Word template
advertisement

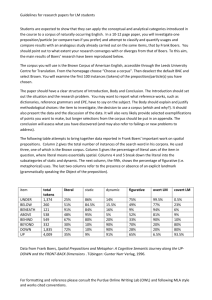
Comparison of Performance of Enhanced Morpheme-Based Language Model with Different Word-based Language Models for Improving the Performance of Tamil Speech Recognition System S. SARASWATHI Pondicherry Engineering College, Puducherry, India AND T.V. GEETHA College of Engineering, Anna University, Chennai, India. ________________________________________________________________________ This paper describes a new technique of language modeling for a highly inflectional Dravidian language, Tamil. It aims to alleviate the main problems encountered in processing of Tamil language, like enormous vocabulary growth caused by the large number of different forms derived from one word. The size of the vocabulary was reduced by, decomposing the words into stems and endings and storing these sub word units (morphemes) in the vocabulary separately. A enhanced morpheme-based language model was designed for the inflectional language Tamil. The enhanced morpheme-based language model was trained on the decomposed corpus. The perplexity and Word Error Rate (WER) were obtained to check the efficiency of the model for Tamil speech recognition system. The results were compared with word-based bigram and trigram language models, distance based language model, dependency based language model and class based language model. From the results it was analyzed that the enhanced morpheme-based trigram model with Katz back-off smoothing effect improved the performance of the Tamil speech recognition system when compared to the word-based language models. Categories and Subject Descriptors: I 2.7 [Artificial Intelligence] – Natural language processing -– Speech recognition and synthesis. General Terms: Design, Performance Additional Key Words and Phrases: Language model, morphemes, perplexity, word error rate and speech recognition ACM File Format: SARASWATHI, S., AND GEETHA, T.V. 2007. Comparison of performance of enhanced morpheme-based language models with different word-based language models for improving the performance of Tamil speech recognition system. ACM Trans. Asian Language. Inform. Process., 6, 3, Article 9 (November 2007), 19 pages. DOI = 10.1145/1290002.1290003 http://doi.acm.org/10.1145/1290002.1290003 ________________________________________________________________________ 1. INTRODUCTION Automatic speech recognition has been the goal of researchers for many years and it has a long history of being a difficult challenge. Early research in speech recognition attained acceptable performances only by imposing constraints in the task domain such as speaker __________________________________________________________________________________________ Authors’ addresses: S. Saraswathi, Department of Computer Science and Engineering and Information Technology, Pondicherry Engineering College, Puducherry, India. E-mail: swathimuk@yahoo.com; T.V. Geetha, Department of Computer Science and Engineering, College of Engineering, Anna University, Chennai, India; E-mail : rctamil@annauniv.edu Permission to make digital/hard copy of part of this work for personal or classroom use is granted without fee provided that the copies are not made or distributed for profit or commercial advantage, the copyright notice, the title of the publication, and its date of appear, and notice is given that copying is by permission of the ACM, Inc. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Permission may be requested from the Publications Dept., ACM, Inc., 2 Penn Plaza, New York, NY 11201-0701, USA, fax: +1 (212) 869-0481, permission@acm.org © 2001 ACM 1530-0226/07/0900-ART9 $5.00 DOI 10.1145/1290002.1290003 http://doi.acm.org/10.1145/ 1290002.1290003 ACM Trans. Asian Language Information Processing, Vol. 6, No. 3, Article 9, Pub. date: November 2007. 9 9: 2 ● S. Saraswathi and T.V. Geetha Table II. Trigram perplexity results for different values of 1 and 2 Trigram perplexity 1 2 News Corpus Politics Corpus 0.1 0.9 251.11 302.34 02 0.8 240.33 299.1 0.3 0.7 221.26 291.03 0.4 0.6 209.3 286.7 0.5 0.5 197.2 282.3 0.6 0.4 180.1 270.1 0.7 0.3 150.23 261.31 0.8 0.2 126.98 226.04 0.9 0.1 140.1 240.1 Table III. Results of Bigram and Trigram Models Bigram Trigram Corpus OOV Perplexity WER Perplexity WER News 4.5 147.02 14.1 126.98 13.8 Politics 9.2 234.73 28.6 226.04 25.04 It was found that for values of 1 =0.8 and 2 = 0.2 improved perplexity and word error rate (WER) results were obtained for both bigram and trigram as shown in table III. The WER values was evaluated as WER (Subs Dels Ins) * 100 % No.Of words incorrect sentence where Subs – No.of wrong words substituted in the recognized text. Dels – No. of correct words deleted in the recognized text Ins – No. of new words inserted in the recognized text The perplexity values evaluated for the test data were high for the politics corpus than the news corpus. This was due to the small vocabulary size and high OOV words in the politics corpus, when compared to the news corpus. The number of unigrams, bigrams and trigrams were high for both the corpora. The performance of the speech recognition system was further enhanced by the use of distance based language model, dependencybased language model, class-based language model and enhanced morpheme-based language model as discussed in the next section. 4. DISTANCE-BASED LANGUAGE MODEL In any natural language a word is not only related to its immediate neighbors but also on distant words. Therefore a model that deals with the concept of distance is used. For ngram model, the history h is made of n-1 preceding words. It assumes that the word to predict depends on its history as a single block. Language modeling is thus reduced to a single relation between two components: the word to predict and its entire history. For example if we consider the following sentence, “The book I bought is brown”, “book” is ACM Trans. Asian Language Information Processing, Vol. 6, No. 3, Article 9, Pub. date: November 2007. Comparison of Morpheme-Based Language Model with Different Word-based models ● 9: 3 35 30 WER 25 20 New s corpus Politics corpus 15 10 5 tri gr e am ba di se st d an bi ce de gr ba pe am se nd d en tri cy de gr pe ba am nd se en d bi cy gr ba am se cl d as tri gr s ba en am se ha cl d nc as bi ed gr s ba m am en or se ha ph d nc em tri ed gr e a m ba m or se ph d m bi e gr ba am se d tri gr am di st an c bi gr am 0 language models Fig. 4. Comparison of WER values obtained for news and politics corpora for different language models when compared to the other language models. The comparison of the perplexity and WER values in the different language models is shown in figures 3 and 4. There is a significant reduction in perplexity and WER for the news corpus when compared with the politics corpus. The main reason for this was due to the corpora used in the training set. The news corpus has more data for training the language model than the politics corpus. The size of the news text corpus used for training purpose was 40% higher than the size of the politics text corpus used for training. The OOV rate of news corpus is lower than the political corpus. The perplexity values are also less for the news corpus when compared to the politics corpus. Bigram and trigram form the base for statistical language models. Trigram-based language model gave improved perplexity and WER values over the bigram model. Improvements were done on the n-grams to consider the words that were even n-1 position away from them. This led to the design of distance based language models, whose performance showed only a slight improvement when compared to n-grams because of the free word order characteristics of Tamil language. A sentence in Tamil can be represented by different ways, changing their word order. Hence this led to the design of linguistic based language models for Tamil speech recognition system. The dependency based language model showed improved results than the n-gram approaches. This is due to the following limitations that exist in the dependency model. The performance of dependency model is limited to projective dependency grammar although certain constructions in Tamil are non-projective in nature. The dependency relations are limited to relations between heads and their dependents, whereas a more distance relation has to be taken into account for improving the performance of the model. The class based model showed greater improvement than the bigram- and trigram-based language model. For limited domain speech recognition class-based models gave good results. But for larger domain the class-based model generated too many n-grams that do not take into account the relations inherent in the vocabulary. The branching factor is more at these points in predicting the word sequences that led to inaccurate word predictions. The variation in perplexity with respect to WER is shown in figure 5. It is found that there is a drastic change in the perplexity values obtained for different language models, with the highest value for the bigram language model and the lowest for the enhanced morpheme based trigram language model. However, the change that occurs in WER ACM Trans. Asian Language Information Processing, Vol. 6, No. 3, Article 9, Pub. date: November 2007. 9: 4 ● S. Saraswathi and T.V. Geetha recognition performance for the two Tamil corpora. The results have shown that the proposed enhanced morpheme-based language model is much better than the word-based language models. The future scope of this work is to test this technique on large test sets from various domains to prove their robustness. REFERENCES ALI, A.M.A. 1998. Segmentation and Categorization of Phonemes in Continuous Speech. Technical Report TRCST25JUL98, Center for Sensor Technology, University of Pennsylvania. ALI, A.M.A., VANDER SPIEGEL, J., MUELLER, P., HAENTJENS, G., AND BERMAN, J. 1999. An Acoustic-Phonetic feature based system for Automatic Phoneme Recognition in Continuous Speech. In IEEE Proceedings of the International Symposium on Circuits and Systems (ISCAS), 3, 118-121. ALI, A.M.A. 2001. Acoustic–Phonetic Features for the Automatic Classification of Stop Consonants. IEEE Trans. Speech and Audio Processing, 9(8), 833-841. ANANDAN, P., GEETHA, T.V., AND PARATASARATHY, R. 2001. Morphological Generator for Tamil, In Proceedings of the Tamil Inayam Conference, Malaysia, 46-54. ANANDAN, P., SARAVANAN, K., PARTASARATHI, R., AND GEETHA, T.V. 2002. Morphological Analyzer for Tamil. In Proceedings of ICON2002, 3-10. ARDEN, A.H. REV. AND CLAYTON, A. C. 1969. A Progressive Grammar of the Tamil Language, Christian Literature Society, Madras. AVERSANO, G., ESPOSITO, A., ESPOSITO, A., AND MARINARO, M. 2001. A new Text Independent Method for Phoneme Segmentation. In Proceedings of IEEE International Workshop on Circuits and Systems, 2, 516519. AVERSANO, G., ESPOSITO, A., AND CHOLLET, G., 2003. A JAVA interface for speech analysis and segmentation. In Proceedings of the ISCA tutorial and Research Workshop on Non-linear Speech Processing (NOLISP03), Le Croisic , France, Paper. 026. BROWN, P., PIETRA, S,.DELLA PIETRA, V., AND MERCER, R. 1993. The mathematics of statistical machine translation: Parameter estimation’, Computational Linguistics, 19(2), 263-311. BYRNE, W., HACIC, J., IIRCING, P., JELINEK, F., KHUDANPUR, S., KRBEC,.P., AND PSUTKA, J. 2001. On large vocabulary continuous speech recognition of highly inflectional language – Czech. In Proceedings of Eurospeech 2001, Aalborg, Denmark, 487-489. CHOUDHURY, M. 2003. Rule based grapheme to phoneme mapping for Hindi speech synthesis, presented in 90th Indian Science Congress of ISCA, Bangalore (http://www.mla.iitkgp.ernet.in/ papers/G2Phindi.pdf. ) COLLIN, M. J. 1996. A new statistical parser based on lexical dependencies. In Proceedings of the 34th Annual Meeting of the Association for Computational Linguistics, 184-191. CREUTZ, M., AND LAGUS, K. 2002. Unsupervised discovery of Morphemes. In Proceedings of workshop on Morphological and Phonological Learning of ACL 2002, 21-30. FRANZ, M., AND MCCARLEY, S. 2002. Arabic information retrieval at IBM, In Proceedings of TREC 2002, 402405. GAO, J., AND SUZUKI, H. 2003. Unsupervised learning of dependency structure for language modeling. In Proceedings of ACL-2003, 7-12. HUCKVALE, M., AND FANG, A. C. 2002. Using phonologically constrained Morphological Analysis in Speech Recognition. Computer Speech and Language, 165-181. KNEISSLER, J., AND KLAKOW, D. 2001. Speech recognition for huge vocabularies by using optimized sub-word units. In Proceedings of Eurospeech 2001, 69-72. LAFFERTY, J., SLEATOR , D., AND TEMPERLEY, D., 1992. Grammatical Trigrams: A probabilistic model of link grammars, In Proceedings of AAAI Fall Symposium on Probabilistic Approaches to Natural LanguagI Issued as technical report CMU-CS-92-181. LAFFERTY, S. AND SUHM, B. 1995. Cluster Expansion and Iterative scaling of Maximum Entropy Language Models. In Hanson, K., Silver, R. (Eds) Maximum Entropy and Bayesian Methods, Kluwer Academic Publishers, Norwell, MA. Received May 2007; accepted July 2007 ACM Trans. Asian Language Information Processing, Vol. 6, No. 3, Article 9, Pub. date: November 2007.