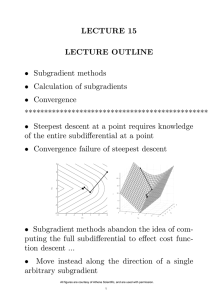
Appendix s1 We introduce a simple optimization procedure for the
advertisement

Appendix s1
We introduce a simple optimization procedure for the support vector machine as
described in Equation (5). Recall that objective is
n
1
2
𝐺(𝑊) = min [ ||𝑊|| + 𝐶 ∑ max(1 − yi 𝑊 T Xi , 0)]
𝑊 2
i=1
Because it is not strictly monotonic, we can calculate the subgradient directions of
the objective function as follows,
0 −𝑦𝑖 𝑊 𝑇 𝑋𝑖 < −1
𝜕𝐺
𝑦𝑖 𝑋𝑖
=𝑊+∑
−
𝑦𝑖 𝑊 𝑇 𝑋𝑖 = 1
𝜕𝑊
2
𝑖
{ −𝑦𝑖 𝑋𝑖 −𝑦𝑖 𝑊 𝑇 𝑋𝑖 > −1
and iteratively optimize the support vector machine objective.
Algorithm 1: Subgradient descent optimization for SVM
Input: Features 𝑿, labels 𝒚, parameter 𝐶, precision 𝜖
Output: Learned weight parameters 𝑊
1. Initilaize weight parameters 𝑊 with random values ranging from 0 to 1.
𝜕𝐺
2. For all elements 𝑋𝑖 ∈ 𝑿, 𝑦𝑖 ∈ 𝒚 calculate Δ𝑊 = 𝜕𝑊 using the equation
above the algorithm.
3. Update 𝑊𝑡+1 = 𝑊𝑡 + 𝜂Δ𝑊, where 𝑡 is an index for the iteration and 𝜂 is a
step size parameter (i.e., a small number like 0.01)
4. If the maximum difference between 𝑊𝑡+1 and 𝑊𝑡 is smaller than the
precision 𝜖, terminate the algorithm and return outputs. Otherwise, iterate
step 2-3 until convergence.