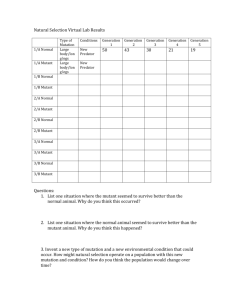
T test and ANOVA examples for filtering genes in
microarray experiments
T test
Here is part of a gene expression matrix (with log2 ratios relative to a reference). In
the first 5 arrays, the test sample comes from a normal mouse and in the 2nd 5 arrays,
the test sample comes from a mutant mouse:
Normal mice
Gene 1
Gene 2
………
Array
no. 1
0.46
0.15
…
Array
no. 2
0.30
0.74
…
Array
no. 3
0.80
0.04
…
Mutant mice
Array
no. 4
1.51
0.10
…
Array
no. 5
0.90
0.20
…
Array
no. 6
-0.10
-0.45
…
Array
no. 7
0.49
-1.03
…
Array
no. 8
0.24
-0.79
…
Array
no. 9
0.06
-0.56
…
Array
no.10
0.46
-0.32
…
We want to perform a two-sample T test on each gene to see if it is differentially
expressed between normal and mutant mice. [As mentioned, the 5 repeat experiments
with several arrays used to compare normal/mutant mouse RNA to a reference allow
us to distinguish, to some extent, between differences of intensity measurement due to
gene expression differences between normal and mutant mice and those due to other
factors such as a slightly defective array chip.] We start with gene 1:
We think of the row for gene 1 as consisting of two “samples”, in the statistical sense,
(ie. normal & mutant). We want to compare samples to see if they have equal means.
We test this hypothesis using a two-sample T test.
Recall that, when we have a sample of length m and another of length n, the Tstatistic follows a t-distribution with n+m-2 degrees of freedom and is given by
T
(X Y )
( X Y ) / ˆ jo int
.
2
2
1 1
nS X mSY
1 1
n m
nm2
n m
where ˆ jo int is an unbiased estimator for the standard deviation and has
computational formula:
n
ˆ jo int 2
nS X mSY
nm2
2
2
m
X i nX 2 Yi mY 2
2
1
1
nm2
2
.
Both of the samples have size 5, so we have m=n=5 and we are considering a tdistribution with 8 degrees of freedom.
The “division factor”
1 1
2
=
0.6325.
n m
5
1
Next we calculate the sample means:
Normal mice:
0.46
0.30
0.80
1.51
0.90
total 3.97
Mutant mice:
-0.10
0.49
0.24
0.06
0.46
1.15
mean 0.794
Difference between means = 0.564
0.23
Next we work out ˆ jo int by first computing the sums of squares.
n
The sums of squares for the normal mice,
X
2
i
, is
1
(0.46)2+(0.30)2+(0.80)2+(1.51)2+(0.90)2=4.0317.
Correction factor, nX 2 , to subtract to give n times normal sample variance also called
the sum of squared residuals
=5*(0.794)2=3.1522
The sums of squares for the mutant mice, is likewise 0.5229.
So
ˆ jo int 2
4.0317 5 * (0.794) 0.5229 5 * (0.23) 0.8795 0.2584 0.1422
and ˆ jo int =0.3771.
2
2
8
8
Thus our T statistic is given by 0.564/(0.3771*0.6325) = 2.365.
Suppose we want to test whether gene 1 is up-/ downregulated between normal and
mutant mice at 5% (often written as 95%) significance. We look up in T test table
under the t-distribution with 8 degrees of freedom for the value that the T statistic
would take at that confidence and find it is 2.306 (see table). Our T statistic exceeds
this and thus the mean of the mutant sample is different from the mean of the normal
sample at 5% significance. So our gene is significantly up-/ downregulated in mutant
mice. [In fact we can see that the P value is less than but close to 0.05].
[NB we are doing a two-tailed test here. The T statistic has probability 0.025 of
exceeding 2.306 by chance. It has an additional probability 0.025 of being less than
–2.306, since the t-distribution is symmetrical.]
2
Gene 2:
Likewise for gene 2, we have
0.15 0.74 0.04 0.1 0.2
0.246
5
0.45 1.03 0.79 0.56 0.32
0.63
Sample mean (mutant)=
5
Difference between means=0.876
Sample mean (normal)=
Division factor,
1 1
, =0.6325, as before.
n m
Sum of squares (normal)= 0.15 2 0.74 2 0.04 2 0.12 0.2 2 0.6217
Correction factor, nX 2 ,=5*(0.246)2=0.3026
Sum of squares (mutant)=
(0.45) 2 (1.03) 2 (0.79) 2 (0.56) 2 (0.32) 2 2.3035
Correction factor (mutant), mY 2 , =5*(-0.63)2 =1.9845
So the estimated standard deviation, ˆ jo int is given by
ˆ jo int
[0.6217 0.3026] [2.3035 1.9845]
0.3191 0.319
=0.2824
552
8
So our T statistic is given by
T=
0.876
=4.904.
0.6325 * 0.2824
Once again we are comparing with a t-distribution with 5+5-2=8 degrees of
freedom. If we test at (5% or in the notation of the table) 95% significance, there is
clearly a significant difference between the normal and mutant mice. If you look at
the T table it is clear that gene 2 has a P value that is <0.01 for the two-tailed T
test.
3
Analysis of variance (ANOVA)
We could just perform analysis of variance for each gene of the table above to test for
differences in means of the normal mouse and mutant mouse samples. We should get
the same answers as before for significance values, because ANOVA with two groups
is formally equivalent to the T test. However, to illustrate why we want to use
ANOVA, we will consider data from a second mutant type of mouse, which we will
call “double mutant”. We only manage to get three microarray experiments with
cDNA from this type of mouse.
Gene 1
Gene 2
………
Array
no. 11
-0.34
-1.02
…
Array
no. 12
0.56
-0.52
…
Array
no. 13
0.33
0.01
…
Analysis of variance for gene 1:
Data for gene 1:
Normal
0.46
0.30
0.80
1.51
0.90
Mutant
-0.10
0.49
0.24
0.06
0.46
Double mutant
-0.34
0.56
0.33
We need to calculate
1. the sum of squared residuals within groups
2. the sum of squared residuals between groups:
Group mean (X )
Sum of squares in group
nj
X ij 2
i 1
Sum of squared residuals
within group
nj
( X ij X ) 2
i 1
Normal
0.794
Mutant
0.23
Double mutant
0.1833
4.0317
0.5229
0.5381
0.8975
0.2584
0.4373
[The sum of squared residuals = sum of squares – correction factor].
4
Recall “sum of squares within” (actually means sum of squared residuals) is
SS w j 1 i j1 ( X ij X j ) 2 squared data Group size(group mean) 2
m
n
Normally the latter formula would be easier to use for computations, but we have
already worked out the individual group residuals. SSw is just the sum across groups
of the SS residual within the group, ie.
SS w =0.8975+0.2584+0.4373=1.5752.
Grand mean= (5*0.794+5*0.23+3*0.1833)/13=0.4362.
“Sum of squares between” is
SS B j 1 n j ( X j X ) 2 Group size(group mean) 2 N (Grand mean) 2
m
=5*(0.794)2+5*(0.23)2+3*(0.1833)2-13*(0.4362)2=1.0445.
We present the values of the statistics required to compute the F statistic in a table:
Sum of squared
residuals (SS)
Between samples
1.0445
Within samples
1.5752
Total
2.6197
[NB here m is no. of groups.]
Degrees of freedom Mean squared
(MS)
m-1=2
0.5223
N-m=10
0.1575
N-1=12
[Note that an alternative way of working out the within samples sum of squared
residuals is to work out the total and between samples SSs and subtract “between”
from “total”. This is because
2
2
2
i, j X ij X i, j X ij X j j n j X j X .
Using Total SS in the form
i, j
X ij NX 2 is usually the easiest way to compute
2
these numbers (if we hadn’t already done a T test).]
Thus the F statistic is given by
MSB Mean squared between 0.5223
=3.316.
F2,10
MSE
Mean squared within
0.1575
We are comparing with an f-distribution with degrees of freedom for the numerator
of 2 and degrees of freedom for the denominator of 10. From the table we see that
this is not significant at the 5% level (F value is 4.10). Thus at 5% significance the
genes do not vary across the three conditions. The P value is actually 0.079. If we
wanted to know specifically whether a gene varied between the two mutant types, then
we would have to perform pairwise T tests (or ANOVA) on the data.
[NB the ANOVA F test is two-tailed.]
5
Computational formulae:
Total Sum of Squared Residuals j,i X ij NX 2
2
Within Groups SS residuals j,i X ij j n j X j
2
2
Between Groups SS residuals j n j X j NX 2
2
6
 0
0