ScaLAPACK notes
advertisement

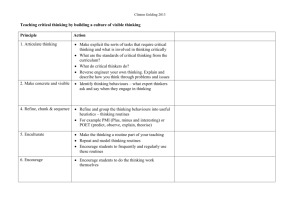
High Performance Computing B, 2009 ScaLAPACK Notes In the lecture on Nov. 17 an introduction to ScaLAPACK was started. It is a bit difficult to find good material and example programs on the web, but links to the ScaLapack user guide and a few other documents are at the end of these notes A program using ScaLapack will run in several processes (often each process runs on its own processor), and should be run with mpirun. These notes assume that all matrices are double precision general dense (as for Blas/Lapack, routines also exist for single precision and complex, and triangle, tridiagonal, and band matrices are also supported). Using ScalaPACK There are four steps involved in using ScaLapack: 1. Create a logical process grid. This is a p by q array of processes, layed out as shown here for the case p = 2 and q = 4: Let the process in row i and column j of the grid be Pij. To initialize a process grid, from Fortran, use: call sl_init(context, p, q) where context is an integer variable returning a so-called context handle which is used to refer to the created grid in subsequent ScaLAPACK calls. When called from C, use the call: sl_init_(&context, &p, &q); i.e. decorate and pass all arguments by reference (see sections 3 and 6 of Assignment 2). In later steps it will be necessary to know which process is current, and this information may now be obtained, with: call blacs_gridinfo(context, p, q, myrow, mycol). (cf. MPI_Comm_rank). If the process is Pij then myrow returns i and mycol returns j. If the current process is not part of the context, myrow will return –1. 2. Distribute matrices and vectors on the process grid. A matrix is partitioned into MB by NB blocks (recommended block sizes 32 32, 64 64 or possibly 128 128). The first q blocks in the top block row are mapped to the top row of the process grid in order, the next q blocks in the top row are also mapped to these same processes and so on. Similarly the second block row is mapped to the second grid row etc. When row p + 1 is reached, the mapping returns back to the first grid row. This is the same mapping as checkerboard partitioning explained briefly on p. 356 in the text book. To each process belongs a local matrix with a non-contiguous portion of the global matrix. Here is an illustration from Jack Dongarra: 1 We see, for instance, that P02 holds blocks from block rows 1, 3, 5, 7 and block columns 3 and 6. Before going further, matrix descriptors, to be used in subsequent calls, must be created. To create a descriptor for an M N matrix use: call descinit(desc, M, N, MB, NB, 0, 0, context, llda, info) Here desc returns the descriptor (which should be a 9 element integer vector) and info returns 0 if all went well (otherwise, if info = –i, then the i-th argument had a bad value). The other arguments have already been described, except for llda, which (on entry) specifies the leading dimension of the local matrix. The 0's (arguments 6 and 7) actually say that the matrix starts in P00 (it can start elsewhere). The function numroc, described below, may be used to find the number of rows and columns which the current local matrix must be able to hold. The maximum row count over all the processes is ceil(ceil(M/MB)/p)*MB. There are now several ways to create and distribute the matrix. To name a few: (a) Each local matrix may be created in its process from scratch (b) The global matrix may be read from file by one process and then distributed in pieces (c) The global matrix may be created in one of the processes, and then distributed to all the rest of them (d) Each process can read its portion of the matrix from file (e) The matrix may be assembled in small pieces (as in finite element updating), each time sending updates to the relevant process. One reason for avoiding (b) or (c) would be that the global matrix is too big to fit into the memory of a single process. ScaLapack comes with two example programs, no. 1 uses (a) and no. 2 uses (b). There are also several programs available to distribute the matrix. Maybe the simplest is to follow (c) and distribute with the routine pdgemr2d, described below, and in more detail in the ScaLapack User’s Guide (see the section Matrix Redistribution/Copy Routines; once there select Next a few times). Other possibilities include broadcasting the whole matrix to all the proceessors with dgebs2d/dgebr2d, or sending each local matrix (or block) to its process with dgesd2d/dgerv2d (the routine names are mnemonic for double general-matrix broadcast-send 2-dimensional, …broadcast-receive…, …send… and …receive…). More information on these routines is in the Reference to BLACS routines on netlib.org/blacs. Some other useful routines are pdelset (that finds where aij of the global matrix is in the local one) and numroc (that calculates dimensions of the local matrix). A summary of these distribution routines is given below. 3. Call ScaLAPACK routine. Most Blas and Lapack routines have corresponding ScaLapack routines with a P prefixed (e.g. DGEMV → PDGEMV or DPOTRF → PDPOTRF). The Blas and Lapack routines are designed to work on submatrices. An M N submatrix of a matrix A, with leading dimension lda, having aij in the top left corner (i.e. A(i:i+M-1,j:j+N-1) in Matlab notation), is identified with 4 arguments in Blas/Lapack: M, N, A(i,j), lda. ScaLapack can also work on submatrices. It uses 6 arguments: M, N, Aloc, i, j, descA (where Aloc is the local matrix and descA its descriptor). The whole (global) matrix A will be specified in Blas/Lapack with M, N, A, lda but in ScaLapack with M, N, Aloc, 1, 1, descA. See also Jack Dongarra’s overview of ScaLapack. Vectors in Blas/Lapack are given by 3 arguments. An N elelment subvector of a column in the matrix A starting at aij, i.e. A(i:i+N-1,j), is: N, A(i,j), 1, and if it is a subvector of a row, A(i,j:j+N-1), it is N, A(i,j), lda. In ScaLapack these become N, A, i, j, descA, 1 and N, A, i, j, descA, lda respectively. Whole vectors in Blas/Lapack are specified with N, X, 1, and in ScaLapack they are stored in the same way as N by 1 matrices and specified with N, X, 1, 1, descX, 1. Result matrices may have to be transferred back from individual local matrices to a master process that uses the results or writes them to file, using the transfer functions discussed in step 2 above. 4. Release the process grid. Two routines are used after finishing calculation. A particular process grid is released with blacs_gridexit, and after all computation is finished, blacs_exit should be called. A typical calling sequence is: call blacs_gridexit(context) call blacs_exit(0) 2 Summary of distribution routines for dense matrices The following will copy A(iA:iA+M-1,jA:jA+N-1) to B(iB:iB+M-1,jB:jB+N-1): call pdgemr2d(M,N,Aloc,iA,jA,descA,Bloc,iB,jB,descB,context) Here A and B are global matrices, Aloc, and Bloc, are local matrices, and context is a process grid that covers all parts of either A or B. If a whole global matrix is to be distributed, use the call: call pdgemr2d(M,N,A,1,1,descA,Bloc,1,1,descB,context) (where A is a contained on a 1 1 process grid with block sizes MB = M and NB = N). A process that is not a part of the context of A should set descA(2) to –1, and similarly for B. The call: pdelset(Aloc, i, j, descA, alpha) sets the (i, j)-entry in the global matrix, A(i,j), to alpha. The call has no effect except in the process where Aloc contains A(i,j). There is also a pdelget routine, slightly more complicated to use. Contrary to many of the routines discussed so far, the following routines do not use the concepts of global and local matrices, and no matrix descriptors are involved. The calls: dgesd2d(context, M, N, A, lda, drow, dcol) dgerv2d(context, M, N, A, lda, srow, scol) are used to send a matrix (or submatrix) from process Psrow,scol (the source) to process Pdrow,dcol (the destination). Normally the calls will be inside if-statements, restricting the send operation to the source process and the receive operation to the destination, for example: if (myrow==srow .and. mycol==scol) dgesd2d(context, M, N, A, lda, drow, dcol) if (myrow==drow .and. mycol==dcol) dgerv2d(context, M, N, A, lda, srow, scol) To send a submatrix A(i:i+M-1, j:j+N-1), use dgesd2d(context,M,N,A(i,j),lda,drow,dcol) . M*N must be the same for sending and receiving, but a reshape is allowed, for instance dgesd2d(ctxt, 8, 1, A, 8, 3, 5) dgerv2d(ctxt, 2, 4, B, 2, 0, 0) The calls: dgesd2d(context, 'ALL', ' ', M, N, A, lda) dgerv2d(context, 'ALL', ' ', M, N, A, lda, srow, scol) are used to broadcast a matrix from Psrow,scol to all the other processes in the specified context. The third argument controls the so-called topology of the broadcast (space gives the default), and the remaining arguments are as for dgesd2d/dgesrv2d. It is also possible to broadcast to a row or a column in the process grid (using 'ROW' or 'COLUMN' as the second argument). The function numroc may be used to find the dimensions of the local matrices (of the parts actually holding data, in case they are declared bigger than needed). The calls needed to find the row and column counts are: nrows = numroc(M, MB, myrow, 0, p) ncols = numroc(N, NB, mycol, 0, q) where the parameters are as described earlier. The 0's given as fourth argument, correspond to the 0's used in the call to descinit shown earlier. 3 Compiling and running ScaLAPACK programs Assume that the Scalapack, Blacs, and Lapack/Blas libraries are called libscalapack.a, libblacs.a and libgoto2.a, and that they all reside in folders pointed to by the shell variable LIBRARY_PATH. Assume also that the MPI being used has an mpif90 command that is on the Unix path. Note that some versions of MPI require that the shell variable LD_LIBRARY_PATH points to the MPI lib folder (where the MPI-libraries are). This can be set up in the shell initialization file (e.g. .bashrc). The following commands can now be used to compile, link and run a ScaLapack program ex1.f needing a 4 4 process grid: mpif90 -o ex1 ex1.f -lscalapack -lblacs -lgoto2 mpirun -np 16 ex1 If a C program is used to call ScaLapack, the following commands may be needed (or better): mpicc -c ex1.c mpif90 -o ex1 ex1.o -lscalapack -lblacs -lgoto2 mpirun -np 16 ex1 On Sól there are ScaLapack, Blacs and Lapack/Blas libraries in /data/users/jonasson/lib, named as indicated above, and MPI should already work. Thus one can add the line: export LIBRARY_PATH=/data/users/jonasson/lib:$LIBRARY_PATH to ones .bashrc file and subsequently compile as shown above. If Torque must be used to run parallel jobs (as is the case on Sól), then one must place the mpirun command in a Torque script and submit that with qsub. References (links) ScaLAPACK User’s Guide (several authors): www.netlib.org/scalapack/slug Overview of ScaLAPACK (Jack Dongarra): www.netlib.org/utk/people/JackDongarra/pdf/over-scalapack.pdf A User's Guide to the BLACS v1.1 (Jack Dongarra & Clint Whaley): http://www.netlib.org/blacs/lawn94.ps Reference to BLACS routines (extract from the guide): http://www.netlib.org/blacs/BLACS/QRef.html PBLAS Home Page: http://www.netlib.org/scalapack/pblas_qref.html Example Program #1 from the ScaLAPACK User’s Guide: http://www.netlib.org/scalapack/examples/example1.f 4