Computer Graphics: Output Primitives & Line Algorithms
advertisement
.
UNIT: - 1
COMPUTER GRAPHICS
UNIT-I: Output Primitives: Points and Lines – Line-Drawing algorithms – Loading
frame Buffer – Line function – Circle-Generating algorithms – Ellipse-generating
algorithms. Attributes of Output Primitives: Line Attributes – Curve attributes – Color
and Grayscale Levels – Area-fill attributes – Character Attributes
OUTPUT PRIMITIVES
Graphics programming package provide functions to describe a scene in terms of basis
geometric structure, is referred as output primitives.
POINTS OF LINES:
Points of plotting are accomplished by converting a single co-ordinate position further by
an application program in to appropriate operations for output devices.
Eg: CRT monitor displays color pictures by using a combination of phosphorus that
emits different colored light.
CRT monitor eg: electron beam is turned on to illuminate the screen phosphor at the
selected location.
Random scan (vector) system stores a point plotting instruction in display list, and coordinate values in these instructions are converted to deflection voltage.
For black and white raster system, a point is plot by setting the bit values. Specified
screen position in frame buffer to 1. When electron beam cross each horizontal scan line,
it emits a burst of electrons whenever value is 1.
Line drawing is accomplished by calculating intermediate position along the line path
between two specified end point positions.
Eg:(10, 4.8) (20, 51) (10, 21) (Floating, Integer)
LINE DRAWING ALGORITHM
Line Equation
The Cartesian slop-intercept equation for a straight line is
y=mx+b
-----with
m->slope
b->y intercept
(1)
The 2 end points of a line segment are specified at a position(x1,y1)
Determine the values for the slope m and y intercept b with the following calculation.
here, slope m:
m = ( y2 - y1) / ( x2 - x1 )
m= Dy / Dx
------ ( 2 )
y intercept b
b=y1-mx1
-----
(3)
Algorithms for displaying straight line based on this equation
y interval Dy from the equation
m= Dy / Dx
Dy= m. Dx
------ ( 4 )
Similarly x interval Dx from the equation
m = Dy / Dx
Dx = Dy /m
------- ( 5 )
A straightforward line drawing algorithm
The above points can be used to implement a rather straightforward line drawing
algorithm.
The slope and the intercept of a line are calculated from its endpoints. If jmj · 1, then the
value of the x coordinate is incremented from min(xa; xb) to max(xa; xb), and the value
of
the y coordinate is calculated using the Cartesian line equation. Similarly, for jmj > 1, the
value of the y coordinate is varied from min(ya; yb) to max(ya; yb) and the x coordinate
is calculated (using x = y¡cm ).
The following algorithm assumes that 0 · m · 1 and xa < xb. The other cases can
be considered by suitable re°ections with the coordinate axes and looping through the y
coordinates instead of the x coordinates.
m := (yb - ya) / (xb - xa);
c := ya - m * xa;
for x := xa to xb do
begin
y := round (m*x + c);
PlotPixel (x, y)
end;
However, this algorithm is extremely ignescent due to the excessive use of floating point
Arithmetic and the rounding function round.
Line DDA Algorithm:
The digital differential analyzer(DDA) is a scan conversion line algorithm based
on calculation either
Dy or Dx.
The line at unit intervals is one coordinate and determine corresponding integer
values nearest line for the other coordinate.
Consider first a line with positive slope.
Step : 1
If the slope is less than or equal to 1, the unit x intervals Dx=1 and compute each
successive y values.
Dx=1
m = Dy / Dx
m = ( y2-y1 ) / 1
m = ( yk+1 – yk ) /1
yk+1 = yk + m
-------- ( 6 )
Subscript k takes integer values starting from 1,for the first point and increment
by 1 until the final end point is reached.
m->any real numbers between 0 and 1
Calculate y values must be rounded to the nearest integer
Step : 2
If the slope is greater than 1, the roles of x any y at the unit y intervals Dy=1 and
compute each successive y values.
Dy=1
m= Dy / Dx
m= 1/ ( x2-x1 )
m = 1 / ( xk+1 – xk )
xk+1 = xk + ( 1 / m )
--- ( 7 )
----
Equation 6 and Equation 7 that the lines are to be processed from left end point to
the right end point.
Step : 3
If the processing is reversed, the starting point at the right
Dx=-1
m= Dy / Dx
m = (y2 – y1) / -1
yk+1 = yk - m
-- (8)
------
Iintervals Dy=1 and compute each successive y values.
Step : 4
Here, Dy=-1
m= Dy / Dx
m = -1 / ( x2 – x1 )
m = -1 / ( xk+1 – xk )
xk+1 = xk + ( 1 / m )
- (9)
-------
Equation 6 and Equation 9 used to calculate pixel position along a line with –ve slope.
Advantage:
Faster method for calculating pixel position then the equation of a pixel position.
Y=mx+b
Disadvantage:
The accumulation of round of error is successive addition of the floating point
increments is used to find the pixel position but it take lot of time to compute the pixel
position.
Algorithm: A naïve line-drawing algorithm
dx = x2 - x1
dy = y2 - y1
for x from x1 to x2 {
y = y1 + (dy) * (x - x1)/(dx)
pixel(x, y)
}
C Programming
void linedda(int xa,int ya,int xb,int yb)
int dx=xb-xa,dy=yb-ya,steps,k;
float xincrement,yincrement,x=xa,y=ya;
if(abs(dx)>abs(dy))
steps=abs(dx);
else
steps=abs(dy);
xincrement=dx/(float)steps;
yincrement=dy/(float)steps;
putpixel(round(x),round(y),2)
for(k=0;k<steps;k++) {
x+=xincrement;
y+=yincrement;
putpixel(round(x),round(y),2);
}
}
Example:
{
xa,ya=>(2,2)
xb,yb=>(8,10)
dx=6
dy=8
xincrement=6/8=0.75
yincrement=8/8=1
1) for(k=0;k<8;k++)
xincrement=0.75+0.75=1.50
yincrement=1+1=2
1=>(2,2)
2) for(k=1;k<8;k++)
xincrement=1.50+0.75=2.25
yincrement=2+1=3
2=>(3,3)
It will be incremented up to the final end point is reached
The Midpoint Line Drawing Algorithm - Pitteway (1967)
Previously, we have shown that the difference between successive values of y in the line
Equation is ±y = m. However, in practice, for 0 · m · 1 the difference between the
A successive value of the y coordinate of the pixel plotted (Round (y)) is either 0 or 1.
So, given that the previous pixel plotted is (xp; yp), then the next pixel ((xp+1; yp+1)) is
either (xp + 1; yp) (let us call this point E, for East) or (xp + 1; yp + 1) (NE).
Therefore, the incremental DDA algorithm can be modi¯ed so that we increment the
value of the y coordinate only when necessary, instead of adding ±y = m in each step of
the loop.
Given that the line equation is:
f(x) = mx + c
E is plotted if the point M (the midpoint of E and NE) is above the line, or else
NE is plotted if M is below the line.
Therefore, E is plotted if:
f(xp+1) · My
mxp+1 + c · yp +
1
2
m(xp + 1) + (ya ¡ mxa) · yp +
1
2
m(xp ¡ xa + 1) · yp ¡ ya +
1
2
defining
¢x = xb ¡ xa
¢y = yb ¡ ya
¢y
¢x
(xp ¡ xa + 1) · yp ¡ ya +
1
2
¢y(xp ¡ xa + 1) ¡ ¢x(yp ¡ ya +
1
2
)·0
2¢y(xp ¡ xa + 1) ¡ ¢x(2yp ¡ 2ya + 1) · 0
Now, let us de¯ne the left hand side of the above inequality by:
C(xp; yp) = 2¢y(xp ¡ xa + 1) ¡ ¢x(2yp ¡ 2ya + 1)
So for all p the point
² (xp + 1; yp) is plotted if C(xp; yp) · 0, or else
² (xp + 1; yp + 1) is plotted if C(xp; yp) > 0.
But how does the value of C(xp; yp) depend on the previous one? If we choose E, then
(xp+1; yp+1) = (xp + 1; yp). Therefore,
C(xp+1; yp+1) = C(xp + 1; yp)
= 2¢y(xp + 1 ¡ xa + 1) ¡ ¢x(2yp ¡ 2ya + 1)
= 2¢y(xp + 1 ¡ xa) ¡ ¢x(2yp ¡ 2ya + 1) + 2¢y
= C(xp; yp) + 2¢y
and, if we choose NE, then (xp+1; yp+1) = (xp + 1; yp + 1). Therefore,
C(xp+1; yp+1) = C(xp + 1; yp + 1)
= 2¢y(xp + 1 ¡ xa + 1) ¡ ¢x(2yp + 2 ¡ 2ya + 1)
= 2¢y(xp + 1 ¡ xa) ¡ ¢x(2yp ¡ 2ya + 1) + 2¢y ¡ 2¢x
= C(xp; yp) + 2(¢y ¡ ¢x)
Moreover, the initial value of C is:
C(xa; ya) = 2¢y(xa ¡ xa + 1) ¡ ¢x(2 ¤ ya ¡ 2 ¤ ya + 1)
= 2¢y ¡ ¢x
Note that the value of C is always an integer.
The value of y is always an integer.
The value of C can be computed from the previous one by adding an integer value
which does not depend on the x and y-coordinates of the current pixel.
Procedure Midpoint Line (xa, ya, xb, yb: Integer);
Var
Dx, Dy, x, y: Integer;
C, incE, incNE: Integer;
Begin
Dx := xb - xa;
Dy := yb - ya;
C := Dy * 2 - Dx;
incE := Dy * 2;
incNE := (Dy - Dx) * 2;
y := ya;
for x := xa to xb - 1 do
begin
PlotPixel (x, y);
If C <= 0 then
C := C + incE
else
begin
C := C + incNE;
inc (y)
end
end;
PlotPixel (xb, y)
End;
The Bresenham line algorithm is an algorithm which determines which points in an ndimensional raster should be plotted in order to form a close approximation to a straight
line between two given points. It is commonly used to draw lines on a computer screen,
as it uses only integer addition, subtraction and bit shifting, all of which are very cheap
operations in standard computer architectures. It is one of the earliest algorithms
developed in the field of computer graphics. A minor extension to the original algorithm
also deals with drawing circles.
While algorithms such as Wu's algorithm are also frequently used in modern computer
graphics because they can support antialiasing, the speed and simplicity of Bresenham's
line algorithm mean that it is still important. The algorithm is used in hardware such as
plotters and in the graphics chips of modern graphics cards. It can also be found in many
software graphics libraries. Because the algorithm is very simple, it is often implemented
in either the firmware or the hardware of modern graphics cards.
The label "Bresenham" is used today for a whole family of algorithms extending or
modifying Bresenham's original algorithm
The algorithm
Illustration of the result of Bresenham's line algorithm. (0,0) is at the top left corner.
The common conventions that pixel coordinates increase in the down and right directions
and that the pixel centers that have integer coordinates will be used. The endpoints of the
line are the pixels at (x0, y0) and (x1, y1), where the first coordinate of the pair is the
column and the second is the row.
The algorithm will be initially presented only for the octant in which the segment goes
down and to the right (x0≤x1 and y0≤y1), and its horizontal projection x1 − x0 is longer than
the vertical projection y1 − y0 (the line has a slope less than 1 and greater than 0.) In this
octant, for each column x between x0 and x1, there is exactly one row y (computed by the
algorithm) containing a pixel of the line, while each row between y0 and y1 may contain
multiple rasterized pixels.
Bresenham's algorithm chooses the integer y corresponding to the pixel center that is
closest to the ideal (fractional) y for the same x; on successive columns y can remain the
same or increase by 1. The general equation of the line through the endpoints is given by:
Since we know the column, x, the pixel's row, y, is given by rounding this quantity to the
nearest integer:
The slope (y1 − y0) / (x1 − x0) depends on the endpoint coordinates only and can be
precomputed, and the ideal y for successive integer values of x can be computed starting
from y0 and repeatedly adding the slope.
In practice, the algorithm can track, instead of possibly large y values, a small error value
between −0.5 and 0.5: the vertical distance between the rounded and the exact y values
for the current x. Each time x is increased, the error is increased by the slope; if it exceeds
0.5, the rasterization y is increased by 1 (the line continues on the next lower row of the
raster) and the error is decremented by 1.0.
In the following pseudo code sample plot(x,y) plots a point and abs returns absolute
value:
function line(x0, x1, y0, y1)
int deltax := x1 - x0
int deltay := y1 - y0
real error := 0
real deltaerr := deltay / deltax // Assume deltax != 0 (line is not vertical),
// note that this division needs to be done in a way that preserves the fractional part
int y := y0
for x from x0 to x1
plot(x,y)
error := error + deltaerr
if abs(error) ≥ 0.5 then
y := y + 1
error := error - 1.0
Generalization
The version above only handles lines that descend to the right. We would of course like
to be able to draw all lines. The first case is allowing us to draw lines that still slope
downwards but head in the opposite direction. This is a simple matter of swapping the
initial points if x0 > x1. Trickier is determining how to draw lines that go up. To do this,
we check if y0 ≥ y1; if so, we step y by -1 instead of 1. Lastly, we still need to generalize
the algorithm to drawing lines in all directions. Up until now we have only been able to
draw lines with a slope less than one. To be able to draw lines with a steeper slope, we
take advantage of the fact that a steep line can be reflected across the line y=x to obtain a
line with a small slope. The effect is to switch the x and y variables throughout, including
switching the parameters to plot. The code looks like this:
function line(x0, x1, y0, y1)
boolean steep := abs(y1 - y0) > abs(x1 - x0)
if steep then
swap(x0, y0)
swap(x1, y1)
if x0 > x1 then
swap(x0, x1)
swap(y0, y1)
int deltax := x1 - x0
int deltay := abs(y1 - y0)
real error := 0
real deltaerr := deltay / deltax
int ystep
int y := y0
if y0 < y1 then ystep := 1 else ystep := -1
for x from x0 to x1
if steep then plot(y,x) else plot(x,y)
error := error + deltaerr
if error ≥ 0.5 then
y := y + ystep
error := error - 1.0
The function now handles all lines and implements the complete Bresenham's algorithm.
Optimization
The problem with this approach is that computers operate relatively slowly on fractional
numbers like error and deltaerr; moreover, errors can accumulate over many floatingpoint additions. Working with integers will be both faster and more accurate. The trick
we use is to multiply all the fractional numbers above by deltax, which enables us to
express them as integers. The only problem remaining is the constant 0.5—to deal with
this, we change the initialization of the variable error, and invert it for an additional small
optimization. The new program looks like this:
function line(x0, x1, y0, y1)
boolean steep := abs(y1 - y0) > abs(x1 - x0)
if steep then
swap(x0, y0)
swap(x1, y1)
if x0 > x1 then
swap(x0, x1)
swap(y0, y1)
int deltax := x1 - x0
int deltay := abs(y1 - y0)
int error := deltax / 2
int ystep
int y := y0
if y0 < y1 then ystep := 1 else ystep := -1
for x from x0 to x1
if steep then plot(y,x) else plot(x,y)
error := error - deltay
if error < 0 then
y := y + ystep
error := error + deltax
Parallel algorithm for line and circle drawing that are based on J.E. Bresenham's line
and circle algorithms The new algorithms are applicable on raster scan CRTs,
incremental pen plotters, and certain types of printers. The line algorithm approaches a
perfect speedup of P as the line length approaches infinity, and the circle algorithm
approaches a speedup greater than 0.9P as the circle radius approaches infinity. It is
assumed that the algorithm are run in a multiple-instruction-multiple-data (MIMD)
environment, that the raster memory is shared, and that the processors are dedicated and
assigned to the task (of line or circle drawing)
Some points worth considering
Intensity of a line depending on the slope
It can be noted that lines with slopes near to §1 appear to be fainter than those with
slopes near to 0 or 1. This discrepancy can be solved by varying the intensity of the pixels
according to the slope.
Antialiasing
Due to the discrete nature of the pixels, diagonal lines often appear jaggied. This
staircasing e®ect is called aliasing, and techniques which try to solve, or at least
minimize this problem are called antialiasing. For example, a line can be treated as a onepixel thick rectangle and the intensity of the pixels is set according to a function of the
area the rectangle covers over that particular pixel.
Endpoint Order
It must be ensured that a line drawn from (xa; ya) to (xb; yb) must be identical to the line
drawn from (xb; yb) to (xa; ya). In the midpoint/Bresenham algorithm, the point E is
chosen when the selection criterion C = 0. (i.e. when the line passes through the
midpoint of NE
and E.) Thus it must be ensured that when the line is plotted from right to left, the point
SW (not W) is selected when the criterion does not specify an obvious choice.
Clipping Lines
Suppose that the line segment ((xa; ya) ! (xb; yb)) is clipped into ((xc; yc) ! (xd; yd)). It
must be ensured that the clipped line segment is identical to the relevant line segment of
the otherwise unclipped line. This can be achieved by calculating the initial selection
criterion C(xc; yc) relative to the initial point (xa; ya) instead of considering (xc; yc) as
the initial point.
LINE FUNCTIONS:
A procedure for specifying straight line segment can be set up in a number of different
forms. The 2D line function is Polyline (n, wc points) where n is assigned as integer
value equal to the number of co-ordinate position to be input.
Wc is the array of world- co-ordinate values for ,line segment end points. The function
is to definr a set of n-1 connected straight line segment .polyline provide more general
line functions. To display a single straight line segment end point co-ordinates in wc
points.
CIRCLE GENERATING ALGORITHM
Beginning with the equation of a circle:
We could solve for y in terms of x
,
Obviously, a circle has a great deal more symmetry. Just as every point above an x-axis
drawn through a circle's center has a symmetric point an equal distance from, but on the
other side of the x-axis, each point also has a symmetric point on the opposite side of a yaxis drawn through the circle's center.
We can quickly modify our previous algorithm to take advantage of this fact as shown
below
So our next objective is to simplify the function evaluation that takes place on each
iteration of our circle-drawing algorithm. All those multiply and square-root evaluations
are expensive. We can do better.
One approach is to manipulate of circle equation slightly. First, we translate our
coordinate system so that the circle's center is at the origin (the book leaves out this step),
giving:
Next, we simplify and make the equation homogeneous (i.e. independent of a scaling of
the independent variables; making the whole equation equal to zero will accomplish this)
by subtracting r2 from both sides.
We can regard this expression as a function in x and y.
Functions of this sort are called discriminating functions in computer graphics. They have
the property of partitioning the domain; pixel coordinates in our case, into one of three
categories. When f(x,y) is equal to zero the point lies on the desired locus (a circle in this
case), when f(x, y) evaluates to a positive result the point lies one side of the locus, and
when f(x,y) evaluates to negative it lies on the other side.
What we'd like to do is to use this discriminating function to maintain our trajectory of
drawn pixels as close as possible to the desired circle. Luckily, we can start with a point
on the circle, (x0, y0+r) (or (0, r) in our adjusted coordinate system). As we move along in
steps of x we note that the slope is less than zero and greater than negative one at points
in the direction we're heading that are near our known point on a circle. Thus we need
only to figure out at each step whether to step down in y or maintain y at each step.
We will proceed in our circle drawing by literally "walking a tight rope". When we find
ourselves on the negative side of the discriminating function, we know that we are
slightly inside of our circle so our best hope of finding a point on the circle is to continue
with y at the same level. If we ever find ourselves outside of the circle (indicated by a
positive discriminate) we will decrease our y value in an effort to find a point on the
circle. Our strategy is simple. We need only determine a way of computing the next value
of the discriminating function at each step.
All that remains is to compute the initial value for our discriminating function. Our initial
point, (0,r), was on the circle. The very next point, (1, r), will be outside if we continue
without changing y (why?). However, we'd like to adjust our equation so that we don't
make a change in y unless we are more than half way to it's next value. This can be
accomplished by initialing the discriminating function to the value at y - 1/2, a point
slightly inside of the circle. This is similar to the initial offset that we added to the DDA
line to avoid rounding at every step.
Initializing this discriminator to the midpoint between the current y value and the next
desired value is where the algorithm gets its name. In the following code the symmetric
plotting of points has be separated from the algorithm
ATTRIBUTES OF OUTPUT PRIMITIVES
Line attributes
line type
line width
pen and brush option
line color
Basic straight line segments can be of type , width and color. We consider how line
drawing routines can be modified to accommodate various attribute specification.
Curve attributes
It may vary with various pixel position and have dotted , dashed lines of curves
If we assign as a mask value as 11100, then according to this we can plot the
curves in pixels.
If points are marked as 3 pixel points then the inter-spacing can be of 2 pixels.
OR it can have 4 pixel points also with no inter-spacing.
Color and grey scale levels
Various colors and intensity are available to the users
Numbers of color choices are available depending on the amount stored in buffer.
Color value is stored in color look up table.
Area fill attributes
It is used to fill color with different styles and color
Hollow
Solid
Character attributes
Font styles
Text size
Width
Character spacing
Setting up vector
Marker symbols
UNIT- II
UNIT-II: 2D Geometric Transformations: Basic Transformations – Matrix
Representations – Composite Transformations – Other Transformations. 2D Viewing:
The Viewing Pipeline – Viewing Co-ordinate Reference Frame – Window-to-Viewport
Co-ordinate Transformation - 2D Viewing Functions – Clipping Operations – Point,
Line, Polygon, Curve, Text and Exterior clippings..
GEOMETRIC TRANSFORMATION
A matrix is a rectangular array of real numbers which can be used to represent operations
(Called transformations) on vectors. A vector in n-space is effectively an nx1 matrix, or a
Column matrix. Non-column matrices will be denoted using capitalized italics
A=
301
201
031
Multiplication: if A is an nxm matrix with entries aij and B is an mxp matrix with entries
bij , then AB is defined as an nxp matrix with entries cij
Identity matrix:
I=
10 0
010
001
Determinant (of a square matrix)
where Aij denotes the determinant of the (n ¡ l)x(n ¡ 1) matrix obtained by removing the
ith row and jth column of A.
Motivation – Why do we need geometric transformations in CG?
As a viewing aid
As a modeling tool
As an image manipulation tool
Example: 2D Geometric Transformation
Modeling Co-ordinates
Coordinates
World Co-ordinates
Scale (0.3, 0.3)
Rotate (-90)
Translation
x x tx
y y ty
Scale
x x sx
y y sy
Rotation
Shear
TWO-DIMENSIONAL VIEWING
Viewing pipeline
Window:-A world-coordinate area selected for display. defines what is to be
viewed
Viewport: - An area on a display device to which a window is mapped. Defines
where it is to be displayed
Viewing transformation: - The mapping of a part of a world-coordinate scene to
device coordinates.
A window could be a rectangle to have any orientation.
2d viewing
Viewing pipeline
Viewing effects
Zooming effects: - Successively mapping different-sized windows on a fixed-sized
view ports.
Panning effects: - Moving a fixed-sized window across the various objects in a
scene.
Device independent:- View ports are typically defined within the unit square
(normalized coordinates)
Viewing coordinate reference frame
The reference frame for specifying the world-coordinate window.
Viewing-coordinate origin: P0 = (x0, y0)
View up vector V: Define the viewing yv direction
Window to view port co-ordinate transformation
xv xvmin
xw xwmin
xvmax xvmin xwmax xwmin
sx
xvmax xvmin
xwmax xwmin
yvmax yvmin
yv yvmin
yw ywmin sy
ywmax ywmin
yvmax yvmin
ywmax ywmin
xv xvmin ( xw xwmin )sx
yv yvmin ( yw ywmin )sy
Homogeneous coordinates
A combination of translations, rotations and scaling can be expressed as:
P0 = S ¢ R ¢ (P + T)
= (S ¢ R) ¢ P + (S ¢ R ¢ T)
=M¢P+A
Because scaling and rotations are expressed as matrix multiplication but translation is
Expressed as matrix addition, it is not, in general, possible to combine a set of operations
Into a single matrix operation. Composition of transformations is often desirable if the
same set of operations have to be applied to a list of position vectors.
We can solve this problem by representing points in homogenous coordinates. In
homogenous coordinates we add a third coordinate to a point i.e. instead of representing a
point by a pair (x; y), we represent it as (x; y;W). Two sets of homogenous coordinates
represent the same point if one is a multiple of the other e.g. (2; 3; 6) and (4; 6; 12)
represent the same point.
Given homogenous coordinates (x; y;W), the Cartesian coordinates (x0; y0) correspond
to
(x=W; y=W) i.e. the homogenous coordinates at which W = 1. Points with W = 0 are
called points at infinity.
Applying transformations
Transformations can be applied to polygons simply by transforming the polygon vertices,
and then joining them with lines in the usual way. However, with the exception of
translation and reflection, transformation of circles, ellipses, and bitmap images is not so
straightforward For example: when a circle or ellipse is sheared, its symmetrical
properties are lost; if a circle or bitmap is scaled by applying the scaling transformation
to each plotted pixel, this could result in gaps (if the scale factor > 1) or the same pixel
being plotted several times (if the scale factor < 1), possibly leaving the wrong color in
the case of bitmaps;
In general, algorithms for transforming bitmap images must ensure that no holes appear
in the image, and that where the image is scaled down, the color chosen for each pixel
Represents the best choice for that particular area of the picture.
To simplify transformation of circles and ellipses, these are often approximated using
Polygons with a large number of sides.
Clipping in 2D
Usually only a specified region of a picture needs to be displayed. This region is called
the clip window. An algorithm which displays only those primitives (or part of the
primitives) which lie inside a clip window is referred to as a clipping algorithm. This
lecture describes a few clipping algorithms for particular primitives
A point (x; y) lies inside the rectangular clip window (xmin; ymin; xmax; ymax) if and
only if the following inequalities hold:
xmin · x · xmax
ymin · y · ymax
Viewing involves transforming an object specified in a world coordinates frame of
reference into a device coordinates frame of reference. A region in the world coordinate
system which is selected for display is called a window. The region of a display device
into which a window is mapped is called a viewport.
The steps required for transforming world coordinates (or modeling coordinates) into
Device coordinates are referred to as the viewing pipeline. Steps involved in the 2D
viewing pipeline:
Transforming world coordinates into viewing coordinates, usually called the
viewing transformation.
Normalizing the viewing coordinates.
Transforming the normalized viewing coordinates into device coordinates.
Given 2D objects represented in world coordinates, a window is specified in
terms of a viewing coordinate system defined relative to the world coordinate
system.
The object's world coordinates are transformed into viewing coordinates and
usually normalized so that the extents of the window ¯t in the rectangle ¯t in the
rectangle with lower left corner at (0; 0) and the upper right corner at (1; 1).
The normalized viewing coordinates are then transformed into device coordinates
to into the view port
CLIPPING OPERATIONS
Clipping: - Identify those portions of a picture that are either inside or outside of
a specified region of space.
Clip window: - The region against which an object is to be clipped. The shape of
clip window
Applications of clipping
World-coordinate clipping
View port clipping
It can reduce calculations by allowing concatenation of viewing and geometric
transformation matrices.
TYPES OF CLIPPING
Point clipping
Line clipping
Area (Polygon) clipping
Curve clipping
Text clipping
Point clipping (Rectangular clip window)
Line clipping
Possible relationships between line positions and a standard rectangular clipping region
Possible relationships
– Completely inside the clipping window
– Completely outside the window
– Partially inside the window
Parametric representation of a line
x = x1 + u(x2 - x1)
y = y1 + u (y2 - y1)
The value of u for an intersection with a rectangle boundary edge
– Outside the range 0 to 1
– Within the range from 0 to 1
Before clipping
After clipping
COHEN SUTHERLAND LINE CLIPPING
Clipping a straight line against a rectangular clip window results in either:
1. A line segment whose endpoints may be different from the original ones, or
2. Not displaying any part of the line. This occurs if the line lies completely outside the
Clip window.
The Cohen-Sutherland line clipping algorithm considers each endpoint at a time and
Truncates the line with the clip window's edges until the line can be trivially accepted
Or trivially rejected. A line is trivially rejected if both endpoints lie on the same outside
Half-plane of some clipping edge.
The xy plane is partitioned into nine segments by extending the clip window's edges
Each segment is assigned a 4-bit code according to where it lies with respect to
The clip window:
Bit Side Inequality
1 N y > ymax
2 S y < ymin
3 E x > xmax
4 W x < xmin
For example bit 2 is set if and only if the region lies to the south of (below) the clip
Window
Region code
–
–
A four-digit binary code assigned to every line endpoint in a picture.
Numbering the bit positions in the region code as 1 through 4 from right to
left.
Bit values in the region code :- Determined by comparing endpoint coordinates to the clip boundaries
- A value of 1 in any bit position: The point is in that relative position.
Determined by the following steps:
Calculate differences between endpoint coordinates and clipping Boundaries. Use
the resultant sign bit of each difference calculation to set the corresponding bit
value.
The possible relationships:
Completely contained within the window
0000 for both endpoints.
Completely outside the window
Logical and the region codes of both endpoints, its result is not 0000.
Partially
LIANG BARSKY LINE CLIPPING
Rewrite the line parametric equation as follows:
x x1 ux
y y1 uy
Point-clipping conditions:
xwmin x1 ux xwmax
ywmin y1 uy ywmax
Each of these four inequalities can be expressed as:
upk qk
k 1,2,3,4
Parameters p and q are defined as
p1 x
q1 x1 xwmin
p2 x
q2 xwmax x1
p3 y
q3 y1 ywmin
p4 y
q4 ywmax y1
pk = 0, parallel to one of the clipping boundary
qk < 0, outside the boundary
qk >= 0, inside the parallel clipping boundary
pk < 0, the line proceeds from outside to the inside
pk > 0, the line proceeds from inside to outside
NICHOLL-LEE-NICHOLL LINE CLIPPING
Compared to C-S and L-B algorithms
NLN algorithm performs fewer comparisons and divisions.
NLN can only be applied to 2D clipping.
The NLN algorithm
Clip a line with endpoints P1 and P2
First determine the position of P1 for the nine possible regions.
Only three regions need be considered
The other regions using a symmetry transformation
Next determine the position of P2 relative to P1.
Non rectangular clip windows
Algorithms based on parametric line equations can be extended
Liang-Barsky method
Modify the algorithm to include the parametric equations for the boundaries of the
clip region
Concave polygon-clipping regions
Split into a set of convex polygons
Apply parametric clipping procedures
Circle or other curved-boundary clipping regions
Lines can be clipped against the bounding rectangle
Splitting concave polygons
Rotational method
-Proceeding counterclockwise around the polygon edges.
-Translate each polygon vertex Vk to the coordinate origin.
-Rotate in a clockwise direction so that the next vertex Vk+1 is on the x axis.
-If the next vertex, Vk+2, is below the x axis, the polygon is concave.
-Split the polygon along the x axis.
Polygon clipping
UNIT III
UNIT-III: 3D Concepts: 3D Display Methods – 3D Graphics Packages. 3D Object
Representations: Polygon Surfaces – Curved lines and Surfaces – Quadric Surfaces –
Super quadrics – Blobby Objects – Spline representations. 3D Geometric Modeling and
Transformations: Translation – Rotation – Scaling – Other Transformations –
Composite- Transformations – 3D Transformation functions..
Introduction
Graphics scenes can contain many different kinds of objects
No one method can describe all these objects
Accurate models produce realistic displays of scenes
Polygon and quadric surfaces
Spline surfaces and construction techniques
Procedural methods
Physically-based modeling methods
Octree encodings
Boundary representations (B-reps)
Space-partitioning representations
Polygon Surfaces
The most commonly used boundary represent-ation
All surfaces are described with linear equations
Simplify and speed up surface rendering and display of objects
Precisely define a polyhedron
For non-polyhedron objects, surfaces are tessellated
Commonly used in design and solid modeling
The wire frame outline can be display quickly
Polygon Tables
Alternative arrangements
• Use just two tables: a vertex table and a polygon table
• Some edges could get drawn twice
• Use only a polygon table
• This duplicates coordinate information
Extra information to the data tables
Expand the edge table to include forward pointers into the polygon table
Common edges between polygons
Expand vertex table to contain cross-reference to corresponding edges
Additional geometric information
The slope for each edge
Coordinate extents for each polygon
Tests for consistency and completeness
Every vertex is an endpoint for at least two edges
Every edge is part of at least one polygon
Every polygon is closed
Each polygon has at least one shared edge
Every edge referenced by a polygon pointer has a reciprocal pointer back to
the polygon
We specify a polygon surface with a set of vertex co-ordinates and associated attribute
parameters. A convenient organization for storing geometric data is to create 3 lists.
1. vertex table
2. edge table
3. polygon table
Co-ordinate values of each vertex in the object are stored in vertex table.
Edge table contains pointers back in to the vertex table to identify the vertices for each
polygon edge
Polygon table contains pointers back in to the edge table to identify the edges for each
polygon
Vertex table
V1=x1 y1 z1
V2= x2 y2 z2
V3= x3 y3 z3
V4=x4 y4 z4
V5= x5 y5 z5
Edge table
Polygon surface table
E1= v1 v2
E2= v2v3
E3= v3 v1
E4= v3 v4
E5= v4 v5
E6= v5 v1
S1= e1 e2 e3
S2= e3 e4 e5 e6
It provides convenient reference to individual component. Error checking is easier.
Alternative arrangement contain 2 tables
Vertex table
Polygon table
It has less convenient.
There are 4 tests.
Every vertex has at least 2 edges
Every edge is part of any one polygon
Very polygon is closed
Every polygon has at least one shared edge.
Specify a polygon surface
• Geometric tables
• Vertex coordinates
• Spatial orientation of the polygon
• Attribute tables
• Degree of transparency
• Surface reflectivity
• Texture
Plane equations
The equation for a plane surface
• Ax + By + Cz +D = 0
By Cramer’s rule:
Values of A,B,C and D are computed for each polygon and stored with the other
polygon data
Orientation of a plane surface
• Surface normal vector (A, B, C)
Distinguish two sides of a surface
• “Inside” face
• “Outside” face
• The normal vector from inside to outside
• Viewing the outer side of the plane in a right-handed coordinate
system
• Vertices are specified in counterclockwise direction
To produce a display of a 3D object, we must process the I/P data representation for
object through several procedures.
The processing steps are
1. transformation of modeling co-ordinates into Wc Vc Dc
2. Identification of visible surface.
3. Application of surface rendering procedures.
4. For some process we need information about spatial orientation of the surface.
5. equation for a planning surface expressed as
Ax+By+CZ+D=0 1
Where (x, y, z) are the point on the plane.
(A, B, C, D) are the co-efficient of the constant that describes the spatial
properties of the plane.
We can obtain A, B, C, and D by solving a set of three plane equations.
We can select 3 successive polygon vertices as (x, y, z) (x2, y2, z2) and (x3, y3, z3)
Identify a point (x, y, z) as either inside or outside a plane surface
• In a right-handed coordinate system, the plane parameters A, B, C, and D
were calculated using vertices selected in a counterclockwise order when
viewing the surface in an outside-to-inside direction.
If Ax+By+Cz+D<0, the point(x,y,z) is inside the surface
If Ax+By+Cz+D>0, the point(x,y,z) is outside the surface
Polygon Mesh
A single plane surface can be specified with a function as fill area. But when object
surface are to be filed it is more convenient to specify the surface. There are two types of
polygon mesh.
One type of polygon mesh is triangle strip connected with (n-2) functions.
A triangle strip formed with n triangle connecting 13 vertex.
Another type is quadrilateral mesh, which generates a mesh of (n-1) by (m-1)
quadrilateral
Curved Lines and Surfaces
These methods are commonly used to design new object shapes, to digitize drawing and
to describe animation paths.
Display of 3D curved lines and surfaces can be generated from i/p sets of mathematical
functions defining the objects or fr4om a set of user specified data points.
Curved surface are expressed in parametric and non- parametric form.
Here parametric application is more convenient
The generation of 3D curved lines and surfaces
• An input set of mathematical functions
• A set of user-specified data points
Curve and surface equations
• Parametric (more convenient)
• Nonparametric
Quadric Surfaces
• Sphere
• Ellipsoid
• Torus
Parametric Representation
A curve can be described with a single parameter ‘U’. We can express of 3 Cartesian coordinates in terms of parameters view.
P (u) =(x/u), y/u), z/u))
u 0 to 1 , u = unique interval.
Non- Parametric Representation
Object descriptions are return directly in terms of the co-ordinates.
Example: represent a surface with the following Cartesian functions.
If (x, y, z) = 0 implicit
If z = f(x, y) explicit.
Here x, y are independent variables and z is the dependent variable.
Quadratic surface
Frequently used classes of object are the quadratic surface.
This includes sphere, ellipsoids, torus, paraboloids, and hyper boloids.
Primitives from which more complex objects can be constructed
Ellipsoid
Ellipsoid
It is an extension of
spherical surface. Where
radius is in 3 mutually
similar direction with
different values.
Torus
It is a dough-nut shaped object.
It is generated by rotating a circle or other conic about specified axis.
y
(x y,z)
x
r
x y
rx ry
2
2
2
2
z 1
rz
x rx (r cos ) cos
y ry (r cos ) sin
z rz sin
Torus
Sphere.
In Cartesian co-ordinates, a spherical surface with radius r centered on the co-ordinates
origin is defined as a set of points (x, y, z) that satisfy the equations.
Z axis
We can also represent using u and v parameters that range from 0 to 1, by substituting.
Super quadrics
It is formed by incorporating additional parameters. Quadratic equation is to provide
increased flexibility for adjusting object shape.
Additional parameters are used to equal to the dimension of the object.
One parameter for curve
One parameter for surface
A generalization of the quadric representations
– Incorporate additional parameters into the quadric equations
–
The number of additional parameters used is equal to the dimension of the
object.
Super ellipse
y
r
y
x rx cos s
x
rx
0.5
2/ s
1.0
2/ s
1
y ry sin s
1.5
2.0
2.5
Blobby Objects
Some objects do not maintain a fixed shape. They change their surface characteristic in
certain motion.
Eg: it includes molecular structure, water droplets, melting objects, muscles shapes in the
human body
It illustrates the stretching shaping and contracting effects on molecular shape, when two
molecules move apart.
a
b
It shows, muscle shape in human arm, which exhibit similar characteristic.
In this way we use a Gaussian density function, a surface function is defined.
Metaball, or ‘Blobby’, Modelling is a technique which uses implicit surfaces to produce
models which seem more ‘organic’ or ‘blobby’ than conventional models built from flat
planes and rigid angles”.
Uses of Blobby Modelling
Organic forms and nonlinear shapes
Scientific modelling (electron orbital’s, some medical imaging)
Muscles and joints with skin
Rapid prototyping
CAD/CAM solid geometry
How does it work?
Each point in space generates a field of force, which drops off as a function of
distance from the point.
A blobby model is formed from the shells of these force fields, the implicit
surface which they define in space.
Several force functions work well. Examples:
“Blobby Molecules” - Jim Blinn
F(r) = a e-br2
Here ‘b’ is related to the standard deviation of the curve, and ‘a’ to the
height
Spline Representations
Spline: In drafting terminology
• A flexible strip used to produce a smooth curve through a designated set
of points
• Several small weights are distributed along the strip
Spline Curve: In computer graphics
• Any composite curve formed with (cubic) polynomial sections satisfying
specified continuity conditions at the boundary of the pieces.
Spline surface
• Described with two sets of orthogonal spline curves
There are several different kinds of spline specifications
Interpolation and Approximation Splines
Control points
• A set of coordinate positions indicates the general shape of the curve
• A spline curve is defined, modified, and manipulated with operations on
the control points.
• Interpolation curves: the curve passes through each control points
• Digitize drawings
• Specify animation path
• Approximation curves: fits to the general control-points path without
necessarily passing through any control points
• Design tools to structure surfaces
Interpolation and Approximation Splines
Convex hull
• The convex polygon boundary encloses a set of control points.
• Provide a measure for the deviation of a curve or surface from the region
bounding the control points
Control graph (control polygon, characteristic polygon)
Parametric Continuity
Continuity conditions
• To ensure a smooth transition from one section of a piecewise parametric
curve to the next.
• Set parametric continuity by matching the parametric derivatives of
adjoining curve sections at their common boundary.
Zero-order (C0) continuity
First-order (C1) continuity
Second-order (C2) continuity
• The rates of change of the tangent vectors for connecting sections are
equal at their intersection
Geometric Continuity
C2
p0
p1
p2
C1
C3
p0
p1
p2
C1
Spline Specifications
Three methods for specifying a spline
• A set of boundary conditions imposed on the spline
• The matrix characterizes the spline
• The set of blending functions (or basis functions)
Boundary conditions
x(u)=axu3+bxu2+cxu+dx
0<=u<=1
• On the endpoints x(0) and x(1).
• First derivatives at the endpoints x’(0) and x’(1).
• Determine the values of ax, bx, cx, and dx.
Cubic Spline Interpolation Methods
Cubic polynomials
• Offer a reasonable compromise between flexibility and speed of
computation.
• Compared to higher-order polynomials
• Less calculations and memory
• More stable
• Compared to lower-order polynomials
• More flexible for modeling arbitrary curve shapes
Cubic Spline Interpolation Methods
Cubic interpolation splines
• Given a set of control points
• Fitting the input points with a piecewise cubic polynomial curve
Suppose we have n + 1 control points
pk ( xk , yk , zk )
UNIT-IV
Visible – surface Detection methods: classification of visible surface algorithms – backface detection – Depth Bugger method – A buffer method – Scan line method – Depth
sorting method – BSP tree method – Area subdivision method – Octree methods – Ray
casting methods – curved surfaces – wire frame methods – visibility detection functions.
VISIBLE SURFACE DETECTION METHODS:
They deal with object definition directly or with their projected image. They deals
with 2 approaches,
Object Space methods
Image Space Methods.
Object Space Methods:
This method compares object and parts of an object to each other
within the same definition to
Determine which surface as a whole, we should label as visible.
Image Space Methods:
Visibility is decided point by point at each pixel position on the
projection plane.
BACK FACE DETECTION:
A fast and simple object space method for identifying the back face of a
polyhedron is based on “Inside- Outside” tests.
If a point X,Y,Z is inside , then the plane parameters A,B,C and D if
AX+BY+CZ+D<0
1 surface, polygon must be
When an inside point is along the line of the sight to the
a back face.
Simplify this test by considering the normal vector N to a polygon surface.
If V is the viewing direction from the eye position then
V.N > 0
2
Then it is converted to projection co-ordinate and our viewing direction is parallel
to viewing Z axis , then v=(0,0,Vz) and
V.N =Vz C.
If C<0, then the viewing Direction along the negative Zv axis,
If C=0, we cannot see any normal face in Z component.
We can label any polygon as back face detection if the vector has Z component
value.
C<0
3
N=(A,B,C)
V
Vector V in the viewing direction and a back face normal vector N of a
polyhedron.
N(A,B,C)
Yv
Xv
Zv
A Polygon surface with plane parameter c<0 in a back face detection with
negative Z value.
The plane package of A,B and C are calculated by polygon vertex specified in
clockwise direction.
If the back face detection is normal vector that point away from viewing position,
identified by c>0 with positive Z axis.
DEPTH BUFFER METHOD:
A commonly used image space approach to detecting visible surface is the depth
buffer method.
This compares the surface of the depth at each pixel position on the projection
plane.
Object depth is usually measured from the view plane along Z axis.
Depth values are computed very quickly and easy to implement.
Yz
Xz
(X,Y)
Zv
Object description converted to the co-ordinate of (x,y,z) position that
corresponds to view plane (x,y).
Therefore the pixel position (x,y) on view plane, object depths can be compared
by Z- values.
Therefore it shows the three surface at varying distance along the projection line
from (x,y) in a view plane
Taken as Xv,Yv plane.
A depth buffer is used to store depth values for each (x,y) position as the surface
are processed. And the refresh
Buffer stores the intensity values for each position.
If the calculated depth is greater than the value stored in the depth buffer, the new
depth value is stored.
Depth values for a surface position (x,y) are calculated from the plane equation.
Z= -Ax-By-D
C
1
The horizontal and the vertical across the line differ by 1.
If depth of position (x,y) has been determined to be z, then the depth z` of next
position (x+1,y) long
The Equation 1,
Y
y
y-1
X
x
Z`= -A(x+1)-by-D
C
(OR)
x+1
2
Z`=Z –A/C
There fore –A/C is the Constant for each surface.
We first determine y co-ordinate extents of each polygon and process the surface
from top most to bottom most Scan Line.
Starting from top vertex , we have to calculate x position edge as
X` = X-1/m Where m is the slope of edge then,
Z`= Z+A/M+B
C
We propose down vertical edge as
Z`=Z+B/C
3
To Scan Line
Y Scan line
Bottom Scan Line
(i)
Scan Line interacting a polygon
surface
(ii)
y scan line
y+1 scan line
Line along a left polygon edge
A BUFFER METHOD:
It represent as ant aliased, area averaged accumulation buffer method. Developed
by Lucas film for implementation
in surface rendering system called REYES(Rendering Everything You Even
Saw).
Drawbacks:
(i). Finds visible surface at each pixel position.
(ii). It deals with opaque surface.
A buffer method expands the depth buffer so that position in buffer can reference
in linked list of surface.
It has 2 fields,
Depth Field ---- Store a positive or negative real number.
Intensity Field ---- Stores Surface--- intensity information
or a pointer values.
background
opaque
surface
2>0
1
foreground transparent
surface
D<0
Surf1
Sruf2
Depth
Field
intensity
Field
(i)
(ii)
If depth Field is positive, then the position is the depth of single surface
overlap.
If the depth field is negative, then indicates multiple surface contributions
to the pixel intensity.
This intensity field stores a point to a linked list of Surface data.
These linked lists includes..,
RGB intensity Components
Opacity Parameter(Percent of transparency)
Depth
Percent of area coverage
Surface Identifier
Other Surface Rendering Parameters
Pointer to next Surface
SCAN LINE METHOD:
This image space method for removing hidden surface is an extension of
the scan line Algorithm.
Each scan line is processed, all polygon surface intersecting that lines are
examined to determine which is visible.
Across each scan line, depth calculations are made for each overlapping
surface to determine which is nearest to the view plane.
After determining the visible surface, the intensity value for that position
is entered into the refresh buffer.
Yv
BE
A
F
Scan Line1
S1 S2
H
D
Scan Line2
Scan Line3
C
G
Xv
The scan line method for locating visible position edge of surface pixel
position along the line.
Active scan line1 contains the edges of AB, BC, EH and FG.
Edge between the scan line AB and BC the flag surface is S1 is ON.
Similarly edge between EF and FG the flag surface is S2 is ON.
Depth Calculation must be made using the plane co-efficient for the two
surfaces.
E.g.: If depth surface of S1 is assumed to be less than S2, then the intensity for
surface S1 are loaded into the refresh buffer.
Scan line3 has the same active list of edges as scan line2. Since there is no
change have occurred in line intersection.
Then the depth calculation are made between EF and BC
Any number of overlap polygon surface is processed, then it indicated
whether the position in inside or outside.
Then depth calculation are performed when the surface overlap.
If the surfaces overlap each other, then we can divide the surface to
eliminate the overlap.
The dashed lines indicate where planes could be sub divided to form 2
distinct surfaces. So overlap are eliminate
Sub-dividing line
Sub dividing line
(i)
(ii)
Sub dividing line
(iii)
DEPTH BUFFER METHOD:
It is based on image space and the object space method, It performs following
functions.
Surface are sorted in order of decreasing depth
Surface area scan converted in order, starting with the surface of greatest depth.
Sorting is carried out in both image and object space.
It is used for hidden surface method and it is referred as “Pointer algorithm”.
We 1st sort the surface according to the distance from the view plane.
Then the intensity values for the farthest surface are entered into the refresh
buffer.
Yz
Zmax
Zmin
Z’max
Z’min
2 surface that overlap in the XY Plane but have no depth overlap
4 methods to test the surface. They are
Bounding rectangle in the XY plane for the 2 surfaces do not overlap.
Surface S is completely behind the overlapping surface relative to the
viewing position.
The overlapping surface is completely in front of S relative to the
viewing surface.
The projections of the two surfaces onto the view plane do not overlap.
Test 1 is performed in 2 parts, 1st check for overlap in x- direction, and then we
check for overlap in Y.
If any one shows overlap, then the two planes cannot obscure one other.
Yv
S
S’
Xmin Xmax
X’max X’min
Xv Zv
We can perform test 2 and 3 with an “Inside- Outside” polygon test
If the test 1and 3 are failed, we try the test 4 by checking for intersection between
the bounding edges of the two
Surfaces using line equation in the XY- plane
Yv
Yv
S
S’
S’
Xv
Xv
Zv
Zv
(i)Surface S is completely behind (“inside”)
is
the overlapping surface.
(“outside”)
of surface S but S is not
completely behind S’
(ii) Overlapping surface S’
Completely in front
S’
(a)
(b)
[Two surface with overlapping bounding rectangle in the XY
Plane]
2 surfaces may or may not interest even though their co-ordinate extents
overlap in the X, Y and z- directions.
If we cannot find any of the depth surface, we can replaced by new surface
by original surface and we continue
processing as before.
BSP-TREE METHOD:
It is an efficient method for determining object visibility by painting
surfaces onto the screen from front to back.
This is used, when the view reference point changes, but the object in a
scene are at fixed position.
P2
P1
P1
C
front
back
A
Front
D
P2
back
front
A
back
C
P3
front
B
back
D
(i)
(ii)
With plane P1 we 1st partition the space into 2 sets of object.
One set of object is behind, or in back of plane P1 relative to the viewing direction.
And other set in front of P1.
Since one object is intersected by plane P1, we divided that object into 2 separate
objects labeled A and B.
Object A and C are in front of P1 and objects B and D are behind P1.
In this, the object are represented as terminal nodes, with front objects as left
branches and back object as right branches.
Polygon equations are used to identify “inside” and” outside”, and tree is constructed
with one partitioning plane for each polygon face
When the BSP tree is completed, we process the tree by selecting the surface for
display in the order back to front
AREA SUBDIVISION METHOD:
It is used to divide the total viewing area into smaller and smaller rectangles until
each small area is the
Projection of a part of a single visible surface.
We need to establish tests that can quickly identify the area as a single surface
part.
Then we divide the parts into single surface and we can view easily.
If the test indicate that the view is sufficiently complex, then we sub divided it.
We continue this process until they are reduced to size of a single pixel,
Dividing a square area into equal sized quadrants at each step.
Surrounding Surfaces: One that completely encloses the area.
Overlapping Surfaces: One that is partly inside and partly outside the
area.
Inside Surfaces
: One that is completely inside the area.
Outside surfaces
: One that is completely outside the area.
Classification of visible surface that are stated:
The entire surfaces are outside surface with respect to the area.
Only one inside, overlapping, or surrounding surface is in the area
A surrounding surface obscures all other surfaces within the area boundaries.
Surrounding Surface
outside Surface
Overlapping Surface
inside Surface
Once a single inside, overlapping or surrounding surface has been
identified, its pixel intensities are transferred to the appropriate area
within the frame buffer.
One method for implementing test 3 is to order surfaces according to
their minimum depth from the view plane.
Yv
Zmax
Zv
Area
Fig: Within a specified area, a surrounding surface with a maximum depth of Zmax
obscures all surface that have a minimum depth beyond Zmax
Test 3 is satisfied.
Another method is, if the calculated depth for one of the surrounding
surface is less than the calculated depth for all other surface test is
true.
Calculated depth for all other surface test is true.
In the limiting case, when a sub division the size of a pixel is
produced. We simply calculated the depth of each
Relevant surface at that point and transfer the intensity of the nearest surface to
the frame buffer.
Yv
S
A2
A1
Xv
Zv
Fig: Area A is sub divided into A1 and A2 using the boundary of surface
S on the view plane.
Surface S is used to partition the original area A into the sub division
A1 and A2.
Surface S is then a surrounding surface for A1 and visibility tests 2
and 3 can be applied to determine
Whether further sub dividing is necessary.
OCTREE METHOD:
Numbered octants of a region.
7
0
2
1
3
V (viewing direction)
Fig: Objects in octants 0, 1, 2 and 3 obscures objects in the back octants
(4,5,6,7) when the viewing direction is as shown.
Octants 0,1,2,3 are visible to the viewer.
Any surface toward the rear of the front octants or in the back octants 4, 5, 6 and 7
may be hidden by the front surfaces.
Back surfaces are eliminated for the viewing direction by processing data elements
in the octree nodes in the order 0, 1,2,3,4,5,6,7.
This results in a depth first transversals of the octree.So that nodes representing
octants 0, 1,2and 3 for the entire region are visited before the nodes representing
octants 4, 5, 6 and 7.
Similarly the nodes for the front four sub- octants of octants 0 are visited before the
nodes for the four back sun octants.
When a color value is uncounted in an octree node, the pixel area in the frame buffer
corresponding to this node is assigned.
Only the front colors are loaded into the buffer.
Nothing is loaded an area is void.
Any node that is found to be completely obscured is eliminated from further
processing, so that its
sub tree is not accessed.
5
6
4
1
1
3
7
2
2
3
Octants in Space
Quadrants for the view plan
A method for displaying an octree is first to map the octree onto a quad tree of
visible area by traversing octree nodes from front to back in a recursive
procedure.
Color values in quadrant 1 are obtained from surface in octants 1 and 5 and values
in each of the other
o two quadrants are generated from the pair of octants aligned with each of
these quadrants.
Both front and back octants must be considered determine the correct color values
for a quadrant.
But if, the front octant is homogeneously filled with some color, due do not
process the back octant.
For heterogeneous regions, the procedure is recursively called passing as new
arguments the child of the
Heterogeneous octant and a newly created quad tree nodes.
If the front is empty, the rear octant is processed.
RAY CASTING METHOD:
In this diagram we can determine which object in the scene intersects this line.
After calculating all rays surface intersections, we identify the visible surface as
the one whose intersection point is closest to the pixel.
This visibility detection scheme uses ray casting procedures.
Ray casting as a visibility detection tool is based on geometric optics methods,
which trace the paths of light rays.
Since there are an infinite number of light the rays in a scene and we are
interested only in those rays that pass through pixel positions, we can trace the
light ray paths backward from the pixel through the scene
The ray casting approaches is an effective visibility detection method for scene
with curved surface, particularly spheres.
In ray casting we process pixels one at a time and calculate depths for all surface
along the projection path to that pixel.
Ray casting is a pixel case of ray tracing algorithm that trace multiple ray path to
pick up global reflection and refraction contribution from multiple object ia a
scene.
CURVED SURFACES:
(i) CURVED SURFACE REPRESENTATION:
We can represent a surface with an implicit equation of the form f(x,y,z)=0 or
with parametric representation.
Spline are normally described with parametric equation
A height function over an xy ground plane is Z=f(x,y)
These surfaces are commonly used to model molecular structure roller bearing,
rings and shafts.
(ii) SURFACE CONTOUR PLOTS:
For many applications in mathematics physical science, engineering it is useful
to display a surface function with a set of contour lines that show the surface
shape.
The surface may be described with an equation (or) data tables such as
topographic data or elevation or population density.
To obtain an xy plot of a functional surface, we write the surface
representation in the form, Y=f(x,y).
A curve in the xy plane can then be plotted for values of z within some selected
range, using a specified interval Z.
Starting with the largest value of Z we plot the curve from “ffront” to “back”
and eliminate hidden sections.
We draw the curve section on the screen by mapping an xy range for the
function into an xy pixel screen range.
Then unit steps are taken in x and the corresponding Y value for each Z value
is determine from the previous equation for a given value of Z.
One way to identify the visible curve sections on the surface is to maintain a
list of Ymin and Ymax value previously calculated for the pixel x co-ordinate
on the screen.
If Ymin< Y<Ymax that point on the surface is not visible and we do not plot.
But if the calculated Y value is outside the stored Y bounds for that pixel the
point is visible.
WIREFRAME METHODS:
When only the outside of an object is to be displayed visibility test are applied
to surface edges.
Visible edges sections are displayed and the hidden edge section can either be
eliminated or displayed differently from the visible edges.
Therefore hidden surface are drawn in dashed lines.
Procedures for determine visibility of object edges are referred to as wireframe
visibility method. They also called visible line detection method or hidden line
detection method.
Hidden line section (dashed)
Penetrate the surface
for a line that passes behind surface (i)
(i)
(ii)
A direct approach to identify the visibility the visible lines in a scene is to
compare the line to each surface.
For each line depth value are compared to the surface to determine which
line sections are not visible.
We can use coherence method to identify hidden line segment without
actually testing each co ordinate position.
If both line intersection with the projection of a surface boundary have
greater depth than the surface boundary have greater depth than the surface at
those points, the line segment between the intersection is completely
hidden(Fig i).
When a line has greater depth at one boundary intersection and less depth
than the surface at the other boundary intersection, the line must penetrate the
surface interior (Fig ii).
Some visible surface methods are readily adapted to wireframe visibility
testing.
VISIBILITY DETECTION FUNCTIONS:
Back face or Depth buffer
In general programming package, such as GKS and PHIGS, visibility methods
are implementation dependent.
Set HLHSR identifier( Hidden Line Hidden Surface Removal)
It is assigned an integer code to identify the visibility that is to be
applied to subsequently specified output primitives.
UNIT-V
Illumination models: Properties of Light – Standard primaries and the chromaticity
diagram – intuitive color concepts – RGB color model – YIQ color model - CMY color
model – HSV color model - Conversion between HSV and RGB models – color
selection and Applications.
ILLUMINATION MODELS AND SURFACE RENDERING METHODS
INTRODUCTION:
An illumination model also called a lighting model and sometimes referred to as a
shading model, is used to calculate the intensity of light that we should see at a given
point on the surface of an object.
Sometimes surface rendering procedures are termed as Surface shading methods.
To avoid confusion, we will refer to the model or a lighting model, and we will use the
term surface rendering to mean a procedure for applying model a lighting model to obtain
pixel intensities for all the projected surface positions in a scene.
Illumination models in computer graphics are often loosely derived from the
physical laws that describe surface light intensities. To minimize intensity calculations
most packages use empirical models based on simplified photometric calculations.
LIGHT SOURCES:
When we view an opaque non-luminous object, we see reflected light from the
surfaces of the object. The total reflected light is the sum of the contribution from light
source and other reflecting surface in the scene.
(Light viewed from a opaque nonluminous surface is in general a combination of
reflected light from a light source and reflection of light reflection from other surfaces)
Sometimes light source are referred to as light-emitting sources; and reflecting
surfaces such as the walls of a room are termed as light reflecting sources. A luminous
object in general can be both a light source and a light reflector.
The simplest model for a light emitter is a point source. Rays from the source then
follow radically diverging paths from the source position. This light source model is a
reasonable approximation for sources whose dimensions are small compared to the size
of objects in the scene.
•
(Diverging ray paths from a point light source)
The illumination effects cannot be approximated realistically with a point source
because the area of the sources is not small compared to the surfaces of the sources.
When light is incident on an opaque surface, part of it is reflected and part is absorbed.
The amount of incident light reflected by a surface depends on the type of material. Shiny
materials reflect more of the incident light, and dull surface absorb more of the incident
light.
(An object illuminated with a distributed light sources.)
Surfaces that are rough or grainy tend to scatter the reflected light in all
directions. This scattered light is called diffuse reflection. In addition to diffuse
reflection, light source create highlights or bright spots called specular reflection. This
highlight effects is more pronounced on shiny surface than on dull surfaces.
BASIC ILLUMINATION MODELS:
Lighting calculations are base don the optical properties of surfaces the
background lighting conditions and the light source specifications. All light sources are
considered to be point sources specified with a coordinate position and an intensity value
(color).
Ambient Light:
A surface that is not exposed directly to a light source still will be visible if
nearby objects are illuminated. The combinations of light reflection from various surfaces
to produce a uniform illumination called the ambient Light.
The level for the ambient light in a scene with parameter Ia and each surface
is then illuminated with this constant value.
Diffuse Reflection:
Ambient light reflection is an approximation of global diffusion lighting
effects. Diffusion refection are constant over each surface is a scene, independent of the
viewing direction, The fraction amount of the incident light that is diffusely reflected can
be set for each surface with parameter Kd is assigned a constant value in the interval 0 to
1. Highly reflected surface we set the value Kd near 1 which produce bright surfaces. A
surface that absorbs most of the incident light we set the value as 0. Where Kd is
constant.
N
ǿN
ǿN
Radiant energy direction
dA
Iambdiff=KdIa
1
Since ambient light produces a flat uninteresting shading for each surface scenes are
rarely rendered with ambient light alone. The diffuse reflection from the surface are
scattered with equal intensity in all direction, independent of the viewing direction. Such
surface are sometimes referred to as ideal diffuse reflectors. They are surface is governed
by Lambert’s Cosine Law.
(a)
(b)
(A surface perpendicular to the direction of the incident light (a) is more illuminated
than an equal-sized surface at an oblique angle (b) to the incoming light direction)
N
Incident light
ǿ
A
ǿ
A Cosǿ
(An illuminated area projected perpendicular to the path of the incoming light rays.)
If we denote the angle of incidence between the incoming light direction and the
surface normal as ǿ then the projected area of a surface patch perpendicular to the light
direction is proportional to cosǿ. If Il is the intensity of the point light source, then the
diffuse reflection equation for a point on the surface can be written as,
Itdiff=KdIlcosǿ
If N is the unit normal vector to a surface and L is the 2unit direction vector to the
point light source from a position on the surface then cosǿ=N.L and the diffuse reflection
equation for single point source illumination is
Ildiff = KdIl (N.L)
3
N
To light source L
ǿ
Reflections for point source illumination are calculated in world coordinates or viewing
coordinates before shearing and perspective transformation are applied.
In addition many graphics package introduce an ambient reflection coefficient
Ka to modify the ambient light intensity Ia for each surface.
Idiff = KaIa+KdIl(N.L)
4
Specular reflection and the phong model:
Bright spot at certain viewing direction is called as specular reflection, is the result of
total or near total reflection of the incident light in a concentrated region around the
specular reflection angle.
The specular reflection angle equals the angle of the incident light, with the two
angles measured on opposite sides of the unit normal surface vector N. In this figure we
use R to represent the unit vector in the direction of ideal specular reflection, L to
represent the unit vector directed toward the point light sources, and V as the unit vector
pointing to the viewer from the surface position.
Reflected light when vector V and R coincide (ǿ=0).
N
L
R
Ǿ ǿ
V
(Specular reflection angle equals angle of incidence ǿ)
An empirical model for calculating the specular reflection range developed by Phong Bui
model sets the intensity of specular reflection proportional to Cos^nsǿ. We can
approximately model monochromatic specular intensity variations using a specular
reflection coefficient, W(ǿ), for each surface.
Using the spectral reflection function W (ǿ) we can write the phong specular
reflection model as,
Ispec = W (ǿ)Il cos^nsǿ
Where Il is the intensity of the light source and ǿ is the5viewing angle relative to
the specular reflection direction R. N
N
L
R
L
R
Shiny Surface (large Ns)
Dull Surface (Small Ns)
Since V and R are unit vectors in the viewing and specular reflection direction, we
can calculate the value of cosǿ with the dot product V.R. Assuming the specular
reflection co-efficient is a constant, we can determine the intensity of the specular
reflection at a surface point with the calculation.
Ispec = KsIl (V.R) ^ns
6
Vector R in the expression can be calculated in terms of vectors
L and N.
R+L =(2N.L)N
And the specular reflection vector is obtain as
R= (2N.L)N-L
7
N
L
L
R
N.L
(Calculation of vector R by considering projection onto the direction of the normal
Vector N)
Phong model is obtained by using the halfway vector H between L and V to
calculate the range of specular reflections. If we replace V.R in the Phong model with the
dot product N.H, this simply replaces the empirical cosǿ calculation with the empirical
cos ά calculation. The halfway vector is obtained as,
H= L+V
L+V
8
L
N H
ά
R
ǿ
V
(Halfway vector H along the bisector of the angle between L and V)
If both the viewer and the light source are sufficiently far from the surface both the
V and L are Constant over the surface where H is constant for all the surface. Non polar
surface N.H requires less computation than the V.R. Since the calculation of R at each
surface point involves the variable vector N.
Combined Diffuse and Specular Reflection with Multiple Light Source:
A single point light source we can model the combined diffuse and specular
reflection from a point on an illuminated surface as
I = Idiff + Ispec
= KaIa + KdIl (N.L) + KsIl (N.H) ^ns
Equ 9, If we place more than one point source in a scene, we obtain
9 the light
reflection at any surface point by summing the contribution from the individual sources.
n
I=KaL + Σ Lli [Kad (N.Li) + Ks (N.Hi) ^ns]
10
i=1
To ensure that any pixel intensity does not exceed the maximum allowable value,
we can apply some type of normalization procedure. A simple approach is to set a
maximum magnitude for each term in the intensity equation.
Warn Model:
The warn model provides a method for simulating studio lighting effects by
controlling light intensity in different directions. Light sources are modeled as points on a
reflecting surface, using the phong model for the surface points. In addition, light controls
such as “barn doors” and spotlighting, used by studio photographers can be simulated in
the warn model.
Flaps are used to control the amount of light emitted by a source in various
directions. Two flaps are provided for each of the x, y and z directions. Spotlights are
used to control the amount of light emitted within a cone with apex at a point source
position. It is implemented in PHIGS model.
14.3 TO & 14.5 REFER DONALD HEARN BOOK
HALFTONE PATTERNS AND DITHERING TECHNIQUE:
Continuous-tone photographs are reproduced for publications in newspaper,
magazines and book with a printing process called half toning and the reproduced
pictures are called halftones. For a black and white background each intensity area is
reproduced as a series of black circles on a white background.
Diagram Refer book page 537
Halftone Approximations:
Halftone reproductions are approximated using rectangular pixel region called
halftone patterns or pixel patterns. The number of intensity levels that we can display
with this method depends on how many pixels we include in the rectangular grids and
how many levels a system can display. With n by n pixels for each grid on a bi-level
system, we can represent n^2+1 levels.
For any pixel grid size we can represent the pixel patterns for the various possible
intensities with a “mask” of pixel position numbers. E.g.: Mask can be used to generate
the nine 3 by 3 grid patterns for intensity levels above 0.
837
512
496
To display a particular intensity with level number k, we turn on each pixel whose
position number is less than or equal to k.
Although the use of n by n pixel patterns increase the number of intensities that
can be displayed, they reduce the resolution of the displayed picture by a factor of 1/n
along each of the x and y axes. The grid size can be used without distorting the intensity
variations depends on the size of a displayed pixel.
Pixel grid patterns for halftone approximations must also be constructed to
minimize contouring and other visual effects not present in the original scene. A grid
pattern with an single “on” pixel or one with isolated “on” pixels should be avoided.
Halftone approximations also can be used to increase the number of intensity
options on system that are capable of displaying more than two intensities per pixel.
(a)
(b)
(c)
(d)
(For a 3 by 3 pixel grid, pattern (a) is to be preferred to the patterns in (b) for representing
the third intensity level above 0)
Dithering Technique:
The term dithering is used in various context. It refers to techniques for
approximating halftone without reducing resolution as pixel grid patterns do. Random
values added tp pixel intensities to break up contours are often referred to as dither noise.
Ordered dither methods generate intensity variations with a one to one mapping of
points in a scene to the display pixels. To obtain n^2 intensity level, we see up an n by n
dither matrix Dn, whose elements are distinct positive integers in the range 0 to n^2-1.
D2 = 3 1
02
And we can generate nine intensity levels with
D3 = 7 2 6
401
385
The matrix elements for D2 and D3 are in the same order as the pixel mask for setting up
2 by 2 and 3 by 3 pixel grids, respectively. If the intensity I is to be applied to screen
position (x,y), we calculate row and column numbers for the dither matrix as
I= (x mod n) + 1, j=(y mod n ) +1
If I>Dn (i,j), we turn on the pixel at position (x,y). Otherwise the pixel is not
turned on. Typically the number of intensity levels is taken to be a multiple of 2. Higher
order dither matrices are then obtained from lower-order matrices with the recurrence
relation.
Dn = 4Dn/2 + D2 (1, 1) Un/2 4Dn/2 + D2 (1, 2) Un/2
4Dn/2 + D2 (2, 1) Un/2
4Dn/2 + D2 (2, 2) Un/2
Assuming n>4. Parameter Un/2 is the “unity” matrix (all elements are 1). As an example
if D2 is specified as recurrence relation
D4 =
15 7 13
3 11 1
12 4 14
0 8 2
5
9
6
10
Another method for mapping a picture with m by n points to a display area with m by n
pixel is error diffusion.
Algorithm Refer Book page 541
PROPERTIES OF LIGHT:
We perceive as “light”, or different colors are a narrow frequency band within the
electromagnetic spectrum. A few of the other frequency bands within this spectrum are
called radio waves, micro waves, infrared waves and x-rays.
Each frequency value within the visible band corresponds to a distinct color. At
the low frequency end is a red color (4.3+10^14 hertz), and the highest frequency we can
see is a violet color (7.5*10^14 hertz). Spectral colors range from the reds through orange
and yellow at the low frequency end to greens, blues and violet at the high ends.
Diagram refer Book page 585
E
t
λ
(Time variations for one electric frequency component of a plane polarized
electromagnetic
wave).
Since light is an electromagnetic wave, we can describe the various colors in terms
of either the frequency f or the wavelength λ of the wave. The wave length and frequency
of the monochromatic wave are inversely proportional to each other, with the
proportionality constant as the speed of light c;
C=λf
1 bulb emits all frequencies within the
A light source such as the sun or a light
visible range to produce white light. When white light is incident upon an object, some
frequencies are reflected and some are absorbed by the object.
If low frequencies are predominant in the reflected light, the object is described as
red. The perceived light has a dominant frequency at the red end of the spectrum. The
dominant frequency is also called the Hue or simply the color of the light.
Radiant energy is related to the luminance of the source. The second perceived
characteristic is the purity or saturation of the light. Purity describes how washed out or
how “pure” the color of the light appears. These three characteristic, dominant frequency,
brightness and purity are commonly used to describe the different properties we perceive
in a source of light.
Energy
Frequency
Red
White
(Energy distribution of a white light source)
The energy density of the dominant light component is labeled as Ed and the
contributes from the other frequencies produce white light of energy density Ew. Purity
depends on the difference between Ed and Ew. The larger the energy Ed of the dominant
frequency compared to the white-light component Ew. We have a purity of 100 percent
when Ew=0 and a purity of 0 percent when Ew=Ed.
If the two colors combine to produce white light they are referred to as
complementary colors.
Energy
Ed
Ew
Red
Frequency
Violet
Dominant Frequency
(Energy distribution of a light source with a dominant frequency near the red end of the
frequency range)
Colors models that are used to describe combinations of light in terms of
dominant frequency use three colors to obtain a reasonably wide range of colors called
the color gamut for that model. The two or three colors used to produce other colors in
such a color are referred to as primary colors.
Standard primaries and the chromaticity diagram:
The three standard primaries are imaginary colors. They are defined
mathematically with positive color matching functions that specify the amount of each
primary needed to describe any spectral color.
XYZ Color Model:
The set of CIE primaries is generally referred as the XYZ, or (X,Y,Z) color model
where X,Y and Z represent vectors in a three- dimensional, additive color space. Any
color Cλ is then expressed as.
Cλ = XX + YY + ZZ
2
Where X, Y, Z designate the amount of the standard primaries needed to match
Cλ. It is convenient to normalize the amount in luminance(X +Y+ Z). Normalized
amounts are thus calculated as
x= X
,y=
Y
,z=
Z
3
X+Y+Z
X+Y+Z
X+Y+Z
With X +y +z =1 , thus any color can be represented with just the x and y
amounts, Parameters x and y are called the chromaticity values because they depend only
on hue and purity. The remaining CIE amounts are then calculated as
X = x/y Y, Z = z/yY
Where z=1-x-y. Using chromaticity coordinates (x,y), we4 can represent all colors on a
two dimensional diagram
CIE Chromaticity Diagram:
When we plot the normalized amount x and y for colors in the visible spectrum,
we obtain the tongue shaped curve is called as the CIE Chromaticity Diagram.
Diagram Refer Book page 590
The line joining the red and violet spectral points called the purple line is mot part
of the spectrum. Interior point represents all possible visible color combinations. Point is
plotted for a white- light source known as illuminant C, which is used as standard
approximation for “average” daylight.
The chromaticity diagram is useful for the following.
(i) Comparing color gamut’s for different sets of primaries
(ii) Identifying complementary colors
(iii)Determining dominant wavelength and purity of a given color
The color gamut for three color points such as C3, C4, and C5 is a triangle with
vertices at the three color positions. Three primaries can only generate colors inside or on
the bounding edges of the triangle. When we mix proper amounts of the two colors C1
and C2 we can obtain white light. We can draw a straight line from C through C1 to
intersect the spectral curve at point’s color C1 can then be represented as a combination
of white light C and the spectral color C. Point C2 is referred to as a nonspectral color
and its dominant wavelength is taken as the compliment of Cp that lies on the spectral
curve (point Csp). Nonspectral colors are in the purple-magenta range and have spectral
distributions with subtractive dominant wavelengths.
Intuitive Color Concepts:
Starting with the pigment for a “pure color” the artist adds a black pigment to
produce different shades of that color. The more black pigment the darker the shade.
Different tints of the color are obtained by adding a white pigment to the original color,
making it lighter as more white is added. Tones of the color are produce by adding both
black and white pigments.
One model provides an intuitive color interface for the user and others described
the color components for the output devices.
RGB Color Model:
Based on the tristimulus theory of vision, our eyes perceive color through the
stimulation of three visual pigments in the cones of the retina. These visual pigments
have a peak sensitivity at wave length of about 630nm (red), 530nm (green) and 4450nm
(blue).
We can represent this model with the unit cube defined on R, G and B axes. The
origin represents black and the vertex with coordinates (1, 1, 1) is white. As with XYZ
color system, the RGB color scheme is an additive model. Intensities of the primary color
are added to produce other colors. Each color point within the bounds of the cube can be
represented as the triple (R, G, B), where values for R, G, B are assigned in the range
from 0 to 1. Cλ is expressed in RGB components as,
Cλ = RR + GG +BB
The magenta vertex is obtained by adding red, and blue to produce the triple
(1,0,1) and white at (1,1,1) is the sum of the red, green, and blue vertices.
Diagram Refer Book Page 592
White is represented as (0.5, 0.5, 0.5,) the color graduations along the front and
top planes of the RGB cube.
YIQ Color Model:
YIQ color model parameter Y is the same as in XYZ model. Luminance
information is contained in the Y parameter, while chromaticity information is contained
in the Y parameter while chromaticity information incorporated into I and Q parameters
A RGB signals can be converted to a television signal using NTSC encoder,
which converts RGB values to YIQ values, then modulates I and Q information on the Y
signals. Then the conversion of RGB into YIQ is,
Y
0.299 0.587 0.144
R
I
=
0.596 -0.275 -0.321
*
G
Q
0.212 -0.528 0.311
B
An NTSC video signal can be converted to an RGB signal using an NTSC
decoder, which separates the video signal into the YIQ components, then converts to
RGB values.
R
1.000 0.956 0.620
Y
G
=
1.000 -0.272 -0.647
*
I
B
1.000 -1.108 1.705
Q
CMY Color Model:
A color model defined with the primary color cyan, magenta and yellow (CMY) is useful
for describing color output to hard copy devices. In this model point (1,1,1) represents
black, because all components of the incident light are subtracted. The origin represents
white light. Equal amounts of each of the primary color produce grays, along the main
diagonal of the cube.
Printing process often used with the CMY model generates a color point with a collection
of four ink dots; Where RGB monitor uses a collection of three phosphor dots. We can
express the conversion from RGB represents to a CMY representation with the matrix
transformation.
C
M
Y
=
1
1
1
-
R
G
B
Where the white is represented in the RGB system as the unit column vector, We convert
from a CMY color representation to an RGB representation with the matrix
transformation
R
1
C
G
=
1 M
B
1
Y
Where black is represented in the CMY system as the unit column vector.
Conversion between HSV and RGB Models:
HSV color parameter are made available to a user of a graphics package, these
parameters are transformed into the RGB settings needed for the color monitor. Consider
HSV hex cone can be derived from RGB cube. The diagonal of this cube from black to
white corresponds to the V axis of the hexacone. RGB cube corresponds to hexagonal
cross sectional area of the hexacone V. Parameter S is the relative position of the point
within each hexagon.
Algorithm Refer Book Page 598
HLS Color Model:
This model base don intuitive color parameter is the HLS system used by
Tektronix. It is the double cone representation. The three color parameter in this model
are called hue (H), lightness (L) and saturation(S)
Hue has the same meaning as HSV it specifies the vertical axis that locates as
chosen Hue. H=0º corresponds to blue, magenta 60º, red 120º and cyan at H=180º.
Complementary 180º is part on the double cone.
The vertical axis in this model is called Lightness L at L=0 we have black and
white is at L=1. Gray scale is along the L axis and the “pure hues” lie on the L=0.5 plane.
Saturation parameter S again specifies relative purity of a color. This parameter varies
from 0 to 1, and pure hues are those for which S=1 and L=0.5. HSV model, HLS system
allows a user to think in terms of making a selected hue darker or lighter.
Diagram Refer Book Page 600
Color Selection and Applications:
Various combinations of colors can be selected using sliders and color wheels and
the system can be also being designed to aid in the selection of harmonizing colors.
If colors are selected at regular intervals along any straight line within the RGB or
CMY cube. Selection of color combinations is that different colors are perceived at
different depths. Displaying a blue pattern next to a red pattern can cause eye fatigue
because we continually need to refocus when our attention is switched from one area to
other.
The use of smaller number of colors produces a more display than a large number
of colors, tints, and shades blend better than pure hues.
 0
0
advertisement
Related documents
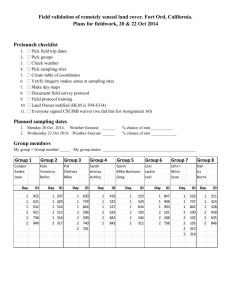

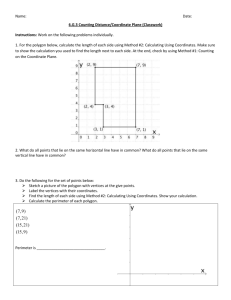





Download
advertisement
Add this document to collection(s)
You can add this document to your study collection(s)
Sign in Available only to authorized usersAdd this document to saved
You can add this document to your saved list
Sign in Available only to authorized users