Semantic Description and Discovery of Grid Services Using WSDL
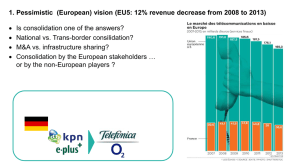
advertisement

Semantic Description and Discovery of
Grid Services using WSDL-S and QoS based
Matchmaking Algorithm
#Thamarai Selvi Somasundaram, R.A.Balachandar, Vyas Swaminathan, Ashwin Kumar, Venkatesh
Paramasivan
Department of Information Technology,Madras Institute of Technology, Anna University
Chromepet, Chennai – 600 044, stselvi@annauniv.edu
Abstract
This paper addresses the problem of describing and
discovering grid services semantically in a heterogeneous
grid environment. We propose a matchmaking system that
enables semantic descriptions of grid services using
WSDL-S. Also, the matchmaking algorithm proposed in
our system uses weighted QoS factors to match requests
with service advertisements. The semantic similarity
between the requested capability and that of the advertised
ones is determined using the respective domain ontology.
We also propose ontology clustering to group similar
categories of advertisements so that service discovery
becomes fast and accurate.
1.
INTRODUCTION
The Grid Architecture defined in [1, 2] facilitates
flexible, secure and coordinated resource sharing among
dynamic collections of individuals, institutions and
organizational resources. Currently, conventional Grid
Services use metadata to describe their capabilities.
However, simple metadata and queries provide a small and
insignificant improvement in information integration [5].
Fundamental research on the semantic web has allowed the
grid community to move from the current data centric view
supporting the Grid, towards a Semantic Grid with a set of
domain specific problem solving services and knowledge
services [4, 5]. The Semantic Grid supports flexible
collaboration and computation on a global scale with a
high degree of automation. In such an environment, it is
essential to provide facilities to the user for easy discovery
of the services and also to the service provider, a better
way to describe their services.
The matchmaking system proposed in this paper uses
WSDL-S to add semantics to the grid service concepts
[15]. The service matchmaking algorithm infers knowledge
from the description to discover closely related services.
We use user-defined weighted QoS factors to obtain the
suitable services that meet the user’s requirements. The
paper is organized as follows: - We discuss some of the
related work in section 2. Section 3 details the architecture
of the matchmaking system. Section 4 explains the
Weighted QoS factors considered for service matchmaking
and their illustration.
1-4244-0715-X/06/$20.00 ©2006 IEEE
Section 5 concludes the paper by highlighting the
advantages of the proposed matchmaking system and the
further scope for enhancement.
2.
RELATED WORK
The Globus Toolkit’s Monitoring and Discovery
System (MDS) defines and implement mechanisms for
service discovery and monitoring in grid environment [8].
However, MDS supports traditional service matching,
which is symmetric and attribute based. The literature [9,
10] also implements a grid service matchmaking system
that works purely based on attributes.
Currently, WSDL specification [7] is used to describe
service capabilities. However, it lacks the ability to provide
semantics to the service descriptions. Literature [11] uses
WSDL-S to enrich the semantics of the WSDL
descriptions. The OWL-S semantic description language
[12] aims to increase the meaning of web services by
annotating the data with Ontologies. However, OWL-S
based matchmaking algorithms consider Input and Output
parameters for service matching leading to the possibility
of retrieving irrelevant services.
In literature [3], QoS parameters are used for resource
discovery. It proposes various parameters viz., CPU cycles,
bandwidth, and memory space.
In this paper, we consider the QoS parameters as
suggested by [3]. In addition to that, we consider network
latency and reliability. The matchmaking algorithm
proposed in this paper, matches the QoS factors if multiple
advertised services meet the requested capabilities. It
allows the service requester to associate a weight to the
QoS factors defined by the matchmaking system. Also, we
describe an approach for describing grid services using
WSDL-S and a clustering mechanism to group the service
advertisements into different categories for faster discovery
of services.
3.
MATCHMAKING SYSTEM
Fig 1 shows the architecture and the various modules
involved in the matchmaking system. There are two major
building blocks of the system, namely the description
module and discovery module.
A Description Module
The description module enables semantic descriptions of
the grid services through WSDL-S. The Grid Service
Provider generates the WSDL based service description
file. This description only supports keyword based
discovery of grid services and lacks the expressiveness of
semantic annotations. Generally, ontology is used to
describe the concepts of a particular domain semantically
and Web Ontology Language (OWL) is used for creating
ontology [6, 13]. The primary limitation of OWL is that it
cannot be used for describing services. OWL-S is an
extension of OWL that describes the capability of web
services. However, converting the WSDL description of a
grid service into an OWL-S description is difficult and
complicates our design. Therefore, we use WSDL-S to
provide semantics to the concepts involved in the grid
service and thereby creating service advertisements. The
concepts considered in this research work includes the data
used in the service, input and output arguments of the
service, functionality offered by the service. This approach
allows the integration of non-semantic and semantic data in
the service description itself.
and stored in the UDDI registry. The clustering is based on
the functionality a service offers and a unique index is
provided to each cluster. This grouping minimizes the
number of advertisements to be compared against the
requested advertisements resulting in the quicker discovery
of the service requested.
B Discovery Module
The discovery module matches the service requests
against the service advertisements and returns the service
that meets the requested capabilities. The matchmaking
algorithm first identifies the suitable cluster containing the
services related to the functionality requested. Once a
suitable cluster is obtained, the algorithm retrieves the
advertisements from that cluster one by one and compares
the other parameters. With this approach, we eliminate
irrelevant services from being compared and this improves
the accuracy of the end results. Users may have different
QoS requirements with respect to the service requested, for
example, cost and reliability in addition to functionality,
inputs and outputs. Hence, when the service requests are
matched by multiple services on a grid, it becomes difficult
to choose the most appropriate service that meets the
requirements. A lot of research is going on in trying to
solve this problem. Devising a generic QoS based
matchmaking algorithm is a difficult task as users have
varied QoS requirements. Our algorithm attempts to solve
this problem by using several QoS factors associated with
user-defined weights for matchmaking. The discovery
module allows the users to specify their own priorities in
terms of weights to the QoS factors that the matchmaking
system supports. For example, a user might require a
highly reliable service provider more than one that could
process the request fastest. In this case, he would prioritize
reliability by giving it a higher weight than the other
factors. Based on the weighted QoS values, the discovery
module computes the overall QoS and selects the most
appropriate service.
4.
WEIGHTED QOS FACTORS
We model the QoS needed by a service request in
terms of six different factors viz., CPU cycles (CPU),
network bandwidth (NBW), disk space (DS), memory
buffers (MB), reliability (REL) and network latency (NL).
These factors can be computed as shown below:Fig.1: Matchmaking System
We use domain ontology for determining similarity
between the advertised and requested concepts. We define
domain ontology as an ontology in which all possible
concepts are described semantically. In such ontology,
each concept and its subconcept(s) represent some form of
knowledge present in the service. For example, the data
types of the input and output parameters of a service can be
represented well using the concept of ontology.
The clustering mechanism proposed in the system
enables faster discovery of intended grid services. This
module clusters similar WSDL-S descriptions into groups
CPU = 1 - (RrequiredCPU / SavailableCPU)
NBW =1 - (RrequiredNBW / SavailableNBW)
DS = 1 - (RrequiredDS / SavailableDS)
MB = 1 - (RrequiredMB / SavailableMB)
REL = 1 - (RrequiredREL / SavailableREL)
NL = 1 - (RrequiredNL / SavailableNL)
Where RrequiredCPU is the minimum CPU cycles required,
SavailableCPU is the CPU cycles available at the service
provider and so on. Therefore, Rrequired / Savailable must be
minimum and 1- (Rrequired / Savailable ) must be maximum for
a service provider to offer the highest Quality of Service.
The parameters representing available resources such as
SavailableCPU can be obtained from the service provider using
any Network Monitoring Tool such as Network Weather
Service (NWS) [14]. If the value of any of the QoS factors
is negative, that particular service cannot satisfy the user’s
requirements as the minimum requirement is greater than
the availability and is rejected. We define reliability as the
ratio between the number of successful responses from the
service provider (NoS) and the total number of service
requests to that service provider (ToS).
Reliability = {NoS / ToS}
----------
In this case, the user does not specify any priority
towards QoS. Hence, the matchmaking system distributes
∑wi equally to all QoS.
The Overall QoS for both the services S1 and S2 can
be calculated using (2) as
Overall QoS = ∑ (ASn * W)
For S1,
CPU NBW DS
MB
REL
NL
AS1
0.1
0.3
0.4
0.5
0.9
0.8
W
2
2
2
2
2
2
AS1*W
0.2
0.6
0.8
1
1.8
1.6
CPU NBW DS
MB
REL
NL
AS2
0.8
0.1
0.5
0.4
0.3
0.1
W
2
2
2
2
2
2
0.2
1
0.8
0.6
0.2
(1).
A separate java module is being developed to obtain
these QoS parameters periodically from the service
provider and will be providing the inputs to the
matchmaking system.
The parameters required by the service request such as
RrequiredCPU are obtained from the service requester. The
requester also specifies the priorities of the QoS in terms of
weights (W) to select a single suitable service when the
requested capabilities are met by more than one service.
The matchmaking system computes overall QoS requested
by the user as a function (f) of weighted QoS parameters as
shown in equation (2).
Overall QoS = ∑ (w1* CPU,w2* NBW,w3* DS,w4*
MB,w5* REL,w6* NL)
---------- (2)
where w is the weight associated with every QoS factor and
∑wi =No_of_QoS * n. n=2, 3, 4....
The value of ∑wi gives the maximum number of
weights available to the user which he has to distribute
amongst the QoS factors depending on his requirement.In
our case, since we considered six QoS factors, ∑wi is a
multiple of six. This helps the requester distribute the
weights in integral values. Also, if “n” increases, the
weights to be assigned to various factors can be
distinguished clearly and thereby enables the accurate
specification of priority.
Overall QoS = ∑ (AS1*W) =6.0
Similarly for S2,
AS2*W 1.6
Overall QoS=∑ (AS2*W) =4.4
With the overall QoS obtained for S1 and S2, we
observe that when the QoS factors are assigned default
weights, where the user does not prioritize his
requirements, the matchmaking selects S1 as the best match
for the user’s requirements. It also infers that the weights
considered may not have any effect in the ultimate
selection of services.
A Illustration
Case (ii)
We illustrate our QoS modeling and its effect on the
discovery of the best service in this section. For simplicity,
we consider the value of “n” as 2 and hence ∑wi=12.
We simulate the effect of default as well as user defined
weights on the accuracy of service discovery by assuming
a set of QoS factors for two different services S1 and S2.
We clearly distinguish the selection of services in both the
cases.
Let ASn be the set of QoS factors of the service Sn as
ASn = {CPU, NBW, DS, MB, REL, NL}.
We assume the values of the sets AS1 and AS2 for S1 and S2
as follows:AS1= {0.1, 0.3, 0.4, 0.5, 0.9, 0.8}
AS2= {0.8, 0.1, 0.5, 0.4, 0.3, 0.1}
Let us consider another case in which the user wishes
to give CPU cycles and NBW a higher priority than the
other four factors. With the same set of QoS factors for
both S1 and S2, we compute overall QoS as shown below:For S1,
CPU NBW DS
MB
REL
NL
AS1
0.1
0.3
0.4
0.5
0.9
0.8
W
4
4
1
1
1
1
AS1*W
0.4
1.2
0.4
0.5
0.9
0.8
Case (i)
Overall QoS=∑ (AS1*W) =4.2
For S2,
CPU NBW DS
MB
REL
NL
AS2
0.8
0.1
0.5
0.4
0.3
0.1
W
4
4
1
1
1
1
0.4
0.5
0.4
0.3
0.1
AS2*W 3.2
Overall QoS=∑ (AS2*W) =4.9
Comparing the overall QoS of S1 and S2, the
matchmaking system infers that S2 is a better match for the
user's requirements than S1. With this illustration, we argue
that the proposed matchmaking system reduces the
ambiguity in the discovery of services and gives the user
more flexibility in specifying his requirements.
5.
CONCLUSION
In this paper, we propose a matchmaking system that
provides grid users with a perfect platform to describe and
discover their grid services semantically. The QoS based
matchmaking algorithm provides a flexible discovery
mechanism offering a means to the user to control the
result set. Further, with effective clustering techniques, we
believe that the algorithm enables faster discovery of
services, eliminating irrelevant services from the result set.
ACKNOWLEDGEMENT
This research is being carried out to contribute to
GARUDA –The National Grid Computing Initiative by the
Centre for Development of Advanced Computing, India
funded by Ministry of Information Technology,
Government of India. The authors express their sincere
thanks to the Centre for Development of Advanced
Computing, India for providing financial assistance to this
research work.
REFERENCES
[1] Foster and C. Kesselman (eds), “The Grid: Blueprint
for a New Computing Infrastructure”, Morgan
Kaufmann, 1999, 259-278.
[2] Foster, C. Kesselman, and S. Tuecke, “The Anatomy
of the Grid: Enabling Virtual Organizations”,
International Journal of High Performance Computing
Applications, 15(3), 2001, 200-222.
[3] Yun Huang and Nalini Venkatasubramanian: QoSbased Resource Discovery in Intermittently Available
Environments. Dept. of Information & Computer
Science,University of California, Irvine. Proceedings
of the 11th IEEE International Symposium on High
Performance Distributed Computing HPDC-11 2002
(HPDC’02).
[4] David De Roure, Nicholas R. Jennings and Nigel R.
Shadbolt, “The Semantic Grid: A future e-Science
Infrastructure”, Grid Computing – Making the Global
Infrastructure a reality, John Wiley & Sons, Ltd,
2003.
[5] M.Li, P.Van Santen, D.W.Walker, O.F.Rana,
M.A.Baker, “sGrid: a service-oriented model for the
Semantic Grid”, Future Generation Computer Systems
20, July 2004, PP 7-18
[6] David De Roure, Nicholas R. Jennings and Nigel R.
Shadbolt, “The Semantic Grid: Past, Present, and
Future”, Proceedings of the IEEE, Vol.93, No.3,
March 2005, PP 669-681.
[7] Web Services Description Language (WSDL) Version
2.0 Part 1: Core Language W3C Candidate
Recommendation 27 March 2006.
[8] www.globus.org/toolkit/mds
[9] M.Solomon, R.Raman, M.Linvy, “Matchmaking
distributed resource management for high throughput
computing”, In proceedings of the Seventh IEEE
International Symposium on High Performance
Distributed Computing, Chicago, IL, July 1998.
[10] Portable batch system, http://pbs.mrj.com.
[11] Sheth, K. Verma, J. Miller and P. Rajasekaran
(University of Georgia), "Enhancing Web Service
Descriptions using WSDL-S," Research-Industry
Technology Exchange at EclipseCon 2005,
Burlingame, CA, Feb. 28 - Mar. 3, 2005.
[12] http://www.daml.org/services/owl-s/
[13] OWL Web Ontology Language Overview. W3C
Recommendation, 10 February 2004
[14] R.Wolski, N.Spring, and J.Hayes, “The Network
Weather Service: A Distributed Resource Performance
Forecasting Service for Metacomputing”, Journal of
Future Generation Computing Systems, Volume 15,
Numbers 5-6, pp.757-768.
[15] Rama Akkiraju, Joel Farrell, John Miller, Meenakshi
Nagarajan, Marc-Thomas Schmidt, Amit Sheth,, Kunal
Verma, LSDIS Lab, University Of Georgia, IBM
Software Group, ”Web Service Semantics - WSDL-S”.
7 November 2005.