Toronto CO2 Project – Population Synthesis Documentation – Draft
advertisement

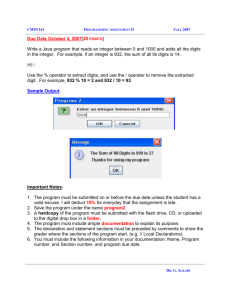
Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft City of Toronto CO2 Project Population Synthesis Documentation – Draft Nov 11, 01 Matthew Roorda 1. Introduction The population synthesis procedures presented in this document are developed as part of the Toronto CO2 Emissions Project. It is the first stage of the activity/travel model analysis, which provides the necessary inputs into the household activity scheduler model. The procedures documented in this report perform the following functions: Raw 1996 Transportation Tomorrow Survey (TTS) data are “cleaned” such that missing information for each person/household surveyed is generated based on some simple rules and information from other people in a similar geographical area. New weights (expansion factors) are applied to each household and person record in the TTS database to reflect population growth totals provided by the City of Toronto. Future employment, school and daycare locations are generated for each person record. Future employment locations are based on the 1996 distribution of placeof-residence place-of-work linkages and the shifts and overall growth in population and employment that are expected in the GTA, as provided by the City of Toronto. Future school locations are based on the 1996 distribution of placeof-residence place-of-school linkages and growth in population. September 27, 2001 Page 1 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft 2. Data Cleaning The TTS data are not complete because not all survey respondents were able to or willing to give complete and sufficient answers to all survey questions. Therefore, for each data variable many household or person records are coded with an “unknown” data entry. For these records a preprocessing routine is developed to impute the unknown variable based on the distributions of the variable for people in the same GTA traffic zone. In addition, some simple rules were used. The procedure for imputing values for each unknown variable is shown as follows: Location Attributes 1996 employment and school zones in the original TTS database have two problems. First, the external zone numbering system does not match that of the GTA EMME/2 model, on which the final model assignments are to be run. To resolve this problem, an equivalency, developed as part of an earlier project, was applied to the TTS zone system. Second, there are a number of employment and school zones coded as 9999 (unknown) or coded as 4000 (unknown external). For unknown employment zones the following steps are taken: The “most popular” GTA employment zone for each residence zone is determined (i.e. the place of work zone in which the greatest number of people from the residence zone work). In many cases this is the same as the residence zone. The “most popular” employment zone is entered for each unknown employment zone. For unknown external codes, the closest external zone with a reasonably large population base is applied Employment zones coded 8888 (no usual place of work) are not modified, as this code is considered to be an important insight into the traveling behaviour of that person that should be considered by the scheduler model. For unknown school zones the following steps are taken: The “most popular” GTA school zone for each residence zone is determined (i.e. the place of school zone in which the greatest number of people from the residence zone attend). In many cases this is the same as the residence zone. The “most popular” school zone is entered for each unknown school zone. For unknown external codes, the closest external zone with a reasonably large university/college is applied School zones coded 8888 (no usual place of school) are treated in the same way as those coded as unknown. Both the revisions to the zone numbering system and generation of missing location attributes were done using a Microsoft ACCESS database. September 27, 2001 Page 2 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft Household Attributes The only household attribute that has an unknown value is dwelling type. No preprocessing is required for this attribute since it is not used in the scheduling program Person Attributes Person attributes that require cleaning include age, sex, drivers license, employment status, occupation, and student status. For each of these attributes, the number of records and expanded trips coded as unknown is shown in Table 1. Table 1: Number of missing fields for person attributes Insert table 1 here For each attribute, an algorithm is developed to impute a value based on simple rules and observed distributions. A C++ program, entitled data_clean.cpp was developed in order to impute the unknown attributes. Program inputs are almost the same as those of the population synthesis program, as described in Section 3. Two additional fields are required for each record in the TTS Person data input file (fin_pers.txt), namely, “made_work_trip” and “made_auto_trip”. The “cleaned” person output file from the data cleaning program is in the correct format for input into the population synthesis routine. The output filename is cln_pers.txt. The algorithm is outlined for each missing person attribute as follows. Age Step 1: Assess whether the person is an adult If person has drivers license, then age >= 16 If person is a worker then age >=16 If only person in household then >=16 Step 2: Randomly choose age based on household zone age distribution If person is an adult, then select from the zonal age distribution of people >= 16 Otherwise select age from the zonal age distribution of all people in the zone Sex Choose sex randomly (50% male, 50% female) Drivers License If person has age < 16 or >=80 then assume the person has no drivers license If person has age >=16 and <80: o If person made an auto trip, then the person has a drivers license o If no auto trip, then determine driver license attribute randomly based on overall GTA distribution conditional upon broad age category and sex. September 27, 2001 Page 3 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft Employment Status Step 1: Decide whether employed or not If occupation = O, then not employed If occupation = 9 (unknown), then o If made a work trip then employed o Else If age <16 or >=70, or school_stat = full time, then not employed o Else choose employment status randomly from zonal distribution If person has an occupation type, then employed Step 2: Choose employment status for employed people Choose employment status randomly based on place of residence zonal distribution (full-time, part-time, work-at-home full time, work-at-home parttime) Occupation Choose occupation randomly from usual place of work zonal occupation distribution Student Status If age < 5, then not a student If age between 5 and 18, then full time student If age > 18 or age unknown then not a student September 27, 2001 Page 4 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft 3. Population Synthesis Program Input File Formats The population synthesis program requires the following types of input data: 1) TTS Person Data, 2) TTS Household Data, 3) Future year total population and employment by 1996 TTS traffic zone, The required input data and file formats are as follows: 1) TTS Person Data (after undergoing the data cleaning process described in Section 2) Filename: cln_pers.txt Format: comma delimited Field - data type: - Household number – 6 digit integer - Person number – single digit integer - Age – integer 0-99 - Sex – single digit character - Drivers License – single digit character - Transit Pass – single digit character - Employment Status - single digit character - Occupation - single digit character - No work - single digit character - Student Status - single digit character - Planning District of Employment – integer 1-113 - Employment Zone – integer 0-8888 - Free Park - single digit character - Planning District of School – integer 1-113 - School Zone – integer 0-8888 - Number of Person Trips – integer, 0-99 - Number of Transit Trips – integer, 0-99 Exact data definitions can be found in the Transportation Tomorrow Survey 1996 Version 2.1 Data Guide (see Appendix A) 2) TTS Household Data Filename: fin_hhld.txt Format: comma delimited Field – data type: - Household number – 6 digit integer - Household Planning District – integer 1-113 - Census Tract Name – floating point 7.2 - Household zone – integer 1-2670 - 1996 expansion factor – floating point 2.2 - Dwelling Type – single digit character - Number of persons – integer 1-9 - Number of vehicles – integer 0-99 September 27, 2001 Page 5 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft 3) Future year total population and employment by 1996 TTS traffic zone Filename: fin_zone.txt Format: comma delimited Field – data type: - 1996 TTS Zone number – integer 1-8888 i. 1-2670: Internal GTA zones ii. 4000 – 4409: External zones iii. 8888: No usual place of work - Planning District – integer 1-48 i. 1-46: TTS planning district ii. 47: External Zones iii. 48: No usual place of work - Future year total population – integer or floating point i. Note: future population should be 0 for zones 4000 – 4409, and 8888, since we are not attempting to synthesize any households whose residence is outside of the GTA. - Future year total employment – integer or floating point i. Note: future employment should be estimated using a growth factor for zones 4000 – 4409 and 8888. Currently a growth factor of 50% is assumed based on the average GTA growth rate [**********Check 50%********] 4) Distribution of 1996 TTS daycare trips Filename: fin_dayc.txt Format: comma delimited Field – data type: - residence planning district - integer 1-46 - daycare destination zone – integer 1-4409 - number of expanded trips from residence planning district to daycare destination zone – float 7.2 September 27, 2001 Page 6 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft - 4. Population Synthesis Program Output File Formats The population synthesis program generates the following output files: 1) Updated Person Data 2) Updated Household Data 3) Updated Zone Data 4) Planning District Totals 5) GTA Totals The output is in the following format: 1) Updated Person Data Filename: fout_per.txt Format: comma delimited Field – data type: - 1st 17 fields – same as TTS Person input file (see Section 3) - Future employment zone – integer, 0-8888 - Future school zone – integer, 0-4409 - Day care status – single digit character (‘D’ = Out-of-home child care) - Day care zone – integer 0-4409 2) Updated Household Data Filename: fout_hhl.txt Format: comma delimited Field – data type: - 1st 8 fields – same as TTS Household Data input file (see Section 3) - Future expansion factor – floating point 2.2 3) Updated Zone Data Filename: fout_zon.txt Format: comma delimited Field – data type: - Zone number – integer 1 – 8888 - Planning District ID – integer, 0 - 47 - Number of Person Records – integer, 1 – 6 digits - 1996 Population total - integer, 1 - 6 digits - 1996 Workers gen office/clerical - integer, 1 - 6 digits manufacturing / const - integer, 1 - 6 digits professional/mgmt - integer, 1 - 6 digits retail/sales/service - integer, 1 - 6 digits unknown occupation - integer, 1 - 6 digits - 1996 Employment Total - integer, 1 - 6 digits gen office/clerical - integer, 1 - 6 digits manufacturing / const - integer, 1 - 6 digits professional/mgmt - integer, 1 - 6 digits September 27, 2001 Page 7 Toronto CO2 Emissions Project Department of Civil Engineering - - - Population Synthesis Documentation - Draft retail/sales/service - integer, 1 - 6 digits unknown occupation - integer, 1 - 6 digits Future Population Total - integer, 1 - 6 digits gen office/clerical - integer, 1 - 6 digits manufacturing / const - integer, 1 - 6 digits professional/mgmt - integer, 1 - 6 digits retail/sales/service - integer, 1 - 6 digits unknown occupation - integer, 1 - 6 digits Future Raw Employment Total (figures provided by City of Toronto) - integer, 1 - 6 digits Future Adjusted Employment Total (adjusted target total consistent with worker totals) - integer, 1 - 6 digits gen office/clerical - integer, 1 - 6 digits manufacturing / const - integer, 1 - 6 digits professional/mgmt - integer, 1 - 6 digits retail/sales/service - integer, 1 - 6 digits unknown occupation - integer, 1 - 6 digits Future Simulated Employment Total (simulated, which are slightly different than “adjusted” employment, since pow is chosen randomly with replacement) - integer, 1 - 6 digits gen office/clerical - integer, 1 - 6 digits manufacturing / const - integer, 1 - 6 digits professional/mgmt - integer, 1 - 6 digits retail/sales/service - integer, 1 - 6 digits unknown occupation - integer, 1 - 6 digits 5) Planning District Totals Filename: fout_pd.txt Format: comma delimited Field – data type: - Planning District ID – integer, 0-47 - Planning District Number – integer, 1-48 - Fields 3 – 33 – Same as Updated Zone Data output file fields 4 – 34 6) GTA totals Filename: fout_gta.txt Format: see example Field – data type: explained in output file Example of GTA total output file GTA Statistics No. of household records (original) :88898 No. of household records (with seeds):120882 No. of person records (original) :243286 September 27, 2001 Page 8 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft No. of person records (with seeds) :337925 1996 1996 1996 1996 1996 1996 1996 gta gta gta gta gta gta gta pop workers gen office clerical work manufacturing const work professional/mgmt tech work retail sales service work unknown work :4.92637e+006 :2.42169e+006 :332115 :528520 :984696 :566452 :9908.66 1996 1996 1996 1996 1996 1996 gta gta gta gta gta gta emp gen office clerical emp manufacturing const emp professional/mgmt tech emp retail sales service emp unknown emp :2.42169e+006 :332115 :528520 :984696 :566452 :9908.66 Future Future Future Future Future Future Future gta gta gta gta gta gta gta pop :7.22148e+006 work :3.57777e+006 gen office clerical work :485669 manufacturing const work :776371 professional/mgmt tech wrk:1.47306e+006 retail sales service wrk:828216 unknown work :14459 Future gta raw employment (no adj) Employment growth adjustment factor Future Future Future Future Future Future gta gta gta gta gta gta :4.18166e+006 :0.656875 employment adjusted :3.57777e+006 gen office clerical emp :485669 manufacturing const emp :776371 professional/mgmt tech emp:1.47306e+006 retail sales service emp:828216 unknown emp :14459 September 27, 2001 Page 9 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft 5. Structure of the Program The population synthesis program consists of ten classes, each of which is briefly described in this section. The full set of details can be found by reviewing the program code shown in Appendix B. CGta - Contains all GTA 1996 and future population, employment and worker totals Contains simulation parameters, such as the “next household Id and “next person Id” This class is the main “control center” of the program; all major functions are invoked in this class There is one instantiation of this class (gta0) which is a global variable CPlanningDistrict - Contains planning district 1996 and future population, employment and worker totals - Contains three lists of POS objects, for post-secondary, high-school and daycare locations, which define the POS and the number of people that live in the residence planning district and attend school in the POS zone (for daycare it includes the # of daycare trips to the POS zone - Contains an array of household Ids whose residence is in the planning district - Has a function to return a random household from the household ID array - Other than that, it is basically a container of pd totals - 48 planning districts are instantiated globally and stored in an array on the heap space. There is a pointer to this array (pointer name: pd) CZone - - - Contains all zonal 1996 and future population, employment and worker totals Contains a set of lists of POW objects, one for each occupation type, which define the POW and the number of people in the zone that work in the pow zone Contains a range of functions to add or return population/employment/worker totals within the zone, to seed itself appropriately with randomly selected households from the planning district, and to return a randomly selected POW 1703 zones are instantiated globally and stored as an array in the heap space. There is a pointer to this array (pointer name: zone) CHouseholdRecord - Contains household attributes from the TTS input file - Contains a list of person Ids in the household - Contains 1996 and future expansion factors for the household - Can copy itself to another household (for the seeding procedure) and can calculate its future expansion factor by accessing zonal totals - 88898 household records are instantiated globally and stored in an array in the heap space. Space for an additional 35,000 household records is reserved in September 27, 2001 Page 10 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft the array to allow for seeding of zones. There is a pointer to the array (household_record) - The array index does not correspond to the TTS household number. See class CHouseholdIndex for details CPersonRecord - Contains person attributes from the TTS person input file - Contains 1996 and future employment and school zones - Contains randomly generated day care status and day care location, where appropriate - Can copy itself to another person (for the seeding procedure) - 243286 person records are instantiated globally and stored in an array in the heap space. Space for an additional 100,000 person records is also reserved in the array to allow for seeding of zones. There is a pointer to this array (person_record) CHouseholdIndex - This is an index that returns a sequentially ordered Household Id, given the TTS household number - It allows for households to be stored in an array with the household ID as the array index, thereby leaving no gaps in the household_record array and preserving memory CZoneIndex - This is an index that returns a sequentially ordered Zone Id, given the GTA zone number - It allows for zones to be stored in an array with no gaps as for the households CPow - - - A pow is a simple place-of-work object that contains two data variables, the place of work zone and the number of people from place of residence zone X that work there (for a particular occupation type). Pow objects are stored in a list in the place of residence zone (i.e. the CZone class). A list is an efficient storage container for this purpose, because zones that are not a place of work for a particular place of residence need not be included in the list for that por zone. Pow objects are used in evaluating a randomly chosen place of work for each person CPos - - A pos is a simple place-of-school object that contains 2 data variables, the place-of-school zone and the number of people from planning district X that attend school there (for a particular school level, i.e. high school versus post secondary school) Pos objects are stored in a list in the place of residence planning district (i.e. the CPlanningDistrict) class. A list is an efficient storage container for this September 27, 2001 Page 11 Toronto CO2 Emissions Project Department of Civil Engineering - Population Synthesis Documentation - Draft purpose because zones that are not a pos for a particular por planning district need not be included in the list for that por planning district. Pos objects are used in evaluating a randomly chosen future place of school for high school students and post secondary students CPorpow - Contains a full 1996 porpow matrix, 2 vectors that contain factors for frataring the O-zone and the D-zone, - Contains a planning district to zone porpow matrix, and a zone to planning district matrix, to aid in seeding rows or columns where significant growth in either workers or employment are expected to increase significantly for a particular occupation type - Contains occupation Id (i.e. each Porpow matrix is for a single occupation) - Will fratar itself, seeding appropriately - Will load the zonal pow lists based on the fratared matrix CPorpos - - Contains 2 place-of-residence place-of-school (porpos) matrices, one for high school students (16-18 years old) and one for post-secondary students (>18 years old) Por is defined by planning district and pos is defined by traffic zone. Loads the planning district pos lists based on the data in the porpos matrices CFileMgr - Performs some simple file management functions, such as opening output files September 27, 2001 Page 12 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft 6. Outline of the Methodology The program follows the following general steps: 1) Data for households, persons and zones are loaded into memory and indexes set up 2) 1996 population and employment are summed with a breakdown by occupation 3) Future expansion factors are calculated based on existing and future total population by zone a. Population growth factors for each zone are calculated based on existing and future total population b. Zones with population growth factor >2.0 are seeded with randomly chosen households from the planning district, such that the future expansion factor is no greater than 20. c. Future expansion factors are calculated based on the seeded population databank. 4) Future total zonal employment growth is adjusted such that total GTA employment is consistent with total GTA workers. 5) The future total zonal employment by occupation is broken down into occupation groups by frataring the 1996 employment occupation distribution to reflect future total zonal employment and future total gtaGTA workers by occupation type 6) The 1996 place-of-residence place-of-work (POR POW) matrix for each occupation type is generated from the TTS data 7) The future POR POW table is generated as follows: a. Using the 1996 POR POW table as a seed matrix, b. For those POR “rows” where the number of workers increases tenfold, the planning district totals are used to seed that particular row. c. For those POW “columns” where the employment increases tenfold, the planning district totals are used to seed that particular column. d. The fratar method is applied to each of the seeded occupational POR POW tables such that row and column sums reflect future worker and employment totals by occupation type. 8) The future place of work for each worker is generated as follows: a. The distribution of workers of Occupation Type X and Place of Residence Y that are expected to work in each Zone Z is calculated based on the future occupational POR POW tables. b. A future place of work is drawn (with replacement) from this probability distribution and assigned to each worker based on his or her occupation and place of residence. 9) The future place of school for each student is generated as follows: a. The 1996 place-of-residence place-of-school (porpos) matrices are generated for high school age (14-18 years old) and post-secondary school age (>18 years old) students based on 1996 TTS data b. The distribution of students in age group X and place of residence Y that attend school in each zone Z is calculated based on the 1996 porpos matrices September 27, 2001 Page 13 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft c. For elementary students and high school students, the future pos zone is assumed to equal the 1996 pos zone, unless the student record is generated as part of the seeding process (in Methodology step 3b) d. For “seeded” elementary students (<14 years old), the future pos zone is assumed to equal the por zone, on the assumption that most elementary schools are located very close to the residence. e. For “seeded” high school students (14 to 18 years old), a future pos school zone is randomly drawn from the 1996 planning district distribution of high school pos zones. f. For post-secondary age students (>18 years old), a future pos zone is randomly drawn from the 1996 planning district distribution of postsecondary age pos zones. 10) Day care status and location of children is generated as follows: a. an input file is loaded that contains the TTS expanded day-care trips by residence planning district and day-care trips destination zone b. based on Statistics Canada data from the (******Insert study name*****), day care status is assigned randomly to all children < 11 years old whose household contains only adults that are working (part-time or full time) or attending school c. the place-of-day-care distribution for each planning district is applied to all day-care children in that planning district to result in day-care location 11) The program outputs data to the output data files and clears all objects in memory. September 27, 2001 Page 14 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft 7. Detailed Methodology The program follows the following general steps: 1) Data for households, persons and zones are loaded into memory and indexes set up Input files are described in detail in Section 4. They are loaded into the heap space memory. It is noted that the following simulation parameters are set to match the data in the input files as described below: NUMPERS – 243286 – the number of person records in the person input file NUMHHLD – 88898 – the number of households in the household input file NUMZONE – 1703 – the number of zones (includes 1677 GTA zones, 25 external zones and zone 8888, which represents “no usual place of work”) NUMPD – 48 – the number of planning districts (pd 47 includes all external zones, and pd 48 is for zone 8888, “no usual place of work”) HIHHLD – 268184 – the highest household number in the household input file HIZONE – 8888 – the highest zone number in the zone input file MAXPDHHLD – 8653 – the maximum number of household records expected for a given planning district (for setting hhld list array size) NUMPERSSEED – 100000 – the expected number of persons required for seeding (this number may require adjustment if new population and employment forecasts are obtained) NUMHHLDSEED – 35000 – the expected number of households required for seeding (this number may require adjustment if new population and employment forecasts are obtained) Additional data is added to each household record, person record, zone and planning district as the data is loaded in. The household ID (to be distinguished from the household number) is a sequential ID number that corresponds to the array index for the household records (whereas the TTS household number has gaps). Similarly, a person ID is created for each person record and a zone ID (to be distinguished from the 1996 zone number) is created to each zone. The household ID and the zone ID are entered into household index and zone index arrays, respectively, so that the household and zone Ids can be easily looked up if the household or zone numbers are known. Also part of the initialization procedure, a list of households is created for each planning district and a list of persons is created in each household object. This basically concludes the process of loading and setting up the initial data in the program. 2) 1996 population and employment are summed with a breakdown by occupation 1996 population and employment are summed by scrolling through the person list, determining the person’s household (to obtain the expansion factor), adding the expansion factor to the 96 population total for the zone of residence and adding the September 27, 2001 Page 15 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft expansion factor to the 96 employment total for the zone of employment. The 1996 numbers were checked against TTS totals using the DRS (the data retrieval system from the Data Management Group), and were found to be consistent for population. For employment, the DRS indicates that about 3.5% of people employed within the GTA reside outside of the GTA, and are therefore about 3.5% of GTA employment is not incorporated in the GTA population-based list generated for the scheduling program. Workers and employment by occupation were also determined and entered into an array of worker and employment totals as follows: work1996[i] = 1996 workers of occupation type i. emp1996[i]= 1996 employment of occupation type i, where for i, 0 = general office / clerical 1 = manufacturing / construction / trades 2 = professional management / technical 3 = retail sales and service 4 = unknown GTA total population and employment by occupation type are then calculated as the sum of zonal population and employment. 3) Future expansion factors are calculated based on existing and future total population by zone - Population growth factors for each zone are calculated based on existing and future total population This calculation is done if the 1996 population > 0 and 1996 population > 0.5* the future population. If there is no 1996 population and no future population, the population growth factor is set to zero. If the population growth is > 2.0 then the factor is set to 999999 temporarily, since it must be recalculated after the zone is seeded, as discussed below. - Zones with population growth factor >2.0 are seeded with randomly chosen households from the planning district, such that the future expansion factor is no greater than 20. Households are chosen randomly from the household list (an array member variable of the pd class). These households are then copied into new households in the zone that is being seeded. The persons within this household are copied to a new set of identical persons in the zone being seeded and are given the household number of the seeded household. - Future expansion factors are calculated based on the seeded population databank. September 27, 2001 Page 16 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft Future expansion factors are calculated by multiplying the 1996 expansion factor by the zonal population growth factor. If the zone was seeded, the population growth factor is set to 999999, in such cases the total number of person records (including seed records) in that zone are calculated, and the future population is divided by that number. 4) Future total zonal employment growth is adjusted such that total GTA employment is consistent with total GTA workers. Future population and employment and workers by occupation type are calculated for each zone and for the entire GTA. It is noted that the total employment for the GTA that is calculated in this way (i.e. by summing the expansions factors based on the population growth factor) is significantly lower than the total GTA population provided by the City of Toronto. There are at least three reasons for this. First, the estimate by summing the expansion factors does not include population that commutes from outside of the GTA. Second, only one job is included for each worker, whereas in reality, some workers have two or more jobs. Third, employment forecasts often tend to be over-optimistic compared to population forecasts. Since the purpose of the population synthesis exercise is to generate the “usual” place of work for each person in the GTA, the total GTA employment estimate that is most appropriate is the summation of GTA workers. Growth in all future zonal employment estimates is therefore reduced such that the estimates of total GTA employment are consistent. 5) The future total zonal employment by occupation is broken down into occupation groups by frataring the 1996 employment occupation distribution to reflect future total zonal employment and future total GTA workers by occupation type To maintain the maximum possible consistency within the database, it is necessary to break down the zonal employment into occupation types bearing in mind the 1996 distribution of occupation types. The fratar method of biproportional updating is a straightforward method to achieve this end. A full description of the fratar method can be found in the EMME/2 manual. It is necessary to seed the matrix because in some zones no employment exists in 1996, but employment is expected to occur there by the future analysis year. In such zones, there is no initial distribution to modify, so the zone must be seeded. Even if a small employment base (say 100 jobs) exists in 1996 but employment is expected to increase significantly (say, to 2000) by the future year, the 1996 distribution probably would not be sufficiently precise to adequately represent the new employment base. Therefore, zones are seeded with the planning district distribution if there is no 1996 employment or there is greater than a tenfold increase in employment to the future year. 6) The 1996 place-of-residence place-of-work (POR POW) matrix for each occupation type is generated from the TTS data September 27, 2001 Page 17 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft Because the POR POW matrices are large (1703 x 1703 =2.9 million cells), only one matrix (for one occupation type) is loaded into memory at a time and all probability calculations are completed for that occupation type before the next occupation type is considered. The POR POW matrix for a particular occupation type is generated by iterating through all workers and adding the expansion factor to the correct (por, pow) cell for all workers of that occupation type. The por planning district to pow zone and por zone to pow planning district matrices are also calculated at this stage for use in seeding of the POR POW matrices in the fratar process. It is noted that POR POW matrices do not consist of integers because expansion factors are not integers. 7) The future POR POW table is generated as follows: - Using the 1996 POR POW table as a seed matrix, - For those POR “rows” where the number of workers increases tenfold, the planning district totals are used to seed that particular row. - For those POW “columns” where the employment increases tenfold, the planning district totals are used to seed that particular column. - The fratar method is applied to each of the seeded occupational POR POW tables such that row and column sums reflect future worker and employment totals by occupation type. The major problem encountered in this procedure is that the POR POW matrices are relatively sparse, since there are so many cells in the matrix, and the workers are split among several occupation types. The matrices would not converge properly for all matrices, probably due to the problem of sparseness. If the rule of applying the planning district distribution where there is a tenfold increase in either workers or employment solves the problem for all but a small handful of zones if it is only applied at the outset of the frataring process. For the small number of zones that still do not converge, the planning district distribution is applied at the point in the frataring process where a frataring parameter of > 10 is necessary (analogous to a tenfold increase in workers or employment). By this process, the POR POW matrix converges for all occupation types. 8) The future place of work for each worker is generated as follows: a. The distribution of workers of Occupation Type X and Place of Residence Y that are expected to work in each Zone Z is calculated based on the future occupational POR POW tables. Only the pow zones that have a non-zero number of workers are stored in each place of residence zone, in order to save memory. They are stored in a “list” container, which is an efficient means of storing such data (see MSDN library in Visual C++ for details on the list container). September 27, 2001 Page 18 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft b. A future place of work is drawn (with replacement) from this probability distribution and assigned to each worker based on his/her occupation and place of residence. In order to attain consistency between the (adjusted) employment totals provided by the City of Toronto, it would be necessary to sample without replacement, or in other words, to reduce the probability associated with each pow each time it is actually chosen by the random process. There are two problems implementing the “sampling without replacement” process. First, the POR POW matrices are not integer matrices and each time a pow is chosen the person’s expansion factor must be subtracted from this cell. However, this may result in negative numbers in the revised probability distribution, since the non-integer expansion factors may be larger than the remaining value in each POR POW cell. Second, as part of the seeding process the planning district totals were applied for a number of por and pow zones. After the fratar process these rows and columns have a wider distribution of zones, and therefore relatively a small number of workers in each por/pow cell. This amplifies the first problem associated with sampling without replacement as described above. It is reasonable to use sampling with replacement and to accept the fairly small inconsistencies given that the employment forecasts are quite approximate in the first place. 9) The future place of school for each student is generated as follows: a. The 1996 place-of-residence place-of-school (porpos) matrices are generated for high school age (14-18 years old) and post-secondary school age (>18 years old) students based on 1996 TTS data The 1996 porpos matrices are generated with planning district as the por and TTS traffic zone as the pos. Planning districts are used as the por because for high school and postsecondary school, travel is fairly regional in nature since such school institutions are generally widely spaced. For zones that require seeding (in Methodology step 3b), it is also unlikely that a sufficient number of school records would exist to provide a valid distribution. b. The distribution of students in age group X and place of residence Y that attend school in each zone Z is calculated based on the 1996 porpos matrices Only the pos zones that have a non-zero number of students are stored in each place of residence planning district, in order to save memory. They are stored in a “list” container, which is an efficient means of storing such data (see MSDN library in Visual C++ for details on the list container). September 27, 2001 Page 19 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft c. For elementary students and high school students, the future pos zone is assumed to equal the 1996 pos zone, unless the student record is generated as part of the seeding process (in Methodology step 3b) This assumption implies that the school travel patterns are stable over time for mature zones. d. For “seeded” elementary students (<14 years old), the future pos zone is assumed to equal the por zone This assumption implies that most elementary schools are located very close to the residence, and that for areas high in population growth, new elementary schools will also be built to support the communities. e. For “seeded” high school students (14 to 18 years old), a future pos school zone is randomly drawn from the 1996 planning district distribution of high school pos zones. This assumption implies that high school travel is more regional in nature. Since the existing distribution of high school destinations is used for areas high in population growth it is, in effect, assumed that new high schools are not being built for these areas. This simplifying assumption is made since we do not know future high school locations. f. For post-secondary age students (>18 years old), a future pos zone is randomly drawn from the 1996 planning district distribution of postsecondary age pos zones. This assumption implies that no new post-secondary institutions will be constructed in new locations in the GTA. The increase in post-secondary students is assumed to be accommodated in existing (although perhaps expanded) institutions. 10) Day care status and location of children is generated as follows: a. an input file is loaded that contains the TTS expanded day-care trips by residence planning district and day-care trips destination zone b. based on Statistics Canada data from the (******Insert study name*****), day care status is assigned randomly to all children < 11 years old whose household contains only adults that are working (parttime or full time) or attending school Day care status is applied using this methodology to both the 1996 and future year data. 1996 TTS are considered to be sufficient to obtain a distribution, but are thought to be significantly underreported, based on a comparison to Statistics Canada survey data c. the place-of-day-care distribution for each planning district is applied to all day-care children in that planning district to result in day-care location September 27, 2001 Page 20 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft 11) The program outputs data to the output data files and clears all objects in memory. Output file formats are given in Section 4. September 27, 2001 Page 21 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft APPENDIX A TTS DATA GUIDE 2.0 – DATA DEFINITIONS September 27, 2001 Page 22 Toronto CO2 Emissions Project Department of Civil Engineering Population Synthesis Documentation - Draft APPENDIX B POPULATION SYNTHESIS CODE September 27, 2001 Page 23