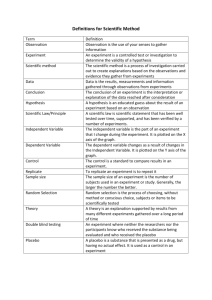
Probability and p-values
advertisement

Probability: What is a p-value?
Suppose we run a clinical trial to compare two treatments, A and B. We get these values
for the response for each patient.
Treatment
A
A
A
A
A
A
A
A
A
A
A
Mean
Response
6
11
15
18
29
33
34
46
49
73
102
37.82
Treatment
B
B
B
B
B
B
B
B
B
B
B
Mean
Response
12
13
14
23
26
33
59
59
69
75
78
41.91
The difference between the means is 41.91 – 38.82 = 4.09.
Before we begin the experiment, we assume that there is no difference between treatment
A and treatment B (the null hypothesis), that both samples are random samples from the
same parent population.
We perform the experiment to gather evidence that there is a difference (to reject the null
hypothesis).
The null hypothesis is that there is no difference between treatment A and treatment B,
and that both treatment groups are random samples from the same parent population.
If the null hypothesis is true, then any difference between the means of the two samples is
just the result of random sampling – the particular observations from the parent
population that, by random selection, were assigned to A or B.
You might think of this as though everyone in both A and B actually got the same
treatment. For example, everyone actually got a placebo.
So we can ask the following question.
If the null hypothesis is true (that there is no real difference between the
treatments),
then what is the probability that we would observe as big a difference between the
means of A and B as we see in the clinical trial data just by chance?
One way to estimate this probability would be to do the following experiment.
1. Select a group of patients from the same population of patients as were used in the
first trial.
2. Give each patient a placebo.
3. Randomly assign each patient the label “A” or “B”.
4. Calculate the mean of those patients labeled “A”
5. Calculate the mean of those patients labeled “B”
6. Calculate the difference between the mean of group “A” and the mean of group
“B”.
7. Repeat this process 100 times, giving 100 random samples.
After completing the process for the 100 random samples, count the proportion of times
that the (absolute value) of the difference in means (A vs B) for the original clinical trial
is more extreme than the difference in means for the 100 random samples.
If the (absolute value) of the difference in means (A vs B) for the original clinical trial is
more extreme than the difference in means for the ALL 100 random samples, then we can
make the following statement.
If it is true that there is no difference between treatment A and treatment B (the null
hypothesis), the probability that we would observe as large a difference between the
means of A and B as we see in the clinical trial data just by chance is less than 1 in 100,
or P < 0.01.
Here’s an alternative way to say the same thing.
If the null hypothesis is true (no difference between A and B), then the probability is P <
0.01 that we would observe as large a difference between the means of A and B (as in the
clinical trial) just by chance.
The p-value is the probability of the observed result, or a more extreme result, if the null
hypothesis is true.
Here’s a simulation to illustrate the idea, and to show how to estimate p-values in
practice.
We’ll start with the original clinical trial data that we showed above.
Original data
Treatment
A
A
A
A
A
Response
6
11
15
18
29
Treatment
B
B
B
B
B
Response
12
13
14
23
26
A
A
A
A
A
A
Mean
33
34
46
49
73
102
37.82
B
B
B
B
B
B
Mean
33
59
59
69
75
78
41.91
Difference between the means is 41.91 – 38.82 = 4.09.
We are asking this question. If the null hypothesis is true (that there is no real difference
between the treatments), what is the probability that we would observe as large a
difference between the means of A and B as we see in the clinical trial data just by
chance?
We saw above a way to estimate this probability that used many samples taken from the
parent population, where all the patients received placebo. Usually, we can’t take many
samples. Can we simulate that experiment using the data from the one clinical trial that
we have?
If the null hypothesis is true (the labels “A” and “B” don’t mean anything), then we can
randomly shuffle the labels “A” and “B” among the patients. So we can perform the
following simulation.
1. Start with the original clinical trial data.
2. Randomly shuffle the labels “A” or “B” among all the patients.
a. To do this, take a stack of index cards, label them "A" or "B" in the same
proportion as in the original data, then shuffle them.
b. Assign the (shuffled) labels to the patients.
c. Now, some patients who were labeled “A” will be labeled “B”, and vice
versa. The total number of patients labeled “A” is unchanged, as is the
total number labeled “B”.
3. Calculate the mean of those patients labeled “A”
4. Calculate the mean of those patients labeled “B”
5. Calculate the difference between the mean of group “A” and the mean of group
“B”.
6. Repeat this process 100 times, giving 100 random samples.
After completing the process for the 100 random shuffles, count the proportion of times
that the (absolute value) of the difference in means (A vs B) for the original clinical trial
is greater than the difference in means for the 100 random samples.
Here’s an example of what we get when we do one random shuffle of the labels for the
original clinical trial.
First random shuffle of the data
Treatment
A
A
A
A
A
A
A
A
A
A
A
Mean
Response
26
29
11
15
23
49
75
69
102
6
59
42.18
Treatment
B
B
B
B
B
B
B
B
B
B
B
Mean
Response
12
34
73
33
18
13
46
59
14
78
33
37.55
The difference between A and B in the original clinical trial was 4.09. When we
randomly shuffle the labels (which is legitimate if the null hypothesis is true), we get a
difference of |-4.64| = 4.64. So when we randomly shuffle the labels, we get a bigger
difference between the means of A and B than we did in the original clinical trial. Let’s
do another random shuffle.
Second random shuffle of the data
Treatment
A
A
A
A
A
A
A
A
A
A
A
Mean
Response
18
14
34
33
13
29
73
75
46
12
33
34.55
Treatment
B
B
B
B
B
B
B
B
B
B
B
Mean
Response
59
26
59
49
78
102
23
6
15
11
69
45.18
This time the random shuffle gives us a difference of 45.18-34.55 = 10.64. Again, when
we randomly shuffle the labels, we get a bigger difference between the means of A and B
than we did in the original clinical trial. By now we should be starting to think that the
difference between the samples in the original clinical trial could be produced just by
random sampling, even if the two treatments didn’t differ.
We want to do a large number of random shuffles (at least 100, preferably more) to count
the proportion of times that the (absolute value) of the difference in means (A vs B) for
the original clinical trial is greater than the difference in means for the random samples.
Simulation of random shuffles using R
Here’s some code in the R statistics language to do the simulation.
You can install R for free by downloading it from the website
http://cran.r-project.org/
In California, a convenient mirror site where you can download R is at Berekely.
http://cran.cnr.Berkeley.edu
# Example of generating random permutations to see if an observed difference between
# the means of two groups is large compared to differences between randomly generated
groups
# Here’s the original data from the clinical trial, stored in a vector x. The first 11 values
are for treatment A, the second 11 are for treatment B.
x=c(6,11,15,18,29,33,34,46,49,73,102,12,13,14,23,26,33,59,59,69,75,78)
# Calculate the difference between the means.
mean(x[12:22])-mean(x[1:11])
[1] 4.090909
# Take 100 random samples with two groups each from x and calculate the difference
between the means of the two groups. We use the R function “sample()” to perform the
random shuffle (sample without replacement). We store the difference between the means
for the 100 samples in the variable “diff”.
diff=0
for(permutation in 1:100)
{
y=sample(x,22)
diff[permutation]=mean(y[1:11])-mean(y[12:22])
}
# Here are the differences between the randomly generated groups
print(diff)
> print(diff)
[1]
[6]
1.72727273
3.18181818
3.54545455
4.09090909
15.90909091
0.09090909
2.09090909
15.36363636
3.54545455
-2.45454545
[11]
[16]
[21]
[26]
[31]
[36]
[41]
[46]
[51]
[56]
[61]
[66]
[71]
[76]
[81]
[86]
[91]
[96]
>
-7.18181818
-3.72727273
8.63636364
-5.54545455
-13.00000000
-12.81818182
11.90909091
1.54545455
-3.72727273
20.27272727
-0.45454545
-7.18181818
-6.27272727
2.81818182
-9.18181818
-17.54545455
6.09090909
-10.27272727
5.18181818
3.90909091
-4.27272727
-15.72727273
-29.00000000
0.63636364
-19.36363636
-9.36363636
-0.09090909
-14.63636364
-6.63636364
13.90909091
-4.27272727
-2.27272727
-2.09090909
-3.00000000
-8.45454545
3.36363636
14.45454545
-19.72727273
-21.36363636
7.18181818
1.18181818
-0.09090909
-17.36363636
11.36363636
19.72727273
7.72727273
-15.36363636
-9.00000000
-4.27272727
20.63636364
7.90909091
4.45454545
8.45454545
-8.81818182
1.18181818
1.54545455
17.54545455
-7.18181818
1.36363636
-36.27272727
-15.90909091
-38.63636364
16.45454545
5.00000000
1.72727273
10.63636364
9.00000000
7.36363636
19.54545455
5.36363636
-4.45454545
-15.18181818
13.54545455
-2.63636364
-11.90909091
0.27272727
-8.27272727
12.09090909
23.90909091
-3.54545455
-0.81818182
-17.54545455
9.36363636
-10.27272727
22.09090909
-22.09090909
-20.45454545
-1.00000000
-1.90909091
20.45454545
# Here are the differences between the randomly generated groups, now sorted
sort(diff)
> sort(diff)
[1]
[6]
[11]
[16]
[21]
[26]
[31]
[36]
[41]
[46]
[51]
[56]
[61]
[66]
[71]
[76]
[81]
[86]
[91]
[96]
>
-38.63636364
-20.45454545
-17.36363636
-14.63636364
-10.27272727
-8.45454545
-6.63636364
-4.27272727
-3.00000000
-1.90909091
-0.09090909
1.18181818
1.72727273
3.54545455
5.00000000
7.36363636
9.00000000
12.09090909
15.90909091
20.27272727
-36.27272727
-19.72727273
-15.90909091
-13.00000000
-9.36363636
-8.27272727
-6.27272727
-4.27272727
-2.63636364
-1.00000000
0.09090909
1.36363636
2.09090909
3.54545455
5.18181818
7.72727273
9.36363636
13.54545455
16.45454545
20.45454545
-29.00000000
-19.36363636
-15.72727273
-12.81818182
-9.18181818
-7.18181818
-5.54545455
-3.72727273
-2.45454545
-0.81818182
0.27272727
1.54545455
2.81818182
3.90909091
5.36363636
7.90909091
10.63636364
13.90909091
17.54545455
20.63636364
-22.09090909
-17.54545455
-15.36363636
-11.90909091
-9.00000000
-7.18181818
-4.45454545
-3.72727273
-2.27272727
-0.45454545
0.63636364
1.54545455
3.18181818
4.09090909
6.09090909
8.45454545
11.36363636
14.45454545
19.54545455
22.09090909
-21.36363636
-17.54545455
-15.18181818
-10.27272727
-8.81818182
-7.18181818
-4.27272727
-3.54545455
-2.09090909
-0.09090909
1.18181818
1.72727273
3.36363636
4.45454545
7.18181818
8.63636364
11.90909091
15.36363636
19.72727273
23.90909091
In these random shuffles, the differences between the mean range from -38.6 to 23.9.
# Here is a histogram showing the differences between the randomly generated groups
hist(diff,
main = "Histogram of differences between the means \n for 100 randomly generated
groups",
xlab="Difference between the means")
What percent of the 100 random shuffles that have difference between the mean with
absolute value greater than 4.09? For this set of 100 random shuffles, 69 percent of the
random shuffles have a difference between the mean with absolute value greater than
4.09. So the probability that a random sample of two groups (A and B) will have a
difference between the mean with absolute value greater than 4.09 is P=0.69.
Recall our earlier question:
If the null hypothesis is true (that there is no real difference between the
treatments), what is the probability that we would observe as large a difference
between the means of A and B as we see in the clinical trial data just by chance?
The probability is P=0.69. That is, even if there is no difference between the treatment
groups, 69% of the time we would get a difference between the means more extreme than
the value of 4.09 in the original data. This is what a p-value means.
Suppose that the difference between the means in the original clinical trial data was 41. In
our 100 random shuffles, the most extreme difference in the means was |-38| = 38. If the
original difference in means was 41, we would make the following statement.
If the null hypothesis is true (that there is no real difference between the treatments), the
probability that we would observe as large a difference between the means of A and B as
we see in the clinical trial data is less than 1/100, or p < 0.01.
Suppose that our 100 random shuffles, four of the random differences (4/100) were more
extreme than in our original clinical trial. Then we would make the following statement.
If the null hypothesis is true (that there is no real difference between the treatments), the
probability that we would observe as large a difference between the means of A and B as
we see in the clinical trial data is approximately 4/100, or p =0.04. We could get more
precision by doing more random shuffles. Doing 1,000 or 10,000 would give us increased
precision.
This randomization / permutation method for estimating p-values underlies the p-values
that we get for t-tests, anova, regression, and many other statistics tests. Doing
permutations and random samples is computationally expensive. When statisticians were
developing the t-test, ANOVA, regression, and similar methods, they didn’t have
computers to take random samples. So they developed analytical methods that were easy
to calculate (by making certain assumptions, such as normal distributions) that gave good
approximations to the p-values you get by doing permutations and random samples.
A simulation to illustrate p-values when the two treatment groups do not differ
Suppose that we have the following situation.
We have one population. Everyone got a placebo.
We perform an experiment: take two samples (as in a clinical trial) and perform a test
(such as a t-test) to see if the treatment groups are different).
If there is no difference between the two treatment groups (both got placebo), we expect
to get a p-value of 0.05 in about 1 in 20 experiments (samples).
If we do a simulation, will we get p-value < 0.05 in about 1 in 20 experiments?
# Let's generate 10,000 patients who receive a placebo.
placebo= rnorm(10000, 150, 20)
mean(placebo)
sd(placebo)
> mean(placebo)
[1] 150.1079
> sd(placebo)
[1] 20.16905
# Plot the 10,000 points.
plot(density(placebo), xlim= c(50, 250),ylim=c(0,.025))
# Take samples each of size n = 30
placebo.sample1 = sample(placebo, size=30)
placebo.sample2 = sample(placebo, size=30)
# Plot the two samples
plot(density(placebo.sample1), xlim= c(50, 250),ylim=c(0, .025))
lines(density(placebo.sample2), lty=2)
# Do a t-test to see if the two samples are different
t.test(placebo.sample1, placebo.sample2, var.equal=TRUE)
ttest.result = t.test(placebo.sample1, placebo.sample2, var.equal=TRUE)
ttest.result$p.value
> t.test(placebo.sample1, placebo.sample2, var.equal=TRUE)
Two Sample t-test
data: placebo.sample1 and placebo.sample2
t = -0.3914, df = 58, p-value = 0.697
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-11.750072
7.906978
sample estimates:
mean of x mean of y
148.9798 150.9014
> ttest.result = t.test(placebo.sample1, placebo.sample2,
var.equal=TRUE)
> ttest.result$p.value
[1] 0.6969725
>
The p-value of 0.69 indicates that the two samples are not different.
# Repeat sampling and t-test a few times.
placebo.sample1= sample(placebo, size=30)
placebo.sample2= sample(placebo, size=30)
t.test(placebo.sample1, placebo.sample2, var.equal=TRUE)
ttest.result = t.test(placebo.sample1, placebo.sample2, var.equal=TRUE)
ttest.result$p.value
> ttest.result$p.value
[1] 0.4570366
> ttest.result$p.value
[1] 0.9336696
> ttest.result$p.value
[1] 0.0993568
> ttest.result$p.value
[1] 0.2260408
# We get many different p-values, just by taking a different sample.
# What is the probability that we will detect a significant difference (p < 0.05) if we take
many samples of size n=30?
To answer that question, let's do a simulation of 1000 samples and t-tests, and look at the
distribution of p-values.
rm(pvalue.list)
pvalue.list = c()
for (i in 1:1000)
{
placebo.sample1= sample(placebo, size=30)
placebo.sample2= sample(placebo, size=30)
pvalue.list[i] = t.test(placebo.sample1, placebo.sample2, var.equal=TRUE)$p.value
pvalue.list
}
# Plot the pvalue.list
hist(pvalue.list, xlim= c(0, 1), breaks=seq(0,1,.05), ylim=c(0,1000))
We have one population. Everyone got a placebo.
We performed an experiment: take two samples (as in a clinical trial) and perform a test
(such as a t-test) to see if the treatment groups are different).
If there is no difference between the two treatment groups (both got placebo), we expect
to get a p-value of 0.05 or less in about 1 in 20 experiments (samples) 1/20 = 0.05.
# How many of the 1000 simulated samples give a p-value less than 0.05?
PLT05=sum(sort(pvalue.list)<.05)
PLT05
[1] 46
PLT05/1000
[1] 0.046
In 1000 simulated experiments, we got 46 p-values less than 0.05, which is close to the
expected number of 0.05*1000 = 50.