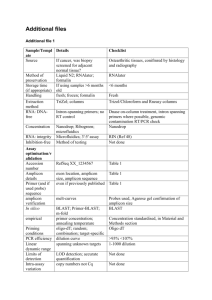
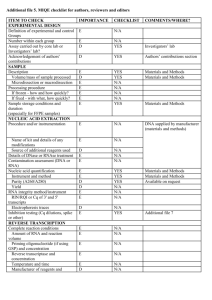
BIODIVERSITY ASSESSMENT OF INSECTS FROM
advertisement

Biodiversity Assessment of Insect from Environmental Samples Using qPCR and Next-Generation Parallelized Sequencing of DNA Barcodes by Saina Taidi A Thesis Presented to The University of Guelph In partial fulfillment of requirements for the degree of Master of Science in Integrative Biology Guelph, Ontario, Canada © Saina Taidi, August, 2012 ABSTRACT Biodiversity Assessment of Insect from Environmental Samples Using qPCR and Next-Generation Parallelized Sequencing of DNA Barcodes Saina Taidi University of Guelph, 2012 Advisor: Mehrdad Hajibabaei This thesis employs three bioindicator species of mayfly (Insecta: Ephemeroptera) and three of caddisfly (Insecta: Trichoptera) as models to develop a reliable biodiversity and biomonitoring assessment approach by using quantitative PCR (qPCR) and next generation sequencing (NGS) technology. Quantitative PCR was employed to assess the efficiency of species-specific PCR primers in amplifying their target species versus other taxa from closely or distantly related taxonomic groups from benthic habitats. Results showed qPCR can be used as a practical test for evaluating PCR primers for amplifying specific taxa in mixed environmental samples although it might be influenced by amplification bias. Target specific primers are an alternate to presumably universal primers. Each primer set can be tested and optimized using qPCR prior to use in nextgeneration sequencing. qPCR results showed corroboration with 454 pyrosequence data and hence it can be used in experimental design procedure for NGS based biomonitoring which could indicate that qPCR is a useful tool for selecting primers in the NGS amplicon preparation. ACKNOWLEDGMENTS First and foremost I offer my sincerest gratitude to my supervisor, Dr. Mehrdad Hajibabaei, who has supported me throughout my thesis with his patience and knowledge. I attribute the achievement of my Master’s degree to his encouragement and assistance. Without his advice, this thesis would not have been written or completed. One simply could not wish for a better or more friendly supervisor. I would like to especially thank Dr. Teresa Crease for all her support both as my committee member and as Graduate Coordinator. I will never forget her kind support; nobody could wish for a better professor. Many thanks to my co-adviser, Dr. Paul Hebert, who supported me with his constructive opinions; it was a great honour for me to have such opportunity to have his guidance through my project. I also had such an unforgettable time in Dr. Donald Baird’s lab. Also many thanks to Dr. Baird and his team, especially Kristie Heard, who supervised my very first experience in sample collection and species identification. Heartfelt thanks to my dear friends and lab mates Claudia, Jennifer, Steve, Connor, Joel, Ian and Stephanie, who blessed my everyday work brain storming and having a good time together as well. Special thanks to Shannon who was always there to support me in more ways than anyone can expect. Many thank to Dr. Shady Shokarallah, who helped me throughout this journey not only by his scientific knowledge, but with his great attitude and encouragement to keep on going. I definitely would not be here without his great support. I am deeply lucky to have friends who helped me maintain the courage to write and to move forward. I would like to thank all of them, near or far, for their support and encouragement. iii My especial thank to Ahmed Al-Wattar, Margaret Hundleby and Shawn Kehoe, who read over my thesis and provided great comments, explaining their concerns and paying careful attention. Thanks to the great help of Xin Zhou and Terri Porter who helped me in learning the strategies for classic taxonomic identification and bioinformatics analysis of my data. Susan Mannhardt, with her extra busy schedule, was always there to answer all questions and support me in all aspects of the administrative process. Also I would like to thank Mary-Ann Davis, Karen White, Lori Ferguson and all the IB department staff. I would like to thank to all of my colleagues and friends at Biodiversity Institute of Ontario, especially Natalia Ivanova, for aid with laboratory protocols and workshops on sequence editing. Finally I would like to thank especially my mother and father for all their love and support they gave me in my life, and also my sisters and brother for their love and support. iv Table of Contents LIST OF TABLES ....................................................................................................................... vi LIST OF FIGURES ................................................................. viError! Bookmark not defined. LIST OF APPENDICES ......................................................... viError! Bookmark not defined. INTRODUCTION......................................................................................................................... 1 The challenges of biodiversity analysis ...................................................................................... 2 Biodiversity and biomonitoring .................................................................................................. 2 DNA information and biodiversity analysis ............................................................................... 4 DNA barcoding: standardized molecular biodiversity analysis.................................................. 5 Next-Generation sequencing for biomonitoring ......................................................................... 6 Quantitative PCR ........................................................................................................................ 7 Why qPCR? ................................................................................................................................ 9 Objectives ................................................................................................................................. 10 MATERIAL AND METHODS ................................................................................................. 11 Target species selection and specimen collection ..................................................................... 11 DNA extraction ......................................................................................................................... 12 Primer design and optimization ................................................................................................ 12 Sanger sequencing validation of amplicons .............................................................................. 14 Quantitative PCR ...................................................................................................................... 14 v 1. Template selection and normalization .............................................................................. 14 2. Experimental design.......................................................................................................... 14 3. Reaction conditions for qPCR experiments ...................................................................... 15 4. Data analysis ..................................................................................................................... 16 454 pyrosequencing .................................................................................................................. 18 1. Experimental design.......................................................................................................... 18 2. Multiplexing amplicons .................................................................................................... 18 3. Amplicon preparation ....................................................................................................... 19 4. 454 Pyrosequencing amplicon library preparation ........................................................... 20 5. 454 data analysis framework ............................................................................................ 20 Automated sequence filtering ................................................................................................... 21 Manual sequence analysis ......................................................................................................... 22 RESULTS .................................................................................................................................... 23 Quantitative PCR Results ......................................................................................................... 23 Relative Amplified Copies (RAC) Analysis ............................................................................. 25 Quantitative and qualitative analysis of pyrosequencing reads ................................................ 26 vi DISCUSSION .............................................................................................................................. 29 Primer behaviour in multi-template PCR ................................................................................. 30 Quantitative PCR as a tool for target identification .................................................................. 31 Optimal NGS analysis of target genes and taxa........................................................................ 32 Comparing qPCR and 454 results ............................................................................................. 34 Towards an standardized approach for metagenomics analysis of environmental DNA ......... 35 REFERENCES ............................................................................................................................ 37 TABLES ....................................................................................................................................... 44 Table 1: Species-specific oligonucleotide primers ................................................................... 44 Table 2: gDNA extracts concentration from target species ...................................................... 45 Table 3: 454 Pyrosequencing tagged primers ........................................................................... 46 Table 4: CT Values of target species setA (Trichoptera) .......................................................... 47 Table5: CT Values of target species setA (Ephemeroptera) ...................................................... 48 Table 6: CT Values of target species setB (Trichoptera) ........................................................... 49 Table 7: CT Values of target species setB (Ephemeroptera) ..................................................... 50 Table 8: Summary results from qPCR & 454 pyrosequencing analysis ................................... 51 Table 9: Slope and efficiency rates for primer set A and B amplicon-based material ............. 52 Table 10: Read numbers for gDNA-based material, automated analysis ................................ 53 Table 11: Read numbers for amplicon-based material, automated analysis ............................. 54 vii Table 12: Read numbers for gDNA based material, manual analysis ...................................... 55 Table 13: Reads numbers for amplicon based material, manual analysis ................................ 56 FIGURES ..................................................................................................................................... 57 Figure 1: Amplification plot sample ......................................................................................... 57 Figure 2: The workflow used in qPCR experiments ................................................................ 58 Figure 3: 454 pyrosequencing experimental workflow ............................................................ 59 Figure 4: Exemplar standard curves for qPCR experiments (gDNA based) ............................ 60 Figure 5: Exemplar standard curves for qPCR experiments (amplicon based) ........................ 61 Figure 6. Exemplar Relative Amplified Copies (RAC). ........................................................... 62 Figure 7. MID distribution for gDNA based material. ............................................................. 63 Figure 8. MID distribution for Amplicon based material. ........................................................ 64 APPENDIX 1: Standard curves for target samples, gDNA based .............................................. 65 APPENDIX 2: Standard curves for target samples, amplicon based .......................................... 69 APPENDIX 3: 454 pyrosequencing analysis results .................................................................. 73 viii INTRODUCTION Biodiversity is the diversity of genes, species and ecosystems, or the variety of every living organism and can be defined at many different levels, from allelic diversity and heterozygosity to the variation of population distribution in a region (Lovejoy, 1997). Today, the concept of biodiversity within conservation biology is not only focused on the subject of species diversity or endangered species but also on other aspects of biodiversity that focus on practical applications such as water quality analysis, conservation biology or measuring the health of biological resources . Biodiversity and its impact on other fields of biological sciences has long been a subject of fascination for scientists around the world. Modern biodiversity analysis started with the work of Linnaeus almost 250 years ago, and yet even today only a small fraction of the world’s species are known to humanity. The greatest diversity exists among insects, which account for more than one million of the planet's named animal species. From the canopy of the tropical rain forests to ocean floor, it is estimated that millions of undescribed insect species and other organisms exist (Mora et al. 2011). All together, the earth's oceans and continents support close to 50,000-55,000 species of vertebrate animals and 300,000-500,000 species of plants, with anywhere from 10 to 100 million species still to be identified (Mora et al. 2011). A new study used a statistical approach to estimate the total number of species to be 8.7 million (Mora et al. 2011). However, the authors recognize limitations of current direct methods for estimating biodiversity. 1 The challenges of biodiversity analysis Biodiversity is fundamentally concerned with measuring the number of species and how they combine to form communities and ecosystems. The most common way of studying this is to characterize the differences between species using different traits such as body size, physiological tolerance and body shape or even by habitat preferences (Bonada et al. 2006). However, it is important to note the difficulty of measuring these characteristics easily and accurately for biodiversity analysis. There are bottlenecks such as difficulties in the identification of species at different life stages (such as difficulties in identifying larvae) or sometimes measuring the biodiversity based on this method is more difficult when parameters such as species richness or the increase in consistency (evenness) distributes more equally among these species. Although biodiversity measurements are based on counting the abundance of species in a target environment, the ability of research scientists to conduct measurements on a large scale is an important factor in the efficacy of any method. When considering species-rich ecosystems such as in the tropics, analyses become more complicated and the nature of these complex ecosystems makes biodiversity assessment much more difficult. Biodiversity and biomonitoring Biological monitoring or biomonitoring is the systematic utilization of biological responses to assess and monitor changes in the environment with the intention of using that information in environmental assessment programs (Bonada et al. 2006). The utilization of environmental bio-indicators has become one of the common methods for evaluating the health of a 2 target environment. In general, bio-indicators are defined as taxa that can respond to environmental changes or disturbances in a way that can be observed and measured (quantified). The sensitivity of an organism’s reactions to environmental changes and the capacity of scientists to measure them are important factors in selecting bio-indicators (Hajibabaei, et al., 2011; Nash, 1989; Noss, 1990). Biomonitoring of water quality can occur in freshwater or marine water. Freshwater biomonitoring can occur in lentic (lakes and ponds) or lotic (rivers and streams) inland waters. Organisms that live in the bottom subtracts (sediments, debris, logs, macrophytes, filamentous algae, etc.) of freshwater habitats (lentic and lotic) for at least part of their life cycle are considered benthic. Benthic macroinvertebrates refers to animals that inhabit the bottom substrate for at least part of their life cycle and are retained by mesh sizes ≥ 200 to 500 µm ( Rosenberg et al., 1993; Suess, 1982; Ward et al., 1986). The processing of benthic macroinvertebrate specimens using classical taxonomic approaches is an important barrier to the development of biomonitoring processes especially when applied to large-scale programs such as the biomonitoring of freshwater to indicate the quality of a target stream. Moreover, this type of bottleneck can also occur at the sample collection, sorting and preparation stages. The identification of larvae has always been a major bottleneck in biomonitoring studies involving benthic macroinvertebrates (Bonada et al. 2006). The routine biomonitoring process relies on the identification of one specimen at a time, which requires experienced technicians, sufficient time and funds to complete the process. Another difficulty found within taxonomy-based biomonitoring is the depth of the identification. Although keys exist for the identification of species, they are not comprehensive and are lacking in descriptions of all life stages of target species. 3 DNA information and biodiversity analysis Without genetic diversity, a population loses the ability to evolve and adapt to environmental changes. Genetic diversity has an impact on intraspecific levels of biodiversity. Hence, the study of genetic variation is central to biodiversity analysis. In order to accurately identify species based on genetic information one needs to focus on genetic information that varies between species and not among members of the same species. However, traditionally, the characterization of species has been studied based on morphological characteristics. Nevertheless, morphological inconsistency is one of the main issues that scientists are faced with; diagnose the characteristics may not be apparent at all life stages of an organism’s development and its appearance may be influenced by environment factors. Today, many different genetic markers and techniques have been introduced to assess genetic variation as a complementary tool to aid traditional approaches (Roesch et al. 2007; Gill et al. 2006; Limpiyakorn et al. 2006). Molecular biology tools have provided useful information on the diversity of target organisms through the detection of variation at the molecular level (mainly DNA and proteins). The reliable identification of organisms is an essential and important ability that these techniques can provide within evolutionary, ecological and environmental studies. There are many instances in which genetic tools could give better resolution in the identification of species when barriers in identification processes exist. There are a number of different techniques which are available for genetic identification. The priority of choosing one technique over another is dependent on the material that is being studied or the nature of the questions to be addressed. DNA barcoding is one of the DNA-based techniques that have been used for studying biodiversity and molecular evolution. 4 DNA Barcoding: Standardized molecular biodiversity analysis DNA barcoding(Floyd, et al., 2002; Hebert, et al., 2003) is a relatively new molecular approach that uses a short uniform sequence of DNA to identify species across taxonomic groups. A 650 base pair region near the 5’ end of the mitochondrial gene cytochrome c oxidase 1 (COI) has been suggested as a DNA barcode for animals. Subsequently (Hebert and Gregory, 2005; Smith, et al., 2008), DNA barcoding has gained momentum in biodiversity studies as a standard species identification method (Frézal and Leblois, 2008; Hajibabaei et al., 2006). DNA barcoding can differentiate between morphologically cryptic species more efficiently than other methods; however it does not eliminate the need for traditional taxonomy. Beyond its use as an identification technique, it has been suggested that DNA barcoding can be used to expand our understanding of phylogenetic and population-level differentiation, although DNA barcode sequences are often not appropriate for comprehensive phylogenetic analyses. Some studies have questioned the ability of COI barcodes to distinguish between species from certain taxa, such as hybrids and in recently diverged species (Munch, et al., 2008). These critics propose that COI should be used in concert with nuclear genes to yield more robust conclusions. Additionally, alternative genes have been proposed as DNA barcodes for plants and fungi (Hollingsworth, et al., 2009). In cases where DNA in a specimen is degraded, it has been shown that even a partial fragment of DNA barcode, a mini-barcode, can provide species-level resolution (Meusnier et al., 2008). These mini-barcodes can often provide DNA barcode information in situations where a full-length barcode cannot be retrieved. These cases include museum samples with potentially degraded DNA as well as environmental samples in which next generation sequencing methods (that can currently produce sequence reads less than 500 bases) are needed. 5 Next-generation sequencing for biomonitoring Although DNA barcoding contributes to taxonomic research and biodiversity analysis by identifying unknown specimens, some important issues need to be considered concerning the possible applications of barcoding to the analysis of bulk environmental samples. For example, is it possible to analyze and barcode all species in an environmental sample without separating them to individuals? If so, would it then be possible to quantify species abundance by analyzing bulk samples? Next Generation Sequencing (NGS) platforms may aid in answering these questions. While Sanger sequencers work on single specimens, NGS devices such as 454-FLX (Margulies et al., 2005) can read the sequence of thousands to millions of DNA fragments. However, one of these technologies, massively parallelized pyrosequencing, which is currently implemented in the Roche 454 device, has three characteristics that make it suitable for the analysis of biodiversity in a large number of DNA templates, such as DNA extracted from bulk environmental samples: 1) high throughput, 2) the ability of parallel sequencing, and 3) the ability to read a relatively long length of sequence (currently 250-400 bases). The third characteristic is especially important for accurate identification of biota in environmental samples, as the alternative technologies produce short sequence reads incapable of distinguishing taxa in complex environmental samples (Claesson et al. 2010). Therefore, through the use of a 454 pyrosequencer, it is possible to gain sequence information from DNA barcodes and to use bioinformatics to compare this information to standard barcode libraries to assess biodiversity in an environmental sample. 454-pyrosequencing produces large amounts of data at low cost as well as providing a method for sequencing environmental DNA without a former cloning step. To date, 454-pyrosequencing technology has mainly been used in environmental studies involving bacteria. While the use of DNA barcoding combined with next 6 generation sequencing offers great potential in broadening the application of DNA barcodes, such protocols have not been fully developed. The goal of a new technology development project at the Biodiversity Institute of Ontario is to optimize protocols for data generation and bioinformatics analyses of an environmental barcoding system for biomonitoring applications. The 454-FLX pyrosequencing facility has been generating data from sentinel groups, such as benthic macro-invertebrates including mayflies (Ephemeroptera), stoneflies (Plecoptera), and caddisflies (Trichoptera) called “EPTs”. Because of their sensitivity to environmental changes, EPTs are key taxa for environmental biomonitoring studies for freshwater quality assessments (Bonada et al. 2006). If these taxa are to be used in environmental barcoding using a pyrosequencing approach, we need to understand and optimize recovering their DNA barcode sequences directly from environmental samples. Although groundbreaking work at BIO has proved this approach feasible (Hajibabaei et al. 2011), molecular tools for assessing multi-template Polymerase chain reaction (PCR) prior to pyrosequencing analysis are not available. This thesis employs six bioindicator species of Ephemeroptera and Trichoptera (three species from each order) as a model to assess various factors in developing a reliable biodiversity and biomonitoring assessment approach by using pyrosequencing. Quantitative PCR technology will be employed to assess the behavior and efficiency of PCR primers used in the multi-template PCR necessary to perform amplicon-based pyrosequencing. Quantitative PCR The polymerase chain reaction (PCR) can produce millions of copies of a particular DNA sequence in approximately 1.5-2 hours. This automated process avoids the use of cloning and 7 bacteria to amplify DNA. Real-time polymerase chain reaction or quantitative polymerase chain reaction (qPCR) is similar to normal PCR, but the PCR amplicons are detected and quantified as they are generated. Hence, qPCR has been used for quantifying the PCR product of one or more specific sequences in a DNA sample. Preliminary efforts to manage the quantifying power of PCR have been faced with limitations such as generating data by removing an aliquot of reaction at specific cycles, making a serial dilution of PCR product or in some cases by including an internal control (Becker et al., 1996; Kennedy, 2011; Ozawa et al., 1990; Piatak et al., 1993; Roux, 2009). Although these methods are able to quantify the PCR product to some extent, they are time consuming and labour intensive so the use of these methods has been limited. Quantitative PCR has had a great impact on molecular biology and simplified quantification. The mechanism of this technique is based on monitoring the amount of fluorescence in each cycle, which is produced by a dye that binds to the PCR amplicon as it is generated. The amount of PCR product can be plotted as a function of cycle number. By this new method there is no longer a need to actually sample a reaction at various cycles or to use labor intensive techniques to predict the exponential phase. This technique recognizes the exponential region by plotting fluorescence on a logarithmic plot. The preliminary cycle occurs when the fluorescence level is significantly higher than background levels, which represents the initial template amount. The quantification cycles (Cqs) are determined by a fluorescence threshold (The term, “CT value” is the number of cycles required for each template to pass the threshold). Figure 1 provides an example of the differences in CT value and cycle number which may be detected in a qPCR experiment. 8 Why qPCR? Although PCR-based techniques have had a great influence on the field of molecular biology, the post PCR analysis methods used to analyze its results are limited. Gel electrophoresis is one of the most common techniques for visualizing PCR products. Although it is fast, easy and inexpensive, it cannot distinguish between different products with the same molecular weight. Soon after the introduction of qPCR in 1996, it became an everyday tool in molecular labs; Quantitative qPCR machines have simplified amplicon recognition by providing the ability to monitor amplifications during each cycle. All available instruments designed for qPCR experiments measure the progress of PCR amplification by tracking the changes in the fluorescence level coming from each amplicon, in each cycle within each PCR reaction. In addition, these measures can be taken without opening the instrument so the risk of contamination decreases significantly. Quantitative PCR offers many advantages for quantitative analysis and detection of specific target genes and has been widely used in research and diagnostics. The ability to monitor the reaction constantly, rapid running time, potential for high throughput analysis, high sensitivity (~ 3pg or 1 genome equivalent of DNA) and wide range as it can detect across 101010 copies of target DNA are some of the advantages of qPCR . Conversely, there are disadvantages of this technique such as limited capacity for multiplexing, the requirement for high levels of optimization and the need for high technical skills above those required for normal PCR. In this study, I employ qPCR to evaluate primer-binding affinities in different primer sets used in multi-template PCR amplification of bulk environmental samples prior to pyrosequencing. 9 Objectives The objectives of this study are to improve the present understanding of the patterns and processes obtained using molecular information from DNA barcodes in biodiversity assessment using species from two orders of the class Insecta as models. More specifically, an attempt will be made to examine the use of barcoding as a tool for biodiversity assessment and biomonitoring of environmental samples. I predict that the results from pyrosequencing will be more robust in obtaining a comprehensive species-level biodiversity measure from bulk samples at a much faster pace than other approaches such as cloning and Sanger sequencing. I predict that the primers that bind to specific sites (100% matching) in the target species will lead to better amplification efficiency as reflected in qPCR analysis. Moreover, the proportion of pyrosequencing reads obtained from a mixed template PCR analysis will reflect the amplification efficiency of qPCR for each target-specific primer set. 10 MATERIAL AND METHODS Target species selection and specimen collection Three local species from the insect order Trichoptera (Ceratopsyche bronta, C. sparna, and Chimarra obscura) and three local species from the insect order Ephemeroptera (Maccaffertium interpunctatum, M. modestum, and Caenis diminuta) were selected to test the effect of primer bias. In both cases, two species were selected from the same genus and one species was selected from another distantly related genus in the same family. These insect orders were selected because of their importance in freshwater biomonitoring programs. Target species were chosen because of their abundance and availability, which allows access to fresh material for downstream analyses. Three sampling sites were selected for this study. The first two were near Fredericton, New Brunswick. These sites were the Marysville Bridge on the Nashwaak River (45°59'4.19"N, 66°35'29.40"W), and the Renous River (46°47'46.65"N, 66°11'58.52"W). The third site was on the Grand River in Ontario (43°50'0"N, 80°25'0"W) close to the Elora Conservation Area. Both adult and larval insect samples were obtained from all three sites during the spring and summer of 2009. A light trap technique was used to collect adults, and each individual was placed in a 1.5 ml tube containing 95% ethanol. A total of 140 Trichoptera individuals from the two New Brunswick sites were placed in separate empty tubes, frozen overnight and pinned and identified using the taxonomic key on the next day. To select target samples, a total of 279 individual insects from the 6 species were all either pinned or sorted in ethanol from the three sites, and were tentatively classified on the basis of morphological characteristics, and sorted into three 96-well plates. 11 DNA extraction A single leg from each individual was placed into a 10 MP lysing matrix tube (MP Biomedicals Inc., Solon, Ohio USA) and homogenized using the MP FastPrep-24 Instrument (MP Biomedicals Inc.) set at “6” for 30 seconds. DNA was extracted from each homogenized tissue sample using a NucleoSpin tissue kit (MACHEREY-NAGEL Inc. Bethlehem, Pennsylvania , USA) following the manufacturer’s instructions. The DNA was eluted with 70 l of molecular biology grade water pre-warmed to 70 °C. Primer design and optimization Routine DNA barcoding of target samples followed standard COI barcoding protocols (Hajibabaei et al., 2005). A full-length COI DNA barcode was amplified using the LCOI490/HCO2198 primers (Folmer et al., 1994). In order to evaluate primer binding bias, additional primers were designed with 100% match to the sequence of the target species. Previous studies focusing on the amount of DNA barcode sequence information needed for species differentiation and resolution have shown that a partial fragment of the standard COI barcoding region can be informative enough to discriminate species in most groups (Hajibabaei et al., 2006; Hollingsworth et al., 2009; Janzen et al., 2005). Following these studies and by taking advantage of available barcode sequences (for primer design), the species-specific primers were designed within the COI standard barcode region. After aligning the available barcodes for the target species, two regions for designing primers were selected. Twelve primer sets were designed in total: six were designed near the 5’ end of the COI DNA barcode region (Set A) and the other six primer sets were designed (Set B) 12 at the 3’ end of the DNA barcode region. Primer Set A targeted a 143bp amplicon of the COI barcode region and Primer Set B targeted a longer fragment of 305bp at the opposite end of the COI barcode region. The routine primer design conventions, including high G+C content (more than 50%), minimal secondary structure, primer length and self complementarities were considered (Aird et al., 2011; Lakes, 2001). Primers were checked for routine primer designing rules using tools available on the Integrated DNA Technologies, Inc (Coralville, Iowa, USA) website and produced by the same company. All primers were received in lyophilized tubes, and diluted to 10mM working solutions (molecular biology grade water). Table 1 provides details of primer codes and their nucleotide sequences. The PCR mixture consisted of 17.5 l molecular biology grade water, 2.5 l 10X reaction buffer, 2mM of 50 mM MgCl2 , 0.2mM of 10 mM dNTPs mix, 0.2μM of 10μM, 0.2 μM of 10μM reverse primer and 5 U/ μl Invitrogen’s Platinum Taq polymerase in a total volume of 25 μl. The amplification regime was set to initial denaturing at 94°C for one min, followed by 4 cycles of denaturing at 94°C for 40 s, annealing at 45°C for 40 s and extension at 72°C for one min. For the next 35 cycles, the annealing temperature was increased to 50°C, followed by final extension at 72°C for 10 min. Amplicons were visualized on 1.5% agarose gel using 0.3 l of ethidium bromide for 5 μl of each PCR product in TE 10X buffer. A consensus optimal condition (considering factors affecting PCR) was selected by running test PCRs for each primer set for each species and selecting the condition where all primer sets provided amplicons with relatively similar intensity on Agarose gels. For example, an optimal annealing temperature of 50°C was selected after gradient PCR was done at varying annealing temperatures of 40°C, 43.5°C, 46°C, 50°C and 55°C. 13 Sanger sequencing validation of amplicons Amplicons were verified to correspond to the targeted fragment of the COI barcode region by direct sequencing using a bidirectional Sanger sequencing approach utilizing BigDye chemistry version 3.1 (Applied Biosystems). Excess primers and dNTPs were removed from the sequencing reaction using EdgeBio’s AutoDTR96 (Gaithersburg, MD, USA), after which, the purified products were visualized on an ABI 3730xl sequencer, Applied Biosystems (Foster City, CA, USA). Quantitative PCR Figure 2 provides an overview of the qPCR experimental workflow. Below I provide the details of major steps in this workflow. 1. Template selection and normalization Quantitative PCR experiments were performed using three dilutions of DNA extracts (101 , 10-2 and 10-3) starting with the same concentration (250 ng/µl) in all tested specimens. Additionally, normalized and purified amplicons from each species (amplified barcode region using standard barcoding primers) were used as the DNA template for qPCR in six different normalized dilutions. 2. Experimental design Measurements with the Nanodrop spectrophotometer showed the DNA concentration acquired from target species (Table 2). Quantitative PCR optimization was performed for 14 dilutions of 10-1, 10-2 and 10-3 for normalized genomic DNA extracts (250 ng/µl), whereas for purified amplicon-based material (70 ng/µl), six dilutions (10-1, 10-2, 10-3, 10-4, 10-5, and 10-6) were used. The experiment was designed as a matrix so that the PCR product for each species matched with its own primers and every other primer. The matrix layout also allowed the primer behavior among all target species to be studied. Three dilutions (1000, 250 and 50 pg/ µl) were subsequently tested in qPCR (see below). To obtain a presumably equal number of the target DNA template and to avoid fluctuations in gene/mitochondrial copy number, normalized DNA extracts were used as a template to produce an amplicon from the standard barcode region (Figure 2) that was then used as template for subsequent qPCR analyses. Primer set, LCOI490/HCO2198 (Folmer et al., 1994) was used to amplify the full-barcode amplicons. The same PCR condition for amplicon preparation used for Sanger sequencing was used for preparation of amplicon based material. All amplicons were purified using the QIAquick 96 PCR Purification Kit (Qiagen Inc. Toronto, Ontario, Canada) and subsequently quantified using the NanoDrop spectrophotometer ND-1000 (V3. 3.0), and normalized on the basis of the least concentrated amplicon. 3. Reaction conditions for qPCR experiments QuantiTect SYBR® Green PCR kit (Qiagen) and Eppendorf Mastercycler® ep realplex Thermal Cyclers were used for all qPCR experiments. Based on primer optimization results, the annealing temperature was set at 50°C for all subsequent qPCR experiments. Other PCR variables were optimized as well. For example, the concentration of MgCl2 was set to 7mM final concentration instead of 2mM. Likewise, primer concentration was set to 900 nM after testing 300 nM, 600 15 nM, 900 nM and, 1200 nM. PCR reactions also included 2x quantitech SYBR green PCR master mix (12.5 l per reaction), 2 l of DNA template (for both genomic DNA and full-barcode amplicons as template) and, RNAse-free water to a total volume of 25 l for each reaction. 4. Data analysis All qPCR experiments were performed in triplicate to determine the stability of the results and the average of the three replicates was used for the qPCR analysis (Rieu and Powers, 2009; Udvardi, et al., 2008). Standard curves were generated from the machine default software and the logarithm of relative amplification and threshold cycle (CT) values were determined. The CT value is used commonly in reporting qPCR results and corresponds to the cycle number in which the fluorescent signal of the reaction passes the threshold line. The CT value is inversely related to the amount of starting template. Assuming that PCR is operating with 100% efficiency, the copy number of amplicons doubles every cycle. The Eppendorf analysis software (Eppendorf mastercycler ep, realplex 2.0) was used to analyze the results; CT values were recorded with a default threshold setting of 100 and an automatic mode baseline setting for all target specimens. To ensure consistency of qPCR experiments in different target species and primer combinations, a standard curve was generated for each primer/species using the CT value with the threshold set at 100 in 6 different dilutions. To describe the difference between the CT value of the target gene and the CT value of the corresponding gene (COI), ∆CT value is calculated: ∆CT = CT (target species with specific primers) – CT (non target species with the same primers) 16 I used 2∆CT to calculate the copy number of generated amplicons in sample A relative to that in sample B. For example if ∆CT between species A and B is 7 cycles (it takes 7 more cycles to see amplification of A), then there is: 27 = 128 times more B than A 17 454 pyrosequencing 1. Experimental design Amplicon-based metagenomics analysis is one of the major applications of next generation sequencing (NGS) technology in biodiversity science. The amount of data produced by NGS technology provides insights into the diversity of organisms in bulk samples in an unprecedented way. Specifically, for amplicon-based analysis of biodiversity, Roche 454pyrosequencing technology has been the most practical choice since this technology produces longer reads as compared to other available NGS options, namely Illumina and SOLiD (Pandey et al., 2011). Since 454 pyrosequencing and other NGS approaches are becoming the main tools for the analysis of mixed environmental samples, I used two experimental mixtures to test primerbinding properties in 454 experiments. The first mixture consisted of an equimolar pool of the DNA extracts from all six target species, while the second included an equimolar pool of purified full-length COI DNA barcode amplicons of the target species (following the same procedure as amplicon-based qPCR analysis described above). Full-length DNA barcode amplicons of each target were normalized to 70ng/µl, and a 10-3 dilution (1µl of PCR in 999µl of water) was used to prepare the equimolar pool (Figure 3). 2. Multiplexing amplicons In order to combine sequencing reactions for multiple specimens in a single 454 sequencing lane and further separate and track individual 454 sequencing reads, Multiplex Identifier sequence tags/ molecular barcodes (MID) (Binladen et al., 2007) were designed for 18 each target species and were incorporated in each species-specific primer set (A and B) . Additionally, because the sequences of the primers themselves were not fully discriminatory and in order to rule out any mismatch and wrong assignments or sequencing errors, MIDs were employed in this 454 analysis. Each MID is a 10-base oligonucleotide (Table 3). The 454 experiment was completed in two physically separated lanes in a 16-lane 454 picotiter plate. One lane was used for genomic DNA-based analysis (for primer sets A and B) and the other for PCR product based material (for primer sets A and B). 3. Amplicon preparation The first PCR was performed with target specific primers. Each PCR reaction contained 2 µl pooled DNA templates (250 ng/µl each), 17.5 µl molecular biology grade water, 2.5 µl 10× reaction buffer, 1 µl 50× MgCl2 (50 mM), 0.5 µl dNTPs mix (10 mM), 0.5 µl forward primer (10 mM), 0.5 µl reverse primer (10 mM), and 0.5 µl Invitrogen's Platinum Taq polymerase (5 U/µl) in a total volume of 25 µl. The PCR started with heated lid at 95°C for 5 min, followed by 15 cycles of 94°C for 40 sec, 43.5°C for 1 min, and 72°C for 30 sec, a final extension step at 72°C for 5 min, and hold at 4°C. All target species amplicons were purified using Qiagen's MiniElute PCR purification columns and eluted in 50 µl molecular biology grade water. The amplicons from the first PCR were used as template in the second PCR with similar conditions using 454 fusion-tailed primers in a 30-cycle amplification regime. The second PCR was used to attach fusion tails to the amplicons to allow them to bind to the beads in the 454 emulsion PCR (described below). For all PCRs the Eppendorf Mastercycler gradient S thermalcycler was used. 19 The results for PCR success were visualized by agarose gel electrophoresis (1.5%) and negative controls were included in all experiments. 4. 454 Pyrosequencing amplicon library preparation In 1.5ml tubes, 22.5ul of the generated amplicons were mixed with 22.5ul of molecular grade water. To this mix, 72µl of AMPure beads were added and vortexed well. The mixture was stored at room temperature for 10 minutes in a Magnetic Particle Concentrator (MPC). Unused reagents and primer dimers were washed away with 70% ethanol and fragments were eluted with 10µl of 1× Tris EDTA (TE) buffer. Subsequently, the quantified libraries were amplified in micro-reactors through emulsion PCR (emPCR) followed by Streptavidin bead enrichment and emulsion breaking. The beads attached to amplified DNA fragments were denatured with 1N sodium hydroxide solution and annealed to a specific sequencing primer. All these steps and subsequent sequencing steps on the 454 instrument were performed according to Roche-454 GS FLX amplicon sequencing manual protocol updated in October 2009 and revised by November 2010 (Roche 2009). 5. 454 Data analysis framework The FASTA files (FNA) and the quality score files (QUAL) were obtained from the 454 FLX Sequencer after signal processing. Both FNA and QUAL files were generated through Roche signal processing software using amplicon processing with default settings. Data analysis was performed using two approaches: 20 A. Manual analysis: sequences were inspected by eye in sequence editing software such as Bioedit (Hall, 1999) and the quality-filtering step was omitted for manual filtering. This approach allowed the retrieval of a maximal number of reads for subsequent analysis (see Results for details). I used all the generated sequences to count the number of sequences generated by each primer set for each target species. B. Automated analysis: In this approach the SeqTrim software (Falgueras et al. 2010) was used for filtering low quality sequences based on set criteria (See below). Automated sequence filtering After obtaining both FNA and QUAL files, all MIDs were sorted with zero mismatches. Using quality filter software SeqTrim (Falgueras et al., 2010), the sequences were filtered as follows: A quality filter with a 10bp sliding window was applied to the sequences. If the Phred score (Ewing et al. 1998; Ewing and Green 1998) was less than 20 for any window of 10 bp, the sequence was deleted. After quality filtering, all sequences were sorted based on their amplification primers and all sequences shorter than 80bp were removed. The remaining sequences were clustered using the UClust program(Edgar, 2010) and all clusters with less than 3 reads were removed. Finally, all sequences were Megablasted to the reference library and the number of reads for each target species was determined. The above routine was performed using a Perl script (Wall, et al., 2000) and filtering was completed using SeqTrim filtering software. 21 Manual sequence analysis By using the manual sequence analysis method I omitted the filtering step to keep all sequences and used BioEdit and MEGA to sort sequences and eliminate low quality sequences. I sorted the sequences based on the multiple identifiers (MID) with zero mis-matches. After sorting each MID based on the forward and reverse primer sequences, all MIDs and primers were trimmed and the remaining sequences were sorted by length to a minimum of 100bp to be prepared for alignment. Sequences were then aligned using available reference sequences of the 6 target species. Finally, all sequences were clustered by constructing a neighbor – joining (NJ) tree from Kimura 2-parameter sequence divergence estimates in MEGA4 (Tamura et al., 2007). I used this tree to cluster my sequences so I could count the sequences belonging to each species more effectively. 22 RESULTS Quantitative PCR Results The 1000 pg/ µl and 50 pg/ µl template dilutions gave CT values that were either too low (≤ 10 cycles) or too high (≥ 38 cycles), respectively using a 100 fluorescence threshold. The 250 pg/ µl dilution gave CT values in the expected range (≥10 and ≤ 38). The results from qPCR experiments using total genomic DNA as template did not show a general trend that can either support or refute the expected higher efficiency of species-specific primers in amplifying target species in any of the 6 species tested. Therefore I could not generate standard curves based on genomic DNA results, because of the lack of data points in several qPCR cycles in different combinations; therefore there were not sufficiently consistent to allow generation of a standard curve. In fact, there were cases of target species being less efficiently amplified as compared to non-targets (Figure 4, Appendix 1). Thus, primer match may not be the only factor at play in this experimental design and availability of target mitochondrial DNA might vary to the point that it may offset potential primer mismatch. Hence, normalized PCR products were used to test the primer binding bias. Based on the results from experiments using genomic DNA templates, it was hypothesized that the fluctuations and non-linear results might be due to variation in the mitochondrial copy number or non-specific amplification. Using the full-length DNA barcode amplicons as template for qPCR allowed me to generate consistent standard curves for different target species (Figure 5, Appendix 2). It is 23 important to note that there are fluctuations in the slope of standard curves, which may indicate different efficiencies of primer binding at different concentrations of template DNA (Figure 5). In the qPCR experiments using genomic DNA as template, amplification only occurred with 10-1 and 10-2 dilutions of the template DNA (250g/ul) with the exception of E1 (C. diminuta) primers (sets A and B) that produced detectable amplification with a template dilution of 10-3 as well (Tables 4 and 5). As previously mentioned, I noted a lack of consistency in standard curve calculations of genomic DNA-based experiments (see above), and with the small number of data points in the actual cross species qPCR experiments, I decided not to pursue this line of experimentation further. Unlike standard curves generated using genomic DNA as the template, standard curves using full length amplicon templates were consistent across primer sets (Figure 5, table 6 and 7). Hence, I predict that amplicon-based qPCR analysis of cross species primer tests should provide reliable results on the effect of primer specificity in qPCR efficiency. Results of the amplicon-based qPCR in set A supported this hypothesis. With the exception of two primer sets, all target-specific primers amplified their target species more efficiently than non-target species (Table 4 and 5). The first exceptional case was the primer set designed for Maccaffertium modestum (E2mod), which amplified Maccaffertium interpunctatum (E3int) in earlier cycles (e.g. more efficiently) than its own target species. The second exception involved Caenis diminuta (E1dim) which amplified Ceratopsyche bronta (T2bro), Maccaffertium modestum (E2mod) and Maccaffertium interpunctatum (E3int) in earlier cycles, than it amplified itself. This observation is important because primer E1dim was designed for an Ephemeroptera species but in fact amplified a Trichoptera species more efficiently (Table 4 and 5). 24 The number of species which could pass the threshold in all 6 different dilutions in qPCR was higher when using primer set B than set A (Tables 4 to 7). For example, using primer set A for Chimarra obscura (T1obs), none of the other species passed threshold in all dilution except the target. However, set B primer designed for this species produced positive qPCR results for other species (table 6 to 8). In the majority of experiments, using primer set B, target species amplified more efficiently (passed threshold at lower cycle numbers) except for primers designed for C. diminuta (E1dim.) and M. modestum (E2mod). Relative Amplified Copies (RAC) Analysis The Relative Amplified Copies (RAC) approach shows the rate of amplification of each species as compared to the target species of a specific primer set (Jolla, 2004). Based on qPCR results from experiments using full-length barcode amplicons as template, RAC plots were generated for each target species for both primer sets (A and B) and for all dilutions. The plot for C. obscura as the target species (Figure 6) shows the importance of dilution in relative amplification of non-target species. All non-target species were amplified less efficiently as compared to target species. However, substantial differences exist in the relative amplification of the non-target species with RAC values ranging from 212 for C. bronta to 76 million for C. sparna at a template dilution of 0.1. Moreover, only three of the five non-target species amplified with the 10-2 template dilution and none amplified at higher dilutions. Similar analyses were conducted for all other combinations of target species and primer sets A and set B (Appendix 3). 25 Quantitative and qualitative analysis of pyrosequencing reads Using both primer sets A and B, 454 pyrosequencing reads were obtained for amplicons directly generated from genomic DNA mixtures of the target species and from mixtures of fulllength COI barcode amplicons. A total of 10,034 reads were generated from genomic DNA templates and 13,681 reads from full-length COI barcode amplicons. The distribution of sequence read lengths has been used as a measure to evaluate pyrosequencing run quality. I sequenced two amplicons of 143 bp (set A) and 305 bp (set B). However, the addition of PCR primers, pyrosequencing fusion tail and MID tags increases the total size of each amplicon by about 50 bases. Hence, sequence reads should optimally be distributed around 193 bp (set A) and 355 bp (set B). Automated sequence analysis conducted by SeqTrim software greatly reduced the number of sequence reads as compared to raw sequences obtained. Only 6.5% and 4.6% of the reads passed SeqTrim in genomic DNA-based and amplicon-based analyses, respectively. This rather small proportion of reads did not provide a stable trend for target species specificity of primers and compatibility of 454 analysis and qPCR results. For example, in the automated analysis of genomic DNA templates, both primer sets designed for C. obscura (T1) showed results only for their target species (108 sequences for set A and 35 sequences for set B) (Table 13). Conversely, primer set A for C. bronta (T2) did not produce any results for the target species and set B only produced 34 reads. However, primer set B for T2 produced 179 reads for non-target Ephemeroptera species, C. diminuta (E1), which is much more than the number of reads produced for its target species. Fewer reads were obtained after Seqtrim filtering of genomic DNA templates compared to pyrosequenced COI amplicons (Table 11 and 12, 10034 reads from genomic DNA pooled 26 templates and 13681 reads from pooled full-length barcode amplicons templates). In 4 out of 6 cases, target species produced more reads than non-targets, but these results were only obtained by one of the two primer sets in each case (Table 13). On the other hand, there were 4 cases in which the target species did not show the highest amount of amplification. As an example, 4 reads were obtained for the target species using C.obscura (T1) primer set B while 8 reads were obtained for C.diminuta (E1) and 30 reads for C. bronta (T2) (Table 13). The manual analysis of 454 sequences provided a higher number of sequence reads compared to SeqTrim (Table 13). In other words, many sequences that did not pass SeqTrim filter were retrieved after manual inspection and editing of each pyrosequence read. Consequently, 21.5% of sequences obtained from genomic DNA templates and 31.4% of sequence reads from amplicon templates passed manual inspection and were used for subsequent comparisons. In the manual analysis of the pyrosequences obtained from DNA-based pooled material, target species produced more reads in both primer sets with the exception of C. bronta (T2). In this case, E2 (M.modestum) and E1 (C.diminuta) produced more reads, for primer sets A and B, respectively (Table 13). In manual analysis of amplicon-based material, target species produced more reads in both primer sets with two exceptions. In one case, T1 (C. obscura) COI amplicons produced 1.6X more reads than the target species using T2 (C.bronta) primer set B (Table 13). The second exceptional case was manual analysis of DNA-based material using E2 (M. modestum) primer set B, for which T1 (C. obscura) COI amplicons produced 1.9X more reads than the target species. An important factor in the utility of NGS is the ability to parallelize the analysis of many templates in one sequencing reaction. Aside from using this approach in analyzing mixed DNA 27 templates such as environmental samples, sets of specific oligonucleotide tags (MIDs) can be used for mixing amplicons and then retrieving corresponding sequences bioinformatically. However, the efficiency of this MID approach needs to be evaluated to be able to use this approach in applications reliably. Here, we used 6 MIDs for our target species primer sets (A and B). Based on the analysis of raw 454 reads, it is clear that the MID approach can provide a rather uniform distribution of sequence reads for each MID (Figures 7, Table 1 in Appendix 3). However, we observed some fluctuations in the number of reads per MIDs in amplicon based material (Figure 8). 28 DISCUSSION Since the early days of NGS, most of its applications in biodiversity science have been focused on discovering unknown biodiversity from the bottom of the ocean (Sogin et al., 2006) to the human microbiome (Gilbert et al., 2008). These applications have mainly been focused on data generation and biological interpretations by using much higher sequencing capacity offered by NGS platforms. However, some recent studies have illuminated the importance of NGS data quality and the fact that low quality data may lead to misleading biological interpretations (Quince et al., 2009). NGS workflow and potential biases associated with it become even more critical in applications that involve targeting specific groups of organisms, especially in socioeconomically important taxa such as pathogens, pests and bioindicator species. This study was conducted to specifically address the issue of amplification bias in NGS analysis of DNA barcodes (and similar marker gene amplicons) from two sets of closely related target species (fresh water bioindicator species in this case). NGS technologies, in general, have made the genomic analysis of environmental samples such as benthos, soil, water or bulk samples of terrestrial or marine biota more feasible. For example, several recent studies have demonstrated the accuracy and reproducibility of the 454 pyrosequencing results (Hajibabaei et al., 2011; Schwartz et al., 2011; Shokralla et al., 2012). More specifically, short fragments of COI DNA barcodes were successful in providing data for identification of freshwater invertebrates for biomonitoring purposes (Hajibabaei et al., 2011). The purpose of this study was to advance our understanding of genomics analysis of mixed environmental samples by developing a qPCR-based approach with customized primers to quantify species from mixed samples and to optimize and select primers for downstream next29 generation sequencing analysis. This work will hopefully help us use NGS technologies in realworld biomonitoring applications. The majority of studies using qPCR have focused on gene expression analysis and methods developed to analyze and interpret qPCR results are mainly geared towards gene expression (Livak & Schmittgen, 2001; Ohtsu et al., 2007; Selinger et al., 1998; Torres et al., 2008; Wang, 2003). However, in recent years qPCR has been used in the molecular diagnosis of infectious diseases or genetic defects (Francois et al., 2003; Menard et al., 2008). Because this study aimed at evaluating qPCR as a method to test efficiency and behavior of primers in multi-template amplifications and no reference gene or target was involved I decided to use an alternate approach to analyze the data. Primer behavior in multi-template PCR Previous studies on multi-template PCR bias in template-to-product ratios on bacteria suggested that there are numerous uncertainties about the source of this problem ( Polz and Cavanaugh 1998; Thompson, et al., 2002; Acinas et al. 2005). However, aside from a number of studies mainly conducted prior to the introduction of NGS, the issue of primer selection for multi-template PCR remains understudied. Perhaps an important factor that has contributed to this problem is the notion of universal primers and that selecting genomic targets with conserved primer binding sites is the only solution to achieve optimal amplification (Sogin et al., 2006). Consequently, the majority of studies that target environmental samples for NGS analysis use ribosomal markers such as 16S rDNA and 18S rDNA genes for targeting prokaryotes and eukaryotes, respectively. The proponents of these genes have suggested that the difficulty in designing primers for other genes such as COI DNA barcodes is a reason to abandon using these 30 markers in NGS studies of environmental samples (Creer et al., 2010; Wang et al., 2007). However, recent work has shown that differential amplification (PCR bias) is problematic in NGS analysis even for ribosomal genes (Hajibabaei et al., 2011; Schwartz et al., 2011). It is widely accepted that quantitative analysis of NGS amplicon results should be interpreted with caution. In many cases, a number of specific taxonomic or functional genes are targets of NGS analysis (Hajibabaei et al., 2011). These cases demand better understanding of primer behavior in multi-template PCR. Quantitative PCR as a tool for target identification Different commercially available qPCR tests are increasingly used for measuring levels of gene expression and for target identification in molecular diagnostic tests of genetic diseases or infectious agents. These tests typically use differential amplification as a measure for a specific gene expression or gene target validation. Because qPCR instruments and reagents are relatively cheap and tests can be performed rather quickly and do not require large lab operations, qPCR is now a workhorse in many molecular biology labs. In this study, I demonstrated that qPCR has the potential to be used for validation of PCR primers before they are used in more expensive NGS analysis of multi-template DNA such as bulk environmental samples. However, my experimental design challenged the sensitivity of qPCR when genomic DNA was used as the template. Hence, results obtained from these comparisons could not provide conclusive evidence for primer specificity. Nevertheless, when more uniform amplicons were used as templates, qPCR behaved mainly as expected and target species showed more efficient amplification in the majority of cases. 31 This study is the first attempt to use qPCR for validating primers for NGS analysis of multi-template PCR for taxonomic identifications. However, qPCR has recently been suggested as a method for library quantification in NGS analysis of whole genomes (Buehler et al., 2010). In this case, specific primers target adaptor sequences (common among all genomic fragments) at different dilutions and qPCR analysis is conducted at different steps of library preparation to provide a guide for selecting the optimal dilution for downstream NGS. However, in the current study, primers that target different taxa were selected based on their target specificity in qPCR analysis of amplicons, which offsets fluctuations in target copy number in genomic DNA. Primers with the best target specificity can then be used in NGS experiments. Optimal NGS analysis of target genes and taxa Although NGS approaches have the capacity to generate a large volume of DNA sequences, they often involve tedious workflows and require highly skilled bioinformaticians to handle the data. Additionally, available software may not provide the optimal tools for data filtering and analysis, as I observed in this study. Lack of efficient software dictated a rather tedious manual approach in data editing, but this approach allowed recovery of many additional sequences for downstream analysis. Results from pyrosequencing analysis provided evidence for the utility of specific primer sets for targeting genes and species of interest. In contrast to universal primers, combinations of species-specific primers may provide a more reliable solution to avoid false negatives in NGS analysis of bulk environmental samples. Fluctuations in gene copy number or differences in biomass can influence the utility of any primer set in a mixture. However, even in our analysis of 32 genomic templates (which are potentially more prone to gene copy number fluctuation) we were able to detect our target species using a combination of two target-specific primer sets (Table 8) Moreover the efficiency and slope of each primer set has been calculated and shown in table 9. Quantitative analysis of bulk samples using mitochondrial markers is challenging. The mtDNA copy number per reaction can vary between species and tissue types in mixed environmental samples. In my experiments, I overcame the fluctuation effect of different gene copies within certain biomass on amplification dynamics by performing another set of experiments using normalized full-length DNA barcode amplicons as templates for my species specific PCRs (Figure 2). In real environmental sample with a wide range of individuals’ sizes, this approach can help to interpret the NGS results and relate the numbers of generated sequences to the known information about each individual biomass. Automated SeqTrim analysis greatly reduced the number of sequences that were used in comparative analysis of primers. Moreover, there was a trend towards target specificity using some primer sets, suggesting that it is not reasonable to use only a few sequences in these comparisons. However, substantially more sequences passed manual inspection and provided the basis for our comparative analysis. We investigated two types of material as template for PCR, genomic DNA and COI amplicons. Analysis of both genomic and amplicon templates shows a rather strong trend towards more efficient sequencing (as reflected in number of sequence reads in each comparison; Tables 9 to 12) by target-specific primers. However, there are few exceptions in both DNA and amplicon-based analyses. These exceptions may be due to higher number of available templates, especially for genomic DNA, as a consequence of variation in mitochondrial DNA copies. However, in the only exceptional case using genomic templates (C.bronta (T2)), two different non-target species produced more sequences than target species 33 for the two primer sets A and B. If a single non-target species had outcompeted the target species, then the likelihood of a higher mitochondrial copy number for this non-target species seems to be higher. On the other hand, the only two exceptions in analysis of amplicon templates are linked to primer set B and in both cases, the non-target species that outcompetes the target species is T1 (C.obscura). Comparing qPCR and 454 results I had hypothesized that qPCR results obtained for each target species using its specific primer sets would be reflected in the corresponding pyrosequencing reads (Table 8). In each case I ascertained if the target species was more efficiently amplified in qPCR and pyrosequenced. These comparisons show more consistency between qPCR and pyrosequencing using amplicon templates. However, results obtained for each primer set are somewhat different. In primer set A, we observed an almost perfect agreement between qPCR and 454 results, supporting the hypothesis that target species are amplified and sequenced more efficiently using their specific (i.e.100% matching) primers. In this comparison, with the exception of qPCR using the T2 primers, all other target species were more efficiently amplified and pyrosequenced. On the other hand, qPCR and pyrosequencing data showed the same pattern using primer set B with the exception of the T3 primers. However, the target species amplified and pyrosequenced more efficiently in only half the cases. Perhaps the most realistic (applicable) comparison can be conducted between qPCR analysis of amplicon templates and pyrosequencing of genomic templates. In other words, because qPCR testing of primers can potentially be used as a guide to select optimal target34 specific primers for pyrosequencing analysis, these comparisons can provide important insights concerning the utility of this approach in a wider context. The majority of target species showed a consistent pattern between qPCR of amplicon templates and pyrosequencing of genomic templates. However, the two target species, T3 and E3, were exceptions as results using primer sets for both these species were not similar when I compared the qPCR and pyrosequencing results. Towards an standardized approach for metagenomics analysis of environmental DNA Based on recent advances in genomics instrumentation and bioinformatics tools it is clear that biological sciences and a wide range of socio-economic applications will rely on genomics information captured from environmental DNA. For example, a special issue of Molecular Ecology (April 2012) was devoted to Environmental DNA focusing on recent advancements and applications of NGS in ecological research (Baird & Hajibabaei, 2012; Shokralla et al., 2012; Taberlet, et al., 2012) The excitement in using NGS tools for many different applications has led to many primary publications and may potentially lead to better technologies and tools. However, the user communities (i.e. ecologists) should work with genomics and bioinformatics experts to overcome technical challenges that can limit the usability of NGS in larger-scale studies. Most of the studies in ecological use of NGS are in fact one-off or proof of concept (Callaway, 2012). A recent Genome Web article highlights challenges in moving NGS tools to real-world diagnostics and the fact that many industry leaders believe NGS is still far from being applicable in standard diagnostics settings (Karow, 2012). These challenges mainly involve difficulties (and black boxes) in data generation and workflows as well as data quality and lack of efficient 35 standard software to differentiate accurate sequence information from errors. In fact, this thesis confirms the above-mentioned issues both at the level of molecular biology (PCR bias and primer specificity) and bioinformatics analysis (automated versus manual sequence filtering). This line of work will hopefully set the stage for the use of available tools such as qPCR and specific primers for more efficient and standardized application of NGS in biodiversity analysis. Based on my study, qPCR can be efficiently used for designing primers for target specific groups of organisms according to the environmental/ecological question. Commonly used bioindicators for fresh water bioassesment, such as Trichoptera, Ephemeroptera and Plecoptera would be a good potential target for this type of studies. By this approach, testing the designed primers through qPCR would be applicable among different individual species of these groups starting with both gDNA and amplicon material. This study showed that qPCR can be used as a proxy for testing the efficiency of PCR primers for amplifying mixed environmental samples for biomonitoring applications. The primers designed for this study could be able to perform in relatively efficient way however for further studies slight changes in designing the primers for in-groups is recommended. DNA material could illustrate the behavior of the primers with individual sample as the real life while the amplicon material could provide the chance of dealing efficiently with the sequence variation only. Also the amplicon based material will eliminate the variation in the mitochondrial copy number between different species at the same time. Once we reach the optimal primer design which can amplify the majority of the targets in a relative uniform pattern, then the results obtained from qPCR could be used in developing optimized 454 pyrosequencing amplicon based analysis for bulk environmental sample. 36 REFERENCES Acinas, S. G., Sarma-Rupavtarm, R., Klepac-Ceraj, V., & Polz, M. F. (2005). PCR-Induced sequence artifacts and bias: Insights from comparison of two 16S rRNA clone libraries constructed from the same sample. American Society of Microbiology, 71(12), 8966-8969. Aird, D., Ross, M. G., Chen, W.-S., Danielsson, M., Fennell, T., Russ, C., Jaffe, D. B., et al. (2011). Analyzing and minimizing PCR amplification bias in Illumina sequencing libraries. Genome Biology, 12(2), R18. Applied Biosystems. (2008). Guide to performing relative quantitation of gene expression using real-time quantitative PCR. Applied Biosystems. Baird, D. J., & Hajibabaei, M. (2012). Biomonitoring 2.0: a new paradigm in ecosystem assessment made possible by next-generation DNA sequencing. Molecular ecology, 21(8), 2039-44. Baird, D. J., Pascoe, T. J., Zhou, X., & Hajibabaei, M. (2011). Building freshwater macroinvertebrate DNA-barcode libraries from reference collection material: formalin preservation vs. specimen age. Journal of the North American Benthological Society, 30(1), 125-130. Becker, A., Reith, A., Napiwotzki, J., & Kadenbach, B. (1996). A quantitative method of determining initial amounts of DNA by polymerase chain reaction cycle titration using digital imaging and a novel DNA stain. Analytical Biochemistry, 237(2), 204-207. Binladen, J., Gilbert, M. T. P., Bollback, J. P., Panitz, F., Bendixen, C., Nielsen, R., & Willerslev, E. (2007). The use of coded PCR primers enables high-throughput sequencing of multiple homolog amplification products by 454 parallel sequencing. PLoS ONE, 2(2), e197. Bonada, N., Prat, N., Resh, V. H., & Statzner, B. (2006). Developments in aquatic insect biomonitoring: a comparative analysis of recent approaches. Annual Review of Entomology, 51, 495-523. Buehler, B., Hogrefe, H. H., Scott, G., Ravi, H., Pabón-Peña, C., O’Brien, S., Formosa, R., et al. (2010). Rapid quantification of DNA libraries for next-generation sequencing. Methods, 50(4), 15-18. Callaway, E. (2012). A bloody boon for conservation. Nature News. Available: http://www.nature.com/news/a-bloody-boon-for-conservation-1.10499 37 Claesson, M. J., Wang, Q., O’Sullivan, O., Greene-Diniz, R., Cole, J. R., Ross, R. P., & O’Toole, P. W. (2010). Comparison of two next-generation sequencing technologies for resolving highly complex microbiota composition using tandem variable 16S rRNA gene regions. Nucleic Acids Research, 38(22), e200. Creer, S., Fonseca, V. G., Porazinska, D. L., Giblin-Davis, R. M., Sung, W., Power, D. M., Packer, M., et al. (2010). Ultrasequencing of the meiofaunal biosphere: practice, pitfalls and promises. Molecular Ecology, 19(s1), 4-20. Edgar, R. C. (2010). Search and clustering orders of magnitude faster than BLAST. Bioinformatics, 26(19), 2460-2461. Ewing, B., & Green, P. (1998). Base-Calling of automated sequencer traces using Phred. II . Error probabilities. Genome Research, 8(3), 186-194. Ewing, B., Hillier, L., Wendl, M. C., & Green, P. (1998). Base-Calling of automated sequencer traces Using Phred. I . Accuracy assessment. Genome Research, 8(3), 175-185. Falgueras, J., Lara, A., Fernandez-Pozo, N., Canton, F., Perez-Trabado, G., & Claros, M. G. (2010). SeqTrim: a high-throughput pipeline for preprocessing any type of sequence reads. BMC Bioinformatics, 11(1), 38. Floyd, R., Abebe, E., Papert, A., & Blaxter, M. (2002). Molecular barcodes for soil nematode identification. Molecular ecology, 11(4), 839–50. Folmer, O., Black, M., Hoeh, W., Lutz, R., & Vrijenhoek, R. (1994). DNA primers for amplification of mitochondrial cytochrome c oxidase subunit I from diverse metazoan invertebrates. Molecular Marine Biology and Biotechnology, 3(5), 294-299. Francois, P., Pittet, D., Bento, M., Pepey, B., Vaudaux, P., Lew, D., & Schrenzel, J. (2003). Rapid detection of methicillin-resistant Staphylococcus aureus directly from sterile or nonsterile clinical samples by a new molecular assay. Journal of Clinical Microbiology, 41(1), 254-260. Frézal, L., & Leblois, R. (2008). Four years of DNA barcoding: current advances and prospects. Infection, genetics and evolution : Journal of Molecular Epidemiology and Evolutionary Genetics in Infectious Diseases, 8(5), 727-36. Gilbert, M. T. P., Kivisild, T., Grønnow, B., Andersen, P. K., Metspalu, E., Reidla, M., Tamm, E., et al. (2008). Paleo-Eskimo mtDNA genome reveals matrilineal discontinuity in Greenland. Science, 320(5884), 1787-9. 38 Gill, S. R., Pop, M., Deboy, R. T., Eckburg, P. B., Turnbaugh, P. J., Samuel, B. S., Gordon, J. I., et al. (2006). Metagenomic analysis of the human distal gut microbiome. Science, 312(5778), 1355-9. Hajibabaei, M., DeWaard, J. R., Ivanova, N. V., Ratnasingham, S., Dooh, R. T., Kirk, S. L., Mackie, P. M., et al. (2005). Critical factors for assembling a high volume of DNA barcodes. Philosophical Transactions of the Royal Society of London - Series B: Biological Sciences, 360(1462), 1959-1967. Hajibabaei, M., Shokralla, S., Zhou, X., Singer, G. A. C., & Baird, D. J. (2011). Environmental barcoding: A Next-Generation sequencing approach for biomonitoring applications using river benthos. PLoS ONE, 6(4), e17497. Hajibabaei, M., Smith, M. A., Janzen, D. H., Rodriguez, J. J., Whitfield, J. B., & Hebert, P. D. N. (2006). A minimalist barcode can identify a specimen whose DNA is degraded. Molecular Ecology Notes, 6(4), 959-964. Hall, T. A. (1999). BioEdit: a user-friendly biological sequence alignment editor and analysis program for Windows 95/98/NT. Nucleic Acids Symposium Series, 41(41), 95-98. Hebert, P. D. N., Cywinska, A., Ball, S. L., & DeWaard, J. R. (2003). Biological identifications through DNA barcodes. Proceedings of the Royal Society B: Biological Sciences, 270(1512), 313–321. Hebert, P. D. N., & Gregory, T. R. (2005). The promise of DNA barcoding for taxonomy. Systematic Biology, 54(5), 852-859. Hollingsworth, P. M., Forrest, L. L., Spouge, J. L., Hajibabaei, M., Ratnasingham, S., Van Der Bank, M., Chase, M. W., et al. (2009). A DNA barcode for land plants. Proceedings of the National Academy of Sciences of the United States of America, 106(31), 12794-12797. Janzen, D. H., Hajibabaei, M., Burns, J. M., Hallwachs, W., Remigio, E., & Hebert, P. D. N. (2005). Wedding biodiversity inventory of a large and complex Lepidoptera fauna with DNA barcoding. Philosophical Transactions of the Royal Society of London - Series B: Biological Sciences, 360(September), 1835-1845. Karow, J.(2012). Experts discuss challenges of moving next-generation sequencing into diagnostics. Genome Web. Available: http://www.genomeweb.com/sequencing/expertsdiscuss-challenges-moving-next-gen-sequencing-diagnostics Kennedy, S. (2011). PCR troubleshooting and optimization: The essential guide. Wydmondham: Caister Academic Press. 235p. 39 Lakes, F. (2001). Optimization of annealing temperature to reduce bias caused by a primer mismatch in multitemplate PCR. American Society of Microbiology, 67(8), 3753-5. Limpiyakorn, T., Kurisu, F., & Yagi, O. (2006). Development and application of real-time PCR for quantification of specific ammonia-oxidizing bacteria in activated sludge of sewage treatment systems. Applied Microbiology and Biotechnology, 72(5), 1004-13. Livak, K. J., & Schmittgen, T. D. (2001). Analysis of relative gene expression data using realtime quantitative PCR and the 2(-Delta Delta C(T)) Method. Methods, 25(4), 402-8. Lovejoy, T. E. (1997). Biodiversity: what is it? In: ML Reaka-Kudla, DE Wilson & EO Wilson, editors. Biodiversity II: understanding and protecting our biological resources, Joseph Henry Press, Washington D.C., pp. 7-14. Margulies, M., Egholm, M., Altman, W. E., Attiya, S., Bader, J. S., Bemben, L. A, Berka, J., et al. (2005). Genome sequencing in microfabricated high-density picolitre reactors. Nature, 437(7057), 376-80. Menard, J.-P., Fenollar, F., Henry, M., Bretelle, F., & Raoult, D. (2008). Molecular quantification of Gardnerella vaginalis and Atopobium vaginae loads to predict bacterial vaginosis. Clinical Infectious Diseases, 47(1), 33-43. Meusnier, I., Singer, G. A., Landry, J.-F., Hickey, D. A., Hebert, P. D., & Hajibabaei, M. (2008). A universal DNA mini-barcode for biodiversity analysis. BMC Genomics, 9(1), 214. Mora, C., Tittensor, D. P., Adl, S., Simpson, A. G. B., & Worm, B. (2011). How many species are there on Earth and in the ocean? PLoS Biology, 9(8), e1001127. Munch, K., Boomsma, W., Willerslev, E., & Nielsen, R. (2008). Fast phylogenetic DNA barcoding. Philosophical transactions of the Royal Society of London. Series B, Biological sciences, 363(1512), 3997-4002. Nash, R. (1989). The rights of nature: a history of environmental ethics. Madison: University of Wisconsin Press. 304p. Noss, R. F. (1990). Indicators for monitoring biodiversity: A hierarchical approach. Conservation Biology, 4(4), 355-364. Ohtsu, K., Smith, M. B., Emrich, S. J., Borsuk, L. a, Zhou, R., Chen, T., Zhang, X., et al. (2007). Global gene expression analysis of the shoot apical meristem of maize (Zea mays L.). The Plant Journal: for Cell and Molecular Biology, 52(3), 391-404. Ozawa, T., Tanaka, M., Ikebe, S., Ohno, K., Kondo, T., & Mizuno, Y. (1990). Quantitative determination of deleted mitochondrial DNA relative to normal DNA in parkinsonian 40 striatum by a kinetic PCR analysis. Biochemical and Biophysical Research Communications, 172(2), 483-489. Pfaffl, M. W. (2001). Quantification strategies in real-time PCR, In: Bustin S.A, editor. A-Z of quantitative PCR. La Jolla: International University Line. pp 87-112. Pandey, R. V., Nolte, V., Boenigk, J., & Schlotterer, C. (2011). CANGS DB: a stand-alone webbased database tool for processing, managing and analyzing 454 data in biodiversity studies. BMC Research Notes, 4(1), 227. Pang, S., Koyanagi, Y., Miles, S., Wiley, C., Vinters, H. V., & Chen, I. S. (1990). High levels of unintegrated HIV-1 DNA in brain tissue of AIDS dementia patients. Nature, 343(6253), 8589. Piatak, M., Saag, M. S., Yang, L. C., Clark, S. J., Kappes, J. C., Luk, K. C., Hahn, B. H., et al. (1993). Determination of plasma viral load in HIV-1 infection by quantitative competitive polymerase chain reaction. AIDS, 7 Suppl 2, S65-S71. Polz, M. F., & Cavanaugh, C. M. (1998). Bias in template-to-product ratios in multitemplate PCR. Applied and Environmental Microbiology, 64(10), 3724-30. QIAGEN. (2006). Critical factors for successful real-time PCR. QIAGEN . Available : http://www.qiagen.com/selectlocation.aspx?redirect=%2fliterature%2frender.aspx%3fid%3 d23490 Quince,C., Lanzen,A., Curtis,T.P., Davenport,R.J., Hall,N.,Head,I.M., Read,L.F. and Sloan,W.T. (2009) Accurate determination of microbial diversity from 454 pyrosequencing data. Nature Methods, 6, 639–641. Qu, X. D., Song, M. Y., Park, Y. S., Oh, Y. N., & Chon, T. S. (2008). Species abundance patterns of benthic macroinvertebrate communities in polluted streams. Annales de Limnologie International Journal of Limnology, 44(2), 119-133. Rieu, I., and Powers, S. J. (2009). Real-time quantitative RT-PCR: design, calculations, and statistics. American Society of Plant Biologists, 21(4), 1031-3. Roche, (2006). Sequencing Method Manual, GS FLX Titanium Series. Available: http://454.com/downloads/my454/documentation/gs-flx/method-manuals/GS-FLXTitanium-Sequencing-Method-Manual-%28Nov2010%29.pdf Roesch, L. F. W., Fulthorpe, R. R., Riva, A., Casella, G., Hadwin, A. K. M., Kent, A. D., Daroub, S. H., et al. (2007). Pyrosequencing enumerates and contrasts soil microbial diversity. The International Society of Microbial Ecology, 1(4), 283-90. 41 Rosenberg, D. M., & Resh, V. H. (1993). Introduction to freshwater biomonitoring and benthic macroinvertebrates. In: D. M. Rosenberg & V. H. Resh, editors. Freshwater Biomonitoring and Benthic Macroinvertebrates. New York: chapman and Hall. pp.1-9). Roux, K. H. (2009). Optimization and troubleshooting in PCR. Cold Spring Harbor protocols, ip66. Schmieder, R., & Edwards, R. (2011). Quality control and preprocessing of metagenomic datasets. Bioinformatics, 27(6), 863-864. Schwartz, S., Oren, R., & Ast, G. (2011). Detection and removal of biases in the analysis of nextGeneration sequencing reads. PLoS ONE, 6(1), e16685. Selinger, L. B., Khachatourians, G. G., Byers, J. R., & Hynes, M. F. (1998). Expression of a Bacillus thuringiensis delta-endotoxin gene by Bacillus pumilus. Canadian Journal of Microbiology, 44(3), 259-69. Smith, P. J., McVeagh, S. M., & Steinke, D. (2008). DNA barcoding for the identification of smoked fish products. Journal of Fish Biology, 72(2), 464-471. Shokralla, S., Spall, J. L., Gibson, J. F., & Hajibabaei, M. (2012). Next-generation sequencing technologies for environmental DNA research. Molecular Ecology, 21(8), 1794-805. Sogin, M. L., Morrison, H. G., Huber, J. A, Welch, D. M., Huse, S. M., Neal, P. R., Arrieta, J. M., et al. (2006). Microbial diversity in the deep sea and the underexplored “rare biosphere”. Proceedings of the National Academy of Sciences of the United States of America, 103(32), 12115-20. Suess, M. J. (1982). Examination of water for pollution control. Oxford: Pergamon Press. 554 p. Su, Z., Ning, B., Fang, H., Hong, H., Perkins, R., Tong, W., & Shi, L. (2011). Next-generation sequencing and its applications in molecular diagnostics. Expert Review of Molecular Diagnostics, 11(3), 333-343. Taberlet, P., Coissac, E., Hajibabaei, M., & Rieseberg, L. H. (2012). Environmental DNA. Molecular Ecology, 21(8), 1789-93. Tamura, K., Dudley, J., Nei, M., & Kumar, S. (2007). MEGA4: Molecular Evolutionary Genetics Analysis (MEGA) software version 4.0. Molecular Biology and Evolution, 24(8), 1596-1599. Thompson, J. R., Marcelino, L. A, & Polz, M. F. (2002). Heteroduplexes in mixed-template amplifications: formation, consequence and elimination by “reconditioning PCR”. Nucleic Acids Research, 30(9), 2083-8. 42 Torres, T. T., Metta, M., Ottenwälder, B., & Schlötterer, C. (2008). Gene expression profiling by massively parallel sequencing. Genome Research, 18(1), 172-7. Udvardi, M. K., Czechowski, T., & Scheible, W. R. (2008). Eleven golden rules of quantitative RT-PCR. American Society of Plant Biologists, 20(7), 1736-7. Wall, L., Christiansen, T. & Orwant, J. (2000). Programming Perl (3rd edition). O’Reilly and Associates. 1104p. Wang, C., Mitsuya, Y., Gharizadeh, B., Ronaghi, M., & Shafer, R. W. (2007). Characterization of mutation spectra with ultra-deep pyrosequencing: application to HIV-1 drug resistance. Genome Research, 17(8), 1195-201. Wang, X. (2003). A PCR primer bank for quantitative gene expression analysis. Nucleic Acids Research, 31(24), 154e-154. Wang, C., Mitsuya, Y., Gharizadeh, B., Ronaghi, M., & Shafer, R. W. (2007). Characterization of mutation spectra with ultra-deep pyrosequencing: application to HIV-1 drug resistance. Genome Research, 17(8), 1195-1201. Ward, R. C., Loftis, J. C., & McBride, G. B. (1986). The “data-rich but information-poor” syndrome in water quality monitoring. Environmental Management, 10(3), 291-297. 43 TABLES: Table 1. Species-specific oligonucleotide primers targeting two fragments of cytochrome c oxidase 1 (COI) gene for Set A (40F/183R) and set B (240F/545R). T1=Chimarra obscura, T2=Ceratopsyche bronta, T3=Ceratopsyche sparna, E1=Caenis diminuta, E2=Maccaffertium modestum, E3=Maccaffertium interpunctatum. Set A Primer Code T_40_F T1 T_183_R T_40_F T2 E3 T3 E_183_R T_240_F T_545_R E1 E_240_F E_545_R E2 E_183_R E_40_F T_240_F T_545_R E_183_R E_40_F E2 T2 T_183_R E_40_F E1 T_545_R T_183_R T_40_F T3 T1 Primer code T_240_F E_240_F E_545_R E3 E_240_F E_545_R 44 Set B Sequence (5’-3’) CCAGACATAGCCTTCCCTCG 20 GCTCCTGCTAATACAGG 17 CCAGATATAGCATTCCCCCG 20 GCTCCGGCTAAAACAGG 17 CCTGATATAGCTTTTCCTCG 20 GCTCCAGCAAGAACAGG 17 CCAGATATGGCATTCCCCCG 20 GCTCCTGCTAAAACAGG 17 CCTGATATAGCCTTCCCACG 20 GCTCCTGCTAATACAGG 17 CCTGATATGGCCTTCCCCCG 20 GCCCCTGCCAATACAGG 17 Table 2. Concentration of Genomic DNA extracts obtained from each target species as measured by NanoDrop. Target species Voucher DNA conc. Amplicon conc. Number (ng/ µl) (ng/ µl) Chimarra obscura (T1) STRI20091 31.6 136.5 Ceratopsyche sparna (T2) STRI20092 41.1 281.1 Ceratopsyche bronta (T3) STRI20093 48.2 242.8 Caenis diminuta (E1) SEPH20091 6.0 210.5 Maccaffertium modestum (E2) SEPH20092 0.9 71.8 Maccaffertium interpunctatum(E3) SEPH20093 1.3 109.7 45 Table 3. 454 pyrosequencing tagged primer, species-specific primers modified by adding Multiplex Identifier sequence tags (MID) were employed in 454 pyrosequencing experiments. T1=Chimarra obscura, T2 =Ceratopsyche bronta, T3=Ceratopsyche sparna, E1=Caenis diminuta, E2=Maccaffertium modestum, E3=Maccaffertium interpunctatum. Name MID code MID16-TCACGTACTA SetA MID16-TCACGTACTA Primer code Sequence (5` - 3`) Tagged_T_1_40_F TCACGTACTATTGATCAAGAATATTAGG Tagged_T_1_183_R TCACGTACTACCYCCAATTATGATGGG SetB Tagged_T_1_240_F TCACGTACTACCAGACATAGCCTTCCCTCG Tagged_T_1_545_R TCACGTACTAGCTCCTGCTAATACAGG MID16-TCACGTACTA MID16-TCACGTACTA SetA MID50_ACTAGCAGTA Tagged_T_2_40_F ACTAGCAGTATTGATCAGGTCTAGTAGG MID50_ACTAGCAGTA Tagged_T_2_183_R ACTAGCAGTACCCCCAATTATAATAGG SetB MID50_ACTAGCAGTA Tagged_T_2_240_F ACTAGCAGTACCAGATATAGCATTCCCCCG MID50_ACTAGCAGTA Tagged_T_2_545_R ACTAGCAGTAGCTCCGGCTAAAACAGG SetA MID51_AGCTCACGTA MID51_AGCTCACGTA Tagged_T_3_40_F AGCTCACGTATTGATCAGGATTAGTAGG Tagged_T_3_183_R AGCTCACGTACCCCCAATTATAATTGG SetB MID51_AGCTCACGTA MID51_AGCTCACGTA Tagged_T_3_240_F AGCTCACGTACCTGATATAGCTTTTCCTCG Tagged_T_3_545_R AGCTCACGTAGCTCCAGCAAGAACAGG SetA MID54_AGTGCTACGA Tagged_E_1_40_F AGTGCTACGATTGATCTGGGATAGTAGG MID54_AGTGCTACGA Tagged_E_1_183_R AGTGCTACGACCCCCAATTATGATGGG SetB MID54_AGTGCTACGA Tagged_E_1_240_F AGTGCTACGACCAGATATGGCATTCCCCCG MID54_AGTGCTACGA Tagged_E_1_545_R AGTGCTACGAGCTCCTGCTAAAACAGG SetA MID56_CGCAGTACGA Tagged_E_2_40_F CGCAGTACGATTGATCAGGGATGGTAGG MID56_CGCAGTACGA Tagged_E_2_183_R CGCAGTACGACCTCCAATCATAATAGG SetB MID56_CGCAGTACGA Tagged_E_2_240_F CGCAGTACGACCTGATATAGCCTTCCCACG MID56_CGCAGTACGA Tagged_E_2_545_R CGCAGTACGAGCTCCTGCTAATACAGG SetA MID61_CTATAGCGTA MID61_CTATAGCGTA Tagged_E_3_40_F CTATAGCGTATTGATCGGGGATGGTAGG Tagged_E_3_183_R CTATAGCGTACCTCCAATCATAATAGG SetB MID61_CTATAGCGTA MID61_CTATAGCGTA Tagged_E_3_240_F CTATAGCGTACCTGATATGGCCTTCCCCCG Tagged_E_3_545_R CTATAGCGTAGCCCCTGCCAATACAGG 46 Table 4. CT values obtained in qPCR analysis for each Trichoptera primer set A. The templates are shown in different dilutions in all Trichoptera (starting from 70 pg/ µl). A full length COI barcode amplicon was used as template in qPCR for each target species. T1=Chimarra obscura, T2=Ceratopsyche bronta, T3 = Ceratopsyche sparna, E1=Caenis diminuta, E2=Maccaffertium modestum, E3= Maccaffertium interpunctatum. CT values in bold indicate the primer set tested matches the template DNA. -- did not pass threshold. log dilution Dilution T1 Primer on T1 amplicon T1 Primer on T2 amplicon T1 Primer on T3 amplicon T1 Primer on E1 amplicon T1 Primer on E2 amplicon T1 Primer on E3 amplicon log dilution Dilution T2 Primer on T1 amplicon T2 Primer on T2 amplicon T2 Primer on T3 amplicon T2 Primer on E1 amplicon T2 Primer on E2 amplicon T2 Primer on E3 amplicon -1 0.1 3.68 11.41 29.86 17.76 26.44 27.83 -1 0.1 29.78 13.41 20.92 35.58 22.85 23.07 -2 -3 -4 -5 -6 0.01 0.001 0.0001 0.00001 0.000001 10.68 11.67 17.87 21.65 26.1 17.17 ---------23.18 27.38 30.78 34.57 -----34.89 ---39.39 39.9 -2 0.01 32.21 18.53 22.2 37.61 23.68 22.82 -3 -4 -5 -6 0.001 0.0001 0.00001 0.000001 ---34.34 20.2 21.34 22.2 26.08 31.74 35.91 37.31 --36.55 --27.13 31.16 34.05 36.8 34.78 37.41 37.98 -- log dilution -1 -2 -3 -4 -5 -6 Dilution 0.1 0.01 0.001 0.0001 0.00001 0.000001 T3 Primer on T1 amplicon 6.03 13.09 5.04 12.88 5.15 5.64 T3 Primer on T2 amplicon 3.79 11.51 4.31 11.37 10.72 4.42 T3 Primer on T3 amplicon 3.12 3.98 4.66 4.2 4.37 10.86 T3 Primer on E1 amplicon 12.74 14.8 11 5.68 5.5 11.05 T3 Primer on E2 amplicon 4.98 14.31 5.2 5.05 12.52 4.06 T3 Primer on E3 amplicon 6.2 15.67 5.26 5.81 4.39 5.7 47 Table 5. CT values obtained in qPCR analysis for each Ephemeroptera primer set A. The templates are shown in different log dilutions from all six target species (starting from 70 pg/ µl). A full length COI barcode amplicon was used as template in qPCR for each target species. E1=Caenis diminuta, E2=Maccaffertium modestum, E3= Maccaffertium interpunctatum, T1=Chimarra obscura, T2=Ceratopsyche bronta, T3 = Ceratopsyche sparna. CT values in bold indicate target species for the primer set tested. -- did not pass threshold. log dilution Dilution E1 Primer on T1 amplicon E1 Primer on T2 amplicon E1 Primer on T3 amplicon E1 Primers on E1 amplicon E1 Primers on E2 amplicon E1 Primers on E3 amplicon -1 0.1 6.03 3.79 3.12 8.3 4.98 6.2 -2 0.01 28.6 32.49 32.29 9.34 21.27 23.35 -3 -4 -5 -6 0.001 0.0001 0.00001 0.000001 31.03 37.87 32.71 -25.94 29.73 31.93 30.24 29.92 34.89 --11.61 12.74 15.55 18.65 23.75 27.1 30.34 29.89 35.02 31.75 31.92 31.28 log dilution Dilution E2 Primer on T1 amplicon E2 Primer on T2 amplicon E2 Primer on T3 amplicon E2 Primers on E1 amplicon E2 Primers on E2 amplicon E2 Primers on E3 amplicon -1 0.1 39.98 34.52 38.33 28.84 19.15 14.62 -2 0.01 32.17 38.36 37.74 33.57 21.49 15.62 -3 -4 -5 -6 0.001 0.0001 0.00001 0.000001 35.65 32.17 35.65 -30.21 33.99 37.96 37.96 ----38.38 35.65 --25.66 28.41 32.73 34.74 25.26 23.74 27.52 30.45 log dilution -1 -2 -3 -4 -5 -6 Dilution 0.1 0.01 0.001 0.0001 0.00001 0.000001 E3 Primer on T1 amplicon ---23.37 27.16 29.91 E3 Primer on T2 amplicon ---21.68 25.32 28.23 E3 Primer on T3 amplicon ---32.15 33.75 -E3 Primers on E1 amplicon 26.46 31.89 35.29 27.66 31.06 33.58 E3 Primers on E2 amplicon 11.89 15.33 19.57 22.33 25.78 28.7 E3 Primers on E3 amplicon 4.74 10.12 15.55 17.32 19.45 21.88 48 Table 6. CT values obtained in qPCR analysis for each primer set B. The templates are shown in different log dilutions in all Trichoptera (starting from 70 pg/ µl). A full length COI barcode amplicon was used as template in qPCR for each target species. T1=Chimarra obscura, T2=Ceratopsyche bronta, T3 = Ceratopsyche sparna, E1=Caenis diminuta, E2=Maccaffertium modestum, E3= Maccaffertium interpunctatum. CT values in bold indicate target species for the primer set tested. -- did not pass threshold. log dilution Dilution T1 Primer on T1 amplicon T1 Primer on T2 amplicon T1 Primer on T3 amplicon T1 Primer on E1 amplicon T1 Primer on E2 amplicon T1 Primer on E3 amplicon log dilution Dilution T2 Primer on T1 amplicon T2 Primer on T2 amplicon T2 Primer on T3 amplicon T2 Primer on E1 amplicon T2 Primer on E2 amplicon T2 Primer on E3 amplicon -1 0.1 3.22 15.57 32.52 19.9 18.12 21.45 -1 0.1 11.24 24.07 27.06 2.6 21.23 19.28 -2 0.01 10.55 18 34.52 22.15 19.06 22.13 -3 -4 -5 -6 0.001 0.0001 0.00001 0.000001 13.23 20.86 25.33 37.09 31.88 34.86 36.42 36.67 35.5 36.26 36.04 37.45 31.24 34.42 36.55 38.72 19.88 25.27 28.99 36.74 31.62 35.99 37.46 37.11 -2 0.01 16.75 26 31.78 9.38 26.13 21.54 -3 -4 -5 -6 0.001 0.0001 0.00001 0.000001 19.73 26.91 32.48 --26.35 30.19 35.99 37.82 ---12.07 16.99 21.21 30.2 28.74 33.51 36.3 -14.61 19.54 23.85 32.64 log dilution -1 -2 Dilution 0.1 0.01 T3 Primer on T1 amplicon 8.48 20.33 T3 Primer on T2 amplicon 3.64 11.93 T3 Primer on T3 amplicon 3.81 12.57 T3 Primer on E1 amplicon 28.42 30.66 T3 Primer on E2 amplicon --T3 Primer on E3 amplicon 36.35 37.49 -3 -4 -5 -6 0.001 0.0001 0.00001 0.000001 36.02 ---37.71 -----29.14 35.28 21.63 26.54 31.08 39.77 ----34.9 37.74 --- 49 Table 7. CT values obtained in qPCR analysis for each primer set B. The templates are shown in different dilutions in all Ephemeroptera (starting from 70 pg/ µl). A full length COI barcode amplicon was used as template in qPCR for each target species. E1=Caenis diminuta, E2=Maccaffertium modestum, E3= Maccaffertium interpunctatum, T1=Chimarra obscura, T2=Ceratopsyche bronta, T3 = Ceratopsyche sparna. CT values in bold indicate target species for the primer set tested. -- did not pass threshold. log dilution Dilution E1 Primer on T1 amplicon E1 Primer on T2 amplicon E1 Primer on T3 amplicon E1 Primers on E1 amplicon E1 Primers on E2 amplicon E1 Primers on E3 amplicon -1 0.1 12.43 22.53 16.42 5.42 27.06 9.44 -2 0.01 18.48 26.49 21.58 9.58 30.05 12.52 -3 -4 -5 -6 0.001 0.0001 0.00001 0.000001 19.93 26.36 --20.35 25.21 --32.97 35.31 ----10.01 13.75 31.83 31.26 --25.7 29.33 --- log dilution Dilution E2 Primer on T1 amplicon E2 Primer on T2 amplicon E2 Primer on T3 amplicon E2 Primers on E1 amplicon E2 Primers on E2 amplicon E2 Primers on E3 amplicon -1 0.1 4.14 16.79 29.22 20.02 11.66 12.55 -2 0.01 11.25 20.49 32.64 23.49 15.32 15.34 -3 -4 -5 -6 0.001 0.0001 0.00001 0.000001 14.13 21.05 25.84 37.68 25.31 29.13 32.48 -35.51 36.7 -29.1 33.84 38.73 --25.72 30.76 33.84 17.13 21.9 25.6 34.89 log dilution Dilution E3 Primer on T1 amplicon E3 Primer on T2 amplicon E3 Primer on T3 amplicon E3 Primers on E1 amplicon E3 Primers on E2 amplicon E3 Primers on E3 amplicon -1 0.1 19.08 27.3 21.81 16.87 13.02 3.48 -2 0.01 22.63 33.23 25.94 20.87 17.62 5.5 -3 -4 -5 -6 0.001 0.0001 0.00001 0.000001 25.75 32.93 35.14 38.84 28.41 31.61 34.93 38.88 36.11 38.27 33.94 38.72 31.63 33.8 37.91 37.53 30.37 34.8 31.04 35.83 8.69 13.39 16.39 26.31 50 Table 8. Summary of the results from both qPCR and 454 pyrosequencing analysis. “Yes” for qPCR analysis means the target sample passed the threshold in an earlier cycle than any nontarget samples. “Yes” for 454 pyrosequencing means the target species produced a higher number of reads than non-target species. “No” represents the opposite pattern. T1: Chimarra obscura T2: Ceratopsyche bronta T3: Ceratopsyche sparna E1: Caenis diminuta E2: Maccaffertium modestum E3: Maccaffertium interpunctatum Target gDNA (setA) gDNA (setB) Amplicon (setA) Amplicon (setB) species qPCR 454 qPCR 454 qPCR 454 qPCR 454 T1 Yes Yes Yes Yes Yes Yes Yes Yes T2 Yes No No No Yes Yes Yes No T3 No No No Yes Yes Yes Yes Yes E1 Yes Yes Yes Yes No Yes Yes Yes E2 No Yes No No No Yes No No E3 Yes No No No Yes Yes Yes Yes 51 Table 9. The slope and efficiency of each primer set for amplicon-based material set A and set B. T1: Chimarra obscura T2: Ceratopsyche bronta T3: Ceratopsyche sparna E1: Caenis diminuta E2: Maccaffertium modestum E3: Maccaffertium interpunctatum T1 primer- set A SLOPE EFFICIENCY -6.323428571 0.439269283 -4.678285714 0.635887793 -0.856285714 13.71751548 -4.013714286 0.774785149 -3.665142857 0.874306715 -3.676 0.870832132 E1 primer- set A SLOPE EFFICIENCY -4.324 0.703206654 -0.19 183297.0711 -6.806 0.402584968 -2.542 1.473950642 -1.438 3.959184798 -7.285 0.371729124 T1 primer-set B SLOPE EFFICIENCY -4.32 0.704046656 -5.76 0.491458285 0 0 -3.3 1.009233003 -8.45 0.313237257 -6.035 0.464536105 E1 primer-set B SLOPE EFFICIENCY -2.28 1.745342234 -1.06 7.778013136 -4.649 0.640967658 -0.2014 92307.84074 -2.9969 1.156145846 -4.441 0.679478739 T2 primer- set A SLOPE EFFICIENCY -5.264 0.548708225 -2.803 1.273843726 -5.38 0.534170424 -5.097428571 0.571004194 -3.752 0.847245087 -2.247428571 1.785819424 E2 primer- set A SLOPE EFFICIENCY -6.239714286 0.446317857 -4.002 0.777767909 -2.531 1.483709227 -4.777 0.619333885 -4.207142857 0.728586041 -5.98 0.469684386 T2 primer-set B SLOPE EFFICIENCY -2.28 1.745342234 -1.06 7.778013136 -4.649 0.640967658 -0.2014 92307.84074 -2.9969 1.156145846 -4.441 0.679478739 E2 primer-set B SLOPE EFFICIENCY -2.28 1.745342234 -1.06 7.778013136 -4.649 0.640967658 -0.2014 92307.84074 -2.9969 1.156145846 -4.441 0.679478739 52 T3 primer- set A SLOPE EFFICIENCY -13.77 0.182011335 -17.035 0.144728963 -11.098 0.230570006 -1.797714286 2.599663628 0 0 -0.158 2133603.527 E3 primer- set A SLOPE EFFICIENCY -4.100285714 0.753417931 -1.891428571 2.37832095 -3.163142857 1.070814847 -4.474 0.67306816 -4.329142857 0.702129538 -4.750285714 0.623729396 T3 primer-set B SLOPE EFFICIENCY -2.28 1.745342234 -1.06 7.778013136 -4.649 0.640967658 -0.2014 92307.84074 -2.9969 1.156145846 -4.441 0.679478739 E3 primer-set B SLOPE EFFICIENCY -2.28 1.745342234 -1.06 7.778013136 -4.649 0.640967658 -0.2014 92307.84074 -2.9969 1.156145846 -4.441 0.679478739 Table 10. The number of reads for gDNA-based material with automated analysis approach for set A and B. The number of sequences captured by each tag is shown as well. T1 represents Chimarra obscura, T2 Ceratopsyche bronta, T3 Ceratopsyche sparna, E1 Caenis diminuta, E2 Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Set A Set B # of Sample Analysis Detected # of # of Primer used sequences type method species sequences sequences per tag 40F/183R 240F/545R T1 111 108 3 Chimarra T2 0 0 0 obscura T3 0 0 0 E1 0 0 0 Tag 16 E2 0 0 0 (111 reads total) E3 0 0 0 T1 4 0 4 Ceratopsyche T2 34 0 34 bronta T3 0 0 0 E1 179 0 179 Tag 50 E2 0 0 0 (217 reads total) E3 0 0 0 T1 0 0 0 Ceratopsyche T2 0 0 0 sparna T3 69 0 69 E1 0 0 0 Tag 51 E2 0 0 0 (69 reads total) E3 0 0 0 DNA Automated T1 0 0 0 Caenis T2 14 0 14 diminuta T3 0 0 0 E1 191 69 121 Tag 54 E2 0 0 0 (205 reads total) E3 0 0 0 T1 16 0 16 Maccaffertium T2 0 0 0 modestum T3 0 0 0 E1 0 0 0 Tag 56 E2 0 0 0 (16 reads total) E3 0 0 0 T1 0 0 0 Maccaffertium T2 0 0 0 interpunctatum T3 0 0 0 Tag 61 E1 0 0 0 (0 reads total) E2 0 0 0 E3 0 0 0 53 Table 11. Number of pyrosequencing reads from automated analysis of COI amplicon templates. The number of sequences captured by each tag is shown as well. T1 = Chimarra obscura, T2 =Ceratopsyche bronta, T3 =Ceratopsyche sparna, E1 =Caenis diminuta, E2 =Maccaffertium modestum E3 = Maccaffertium interpunctatum. Set A Set B # of Sample Analysis Detected # of # of Primer used sequences type method species sequences sequences per tag 40F/183R 240F/545R T1 45 41 4 Chimarra T2 30 0 30 obscura T3 0 0 0 E1 8 0 8 Tag 16 E2 0 0 0 (83 reads total) E3 0 0 0 T1 0 0 0 Ceratopsyche T2 122 37 85 bronta T3 0 0 0 Tag 50 E1 37 0 37 (159 reads E2 0 0 0 total) E3 0 0 0 T1 0 0 0 Ceratopsyche T2 21 0 21 sparna T3 109 0 109 Tag 51 E1 22 0 22 (152 reads E2 0 0 0 total) E3 0 0 0 Amplicon Automated T1 0 0 0 Caenis T2 25 0 25 diminuta T3 0 0 0 Tag 54 E1 170 32 138 (195 reads E2 0 0 0 total) E3 0 0 0 T1 0 0 0 Maccaffertium T2 49 0 49 modestum T3 0 0 0 E1 3 0 3 Tag 56 E2 0 0 0 (52 reads total) E3 0 0 0 T1 0 0 0 Maccaffertium T2 0 0 0 interpunctatum T3 0 0 0 E1 0 0 0 Tag 61 E2 0 0 0 (0 reads total) E3 0 0 0 54 Table 12. Number of reads for gDNA-based material with manual analysis approach for set A and B. The number of sequences captured by each tag is shown as well. T1 represents Chimarra obscura, T2 Ceratopsyche bronta, T3 Ceratopsyche sparna, E1 Caenis diminuta, E2 Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Set A Set B # of Sample Analysis Detected # of Target species sequences/ # of sequences type method species sequences tag 240F/545R 40F/183R T1 450 320 130 Chimarra T2 19 0 19 obscura T3 15 0 15 Tag 16 E1 0 0 0 (591 reads E2 47 0 47 total) E3 60 51 9 T1 160 4 156 Ceratopsyche T2 7 7 0 bronta T3 0 0 0 Tag 50 E1 466 1 465 (648 reads E2 15 15 0 total) E3 0 0 0 T1 11 0 1 T2 0 0 0 Ceratopsyche T3 4 0 4 sparna Tag 51 E1 0 0 0 (17reads total) E2 2 0 2 E3 0 0 0 DNA Manual T1 2 0 2 Caenis T2 1 1 0 diminuta T3 0 0 0 Tag 54 E1 288 100 188 (294 reads E2 6 1 5 total) E3 2 0 2 T1 333 0 333 Maccaffertium T2 0 0 0 modestum T3 0 0 0 Tag 56 E1 0 0 0 (516 reads E2 180 5 175 total) E3 3 0 3 T1 0 0 0 Maccaffertium T2 0 0 0 interpunctatum T3 53 0 53 E1 0 0 0 Tag 61 E2 0 0 0 (53 reads total) E3 0 0 0 55 Table 13. The number of reads for amplicon-based material with manual analysis approach of COI amplicon template for set A and B. The number of sequences captured by each tag is shown as well. T1 represents Chimarra obscura, T2 Ceratopsyche bronta, T3 Ceratopsyche sparna, E1 Caenis diminuta, E2 Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Set A Set B # of Sample Analysis Detected # of Primer used sequences # of sequences type method species sequences per tag 240F/545R 40F/183R T1 509 192 317 Chimarra T2 129 0 129 obscura T3 0 0 0 Tag 16 E1 27 0 27 (909 reads E2 175 0 175 total) E3 69 0 69 T1 317 0 317 Ceratopsyche T2 197 68 129 bronta T3 12 12 0 Tag 50 E1 27 0 27 (1021 reads E2 394 22 175 total) E3 74 5 69 T1 0 0 0 Ceratopsyche T2 74 10 64 sparna T3 168 34 138 Tag 51 E1 56 0 56 (302 reads E2 0 0 0 total) E3 4 0 4 Amplicon Manual T1 185 0 185 Caenis T2 138 2 136 diminuta T3 29 22 7 Tag 54 E1 411 60 351 (909 reads E2 121 19 102 total) E3 25 1 24 T1 157 13 144 Maccaffertium T2 116 46 70 modestum T3 29 26 3 Tag 56 E1 8 1 7 (623 reads E2 213 115 98 total) E3 100 53 47 T1 71 5 66 Maccaffertium T2 9 7 2 interpunctatum T3 28 28 0 Tag 61 E1 2 2 0 (537 reads E2 78 73 5 total) E3 349 143 206 56 FIGURES: Figure 1: Amplification plots showing threshold and baseline values of fluorescence. The threshold (dotted line) is set by either the machine itself or the researcher based on the experiments needs. ∆Rn is the difference between the emission intensity of a reporter dye divided by the emission intensity of a passive reference dye measured in each cycle. The CT value is the number of cycles required for each template to pass the threshold, the CT value indicated is for the sample shown by the purple line (QIAGEN 2006). CT Value 57 Figure 2. The workflow used in qPCR experiments involves two different approaches; running a qPCR on genomic DNA as template and using full-length DNA barcode amplicons as template. Target species Genomic DNA Full length Amplicon- purified and normalized PCR Folmer primer qPCR • • Matrix dilution of different primers Measurement 58 Matrix dilution of different primers • Standard curve Figure 3. 454 pyrosequencing experimental workflow. Equimolar amounts of each tagged amplicon were generated using the primers merged into one single lane of the 454 flow cell (1/16 run) and sorted bioinformatically after sequencing (for both set A and B). T1 T2 T3 E1 E2 E3 DNA mix or PCR mix Primer T1 Primer E3 Primer E2 Normalization Primer T2 PrimerT3 Primer E1 •16% •16% •16% •16% •16% •16% T1 primer product T2 primer product T3 primer product E1 primer product E2 primer product E3 primer product •16% •16% •16% •16% •16% •16% T1 T2 T3 E1 E2 E3 Emulation PCR & Data Analysis Tag 1 T1 primer Set A F R Tag 2 T2 Primer Tag3 T3 Primer Tag 4 E1 Primer Tag 5 E2 Primer Set B F R 59 Tage6 E3 Primer Figure 4. Exemplar standard curves for qPCR experiments using genomic DNA templates. Six dilutions were made for each curve to check the consistency of primer behavior. (T1) Chimarra obscura (Trichoptera, T1obs). (T2) Ceratopsyche bronta (Trichoptera, T2bro). (T3) Ceratopsyche sparna (Trichoptera, T3spa). Standard Curve for T1 Primer set B 36.9 CT Value 36.8 36.7 36.6 36.5 T1 36.4 36.3 -8 -6 -4 -2 0 log of Dilution Standard Curve for T2 primer set B 1.2 1 CT Value 0.8 0.6 0.4 T2 0.2 0 -6 -5 -4 -3 -2 -1 0 log of Dilution Standard Curve for T3 primer set B 50 CT Value 40 30 20 T3 10 0 -6 -5 -4 -3 -2 log of Dilution 60 -1 0 Figure 5. Standard curves for Chimarra obscura (Trichoptera, T1obs) (top panel), Ceratopsyche bronta (Trichoptera, T2bro) (middle panel) and Ceratopsyche sparna (Trichoptera, T3spa) (bottom panel) primers in amplicon based qPCR experiments. Six dilutions were made for each case to check the consistency of primer behavior. Standard Curve for T1 set B 40 CT Value 30 20 T1 10 0 -8 -6 -4 -2 0 log of Dilution Standard Curve for T2 set B 40 CT Value 30 20 T2 10 0 -8 -6 -4 -2 0 log of Dilution Standard Curve for T3 set B 80 CT Value 60 40 T3 20 0 -8 -6 -4 -2 log of Dilution 61 0 Figure 6. Exemplar Relative Amplified Copies (RAC) of COI from Chimarra obscura (T1) compared to 5 other target species. For example in the dilution 10-1 the amplified copies of T1 species is 212 times more than T2, 76 million times more than T3, 5million times more than E1, 7million times more than E2 and 18.6 million times more than E3. No histogram indicates lack of RAC value in a comparison. T2: Ceratopsyche bronta, T3: Ceratopsyche sparna. E1: Caenis diminuta E2: Maccaffertium modestum E3: Maccaffertium interpunctatum. Chimarra obscura (T1)-setA 9 Ceratopsyche bronta(T2) 8 Ceratopsyche sparna(T3) 7 Caenis diminuta(E1) log RAC 6 Maccaferritium modestum(E2) 5 Maccaferritium interpunctatum(E3) 4 3 2 1 0 10^-1 10^-2 10^-3 10^-4 PCR template concentrations series 62 10^-5 10^-6 Figure 7. MID distribution for gDNA based material. In the pie chart T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum, E3: Maccaffertium interpunctatum DNA Based MID Distribution 18% 16% T1 T2 T3 19% 18% E1 E2 E3 14% 15% 63 Figure 8. MID distribution for amplicon based material. In the pie chart T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum, E3: Maccaffertium interpunctatum Amplicon Based MID Distribution 9% 24% 17% T1 T2 T3 E1 14% 18% E2 E3 18% 64 APPENDIX 1. Standard curves for target samples, gDNA based DNA based qPCR experiment SetA – Trichoptera. Standard curves for Chimarra obscura-T1obs- (top), Ceratopsyche bronta-T2bro- (middle) and Ceratopsyche sparna-T3spa(bottom) primers in DNA based qPCR experiment. Six dilutions were made for each case to check the consistency of primer behavior. Standard Curve for T1obs primer Set A CT Value 60 50 40 30 20 10 0 -7 -6 -5 -4 -3 -2 -1 T1 0 log of Dilution Standard Curve for T2bro primer Set A 40 CT Value 30 20 T2 10 0 -6 -5 -4 -3 -2 -1 0 log of Dilution Standard Curve for T3spa primer Set A CT Value 15 10 5 T3 0 -6 -5 -4 -3 -2 log of Dilution 65 -1 0 DNA based qPCR experiment SetA- Ephemeroptera Standard curves for Caenis diminuta-E1dim-(top), Maccaffertium modestum -E2mod(middle) and Maccaffertium interpunctatum-E3spa-(bottom) primers in DNA based qPCR experiment. Six dilutions were made for each case to check the consistency of primer behavior. Standard Curve for E1dim primer Set A 50 CT Value 40 30 20 E1 10 0 -6 -5 -4 -3 -2 -1 0 log of Dilution Standard Curve for E2mod primer Set A 36 CT Value 35 34 33 E2 32 31 -6 -5 -4 -3 -2 -1 0 log of Dilution Standard Curve for E3int primer Set A 37 CT Value 36.5 36 E3 35.5 35 -6 -5 -4 -3 log of Dilution -2 66 -1 0 DNA based qPCR experiment SetB- Trichoptera Standard curves for Chimarra obscura-T1obs- (top), Ceratopsyche bronta-T2bro(middle) and Ceratopsyche sparna-T3spa-(bottom) primers in DNA based qPCR experiment. Six dilutions were made for each case to check the consistency of primer behavior. Standard Curve for T1obs primer set B CT Value 36.9 36.8 36.7 36.6 36.5 36.4 36.3 -6 -5 -4 -3 -2 -1 T1 0 log of Dilution Standard Curve for T2bro primer set B 1.2 CT Value 1 0.8 0.6 0.4 T2 0.2 0 -5 -4 -3 -2 -1 0 log of Dilution Standard Curve for T3spa primer set B 50 CT Value 40 30 20 T3 10 0 -5 -4 -3 -2 log of Dilution 67 -1 0 DNA based qPCR experiment SetB- Ephemeroptera Standard curves for Caenis diminuta-E1dim-(top), Maccaffertium modestum -E2mod(middle) and Maccaffertium interpunctatum-E3spa-(bottom) primers in DNA based qPCR experiment. Six dilutions were made for each case to check the consistency of primer behavior. Standard Curve for E1dim primer set B CT Value 35 30 25 20 15 10 5 0 -5 -4 -3 -2 -1 E1 0 log of Dilution Standard Curve for E2mod primer set B 40 CT Value 30 20 E2 10 0 -5 -4 -3 -2 -1 0 log of Dilution Standard Curve for E3int primer set B CT Value 39.5 39 38.5 38 37.5 37 36.5 36 -5 -4 -3 -2 log of Dilution 68 -1 E3 0 APPENDIX 2. Standard curve for target samples, amplicon based Amplicon based qPCR experiment material setA-Trichoptera. Standard curves for Chimarra obscura-T1obs- (top), Ceratopsyche bronta-T2bro- (middle) and Ceratopsyche sparna-T3spa-(bottom) primers in amplicon based qPCR experiment. Six dilutions were made for each case to check the consistency of primer behavior. Standard Curve for T1obs primer set A 30 25 CT Value 20 15 10 T1 5 0 -8 -6 -4 -2 0 log of Dilution Standard Curve for T2bro primer set A CT Value 30 25 20 15 10 5 0 -8 -6 -4 -2 T2 0 log of Dilution Standard Curve for T3spa primer set A CT Value 5 4 3 2 1 0 -8 -6 -4 -2 log of Dilution 69 T3 0 Amplicon based qPCR experiment material setA- Ephemeroptera Standard curves for Caenis diminuta-E1dim-(top), Maccaffertium modestum -E2mod(middle) and Maccaffertium interpunctatum-E3spa-(bottom) primers in amplicon based qPCR experiment. Six dilutions were made for each case to check the consistency of primer behavior. Standard Curve for E1dim primer set A 20 CT Value 15 10 E1 5 0 -8 -6 -4 -2 0 log of Dilution Standard Curve for E2mod primer set A 40 CT Value 30 20 E2 10 0 -8 -6 -4 -2 0 log of Dilution Standard Curve for E3int primer set A 25 CT Value 20 15 10 E3 5 0 -8 -6 -4 log of Dilution 70 -2 0 Amplicon based qPCR experiment SetB-Trichoptera Standard curves for Chimarra obscura-T1obs- (top), Ceratopsyche bronta-T2bro(middle) and Ceratopsyche sparna-T3spa-(bottom) primers in amplicon based qPCR experiment. Six dilutions were made for each case to check the consistency of primer behavior. Standard Curve for T1obs primer set B 40 CT Value 30 20 T1 10 0 -7 -6 -5 -4 -3 -2 -1 0 log of dilution Standard Curve for T2bro primer set B 40 CT value 30 20 T2 10 0 -7 -6 -5 -4 -3 -2 -1 0 log of Dilution Standard Curve for T3spa primer set B CT Value 70 60 50 40 30 20 10 0 -8 -6 -4 log of Dilution 71 -2 T3 0 Amplicon based qPCR experiment SetB-Ephemeroptera Standard curves for Caenis diminuta-E1dim-(top), Maccaffertium modestum -E2mod(middle) and Maccaffertium interpunctatum-E3spa-(bottom) primers in amplicon based qPCR experiment. Six dilutions were made for each case to check the consistency of primer behavior. Standard Curve for E1dim primer set B 20 CT Value 15 10 E1 5 0 -7 -6 -5 -4 -3 -2 -1 0 log of Dilution Standard Curve for E2mod primer set B 40 CT Value 30 20 E2 10 0 -7 -6 -5 -4 -3 -2 -1 0 log of Dilution Standard Curve for E3int primer set B 50 CT Value 40 30 20 E3 10 0 -7 -6 -5 -4 -3 log of Dilution 72 -2 -1 0 APPENDIX 3. 454 pyrosequencing analysis results Table 1. MID distribution in 454 pyrosequencing material. First column indicated the name of target primers which T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum, E3: Maccaffertium interpunctatum. The last two columns show the percentage of the target species that could be generated by the target primer in automated and manual analysis method. Species Tag # Raw reads % Automated % Manual T1 MID16 1051 10.56 56.23 T2 MID50 1256 17.28 51.6 T3 MID51 1011 6.82 6.62 E1 MID54 889 23.1 33.1 E2 MID56 1191 1.34 43.32 E3 MID61 1176 0 4.5 T1 MID16 2587 3.2 35.13 T2 MID50 1937 8.2 42.54 T3 MID51 1915 7.93 16 E1 MID54 1450 13.44 62.7 E2 MID56 1758 3 35.43 E3 MID61 908 0 59.1 DNA Amplicons 73 Comparison between the relative amplification copies obtained from qPCR method (first graph and table) and the number of reads obtained from 454 FLX pyrosequencer for sample Chimarra obscura (second graph and table). T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Chimarra obscura (T1)-setA 9 Ceratopsyche bronta(T2) 8 Ceratopsyche sparna(T3) 7 Caenis diminuta(E1) log RAC 6 Maccefferrtium modestum(E2) 5 Maccafferrtium interpunctatum(E3) 4 3 2 1 0 0.1 0.01 0.001 0.0001 0.00001 0.000001 PCR template concentration series T2 T3 0.1 212 76,026,550 0.01 90 -- 0.001 --- 0.0001 --- 0.00001 --- 0.000001 --- E1 E2 E3 221,969 7,103,014 18,615,486 9,503,318 19,406,007 -- ---- ---- ---- ---- 74 Next gen-Chimarra obscura(T1)-setA 250 Number of Reads 200 150 Seqtrim analysis Manual analysis 100 50 0 Generated Sequence T1-MID 16-Amplicon based 40/183 T1obs T2bro T3spa E1dim E2mod E3int SeqTrim analysis 0 0 0 8 0 0 Manual analysis 192 0 0 0 0 0 75 Comparison between the relative amplification copies obtained from qPCR method (first graph and table) and the number of reads obtained from 454 FLX pyrosequencer for sample Ceratopsyche bronta (second graph and table). T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Ceratopsyche bronta (T2)-setA Chimarra obscura(T1) Ceratopsyche sparna(T3) Caenis diminuta(E1) 5 Maccafferrtium modestum(E2) 4.5 4 Maccafferrtium interpunctatum(E3) log RAC 3.5 3 2.5 2 1.5 1 0.5 0 0.1 0.01 0.001 0.0001 0.00001 0.000001 PCR template concentration series T1 T3 0.1 765 1.64 0.01 1871 2 0.001 6383 1052.7 0.0001 -13400 0.00001 -2402 0.000001 --- E1 -- -- -- -- -- -- E2 E3 6.27 7.31 5 3 43 8659 498 37902 251 3822 --- 76 Next gen-Ceratopsyche bronta(T2)-setA 80 Number of Reads 70 60 50 40 Seqtrim analysis 30 Manual analysis 20 10 0 Generated Sequence T2-MID 50Amplicon based 40 F T1obs T2bro T3spa E1dim E2mod E3int SeqTrim analysis 0 0 0 0 0 0 77 Manual analysis 0 68 12 0 22 5 Comparison between the relative amplification copies obtained from qPCR method (first graph and table) and the number of reads obtained from 454 FLX pyrosequencer for sample Ceratopsyche sparna (second graph and table). T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Ceratopsyche sparna(T3)-setA 4 Chimarra obscura(T1) Ceratopsyche bronta(T2) 3.5 Caenis diminuta(E1) 3 Maccafferrtium modestum(E2) Maccafferrtium interpunctatum(E3) log RAC 2.5 2 1.5 1 0.5 0 0.1 0.01 0.001 0.0001 PCR template concentration series T1 T2 E1 0.1 7 1 786 0.01 885 296 289,6.30 0.001 2 1 111 0.0001 478 168 3 E2 E3 3 8 2,062 5,293 2 2 2 3 0.00001 0.000001 2 2 92 1 2 102 319 1 78 0.80 2 0.00001 0.000001 Next gen-Ceratopsyche sparna(T3)-40F 40 Number of Reads 35 30 25 20 Seqtrim analysis 15 manual analysis 10 5 0 Generated sequence T1obs T2bro T3spa E1dim E2mod E3int T3-MID 51PCR 40/183 SeqTrim manual analysis analysis 0 0 0 10 0 34 0 0 0 0 0 0 79 Comparison between the relative amplification copies obtained from qPCR method (first graph and table) and the number of reads obtained from 454 FLX pyrosequencer for sample Caenis diminuta (second graph and table). T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Caenis diminuta(E1)-setA Chimarra obscura(T1) Ceratopsyche bronta(T2) log RAC 10 Ceratopsyche sparna(T3) 8 Maccafferrtium modestum(E2) 6 Maccafferrtium interpunctatum(E3) 4 2 0 0.1 0.01 0.001 0.0001 0.00001 0.000001 -2 -4 -6 PCR template concentration series T1 T2 0.1 65 14 0.01 627,823 9,307,743 0.001 6,956,836 204,253 T3 E2 E3 8 31 73 8,102,861 0.003 3,902 44762 16,497 110,540,515 0.0001 80,361,436 284,881 0.0003 46020 1,155,431 80 0.00001 2 85,284 0.000001 17,079 3,082 2,117,3.91 7,739,7.54 28,329 2,418 84,695 6,338 Next gen-Caenis diminuta(E1)--setA 70 Number of Reads 60 50 40 Seqtrim analysis 30 Manual analysis 20 10 0 Generated Sequence T1obs T2bro T3spa E1dim E2mod E3int E1-MID 54PCR 40/183 SeqTrim manual analysis analysis 32 0 0 2 0 22 0 60 0 19 0 1 81 Comparison between the relative amplification copies obtained from qPCR method (first graph and table) and the number of reads obtained from 454 FLX pyrosequencer for sample Maccaffertium modestum (second graph and table). T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Maccafferrtium modestum(E2)-setA Chimarra obscura(T1) 9 8 Ceratopsyche bronta(T2) 7 Ceratopsyche sparna(T3) log RAC 6 Caenis diminuta(E1) 5 Maccafferrtium interpunctatum(E3) 4 3 2 1 0 0.1 0.01 0.001 0.0001 0.00001 0.000001 PCR template concentration series T1 T2 T3 E1 E3 0.1 43,064,627 978,356 13,722,119 19,082 23 0.01 -7,005,225 4,558,096 253,214 58 0.001 ---8902 1 0.0001 345 89 -3848 25 82 0.00001 280 89 --37 0.000001 -182 --19 Next gen-Maccafferrtium modestum(E2)-setA 140 Number of Reads 120 100 80 Seqtrim analysis 60 manual analysis 40 20 0 Generated Sequence T1obs T2bro T3spa E1dim E2mod E3int E2-MID 56Amplicon based 40/183 SeqTrim manual analysis analysis 0 13 0 46 0 26 0 1 0 115 0 53 83 Comparison between the relative amplification copies obtained from qPCR method (first graph and table) and the number of reads obtained from 454 FLX pyrosequencer for sample Maccaffertium interpunctatum (second graph and table). T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Maccafferrtium interpunctatum(E3) -setA 10 Chimarra obscura(T1) 9 Ceratopsyche bronta(T2) 8 Ceratopsyche sparna(T3) Caenis diminuta(E1) 7 log RAC Macceferritium modestum(E2) 6 5 4 3 2 1 0 0.1 0.01 0.001 0.0001 0.00001 PCR template concentration series T1 T2 T3 0.1 884,324,121 579,406,248 139,917,386 E1 E2 3,454,391 142 0.01 ---- 0.001 ---- 0.0001 225 70 99,334 3,576,210 2,567,49.2 37 4 84 4,420 109 0.00001 0.000001 209 261 58 81 20,171 -3,125 80 3,326 112 0.000001 Next gen-Maccafferrtium interpunctatum(E3) -setA 160 Numeber of Reads 140 120 100 80 Seqtrim analysis 60 Manual analysis 40 20 0 T1obs T2bro T1obs T2bro T3spa E1dim E2mod E3int T3spa E1dim Generated Sequence E2mod E3-MID 61Amplicon based 40/183 Seqtrim manual analysis analysis 0 5 0 7 0 28 0 2 0 73 0 143 85 E3int T1obs T2bro T3spa E1dim E2mod E3int Comparison between the relative amplification copies obtained from qPCR method (first graph and table) and the number of reads obtained from 454 FLX pyrosequencer for sample Chimarra obscura (second graph and table). T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Chimarra obscura (T1)-setB 14.00 Ceratopsyche bronta(T2) 12.00 Ceratopsyche sparna(T3) log RAC 10.00 Caenis diminuta(E1) 8.00 Maccafferrtium modestum(E2) 6.00 Maccafferrtium(E3) 4.00 2.00 0.00 0.1 -2.00 T2 T3 E1 E2 E3 -1 5220.60 660965624.00 978356.00 30573.63 307451.64 0.01 0.001 0.0001 0.00001 0.000001 PCR template concentration series -2 174.85 16,431,945 4,653,871 364 3,061 -3 44,453 3,245,479 48,115,553 910 546,552 -4 16384 43,238 22,985,420,368 21 35,858 86 -5 2,179 1,675 100,611,202,922 12 4,482 -6 0.75 1.28 452,773,950,009 0.78 1 Next gen-Chimarra obscura(T1) -setB 350 Number of Reads 300 250 200 Seqtrim analysis 150 Manual analysis 100 50 0 Generated Sequence T1-MID 16-Amplicon based 240/545 Seqtrim analysis manual analysis T1obs 0 317 T2bro 10 129 T3spa 0 0 E1dim 66 27 E2mod 0 175 E3int 0 69 87 Comparison between the relative amplification copies obtained from qPCR method (first graph and table) and the number of reads obtained from 454 FLX pyrosequencer for sample Ceratopsyche bronta (second graph and table). T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Ceratopsyche bronta (T2) -setB 12.00 Chimarra obscura(T1) 10.00 Ceratopsyche sparna(T3) Caenis diminuta(E1) 8.00 Maccafferrtium modestum(E2) log RAC 6.00 Maccafferrtium(E3) 4.00 2.00 0.00 0.1 0.01 0.001 0.0001 0.00001 0.000001 -2.00 -4.00 -6.00 -8.00 T1 T3 E1 E2 E3 PCR template concentration series -1 0.00 7.94 0.00 0.14 0.04 -2 0.00 27 0.00 0.55 0.02 -3 0.00 56 0.00 2 11 -4 0.00 1 0.00 0.18 0.00 88 -5 -6 5,990,378,433 ---2,425,750 1,233,405,466 84,603,599,871 -15,120,473 6,692,972,775 Next gen-Ceratopsyche bronta (T2) -setB 350 Number of Reads 300 250 200 Seqtrim analysis 150 Manual analysis 100 50 0 Generated Sequences T2-MID 50Amplicon based 240/545 T1obs T2bro T3spa E1dim E2mod E3int SeqTrim analysis 0 10 0 66 0 0 89 manual analysis 317 129 0 27 175 69 Comparison between the relative amplification copies obtained from qPCR method (first graph and table) and the number of reads obtained from 454 FLX pyrosequencer for sample Ceratopsyche sparna (second graph and table). T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Ceratopsyche sparna (T3) -setB 15.00 Chimarra obscura(T1) Ceratopsyche bronta(T2) 10.00 Caenis diminuta(E1) log RAC 5.00 Maccafferrtium modestum(E2) Maccafferrtium interpunctatom (E3) 0.00 0.1 0.01 0.001 0.0001 0.00001 0.000001 -5.00 -10.00 -15.00 T1 T2 E1 E2 E3 -1 25 0.89 25606380 2449771426 6244764411 PCR template concentration series -2 216 0.64 279,018 45,205,657 31,744,426 -3 34 17,079 3,147 218,913 71,715 90 -4 0.00 12 0.00 9 0.00 -5 --2,269,928,957 --- -6 --937,481,977,746 --- Next gen-Ceratopsyche sparna (T3) -setB 400 Number of Reads 350 300 250 200 Seqtrim analysis 150 Manual analysis 100 50 0 Generated Sequence T1obs T2bro T3spa E1dim E2mod E3int T3-MID 51Am0plicon based 240/545 F Seqtrim manual analysis analysis 1 0 146 64 277 138 338 56 0 0 0 4 91 Comparison between the relative amplification copies obtained from qPCR method (first graph and table) and the number of reads obtained from 454 FLX pyrosequencer for sample Caenis diminuta (second graph and table). T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Caenis diminuta (E1) -setB 8.00 Chimarra obscura(T1) 6.00 Ceratopsyche bronta(T2) 4.00 Ceratopsyche sparna(T3) Maccafferrtium modestum(E2) log RAC 2.00 Maccafferrtium interpunctatom (E3) 0.00 0.1 0.01 0.001 0.0001 0.00001 0.000001 -2.00 -4.00 -6.00 -8.00 -10.00 T1 T2 T3 E2 E3 -1 129 141457 2048 3268053 16 PCR template concentration series -2 478 123145 4096 1452392 8 -3 760 1355130 89525 11945799 33,923 -4 6,251 2,817 3,091,766 186,653 48,983 92 -5 843 359 0.00 891 5,293 -6 ------ Next gen-Caenis diminuta (E1) -setB 400 Numebr of Reads 350 300 250 Seqtrim analysis 200 manual analysis 150 100 50 0 Generated Sequence T1obs T2bro T3spa E1dim E2mod E3int E1-MID 54Amplicon based 240/545 Seqtrim manual analysis analysis 0 185 25 136 0 7 141 351 0 102 0 24 93 Comparison between the relative amplification copies obtained from qPCR method (first graph and table) and the number of reads obtained from 454 FLX pyrosequencer for sample Maccaffertium modestum (second graph and table). T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Maccafferrtium modestum (E2) -setB 6.00 Chimarra obscura(T1) 4.00 Ceratopsyche bronta(T2) 2.00 Ceratopsyche sparna(T3) log RAC 0.00 -2.00 0.1 0.01 0.001 0.0001 0.00001 0.000001 -4.00 Caenis diminuta(E1) Maccafferrtium interpunctatom (E3) -6.00 -8.00 -10.00 -12.00 T1 T2 T3 E1 E3 PCR template concentration series -1 0.00 19 104272 177 0.54 -2 0.06 35 161368 284 0.99 -3 0.03 38 45387 40 134 -4 0.55 150 28526 3929 464 94 -5 1.18 118 0.00 8964 302 -6 7 ----- Next gen-Maccafferrtium modestum (E2) -setB 160 140 Number of Reads 120 100 Seqtrim analysis 80 Manual analysis 60 40 20 0 Generated Sequence T1obs T2bro T3spa E1dim E2mod E3int E2-MID 56Amplicon based 240/545 Seqtrim manual analysis analysis 0 144 49 70 0 3 3 7 0 98 0 47 95 Comparison between the relative amplification copies obtained from qPCR method (first graph and table) and the number of reads obtained from 454 FLX pyrosequencer for sample Maccaffertium interpunctatum (second graph and table). T1 represents Chimarra obscura, T2: Ceratopsyche bronta, T3: Ceratopsyche sparna, E1: Caenis diminuta, E2: Maccaffertium modestum and E3 is Maccaffertium interpunctatum. Maccafferrtium interpunctatum (E3) -setB 6.00 Chimarra obscura(T1) 4.00 Ceratopsyche bronta(T2) Ceratopsyche sparna(T3) 2.00 log RAC Caenis diminuta(E1) 0.00 Maccafferrtium modestum(E2) 0.1 0.01 0.001 0.0001 0.00001 0.000001 -2.00 -4.00 -6.00 -8.00 T1 T2 T3 E1 E2 PCR template concentration series -1 67 19893 443 14 5 -2 32 50012 319 9 0.33 -3 0.11 76 0.75 0.01 -- -4 0.27 0.11 11 0.50 -- 96 -5 17 15 7 117 -- -6 8 8 7 3 -- Next gen-Maccafferrtium interpunctatum (E3) -setB 250 Number of Reads 200 150 Seqtrim analysis Manual analysis 100 50 0 Generated Sequence T1obs T2bro T3spa E1dim E2mod E3int E3-MID 61Amplicon based 240/545 Seqtrim manual analysis analysis 0 66 0 2 0 0 0 0 0 5 0 206 97