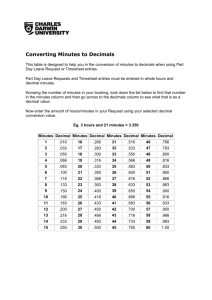
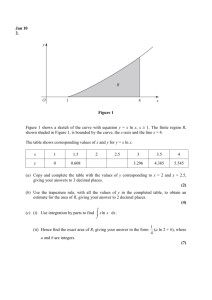
Problems and Answers for Chapter 1 Suppose I want to know which
advertisement

Problems and Answers for Chapter 1 1. Suppose I want to know which type of cola American adults like better, Fizzy Fizz Cola or Snappy Syrup Cola. Fizzy Fizz is a little more bubbly, Snappy Syrup is a little more sweet. So I set up a table in the student union on the university campus where I work in California. I set up 100 little sample cups and fill 50 of them with Fizzy Fizz and 50 of them with Snappy Syrup. I give a sample of each soda to the first 50 people 18 years or older that stop at my table and ask them to rate how much they liked each cola on a scale from 1 to 5, with higher numbers indicating greater enjoyment of the cola. They do not know which cup contains which type of cola. I find that people gave Fizzy Fizz an average rating of 3.00 and gave Snappy Syrup an average rating of 4.00. Question 1A: What is the dependent variable in this study? A: Type of cola B: 50 adults C: The university campus in California D: Ratings of how much participants liked the cola Question 1B: What is the independent variable in this study? A: Type of cola B: 50 adults C: The university campus in California D: Ratings of how much participants liked the cola Question 1C: What is the sample in this study? A: Type of cola B: The 50 adults who participated in the study C: American adults D: The location of the study Question 1D: What is the population in this study? A: Type of cola B: The 50 adults who participated in the study C: American adults D: The location of the study Question 1E: Was the sample used in the study a random sample? A: Yes, because the participants were not selected by the researcher; they came to him. B: Yes, because anyone could have come to the table been included in the study. C: No, because people in other parts of the country had a lower chance of being in the study. D: No, because the participants joined the study in an orderly way. Question 1F: Which of the following is the best example of an extraneous variable in this study? (Remember: an extraneous variable needs to fulfill two conditions. First, it must not have been included in the study. Second, it must plausibly explain the results found in the study). A: Age, because older American adults like sweeter colas. B: Location, because the study was conducted in California. C: Sampling method, because the sample was random. D: Age, because younger American adults like sweeter colas. Question 1G: What type of variable was the independent variable in this study? A: Nominal/Categorical B: Interval/Ratio C: Ordinal Answers for Chapter 1 Question 1 Question 1A: Question 1B: Question 1C: Question 1D: Question 1E: Question 1F: Question 1G: D A B C C D A 2. I want to know if there is any truth to the old saying “Ignorance is Bliss” among Californians. I talk to 50 people in my three college classes, 25 who watch the news every day and 25 who don’t. I ask them to rate their average happiness on a scale of 1 to 10, 1 being “I am miserable” and 10 being “Life is great!” The average score of the daily news addicts is 3.5 while the average of those who could care less is 5.5. Question 2A: What is my independent variable? A: 50 college students B: Level of happiness C: Whether or not news is watched daily. D: Place where news is watched. Question 2B: What is my dependent variable? A: 50 college students B: Level of happiness C: Whether or not news is watched daily. D: Place where news is watched. Question 2C: What is the sample in this study? A: People in California B: The campus where this study took place. C: Types of news programs D: The 50 students in my study. Question 2D: What is the population in this study? A: People in California B: The campus where this study took place. C: Types of news programs D: The 50 students in my study. Question 2E: Was the sample randomly selected? A: Yes, because anyone who raised his/her hand could have been included in my study. B: Yes, because the study was conducted in three different classes. C: No, because people in other parts of the state and not of college age were not given the opportunity to participate. D: No, because college students are never happy. Question 2F: Of the following, which is the best example of an extraneous variable that might have affected my results? A: Age, because college students can?t cope with bad news as well as older or younger people . B: Sampling method, because everyone in California had an equal chance of participating. C: Age, because college students don?t read the news as much as older people. D: Location, because the study was done in Northern California. Question 2G: What type of variable was the dependent variable in this study? A: Nominal/Categorical B: Interval/Ratio C: Ordinal Answers for Chapter 1, Question 2 Question 2A: Question 2B: Question 2C: Question 2D: Question 2E: Question 2F: Question 2G: C B D A C A B Problems and Answers for Chapter 2 1. Suppose that I have a sample of three 2-year-old children. I measure their heights (in inches) and find that the children are 32, 33, and 39 inches tall. A. What is the mean of this distribution? Step 1: Sum (i.e., add) the scores together. Step 2: Divide this sum by the number of scores. (Round your answer to 2 places after the decimal.) B. What is the median of this distribution of scores? Step 1: Arrange the scores in order, from smallest to largest. (Please separate the scores with a comma.) Step 2: Find the middle score in this distribution. C. Why is the median smaller than the mean in this distribution? A: Because the three scores are roughly equal. B: Because there is an outlier at the high end of the distribution. C: Because there is an outlier at the low end of the distribution. D: The mean is not higher than the median. D. Suppose that instead of three 2-year-olds I have a sample of 10. Their heights, in inches, are: 32, 33, 34, 35, 37, 39, and 40 inches tall. What is/are the mode(s) of this distribution? Step 1: Find the score(s) that occur most frequently. E. What is the median of the distribution of scores presented in Question D above? Step 1: Because there is an even number of scores in the distribution find the two numbers in the middle. (Please separate the scores with a comma.) Step 2: Find the average of these two scores. (Round your answer to 1 place after the decimal.) 30, 31, 32, Answers for Chapter 2 Question 1 A: Step 1: 32+33+39 = 104 Step 2: 104/3 = 34.67 B: Step 1: 32,33,39 Step 2: 33 C: Answer: B D: Step 1: 32 E: Step 1: 33,34 Step 2: (33+34)/2 = 33.5 2. I have collected a sample of three college basketball players and questioned them about their eating habits. I find that the players consume 2900, 3100, and 1800 calories each day. A. What is the mean of this distribution? Step 1: Find the sum of these scores. Step 2: Divide the scores by the number of people in my sample. B. What is the median of this distribution? Step 1: Arrange the scores in order, from smallest to largest. (Please use a comma to separate the scores.) Step 2: Find the middle score in the distribution. C. Why is the median larger than the mean in my sample? A: Because there are too many scores in the sample? B: Because there is an outlier at the low end of my distribution? C: There is no reason for this. D: Because there is an outlier at the high end of my distribution? D. Now that I am interested in learning more about the eating habits of basketball players, I decide a larger study is necessary. This time I collect a sample of twelve college players and find the following amounts of daily caloric intake: 3500, 2850, 3200, 1700, 2000, 2500, 2650, 3200, 2400, 2000, 2150, and 3000. What is/are the mode(s) of this distribution? Step 1: Find the score(s) that occur(s) most frequently. (Please separate the scores with a comma if there is more than one score.) E. What is the median of the twelve players’ scores? Step 1: Arrange the calories from smallest to largest.(Please separate the scores with a comma.) Step 2: Because there are an even number of scores, find the two scores that mark the center of this distribution. (Please separate the scores with a comma.) Step 3: Find the average of these two scores. Answers for Chapter 2 Question 2 A: Step 1: 7800 Step 2: 2600 B: Step 1: 1800, 2900, 3100 Step 2: 2900 C: Answer: B D: Step 1: 2000, 3200 E: Step 1: 1700, 2000, 2000, 2150, 2400, 2500, 2650, 2850, 3000, 3200, 3200, 3500 Step 2: 2500, 2650 Step 3: 2575 Problems and Answers for Chapter 3 1. Calculating a standard deviation of a population Suppose that I want to determine the standard deviation in the years of education of all the members of my immediate family. My immediate family includes my mother, my father, my brother, and myself. This group of individuals represents a population. Our years of education are: 12, 16, 19, and 22. What is the standard deviation of this population? Step 1: Calculate the mean of this population. Begin by summing the scores. Step 2: Divide the sum in Step 1 by 4: (Round your answer to 2 places after the decimal.) Step 3: Calculate a deviation score for each case in the population. (Round your answer to 2 places after the decimal.) Step 4: Square each deviation score. (Round your answer to 2 places after the decimal.) Step 5: Sum the squared deviation scores. (Round your answer to 2 places after the decimal.) Step 6: Divide by the number of scores in the population (N = 4). (Round your answer to 2 places after the decimal.) Step 7: Find the square root of the result from Step 6.(Round your answer to 1 place after the decimal.) Answers to Chapter 3 Question 1 Step 1: 69 Step 2: 69/4 = 17.25 Step 3: 12-17.25=-5.25 16-17.25=-1.25 19-17.25= 1.75 22-17.25= 4.75 Step 4: (-5.25)2 = 27.56 (-1.25)2 = 1.56 ( 1.75)2 = 3.06 ( 4.75)2 = 22.56 Step 5: 27.56 + 1.56+ 3.06 + 22.56 = 54.74 Step 6: 54.74/4 = 13.69 (Note: This is the variance) Step 7: 13.69^0.5 = 3.7 2. Calculating a standard deviation of a sample Suppose that I only knew the years of education for three of the four members of my immediate family: my brother, my mother, and myself. Our years of education are 12, 16, and 19. These three scores represent the scores of a sample. What is the standard deviation of this sample? Step 1: Calculate the mean of this sample. Begin by summing the scores. Step 2: Divide the sum in Step 1 by 3: (Round your answer to 2 places after the decimal.) Step 3: Calculate a deviation score for each case in the sample. (Round your answer to 2 places after the decimal.) Step 4: Square each deviation score. (Round your answer to 2 places after the decimal.) Step 5: Sum the squared deviation scores. (Round your answer to 2 places after the decimal.) Step 6: Divide by the number of scores in the sample minus 1 (n - 1 = 2). (Round your answer to 2 places after the decimal.) Step 7: Find the square root of the result from Step 6. (Round your answer to 2 places after the decimal.) Answers Chapter 3 Question 2 Step 1: 47 Step 2: 47/3 = 15.67 Step 3: 12-15.67 = -3.67 16-15.67 = 0.33 19-15.67 = 3.33 Step 4: (-3.67)2 = 13.47 ( 0.33)2 = 0.11 ( 3.33)2 = 11.09 Step 5: 13.47 + 0.11 + 11.09 = 24.67 Step 6: 24.67/2 = 12.34 (Note: This is the variance) Step 7: 12.340.5 = 3.51 3. Calculating the range of a sample Suppose that you are conducting a study of the self-esteem of American adults. You collect data from a sample of 5 adults by giving them a paper-and-pencil assessment of self-esteem. The scores of the five individuals on the self-esteem measure are 65, 43, 72, 81, and 22. What is the range of this sample? Step 1: Arrange the scores in order from the smallest to the largest. (Please separate the scores with a comma.) Step 2: Subtract the smallest score from the largest score. Answers Chapter 3 Question 3 Step 1: 22, 43, 65, 72, 81 Step 2: 81-22 = 59 4. Calculating a standard deviation of a population I want to know the standard deviation in the number of tricks my family’s pet dogs can perform. I collect data from all five of our dogs and find the number of tricks they can each complete: 1, 4, 5, 7, and 11. What is the standard deviation of this population? Step 1: Calculate my population mean. First, add up all the scores. Step 2: Divide the sum by the number of dogs in my population.(Round your answer to 1 places after the decimal.) Step 3: Calculate a deviation score for each dog in the population. (Round your answer to 1 places after the decimal.) Step 4: Square each deviation score: (Round your answer to 2 places after the decimal.) Step 5: Find the sum of the squared deviation scores. (Round your answer to 1 places after the decimal.) Step 6: Divide by the number of scores in the population (N=5). (Round your answer to 2 places after the decimal.) Step 7: Find the square root of the answer in step six. This is the standard deviation. (Round your answer to 2 places after the decimal.) Step 8: Now that I know the standard deviation, what can I say about these dogs and their tricks? A: On average, each dog can perform 3.32 tricks. B: There is a 3.32% chance that each dog can perform a single trick. C: The average difference between each dog?s individual score and the population mean is 3.32 tricks. D: The average number of tricks each dog can perform increases by 3.32 each year. Answers Chapter 3 Question 4 Step 1: 28 Step 2: 5.6 Step 3: -4.6, -1.6, -.6, 1.4, 5.4 Step 4: 21.16, 2.56, .36, 1.96, 29.16 Step 5: 55.2 Step 6: 11.04 Step 7: 3.32 Step 8: C 5. Calculating a standard deviation of a sample Suppose that I only knew the scores of three of my family’s dogs. These are the dogs that can do 1, 5, and 7 tricks. What is the standard deviation of this sample? Step 1: Calculate my sample mean. Begin by adding up all the scores. Step 2: Divide this answer by the number of scores in my sample. (Round your answer to 2 places after the decimal.) Step 3: Calculate a deviation score for each dog in the sample. (Round your answer to 2 places after the decimal.) Step 4: Square each deviation score. (Round your answer to 2 places after the decimal.) Step 5: Add up these deviation scores. (Round your answer to 2 places after the decimal.) Step 6: Divide by the number of scores in the sample minus 1 (n-1=2). (Round your answer to 2 places after the decimal.) Step 7: Find the square root of this number to get your sample standard deviation. (Round your answer to 2 places after the decimal.) Step 8: Now that you know the standard deviation of this sample, what can you conclude? A: Dogs can, on average, perform 3.06 more tricks than cats. B: The average difference between an individual dog?s score in my sample and the mean of the sample is 3.06 tricks. C: On average, the dogs in my sample performed 3.06 tricks each. D: Dogs learn more tricks when they are puppies. Answers Chapter 3 Question 5 Step 1: Step 2: Step 3: Step 4: Step 5: Step 6: Step 7: Step 8: 13 4.33 -3.33, .67, 2.67 11.09, .45, 7.13 18.67 9.34 3.06 B 6. Calculating the range of a sample Imagine you are conducting a study on romance novel interest among adult women in the United Kingdom. You ask a group of 7 random women how many romance novels each one reads per month. The women report reading 12, 5, 6, 2, 24, 10, and 4 books per month on average. What is the range of this data? Step 1: Arrange the scores in order from the smallest to the largest. (Please separate the scores with a comma.) Step 2: Subtract the smallest score from the largest score. Answers to Chapter 3, Question 6 Step 1: 2, 4, 5, 6, 10, 12, 24 Step 2: 22 Problems and Answers for Chapter 4 1. 2. 3. 4. 5. What are the three characteristics of the normal distribution? a. Bell shaped, bimodal, symptotic b. Bell shaped, unimodal, symptotic c. Bell shaped, unimodal, asymptotic d. L-shaped, unimodal, asymptotic Why is the normal distribution important? a. Because in descriptive statistics it helps us calculate probabilities. b. Because we can use it to determine the probability of events occurring in the population based on sample statistics. c. Because the ends intersect with the X axis. d. Because the probability of getting a normal distribution of scores from sample data depend on the method of selecting the sample. Why is the normal distribution called a theoretical distribution? a. Because it is only normal if we use the appropriate theory to test it. b. Because it represents a theoretical distribution of values, not an empirical set of values. c. Because it is based on a large population. d. Because it was developed in association with regression theory. Suppose that I want to know the average height of students at my university. I figure that a large crosssection of students use the gym facilities so I will collect my data from students at the gym. I like to play basketball, so I decide to use basketball players only in my sample. I measure the height of 20 students playing basketball and find the average height of my sample to be 6 feet 4 inches. Critics of my study complain that my sample does not represent the population of students at the university. They say my sample is… a. Normal b. Representative c. Theoretical d. Biased What does asymptotic mean? a. The subject is ill but not showing any symptoms yet. b. The left tail of the normal distribution curve crosses the X axis at zero. c. The shape of the normal distribution is as tall as it is wide. d. The tails of the normal distribution curve never intersect with the X axis. 6. What is the best description of the distribution of scores presented in the graph below? A. The distribution is normal. B. The distribution is negatively skewed. C. The distribution is positively skewed. D. The distribution is theoretical. Answers Chapter 4 1. C 2. B 3. B 4. D 5. D 6. C Problems and Answers for Chapter 5 1. Suppose that I select a random sample of 50 adult men from California and find that they drink an average of 35 colas a year, with a standard deviation of 6. One of the men from my sample only drinks 30 colas a year. What will his z score be? Step 1: Subtract the mean from the individual score: Step 2: Divide by the standard deviation: (Round your answer to 2 places after the decimal.) 2. Suppose that I know that in the population of Americans the average IQ score is 100 with a standard deviation of 15 (round your answer to 2 places after the decimal). A. What score would mark the 75th percentile? Step 1: Find the z score at which 25% of the scores fall beyond (in Appendix A): Step 2: Plug the z score that you found in Step 1 into the formula: X = 100 + (15)(z). Now multiply the z score by the standard deviation and enter the product below. Step 3: Add this product to the mean. B. Using the same population data from the previous problem, find the numbers that mark the extreme 10% of the distribution (round your answer to 3 places after the decimal). Step 1: Find the z score at which 5% of the score fall beyond (in Appendix A): Step 2: Plug the z score that you found in Step 1 into the formula: X = 100 +/- (15)(z). Now multiply the z score by the standard deviation and enter the product below. Step 3: Add this product to the mean. Step 4: Subtract this product from the mean. Answers Chapter 5 Question 1 Step 1: 30-35 = -5 Step 2: -5/6 = -0.83 Answers Chapter 5 Question 2 A: Step 1: 0.67 Step 2: 15 * 0.67 = 10.05 Step 3: 100 + 10.05 = 110.05 B: Step 1: 1.645 Step 2: 15 * 1.645 = 24.675 Step 3: 100 + 24.675 = 124.675 Step 4: 100 - 24.675 = 75.325 3. Suppose that I select a random sample of 50 ten-year-olds in the United States and find that they play outdoors an average of 4 hours a day with a standard deviation of 1.2. One particularly active youngster named Mary is outside an average of 6 hours each day. A. What will her z score be? Step 1: Subtract the mean from the individual score. Step 2: Divide by the standard deviation. (Round your answer to 2 places after the decimal.) B. What percentage of children play outside more often than Mary? Step 1: Find the area beyond Mary’s Z-score in Appendix A. (Round your answer to 4 places after the decimal). Step 2: Convert this answer to a percentage. (Round your answer to 2 places after the decimal.) Answers Chapter 5 Question 3 A: Step 1: 2 Step 2: 1.67 B: Step 1: .0475 Step 2: 4.75% 4. Suppose I know that the average person drinks 3 glasses of water each day with a standard deviation of .8. (Round all your answers to 2 places after the decimal) A. What score would mark the 90 percentile? Step 1: Find the z-score at which 10% of the scores fall beyond (Using Appendix A). Step 2: Using the formula z = 3 + (.8) (z), multiply the z-score by the standard deviation. Step 3: Add this product to the mean. B. Using the same population data from the problem above, find the numbers that mark the extreme 5% of the distribution. Step 1: Find the z-score at which 2.5% of scores fall beyond (Using Appendix A). Step 2: Using the formula z = 3 + (.8) (z), multiply the z-score by the standard deviation. Step 3: Add this product to the mean. Step 4: Subtract this product from the mean. Answers Chapter 5 Question 4 A: Step 1: 1.28 Step 2: 1.02 Step 3: 4.02 B: Step 1: 1.96 Step 2: 1.57 Step 2: 4.57 Step 2: 1.43 Problems and Answers for Chapter 6 1 A. Suppose I selected a random sample of 400 Americans from the population. The population has a mean of 100 with a standard deviation of 15. What is the probability that this sample will have a mean IQ of 102? Step 1: Compute the standard error: (Round your answer to 2 places after the decimal.) Step 2: Calculate the z score: (Round your answer to 2 places after the decimal.) Step 3: Find the area beyond z associated with this z score in Appendix A: (Round your answer to 4 places after the decimal.) B. What is the probability of finding a sample mean between 98 and 101 (again with a sample size of 400)? Step 1: Use the standard error found in the previous problem: (Round your answer to 2 places after the decimal.) Step 2: Calculate the z score for the sample mean of 101: (Round your answer to 2 places after the decimal.) Step 3: Calculate the z score for the sample mean of 98: (Round your answer to 2 places after the decimal.) Step 4: In Appendix A, find the proportion for the area between the mean and the z score of 1.33: (Round your answer to 4 places after the decimal.) Step 5: In Appendix A, find the proportion for the area between the mean and the z score of -2.67: (Round your answer to 4 places after the decimal.) Step 6: Add the two proportions together: (Round your answer to 4 places after the decimal.) Answers Chapter 6 Question 1 A: Step 1: 15/(400^0.5) = 15/20 = 0.75 Step 2: (102 - 100)/0.75 = 2/0.75 = 2.67 Step 3: .0038 B: Step 1: .75 Step 2: (101 - 100)/.75 = 1/.75 = 1.33 Step 3: (98 - 100)/.75 = -2/.75 = -2.67 Step 4: .4082 Step 5: .4962 Step 6: .4082 + .4962 = .9044 2. Suppose that using a random sample of 15 adult men I find an average shoe size of 10 with a standard deviation of 4. Construct a 95% confidence interval around the mean. Step 1: Find the degrees of freedom: Step 2: Calculate the standard error: (Round your answer to 2 places after the decimal.) Step 3: Find the t value for a 95% 2-tailed test with 14 degrees of freedom (from Appendix B): (Round your answer to 3 places after the decimal.) Step 4: Multiply the standard error by the t value: (Round your answer to 2 places after the decimal.) Step 5: Add this product to the mean: (Round your answer to 2 places after the decimal.) Step 6: Subtract this product from the mean: (Round your answer to 2 places after the decimal.) Step 7: Wrap words around these values: I am 95% confident that the interval between ___________ and ____________ contains the population mean. (Round your answer to 2 places after the decimal.) Answers Chapter 6 Question 2 Step 1: 15 - 1 = 14 Step 2: 4/(150.5) = 4/3.87 = 1.03 Step 3: 2.145 Step 4: (1.03)(2.145) = 2.21 Step 5: 10 + 2.21 = 12.21 Step 6: 10 - 2.21 = 7.79 Step 7: between 7.79 and 12.21 3 Suppose I know that in the population of six-year-old girls in Australia, the average girl has 12 dolls with a standard deviation of 4. From this population, I collect a random sample of 100 girls. A. What is the probability that my sample will have a mean of 13? Step 1: Calculate the standard error. (Round your answer to 1 places after the decimal.) Step 2: Find the z score. (Round your answer to 1 places after the decimal.) Step 3: Look in Appendix A to find the area beyond z associated with this z score. (Round your answer to 4 places after the decimal.) B. What is the probability of finding a sample mean between 11 and 12.5 (again with a sample size of 100)? Step 1: Use the same standard error you found in the previous problem. (Round your answer to 1 place after the decimal.) Step 2: Calculate the z score for the sample mean of 11. (Round your answer to 1 place after the decimal.) Step 3: Calculate the z score for the sample mean of 12.5.(Round your answer to 2 places after the decimal.) Step 4: Using Appendix A, find the area between the mean and a z score of –2.5. (Round your answer to 4 places after the decimal.) Step 5: Using Appendix A, find the area between the mean and a z score of 1.25. (Round your answer to 4 places after the decimal.) Step 6: Add the two proportions together. (Round your answer to 4 places after the decimal.) Answers Chapter 6 Question 3 A: Step 1: .4 Step 2: 2.5 Step 3: .0062 B: Step 1: .4 Step 2: -2.5 Step 3: 1.25 Step 4: .4938 Step 5: .3944 Step 6: .8882 4. Suppose that I collect a random sample of 25 cats and find that they sleep an average of 14 hours each day with a standard deviation of 3. Calculate a 99% confidence interval around the mean. Step 1: Find the degrees of freedom: Step 2: Calculate the standard error: (Round your answer to 1 places after the decimal.) Step 3: Look in Appendix B to find the t-value for a 99% Confidence interval. (2-tailed, 24 degrees of freedom) (Round your answer to 3 places after the decimal.) Step 4: Using the formula CI99= 14 +/- (t) (standard error), multiply your t value with your standard error from steps 2 and 3. (Round your answer to 2 places after the decimal.) Step 5: Add this product to the mean. (Round your answer to 2 places after the decimal.) Step 6: Subtract this product from the mean. (Round your answer to 2 places after the decimal.) Step 7: Wrap words around your answer. I am 99% positive that the interval between ___________ and _____________ contains the population mean. OR. . I am 99% positive that the population of cats sleeps between __________ and __________ hours each day. (Round your answer to 2 places after the decimal.) Answers Chapter 6 Question 4 Step 1: 24 Step 2: .6 Step 3: 2.797 Step 4: 1.68 Step 5: 15.68 Step 6: 12.32 Step 7: between 12.32 and 15.68 Problems and Answers for Chapter 7 1. Suppose that you have conducted an independent samples t test to determine whether men and women differ in enjoyment of a new movie. The movie is a romantic comedy called Isn’t Love Funny? The studio that produced the movie needs to know how to best market it, so they want to know who is most likely to enjoy the movie. You have been hired to do the research for them. You showed the movie to a random sample of 100 men and a random sample of 100 women. On a scale of 1 to 10, with 10 indicating that viewers loved the movie, you found that the average score for men in your sample was 6.50 and the average score for women was 7.25. The standard error of the difference between the means was .25 (i.e., Smean(x1)-mean(x2)= .25). The movie studio has two questions for you: Is this a statistically significant difference? What is the effect size for this result? Step 1: Calculate the observed t value (Round your answer to 2 places after the decimal.) Step 2: Determine the degrees of freedom for this t test. Step 3: Using Appendix B, find the critical t value that is closest to, but does not exceed, the observed t value. Step 4: Select the statement below that best describes the statistical significance of the observed t value. A. There is no significant difference between men and women. B. The difference between men and women is significant at the p < .001 level. C. The difference between men and women is significant at the p < .01 level. D. The difference between men and women is significant at the p < .05 level. Step 5: Calculate the effect size for this result. Step 5a: Calculate the difference between the two sample means. Step 5b: Calculate the standard deviation of the difference between the means. Step 5c: Calculate the effect size. Answers to Chapter 7, Problem 1 Step 1: (6.50 – 7.25)/.25 = -3.00 Step 2: 100 + 100 – 2 = 198 Step 3: 2.576 in the ∞ row of the table Step 4: C Step 5a: 6.50 – 7.25 = -.75 Step 5b: s = (100)0.5 * .25=10 * .25=2.5 Step 5c: d = |-.75 / 2.5 |=.3 2. Suppose that I am a kindergarten teacher. Everyday, shortly after lunch, the 30 children in my class take a short nap. I want to know if these children are happier after naptime. One afternoon, I ask the children to rate their level of happiness, on a scale of 1 to 10 before and after their naps. I find that, on average, the children?s happiness level is 6.5 pre-nap and 8.5 post-nap. The standard error of the difference between the means was .8 (i.e., Smean(x1)-mean(x2)= .8). A. Is this a 1-tailed or a 2-tailed test? 1. 1-tailed 2. 2-tailed B. Are the results statistically significant? Step 1: Calculate the observed t value (Round your answer to 2 places after the decimal.) Step 2: Determine the degrees of freedom for this t test. Step 3: Using Appendix B, find the critical t value that is closest to, but does not exceed, the observed t value. Step 4: Select the statement below that best describes the statistical significance of the observed t value. A. There is no significant difference between pre- and post-nap happiness. B. Children are significantly happier post-nap at the p < .001 level. C. Children are significantly happier post-nap at the p < .01 level. D. Children are significantly happier post-nap at the p < .05 level. C: Calculate the effect size for this result. Step 1: Calculate the difference between the two sample means. Step 2: Calculate the standard deviation of the difference between the means. Step 3: Calculate the effect size. Answers to Chapter 7, Problem 2 A. A B. Step 1: -2.50 Step 2: 29 Step 3: 2.462 Step 4: B C. Step 1: -2 Step 2: 4.38 Step 3: .46 3. Suppose that I want to know the average weight, in ounces, of babies born in the United States this year. I select a random sample of 49 newborn babies and find that they have an average weight of 110 ounces, with a standard deviation of 14. Please construct a 95% confidence interval around this sample mean. Step 1: Calculate the standard error of the mean. Step 2: Find the critical value of t for a 95% confidence interval and 48 degrees of freedom from Appendix B. Step 3: Plug the values into the formula for calculating a confidence interval. Step 4: Do the math and report the two numbers (i.e., the lower and upper values) of the confidence interval. Lower Value: Upper Value: Answers to Chapter 7, Problem 3 Step 1. Step 2. Step 3. Step 4. 2 2.021 CI95 = 110 ± (2.021)(2) The lower value is 105.96, the upper value is 114.04 4. Using the same information from the previous problem, please calculate a 99% confidence interval for the mean. Step 1: Find the critical value of t for a 99% confidence interval and 48 degrees of freedom from Appendix B. Step 2: Plug the values into the formula for calculating a confidence interval. Step 3: Do the math and report the two numbers (i.e., the lower and upper values) of the confidence interval. Lower Value: Upper Value: Answers to Chapter 7, Problem 4 Step 1. 2.704 Step 2. CI95 = 110 ± (2.704)(2) Step 3. The lower value is 104.59, the upper value is 115.41 5. Why is the interval between the two numbers slightly larger for the 99% confidence interval than it is for the 95% confidence interval? A. Because to increase your confidence that the interval contains the population mean, the interval must be wider. B. Because if the population mean is actually larger than the sample mean you need a wider interval to capture it. C. Because bigger is usually better. 6. Why do we need to calculate a confidence interval anyway? What does it do for you? A. It allows you to make a good estimate about the true value of your sample mean. B. It allows you to provide, with a certain degree of confidence, a range that captures the actual population mean. C. It allows you to make a good guess about the actual value of the population mean. D. It allows you to combine the sample mean and the population mean into a single number. Answer Chapter 7 Problems 5 and 6 Answer to Problem 5: A Answer to Problem 6: B Problems and Answers for Chapter 8 1. Suppose that among a random sample of 100 American adults there is a correlation of r=.35 between the number of hours spent watching television per week and weight (in pounds). Is this a statistically significant correlation? A. Using the formula on p.86 calculate the observed t value. To do this you will first need to find three values: Step 1: The correlation coefficient, r =(Round your answer to 2 places after the decimal.) Step 2: The sample size, N= Step 3: The correlation coefficient squared: r squared = (Round your answer to 2 places after the decimal.) Step 4: Calculate the numerator of the equation: N-2= Step 5: Calculate the denominator of the equation: 1-(r squared) = (Round your answer to 2 places after the decimal.) Step 6: Solve the fraction: (Round your answer to 2 places after the decimal.) Step 7: Take the square root of the value found in Step 6: (Round your answer to 2 places after the decimal.) Step 8: Multiply the value from Step 7 by the correlation coefficient: (Round your answer to 2 places after the decimal.) B. Find the critical t value using Appendix B. Step 1: Determine the degrees of freedom. N-2= Step 2: Select an alpha level: Step 3: Determine whether this is a 1-tailed or a 2-tailed test: Step 4: Using the conservative estimate of 60 degrees of freedom in Appendix B find the critical t value for an alpha level of .05: (Round your answer to 3 places after the decimal.) Step 5: Using the conservative estimate of 60 degrees of freedom in Appendix B find the critical t value for an alpha level of .01: (Round your answer to 3 places after the decimal.) C. Determine whether this is a statistically significant correlation coefficient. Step 1: Compare the observed t value to the two critical t values and determine which values are higher than which other values: (Round your answer to 2 places after the decimal.) _____________________ is higher than either of the two critical values. Step 2: Is this a statistically significant correlation: (answer "Yes" or "No") Step 3: At what level of probability: (Round your answer to 2 places after the decimal.) Answers chapter 8 question 1 A: Step 1: r = 0.35 Step 2: N = 100 Step 3: r squared = .12 Step 4: N-2 = 98 Step 5: 1-(r squared) = 0.88 Step 6: 98/0.88 = 111.36 Step 7: Square root of 111.36 = 10.55 Step 8: 10.55 * 0.35 = 3.69 B: Step 1: N-2 = 98 Step 2: 0.05 or 0.01 Step 3: 2-tailed Step 4: 2.000 Step 5: 2.660 C: Step 1: 3.69 Step 2: Yes Step 3: p < 0.01 2. Suppose I want to know whether there is a correlation between length of time spent exercising per day and level of happiness. I select a random sample of 50 adults and find a correlation of r = .27. Are my results statistically significant? A. Calculate your observed t-value. Step 1: Find your correlation coefficient: (Round your answer to 2 places after the decimal.) Step 2: Find your sample size: Step 3: Calculate the numerator of the equation (N-2): Step 4: Find the square of your correlation coefficient: (Round your answer to 2 places after the decimal.) Step 5: Calculate the denominator of the equation: 1-(r squared): (Round your answer to 2 places after the decimal.) Step 6: Solve the fraction using the answers you found in steps 3 and 5. (Round your answer to 2 places after the decimal.) Step 7: Take the square root of the value found in Step 6:(Round your answer to 2 places after the decimal.) Step 8: Multiply this answer with the correlation coefficient (Round your answer to 2 places after the decimal.) B. Find the critical T-Value using Appendix B. Step 1: Calculate the degrees of freedom (N-2): Step 2: Is this a 1-tailed or 2-tailed test? A. 1-tailed B. 2-tailed Step 3: Using the conservative estimate of 40 degrees of freedom find the critical t value in Appendix B for an alpha level of .10. (Round your answer to 3 places after the decimal.) Step 4: Again, using the conservative estimate of 40 degrees of freedom find the critical t value in Appendix B for an alpha level of .05. (Round your answer to 3 places after the decimal.) C. Compare your observed t value with these critical t values to determine significance. Step 1: Is my observed t-value larger than the critical t value for an alpha level of .10? A. Yes B. No Step 2: Is my observed t-value larger than the critical t value for an alpha level of .05? A. Yes B. No Step 3: At what level of probability do my results have statistical significance? (Round your answer to 2 places after the decimal.) D. Wrap words around these results. Step 1: In the population of adults, there is a relationship between amount of time spent exercising per day and levels of happiness. Due to the level of probability that produced statistical significance, I am willing to be wrong percent of time in this conclusion (Based on alpha level). Answers Chapter 8 Question 2 A: Step 1: .27 Step 2: 50 Step 3: 48 Step 4: .07 Step 5: .93 Step 6: 51.61 Step 7: 7.18 Step 8: 1.94 B: Step 1: 48 Step 2: B Step 3: 1.684 Step 4: 2.021 C: Step 1: A Step 2: B Step 3: .10 D: Step 1: 10 Problems and Answers for Chapter 9 1. Suppose you want to know whether men and women differ in their average intelligence levels. You randomly select 16 men and 16 women and collected data about their intelligence (IQ scores). The men had an average IQ score of 93 with a standard deviation of 12. The women had an average IQ score of 97 with a standard deviation of 15. Using an alpha level of .05, determine whether this is a statistically significant different? Step 1: Are you going to do a 1-tailed or a 2-tailed test? Step 2: What will the degrees of freedom be for this test? Step 3: What will the critical value of t be? (Round your answer to 3 places after the decimal.) Step 4: Calculate and report the standard error of the differences between the means. Step 4.1: First find the standard error of the mean for group 1. Step 4.2: Find the standard error of the mean for group 2.(Round your answer to 2 places after the decimal.) Step 4.3: Square each of the standard errors of the mean and add them together. (Round your answer to 2 places after the decimal.) Step 4.4: Take the square root of the summed squared standard errors. This is the standard error of the difference between the means. (Round your answer to 2 places after the decimal.) Step 5: Calculate the observed t value.(Round your answer to 2 places after the decimal.) Step 6: Make a decision. Is the difference between the sample means statistically significant? (Please answer "Yes" or "No".) Step 7: Summarize your results. Which of the following options bests summarizes these results? A. In the populations of men and women, men are more intelligent than women, on average. B. In the populations of men and women, women are more intelligent than men, on average. C. In the populations of men and women, there is no difference in average levels of intelligence. D.There is not enough information to make a decision about the differences between men and women. Answers Chapter 9 Question 1 Step 1: 2-tailed Step 2: 16 + 16 - 2 = 30 Step 3: 2.042 Step 4.1: 3 Step 4.2: 3.75 Step 4.3: 23.06 Step 4.4: 4.80 Step 5: t = 93-97/4.80 = -.83 Step 6: No Step 7: C 2. Compute a 99% confidence interval to capture the difference between the population means. Step 1: Identify the t value to be used in this confidence interval: (Round your answer to 2 places after the decimal.) Step 2: Multiply the t value by the standard error: (Round your answer to 2 places after the decimal.) Step 3: Add and subtract 13.20 from -4.00, which is the difference between the sample means. (Round your answer to 3 places after the decimal.) Add 13.20 to -4.00 : _______ Subtract 13.20 from -4.00 :________ Step 4: Summarize your results. A. The difference between the sample means is contained within the interval from -17.20 to 9.20. B. The difference between the population means is contained within the interval from -17.20 to 9.20. C. I am 99% confident that the difference between the sample means is contained within the interval from -17.20 to 9.20 D. I am 99% confident that the difference between the population means is contained within the interval from -17.20 to 9.20 Answers Chapter 9 Question 2 Step 1: 2.75 Step 2: 2.75 * 4.80 = 13.20 Step 3: Add -4.00 + 13.20 = 9.20 ; Step 4: D Subtract -4.00 - 13.20 = -17.20 3. Calculating a standard error of the difference between two independent sample means when sample sizes are equal or roughly equal: A researcher wants to determine whether dogs and cats differ in the average number of hours each type of pet sleeps during a 24-hour period. She selects a random sample of 25 cats and finds that, on average, this sample sleeps 19 hours a day with a standard deviation of 4 hours. The researcher also selects random sample of 25 dogs and finds that this sample sleeps an average of 16 hours a day with a standard deviation of 6 hours. What is the standard error of the difference between the sample means? Step 1: Calculate the standard error of the mean for the cat sample. (Round your answer to 2 places after the decimal.) Step 2: Calculate the standard error of the mean for the dog sample. (Round your answer to 2 places after the decimal.) Step 3: Square the standard error of the mean for the cat sample. (Round your answer to 2 places after the decimal.) Step 4: Square the standard error of the mean for the dog sample. (Round your answer to 2 places after the decimal.) Step 5: Sum the two squared standard errors. (Round your answer to 2 places after the decimal.) Step 6: Find the square root of the summed squared standard errors. (Round your answer to 2 places after the decimal.) Answers Chapter 9 Question 3 Step 1: 4 / (25)0.5 = .80 Step 2: 6 / (25)0.5 = 1.20 Step 3: (0.80)2 = .64 Step 4: (1.2)2 = 1.44 Step 5: .64 + 1.44 = 2.08 Step 6: (2.08)0.5 = 1.44 4. Suppose I want to know whether monkeys in the wild are more social than their relatives in zoos. I collect a random sample of 31 wild monkeys and 31 zoo monkeys. The monkeys in the wild have an average of 35 social interactions per day with a standard deviation of 6. The monkeys in the zoo have an average of 30 social interactions per day with a standard deviation of 4. Using an alpha level of .01, are my results statistically significant? Step 1: Is this a one-tailed or two-tailed test? A. One-tailed B. Two-tailed Step 2: What are my degrees of freedom for this test? Step 3: What is my critical t-value? (Round your answer to 3 places after the decimal.) Step 4: Calculate the standard error of the differences between the means. Step 4.1: Begin by finding the standard error of the mean for the wild monkey group. (Round your answer to 2 places after the decimal.) Step 4.2: Now find the standard error of the mean for the zoo monkey group. (Round your answer to 2 places after the decimal.) Step 4.3: Next square each standard error of the mean and add them together. (Round your answer to 2 places after the decimal.) Step 4.4: Finally, take the square root of the summed squared standard errors. This is the standard error of the differences between the means. (Round your answer to 1 place after the decimal.) Step 5: Calculate the observed t-value. (Round your answer to 2 places after the decimal.) Step 6: Based on your calculations, are my results statistically significant? A. Yes B. No Step 7: Interpret what you have discovered. What do these results mean? A. In the populations of wild monkeys and zoo monkeys, wild monkeys have more social interactions. B. In our sample, monkeys in the zoo are more social than monkeys in the wild. C. In the populations of zoo monkeys and wild monkeys, zoo monkeys have more social interactions. D.There is no significant difference between the populations of zoo and wild monkeys. Answers Chapter 9 Question 4 Step 1: A Step 2: 60 Step 3: 2.390 Step 4.1: 1.08 Step 4.2: .72 Step 4.3: 1.69 Step 4.4: 1.3 Step 5: 3.85 Step 6: A Step 7: A 5. Compute a 95% confidence interval around the differences between the population means. Step 1: Find the appropriate t value for this problem (using Appendix B). (Round your answer to 3 places after the decimal.) Step 2: Multiply this number by the standard error of the difference between the means. (Round your answer to 1 place after the decimal.) Step 3: Find the difference between the sample means: Step 4: Add the number found in step 2 with the difference between the sample means. Step 5: Subtract the number found in step 2 from the difference between the sample means. Step 6: Wrap words around what you’ve found. A. The difference between the sample means is contained in the interval from 2.4 to 7.6. B. The difference between the population means is contained in the interval from 2.4 to 7.6. C. I am 95% confident that the difference between the population means is contained in the interval from 2.4 to 7.6. D. I am 95% confident that the difference between the sample means is contained in the interval from 2.4 to 7.6. Step 7: Now that you understand the statistical way of saying what you have found, what does this mean? A. I am 95% confident that our sample of wild monkeys has a mean of 2.4 to 7.6 more social interactions per day than zoo monkeys. B. Zoo monkeys have 2.4 to 7.6 more social interactions per day than wild monkeys. C. Zoo monkeys are more social. D. I am 95% confident that the population of wild monkeys has a mean of 2.4 to 7.6 more social interactions per day than zoo monkeys. Answers Chapter 9 Question 5 Step 1: Step 2: Step 3: Step 4: Step 5: Step 6: Step 7: 2.000 2.6 5 7.6 2.4 C D 6. Calculating a standard error of the differences between two independent sample means when the samples are of the same size. Suppose you want to know if people who work outdoors and people who work indoors differ in their levels of job satisfaction. You select a random sample of 15 adults who work outdoors and find that their average level of job satisfaction (on a scale of 1 to 10) is 7.5 with a standard deviation of 2. You also sample 15 adults who work indoors and find their average level of job satisfaction to be 6 with a standard deviation of 2.5. What is the standard error of the difference between the sample means? Step 1: Calculate the standard error of the mean for the sample of outdoor workers. (Round your answer to 2 places after the decimal.) Step 2: Now do the same for your sample of indoor workers. (Round your answer to 2 places after the decimal.) Step 3: Square the standard error of the mean for the outdoor workers sample. (Round your answer to 2 places after the decimal.) Step 4: Square the standard error of the mean for the indoor workers sample. (Round your answer to 2 places after the decimal.) Step 5: Sum these two values together. (Round your answer to 2 places after the decimal.) Step 6: Find the square root of the summed squared standard errors. (Round your answer to 2 places after the decimal.) Answers Chapter 9 Question 6 Step 1: Step 2: Step 3: Step 4: Step 5: Step 6: .52 .65 .27 .42 .69 .83 Problems and Answers for Chapter 10 1. Suppose I want to know whether there are differences in the sizes of hogs raised in Arkansas, Oklahoma, and Iowa. I select a random sample of two adult hogs from each state and weigh them. I get the following data. Arkansas: 600 lbs. and 700 lbs. Oklahoma: 800 lbs. and 1000 lbs. Iowa: 300 lbs. and 400 lbs. Are there statistically significant differences in the weights of the hogs raised in three states? To find out perform a one-way analysis of variance (ANOVA). Step 1. Calculate the sum of squared deviations within groups (SS w or SSe). Step 1a: Find the mean for each group. For Arkansas: _______________ For Oklahoma: _______________ For Iowa: ___________________ Step 1b: Find the within-group deviation score for each hog. For Arkansas, hog 1: _______________ For Arkansas, hog 2: _______________ For Oklahoma, hog 1: _______________ For Oklahoma, hog 2: _______________ For Iowa, hog 1: ________________ For Iowa, hog 2: ________________ Step 1c: Square each deviation score. For Arkansas, hog 1: _______________ For Arkansas, hog 2: _______________ For Oklahoma, hog 1: _______________ For Oklahoma, hog 2: _______________ For Iowa, hog 1: ________________ For Iowa, hog 2: ________________ Step 1d: Find the sum of the squared deviations. Step 2. Calculate the sum of squared deviations between groups (SS b). Step 2a: Calculate the grand mean for the entire sample. (Round your answer to 2 places after the decimal.) Step 2b: Calculate the deviation score for each group. (Round your answer to 2 places after the decimal.) For Arkansas: _____________ For Oklahoma: ____________ For Iowa: ________________ Step 2c: Square each deviation score. (Round your answer to 2 places after the decimal.) For Arkansas: _____________ For Oklahoma: ____________ For Iowa: ________________ Step 2d: Multiply each squared deviation by the number of cases in the group. (Round to 2 places after decimal.) For Arkansas: _____________ For Oklahoma: ____________ For Iowa: ________________ Step 2e: Sum the scores found in Step 2d. (Round your answer to 2 places after the decimal.) Step 3. Calculate the mean of the squared deviations within groups (MS e or MSw). Step 3a: Determine the degrees of freedom within groups (dfe or dfw). Step 3b: Divide the SSe by the dfe (or the SSw by the dfw). Step 4. Calculate the mean of the squared deviations between groups (MS b). Step 4a: Determine the degrees of freedom between groups (dfb). Step 4b: Divide the SSb by the dfb. (Round your answer to 2 places after the decimal.) Step 5: Compute the F ratio by dividing the MSb by the MSe (or MSw). (Round to 2 places after the decimal.) Step 6: Find the Critical F value (for an alpha level of .05) in Appendix C. (Round to 2 places after the decimal.) Step 7: Decide whether the observed F value is statistically significant. (Answer "Yes" or "No".) Step 8: Determine which statement below is true. A. There is a statistically significant difference between the average weight of hogs grown in Arkansas, Oklahoma, and Iowa. B. There is not a statistically significant difference between the average weight of hogs grown in Arkansas, Oklahoma, and Iowa. Step 9: Interpret the ANOVA result. Which of the following statements most accurately describes what you know from the ANOVA result found in Step 7? A. All three groups are statistically significantly different from each other. B. Hogs from Iowa weigh significantly less than hogs from Oklahoma but do not differ from hogs raised in Arkansas. C. There is a statistically significant difference between the groups but we do not yet know which groups are different from each other. D. Hogs raised in Arkansas weigh significantly less, on average, than hogs raised in Oklahoma. Answers Chapter 10 Question 1 Step 1a: For Arkansas: 600 + 700 / 2 = 650 For Oklahoma: 800 + 1000 / 2 = 900 For Iowa: 300 + 400 / 2 = 350 Step 1b: For Arkansas, hog 1: 600 – 650 = -50 For Arkansas, hog 2: 700 – 650 = 50 For Oklahoma, hog 1: 800 – 900 = -100 For Oklahoma, hog 2: 1000 – 900 = 100 For Iowa, hog 1: 300 – 350 = -50 For Iowa, hog 2: 400 – 350 = 50 Step 1c: For Arkansas, hog 1: (-50)2 = 2,500 For Arkansas, hog 2: (50)2 = 2,500 For Oklahoma, hog 1: (-100)2 = 10,000 For Oklahoma, hog 2: (100)2 = 10,000 For Iowa, hog 1: (-50)2 = 2,500 For Iowa, hog 2: (50)2 = 2,500 Step 1d: (2,500 x 4) + (10,000 x 2) = 10,000 + 20,000 = 30,000 Therefore, SSe (or SSw) = 30,000. Step 2a: (600 + 700 + 800 + 1000 + 300 + 400) / 6 = 3800 / 6 = 633.33 Step 2b: For Arkansas: 650 – 633.33 = 16.67 For Oklahoma: 900 – 633.33 = 266.67 For Iowa: 350 – 633.33 = -283.33 Step 2c: For Arkansas: (16.67)2 = 277.89 For Oklahoma: (266.67)2 = 71,112.89 For Iowa: (-283.33)2 = 80,275.89 Step 2d: For Arkansas: 277.89 * 2 = 555.78 For Oklahoma: 71,112.89 * 2 = 142,225.78 For Iowa: 80,275.89 * 2 = 160,551.78 Step 2e: 555.78 + 142,225.78 + 160,551.78 = 303,333.34 <-- This is the SSb. Step 3a: 6–3=3 (Note: 6 is the total number of scores, N, and 3 is the number of groups, K) Step 3b: 30,000 / 3 = 10,000 <-- This is the MSw (or the MSe). Step 4a: 3–1=2 Step 4b: 303,333.34 / 2 = 151,666.67 <-- This is the MSb. Step 5: 151,666.67 / 10,000 = 15.17 -> This is the F ratio. Step 6: 9.55 Step 7: Fobs=15.17 > Fcrit=9.55 Step 8: A Step 9: C 2. Calculating the sum of squares within groups (SSe or SSw). Suppose that I want to know whether 10-year-old children in Brazil, India, and Australia differ in the average number of hours they spend per day in school. I select a random sample of two children from each country. (I know, this is a ridiculously small sample. I’m keeping it small to illustrate how to calculate the SSw, so work with me). The number of hours each student spends in school per day are presented in Table 1. Calculate the SSw (or SSe) in this example. Table 1 Student 1 Student 2 Mean Brazil 6 4 5 India 2 7 5.5 Australia 6 7 6.5 Grand mean 5.33 Step 1: Calculate the six deviation scores in this sample, beginning with Student 1 in Brazil, then Student 2 in Brazil, then Student 1 in India, etc. Enter all 6 deviation scores in the space below, separated by semicolons. Step 2: Square each deviation. Enter each squared deviation in the space below, separated by semicolons. Step 3: Sum the squared deviations. Answers Chapter 10 Question 2 Step 1: Step 2: Step 3: 6 - 5 = 1; 4 – 5 = -1; 2 - 5.5 = -3.5; 7 - 5.5 = 1.5; 6 - 6.5 = -0.5; 7 - 6.5 =0.5 1;1;12.25;2.25;.25;.25 1 + 1 + 12.25 + 2.25 + .25 + .25 = 17 3. My grandmother makes delicious cookies for my family every year. She always makes three different kinds of cookies: peanut butter, chocolate chip, and oatmeal cookies. She sends the peanut butter cookies to my aunt and her children, the chocolate chip to my uncle and his children, and the oatmeal cookies to my house with my parents, me, and my three siblings. While taking a statistics class I began wondering whether the family liked some of grandma’s cookies better than others. So I randomly selected a sample of two family members each from my aunt’s house, my uncle’s house, and my house and asked them to rate their liking of cookies on a scale of 1 to 10 with 10 being the highest. Here is what I find: Peanut Butter (my aunt’s house): Chocolate Chip (my uncle’s house): Oatmeal (my house): 7.5 4 8 and and and 9 6 10 Are there significant differences in the liking of Grandma’s cookies? Step 1. Calculate the sum of squared deviations within groups (SSw or SSe). (Round your answer to 2 places after the decimal when necessary.) Step 1a: Find the mean rating for each type of cookie: Peanut Butter:________________ Chocolate Chip: ________________ Oatmeal: ____________________ Step 1b: Find the within group deviation score for both people in each cookie group. Peanut Butter #1: ___________ Peanut Butter #2: ___________ Chocolate Chip #1: ___________ Chocolate Chip #2: ___________ Oatmeal #1: ______________ Oatmeal #2: ______________ Step 1c: Square each deviation score. Peanut Butter #1: ___________ Peanut Butter #2: ___________ Chocolate Chip #1: ___________ Chocolate Chip #2: ___________ Oatmeal #1: ______________ Oatmeal #2: ______________ Step 1d: Sum your squared deviation scores. This is your SS e or SSw. Step 2. Calculate the sum of squared deviations between groups (SS b). (Round your answer to 2 places after the decimal when necessary.) Step 2a: Calculate the grand mean. Step 2b: Calculate the deviation score for each group. Peanut Butter:_______________ Chocolate Chip: ________________ Oatmeal: ____________________ Step 2c: Square each deviation score. Peanut Butter:_______________ Chocolate Chip: ________________ Oatmeal: ____________________ Step 2d: Multiply each score by the number of cases in the group. Step 2e: Calculate the sum of the scores you just found. This is your SSb. Step 3. Calculate the mean of the squared deviations within groups (MS e or MSw). Step 3a: Determine the degrees of freedom within groups (dfe or dfw). Step 3b: Divide the SSe by the dfe (or the SSw by the dfw). This is your MSe (or MSw). (Round to 2 places.) Step 4. Calculate the mean of the squared deviations between groups (MS b). Step 4a: Determine the degrees of freedom between groups (dfb). Step 4b: Divide the SSb by the dfb. This is your MSb. (Round your answer to 2 places after the decimal.) Step 5: Compute the F ratio by dividing the MSb by the MSe (or MSw). (Round your answer to 2 places after the decimal.) Step 6: Using Appendix C, Find the critical F value for this sample (using an alpha level of .05). Step 7: Is this a statistically significant difference? A. Yes. B. No. Step 8: Which of the below statements is true based on what you know? A. There is a significant difference between the three groups in average amount they like Grandma’s cookies. B. There is no significant difference between the three groups in their average liking of Grandma’s cookies. Answers Chapter 10 Question 3 Step 1a: Peanut Butter: 8.25 Chocolate Chip: 5 Oatmeal: 9 Step 1b: Peanut Butter #1: -.75 Peanut Butter #2: .75 Chocolate Chip #1: -1 Chocolate Chip #2: 1 Oatmeal #1: -1 Oatmeal #2: 1 Step 1c: Peanut Butter #1: .56 Peanut Butter #2: .56 Chocolate Chip #1: 1 Chocolate Chip #2: 1 Oatmeal #1: 1 Oatmeal #2: 1 Step 1d: 5.12 Step 2a: 7.42 Step 2b: Peanut Butter: .83 Chocolate Chip: -2.42 Oatmeal: 1.58 Step 2c: Peanut Butter: .69 Chocolate Chip: 5.86 Oatmeal: 2.50 Step 2d: Peanut Butter: 1.38 Chocolate Chip: 11.72 Oatmeal: 5 Step 2e: 18.10 Step 3a: 3 Step 3b: 1.71 Step 4a: 2 Step 4b: 9.05 Step 5: 5.29 Step 6: 9.55 Step 7: B Step 8: B 4. Calculating the sum of squares between groups (SS b). Suppose I am curious as to whether there is a significant difference in the amount of time kittens, puppies and ducklings sleep each day. I collect a small random sample of four of each of these baby types and find the data presented in the chart below. (Round your answer to 2 places after the decimal when necessary.) Baby type #1 Baby type #2 Baby type #3 Baby type #4 Mean Kittens 16 17 18 17 17 Puppies 12 15 14 13 13.5 Ducklings 9 10 9 11 9.75 Step 1: Calculate the deviation score for each group. Kittens: ____________ Puppies: ___________ Ducklings: ___________ Step 2: Square each deviation score. Kittens: ____________ Puppies: ___________ Ducklings: ___________ Step 3: Multiply each squared deviation by the number of cases in the group. Kittens: ____________ Puppies: ___________ Ducklings: ___________ Step 4: Calculate the sum of these scores. Grand mean 13.42 Answers Chapter 10 Question 4 Step 1: Kittens: 3.58 Puppies: .08 Ducklings: -3.67 Step 2: Kittens: 12.82 Puppies: .01 Ducklings: 13.47 Step 3: Kittens: 51.28 Puppies: .04 Ducklings: 53.88 Step 4: 105.20 Problems and Answers for Chapter 11 1. Suppose that I am interested in the investment preferences of men and women. I suspect that, on average, women prefer to invest their money in safer ways (i.e., saving money in the bank, investing in bonds) whereas men prefer riskier investments (e.g., stocks). However, I also suspect that the investment preferences of individuals depends on their age. Specifically, I think that people over 40 are generally more cautious in their investment strategies whereas people under 40 are willing to take more risks with their investments. I also suspect that this tendency to become more cautious with age is particularly true for women. So I select random samples of 100 men (half of them under 40 years old, half over 40) and 100 women (again, half under 40 years old, half over 40). I ask each participant about his or her investment strategy and rate each person’s investment strategy on a scale from 1 (very cautious) to 10 (very risky). Please answer the following questions based on this scenario. 1a. When is it appropriate to conduct a factorial ANOVA? A. When you do not know the sample mean. B. When you have one continuous dependent variable and one categorical independent variable. C. When you have one continuous dependent variable and at least two categorical independent variables. D. When you have one categorical dependent variable and at least two continuous independent variables 1b. In the problem above, what is the dependent variable? A. Gender B. Level of risk in the investment strategy C. Age D. Stocks 1c. Suppose that I actually conduct the study and find that, indeed, men score higher on the investment riskiness scale than women, on average. What kind of an effect is this? A. A main effect. B. An interaction effect. C. A moderator effect. D. A mediator effect. 1d. Suppose that I also find that, indeed, the investment strategies of individuals over 40 are more cautious, on average, than the investment strategies of individuals under 40. What type of effect is this? A. A main effect. B. An interaction effect. C. A moderator effect. D. A mediator effect. 1e. Suppose that I also find my hypothesized interaction effect to be true. Which statement below best summarizes that interaction? A. Women are more cautious in their investment strategies than men. B. Men become more cautious in their investment strategy after they turn 40. C. Men become riskier in their investment strategy after 40 but women become more cautious. D. Both men and women become more cautious in their investment strategy after age 40, but the increase in caution is greater for men. 1f. What is the most accurate description of the moderator effect in this study? A. The association between age and investment risk is moderated by sex. B. The association between sex and investment risk is moderated by age. C. The association between sex and age is moderated by investment risk. D. Both A and B. E. Both A and C. 1g. Now suppose that someone takes a look at my study and says “Wait a minute. Investment strategies depend on how much money one has, and women tend to have less money, on average, than men. So you need to control for the overall net worth of the participants” (i.e., how much total money each participant has). That is a good point. So I add the “net worth” variable to my study. When I put this variable into my ANOVA, what is it called? A. A categorical variable. B. A moderator C. A covariate D. A masker Answers Chapter 11 Question 1 1a. C 1b. B 1c. A 1d. A 1e. D 1f. D 1g. C 2. A few years ago I collected survey data from 920 high school students in California. This sample included 202 first-generation students (i.e., students born outside of the United States), 439 second-generation students (i.e., students born in the U.S. to mothers who were born outside of the U.S.), and 279 third-generation or greater students (i.e., students and mothers both born in the U.S.). This sample included 521 girls (coded ‘0’ in the first table below) and 399 boys (coded ‘1’ in the first table below). I wanted to know whether these students differed by gender or generation on a measure of performance-approach goals. Performanceapproach goals represent a concern with doing better than other students in school. A sample item from the survey that assessed performance-approach goals was “It is important to me that I do better than other students in this class.” In the tables below, “W3APPRCH” refers to scores on my measure of performanceapproach goals. “W3SEX” refers to students reports of their gender (i.e., female or male), “W3ENGGRD” refers to their final grade in their English class, and “W1W3IM” refers to their generational status (i.e,. first, second, or third+ generation). So I conducted a 2 (sex) by 3 (generational status) factorial ANCOVA with English grade as a covariate. The descriptive statistics are presented in the first table below and the ANCOVA results are presented in the second table. 2a. How many first-generation girls are there in this sample? 2b. What is the mean, or average, for second-generation boys on the measure of performance-approach goals?(Round your answer to 4 places after the decimal ) 2c. I used students grades in English (“W3ENGGRD”) class as a covariate in this study. Was this covariate significantly related to the dependent variable? How do you know? A. No, because the F value for this covariate was less than 8.00. B. Yes, because the F value for this covariate had a p value of .012 (under the “Sig.” Column). C. No, because the F value for this covariate had a p value of .012 (under the “Sig.” Column). D. Yes, because W3SEX had a significant F value. 2d. If you look in the second table above you will see that the generational status variable (“W1W3IM”) had an F value of 5.071 and a corresponding p value of .006. What statement below best summarizes this result? A. Second-generation students scored higher on the performance-approach goal variable than did students in the two other generational groups. B. Boys scored higher on the performance-approach goal variable than did girls. C. There is a main effect for generational status on performance-approach goals. D. There is an interaction effect of generational status on performance-approach goals. 2e. There also appears to be a statistically significant interaction between gender and generational status on performance approach goals. How do I know this? A. Because both of the main effects for the two independent variables were statistically significant. B. Because the p value for the interaction effect (“W3SEX * W1W3IM”) was .021, which is lower than .05. C. Because the p value for the interaction effect (“W3SEX * W1W3IM”) was .006, which is lower than .05. D. Because the intercept was huge. 2f. Which statement below most accurately summarizes the interaction effect? A. The association between gender and performance approach-goals is moderated by generational status. Among boys, there appears to be little differences in the performance-approach goal scores across the three generational groups, but among girls third-generation students score substantially lower than first- and second-generation girls. B. The association between gender and performance approach-goals is moderated by generational status. Among girls, there appears to be little differences in the performance-approach goal scores across the three generational groups, but among boys third-generation students score substantially lower than first- and second-generation students. C. The association between generational status and performance approach-goals is moderated by gender. Among second- and third-generation students, girls and boys score roughly the same on the performance-approach goal measure. But among first-generation students, girls score lower than boys on the dependent variable. 2g. In the presence of a significant interaction effect, we must be cautious in our interpretation of the significant main effects. What is the most accurate statement about the main effect for gender, given the interaction effect? A. Boys scored higher on the dependent variable than girls. B. Boys scored higher on the dependent variable than girls, but this is primarily due to the differences among third-generation students. C. Boys scored higher on the dependent variable than girls, but this is primarily due to the differences among first-generation students. D. In the presence of an interaction we must assume there is no main effect for gender. Answers Chapter 11 Question 2 2a. 120 2b. 2.9226 2c. B 2d. C 2e. B 2f. A 2g. B Questions for Chapter 12 1. Why would you even conduct a repeated-measures ANOVA rather than the simpler paired t test? A. Because you have more than two time points of data. B. Because it is more fun. C. Because you want to include a covariate, a between-subjects independent variable, or both. D. Because only one of these statistics provides standard error information. E. Both A and C. F. Both A and D. Answer Chapter 12 Question 1 Answer: E 2. Suppose I want to see how children’s feelings about their parents change as they get older. I ask a group of 50 children how much they respect their parent’s opinion three times: when the children are 7, 11, and 15. I suspect that the answers to these questions may differ depending on whether the children are boys or girls, so I include gender in my analysis. I also suspect that how much children respect their parents may be influenced by how much money their parents make, so I include parental income in my model as well. Please answer the following questions based on this research model. 2A: What is the dependent variable in this study? A. Time, or age. B. Gender. C. Respect for parent’s opinion. D. Parental income. E. There isn’t one. 2B: What is the independent, within-subjects variable in this study? A. Time, or age. B. Gender. C. Respect for parent’s opinion. D. Parental income. E. There isn’t one. 2C: What is the independent, between-subjects variable in this study? A. Time, or age. B. Gender. C. Respect for parent’s opinion. D. Parental income. 2D: E. There isn’t one. What is the covariate in this study? A. Time, or age. B. Gender. C. Respect for parent’s opinion. D. Parental income. E. There isn’t one. Answer Chapter 12 Question 2 2A: C 2B: A 2C: B 2D: D 3. I collected data from 757 high school students (412 girls, 345 boys) over a two year period. I collected information about each student’s grade in their English classes three times: At the end of the first semester of the first year of the study, at the end of the second semester of the first year, and again at the end of the first semester of the second year of the study. I wanted to know whether their performance in English changed more during the school year or between one school year and the next. Grade was measured on a 14-point scale (0 = “F” and 13 = “A+”). In this study, I also included the gender of the student as a between-subjects independent variable. I conducted a repeated-measures ANOVA with these data and got the following results from SPSS. The results are presented in three tables below. The first presents descriptive statistics. The second table provides the results of the within-subjects part of the ANOVA. The last table present results for the between-subjects test. Using the information from these tables, please answer the following questions. 3A: On average, when boys and girls grades are combined, is there a statistically significant change in English grade over the three semesters included in this study? A. Yes. B. No. C. How should I know? 3B: What are the F and p values that provide the answer to question 3A (please round to 2 places after the decimal point). A. F = 24.28, p = .00 B. F = 8.70, p = .00 C. F = .98, p = .38 D. F = 3.08, p = .00 3C: When were students’ grades at their highest, on average? A. First semester, year 1. B. Second semester, year 1. C. First semester, year 2. 3D: Did students grades decline more during the academic year or between the first and second year of the study? A. During the year. B. Between the first and second year. C. Neither. 3E: Was there a difference between boys and girls grade in English, averaged across the three time points in the study? A. Yes. B. No. C. Cannot tell. 3F: How do you know the answer to 3E? A. Because the test of between subjects effects was statistically significant. B. Because the test of within subjects effects was statistically significant. C. Both A and B. D. Neither A nor B. 3G: What are the F and p values that provide the answer to question 3E (please round to 2 places after the decimal point)? A. F = 24.28, p = .00 B. F = 8.70, p = .00 C. F = .98, p = .38 D. F = 3.08, p = .00 3H: Is there a statistically significant interaction between time and gender on English grade? A. Yes. B. No. C. Cannot tell. 3I: If there were a statistically significant interaction in this study, which sentence below would best describe this interaction? A. The change in English grades over time was the same for boys and girls. B. The gender of the student was not related to changes in English grades over time. C. The change in English grade was dependent on the gender of the student. D. Girls’ grades in English declined over time, but so did boys’. Answers Chapter 12 Question 3 3A: A 3B: B 3C: A 3D: A 3E: A 3F: A 3G: A 3H: B 3I: C Questions for Chapter 13 Self-handicapping is a type of behavior that some students engage in from time to time. When these students fear they may not perform well on a test or assignment, they may undermine their own achievement so that if they do not do well, they will have an excuse. For example, a student may put off studying for a test until the last minute. Then, if he does not do well on the test, he can say it is because he did not study enough, not because he lacks intelligence. Similarly, a student may get drunk before writing a paper. If she gets a bad grade she can blame her drinking, not her lack of writing ability. I did a study with several hundred high school students. I asked them to rate how often they engaged in self-handicapping using a 1 to 5 scale (1 = “never” and 5 = “often”). I also asked them to rate on a 1 to 5 scale how much they feared failure (1 = “not at all” and 5 = “very much”). Some students dread making mistakes and think about it all the time. Others are not worried about making mistakes and rarely think about it. I wanted to see whether fear of failure was related to self-handicapping. Because self-handicapping is used mostly when students are afraid they might fail, I predicted that students who often worried about failure would engage in self-handicapping more often. So I ran a regression analysis using SPSS and got the following output: self hand fear of fail Model 1 Model 1 Model 1 Descriptive Statistics Mean Std. Deviation 2.0540 .9067 2.7139 .6087 R .442 N 869 869 Model Summary Adjusted R Square R Square .195 .194 Regression Residual Total (Constant) Fear of Failure ANONA Sum of Squares df 139.182 1 574.345 867 713.527 868 Std. Error of the Estimate .8139 Mean Square 139.182 .662 F 210.101 Coefficients Unstandardized Standardized Coefficients Coefficients B Std. Error Beta .269 .126 .658 .045 .442 Question 1A: How many cases are in my sample? t 2.130 14.495 Sig. .000 Sig. .033 .000 Question 1B: In this regression analysis, which variable is the X variable? A: Self-handicapping B: Fear of failure C: Grade in English D: Constant Question 1C: In this regression analysis, which variable is the Y variable? A: Self-handicapping B: Fear of failure C: Grade in English D: Constant Question 1D: In this regression analysis, which variable is the dependent variable? A: Self-handicapping B: Fear of failure C: Grade in English D: Constant Question 1E: In this regression analysis, what is the correlation between self- handicapping and fear or failure? Question 1F: What is the percentage of variance explained in self-handicapping by fear of failure? Question 1G: In What is the unstandardized regression coefficient for fear of failure? Question 1H: Which statement below best describes the meaning of this regression coefficient? A: For every increase of one unit in self-handicapping there is a corresponding increase of .658 units in fear of failure. B: For every increase of one unit in fear of failure there is a corresponding change of .658 units in the constant. C: For every increase of one unit in fear of failure there is a corresponding increase of .658 units in self-handicapping. Question 1I: What is the value of the constant? (Round your answer to 3 places after the decimal.) Question 1J: Which statement below best describes the meaning of this constant? A: When the value of self-handicapping is zero, the value of fear of failure is .269. B: When the value of fear of failure is zero, the value of self-handicapping is .269. C: When the value of self-handicapping is zero, the value of constant is .269. D: For every increase of one unit in constant there is a corresponding increase of .269 units in self-handicapping. Question 1K: Was fear of failure a statistically significant predictor of self-handicapping in this study? A: No, because the t value is greater than 1.00. B: No, because the BETA value is smaller than the B value. C: Yes, because the BETA is greater than .10. D: Yes, because the p value associated with the regression coefficient is less than .05. Answers for Chapter 13 Question 1 Question 1A: 869 Question 1B: B Question 1C: A Question 1D: A Question 1E: .442 Question 1F: .195 or 19.5% Question 1G: .658 Question 1H: C Question 1I: .269 Question 1J: B Question 1K: D 2. It is possible that self-handicapping is related to fear of failure for the simple reason that low-achieving students have good reason to fear failure. Students who are not doing well in school may reasonably fear that they will fail, and this causes them to engage in self-handicapping. In other words, fear of failure may not be what causes self-handicapping: Low achievement may cause both fear of failure and self-handicapping. To test this I ran multiple regression analysis that included both fear of failure and the students’ grades in their English class as predictor variables. Grades were measured on a 13-point scale (0 = F, 13 = A). The SPSS output for the regression analysis is presented below. Descriptive Statistics Mean Std. Deviation 2.0447 .9015 self handicap 2.7134 .6084 fear of fail 8.0340 3.4495 English grade Model Summary Adjusted Model R R Square R Square .445 .198 .196 1 Model 1 Model 1 Regression Residual Total (Constant) Fear of Failure English grade ANONA Sum of Squares df 132.087 2 535.972 820 668.059 822 N 823 823 823 Std. Error of the Estimate .8085 Mean Square 66.043 .654 F 101.042 Coefficients Unstandardized Standardized Coefficients Coefficients B Std. Error Beta .581 .149 .626 .046 .422 -2.915E-02 .008 -.112 Question 2A: How many cases are in my sample now? Question 2B: What is/are my independent variables in this regression? A: Self-handicapping B: Self-handicapping and fear of failure C: Fear of failure and English grade D: English grade Question 2C: How much of the variance in self-handicapping is explained by fear of failure and achievement in English combined? Sig. .000 t 3.893 13.466 -3.556 Sig. .000 .000 .000 Question 2D: Which statement best describes the associations between the independent variables and the dependent variable in this study? A: Fear of failure is significantly, positively related to self-handicapping and English grade is significantly, positively associated with selfhandicapping. B: Fear of failure is not significantly related to self-handicapping and English grade is significantly, positively associated with selfhandicapping. C: Fear of failure is significantly, positively related to self-handicapping and English grade is not significantly associated with selfhandicapping. D: Fear of failure is significantly, positively related to self-handicapping and English grade is significantly, negatively associated with selfhandicapping. Question 2E: Fear of failure is a stronger predictor of self-handicapping than is English achievement. What statistic tells me this most clearly? A: The standardized regression coefficients (Betas) B: The unstandardized regression coefficients (B) C: The standard errors D: The SIG (P values) Question 2F: In this regression analysis what does the constant tell us? A: The value of self-handicapping when fear of failure is zero. B: The value of self-handicapping when English grade is zero. C: The value of English grade when fear of failure is zero. D: The value of self-handicapping when fear of failure and English grade are zero. Question 2G: Taken together, what do the two regression analyses reveal? A: Both fear of failure and English grade do not really predict selfhandicapping. B: Students high in fear of failure self-handicap more than students low in fear of failure even when controlling for student achievement level. C: The relationship between self-handicapping and fear of failure is mostly due to differences among students in their achievement level. D: When controlling for fear of failure, English grade is unrelated to self-handicapping. Answers Chapter 13 Question 2 Question 2A: Question 2B: Question 2C: Question 2D: Question 2E: Question 2F: Question 2G: 823 C .198 or 19.8% D A D B 3. Suppose I collect a random sample of 100 kids aged 6-10 to find out if there is a relationship between eating candy and getting cavities. On average, I find the kids eat 4 pieces of candy each day with a standard deviation of 1 and have had a mean of 5 cavities with a standard deviation of 1.5. The correlation between these two variables is .40. Question 1: What is my independent (X) variable? A: Number of cavities B: Number of kids C: Age of each kid D: Amount of candy each day Question 2: What is my dependent (Y) variable? A: Number of cavities B: Number of kids C: Age of each kid D: Amount of candy each day Question 3: Based on the data I collected in my study, how many cavities would you expect a kid to have who eats 7 pieces of candy every day? (Round your answer to 1 places after the decimal when necessary.) Step 1: Calculate your regression coefficient. Step 1a: Divide the standard deviation of Y by the standard deviation of X. Step 1b: Multiply this number by the correlation coefficient (.40). Step 1c: Wrap words around the regression coefficient. What do you know so far? A: For every increase in unit X (pieces of candy eaten), I would predict an increase of .6 units in Y (number of cavities). B: For every increase in unit Y (number of cavities), I would predict an increase of .6 units in X (pieces of candy eaten). Step 2: Calculate your intercept. Step 2a: Multiply your regression coefficient by the mean of X. Step 2b: Subtract this number from the mean of Y. Step 2c: Wrap words around this intercept. What does this number tell you? A: When X=0 (i.e.: when kids eat no candy), I would predict the value of Y (i.e.: number of cavities) to be 2.6. B: When Y=0 (ie: when kids have zero cavities), I would predict the value of X (i.e.: amount of candy eaten) to be 2.6. Step 3: Use the regression equation to make your prediction. Step 3a: Multiply the given value of X (7) by the regression coefficient found in step 1b. Step 3b: Add this to your intercept found in step 2b. Step 3c: Interpret your results. What is your prediction? A: We would predict that a child who eats 6.8 pieces of candy would have 7 cavities. B: We would predict that a child who eats 7 pieces of candy would have 6.8 cavities. Answer Chapter 13 Question 3 Question 1: D Question 2: A Question 3: Step 1a: 1.5 Step 1b: .6 Step 1c: A Step 2a: 2.4 Step 2b: 2.6 Step 2c: A Step 3a: 4.2 Step 3b: 6.8 Step 3c: B Problems and Answers for Chapter 14 1. Chi Square Work Problem Suppose that I have collected data from 400 students. The sample was selected from two different states (California and Indiana) and included third, sixth, and tenth graders. The purpose of the study was to determine whether students in California differed from students in Indiana in the average amount of homework they had per night of school. It turns out that students in the higher grades get more homework than those in the lower grades. So before I can determine which state gives more homework, I must determine whether there are differences in the grade levels of the students in each state. For example, if I find that students in Indiana receive more homework, on average, than those in California, but my sample also includes more tenth graders from Indiana and more third graders from California, I will not know if the differences between the states is due to actual regional differences in homework or to grade level differences in my sample. So I must conduct a Chi-square test of independence. Here is the contingency table for these data: Third graders Sixth graders Tenth graders Row totals Californians 100 60 40 200 Indianans 50 70 80 200 Column totals 150 130 120 400 Conduct a chi square test of independence and determine whether it is statistically significant. (Round your answer to 2 places after the decimal when necessary.) Step 1: Calculate the expected value for California third graders. Step 1a: Calculate the proportion of third graders relative to the total sample. Step 1b: Calculate the proportion of Californians relative to the total sample. Step 1c: Multiply these two proportions together. Step 1d: Multiply the product from 1c by the total sample size. Step 2: Calculate the expected value for Indiana third graders. Step 2a: Calculate the proportion of third graders relative to the total sample. Step 2b: Calculate the proportion of Indianans relative to the total sample. Step 2c: Multiply these two proportions together. Step 2d: Multiply the product from 2c by the total sample size. Step 3: Calculate the expected value for California sixth graders. Step 3a: Step 3b: Step 3c: Step 3d: Step 4: Step 4a: Step 4b: Step 4c: Step 4d: Step 5: Step 5a: Step 5b: Step 5c: Step 5d: Step 6: Calculate the proportion of sixth graders relative to the total sample. Calculate the proportion of Californians relative to the total sample. Multiply these two proportions together. Multiply the product from 3c by the total sample size. Calculate the expected value for Indiana sixth graders. Calculate the proportion of sixth graders relative to the total sample. Calculate the proportion of Indianans relative to the total sample. Multiply these two proportions together. Multiply the product from 4c by the total sample size. Calculate the expected value for California tenth graders. Calculate the proportion of tenth graders relative to the total sample. Calculate the proportion of Californians relative to the total sample. Multiply these two proportions together. Multiply the product from 5c by the total sample size. Calculate the expected value for Indiana tenth graders. Step 6a: Calculate the proportion of tenth graders relative to the total sample. Step 6b: Calculate the proportion of Indianans relative to the total sample. Step 6c: Multiply these two proportions together. Step 6d: Multiply the product from 6c by the total sample size. Step 7: Calculate the difference between the observed and expected value for the California third grader cell and square the difference. Step 8: Divide the value in Step 7 by the expected value for California third graders. Step 9: Calculate the difference between the observed and expected value for the Indiana third grader cell and square the difference. Step 10: Divide the value in Step 9 by the expected value for Indiana third graders. Step 11: Calculate the difference between the observed and expected value for the California sixth grader cell and square the difference. Step 12: Divide the value in Step 11 by the expected value for California sixth graders. Step 13: Calculate the difference between the observed and expected value for the Indiana sixth grader cell and square the difference. Step 14: Divide the value in Step 13 by the expected value for Indiana sixth graders. Step 15: Calculate the difference between the observed and expected value for the California tenth grader cell and square the difference. Step 16: Divide the value in Step 15 by the expected value for California tenth graders. Step 17: Calculate the difference between the observed and expected value for the Indiana tenth grader cell and square the difference. Step 18: Divide the value in Step 17 by the expected value for Indiana tenth graders. Step 19: Find the sum of the values of the squared differences between the observed and expected values divided by the expected values for each cell (i.e., the sum of the answers from steps 8, 10, 12, 14, 16, and 18). Step 20: Decide whether this is a statistically significant chi square value. Step 20a: Determine the degrees of freedom. Step 20b: Find the critical chi square value in Appendix E. Step 20c: Reach a conclusion about the statistical significance of the observed X2. A. It is statistically significant. B. It is not statistically significant. Step 20d: What is the best interpretation of a statistically significant X2 test of independence? A. There are significantly more members of the sample in one cell than the others? B. The groups differ from each other at the .05 level? C. Overall, the observed frequencies in the cells of a contingency table differ from the expected frequencies. D. The number of cases at each level of one variable are independent of the values of the second independent variable. Answers Chapter 14 Question 1 Step 1: Step 2: Step 3: Step 4: Step 5: Step 6: Step 7: Step 8: Step 9: Step 10: Step 11: Step 12: Step 13: Step 14: Step 15: Step 16: Step 17: Step 18: Step 19: Step 1a: Step 1b: Step 1c: Step 1d: 150/400 = .38 200/400 = .50 .38 X .50 = .19 .19(400) = 76. This is the expected number of California third graders. Step 2a: 150/400 = .38 Step 2b: 200/400 = .50 Step 2c: .38 X .50 = .19 Step 2d: .19(400) = 76. This is the expected number of Indiana third graders. Step 3a: 130/400 = .33 Step 3b: 200/400 = .50 Step 3c: .33 X .50 = .17 Step 3d: .17(400) = 68. This is the expected number of California sixth graders. Step 4a: 130/400 = .33 Step 4b: 200/400 = .50 Step 4c: .33 X .50 = .17 Step 4d: .17(400) = 68. This is the expected number of Indiana sixth graders. Step 5a: 120/400 = .30 Step 5b: 200/400 = .50 Step 5c: .30 X .50 = .15 Step 5d: .15(400) = 60. This is the expected number of California tenth graders. Step 6a: 120/400 = .30 Step 6b: 200/400 = .50 Step 6c: .30 X .50 = .15 Step 6d: .15(400) = 60. This is the expected number of Indiana tenth graders. (100 - 76)2 = (24)2 = 576 576 / 76 = 7.58 (50 – 76)2 = (-26)2 = 676 676 / 76 = 8.89 (60 – 68)2 = (-8)2 = 64 64 / 68 = .94 (70 – 68)2 = (2)2 = 4 4 / 68 = .06 (40 – 60)2 = (-20)2 = 400 400 / 60 = 6.67 (80 - 60)2 = (20)2 = 400 400 / 60 = 6.67 7.58 + 8.89 + .94 + .06 + 6.67 + 6.67 = 30.81. This is the chi square value. Step 20: Step 20a: Step 20b: Step 20c: Step 20d: (3 – 1) (2 – 1) = 2 5.99 for an alpha level of .05 A C Problems and Answers for Chapter 15 1. 2. 3. 4. Suppose a researcher has collected data using surveys from 300 college students. She has a hypothesis about which items should go together to represent underlying constructs. So the researcher puts the items together and runs a statistical analysis to determine how well her hypothesized grouping of items fits the actual data. What kind of analysis should she conduct? a. Independent t test b. Exploratory factor analysis (EFA) c. Confirmatory factor analysis (CFA) d. Analysis of variance. In a factor analysis, there are indicators and there are underlying constructs known as latent variables. Which of these is actually measured? a. The independent variables b. The indicator variables c. The dependent variables d. The latent variables To determine how many factors to retain from an exploratory factor analysis, researchers often examine a statistic that offers a rough estimate of how much variance in the full set of items is explained by a particular factor. If the value of this statistic is less than 1.0 for any particular factor, many researchers would decide not to retain that factor. What is this statistic called? a. Scree plot b. Fit statistic c. F value d. Eigenvalue Sometimes, an exploratory factor analysis reveals that one item loads fairly strongly on more than one factor. What is the term used to describe such items? a. Factor-jumping b. Freewheeling c. Multi-cooperating d. Cross-loading 5. 6. 7. 8. What does a reliability analysis, as described in Chapter 15, tell a researcher? a. It indicates whether research participants score the same on a test or survey over a two-week period. b. It indicates how strongly the responses to a set of items are associated with each other. c. It indicates how a set of items should be separated into different factors. d. It indicates whether an item is telling the truth. When one conducts a reliability analysis, a statistic is generated that provides an indication of how strongly the items in the analysis hold together. What is the name of this statistic? a. Cronbach’s beta b. Eigenvalue c. Cronbach’s alpha d. Conbach’s delta In what type of analysis would you find a statistic called the item-total correlation? a. Reliability analysis b. Alpha analysis c. Exploratory factor analysis d. Confirmatory factor analysis In an exploratory factor analysis, the factors can be rotated in a variety of ways. When researchers expect the factors to be correlated, they often choose a rotation method that does not maximize the distinctions between them. What is the name for this type of factor rotation? a. Orthogonal b. Maximum likelihood c. Varimax d. Oblique 9. In a confirmatory factor analysis, a set of statistics are generated and used to determine how well the hypothesized factor structure matches the data. What are these statistics called? a. CFA statistics b. Fit statistics c. Factor loading statistics d. Rotation statistics 10. The process of interpreting the meaning of the factors that emerge from an exploratory factor analysis can be quite subjective. How do researchers typically decide what underlying construct is represented by a particular factor? a. By examining the percentage of variance explained by each factor b. By performing the reliability analysis c. By examining which items load most strongly on the factor d. By altering the method of extraction Correct answers for Chapter 15 problems. 1. C 2. B 3. D 4. D 5. B 6. C 7. D 8. A 9. B 10. C