Introduction To Error Control
advertisement

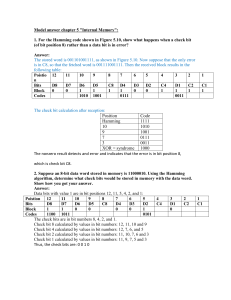
Introduction To Error Control Error control coding provides the means to protect data from errors. Data transferred from one place to the other has to be transferred reliably. Unfortunately, in many cases the physical link can not guarantee that all bits will be transferred without errors. It is then the responsibility of the error control algorithm to detect those errors and in some cases correct them so upper layers will see an error free link. Two error control strategies have been popular in practice. They are the FEC (Forward Error Correction) strategy, which uses error correction alone, and the ARQ (Automatic Repeat Request) strategy which uses error detection combined with retransmission of corrupted data. The ARQ strategy is generally preferred for several reasons. The main reason is that the number of overhead bits needed to implement an error detection scheme is much less then the number of bits needed to correct the same error. The FEC strategy is mainly used in links where retransmission is impossible or impractical. The FEC strategy is usually implemented in the physical layer and is transparent to upper layers of the protocol. When the FEC strategy is used, the transmitter sends redundant information along with the original bits and the receiver makes its best to find and correct errors. The number of redundant bits in FEC is much larger then in ARQ. The following lists a few algorithms used for FEC Convolutional Codes BCH Codes Hamming Codes Reed-Solomon Codes And a few used for ARQ CRC Codes Serial Parity Block Parity Modulo Checksum Error Correction with Hamming Codes Forward Error Correction (FEC), the ability of receiving station to correct a transmission error, can increase the throughput of a data link operating in a noisy environment. The transmitting station must append information to the data in the form of error correction bits, but the increase in frame length may be modest relative to the cost of re transmission. (sometimes the correction takes too much time and we prefer to re transmit). Hamming codes provide for FEC using a "block parity" mechanism that can be inexpensively implemented. In general, their use allows the correction of single bit errors and detection of two bit errors per unit data, called a code word. The fundamental principal embraced by Hamming codes is parity. Hamming codes, as mentioned before, are capable of correcting one error or detecting two errors but not capable of doing both simultaneously. You may choose to use Hamming codes as an error detection mechanism to catch both single and double bit errors or to correct single bit error. This is accomplished by using more than one parity bit, each computed on different combination of bits in the data. The number of parity or error check bits required is given by the Hamming rule, and is a function of the number of bits of information transmitted. The Hamming rule is expressed by the following inequality: p d + p + 1 < = 2 (1) Where d is the number of data bits and p is the number of parity bits. The result of appending the computed parity bits to the data bits is called the Hamming code word. The size of the code word c is obviously d+p, and a Hamming code word is described by the ordered set (c,d). Codes with values of p< =2 are hardly worthwhile because of the overhead involved. The case of p=3 is used in the following discussion to develop a (7,4) code using even parity, but larger code words are typically used in applications. A code where the equality case of Equation 1 holds is called a perfect code of which a (7,4) code is an example. A Hamming code word is generated by multiplying the data bits by a generator matrix G using modulo-2 arithmetic. This multiplication's result is called the code word vector (c1,c2.c3,.....cn), consisting of the original data bits and the calculated parity bits. The generator matrix G used in constructing Hamming codes consists of I (the identity matrix) and a parity generation matrix A: G=[I:A] An example of Hamming code generator matrix: G = 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 | | | | 1 0 1 1 1 1 0 1 1 1 1 0 The multiplication of a 4-bit vector (d1,d2,d3,d4) by G results in a 7-bit code word vector of the form (d1,d2,d3,d4,p1,p2,p3). It is clear that the A partition of G is responsible for the generation of the actual parity bits. Each column in A represents one parity calculation computed on a subset of d. The Hamming rule requires that p=3 for a (7,4) code, therefore A must contain three columns to produce three parity bits. If the columns of A are selected so each column is unique, it follows that (p1,p2,p3) represents parity calculations of three distinct subset of d. As shown in the figure below, validating the received code word r, involves multiplying it by a parity check to form s, the syndrome or parity check vector. T H = [A | I] | 1 0 1 1 | 1 0 0 | | 1 1 0 1 | 0 1 0 | * | 1 1 1 0 | 0 0 1 | |1| |0| |0| |1| |0| |0| |1| = |0| |0| |0| H*r = s If all elements of s are zero, the code word was received correctly. If s contains non-zero elements, the bit in error can be determined by analyzing which parity checks have failed, as long as the error involves only a single bit. For instance if r=[1011001], s computes to [101], that syndrome ([101]) matches to the third column in H that corresponds to the third bit of r - the bit in error. OPTIMAL CODING From the practical standpoint of communications, a (7,4) code is not a good choice, because it involves non-standard character lengths. Designing a suitable code requires that the ratio of parity to data bits and the processing time involved to encode and decode the data stream be minimized, a code that efficiently handles 8-bit data items is desirable. The Hamming rule shows that four parity bits can provide error correction for five to eleven data bits, with the latter being a perfect code. Analysis shows that overhead introduced to the data stream is modest for the range of data bits available (11 bits 36% overhead, 8 bits 50% overhead, 5 bits 80% overhead). A (12,8) code then offers a reasonable compromise in the bit stream . The code enables data link packets to be constructed easily by permitting one parity byte to serve two data bytes. Cyclic Redundancy Check (CRC) Introduction The CRC is a very powerful but easily implemented technique to obtain data reliability. The CRC technique is used to protect blocks of data called Frames. Using this technique, the transmitter appends an extra n- bit sequence to every frame called Frame Check Sequence (FCS). The FCS holds redundant information about the frame that helps the transmitter detect errors in the frame. The CRC is one of the most used techniques for error detection in data communications. The technique gained its popularity because it combines three advantages: Extreme error detection capabilities. Little overhead. Ease of implementation. The following sections will explain the CRC more in depth: How the CRC algorithm works Implementing the CRC algorithm in hardware Implementing the CRC algorithm in software The Most used CRC polynomials How the CRC algorithm works The CRC algorithm works above the binary field. The algorithm treats all bit streams as binary polynomials. Given the original frame, the transmitter generates the FCS for that frame. The FCS is generated so that the resulting frame (the cascade of the original frame and the FCS), is exactly devisable by some pre-defined polynomial. This pre-defined polynomial is called the devisor or CRC Polynomial. For the formal explanation we will define the following : M - The original frame to be transmitted, before adding the FCS. It is k bits long. F - The resulting FCS to be added to M. It is n bits long. T - The cascading of M and F. This is the resulting frame that will be transmitted. It is k+n bits long. P - The pre-defined CRC Polynomial. A pattern of n+1 bits. Click here to see an example: The main idea behind the CRC algorithm is that the FCS is generated so that the reminder of T/P is zero. Its clear that (1) T= M * x^n + F This is because by cascading F to M we have shifted T by n bits to the left and then added F to the result. We want the transmitted frame, T, to be exactly divisible by the predefined polynomial P, so we would have to find a suitable Frame Check Sequence (F) for every raw message (M). Suppose we divided only M*x^n by P, we would get: (2) M*x^n / P = Q + R/P There is a quotient and a reminder. We will use this reminder, R, as our FCS (F). Returning to Eq. 1: (3) T= M*x^n + R We will now show that this selection of the FCS makes the transmitted frame (T) exactly divisible by P: (4) T/P = (M*x^n + R)/P = M*x^n / P +R/P = Q + R/P + R/P = Q + (R+R)/P but any binary number added to itself in a modulo 2 field yields zero so: (5) T/P = Q, With no reminder. Following is a review of the CRC creation process: 1. 2. 3. 4. Get the raw frame Left shift the raw frame by n bits and the divide it by P. The reminder of the last action is the FCS. Append the FCS to the raw frame. The result is the frame to transmit And a review of the CRC check process: 1. Receive the frame. 2. Divide it by P. 3. Check the reminder. If not zero then there is an error in the frame. It can be easily seen that the CRC algorithm must compute the reminder of the division of two polynomials. The process is described in the following documents: Implementing the CRC algorithm in hardware Implementing the CRC algorithm in software The Most used CRC polynomials Following is a list of the most used CRC polynomials CRC-12: X^12+X^11+X^3+X^2+X+1 CRC-16: X^16+X^15+X^2+1 CRC-CCITT: X^16+X^12+X^5+1 CRC-32: X^32+X^26+X^23+X^22+X^16+X^12+X^11+X^10+X^8+X^7+X^5+X^4+X^2 +X+1 The CRC-12 is used for transmission of streams of 6-bit characters and generates 12-bit FCS. Both CRC-16 and CCRC-CCITT are used for 8 bit transmission streams and both result in 16 bit FCS. The last two are widely used in the USA and Europe respectively and give adequate protection for most applications. Applications that need extra protection can make use of the CRC-32 which generates 32 bit FCS. The CRC-32 is used by the local network standards committee (IEEE-802) and in some DOD applications.