1...Xn-1 and
replace R by the rules:
Xn-1an
Aa1X1, X1a2X2,....
depending on R
Xn-1an B
Example:
AabcB, Bb
gives parse tree:
A
a b
c B
AaX1, X1bX2, X2cB, Bb
gives parse tree:
A
a
X1
b
X2
c
B
b
20
The resulting grammar generates the same languages and is a restricted right linear
grammar.
Example:
(ab)+ccd(ab)+
S ab S
S ccd A
A ab
A ab A
S
ab
S
ab
S
ccd
A
ab
A
a
b
S a A1
A1 b S
S c A2
A2 c A3
A3 d A
A a A4
A4 b
A4 b A
21
S
a
A1
b
S
a
A1
b
S
c
A2
c
A3
d
A
a
A4
b
A
a
A4
b
We obviously have the same result for left linear grammars and restricted left linear
grammars.
Theorem: For every right linear grammar there is an equivalent left linear grammar
(and vice versa).
Proof: This will follow from other facts later.
This means that the right linear languages are exactly the restricted right linear
languages and are exactly the left linear languages.
REGULAR LANGUAGES.
Kleene closure, *, is an operation which maps every language A onto *A.
Union, , is an operation which maps every two languages A and B onto A B.
We introduce a third operation product:
Product, , is a operation which maps every two languages A and B onto A B,
defined as:
The product of A and B: A B = {αβ: α A and β B}
Example: If A = {a,b} and B = {cc, d}
A B = {acc, ad, bcc, bd}
Fact: A+ = A A*
22
Proof:
Case 1. Let e A.
Then A+ = A* , so the claim is: A* = A A*
-Let α A and β A*, then obviously, by definition of A*, αβ A*, hence
A A* A*.
-A A* = {αβ: α A and β A*}
A* = {eβ: β A*}, and since e A, A* A A*.
So indeed A A* = A*.
Case 2. e A.
-We have already proved that A A* A*.
-Since e A, e A A*, because every string in A A* starts with as string from
A.
The two prove that A A* A+.
-Let α A+.
Then either α A, and since α = αe and e A*, α A A*.
Or α = α1...αn, where α1,...,αn A. But then α1 A and α2...αn A*.
Hence, α A A*. So, A+ A A*.
Consequently, A+ = A A*.
Example:
A = {a,b}
A* = {e, a, b, ab, ba, aa, bb, aaa, ….}
A £ A* =
{ a^e, aa, ab, aab, aba, aaa, abb, aaaa,….
b^e, ba, bb, bab,…} =
{a, b, ab, ba, aa, bb, aaa, ….} = A+
Take two languages A and B. First take their union, (A B). Then take the Kleene
closure of that: *(A B).
The composition operation * o is the operation which takes any two languages A
and B and maps them onto *(A B).
Let O be the operation which maps any five languages A,B,C,D,E onto the language
(*(A)*(B))*(C*(DE))). This operation can be decomposed as a finite
sequence of compositions of the operations *,,:
First apply * to A , then apply * to B, then apply to the result. Call this 1.
Then apply union to D and E and apply * to the result. Call this 2.
Apply to C and 2, and apply * to the result. Call this 3.
Now apply to 1 and 3 and you get the output of O.
Defining the notion of 'finite sequence of compositions' is technically complex and
nitty-gritty. I won't do that here, but assume instead that the intuition is clear.
The class of regular operations on languages is given by:
1. *,, are regular operations on languages.
2. Any operation which can be decomposed as a finite sequence of
compositions of the operations *,, is a regular operation.
23
We define:
Language A is a regular language iff
A is a finite language or there is regular operation O and finite languages
A1,…,An and A = O(A1,…,An).
This means that any regular language can be gotten by starting with a finite number of
finite languages and applying a finite sequence of the operations *,,.
For example, anbm(n,m0) is: {a}*{b}*
anbm(n,m1) is: {a}+{b}+
Since we have shown that {a}+ = {a}{a}*, we see that:
anbm(n,m1) is: ({a}{a}*)({b}{b}*)
Equivalently, we can define the class of regular languages inductively as:
R, the class of all regular languages is the smallest class such that:
1. Every finite language is regular.
2. If A and B are regular languages, then A B is regular.
3. If A and B are regular languages, then A B is regular.
4. If A is a regular language, then A* is regular.
(We say 'class' and not 'set' because in this definition we don't put any constraints on
the alphabets that the languages are languages in.)
Theorem: Every regular languages is a right linear language.,
Proof:
Step 1: Every finite language is a right linear language.
Let A = {α1,…,αn}
Sα1,….,Sαn is a right linear grammar.
Note that this also holds if e A, because this grammar is trivially in reduced form.
Step 2: If A and B are right linear languages, then A B is a right linear language.
Suppose GA is a right linear grammar generating A and GB is a right linear grammar
generating B.
-Change everywhere every non-terminal X in GA by a new non-terminal XA.
-Change everywhere every non-terminal X in GB by a new non-terminal XB.
(i.e. we make all non-terminals in GA and GB disjoint).
-Take the union of the resulting grammars.
-For every rule of the form:
SAα AA, SAα, SBβ BB, SBβ
add a rule of the form:
Sα AA, Sα, Sβ BB, Sβ
Call the resulting grammar GAB.
(Note that GAB is in reduced form.)
GAB is a right linear grammar and GAB generates AB.
24
Step 3: If A and B are right linear languages, then A B is a right linear language.
Suppose GA is a right linear grammar generating A and GB is a right linear grammar
generating B.
-Change everywhere every non-terminal X in GB by a new non-terminal XB (not
occurring in GA, i.e. we make all non-terminals in GA and GB disjoint).
1. If e A and e B, then
replace every GA rule of the form:
Aα
by a rule of the form:
Aα SB
Call the resulting grammar GAB
2. If e A and e B, GB contains rule SBe.
Delete that rule and add for every GA rule of the form:
Aα
a rule of the form:
Aα SB
Call the resulting grammar GAB
3. If e A and e B, then
delete S ! e and
replace every remaining GA rule of the form:
Aα
by a rule of the form:
Aα SB
and add for every rule of the form:
SB α BB or SB α
a rule of the form:
S α BB or S α
Call the resulting grammar GAB
4. If e A and e B, then GB contains rule SBe.
Delete that rule and add for every remaining GA rule of the form:
Aα
a rule of the form:
Aα SB
and add for every rule of the form:
SB α BB or SB α
a rule of the form:
S α BB or S α
Call the resulting grammar GAB
In all four cases GAB is a right linear grammar and GAB generates AB.
25
Step 4. If A is a right linear language, then A* is a right linear language.
Suppose GA is a right linear grammar generating A.
-If GA contains rule Se, delete that rule.
-For every remaining rule of the form:
Aα
add a rule:
Aα S
This will generate A*{e}.
-Convert the resulting grammar into reduced form and add Se to the result.
Call the result GA*.
GA* is a right linear grammar and generates A*.
This completes the proof.
So we know now that the class of regular languages is a subclass of the class of right
linear languages. We will soon see that the two classes actually coincide.
26
FINITE STATE AUTOMATA
We now take a parsing perspective. Whereas grammars generate strings, automata
read strings symbol by symbol, from left to right, follow instructions, and
determinine, when the string is read, whether the string is accepted or rejected.
At any point of its operation, we assume that the automaton is in a certain state. We
can think of this state as an array of switches which can be on or off. Each
combination of switch-settings that the automation allows is a possible state that the
automaton can be in. The instructions that the automaton follows, then, can be
interpreted as instructions to reset switches, and hence as instructions to move from
one state to another.
A state automaton is an automaton that can do this and not more: it can read the
input from left to right, symbol by symbol, and at each point follow an instruction to
switch state. The state that it is in after reading the input will determine whether or
not the string is accepted. Importantly:
A state automaton does not have any memory.
A finite state automaton is a state automaton that has a finite number of possible
states it can be in.
A finite state automaton is deterministic iff in any state it is in, there is at most one
state it can switch to, according to its instructions.
A finite state automaton is non-deterministic iff possibly in some state there is more
than one state it can switch to, according to its instructions.
A deterministic state automaton is total iff in any state it is in, there is exactly one
state it can switch to.
In the formal definition we only specify the things that vary from automata to
automata:
A finite state automaton is a tuple M = <S,Σ,δ,S0,F> where:
1. S is a finite set, the set of states.
2. Σ is a finite alphabet, the input alphabet.
3. δ, the transition relation, is a three-place relation relating a symbol in Σ
to two states (an input state and an output state): δ S Σ S.
4. S0 S. S0 is the initial state.
5. F S. F is the set of final states.
Let M be a finite state automaton:
M is deterministic iff δ is a partial function from S Σ into S, i.e. iff δ maps
every pair consisting of an input state and an input symbol onto at most one
output state.
Let M be a deterministic finite state automaton.
M is total iff δ is a total function from S Σ into S, i.e. iff δ maps
every pair consisting of an input state and an input symbol onto exactly one
output state.
27
Since we read 'non-deterministic' as 'possibly non-deterministic', we take 'finite state
automaton' and 'non-deterministic finite state automaton' to be the same notion.
I mentioned that we only specify the variable parts of the automaton. The invariable
parts are the following:
1. Every automaton has an input tape, on which a string in the input alphabet is
written.
2. Every automaton has a reading head which reads one symbol at a time.
3. Every computation starts while the automaton is in the initial state S0, reading
the first symbol of the input string.
4. We assume that after having read the last symbol of the input string, the automaton
reads e.
5. At each computation step the automaton follows a transition.
We write transition δ(Si,a)=Sk as:
(Si,a)Sk
And with this transition, the automaton can perform the following computation step:
Computation step:
If the automaton is in state Si and reads symbol a on the input tape, it
switches to state Sk and reads the next symbol on the input tape.
6. We say:
The automaton halts iff there is no transition rule to continue.
Let α Σ*.
A computation path for α in M is a sequence of computation steps beginning
in S0 reading the first symbol of α, following instructions in δ until M halts.
Fact: If M is a deterministic finite state machine, then every input string α Σ* has a
unique computation path.
This means that for each input string, the automaton will halt.
Now, since e Σ (since Σ is an alphabet), there is by definition of δ no instruction if
M reads e. This means that if the automaton reads e, it halts. We use this in defining
acceptance:
7DET. Deterministic finite state automaton M accepts string α Σ* iff
at the end of the computation path of α in M, M reads e and M is in a final
state. Otherwise M rejects α.
This means that M rejects α if, at the end of the computation path for α in M, M reads
e, but is not in a final state, or if M halts at a symbol before reading the whole input
string, that is, if at the end of the computation path of α in M, M doesn't read e.
28
If M is a non-deterministic automaton, there may be more than one instruction that
M can follow while reading an input symbol in a state. This means that M can
choose, and this means that for each string α of the input alphabet there may be more
than one computation path for α in M. (where a computation path for α in M is,
once again, a sequence of computation steps licensed by transitions in M, starting in
S0 reading the first symbol of α, and halting in some state.) For non-deterministic
automata we define acceptance:
7NDET Non-deterministic finite state automaton M accepts string α Σ* iff
for some computation path for α in M, at the end of that computation path,
M reads e and M is in a final state. Otherwise M rejects α.
This means, that there may be computation paths for α in M at the end of which M is
not reading e, or M is not in a final state, and yet M accepts α: as long as there is at
least one computation path, where M ends up reading e in a final state, M accepts α.
8.
Let M be a finite state automaton.
L(M), the language accepted by M, is the set of all accepted input strings.
(So L(M) Σ*). We call L(M) a finite state language.
M1 and M2 are equivalent iff L(M1) = L(M2).
Now we introduce pictures of finite state automata, called state diagrams:
A state diagram of a finite state automaton represents the states as circles with the
state names as labels, it represents the transitions in δ as arrows between the
appropriate state circles, where each arrow is labeled by the appropriate input symbol,
according to δ, and it represents final states as double circles.
Example.
M is given by:
S = {S0,S1}
Σ = {a}
δ(S0,a)=S1
δ(S1,a)=S0
F = {S0}
a
S0
S1
a
Accepted: e, aa, aaaa, aaaaaa,...
Rejected: a, aaa, aaa, aaaaa,...
Accepted language: an (n is even.)
Note that e is accepted by this automaton.
The automaton starts out in S0 reading e, and halts there. Since S0 is a final state, e is
accepted.
Fact: finite state automaton M accepts e iff S0 is a final state.
29
M is given by:
S = {S0,S1,S2}
Σ = {a}
δ(S0,a)=S1
δ(S1,a)=S0
F = {S1}
a
S0
S1
a
Accepted: a, aa, aaa, aaaaa, ...
Rejected: e, aa, aaaa, aaaaaa,...
Accepted language: an (n is odd)
M is given by:
S = {S0,S1}
Σ = {a,b}
δ: (S0,a)=S1
(S1,a)=S1
(S1,b)=S2
(S2,b)=S2
F = {S1}
a
b
a
S0
b
S1
S2
Accepted language: anbm (n>0, m>0)
Two state diagrams are equivalent iff they are state diagrams for equivalent
automata.
A state diagram is reduced iff there is no equivalent state diagram with fewer
states.
Reduction Theorem: Any two reduced equivalent state diagrams are
isomorphic (i.e. differ at most in the names of the
states).
Proof: Omitted.
This means that for each finite state language, there is, up to isomorphism, a
unique smallest automaton recognizing that language.
30
Theorem: For every deterministic finite state automaton, there is an equivalent
total deterministic finite state automaton.
Proof:
Let M be a deterministic finite state automaton. Add a new state G (for garbage) to
M, which is not a final state.
For each state Si and each symbol a such that δ(Si,a) is undefined, add: δ(Si,a)=G
(also for G itself). The resulting automaton is deterministic and total, and clearly
recognizes the same language as M.
Example.
We make the last automaton total:
a
b
a
b
S0
S1
S2
b
a
G
a
b
Since it is so easy to turn a deterministic automaton into a total deterministic
automaton, when I ask you to make a deterministic automaton, I don't require you to
make it total. But make sure that it is deterministic, because often it is much easier to
make a non-deterministic automaton than a deterministic one (and I sometimes don't
want you to do the easier thing).
Example:
In alphabet {a,b} I want an automaton that recognizes
an bm abk bap (n,m>0,k,p ≥0)
-any string of one or more a's
-any string of one or more b's
-any string consisting of one b, followed by as many a's as you want.
-any string consisting of one a, followed by as many b's as you want.
This is straightforward to do non-deterministically.
a
b
a
S1
S0
a
b
b
S2
31
On the path from S0 to S1 and looping on S1, you accept any string of one or more a's,
and any string starting with b, followed by any number of a's.
On the path from S) to S2 and looping on S2, you accept one or more b's and any string
starting with a, followed by any number of b's. Since what the automaton accepts is
the union of what it accepts along each of these paths, it accepts the language
specified.
Deterministically, you need to think a bit more, though it is not very difficult:
a
S3
a
S1
a
b
b
S4
S0
b
b
b
S2
S5
a
a
S6
The theorem that I will not prove here says that the class of non-deterministic finite
state languages and the class of deterministic finite state languages coincide:
Theorem: For every non-deterministic finite state automaton, there is an equivalent
deterministic finite state automaton.
Proof: Omitted.
It is useful to introduce for automata a familiar notion and a familiar theorem:
Finite state automaton M is in reduced form iff S0 does not occur in the range
of δ, i.e. if M has no arrows going into S0.
Theorem: Every finite state automaton is equivalent to a finite state
automaton in reduced form.
Proof: The same as for grammars: replace each occurrence of S0 in M by S0',
add a new initial state S0, and add for each transition (S0',a)Sk a
transition (S,a)Sk. Make S0 a final state iff e L(M). The resulting
automaton is in reduced form and generates the same languages as M.
The theorem we will prove is:
32
Theorem: The right linear languages are exactly the finite state languages.
Proof:
Step 1: If a language is right linear, there is a finite state automaton accepting it.
Let G = <VN,VT,S,P> be a restricted right linear grammar.
We construct a finite state automaton M:
1. Σ = VT.
2. S = VN {Q}, with Q a symbol not in VN.
3. For every rule Aa B, we have a transition (A,a)B in δ.
4. For every rule Aa, we have a transition (A,a)Q in δ.
5. S is the initial state.
6. -If Se is not in G, then Q is the final state.
-If Se is in G, then Q and S are the final states.
Claim: G and M are equivalent.
A. If G generates α, M accepts α.
-If α=e and G generates α, then S is a final state and M accepts e.
-Suppose G generates α, and α = a1...an.
Then there is a derivation in G of the form:
Sa1A1....a1...an-1An-1a1....an
This means that G contains rules:
Sa1A1, ...,An-2an-1An-1, An-1a
This means that in the automaton we have:
S
a1 A1
......an-1 An-1 an
Q
Clearly, then M accepts α.
B. If M accepts α, G generates α.
-If α=e and M accepts e, then Se is in G, by definition of M, so G generates e.
-If M accepts α and α = a1...an, M contains a path of the above form.
Note that even though, S may in principle be a final state, if α e, M will not accept α
in S, because S is only a final state if Se is in G, and that can only be the case if G
is in reduced form. But that means that M is also in reduced form, and this means
indeed that the path accepting α is of the above form.
But from the construction of M, we know that then all of the rules:
Sa1A1, ...,An-2an-1An-1, An-1a are in G (because that's how we got those
transitions in the first place). Hence G generates α.
Step 2: If a language is a finite state language, there is a right linear grammar
generating it.
Let M be a finite state automaton in reduced form.
We define grammar GM:
1. VT = Σ.
2. VN = S
3. For every instruction in δ: (Ai,a)Ak we add a rule: AiaAk.
4. For every instruction in δ: (Ai,a)F, where F is a final state, we add a rule: Aia.
5. S=S0.
6. If S0 is a final state, we add Se.
33
Since M was in reduced form, GM is in reduced form. Clearly, by an argument which
is the inverse of the above argument, GM will generate what M accepts. And GM is
right linear. Since the class of finite state languages is the class of languages accepted
by finite state automata in reduced form, we have proved our theorem.
Theorem: The Left linear languages are exactly the finite state languages.
Proof:
We define for string a1...an, for language A, and for restricted right linear grammar G:
The reversal of a1...an, (a1a2...an)R = an...a2a1
The reversal of A,
AR = {αR: α A}
The reversal of G,
GR is the result of replacing in G every rule of the
form AaB by ABa.
Fact: L(GR) = (L(G))R
Proof: This is obvious: Right linear derivation D gets replaced by left linear
derivation D':
D S
a
A
a
B
b
aab
D'
S
A
B
a
a
b
baa
THEOREM: If A is a finite state language, AR is a finite state language.
Proof:
Let M be a finite state automaton that accepts A.
Case 1. Assume M has one final state F.
-turn every transition (Si,a) Sk into (Sk,a)Si.
-make S0 the final state.
-make F the initial state.
The resulting finite state automaton accepts AR.
Case 2. Assume M has final states F1,...,Fn.
-turn every transition (Si,a) Sk into (Sk,a)Si.
-make S0 the final state.
-add a new initial state S', and add for every transition:
(Fi,a)Sk a transition (S',a)Sk.
The resulting automaton is in reduced form. If e A, make S' a final state as well.
The resulting automaton recognizes AR.
This completes the proof.
Corrollary: The left linear languages are exactly the right linear languages.
Proof:
-Let A be a right linear language. Then A is a finite state language. Then AR is a
finite state language, by the above theorem, and hence AR is a right linear language.
Take a right linear grammar G for AR. GR is a left linear grammar that generates
ARR, by the earlier theorem. But ARR = A. Hence A is a left linear language.
34
-Let A be a left linear language. Then AR is a right linear language, hence AR is a
finite state language, hence ARR is a finite state language, so A is a finite state
language, and hence A is a right linear language.
The next proof is a difficult proof. It is one of the two difficult proofs I do in this
class. I do it, because it illuminates the structure of regular languages so well.
Remember that we proved earlier that every regular language is a right linear
language, and hence (we now know) a finite state language. We will now prove the
converse of this:
THEOREM: Every finite state language is a regular language.
Proof:
Let M be a finite state automaton with n states.
Assign numbers 1,...,n to the states in M: state m is the state we assign number m.
We are going to define for each number k ≤ n and each two states i and j, with
i,j ≤ n, a set of string Rki,j.
The intuition is that we look at all the paths through the automaton that bring you
from state i to state j, and we are interested in the strings that are accepted along
those paths. This does not mean that these strings are accepted by the automaton M,
but only that if you start in state i, these strings will bring you from there to state j.
The number k puts a restriction on which paths to include and which to exclude.
k says: ignore any path that goes through any state m where m > k.
This means, then, that Rni,j is the set of all strings that bring you from state i to state j,
because there are no states m with m > n, so all paths count.
Similarly, R0i,j is the set of strings that bring you from state i to state j, while ignoring
any path that goes through a state 1,....,n. We will interpret that as meaning that R0i,j
is the set of strings that directly bring you from state i to state j.
Following this intuition, we will define the latter sets as follows:
Definition: for every i,j ≤ n:
if i j then:
R0i,j = {α: δ(i,α) = j}
if i = j then:
R0i,j = {α: δ(i,α) = j} {e}
(i.e. this is R0i,i)
We are now going to look at Rki,j where k >0.
Rki,j is the set of strings which bring you from i to j, without going through any state
with number higher than k.
Intuitively, we can split this set of strings into two sets:
-the set of strings that bring you from i to j, without going though any state with
number higher than k1: that is, Rk1i,j
-the set of strings that bring you from i to j, while going through state k.
35
Let us call the latter set for the moment K.
That means that:
Rki,j = Rk1i,j K
Now we focus our attention on set K, the set of strings that bring us from i to j while
going through state k.
Such strings may go through state k more than once, in that case they loop in state k.
But intuitively we can divide any such string into three parts:
-a string that brings you from state i to state k on a path that doesn't itself go
through state k. (i.e. the string you get the first time you reach state k).
-a string that brings you from state k to state k 0 or more times.
-a string that brings you from state k to state j on a path that doesn't itself go
through state k (i.e. the string you get by going from the last time you are in state k
to state j).
Thus, any string in K is a concatenation of a string in Rk1i,k followed (possibly) by a
string that loops from k to k, followed by a string in Rk1k,j
Writing for the moment L for the set of all middle parts, the strings that loop in k, we
see that:
K = Rk1i,k L Rk1k,j
Now, the loop strings are strings that bring you from state k to state k.
Each such string can be described as a concatenation of strings that bring you from
state k to state k without going through state k itself.
This is obvious: if you loop m times in state k and get string α, divide α into the
substrings you get each time you reach state k again: these substrings themselves do
not go through state k.
This means that loop set L is the closure under string formation of the set Rk1k,k
the string closure of the set of strings that bring you from k back to k, without going
through k (or a state with a higher number):
L = (Rk1k,k)*
Filling in L in K, we get:
K = Rk1i,k (Rk1k,k)* Rk1k,j
Filling in K in Rki,j, we get:
Rki,j = Rk1i,j (Rk1i,k (Rk1k,k)* Rk1k,j)
This we use as a definition:
36
Definition: for every k, such that 0 < k ≤ n,
for every i,j ≤ n:
Rki,j = Rk-1i,j (Rk-1i,k (Rk-1k,k)* Rk-1k,j)
This means that, with our two definitions, we have defined Rki,j for every number
k ≤ n, and for every states i,j ≤ n.
Now we state a theorem:
Theorem: for every number k ≤ n and for every two states i,j ≤n: Rki,j is regular.
Proof:
We prove this with induction to the number k. We will prove the following two
things:
Proposition 1: For every two states i,j≤ n: R0i,j is regular.
Proposition 2: For any number k with 0 < k ≤ n:
If it is the case that for every two states a,b: Rk1a,b is regular,
Then it is the case that for every two states i,j: Rki,j is regular
The proofs of these two propositions together form an induction proof of the
theorem, for the following reason:
Proposition 2 says that if the theorem holds for k1, it holds for k (with k >0).
Since proposition 1 says that the theorem holds for k=0, it then follows with
proposition 2, that the theorem holds for k=1.
It holds for k=1, so once again, proposition 2 says it holds for k=2, etc.
This means that, if we can prove propositions 1 and 2, we have indeed proved the
theorem.
Proof of proposition 1:
By definition of R0i,j, R0i,j is a finite set for every i and j, hence for every i and j, R0i,j
is regular (because finite sets are regular).
Proof of proposition 2:
We assume that it is the case for every two states a,b that Rk1a,b is regular.
Let i and j be any states. We prove that Rki,j is regular.
By definition:
Rki,j = Rk1i,j (Rk1i,k (Rk1k,k)* Rk1k,j)
By assumption:
Rk1i,j is regular, Rk1i,k is regular, Rk1k,k is regular, and Rk1k,j is regular.
But then Rk1i,j (Rk1i,k (Rk1k,k)* Rk1k,j) is regular, since it is built from those
sets with regular operations , , and *.
Hence Rki,j is regular.
37
With the proof of propositions 1 and 2 we have proved the theorem.
Now we will use this theorem to prove the main theorem.
Let a be the number of the initial state and b be the number of a final state.
Rna,b is the set of all strings accepted by M in final state b.
It follows from the theorem just proved that Rna,b is regular.
Let a be the number of the initial state and b1,...,bm be the numbers corresponding to
all the final states in M.
Then the language accepted by M is:
L(M) = Rna,b1 ... Rna,bm
Since we have just seen that all the sets in this union are regular, L(M) is a union of
regular sets, and hence L(M) is itself regular.
This proves the main theorem: every language accepted by a finite state automaton is
regular.
We have now proved that all the language classes discussed here, right linear
languages, left linear languages, finite state languages form one an the same class of
languages, the class of regular languages.
THE PUMPING LEMMA FOR REGULAR LANGUAGES.
Let A be a regular language. A is accepted by a finite state automaton M, with, say, n
states.
Let α A, α = a1...am, m ≥ n.
Assume that there is a path through M for a1...am from S0 to final state F.
Let's call the occurrences of states on that path S0...Sm.
Since m≥n, it is not possible that all the states S0...Sm are distinct, because S0...Sm
form at least n+1 occurrences of states, and there are only n states.
This means that for some j,k≤n: Sj = Sk (let's assume j < k). In other words,
S0...Sm contains a loop.
Suppose substring aj+1...ak is a part of a1...am accepted by going through this loop
once. We know then that: 1 ≤ |aj+1...ak| ≤ n.
Now, instead of going through the loop from Sj to Sk in S0...Sm, and then on to Sk+1,
we could have skipped the loop and gone on directly from Sj to Sk+1, and the
resulting string, α with aj+1...ak replaced by e, would also have been accepted.
Hence, α with aj+1...ak replaced by e, is also in language A.
Similarly, we could have gone through the loop twice, and then go on as before,
and the resulting string, α with aj+1...ak replaced by aj+1...akaj+1...ak, would also have
been accepted, hence, α with aj+1...ak replaced by aj+1...akaj+1...ak is also in language
A.
Thus, if a1....ajaj+1...akak+1...am A, then
a1....aj(aj+1...ak)zak+1...am A, for every z≥0.
38
Hence, for every sufficiently long strong string a1...am A, we can find a substring
that can be 'pumped' through the loop, and the result is also in A. This is the pumping
lemma.
Pumping lemma for regular languages:
Let A be a regular language. There is a number n called the pumping
constant for A(not greater than the number of states in the smallest automaton
accepting A) such that:
For every string φ A with |φ|≥n:
φ can be written as the concatenation of three substrings: αβγ such that:
1. |αβ| ≤ n
2. |β|>0
3. for every i≥0: αβiγ A.
Application: ambm is not a regular language.
Proof:
Assume ambm is a regular language. Let n be the pumping constant for this language.
Choose a number k such that 2k>n,and consider the string akbk ambm of length 2k:
a.....................ab.....................b
k
k
According to the pumping lemma, we can write this string as αβγ, where βe,
|αβ|≤n and αβiγ ambm.
Try to divide this string.
-If β consists only of a's, then pumping β will make the number of a's and b's not the
same, hence the result is not in ambm.
-If β consists only of b's, the same.
-If β constists of a's and b's, it is of the form aubz.
So our string is:
a..................(aubz)......................b
But then pumping β once gives:
a..................(aubz) (aubz)......................b
and this string has the a's and b's mixed, in the middle, hence it is not in ambm.
Since these are the only three possibilities, we cannot divide this string in a way that
satisfies the pumping lemma. This means that ambm does not satisfy the pumping
lemma for regular languages, and hence ambm is not a regular language.
We will see shortly that it follows from this that English is not a regular language.
39
CLOSURE PROPERTIES OF REGULAR LANGUAGES.
We already know that if A,B are regular, then so are A*, AB, and AB.
Theorem: Let L be a language in alphabet A (L A*).
If L is regular, then A*L is regular.
A*L is the complement of L in A*. This means that the class of regular languages is
closed under complementation.
Proof: Let L be regular, and let M be a deterministic and total automaton accepting
L Make every final state in M non-final and every non-final state final.
The resulting automaton accepts A*L
Corrollary: If A and B are regular languages then A B is a regular language.
Proof:
Let A and B be regular languages in alphabet Σ (which can be taken to be just the
union of the symbols occurring in A and the symbols occurring in B).
A B = Σ*((Σ*A) (Σ*B)). That is, the operation of intersection can be defined
as a sequence of compositions of the operations of complementation and union, Since
we have proved the latter operations to be regular, and since sequences of
compositions of regular operations are regular, intersection is regular.
Making an intersection automaton is a lot of work , though.
-Start with a deterministic automaton of A and a deterministic automaton for B.
-Take for both of them the complement automaton (i.e. switch final and non-final
states).
-For the resulting two automata, M1 and M2 form the union automaton. This goes in
the same way as we did for right linear grammars:
make the states of the two automata disjoint, add a new initial state, add for every
arrow leaving M1's old initial state to some state Si a similar arrow from the new
initial state to Si, and the same for any such arrow leaving M2's old initial state.
Make the new initial state a final state if one of the old initial states was final.
-Next convert this automaton to a deterministic automaton (since the union procedure
tends to give you a non-deterministic automaton). And finally take the complement
automaton of the result. This will be an automaton for the intersection.
I will give a simple construction of an intersection automaton later in this course.
These resuls mean that the set of regular languages in a certain alphabet form a
Boolean algebra.
Let A and B be alphabets.
A homomorphism from A* into B* is a function that maps strings in A* onto strings
in B* in which the value for a complex string in A* is completely determined by the
values for the symbols of A. Formally:
40
A homomorphism from A into B is a function h:A*B* such that:
1. h(e)=e
2. for every string in A* of the form αa, with αA* and a A:
h(αa) = h(α)h(a).
So: if h(b)=bb and h(a)=aa, then:
h(bba)= h(bb)h(a) = h(bb)aa = h(b)h(b)aa = h(b)bbaa = bbbbaa.
Let L be a language in alphabet A, and let h:A*B* be a homomorphism,
then: the homomorphic image of L under h, h(L) is given by:
h(L) = {h(α): α L}
Theorem: If L is a regular language in alphabet A and h:A*B* is a
homomorphism, then h(L) is a regular language in alphabet B.
Proof: omitted.
Example:
Let A = {a,b}. Let B = {a,b,c}
Let h:A*B* be a homomorphism such that:
h(e)=e
h(a)=aa
h(b)=cc
We know that: anbm (n,m>0) is a regular language.
h(anbm (n,m>0)) = (aa)n(cc)m (n,m>0).
It follows that: (aa)n(cc)m (n,m>0) is also a regular language.
Example:
Let A = {a,b,c}.
Let h:A*A* be a homomorphism such that:
h(e)=e
h(a)=a
h(b)=b
h(c)=e
We have proved that anbn(n≥0) is not a regular language.
We look at: ancbn(n≥0).
h(ancbn(n≥0)) = anbn(n≥0).
Consequently we know: if ancbn(n≥0) were regular, anbn(n≥0) would be regular. But
anbn(n≥0) is not regular. Hence:
ancbn(n≥0) is not regular.
41
Let h:A*B* be a homomorphism.
For each string β B*, we define:
h1(β) = {α A*: h(α)=β}
We call h1 the inverse homomorphism of h.
(Note: h1 is not a function from B* into A*, but from B* into pow(A*).)
For L B* we define:
h1(L) = {α A*: h(α) L}
Theorem: If L is a regular language in alphabet B and h:A*B* is a
homomorphism, then h1(L) is a regular language in alphabet A.
Proof: omitted.
Let A and B be alphabets.
A substitution from A into B is a function that maps every string of A* onto a set of
strings in B which is determined by the values of the symbols in the following way:
The strings in the set associated with a complex string α are gotten by substituting all
values for the symbols in α at the place where they occur. Formally:
A substitution from A into B is a function s:A*pow(B*) such that:
1. s(e)={e}
2. For any string of the form αa, with α A* and a A:
s(αa) = s(α)s(a)
If L is a language in alphabet A and s a substitution from A into B, then,
the substitution language of L relative to s, s(L), is given by:
s(L) = αLs(α).
Theorem: If L is a regular language in alphabet A and s is a substitution from A into
B, then s(L) is a regular language in alphabet B.
Proof: Omitted.
Example:
abncdm (n,m>0) is a regular language in A={a,b,c,d}
(a, followed by as many b's as you want, followed by c, followed by as many d's as
you want).
We take alphabet B = {John, Bill, Mary, and, walk, talk, sing}
and we take s, a substitution from A into B given by:
s(a) = {John, Bill, Mary}
s(b) = {and John, and Bill, and Mary}
s(c) = {walk, talk, sing}
s(d) = {and walk, and talk, and sing}
42
s(abbcddd) =
{John, Bill, Mary} {and John, and Bill, and Mary} {and John, and Bill, and
Mary} {walk, talk, sing} {and walk, and talk, and sing} {and walk, and talk,
and sing} {and walk, and talk, and sing}.
So, one of the strings in the substitution language of abbcddd is:
John and Bill and Mary walk and talk and sing.
Another one is:
Mary and Mary and Mary talk and talk and talk.
s(abncdm (n,m>0)) =
{John, Bill, Mary} {and John, and Bill, and Mary}+ {walk, talk, sing} {and
walk, and talk, and sing}+.
which contains any string, starting with either John or with Bill or with Mary,
followed by one or more occurrences of strings in {and John, and Bill, and Mary},
followed by one of the items walk or talk or sing, ending with one or more of the
items in {and walk, and talk, and sing}.
With the theorem, we don't have to prove separately that this language is a regular
language, that follows from the theorem.
We see that, with the notions of homomorphism, inverse homomorphism,
substitutions, we can extend our theorems from languages that look like toy languages
(with little a's and b's) to languages that look suspiciously like natural languages.
We use the fact that the intersection of regular languages is regular and the fact that
regular languages are closed under homomorphisms to prove that the natural language
English is not a regular language:
Theorem: English is not a regular language.
Proof:
Let the set of grammatical strings of English be E.
I specify a sequence of strings α1,α2,....
α1 = the fact that Fred was clever was surprising
α2 = the fact that the fact that Fred was clever was surprising was surprising
α3= the fact that the fact that the fact that Fred was clever was surprising was
surprising was surprising
....
and we set: L = {α1,α2,α3,...}
43
We are dealing with the following structure:
IP
DP
D
the
I'
NP
N
fact
CP
C
I
PRED
is
surprising
IP
that
And L is:
L = the fact thatn Fred is clever was surprisingn, (n>0)
Choose the following homomorphism:
h(the fact that)=a, h(Fred is clever)=c, h(was surprising)=b..
Then the homomorphic image of L is ancbn which we showed to be not regular.
Consequently: L is not a regular language.
Now we look at a bit wider language, L':
L' = the fact thatn Fred is clever was surprisingm, (n,m>0)
We chose a homomorphism such that:
h(a) =the fact that, h(c)=Fred is clever, h(b)=was surprising.
L' is the homomorphic image of ancam(n,m>0), which we showed earlier to be regular.
Hence: L' is regular.
Now we observe the empirical fact about English:
Empirical Fact: E L' = L
The only strings of L' that are grammatical in English are the strings sentences in L.
So we have three facts:
1. L is not regular.
2. L' is regular.
3. L = L' E.
Suppose English were a regular language. Then both E and L' would be regular.
The intersection of two regular languages is regular, hence L would be regular.
But L is not regular. Since L' is regular, it follows that E is not regular.
This completes the proof.
44
HOMEWORK ONE
EXERCISE 1
For each of the following languages, give a restricted right linear grammar that
generates it.
a. L1 = {α {a,b,c}*: α contains the substring abc}
b. L2 = {α {a,b,c}*: α contains exactly two occurrences of c,
not necessarily next to each other}
c. I use the notation: |a|α = n for:
'a occurs exactly n times in α'
L3 = {α {a,b,c}*: |a|α = 1} {α {a,b,c}*: |b|α = 1}
{α {a,b,c}*: |c|α = 1}
d. L4 = {α {a,b,}*: α contains an even number of a's and an even
number of b's.
EXERCISE 2
Construct, for each of the languages L1, L2, L3, L4, a non-deterministc finite
automaton accepting that language.
Notes:
-When I say restricted right linear I mean restricted (so no strings in your rules), and I
mean right linear (so no X ! e if X is not S, and S ! e only if the grammar is in
reduced form).
The same for the automata: every arrow has a single symbol (though you're allowed
to summarize multiple arcs by one arc with the symbols separated by comma's), and
there are no arcs labeled by e.
-When I say non-deterministic, I mean that you do not have to go through the effort to
make your automata deterministic, and you do not have to go through the effort of
making them total.
-Note that L4 is in a different alphabet from the other languages.
-Make sure that your grammars/automata do not undergenerate, and do not
overgenerate.
If you're not experienced with this, it is useful to write down all the strings in the
alphabet up to some length (say, 4), and check whether your grammar/automaton
makes the right predictions for them.
45